BLIP
- 核心思想
- MED架构和CapFilt方法
- 效果
- 总结
- CLIP模型 VS BLIP模型
- CLIP模型
- BLIP模型
核心思想
论文:https://proceedings.mlr.press/v162/li22n/li22n.pdf
代码:https://github.com/salesforce/BLIP
BLIP(Bootstrapping Language-Image Pre-training)是一个用于统一视觉-语言理解和生成任务的预训练框架。
专门设计来提升多种视觉和语言任务的性能,包括图像-文本检索、图像描述生成、视觉问答(VQA)、自然语言视觉推理(NLVR^2)、和视觉对话(VisDial)等。
组成:
-
多模态混合编解码器(Multimodal Mixture of Encoder-Decoder, MED):
- BLIP提出了一个新的模型架构,称为MED。这个架构可以作为单模态编码器、图像基础文本编码器或图像基础文本解码器来操作。这种多功能性使得MED能够有效地进行多任务预训练,并灵活地迁移到多种下游任务。
-
数据集引导(Dataset Bootstrapping):
- 为了有效利用从网上收集的含噪声的图像-文本对,BLIP通过一个称为CapFilt的机制来优化数据质量。CapFilt包括两个组件:一个标题生成器(Captioner)用于生成合成标题,和一个过滤器(Filter)用于移除不准确或噪声文本。这种机制使得BLIP能够从次优的监督数据中学习,并提高下游任务的性能。
-
预训练目标:
- BLIP在预训练时联合优化多个目标,包括图像-文本对比损失(ITC)、图像-文本匹配损失(ITM)和语言模型损失(LM)。这些目标帮助BLIP学习图像和文本间的对齐和细粒度关联,并生成文本描述。
-
零样本迁移学习:
- BLIP展现出强大的泛化能力,能够在零样本设置下直接迁移到视频-语言任务,这表明它学习到的视觉-语言表示具有广泛的适用性。
-
开源和可访问性:
- BLIP的代码和模型被开源,使得研究社区可以使用和进一步发展这个框架。
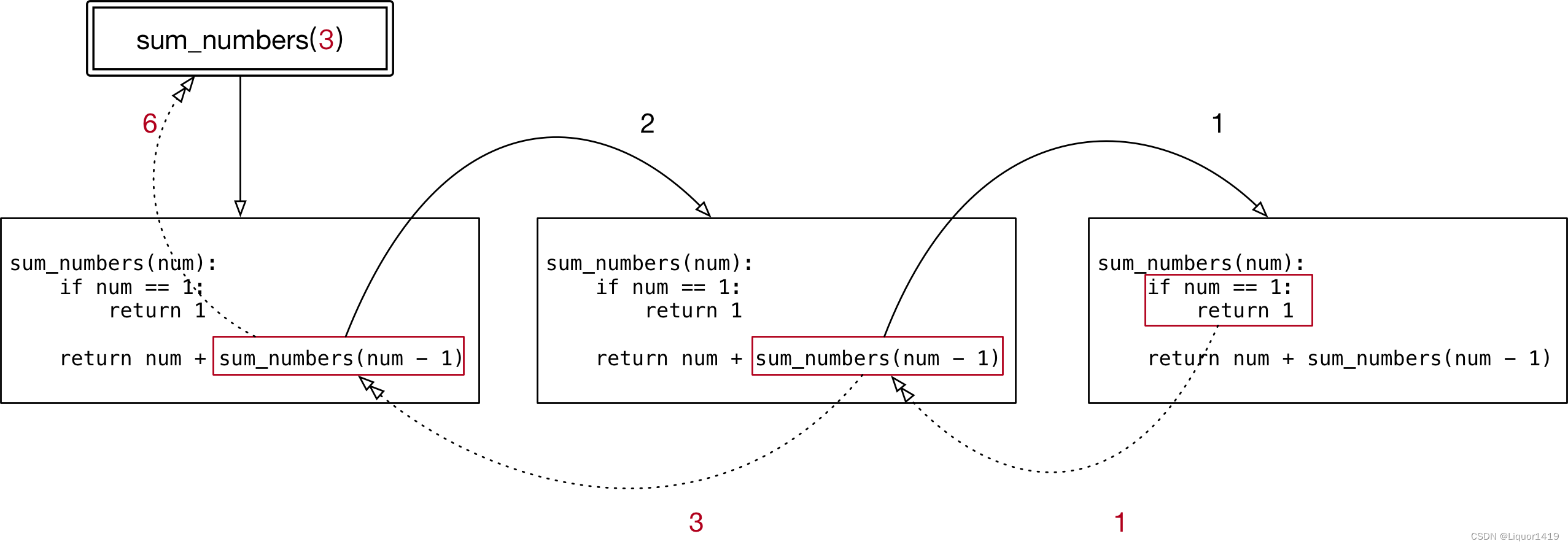
MED架构和CapFilt方法
BLIP的核心方法论,解决现有 视觉-语言预训练模型 在模型结构和数据噪声方面的局限性:
- 子问题1: 单一模型结构局限性
- 具体问题: 现有的视觉-语言预训练模型主要采用编码器模型或编码器-解码器模型。
- 现有模型要么擅长理解任务(如识别图片中的内容),要么擅长生成任务(如描述图片内容)。
- 需要一个模型架构,能够同时处理视觉理解和文本生成任务,以及有效学习视觉和语言之间的对齐。
- 子解法1: 引入多模态混合编码器-解码器(Multimodal mixture of Encoder-Decoder, MED)
- 解法原因: MED模型架构能够有效地进行多任务预训练和灵活的迁移学习。
- MED由于其设计,可以在不同模式间切换:作为编码器理解信息,作为解码器生成信息,或者两者结合起来。这种设计允许它适应多种不同的任务。
在图像描述生成任务中,MED以图像基础文本解码器的形式操作,通过学习图像内容来生成描述文本。
在图像-文本检索任务中,MED则以图像基础文本编码器的形式操作,匹配图像和文本之间的相似性。
MED提供了三种功能:单模态编码器、图像基础文本编码器、和图像基础文本解码器,使模型能够灵活地在不同的任务之间切换,并且通过共享某些层来提高训练效率和促进多任务学习。
这种结构的灵活性意味着同一个模型可以适应多种类型的任务,无需为每种任务定制单独的模型结构。
- 子问题2: 数据噪声问题
- 具体问题: 大多数先进方法获取大规模的图像-文本对,通常通过网络爬虫获取,尽管采用了简单的基于规则的过滤器,这些数据中仍然普遍存在噪声。
- 以往的工作往往忽略了数据噪声的负面影响,只是通过扩大数据集的规模来获得性能提升。
- 子解法2: 标题生成与过滤(Captioning and Filtering, CapFilt)
- 解法原因: 通过对预训练的MED进行微调,分别生成合成标题并过滤掉噪声标题,可以从噪声的图像-文本对中有效学习。这种方法通过提高数据质量,直接解决了数据噪声问题。
假设有一张网络图像,其关联的文本是“蓝天下的一座桥”。
然而,这个文本与图像的实际内容不符,因为图像可能显示的是一场足球比赛。
标题生成器(Captioner)可能会生成一个更准确的描述,如“足球场上的比赛”,然后过滤器(Filter)会识别并去除原始不准确的描述,保留合成的准确描述。
这样,BLIP就能通过改善训练数据的质量来提升模型的性能。
通过引入MED架构和CapFilt方法,BLIP不仅能够在多个视觉-语言任务上实现最先进的性能,还能在零样本场景下直接迁移到视频-语言任务,展现出极强的泛化能力。
3. 子问题3: 知识蒸馏在视觉语言预训练中的应用限制
- 具体问题: 现有的知识蒸馏(KD)方法主要是简单地迫使学生模型拥有与教师模型相同的类别预测,这在VLP的上下文中不够有效。
- 子解法3: 通过CapFilt实现的知识蒸馏
- 解法原因: CapFilt可以被视为一种更有效的知识蒸馏方法,在VLP上下文中,通过语义丰富的合成标题进行知识传递,并通过移除噪声标题来精化学习内容。
比如老师用自己的方式解释了一幅画的含义,而学生们都尝试记住老师的解释。
但如果每个学生只是简单地复述老师的话,那么他们可能无法真正理解画的深层含义。
在BLIP模型中,通过CapFilt进行知识蒸馏就像是让学生们创造自己的故事来描述这幅画,然后老师会指出哪些故事真正理解了画的意义(过滤器移除不准确的故事)。
这样不仅学生能更深刻地理解画作,还能在类似的未来任务中更好地表现。
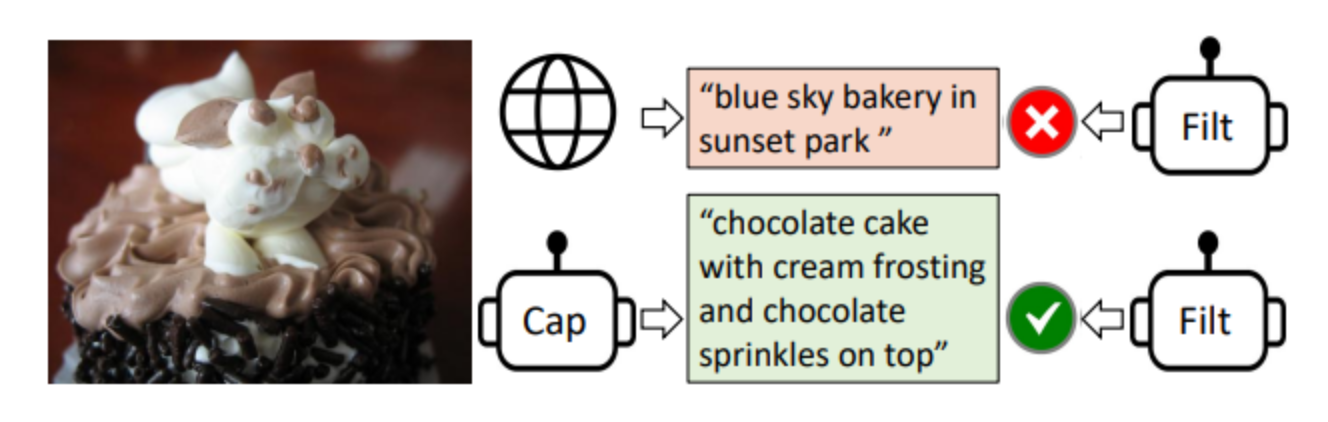
上图 是使用标题生成器(Captioner, 缩写为Cap)和过滤器(Filter, 缩写为Filt)进行数据集引导(Bootstrapping)的过程。
标题生成器用于为网络图像生成合成标题,而过滤器用于移除噪声或不相关的标题。
一个巧克力蛋糕的图像和两个标题:“blue sky bakery in sunset park”被标记为红色的叉,表示过滤器已将其识别为噪声或不相关的标题。
而“chocolate cake with cream frosting and chocolate sprinkles on top”被标记为绿色的勾,表示过滤器已认可该标题准确且相关。
- 子问题4: 视觉语言任务中的数据增强方法局限
- 具体问题: 尽管数据增强(DA)在计算机视觉中被广泛采用,但对于语言任务而言,DA不够直接明了。
- 近期虽有生成性语言模型被用于NLP任务的样本合成,但这些方法主要关注于资源有限的纯语言任务。
- 子解法4: 利用合成标题进行数据增强
- 解法原因: 通过生成合成标题为视觉-语言预训练提供数据增强,这种方法展示了在大规模视觉-语言预训练中合成标题的优势,有效扩充了训练样本的多样性和质量。
一位作家正在尝试为一系列的图片写下描述,为了训练自己的创造力,他不仅使用直接观察到的元素,还尝试添加一些虚构的细节来丰富故事。
BLIP模型中利用合成标题进行数据增强就像这位作家一样,它不仅使用现有的图片描述,还创造新的描述来扩展训练数据。
这样,BLIP模型就能学习到更丰富的语言表达和更多样化的场景理解。
当模型遇到一个新的图片时,它不仅能够识别图中明显的内容,还能够使用它在数据增强过程中学到的知识来创造出富有想象力和详细的描述。
这种方法大大超越了简单复制网络上现有描述的传统方法,使模型能够更好地理解和生成与图片内容相关的文本,增强了它处理视觉-语言任务的能力。
- 子问题5: 提高预训练效率与性能
- 具体问题5: 如何在预训练阶段同时优化多个目标,以提升模型在理解和生成任务上的性能。
- 子解法: 联合优化三个预训练目标
- 解法原因: 通过联合优化图像-文本对比损失(ITC)、图像-文本匹配损失(ITM)和语言模型损失(LM),模型能够在单个前向传播中学习到视觉和语言的细粒度对齐以及生成连贯的文本描述。
一个厨师正在准备一顿大餐,他必须同时处理烤箱里的烤肉、锅里的汤,以及准备甜点。
每道菜都需要不同的技巧和注意力,但他需要确保它们全部都能按时完美地呈现出来。
这就像BLIP在预训练阶段做的工作。
它不仅需要确保能理解图像(像是烤肉需要正确的温度),还要能匹配相关的文本(就像汤要加对调料),并且生成吸引人的图像描述(就像制作诱人的甜点)。
通过同时关注这三个目标,BLIP确保在完成任务时能够取得最佳的综合性能,就像厨师确保每道菜都能达到最高标准一样。
- 子问题6: 提高合成标题的多样性
- 具体问题: 如何生成多样化的合成标题来提供模型学习的新信息。
- 子解法6: 采用核采样(nucleus sampling)生成合成标题
- 解法原因: 核采样通过从概率累积超过阈值的候选集中采样每个令牌,生成更多样化和惊喜的标题,与确定性的束搜索(beam search)方法相比,提供了更多新信息,从而提高了模型性能。
一位艺术家正在为一本图画书创作插图,他可以用同样的风格画出所有的画面,这样虽然一致,但可能有些单调。
相反,如果他决定在每一页尝试不同的颜色和风格,那么图画书将会更加丰富多彩和吸引人。
BLIP模型使用核采样(nucleus sampling)来生成合成标题,就像这位艺术家在每页上尝试新风格一样,它创造出多样化的描述,使模型能从更广泛的样本中学习。
- 子问题7: 参数共享和解耦对模型性能的影响
- 具体问题: 在预训练阶段,文本编码器和解码器除了自注意力层外如何共享参数,以及在CapFilt过程中如何处理参数共享和解耦,以避免确认偏误。
- 子解法7: 预训练中共享除自注意力层外的所有参数,CapFilt中独立微调
- 解法原因: 除自注意力层外共享参数可以提高训练效率并减小模型大小,而在CapFilt过程中独立微调避免了由于参数共享导致的确认偏误,提高了过滤噪声标题的能力。
一个设计团队正在创建一款新的电子产品。
如果团队的每个成员都在各自独立的部分上工作,而没有共享他们的设计理念,那么最终的产品可能会出现不协调的问题。
但是,如果他们在设计的大部分阶段共享想法,只在最后的细节上进行独立工作,那么产品就更可能成为一个协调一致的整体。
同样,在BLIP模型的预训练中,大部分参数(如前馈网络和嵌入层)被共享,以维持模型的一致性和效率,而在CapFilt过程中,通过独立微调captioner和filter来确保噪声数据能够被有效识别并去除,从而避免了因共享相同参数而可能导致的模型在去噪时的盲点。
效果
- 子问题1: 在图像-文本检索任务中实现性能提升
- 具体问题: 如何在COCO和Flickr30K数据集上提升图像到文本和文本到图像的检索性能。
- 子解法1: 使用图像-文本对比(ITC)和图像-文本匹配(ITM)损失进行微调
- 解法原因: 通过使用这两种损失函数,BLIP能够更准确地学习图像和文本之间的特征相似性和配对关系,从而在检索任务上实现更高的准确率。
BLIP通过微调图像-文本对比(ITC)和图像-文本匹配(ITM)损失,显著提高了在COCO和Flickr30K数据集上的图像到文本和文本到图像的检索性能。
- 子问题2: 提升图像描述生成的性能
- 具体问题: 如何在NoCaps和COCO数据集上改善图像描述生成的准确性和质量。
- 子解法2: 采用语言建模(LM)损失并添加提示词进行微调
- 解法原因: 通过引入LM损失和提示词“a picture of”,BLIP能够生成更自然、更相关的图像描述,即使在与使用更多预训练数据的方法相比时也能保持竞争力。
BLIP在NoCaps和COCO数据集上的图像描述生成任务中,通过采用语言模型(LM)损失并添加提示词进行微调,成功改善了图像描述的准确性和质量。
BLIP的预训练模型架构和目标:
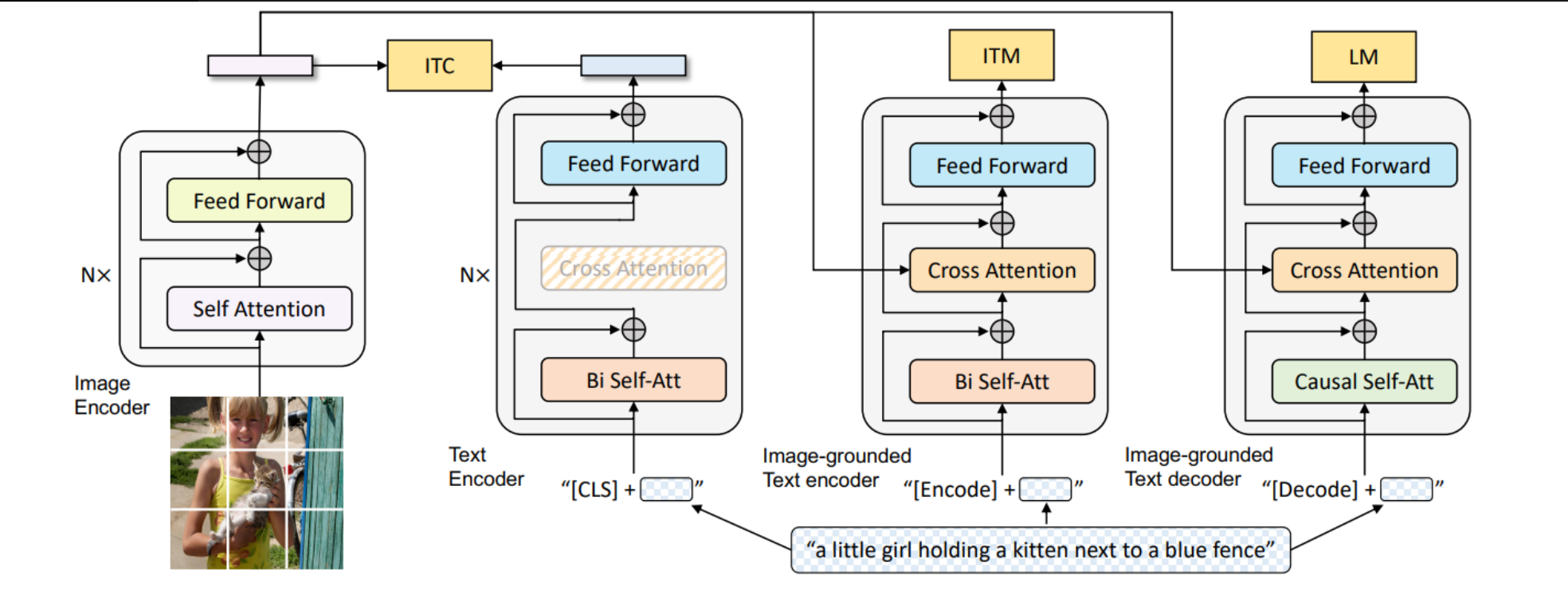
该模型是一个多模态的编解码器混合体,具有三种功能:
- 单模态编码器通过图像-文本对比(ITC)损失训练,以对齐视觉和语言表示。
- 图像基础的文本编码器使用额外的交叉注意力层来模拟视觉-语言交互,并通过图像-文本匹配(ITM)损失训练,以区分正负图像-文本对。
- 图像基础的文本解码器替换了双向自注意力层,采用因果自注意力层,并且与编码器共享相同的交叉注意力层和前馈网络。解码器通过语言建模(LM)损失训练,以生成图像的文字描述。
- 子问题3: 在视觉问答(VQA)任务上超越现有方法
- 具体问题: 如何优化模型以在VQA任务上生成开放式答案,并超越现有的VLP方法。
- 子解法3: 将VQA视为一个答案生成任务,并使用LM损失进行微调
- 解法原因: 这种开放式的答案生成方式使BLIP能够处理更多样化的问题和答案类型,通过LM损失优化使其在VQA任务上表现优于现有方法。
BLIP优化了模型,将VQA任务视为答案生成任务,并使用LM损失进行微调,从而在生成开放式答案方面超越了现有的VLP方法。
- 子问题4: 提高自然语言视觉推理(NLVR2)的准确率
- 具体问题: 如何在NLVR2任务上,即判断一个句子是否描述了一对图像,提高推理准确率。
- 子解法4: 对预训练模型进行简单修改以增强对双图像的处理能力
- 解法原因: 通过引入两个交叉注意力层来分别处理两幅图像,并通过合并这些层的输出,BLIP能够更有效地进行图像之间的推理,从而在NLVR2任务上实现更高的性能。
BLIP在自然语言视觉推理(NLVR^2)任务中,通过对双图像处理能力的增强(两个交叉注意力层),提高了推理准确率。
- 子问题5: 在视觉对话(VisDial)任务中实现领先性能
- 具体问题: 如何在视觉对话任务中整合图像、问题、对话历史和图像的描述来预测答案。
- 子解法5: 通过交叉注意力连接图像和标题嵌入,并使用图像-文本匹配(ITM)损失训练对话编码器
- 解法原因: 这种方法允许BLIP在对话设置中理解图像内容与历史对话之间的复杂关系,通过ITM损失优化能够更准确地评估答案的相关性,从而在VisDial任务上达到更高的性能。
在视觉对话(VisDial)任务中,BLIP通过整合图像、标题、对话历史,并使用ITM损失来训练对话编码器,实现了领先的性能。
BLIP模型在三种下游任务中的架构:视觉问答(VQA),自然语言视觉推理(NLVR^2),以及视觉对话(VisDial):
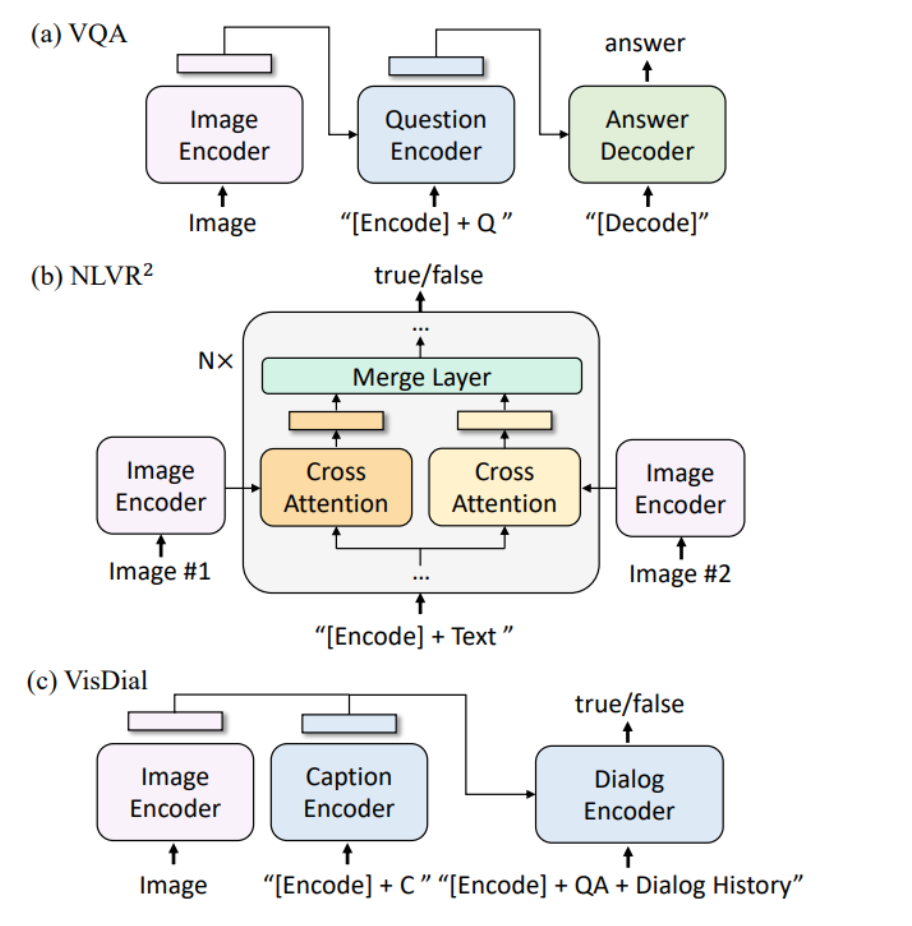
每一部分的架构都被设计用于处理特定任务的需求:
- (a) VQA部分:图像被一个编码器处理,问题被另一个编码器处理,然后将这些信息传递给答案解码器以生成答案。
- (b) NLVR^2部分:处理两个图像的编码器通过交叉注意力层将两个图像合并,然后通过一个融合层,以判断文本是否描述了这对图像。
- © VisDial部分:图像和其标题由各自的编码器处理,然后这些信息以及之前的问答对和对话历史一起传递给对话编码器,以预测当前的答案。
- 子问题6: 零样本转移到视频-语言任务上的性能提升
- 具体问题: 如何在没有针对视频数据进行特定训练的情况下,将图像-语言模型应用于视频-文本检索和视频问答任务,并实现优秀的性能。
- 子解法6: 直接评估在COCO上微调的模型,并对视频输入进行简单处理,如均匀采样帧
- 解法原因: 尽管这种方法忽略了时间信息,但BLIP模型在视频-语言任务上展现出了强大的泛化能力,即使用简单的帧级特征融合也能在零样本设置下实现行业领先的性能。
BLIP在视频-语言任务上实现了出色的零样本性能,证明了即使在没有特定视频数据训练的情况下,通过对视频输入进行简单处理,如均匀采样帧,BLIP也能够有效地处理文本到视频的检索和视频问答任务。
总结
CLIP模型 VS BLIP模型
CLIP(Contrastive Language-Image Pre-training)模型和BLIP(Bootstrapping Language-Image Pre-training)模型虽然都是视觉-语言预训练模型,但它们在设计和功能上有一些关键的不同。
CLIP模型
https://blog.csdn.net/qq_41739364/article/details/135063268
-
训练方式:
- 对比学习:CLIP通过对比正负样本对的方式学习图像和文本之间的关联。
-
数据依赖:
- 自监督学习:CLIP使用了大量的互联网数据,依靠图像和相关联的文本信息进行自监督学习。
-
图像编码器:
- 混合结构:CLIP可以使用不同的图像编码器,如ResNet或Vision Transformer。
-
文本编码器:
- Transformer模型:CLIP使用了Transformer结构来编码文本信息。
-
Zero-shot学习:
- 动态文本特征:CLIP可以直接对类别进行分类,而无需进行模型的微调,通过动态构建文本特征向量进行zero-shot学习。
BLIP模型
-
训练方式:
- 数据集引导(Bootstrapping):BLIP使用一个标题生成器产生合成标题,然后用过滤器去除噪声,优化数据质量。
-
数据依赖:
- 引导的数据集:BLIP在人工注释的数据集上进行微调,提高了模型的准确性和鲁棒性。
-
图像编码器:
- ViT:BLIP通常使用Vision Transformer作为图像编码器。
-
文本编码器与解码器:
- 多模态混合编解码器(MED):BLIP设计了一种新的多功能模型架构,可以同时作为编码器和解码器。
-
应用领域:
- 多任务适用性:BLIP不仅在图像-文本检索和图像描述生成等任务中表现出色,还能处理更广泛的视觉-语言任务,如VQA和VisDial。
CLIP在设计上更侧重于通过大规模的数据和对比学习来学习强大的通用图像和文本表示.
BLIP则采用了更精细的数据处理方法来进一步提升模型的性能,特别是在多任务适用性方面进行了优化。
两者都展示了在各自领域内的先进性能,但BLIP在数据处理和任务适应性上更为灵活。