文章目录
- Einstein学画画(C++,欧拉路)
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
- 样例输入 #1
- 样例输出 #1
- 提示
- 解题思路:
- 并查集(C++)
- [蓝桥杯 2017 国 C] 合根植物(C++,并查集)
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
- 样例输入 #1
- 样例输出 #1
- 提示
- 样例解释
- 解题思路:
- 灾后重建(C++,Floyd)
- 题目背景
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
- 样例输入 #1
- 样例输出 #1
- 提示
- 解题思路:
- [NOIP2017 提高组] 奶酪(C++,并查集)
- 题目背景
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
- 样例输入 #1
- 样例输出 #1
- 提示
- 解题思路:
- [HAOI2006]聪明的猴子(C++,最小生成树)
- 题目描述
- 输入格式
- 输出格式
- 样例 #1
- 样例输入 #1
- 样例输出 #1
- 提示
- 解题思路:
Einstein学画画(C++,欧拉路)
题目描述
Einstein 学起了画画。
此人比较懒~~,他希望用最少的笔画画出一张画……
给定一个无向图,包含 n n n 个顶点(编号 1 ∼ n 1 \sim n 1∼n), m m m 条边,求最少用多少笔可以画出图中所有的边。
输入格式
第一行两个整数 n , m n, m n,m。
接下来 m m m 行,每行两个数 a , b a, b a,b( a ≠ b a \ne b a=b),表示 a , b a, b a,b 两点之间有一条边相连。
一条边不会被描述多次。
输出格式
一个数,即问题的答案。
样例 #1
样例输入 #1
5 5
2 3
2 4
2 5
3 4
4 5
样例输出 #1
1
提示
对于 50 % 50 \% 50% 的数据, n ≤ 50 n \le 50 n≤50, m ≤ 100 m \le 100 m≤100。
对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 1000 1 \le n \le 1000 1≤n≤1000, 1 ≤ m ≤ 10 5 1 \le m \le {10}^5 1≤m≤105。
解题思路:
本文虽然不是转载博文…但是也差不多了,原文出处:洛谷博主TheAutumnGlory
题解传送门:题解 P1636 【Einstein学画画】 - ζั͡އއއ๓秋 的博客 - 洛谷博客 (luogu.com.cn)
了解题目大意后感觉这题有一笔画的意味,这就要提到欧拉路了
先说明一个定义:顶点的度:指和该点相关联的边数
我们称顶点的度为奇数的点为奇点
然后说明欧拉路:
1)存在欧拉路的条件:图是联通的,且存在两个奇点
2)如果存在两个奇点,欧拉路一定是从一个奇点出发,在另一个奇点结束
注意:无向图只会存在偶数个奇点
所以解题思路就很简单了,累计每一个点的顶点的度,然后统计奇点的个数ans
最后输出ans/2即可
当然,ans == 0的时候应该输出1,此时的图会变为欧拉图
AC代码如下
#include <iostream>
using namespace std;
const int max_n = 1000;
const int max_m = 1e5;
int ans = 0;//度数为奇数的点的个数
int nodes[max_n + 1] = { 0 };
int main() {
int n, m, u, v;
cin >> n >> m;
for (int i = 0; i < m; i++) {//存图
cin >> u >> v;
nodes[u]++, nodes[v]++;//累计点的度数
}
for (int i = 1; i <= n; i++) {
if (nodes[i] % 2 != 0) {//度数为奇数
ans++;
}
}
//答案
if (ans == 0) cout.put('1');
else cout << ans / 2 << endl;
return 0;
}
并查集(C++)
根据下面这道题讲下并查集
(其实本来是写题解的…写着写着就变成算法说明了)
[蓝桥杯 2017 国 C] 合根植物(C++,并查集)
题目描述
w 星球的一个种植园,被分成 m × n m \times n m×n 个小格子(东西方向 m m m 行,南北方向 n n n 列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。
如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?
输入格式
第一行,两个整数 m m m, n n n,用空格分开,表示格子的行数、列数( 1 < m , n < 1000 1<m,n<1000 1<m,n<1000)。
接下来一行,一个整数 k k k,表示下面还有 k k k 行数据 ( 0 < k < 1 0 5 ) (0<k<10^5) (0<k<105)。
接下来 k k k 行,第行两个整数 a a a, b b b,表示编号为 a a a 的小格子和编号为 b b b 的小格子合根了。
格子的编号一行一行,从上到下,从左到右编号。
比如: 5 × 4 5 \times 4 5×4 的小格子,编号:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
输出格式
一行一个整数,表示答案
样例 #1
样例输入 #1
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
样例输出 #1
5
提示
样例解释
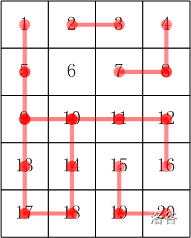
时限 1 秒, 256M。蓝桥杯 2017 年第八届国赛
解题思路:
emmm我也不知道该怎么引入,直接进行说明吧
并查集实现的就是合并两个元素(也可以是集合)成为一个集合
首先我们要知道如何辨别一个集合
我们知道一棵树所有子节点的根节点是相同的,换言之,根节点可以代表一棵树,抽象一点,就可以代表一个集合
那么如何寻访根节点呢?
int find(x) {//寻访节点x的根节点
if (father[x] == x)//x是根节点
return x;
else//x不是根节点
return find(father[x]);//寻访x的父节点
}
这个递归,应该…很好理解吧
但是如果一棵树的深度过深的话会导致寻访很慢,于是我们进行路径压缩
int find(x) {//寻访节点x的根节点
if (father[x] == x)//x是根节点
return x;
else {//x不是根节点
father[x] = find(father[x]);//路径压缩
return father[x];//寻访x的父节点
}
}
就是把所有子节点都连到根节点上
可以将以上代码优化
int find(x) {
return x == father[x] ? x : (father[x] = find(father[x]));
}
学会了辨别一个集合,接下来学习如何合并两个元素(或集合)
void merge(int x, int y) {
father[x] = father[y];
}
当然前提是判断两个元素不在一个集合中
bool is_same(int x, int y) {
if (find(x) == find(y)) return true;//一个集合
else return false;//两个集合
}
至此本题讲解完…好像没完,用递归寻访根节点会被卡掉
接下来介绍优化寻访的另一种方法,按秩合并
寻访慢的原因就是树的深度过深,我们希望深度尽可能的浅,这就是按秩合并的基本思想
void merge(int x, int y) {
if (depths[x] <= depths[y]) {//如果x是更简单的树
father[y] = father[x];//连接简单树到复杂树上
}
else father[x] = father[y];
if (depths[x] == depths[y])
depths[y]++;//如果深度相同,y的深度++,可以自行思考一下为什么(很简单的)
}
使用按秩合并记得要把所有元素的深度初始化为1
最后简单说明一下题意就可以明白了
其实二维的平面是假想的,直接维护一个m*n大小的数组就可以了
寻访根节点可以修改为while循环,大多数返回后没有指令的递归都可以优化为while不定循环
最后,AC代码如下
//并查集
#include <iostream>
using namespace std;
const int max_m = 1000;
const int max_n = 1000;
int ans;
int map[max_m * max_n] = { 0 };
int depths[max_m * max_n] = { 1 };
//寻访根节点
int find(int x) {
while (map[x] != x) x = map[x];
return x;
}
//按秩合并
void merge(int x, int y) {
if (depths[x] >= depths[y]) map[y] = map[x];
else map[x] = map[y];
if (depths[x] == depths[y]) depths[y]++;
}
int main() {
int m, n, k, u, v;
cin >> m >> n >> k;
int mul = m * n;
for (int i = 1; i <= mul; i++) {//初始化
map[i] = i;
depths[i] = 1;
}
ans = m * n;
for (int i = 0; i < k; i++) {//合并集合
cin >> u >> v;
int temp_1 = find(u);
int temp_2 = find(v);
if (temp_1 != temp_2) ans--;//集合数目-1
merge(temp_1, temp_2);
}
cout << ans;
return 0;
}
灾后重建(C++,Floyd)
题目背景
B 地区在地震过后,所有村庄都造成了一定的损毁,而这场地震却没对公路造成什么影响。但是在村庄重建好之前,所有与未重建完成的村庄的公路均无法通车。换句话说,只有连接着两个重建完成的村庄的公路才能通车,只能到达重建完成的村庄。
题目描述
给出 B 地区的村庄数
N
N
N,村庄编号从
0
0
0 到
N
−
1
N-1
N−1,和所有
M
M
M 条公路的长度,公路是双向的。并给出第
i
i
i 个村庄重建完成的时间
t
i
t_i
ti,你可以认为是同时开始重建并在第
t
i
t_i
ti 天重建完成,并且在当天即可通车。若
t
i
t_i
ti 为
0
0
0 则说明地震未对此地区造成损坏,一开始就可以通车。之后有
Q
Q
Q 个询问
(
x
,
y
,
t
)
(x,y,t)
(x,y,t),对于每个询问你要回答在第
t
t
t 天,从村庄
x
x
x 到村庄
y
y
y 的最短路径长度为多少。如果无法找到从
x
x
x 村庄到
y
y
y 村庄的路径,经过若干个已重建完成的村庄,或者村庄
x
x
x 或村庄
y
y
y 在第
t
t
t 天仍未重建完成,则需要返回 -1。
输入格式
第一行包含两个正整数 N , M N,M N,M,表示了村庄的数目与公路的数量。
第二行包含 N N N个非负整数 t 0 , t 1 , … , t N − 1 t_0, t_1,…, t_{N-1} t0,t1,…,tN−1,表示了每个村庄重建完成的时间,数据保证了 t 0 ≤ t 1 ≤ … ≤ t N − 1 t_0 ≤ t_1 ≤ … ≤ t_{N-1} t0≤t1≤…≤tN−1。
接下来 M M M行,每行 3 3 3个非负整数 i , j , w i, j, w i,j,w, w w w为不超过 10000 10000 10000的正整数,表示了有一条连接村庄 i i i与村庄 j j j的道路,长度为 w w w,保证 i ≠ j i≠j i=j,且对于任意一对村庄只会存在一条道路。
接下来一行也就是 M + 3 M+3 M+3行包含一个正整数 Q Q Q,表示 Q Q Q个询问。
接下来 Q Q Q行,每行 3 3 3个非负整数 x , y , t x, y, t x,y,t,询问在第 t t t天,从村庄 x x x到村庄 y y y的最短路径长度为多少,数据保证了 t t t是不下降的。
输出格式
共 Q Q Q行,对每一个询问 ( x , y , t ) (x, y, t) (x,y,t)输出对应的答案,即在第 t t t天,从村庄 x x x到村庄 y y y的最短路径长度为多少。如果在第t天无法找到从 x x x村庄到 y y y村庄的路径,经过若干个已重建完成的村庄,或者村庄x或村庄 y y y在第 t t t天仍未修复完成,则输出 − 1 -1 −1。
样例 #1
样例输入 #1
4 5
1 2 3 4
0 2 1
2 3 1
3 1 2
2 1 4
0 3 5
4
2 0 2
0 1 2
0 1 3
0 1 4
样例输出 #1
-1
-1
5
4
提示
对于 30 % 30\% 30%的数据,有 N ≤ 50 N≤50 N≤50;
对于 30 % 30\% 30%的数据,有 t i = 0 t_i= 0 ti=0,其中有 20 % 20\% 20%的数据有 t i = 0 t_i = 0 ti=0且 N > 50 N>50 N>50;
对于 50 % 50\% 50%的数据,有 Q ≤ 100 Q≤100 Q≤100;
对于 100 % 100\% 100%的数据,有 N ≤ 200 N≤200 N≤200, M ≤ N × ( N − 1 ) / 2 M≤N \times (N-1)/2 M≤N×(N−1)/2, Q ≤ 50000 Q≤50000 Q≤50000,所有输入数据涉及整数均不超过 100000 100000 100000。
解题思路:
根据题目的一个奇怪的条件:对于 Q Q Q次询问,数据保证了 t t t是不下降的。
以及 Q Q Q的最大值是 50000 50000 50000
可以知道不采用动态规划很可能就被卡掉了
再看到随机的起点、要求最短路径,已经可以确定采用floyd算法了
只不过需要增加一个时间判断
思路大体不变,先初始化任意两个节点的距离为无穷大、到达自己的距离为0
然后单独开一个数组用于保存输入的时间
再进行存图(题中已经说明无重边)
最后说明本题的关键解题思路
先看一下原始的floyd算法
for (int i = 0; i < n; i++)//尝试把节点i加入路径
for (int j = 0; j < n; j++)//更新最短路径
for (int k = 0; k < n; k++)
dist[j][k] = min(dist[j][k], dist[j][i] + dist[i][k]);
我们只需要保证尝试加入的节点i是修复完毕的即可
while (j < n) {
if (times[j] > t) {//保证节点合法
j--; break;
}
for (int k = 0; k < n - 1; k++)//尝试更新最短距离
for (int l = k; l < n; l++)
map[l][k] = map[k][l] = min(map[k][l], map[k][j] + map[j][l]);
j++;
}
注意,即使节点n-1未修复完毕也要尝试更新最短路径,可以自行思考一下为什么
AC代码如下
//Floyd
#include <iostream>
#include <memory.h>
using namespace std;
const int max_n = 200;
const int NaN = 0x3F3F3F3F;
int map[max_n][max_n] = { 0 };//存图
int times[max_n] = { 0 };
int main() {
memset(map, 0x3F, sizeof(int) * max_n * max_n);
for (int i = 0; i < max_n; i++) map[i][i] = 0;//初始化
int n, m, u, v, w, q, t;
cin >> n >> m;
for (int i = 0; i < n; i++) cin >> times[i];
for (int i = 0; i < m; i++) {//存图
cin >> u >> v >> w;
map[u][v] = map[v][u] = w;//不含重边
}
cin >> q;
int j = 0;//尝试加入序号为j的节点
for (int i = 0; i < q; i++) {//询问
cin >> u >> v >> t;
while (j < n) {
if (times[j] > t) {//保证节点合法
j--; break;
}
for (int k = 0; k < n - 1; k++)//尝试更新最短距离
for (int l = k; l < n; l++)
map[l][k] = map[k][l] = min(map[k][l], map[k][j] + map[j][l]);
j++;
}
if (j < u || j < v || map[u][v] == NaN) cout << -1 << endl;
else cout << map[u][v] << endl;
j++;
}
return 0;
}
这里注意一下要在输出answer之后将j++,否则会导致重复加入同一个节点,造成TLE
[NOIP2017 提高组] 奶酪(C++,并查集)
题目背景
NOIP2017 提高组 D2T1
题目描述
现有一块大奶酪,它的高度为 h h h,它的长度和宽度我们可以认为是无限大的,奶酪中间有许多半径相同的球形空洞。我们可以在这块奶酪中建立空间坐标系,在坐标系中,奶酪的下表面为 z = 0 z = 0 z=0,奶酪的上表面为 z = h z = h z=h。
现在,奶酪的下表面有一只小老鼠 Jerry,它知道奶酪中所有空洞的球心所在的坐标。如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,特别地,如果一个空洞与下表面相切或是相交,Jerry 则可以从奶酪下表面跑进空洞;如果一个空洞与上表面相切或是相交,Jerry 则可以从空洞跑到奶酪上表面。
位于奶酪下表面的 Jerry 想知道,在不破坏奶酪的情况下,能否利用已有的空洞跑 到奶酪的上表面去?
空间内两点 P 1 ( x 1 , y 1 , z 1 ) P_1(x_1,y_1,z_1) P1(x1,y1,z1)、 P 2 ( x 2 , y 2 , z 2 ) P2(x_2,y_2,z_2) P2(x2,y2,z2) 的距离公式如下:
d i s t ( P 1 , P 2 ) = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 + ( z 1 − z 2 ) 2 \mathrm{dist}(P_1,P_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2} dist(P1,P2)=(x1−x2)2+(y1−y2)2+(z1−z2)2
输入格式
每个输入文件包含多组数据。
第一行,包含一个正整数 T T T,代表该输入文件中所含的数据组数。
接下来是 T T T 组数据,每组数据的格式如下: 第一行包含三个正整数 n , h , r n,h,r n,h,r,两个数之间以一个空格分开,分别代表奶酪中空洞的数量,奶酪的高度和空洞的半径。
接下来的 n n n 行,每行包含三个整数 x , y , z x,y,z x,y,z,两个数之间以一个空格分开,表示空洞球心坐标为 ( x , y , z ) (x,y,z) (x,y,z)。
输出格式
T
T
T 行,分别对应
T
T
T 组数据的答案,如果在第
i
i
i 组数据中,Jerry 能从下表面跑到上表面,则输出 Yes,如果不能,则输出 No。
样例 #1
样例输入 #1
3
2 4 1
0 0 1
0 0 3
2 5 1
0 0 1
0 0 4
2 5 2
0 0 2
2 0 4
样例输出 #1
Yes
No
Yes
提示
【输入输出样例 1 1 1 说明】
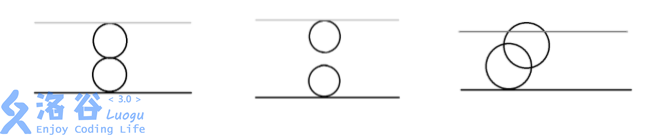
第一组数据,由奶酪的剖面图可见:
第一个空洞在 ( 0 , 0 , 0 ) (0,0,0) (0,0,0) 与下表面相切;
第二个空洞在 ( 0 , 0 , 4 ) (0,0,4) (0,0,4) 与上表面相切;
两个空洞在 ( 0 , 0 , 2 ) (0,0,2) (0,0,2) 相切。
输出 Yes。
第二组数据,由奶酪的剖面图可见:
两个空洞既不相交也不相切。
输出 No。
第三组数据,由奶酪的剖面图可见:
两个空洞相交,且与上下表面相切或相交。
输出 Yes。
【数据规模与约定】
对于 20 % 20\% 20% 的数据, n = 1 n = 1 n=1, 1 ≤ h 1 \le h 1≤h, r ≤ 1 0 4 r \le 10^4 r≤104,坐标的绝对值不超过 1 0 4 10^4 104。
对于 40 % 40\% 40% 的数据, 1 ≤ n ≤ 8 1 \le n \le 8 1≤n≤8, 1 ≤ h 1 \le h 1≤h, r ≤ 1 0 4 r \le 10^4 r≤104,坐标的绝对值不超过 1 0 4 10^4 104。
对于 80 % 80\% 80% 的数据, 1 ≤ n ≤ 1 0 3 1 \le n \le 10^3 1≤n≤103, 1 ≤ h , r ≤ 1 0 4 1 \le h , r \le 10^4 1≤h,r≤104,坐标的绝对值不超过 1 0 4 10^4 104。
对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 1 × 1 0 3 1 \le n \le 1\times 10^3 1≤n≤1×103, 1 ≤ h , r ≤ 1 0 9 1 \le h , r \le 10^9 1≤h,r≤109, T ≤ 20 T \le 20 T≤20,坐标的绝对值不超过 1 0 9 10^9 109。
解题思路:
这里就不介绍并查集了,放一篇我写的并查集传送门qwq,传送门
为什么本题用并查集解决呢?
我们可以对题意进行抽象,把所有与底层连通的空洞作为起点集合,把所有与顶层连通的空洞作为终点集合
那么我们遍历尝试将所有可能的两个点合并为一个集合
最后检查起点集合和终点集合会不会合并即可
引用一句从别的地方学来的话:“凡是涉及到元素的分组管理,都可以考虑用并查集来维护。”
AC代码如下
//并查集
#include <iostream>
#include <cmath>
using namespace std;
const int max_n = 1e3;
int fa[max_n + 3] = { 0 };//根节点
int dep[max_n + 3] = { 0 };//深度
struct node { int x, y, z; }nodes[max_n + 3];//存图
//初始化
void init(int n) {
for (int i = 1; i <= n; i++) {
fa[i] = i;
dep[i] = 1;
}
}
//寻访根节点
int find(int x) {
return fa[x] == x ? x : (fa[x] = find(fa[x]));
}
//按秩合并
void merge(int x, int y) {
int t1 = find(x);
int t2 = find(y);
if (dep[t1] >= dep[t2]) fa[t2] = fa[t1];
else fa[t1] = fa[t2];
if (dep[t1] == dep[t2]) dep[t1]++;
}
//是否相通
bool is_connect(int x, int y, const long long& r) {
long long distance = (long long)(nodes[x].x - nodes[y].x) * (long long)(nodes[x].x - nodes[y].x) +
(long long)(nodes[x].y - nodes[y].y) * (long long)(nodes[x].y - nodes[y].y) +
(long long)(nodes[x].z - nodes[y].z) * (long long)(nodes[x].z - nodes[y].z);
if (4l * r * r >= distance) return true;
else return false;
}
//是否同集合
bool is_same_tree(int x, int y) {
if (find(x) == find(y)) return true;
else return false;
}
int main() {
int T, n, h, r, x, y, z;
bool special;
cin >> T;
for (int i = 0; i < T; i++) {
cin >> n >> h >> r;
//初始化
special = false;
fa[0] = 0; dep[0] = 1;
nodes[0] = { 0,0,0 };//底层
fa[n + 1] = n + 1; dep[n + 1] = 1;
nodes[n + 1] = { 0,0,h };//顶层
init(n);
for (int j = 1; j <= n; j++) {//存图
cin >> x >> y >> z;
nodes[j] = { x,y,z };
if (z + r >= h) fa[j] = fa[n + 1];
if (z - r <= 0) fa[j] = fa[0];
if (z + r >= h && z - r <= 0) {//特判
special = true;
}
}
if (special) {
cout << "Yes" << endl;
continue;
}
//合并
for (int j = 1; j <= n - 1; j++) {
for (int z = j + 1; z <= n; z++) {
if (!is_same_tree(j, z) && is_connect(j, z, r)) merge(j, z);
}
}
if (find(0) == find(n + 1)) cout << "Yes" << endl;
else cout << "No" << endl;
}
return 0;
}
这里加上特判,原因是如果所有的空洞都是上下贯通,那么所有的空洞都会归于起点集合,导致结果错误
[HAOI2006]聪明的猴子(C++,最小生成树)
题目描述
在一个热带雨林中生存着一群猴子,它们以树上的果子为生。昨天下了一场大雨,现在雨过天晴,但整个雨林的地表还是被大水淹没着,部分植物的树冠露在水面上。猴子不会游泳,但跳跃能力比较强,它们仍然可以在露出水面的不同树冠上来回穿梭,以找到喜欢吃的果实。
现在,在这个地区露出水面的有N棵树,假设每棵树本身的直径都很小,可以忽略不计。我们在这块区域上建立直角坐标系,则每一棵树的位置由其所对应的坐标表示(任意两棵树的坐标都不相同)。
在这个地区住着的猴子有M个,下雨时,它们都躲到了茂密高大的树冠中,没有被大水冲走。由于各个猴子的年龄不同、身体素质不同,它们跳跃的能力不同。有的猴子跳跃的距离比较远(当然也可以跳到较近的树上),而有些猴子跳跃的距离就比较近。这些猴子非常聪明,它们通过目测就可以准确地判断出自己能否跳到对面的树上。
【问题】现已知猴子的数量及每一个猴子的最大跳跃距离,还知道露出水面的每一棵树的坐标,你的任务是统计有多少个猴子可以在这个地区露出水面的所有树冠上觅食。
输入格式
输入文件monkey.in包括:
第1行为一个整数,表示猴子的个数M(2<=M<=500);
第2行为M个整数,依次表示猴子的最大跳跃距离(每个整数值在1–1000之间);
第3行为一个整数表示树的总棵数N(2<=N<=1000);
第4行至第N+3行为N棵树的坐标(横纵坐标均为整数,范围为:-1000–1000)。
(同一行的整数间用空格分开)
输出格式
输出文件monkey.out包括一个整数,表示可以在这个地区的所有树冠上觅食的猴子数。
样例 #1
样例输入 #1
4
1 2 3 4
6
0 0
1 0
1 2
-1 -1
-2 0
2 2
样例输出 #1
3
提示
【数据规模】
对于40%的数据,保证有2<=N <=100,1<=M<=100
对于全部的数据,保证有2<=N <= 1000,1<=M=500
感谢@charlie003 修正数据
解题思路:
根据题目描述,要求其实就是使两节点之间的最大距离尽可能的小,然后统计跳跃距离不小于这个最大距离的猴子数量
也就是最小生成树
接下来介绍prim算法
prim算法的本质是贪心
基本思想:首先任意选一个节点加入树中
之后循环加入距离树最近的节点
思想很好理解吧,接下来介绍如何实现
区分加入树和没有加入树的节点很容易实现,通过一个布尔数组即可
如何获取到树的最近节点是关键
要知道到树的最近节点,就要知道每一个节点到树的最短距离
所以开一个数组维护最短距离
每加入一个新节点,尝试用该新节点去更新最短距离数组
然后从更新后的数组选出距离树最近的节点加入,如此循环即可
与常规图不同的是,这里的任意两个节点之间都可以看作相连的,但是区别也不大
本题可以算得上是prim算法的板题了
AC代码如下
//最小生成树prim
#include <iostream>
#include <algorithm>
#include <memory.h>
using namespace std;
const int max_m = 500;
const int max_n = 1000;
const int NaN = 0x3F3F3F3F;
int jump[max_m + 1] = { 0 };
struct tree { int x, y; }trees[max_n + 1];
bool book[max_n + 1] = { false };
int dist[max_n + 1] = { 0 };
int calc_dist(tree& t_1, tree& t_2) {
return (t_1.x - t_2.x) * (t_1.x - t_2.x) +
(t_1.y - t_2.y) * (t_1.y - t_2.y);
}
void prim(const int& n) {
int node = 1;
int temp = node;
dist[node] = 0;//初始化
for (int i = 1; i <= n; i++) {//最小生成树
int min_dist = NaN;//初始化
for (int j = 1; j <= n; j++) {
if (!book[j]) {//未加入最小生成树
dist[j] = min(dist[j], calc_dist(trees[node], trees[j]));//更新到树的最小距离
if (dist[j] < min_dist) {
temp = j;
min_dist = dist[j];
}
}
}
node = temp;
book[node] = true;//加入最小生成树
}
}
int main() {
memset(dist, 0x3F, sizeof(int) * (max_n + 1));//初始化
int m, n, x, y;
cin >> m;
for (int i = 1; i <= m; i++) cin >> jump[i];
cin >> n;
for (int i = 1; i <= n; i++) {//存图
cin >> x >> y;
trees[i] = { x,y };
}
prim(n);
sort(dist + 1, dist + n + 1);
sort(jump + 1, jump + m + 1);
int i;
for (i = 1; i <= m; i++) {
if (jump[i] * jump[i] >= dist[n]) break;
}
cout << m - i + 1;
return 0;
}
这里由于为了避免开根号带来的精度误差,选择存储平方值
(反正不会溢出)
如果学习过Dijkstra算法,这里再说明一下prim和Dijkstra的不同之处
Dijkstra是要求从一个节点到达所有节点的路径最短,并不关心每条边的长度
prim是要求每条边最短,并不关心最短路径
举一个简单的例子
现在有 10 10 10个节点按顺序围成一个环,除了 1 1 1到 10 10 10的距离为 5 5 5,每两个节点之间的距离都是 1 1 1
现在如果是Dijkstra,获取 1 1 1到 10 10 10的距离应该为 5 5 5,
而prim生成的最小生成树中这个距离为 9 9 9