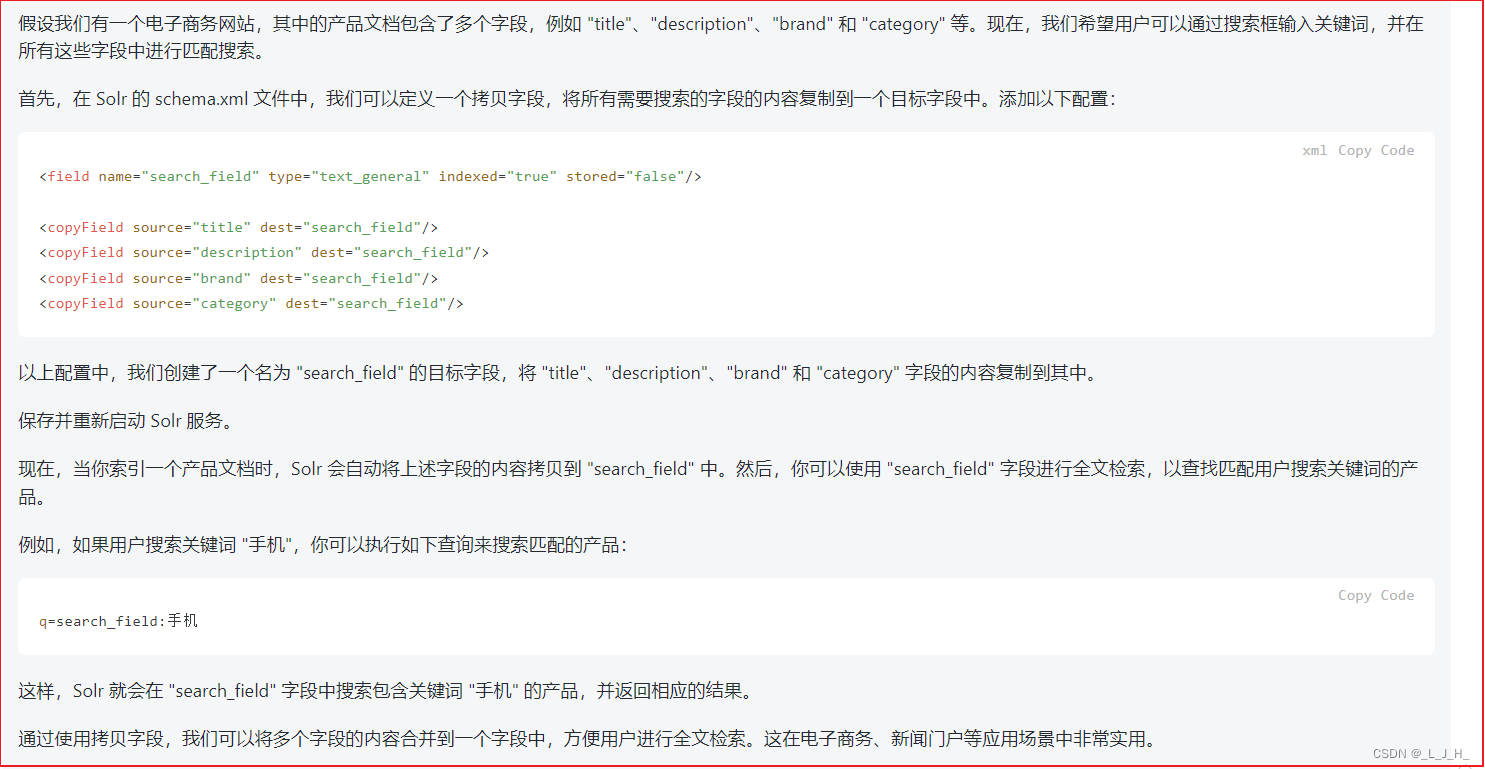
文章目录
- 原理概念
- 等宽分箱
- 等频分箱
- 聚类分箱
- 有监督分箱
原理概念
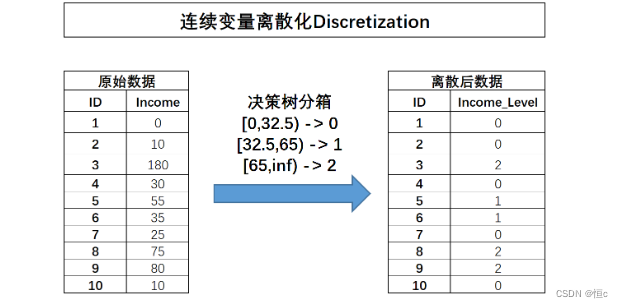
连续变量分箱即对连续型字段进行离散化处理,也就是将连续型字段转化为离散型字段。连续字段的离散过程如下所示:
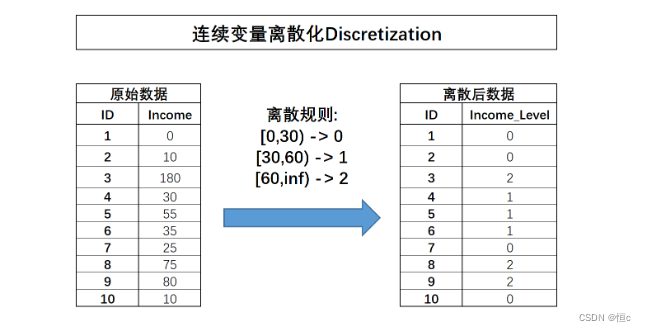
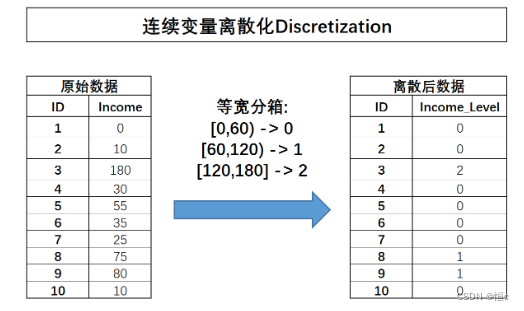
连续变量的离散过程也可以理解为连续变量取值的重新编码过程,在很多时候,连续变量的离散化也被称为连续变量分箱。需要注意的是,离散之后字段的含义将发生变化,原始字段Income代表用户真实收入状况,而离散之后的含义就变成了用户收入的等级划分,0表示低收入人群、1表示中等收入人群、2代表高收入人群。连续字段的离散化能够更加简洁清晰的呈现特征信息,并且能够极大程度减少异常值的影响(例如Income取值为180的用户),同时也能够消除特征量纲影响,当然,最重要的一点是,对于很多线性模型来说,连续变量的分箱实际上相当于在线性方程中引入了非线性的因素,从而提升模型表现。当然,连续变量的分箱过程会让连续变量损失一些信息,而对于其他很多模型来说(例如树模型),分箱损失的信息则大概率会影响最终模型效果。
等宽分箱
所谓等宽分箱,需要先确定划分成几分,然后根据连续变量的取值范围划分对应数量的宽度相同的区间,并据此对连续变量进行分箱。例如上述Income字段取值在[0,180]之间,现对其进行等宽分箱分成三份,则每一份的取值范围分别是[0,60),[60,120),[120,180],连续字段将据此进行划分,分箱过程如下所示:
当然,我们也可以在sklearn的预处理模块中调用KBinsDiscretizer转化器实现该过程:
from sklearn import preprocessing
# 转化为列向量(这里需要注意,一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别)
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
# 三分等宽分箱,strategy选择'uniform'
dis = preprocessing.KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
dis.fit_transform(income)
# 运行结果
# array([[0.],
# [0.],
# [2.],
# [0.],
# [0.],
# [0.],
# [0.],
# [1.],
# [1.],
# [0.]])
# 当然,在分箱结束后,可以通过.bin_edges_查看分箱依据(每个箱体的边界)
dis.bin_edges_
# array([array([ 0., 60., 120., 180.])], dtype=object)
等频分箱
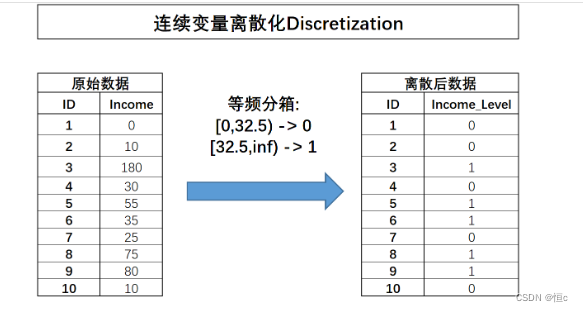
在等频分箱的过程中,需要先确定划分成几分,然后选择能够让每一份包含样本数量相同的划分方式。
from sklearn import preprocessing
# 转化为列向量(这里需要注意,一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别)
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
# 两分等频分箱,strategy选择'quantile'
dis = preprocessing.KBinsDiscretizer(n_bins=2, encode='ordinal', strategy='quantile')
dis.fit_transform(income)
# array([[0.],
# [0.],
# [1.],
# [0.],
# [1.],
# [1.],
# [0.],
# [1.],
# [1.],
# [0.]])
dis.bin_edges_
# array([array([ 0. , 32.5, 180. ])], dtype=object)
聚类分箱
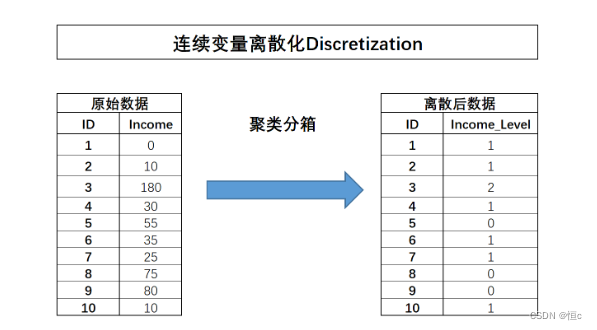
所谓聚类分箱,指的是先对某连续变量进行聚类(往往是KMeans聚类),然后用样本所属类别作为标记代替原始数值,从而完成分箱的过程。这里我们仍然可以通过income数据来模拟该过程,此处我们使用KMeans对其进行三类别聚类:
from sklearn import preprocessing
# 转化为列向量(这里需要注意,一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别)
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
# 两分等频分箱,strategy选择'kmeans'
dis = preprocessing.KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans')
dis.fit_transform(income)
# array([[0.],
# [0.],
# [2.],
# [0.],
# [1.],
# [0.],
# [0.],
# [1.],
# [1.],
# [0.]])
dis.bin_edges_
# array([array([ 0. , 44.16666667, 125. , 180. ])], dtype=object)
有监督分箱
当然,无论是等宽/等频分箱,还是聚类分箱,本质上都是进行无监督的分箱,即在不考虑标签的情况下进行的分箱。而在所有的分箱过程中,还有一类是有监督分箱,即根据标签取值对连续变量进行分箱。在这些方法中,最常用的分箱就是树模型分箱。
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
# 转化为列向量(这里需要注意,一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别)
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
# 可以以income为特征,y为标签训练决策树:
y = np.array([1, 1, 0, 1, 0, 0, 0, 1, 0, 0])
clf = DecisionTreeClassifier().fit(income, y)
plt.figure(figsize=(6, 2), dpi=150)
tree.plot_tree(clf)
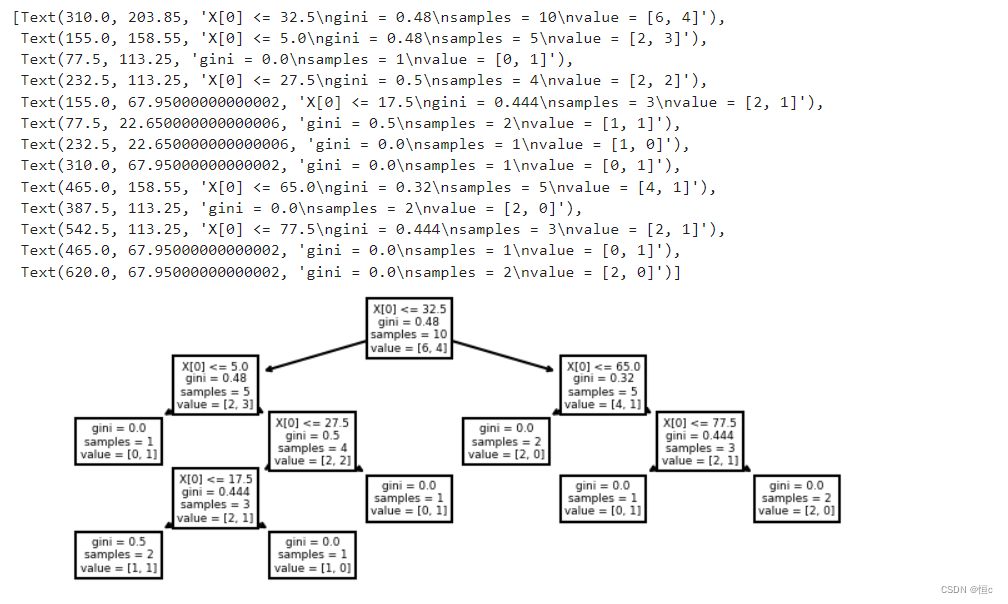
那么根据上述结果,如果需要对income进行三类分箱的话,则可以选择32.5和65作为切分点,对数据集进行切分: