总结
总结:
- bison给出的用例是发现冲突的最便捷方法。
- 第一种用例:明确用例(一个Example),直接反应问题。
- 第二种用例:混淆用例(两个Example),解析器无法区分两条语句。
- 也可以看output输出的状态机中给出的两条冲突规则,可读性比较差。
- 方括号括起来的是冲突的路径。
总结:
- bison给出用例的第二种情况,有时会比较难以理解。为什么呢?
- 因为他给的用例可能是经过reduce的上层用例,真正冲突的地方在语法树下层。
案例一:返回一个Example的场景(简单)
冲突报错返回一个明确用例的场景。
sequence.y
%%
sequence:
%empty
| maybeword
| sequence "word"
;
maybeword:
%empty
| "word"
;
编译
$ bison -Wcex --report='cex' sequence.y
sequence.y: warning: 1 shift/reduce conflict [-Wconflicts-sr]
sequence.y: warning: 2 reduce/reduce conflicts [-Wconflicts-rr]
共有三条冲突,下面是用例:
【冲突一】
注意看用例Example,提供的是一个 "空 word"的例子。
用例说明比较清晰了,"空 word"可能被两条规则消费:
- “空” 被规约为sequence,sequence+"word"规约为sequence。
- “空” 和 “word” 都被移进位sequence
sequence.y: warning: shift/reduce conflict on t0ken "word" [-Wcounterexamples]
Example: . "word"
Shift derivation
sequence
`-> 2: maybeword
`-> 5: . "word"
Reduce derivation
sequence
`-> 3: sequence "word"
`-> 1: %empty .
【冲突二】
输入空的时候,有两个规约路径。
sequence.y: warning: reduce/reduce conflict on tokens $end, "word" [-Wcounterexamples]
Example: .
First reduce derivation
sequence
`-> 1: %empty .
Second reduce derivation
sequence
`-> 2: maybeword
`-> 4: %empty .
output
下面看看output文件怎么阅读。
- 最上面会有告警和冲突的汇总。
- Grammar开始是规则区,y文件中的每一行规则在这里编号,后面使用时会使用编号代替。
- State 0开始是状态区,状态转移如果不唯一的话,会在State区列出例子和冲突选项。
- 状态机转移请看下一个例子。
$ cat sequence.output
Rules useless in parser due to conflicts
4 maybeword: %empty
State 0 conflicts: 1 shift/reduce, 2 reduce/reduce
Grammar
0 $accept: sequence $end
1 sequence: %empty
2 | maybeword
3 | sequence "word"
4 maybeword: %empty
5 | "word"
Terminals, with rules where they appear
$end (0) 0
error (256)
"word" (258) 3 5
Nonterminals, with rules where they appear
$accept (4)
on left: 0
sequence (5)
on left: 1 2 3
on right: 0 3
maybeword (6)
on left: 4 5
on right: 2
State 0
0 $accept: . sequence $end
"word" shift, and go to state 1
$end reduce using rule 1 (sequence)
$end [reduce using rule 4 (maybeword)]
"word" [reduce using rule 1 (sequence)]
"word" [reduce using rule 4 (maybeword)]
$default reduce using rule 1 (sequence)
sequence go to state 2
maybeword go to state 3
shift/reduce conflict on t0ken "word":
1 sequence: %empty .
5 maybeword: . "word"
Example: . "word"
Shift derivation
sequence
`-> 2: maybeword
`-> 5: . "word"
Reduce derivation
sequence
`-> 3: sequence "word"
`-> 1: %empty .
reduce/reduce conflict on t0kens $end, "word":
1 sequence: %empty .
4 maybeword: %empty .
Example: .
First reduce derivation
sequence
`-> 1: %empty .
Second reduce derivation
sequence
`-> 2: maybeword
`-> 4: %empty .
shift/reduce conflict on t0ken "word":
4 maybeword: %empty .
5 maybeword: . "word"
Example: . "word"
Shift derivation
sequence
`-> 2: maybeword
`-> 5: . "word"
Reduce derivation
sequence
`-> 3: sequence "word"
`-> 2: maybeword
`-> 4: %empty .
State 1
5 maybeword: "word" .
$default reduce using rule 5 (maybeword)
State 2
0 $accept: sequence . $end
3 sequence: sequence . "word"
$end shift, and go to state 4
"word" shift, and go to state 5
State 3
2 sequence: maybeword .
$default reduce using rule 2 (sequence)
State 4
0 $accept: sequence $end .
$default accept
State 5
3 sequence: sequence "word" .
$default reduce using rule 3 (sequence)
案例二:返回两个Example的场景(复杂递归)
冲突报错返回两个混淆用例的场景(解析器无法区分两个用例)。
ids.y
%token ID
%%
s: a ID
a: expr
expr: %empty | expr ID ','
编译
$ bison -Wcex --report='cex' ids.y
ids.y: warning: 1 shift/reduce conflict [-Wconflicts-sr]
ids.y: warning: shift/reduce conflict on token ID [-Wcounterexamples]
First example: expr . ID ',' ID $end
Shift derivation
$accept
`-> 0: s $end
`-> 1: a ID
`-> 2: expr
`-> 4: expr . ID ','
Second example: expr . ID $end
Reduce derivation
$accept
`-> 0: s $end
`-> 1: a ID
`-> 2: expr .
ids.y:4.4-7: warning: rule useless in parser due to conflicts [-Wother]
4 | a: expr
| ^~~~
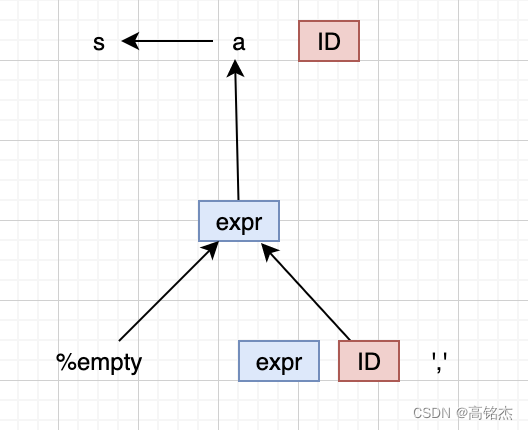
复杂递归的规则,bison无法计算出一个冲突的例子。
所以解析器只能给出两个反例,含义是他无法区分这两个例子的区别。
解析器需要一个look ahead token,来知道逗号是否跟在expr ID后面。
修复的方法是:expr: ID | ',' expr ID.
ids.y
%token ID
%%
s: a ID
a: expr
expr: ID | ',' expr ID
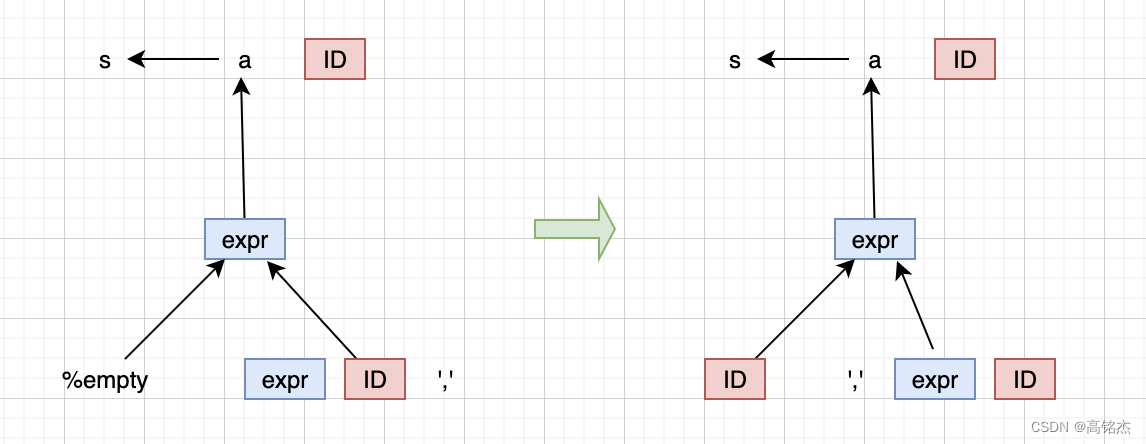
注意:
- 修复前,
expr ID的解析是有歧义的,如果后面有逗号,应该走上面的例子;如果后面没逗号,应该走下面的例子。 - 修复后,
expr ID的解析是稳定的,肯定会走expr reduce a; then shift ID。
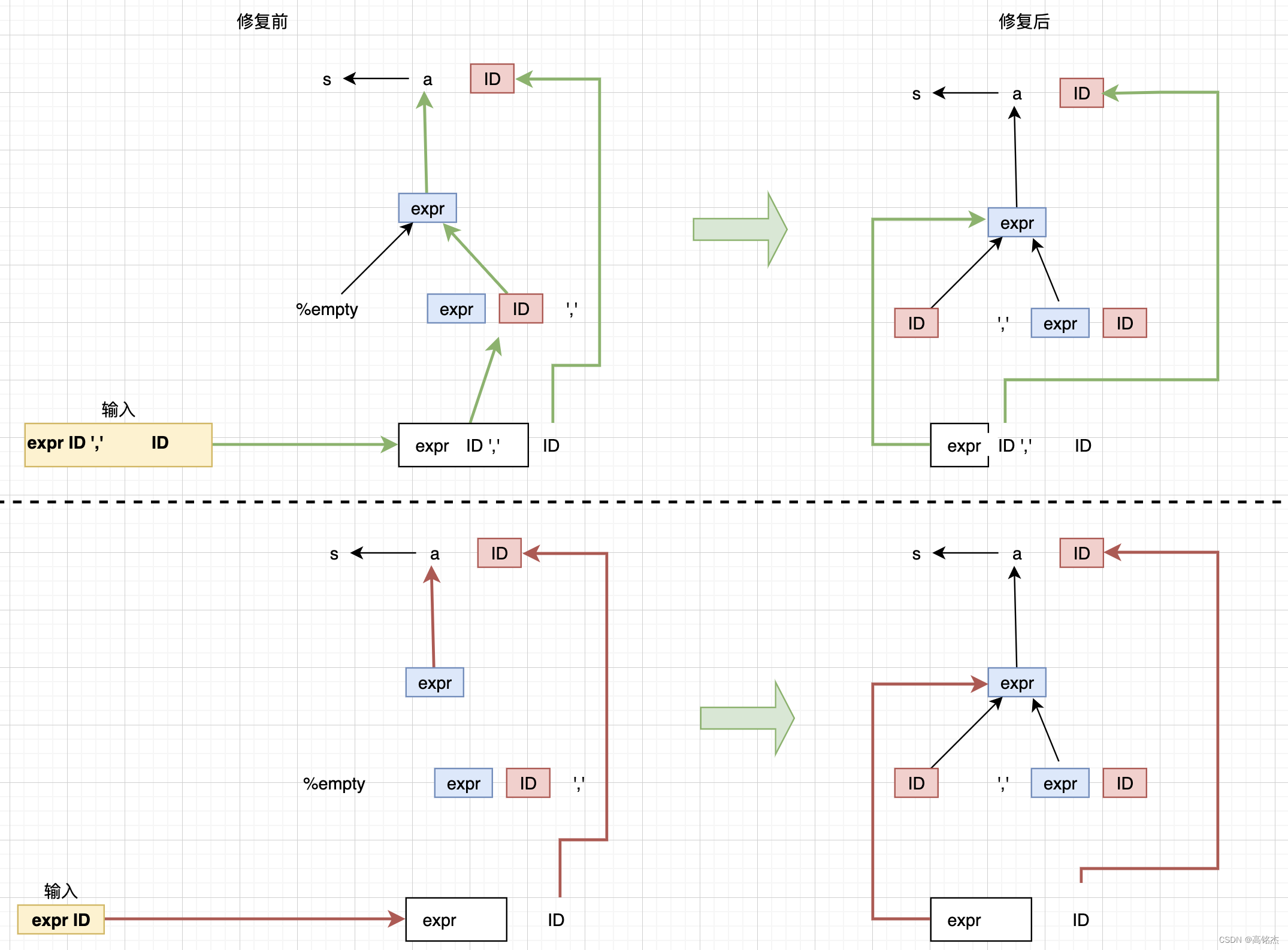
从Output来看,主要问题是无法确定:
- 选路径1:ID shift, and go to state 6
- state 6:
4 expr: expr ID . ','->',' shift, and go to state 7 - 即ID参与`expr: expr ID . ‘,’``规则的shift。
- state 6:
- 还是选路径2:ID [reduce using rule 2 (a)]
- rule2:
a: expr
- rule2:
$ cat ids.output
Rules useless in parser due to conflicts
2 a: expr
State 3 conflicts: 1 shift/reduce
Grammar
0 $accept: s $end
1 s: a ID
2 a: expr
3 expr: %empty
4 | expr ID ','
Terminals, with rules where they appear
$end (0) 0
',' (44) 4
error (256)
ID (258) 1 4
Nonterminals, with rules where they appear
$accept (5)
on left: 0
s (6)
on left: 1
on right: 0
a (7)
on left: 2
on right: 1
expr (8)
on left: 3 4
on right: 2 4
State 0
0 $accept: . s $end
$default reduce using rule 3 (expr)
s go to state 1
a go to state 2
expr go to state 3
State 1
0 $accept: s . $end
$end shift, and go to state 4
State 2
1 s: a . ID
ID shift, and go to state 5
State 3
2 a: expr .
4 expr: expr . ID ','
ID shift, and go to state 6
ID [reduce using rule 2 (a)]
shift/reduce conflict on token ID:
2 a: expr .
4 expr: expr . ID ','
First example: expr . ID ',' ID $end
Shift derivation
$accept
`-> 0: s $end
`-> 1: a ID
`-> 2: expr
`-> 4: expr . ID ','
Second example: expr . ID $end
Reduce derivation
$accept
`-> 0: s $end
`-> 1: a ID
`-> 2: expr .
State 4
0 $accept: s $end .
$default accept
State 5
1 s: a ID .
$default reduce using rule 1 (s)
State 6
4 expr: expr ID . ','
',' shift, and go to state 7
State 7
4 expr: expr ID ',' .
$default reduce using rule 4 (expr)
修复后
Grammar
0 $accept: s $end
1 s: a ID
2 a: expr
3 expr: ID
4 | ',' expr ID
Terminals, with rules where they appear
$end (0) 0
',' (44) 4
error (256)
ID (258) 1 3 4
Nonterminals, with rules where they appear
$accept (5)
on left: 0
s (6)
on left: 1
on right: 0
a (7)
on left: 2
on right: 1
expr (8)
on left: 3 4
on right: 2 4
State 0
0 $accept: . s $end
ID shift, and go to state 1
',' shift, and go to state 2
s go to state 3
a go to state 4
expr go to state 5
State 1
3 expr: ID .
$default reduce using rule 3 (expr)
State 2
4 expr: ',' . expr ID
ID shift, and go to state 1
',' shift, and go to state 2
expr go to state 6
State 3
0 $accept: s . $end
$end shift, and go to state 7
State 4
1 s: a . ID
ID shift, and go to state 8
State 5
2 a: expr .
$default reduce using rule 2 (a)
State 6
4 expr: ',' expr . ID
ID shift, and go to state 9
State 7
0 $accept: s $end .
$default accept
State 8
1 s: a ID .
$default reduce using rule 1 (s)
State 9
4 expr: ',' expr ID .
$default reduce using rule 4 (expr)