本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1
0.问题描述
可以参考issue: ERNIE-Layout在(人名和邮箱)信息抽取的诸多问题阐述#4031
- ERNIE-Layout因为看到功能比较强大就尝试了一下,但遇到信息抽取错误,以及抽取不全等问题
- 使用PDFPlumber库和PaddleNLP UIE模型抽取,遇到问题:无法把姓名和邮箱一一对应。
1.基于ERNIE-Layout的DocPrompt开放文档抽取问答模型
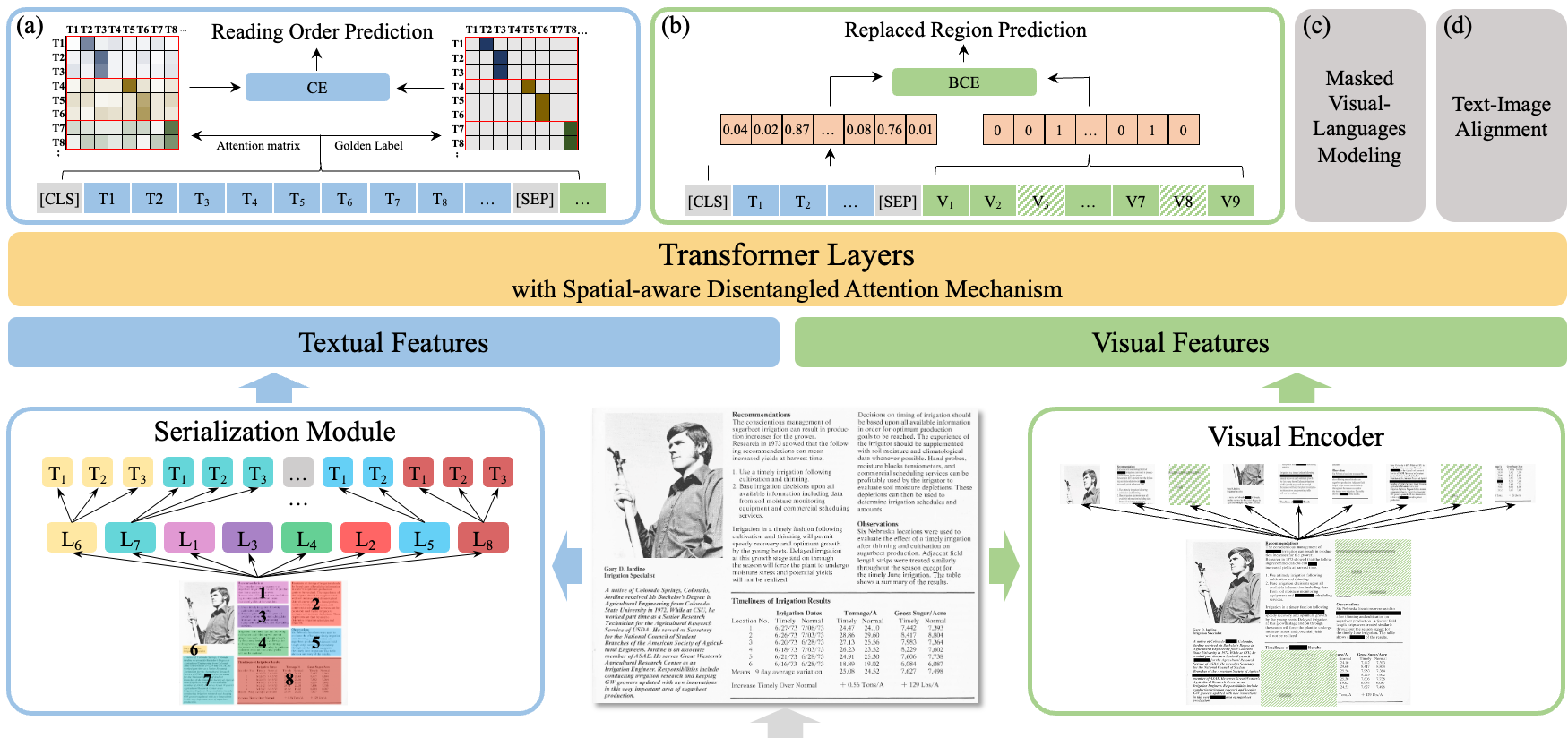
ERNIE-Layout以文心文本大模型ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解偶注意力机制,在各数据集上效果取得大幅度提升,相关工作ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding已被EMNLP 2022 Findings会议收录[1]。考虑到文档智能在多语种上商用广泛,依托PaddleNLP对外开源业界最强的多语言跨模态文档预训练模型ERNIE-Layout。
支持:
- 发票抽取问答
- 海报抽取
- 网页抽取
- 表格抽取
- 长文档抽取
- 多语言票据抽取
- 同时提供pipelines流水线搭建
更多参考官网,这里就不展开了
ERNIE-Layout GitHub地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
Hugging Face网页版:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout
#环境安装
!pip install --upgrade opencv-python
!pip install --upgrade paddlenlp
!pip install --upgrade paddleocr --user
#如果安装失败多试几次 一般都是网络问题
!pip install xlwt
# 支持单条、批量预测
from paddlenlp import Taskflow
docprompt_en= Taskflow("document_intelligence",lang="en",topn=10)
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名和邮箱" ]})
# batch_size:批处理大小,请结合机器情况进行调整,默认为1。
# lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。
# topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。
[{'prompt': '人名和邮箱',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': 'banafshch.nikfar@gmail.com',
'prob': 0.98,
'start': 153,
'end': 159}]}]
可以看到效果不好,多个实体不能一同抽取,需要构建成单个问答,比如姓名和邮箱分开抽取,尝试构造合理的开放式prompt。
小技巧
-
Prompt设计:在DocPrompt中,Prompt可以是陈述句(例如,文档键值对中的Key),也可以是疑问句。因为是开放域的抽取问答,DocPrompt对Prompt的设计没有特殊限制,只要符合自然语言语义即可。如果对当前的抽取结果不满意,可以多尝试一些不同的Prompt。
-
支持的语言:支持本地路径或者HTTP链接的中英文图片输入,Prompt支持多种不同语言,参考以上不同场景的例子。
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名是什么","邮箱是多少", ]})
#无法罗列全部姓名
[{'prompt': '人名是什么',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.74,
'start': 0,
'end': 4}]},
{'prompt': '邮箱是多少',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79}]}]
[{'prompt': '人名是什么',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.74,
'start': 0,
'end': 4}]},
{'prompt': '邮箱是多少',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79}]}]
[{'prompt': '人名',
'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82},
{'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113},
{'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225},
{'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]},
{'prompt': 'email',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': 'banafshch.nikfar@gmail.com',
'prob': 0.98,
'start': 153,
'end': 159}]}]
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名","邮箱","姓名","名字","email"]})
[{'prompt': '人名',
'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82},
{'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113},
{'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225},
{'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]},
{'prompt': '邮箱',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': 'banafshch.nikfar@gmail.com',
'prob': 0.87,
'start': 153,
'end': 159}]},
{'prompt': '姓名',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.76,
'start': 0,
'end': 4}]},
{'prompt': '名字',
'result': [{'value': 'AA.', 'prob': 0.7, 'start': 0, 'end': 1}]},
{'prompt': 'email',
'result': [{'value': 'momtaziaa921@mums.ac.irabbasmomtazi@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': 'banafshch.nikfar@gmail.com',
'prob': 0.98,
'start': 153,
'end': 159}]}]
可以看出得到的效果不是很好,比较玄学,原因应该就是ocr识别对应姓名人名准确率相对不高,无法全部命中;并且无法一一对应。
这块建议看看paddleocr具体实现步骤,研究一下在看看怎么处理。
下面讲第二种方法
2.基于PDFplumber-UIE信息抽取
2.1 PDF文档解析(pdfplumber库)
安装PDFPlumber
!pip install pdfplumber --user
官网链接:https://github.com/jsvine/pdfplumber
pdf的文本和表格处理用多种方式可以实现, 本文介绍pdfplumber对文本和表格提取。这个库在GitHub上stars:3.3K多,使用起来很方便, 效果也很好,可以满足对pdf中信息的提取需求。
pdfplumber.pdf中包含了.metadata和.pages两个属性。
- metadata是一个包含pdf信息的字典。
- pages是一个包含pdfplumber.Page实例的列表,每一个实例代表pdf每一页的信息。
每个pdfplumber.Page类:pdfplumber核心功能,对PDF的大部分操作都是基于这个类,类中包含了几个主要的属性:文本、表格、尺寸等
- page_number 页码
- width 页面宽度
- height 页面高度
- objects/.chars/.lines/.rects 这些属性中每一个都是一个列表,每个列表都包含一个字典,每个字典用于说明页面中的对象信息, 包括直线,字符, 方格等位置信息。
一些常用的方法
- extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串
- extract_words() 返回的是所有的单词及其相关信息
- extract_tables() 提取页面的表格
2.1.1 pdfplumber简单使用
# 利用metadata可以获得PDF的基本信息,作者,日期,来源等基本信息。
import pdfplumber
import pandas as pd
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf:
print(pdf.metadata)
# print("总页数:"+str(len(pdf.pages))) #总页数
print("pdf文档总页数:", len(pdf.pages))
# 读取第一页的宽度,页高等信息
# 第一页pdfplumber.Page实例
first_page = pdf.pages[0]
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)
{'CreationDate': "D:20180428190534+05'30'", 'Creator': 'Arbortext Advanced Print Publisher 9.0.223/W Unicode', 'ModDate': "D:20180428190653+05'30'", 'Producer': 'Acrobat Distiller 9.4.5 (Windows)', 'Title': '0003617532 1..23 ++', 'rgid': 'PB:324947211_AS:677565220007936@1538555545045'}
pdf文档总页数: 24
页码: 1
页宽: 594.95996
页高: 840.95996
# 导入PDFPlumber
import pdfplumber
#打印第一页信息
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf:
first_page = pdf.pages[0]
textdata=first_page.extract_text()
print(textdata)
#打印全部页面
import pdfplumber as ppl
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
# 获得 PDFPlumber 的对象,下面查看pdf全部内容
for page in pdf.pages:
print(page.extract_text())
!pip install xlwt
#读取表格第一页
import pdfplumber
import xlwt
# 加载pdf
path = "/home/aistudio/Scan-1.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第一页
table_1 = page_1.extract_table() # 读取表格数据
print(table_1)
# 1.创建Excel对象
workbook = xlwt.Workbook(encoding='utf8')
# 2.新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3.自定义列名
clo1 = table_1[0]
# 4.将列表元组clo1写入sheet表单中的第一行
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# 保存Excel文件分两种
workbook.save('/home/aistudio/work/input/test_excel.xls')
#读取表格全页
import pdfplumber
from openpyxl import Workbook
class PDF(object):
def __init__(self, file_path):
self.pdf_path = file_path
# 读取pdf文件
try:
self.pdf_info = pdfplumber.open(self.pdf_path)
print('读取文件完成!')
except Exception as e:
print('读取文件失败:', e)
# 打印pdf的基本信息、返回字典,作者、创建时间、修改时间/总页数
def get_pdf(self):
pdf_info = self.pdf_info.metadata
pdf_page = len(self.pdf_info.pages)
print('pdf共%s页' % pdf_page)
print("pdf文件基本信息:\n", pdf_info)
self.close_pdf()
# 提取表格数据,并保存到excel中
def get_table(self):
wb = Workbook() # 实例化一个工作簿对象
ws = wb.active # 获取第一个sheet
con = 0
try:
# 获取每一页的表格中的文字,返回table、row、cell格式:[[[row1],[row2]]]
for page in self.pdf_info.pages:
for table in page.extract_tables():
for row in table:
# 对每个单元格的字符进行简单清洗处理
row_list = [cell.replace('\n', ' ') if cell else '' for cell in row]
ws.append(row_list) # 写入数据
con += 1
print('---------------分割线,第%s页---------------' % con)
except Exception as e:
print('报错:', e)
finally:
wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx')
print('写入完成!')
self.close_pdf()
# 关闭文件
def close_pdf(self):
self.pdf_info.close()
if __name__ == "__main__":
file_path = "/home/aistudio/Scan-1.pdf"
pdf_info = PDF(file_path)
# pdf_info.get_pdf() # 打印pdf基础信息
# 提取pdf表格数据并保存到excel中,文件保存到跟pdf同一文件路径下
pdf_info.get_table()
更多功能(表格读取,图片提取,可视化界面)可以参考官网或者下面链接:
https://blog.csdn.net/fuhanghang/article/details/122579548
2.1.2 学术论文特定页面文本提取
发表论文作者信息通常放在论文首页的脚末行或参考文献的后面,根据这种情况我们可以进行分类(只要获取作者的邮箱信息即可):
- 第一种国外论文:首页含作者相关信息 or 首页是封面第二页才是作者信息 【获取前n页即可,推荐是2页】
- 第二种国内论文:首页含作者信息(邮箱等)在参考文献之后会有各个做的详细信息,比如是职位,研究领域,科研成果介绍等等 【获取前n页和尾页,推荐是2页+尾页】
这样做的好处在于两个方面:
- 节约了存储空间和数据处理时间
- 节约资源消耗,在模型预测时候输入文本数量显著减少,在数据面上加速推理
针对1简单阐述:PDF原始大小614.1KB
| 处理方式 | pdf转文字时延 | 存储占用空间 |
|---|---|---|
| 保存指定前n页面文字 | 242ms | 2.8KB |
| 保存指定前n页面文字和尾页 | 328ms | 5.3KB |
| 保存全文 | 2.704s | 64.1KB |
针对二:以下6中方案提速不过多赘述,可以参考下面项目
- 模型选择 uie-mini等小模型预测,损失一定精度提升预测效率
- UIE实现了FastTokenizer进行文本预处理加速
- fp16半精度推理速度更快
- UIE INT8 精度推理
- UIE Slim 数据蒸馏
- SimpleServing支持支持多卡负载均衡预测
UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!:https://aistudio.baidu.com/aistudio/projectdetail/4516470?contributionType=1
之后有时间重新把paddlenlp技术路线整理一下
#第一种写法:保存指定前n页面文字
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p:
for i in range(3):
page = p.pages[i]
textdata = page.extract_text()
# print(textdata)
data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入
data.write(textdata)
#这里打印出n页文字,因为是追加保存内容是n-1页
#第一种写法:保存指定前n页面文字
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p:
for i in range(3):
page = p.pages[i]
textdata = page.extract_text()
# print(textdata)
data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入
data.write(textdata)
#这里打印出n页文字,因为是追加保存内容是n-1页
#保存指定前n页面文字和尾页
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
texts = []
# 按页打开,合并所有内容,保留前2页
for i in range(2):
text = pdf.pages[i].extract_text()
texts.append(text)
#保留最后一页,index从0开始
end_num=len(pdf.pages)
text_end=pdf.pages[end_num-1].extract_text()
texts.append(text_end)
txt_string = ''.join(texts)
# 保存为和原PDF同名的txt文件
txt_path = pdf_path.split('.')[0]+"_end" + '.txt'
with open(txt_path, "w", encoding='utf-8') as f:
f.write(txt_string)
f.close()
#保留全部文章:
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
texts = []
# 按页打开,合并所有内容,对于多页或一页PDF都可以使用
for page in pdf.pages:
text = page.extract_text()
texts.append(text)
txt_string = ''.join(texts)
# 保存为和原PDF同名的txt文件
txt_path = pdf_path.split('.')[0] +"_all"+'.txt'
with open(txt_path, "w", encoding='utf-8') as f:
f.write(txt_string)
f.close()
#从txt中读取文本,作为信息抽取的输入。对于比较长的文本,可能需要人工的设定一些分割关键词,分段输入以提升抽取的效果。
txt_path="/home/aistudio/work/input/test_paper2.txt"
with open(txt_path, 'r') as f:
file_data = f.readlines()
record = ''
for data in file_data:
record += data
print(record)
2.2 UIE信息抽取(论文作者和邮箱)
2.2.1 零样本抽取
from pprint import pprint
import json
from paddlenlp import Taskflow
def openreadtxt(file_name):
data = []
file = open(file_name,'r',encoding='UTF-8') #打开文件
file_data = file.readlines() #读取所有行
for row in file_data:
data.append(row) #将每行数据插入data中
return data
data_input=openreadtxt('/home/aistudio/work/input/test_paper2.txt')
schema = ['人名', 'email']
few_ie = Taskflow('information_extraction', schema=schema, batch_size=16)
results=few_ie(data_input)
print(results)
with open("./output/reslut_2.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
for result in results:
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
print("数据结果已导出")
2.3长文本的答案获取
UIE对于词和句子的抽取效果比较好,但是对应大段的文字结果,还是需要传统的正则方式作为配合,在本次使用的pdf中,还需要获得法院具体的判决结果,使用正则表达式可灵活匹配想要的结果。
start_word = '如下'
end_word = '特此公告'
start = re.search(start_word, record)
end = re.search(end_word, record)
print(record[start.span()[1]:end.span()[0]])
:
海口中院认为:新达公司的住所地在海口市国贸大道 48
号新达商务大厦,该司是由海南省工商行政管理局核准登记
的企业,故海口中院对本案有管辖权。因新达公司不能清偿
到期债务,故深物业股份公司提出对新达公司进行破产清算
1
的申请符合受理条件。依照《中华人民共和国企业破产法》
第二条第一款、第三条、第七条第二款之规定,裁定如下:
受理申请人深圳市物业发展(集团)股份有限公司对被
申请人海南新达开发总公司破产清算的申请。
本裁定自即日起生效。
二、其他情况
本公司已对海南公司账务进行了全额计提,破产清算对
本公司财务状况无影响。
具体情况请查阅本公司2011年11月28日发布的《董事会
决议公告》。
2.4正则提升效果
对于长文本,可以根据关键词进行分割后抽取,但是对于多个实体,比如这篇公告中,通过的多个议案,就无法使用UIE抽取。
# 导入正则表达式相关库
import re
schema = ['通过议案']
start_word = '通过以下议案'
start = re.search(start_word, record)
input_data = record[start.span()[0]:]
print(input_data)
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(input_data))
# 正则匹配“一 二 三 四 五 六 七 八 九 十”
print(re.findall(r"[\u4e00\u4e8c\u4e09\u56db\u4e94\u516d\u4e03\u516b\u4e5d\u5341]、.*\n", input_data))
['一、2021 年第三季度报告 \n', '二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券\n', '三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项\n', '四、关于续聘会计师事务所的议案 \n', '五、关于向银行申请综合授信额度的议案 \n', '一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5\n', '二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿\n', '六、经理层《岗位聘任协议》 \n', '七、经理层《年度经营业绩责任书》 \n', '八、经理层《任期经营业绩责任书》 \n', '九、关于暂不召开股东大会的议案 \n']
# 3.基于基于UIE-X的信息提取
## 3.1 跨模态文档信息抽取
跨模态文档信息抽取能力 UIE-X 来了。 信息抽取简单说就是利用计算机从自然语言文本中提取出核心信息,是自然语言处理领域的一项关键任务,包括命名实体识别(也称实体抽取)、关系抽取、事件抽取等。传统信息抽取方案基于序列标注,需要大量标注语料才能获得较好的效果。2022年5月飞桨 PaddleNLP 推出的 UIE,是业界首个开源的面向通用信息抽取的产业级技术方案 ,基于 Prompt 思想,零样本和小样本能力强大,已经成为业界信息抽取任务上的首选方案。
除了纯文本内容外,企业中还存在大量需要从跨模态文档中抽取信息并进行处理的业务场景,例如从合同、收据、报销单、病历等不同类型的文档中抽取所需字段,进行录入、比对、审核校准等操作。为了满足各行业的跨模态文档信息抽取需求,PaddleNLP 基于文心ERNIE-Layout[1]跨模态布局增强预训练模型,集成PaddleOCR的PP-OCR、PP-Structure版面分析等领先能力,基于大量信息抽取标注集,训练并开源了UIE-X–––首个兼具文本及文档抽取能力、多语言、开放域的信息抽取模型。
* 支持实体抽取、关系抽取、跨任务抽取
* 支持跨语言抽取
* 集成PP-OCR,可灵活定制OCR结果
* 使用PP-Structure版面分析功能
* 增加渲染模块,OCR和信息抽取结果可视化
项目链接:
[https://aistudio.baidu.com/aistudio/projectdetail/5017442](https://aistudio.baidu.com/aistudio/projectdetail/5017442)
## 3.2 产业实践分享:基于UIE-X的医疗文档信息提取
PaddleNLP全新发布UIE-X 🧾,除已有纯文本抽取的全部功能外,新增文档抽取能力。
UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先。
官网链接:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction
本案例为UIE-X在医疗领域的实战,通过少量标注+模型微调即可具备定制场景的端到端文档信息提取
目前医疗领域有大量的医学检查报告单,病历,发票,CT影像,眼科等等的医疗图片数据。现阶段,针对这些图片都是靠人工分类,结构化录入系统中,做患者的全生命周期的管理。 耗时耗力,人工成本极大。如果能靠人工智能的技术做到图片的自动分类和结构化,将大大的降低成本,提高系统录入的整体效率。
项目链接:
[https://aistudio.baidu.com/aistudio/projectdetail/5261592](https://aistudio.baidu.com/aistudio/projectdetail/5261592)
4.总结
本项目提供了基于ERNIELayout&PDFplumber-UIEX多方案学术论文信息抽取,有兴趣同学可以研究一下UIE-X。
UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先.