sentinel入门
功能
限流:通过限制请求速率、并发数或者用户数量来控制系统的流量,防止系统因为流量过大而崩溃或无响应的情况发生。
熔断:在系统出现故障或异常时将故障节点从系统中断开,从而保证系统的可用性。
降级:在系统过载的情况下保证核心功能的可用性。
熔断和限流的区别在于:熔断是针对
故障节点的,将故障节点从系统中断开,而降级是针对整个系统的,系统在过载的情况下关闭一些非核心功能,仍能提供核心功能的可用性。
资源: 资源是被 Sentinel 保护和管理的对象
规则:用来定义资源应该遵循的约束条件
资源和规则的关系
Sentinel 会根据配置的规则,对资源的调用进行相应的控制,从而保证系统的稳定性和高可用性
sentinel核心概念
- Entry:资源。每个资源对应一个 Entry 对象。每个 Entry 对象包含基本信息(如:名称、请求类型、资源类型等)、数据采集链以及获取指标信息的方法(如:总请求数、成功请求数、失败请求数等指标)。由于一次请求可能涉及多个资源,因此资源采用双向链表结构。
- Context:上下文。资源的操作必须在一个 Context 环境下进行,而一个 Context 可以包含多个资源。
概括为:每个资源需要一个 Entry 对象,资源的操作必须建立在一个 Context 环境下,一个 Context 可以包含多个资源。可以类比为一个 Context 包含一条完整链路的所有资源
资源对象 Entry
要实现流控、熔断降级等功能,我们确实需要首先收集资源的调用指标。这些指标包括但不限于:请求总 QPS、请求失败的 QPS、请求成功的 QPS、线程数、响应时间等。通过收集这些数据,Sentinel 才可以根据预设的规则对资源的调用进行相应的控制
如何收集指标?
过滤器 + 责任链
过滤器: 拦截请求, 统计响应的数据
责任链: 将各个过滤器串联起来, 每个过滤器统计自己相应规则的指标
资源名
统计指标之前, 需要传入统计的对象, 该对象我们称之为资源
这里使用Entry表示一个对象, 其中name是资源名称
public class Entry {
// 资源名称
private final String name;
// 目前省略其他描述属性
}
出/入流量
之前提到的示例是关于入口流量的,即我们作为 API 提供给其他人调用时,然而,还存在一种出口流量的情况, 当我们请求一个第三方 API(如:发送短信的 SMS 服务),这个第三方 API 可能会有 QPS 限制, 此时发起请求的时候需要控制请求速率(出口流量)
补充说明
别人请求我们: 入口流量
我们请求别人: 出口流量
public enum EntryType {
/**
* 入口流量
*/
IN,
/**
* 出口流量
*/
OUT;
}
资源类型
前面说过资源可以是任意的, 也就说资源不一定是Spring MVC的HTTP接口, 还可以是其他类型, 所以需要额外的字段记录`资源类型
public final class ResourceTypeConstants {
// 默认类型
public static final int COMMON = 0;
// web类型,也就是最常见的 http 类型
public static final int COMMON_WEB = 1;
// rpc 类型,如Dubbo RPC,Grpc,Thrift等
public static final int COMMON_RPC = 2;
// API 网关
public static final int COMMON_API_GATEWAY = 3;
// 数据库 SQL 操作
public static final int COMMON_DB_SQL = 4;
}
资源封装
目前的一个资源到目前为止有三个字段:名称(name)、请求类型(entryType)以及资源类型(resourceType)。我们将这三个字段包装成一个新的类
public class ResourceWrapper {
protected final String name;
protected final EntryType entryType;
protected final int resourceType;
public ResourceWrapper(String name, EntryType entryType, int resourceType) {
this.name = name;
this.entryType = entryType;
this.resourceType = resourceType;
}
}
然后将这个 Wrapper 包装类放到我们的资源对象 Entry
public class Entry {
// 封装了 名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
}
}
Entry-ResourceWrapper-EntryType-ResourceTypeConstans四者之间的关系
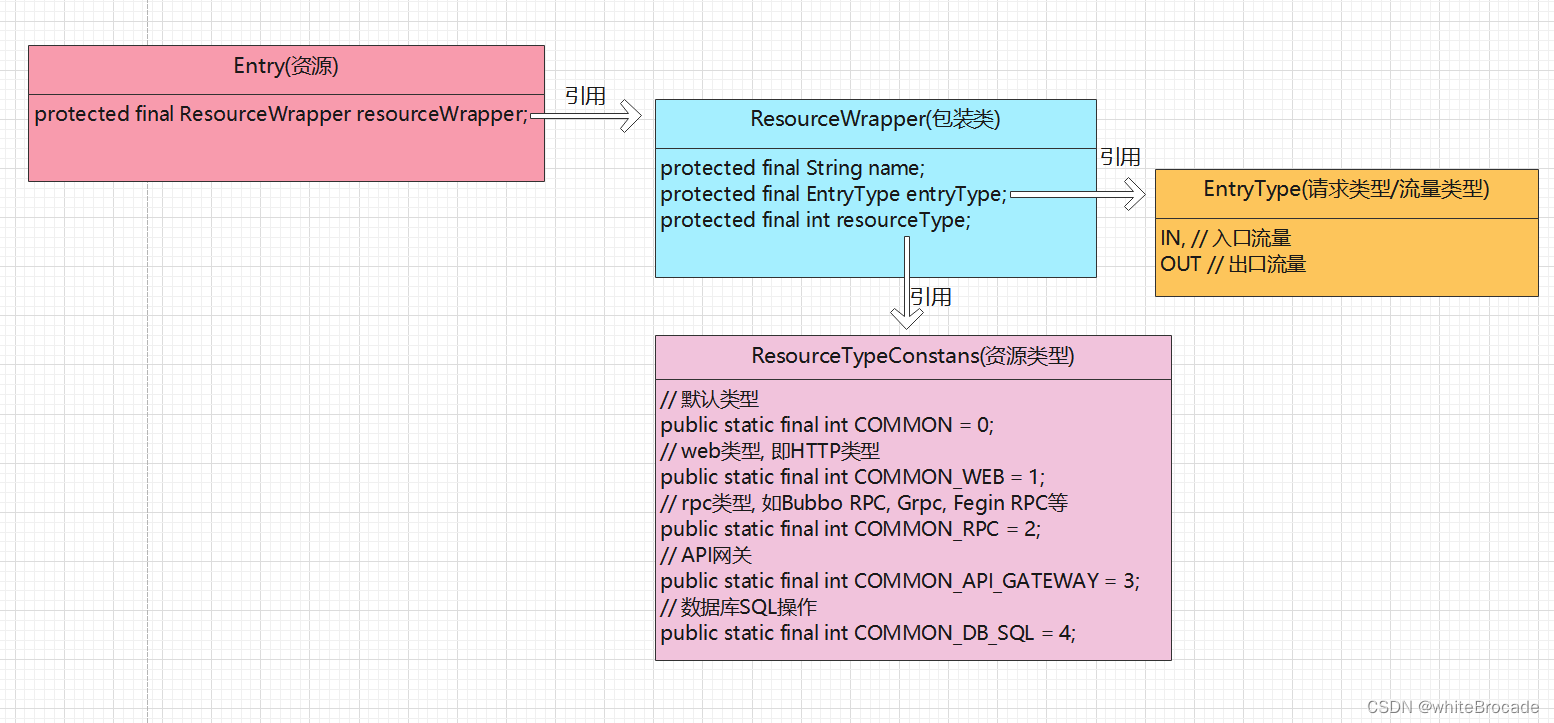
Entry 就是资源管理对象,一个资源肯定要有一个 Entry 与之对应。Entry 对象可以简单理解为处理某个资源的对象
上述的基础上还无法满足,需求, 继续添加字段, 需要记录操作资源的开始时间和完成时间
public class Entry {
// 操作资源的开始时间
private final long createTimestamp;
// 操作资源的完成时间
private long completeTimestamp;
// 封装了 名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
// 给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}
统计数据的存储
上述我们只是定义了一些基本值, 实际还没没有看到统计数据, 统计数据需要计算, 我们将获取这些指标的方法放到一个interface里,然后通过interface提供的方法去获取这些指标,我们称这个 interface 为 Node
/**
* 用于统计各项指标数据
*/
public interface Node {
// 总的请求数
long totalRequest();
// 请求成功数
long totalSuccess();
// ...... 等等
}
将存储统计数据的Node添加到Entry
public class Entry {
// 操作资源的开始时间
private final long createTimestamp;
// 操作资源的完成时间
private long completeTimestamp;
// 统计各项数据指标
private Node curNode;
// 封装了 名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
// 给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}
触发阈值后的通知/处理动作(流控异常)
当触发预设规则阈值,例如 QPS 达到设定的限制,系统将抛出警告提示:“超出 QPS 配置限制”。为了实现这一功能,我们需要自定义一个异常:BlockException。
public abstract class Entry {
// 操作资源的开始时间
private final long createTimestamp;
// 操作资源的完成时间
private long completeTimestamp;
// 统计各项数据指标
private Node curNode;
// 异常
private BlockException blockError;
// 封装了 名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
// 给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}
将Entry抽取成抽象类, 方便后续子类继承
到此为此对象中字段可以做到以下事情,
- 统计一个资源的出口流量(请求类型 = OUT)、成功次数、失败次数等指标
- 并且可以根据规则配置进行判断:如果超出 QPS,那么抛出自定义异常 BlockException
Entry范围表示
现在我们来讨论一个需求。假设我们提供一个外部接口(sms/send)用于发送短信服务。具体的短信发送操作是通过第三方云服务商提供的 API 或 SDK 完成的,这些云服务商会对 QPS 进行限制。当用户请求到达我们的系统时,会生成一个名为 sms/send 的 Entry,然而,在我们的接口请求第三方 API 时,也需要进行限流操作,因此还会生成一个名为 yun/sms/api 的 Entry。

两个Entry都算同一个请求, 两个Entry有链表关系, 所以加入头尾指针
// Entry 的子类
class CtEntry extends Entry {
// 指向上一个节点,父节点,类型为 Entry
protected Entry parent = null;
// 指向下一个节点,字节点,类型为 Entry
protected Entry child = null;
}
但是单单有头尾指针还不足以表达出Entyr的范围, 必须引入Context
// Entry 的子类
class CtEntry extends Entry {
// 指向上一个节点,父节点,类型为 Entry
protected Entry parent = null;
// 指向下一个节点,字节点,类型为 Entry
protected Entry child = null;
// 作用域,上下文
protected Context context;
}
在同一作用范围下获取所有 Entry 链条的信息,以及了解每个 Entry 的名称和指标数据获取方法
指标数据源的采集
可以通过责任链模式设置一系列过滤器,让每个过滤器专注于各自的职责。因此,我们的 CtEntry 还需要增加一个责任链类型的字段
// Entry 的子类
class CtEntry extends Entry {
// 指向上一个节点,父节点,类型为 Entry
protected Entry parent = null;
// 指向下一个节点,字节点,类型为 Entry
protected Entry child = null;
// 作用域,上下文
protected Context context;
// 责任链
protected ProcessorSlot<Object> chain;
}
截至目前,我们的资源对象 Entry(及其子类 CtEntry )已经设计完善,它包括每次请求的 Entry 基本信息、每个 Entry 的指标信息采集(如:流量控制配置、黑白名单配置、熔断降级配置等)以及获取指标信息的方法。
然而,我们还需要解决三个尚未明确的部分,即:数据统计 Node、上下文 Context 以及数据采集责任链 ProcessorSlot
管理资源对象的上下文 Context
Context 对象的用途很简单:用于在一个请求调用链中存储关联的 Entry 信息、资源名称和其他有关请求的数据。这些数据在整个请求处理过程中都可以被访问和操作
- 在 Sentinel 中,每个请求都有一个与之关联的 Context 实例
- 当请求进入系统时,Context 被创建并跟随请求在处理过程中的各个组件之间传递
Context名
Context 也需要有名称,因此我们设计如下类
public class Context {
private final String name;
// 其他待补充的属性...
}
不仅要有 name,我们还需要知道请求来源,比如请求 IP,以及还需要知道当前上下文处理到哪个 Entry
public class Context {
// 名称
private final String name;
// 处理到哪个 Entry 了
private Entry curEntry;
// 来源,比如请求 IP
private String origin = "";
}
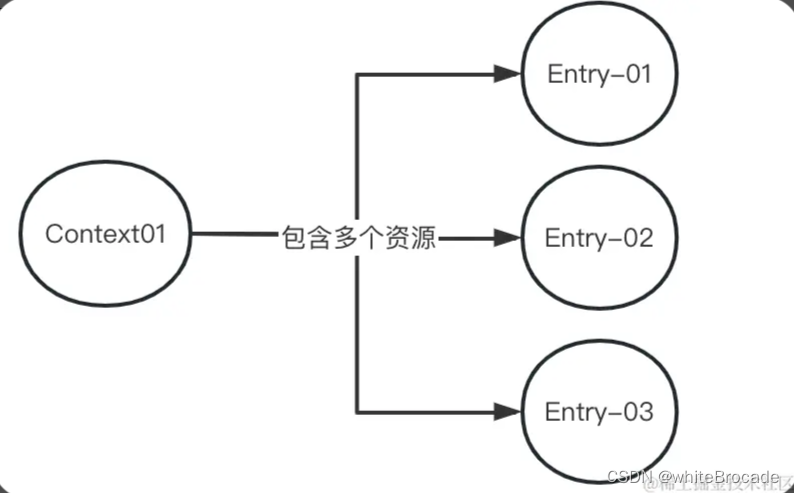
可以发现 Context 比较简单,就好比一个容器,装载了此次请求的所有资源(注意了, 强调的是资源, 而不是接口),也就是装载了Entry双向链表。
由此可见:
- 一个 Context 的生命周期内可能有
多个资源操作(也就是说不是一个接口对应一个 Context,可以是多个接口对应一个 Context,比如 a 调用 b,b 调用 c,那么 a、b、c 三个资源就属于同一个 Context) - Context 生命周期内的最后一个资源
exit时会清理该Context,这也预示整个Context 生命周期的结束。
这里简单总结下:在处理对应资源的时候,或者处理多个资源的时候,这些资源的操作是必须建立在一个 Context 环境下,而且每一个资源的操作是必须通过 Entry 对象来操作,也就是多个资源就需要多个 Entry,但是这些 Entry 可以属于同一个 Context。如下图所示:
数据采集的责任链模式ProcessorSlot接口
ProcessorSlot是一个责任链, 负责各种数据采集, 在 Sentinel 中,每次资源调用都会创建一个 Entry 对象。Entry 对象中有一个名为 ProcessorSlot(插槽)的属性。这意味着在创建 Entry 时,同时也会生成一系列功能插槽(责任链),这些插槽各自承担不同的职责
核心问题: 哪些插槽需要创建?
资源收集器NodeSelectorSlot
首先我们需要资源的路径, 需要一个资源收集器专门负责收集资源的路径,并将这些资源的调用路径以树状结构存储起来。有了这个资源树状图,我们将很容易实现对某个节点的限流和降级,因此第一个插槽就此诞生
NodeSelectorSlot:负责收集资源的路径,并将这些资源的调用路径以树状结构存储起来,主要用于根据调用路径来限流降级。
数据收集插槽
ClusterBuilderSlot:此插槽主要负责实现集群限流功能。在 Sentinel 中,集群限流可以帮助你实现跨多个应用实例的资源访问限制。ClusterBuilderSlot将处理请求的流量信息汇报到集群的统计节点(ClusterNode),然后根据集群限流规则决定是否应该限制请求,此处理器槽在集群限流功能中起到了关键作用。StatisticSlot:此处理器槽负责记录资源的访问统计信息,如通过的请求数、阻塞的请求数、响应时间等。StatisticSlot将每次资源访问的信息记录在资源的统计节点(StatisticNode)中。这些统计信息是 Sentinel 执行流量控制(如限流、熔断降级等)重要指标。
功能性插槽
根据指标信息对资源路径进行各种流控、熔断降级等功能, 需要一些额外的功能, 所以还需要几个功能性插槽
SystemSlot:实现系统保护功能,提供基于系统负载、系统平均响应时间和系统入口 QPS 的自适应降级保护策略。AuthoritySlot:负责实现授权规则功能,主要控制不同来源应用的黑白名单访问权限。FlowSlot: 实现流量控制功能,包括针对不同来源的流量限制、基于调用关系的流量控制等。DegradeSlot: 负责熔断降级功能,支持基于异常比例、异常数和响应时间的降级策略。
插槽之间的关系以及作用
官方网站上的一张图来概括这个责任链之间的关系
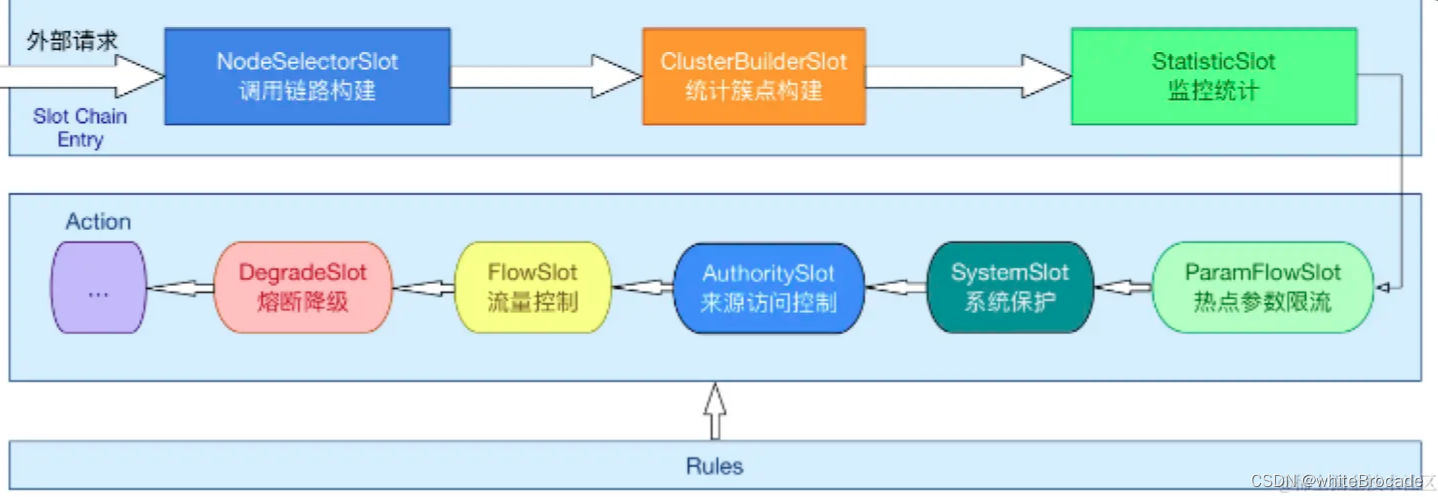
插槽的用途可以用一句话概括为:负责构建资源路径树、进行数据采集,并实施流量控制、熔断降级等规则限制。可以发现上图中有一个 ParamFlowSlot 热点参数限流,这个严格意义上讲不属于默认的 Slot 体系,是作为一个插件附属上去的(后续讲解)
统计各种指标数据Node接口
作用: 基于插槽采集的数据进行统计,最基本的可以统计总的请求量、请求成功量、请求失败量等指标
public interface Node {
// 获取总请求量
long totalRequest();
// 获取请求成功量
long successRequest();
// 获取请求失败量
long failedRequest();
// 其他可能的方法和指标...
}
Node是一个接口, 那么就应该有相关的实现类, 由于 Node 接口主要关注统计相关功能,因此将实现类命名为 StatisticNode 是非常合适的,如下
public class StatisticNode implements Node {
// ......
}
通过这个 StatisticNode 类,我们可以完成 Node 接口定义的各种性能指标的收集和计算。但为了更多维度的计算,比如:上下文 Context 维度、资源维度等,因此还需要额外设计如下三个子类。
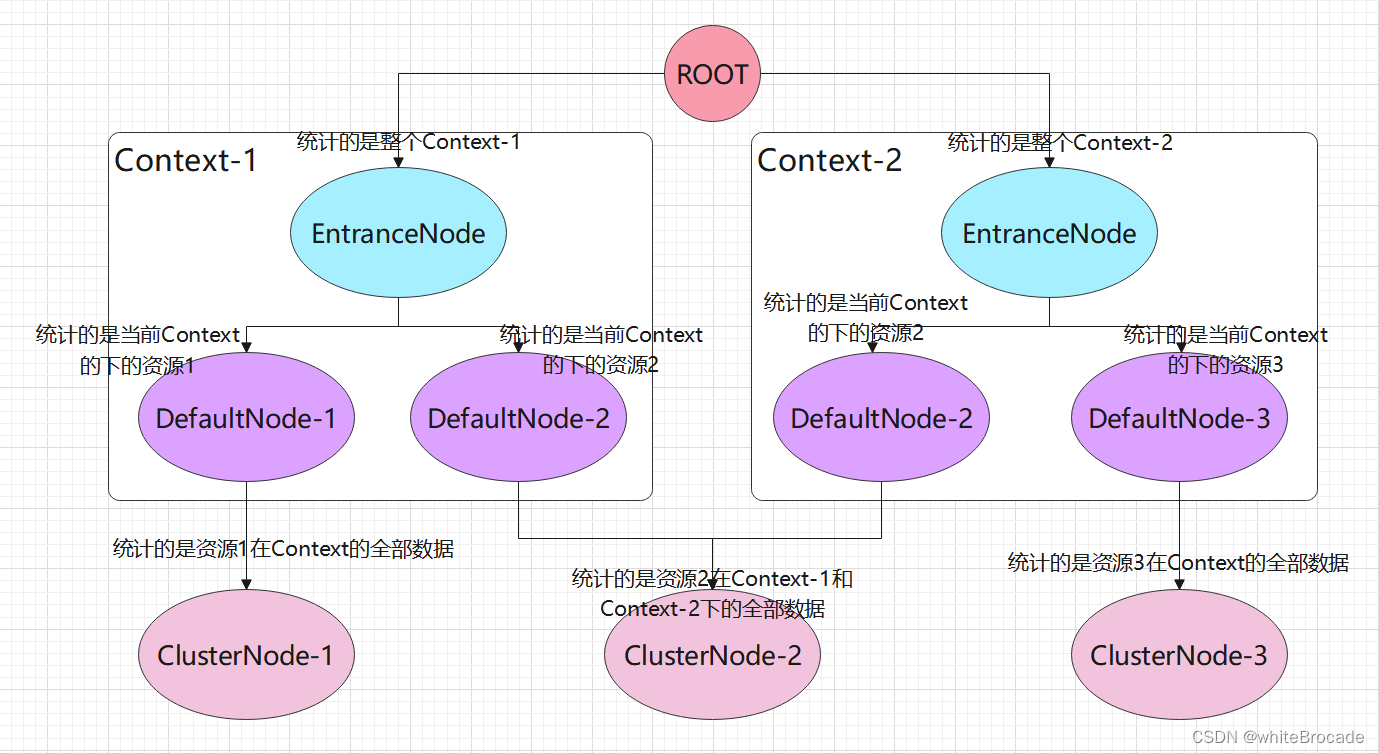
DefaultNode:默认节点,用于统计一个资源在当前 Context 中的数据,意味着 DefaultNode 是以 Context 和 Entry 为维度进行统EntranceNode:继承自DefaultNode,也是每一个 Context 的入口节点,用于统计当前 Context 的总体流量数据,统计维度为ContextClusterNode:ClusterNode 保存的是同一个资源的相关的统计信息,是以资源为维度的,不区分Context
三者的区别是
- DefaultNode统计的是某个Context下的某个资源的数据信息
- EntranceNode统计的是某个Context下的全部资源信息
- ClusterNode统计的是某个资源在所有Context下的统计信息
统计的维度如下图
Node之间的关系
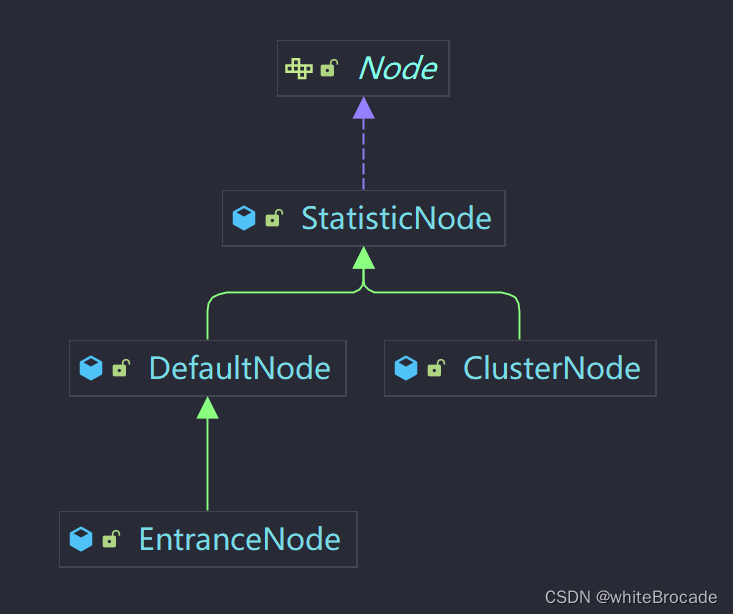
一个 Context 包含多个资源,每个资源都通过 ProcessorSlot 进行数据采集和规则验证,而采集完的数据交由 Node 去做聚合统计、分析
原理分析
Context设计和源码
回顾一下核心概念阐述的Context
每个请求都需要与 Context 绑定,一个 Context 可以关联多个资源,而每个资源都通过责任链 ProcessorSlot 进行数据采集和规则验证,数据采集完成后,通过 Node 进行统计和分析
Context设计思想
每个资源都要附属于 Context 下,那我们这行代码的底层逻辑肯定有一步是初始化一个 Context 对象且与当前请求的线程绑定
那现在就产生了如下几个问题:
- 我们之前说了 Context 是需要name字段的,那么我们
没传递name字段,怎么办呢? - 一个请求会产生一个线程并绑定一个 Context,那么
线程和Context 如何绑定呢?- 如何绑定的?
- 如何初始化
Entry对象? - 如何将Entry挂载到Context 下?
如果没有没传递name字段, 那么sentinel会默认传递一个的name, 即sentinel_default_context
// com.alibaba.csp.sentinel.CtSph.InternalContextUtil#internalEnter(java.lang.String)
Context context = InternalContextUtil.internalEnter("sentinel_default_context");
线程如何和 Context 进行绑定
即然是每个请求都要与一个 Context 进行绑定,那么 ThreadLocal 最为合适不过(ThreadLocal不知道是什么的, 自行百度拓展)
// com.alibaba.csp.sentinel.context.ContextUtil类
// 存放线程与 Context 的绑定关系
private static ThreadLocal<Context> contextHolder = new ThreadLocal<>();
如何初始化
Entry对象?
核心概念中已经明确每个 Entry 至少需要包含三大基本属性:名称、请求类型(IN/OUT)和资源类型(如 HTTP、RPC 等), Entry 还需要包含 ProcessorSlot 和 Node。关于 ProcessorSlot 和 Node 的部分后续补充说明, 先看三个基本属性是如何初始化
这三个基本属性中,调用者并没有传递请求类型和资源类型,所以可以这样处理: 为这三个属性分配默认值
比如我们将请求类型默认为 OUT,也就是出口流量;默认将资源类型设置为通用类型,通用类型代表不区分资源,对所有类型的资源都生效
// 初始化 Entry 的基本属性
ResourceWrapper resource = new ResourceWrapper("/hello/world", EntryType.OUT, ResourceTypeConstants.COMMON);
// 放到 Entry 当中
CtEntry entry = new CtEntry(resourceWrapper);
已经有Entry和Context, 如何将Entry 挂到 Context 下?
Entry 的时候就在 Entry 内部设置了一个字段叫 Context,也就是说这个 Entry 属于哪个 Context,因此我们直接通过构造器或者Set方法进行设置即可
// 初始化 Entry 的基本属性
ResourceWrapper resource = new ResourceWrapper("/hello/world", EntryType.OUT, ResourceTypeConstants.COMMON);
// 初始化 Context
Context context = InternalContextUtil.internalEnter("sentinel_default_context");
// 放到 Entry 当中
CtEntry entry = new CtEntry(resourceWrapper, context);
Context源码
下面这行代码就是调用入口
entry = SphU.entry("/hello/world")
源码的逻辑大概如下
将传递过来的 name(/hello/world)当作 Entry 的名称(name),然后默认请求类型为 OUT,最后调用 entryWithPriority 方法,可想而知 entryWithPriority 方法是初始化 Context 等后续逻辑的
// 源码剖析
// 这里的源码时经过改造的, 省略了源码中的重载方法,直接定位到了最终位置
public Entry entry(String name, int count) throws BlockException {
StringResourceWrapper resourceWrapper = new StringResourceWrapper(name, EntryType.OUT);
return entryWithPriority(resourceWrapper, count, false, OBJECTS0);
}
// 实际上的调用流程应该是这样的
// 1. com.alibaba.csp.sentinel.SphU#entry(java.lang.String)
public static Entry entry(String name) throws BlockException {
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}
// 2. com.alibaba.csp.sentinel.CtSph#entry(java.lang.String, com.alibaba.csp.sentinel.EntryType, int, java.lang.Object...)
@Override
public Entry entry(String name, EntryType type, int count, Object... args) throws BlockException {
StringResourceWrapper resource = new StringResourceWrapper(name, type);
return entry(resource, count, args);
}
// 3. com.alibaba.csp.sentinel.CtSph#entry(com.alibaba.csp.sentinel.slotchain.ResourceWrapper, int, java.lang.Object...)
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
return entryWithPriority(resourceWrapper, count, false, args);
}
StringResourceWrapper和默认的资源类型
上述的代码还存在疑惑
- 参数只传递了名称和请求类型,资源类型怎么没传递?
StringResourceWrapper是什么东西?我们之前一直用的是ResourceWrapper呀!
StringResourceWrapper 是 ResourceWrapper 的子类,且StringResourceWrapper 的构造器默认了资源类型为:COMMON
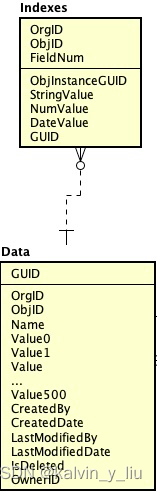
StringResourceWrapper 是 ResourceWrapper 关系图如下

StringResourceWrapper源码如下
// 1. StringResourceWrapper 是 ResourceWrapper 的子类
public class StringResourceWrapper extends ResourceWrapper {
// 2. 调用父类构造器,且默认资源类型为 COMMON
public StringResourceWrapper(String name, EntryType e) {
super(name, e, ResourceTypeConstants.COMMON);
}
// 省略其他代码...
}
entryWithPriority做了什么
StringResourceWrapper调用父类构造器中初始化Entry 的三大基础属性:名称、请求类型、资源类型, 后续调用entryWithPriority 方法进行执行以下操作:
- 初始化 Context
- 将 Context 与线程绑定
- 将
Context和ResourceWrapper都放入Entry中
在创建 Context 之前,首先需要获取已存在的 Context。这意味着要检查当前线程是否已经绑定了 Context,如果已经绑定,则无需再次创建
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 从当前线程中获取Context
Context context = ContextUtil.getContext();
// 如果没获取到 Context,就创建一个名为sentinel_default_context的 Context,并且与当前线程绑定
if (context == null) {
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
// ...... 省略后续动作
}
通过上述代码,我们有如下三个疑问:
- 如何从当前线程中获取 Context?也就是
ContextUtil.getContext()的源码流程。 - 如果当前线程没绑定Context,那么 Context 是如何创建的?也就是
internalEnter()的源码流程。 - 创建完 Context 后,后续流程都有什么?也就是Context创建出来后,然后干什么?
ContextUtil.getContext()源码
// com.alibaba.csp.sentinel.context.ContextUtil
public class ContextUtil {
// 将上下文存储在ThreadLocal中以方便访问, 即存储的是线程和Context的绑定关系
private static ThreadLocal<Context> contextHolder = new ThreadLocal<>();
/**
作用: 从ThreadLocal获取当前线程的Context
返回值: 当前线程的Context。如果当前线程没有Context,将返回Null值
*/
public static Context getContext() {
return contextHolder.get();
}
// 省略其他代码...
}
流程如下
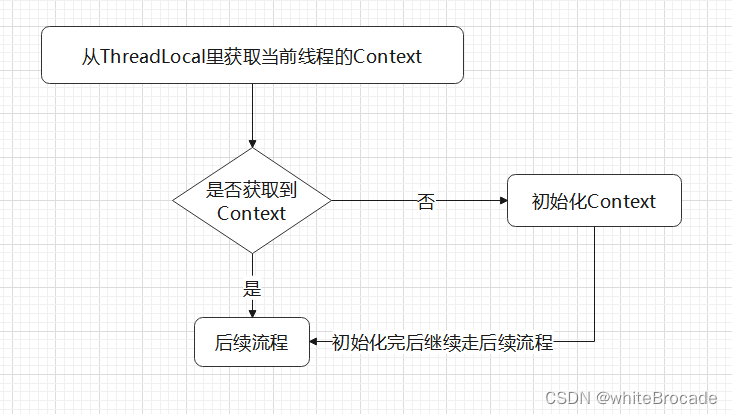
internalEnter()源码
那 ThreadLocal 是何时将 Context 存进去的呢?
肯定是在创建Context的时候,创建完成后就存到ThreadLocal与当前线程进行绑定, 这个流程也就说正要阐述的``internalEnter()`
创建完Context的后续流程都有什么?
- 创建完 Context 之后,需要将其与 Entry 进行绑定
- 初始化一系列的ProcessorSlot
创建完 Context 之后,需要将其与 Entry 进行绑定。即每个资源必须属于一个或多个 Context
在设计 Entry 时,我们已经预留了一个 Context 字段,所以我们可以通过构造器或 Set 方法将其设置:
// 将 Entry 的三个基础属性(resourceWrapper)以及当前 Entry 所属的 Context 都设置好
Entry e = new CtEntry(resourceWrapper, null, context);
在创建 Entry 时需要创建一个责任链 ProcessorSlot,负责采集当前 Entry 的数据以及验证规则, 即还需要初始化一系列的链条
// 初始化责任链链条, 先不用管lookProcessChain里面做了什么东西
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
// 将 Entry 的三大属性以及 Context 以及责任链链条都 set 到 Entry 对象中
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 链条入口,负责采集数据,规则验证
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) { // 规则验证失败,比如:被流控、被熔断降级、触发黑白名单等
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
RecordLog.info("Sentinel unexpected exception", e1);
}
目前为止流程图如下
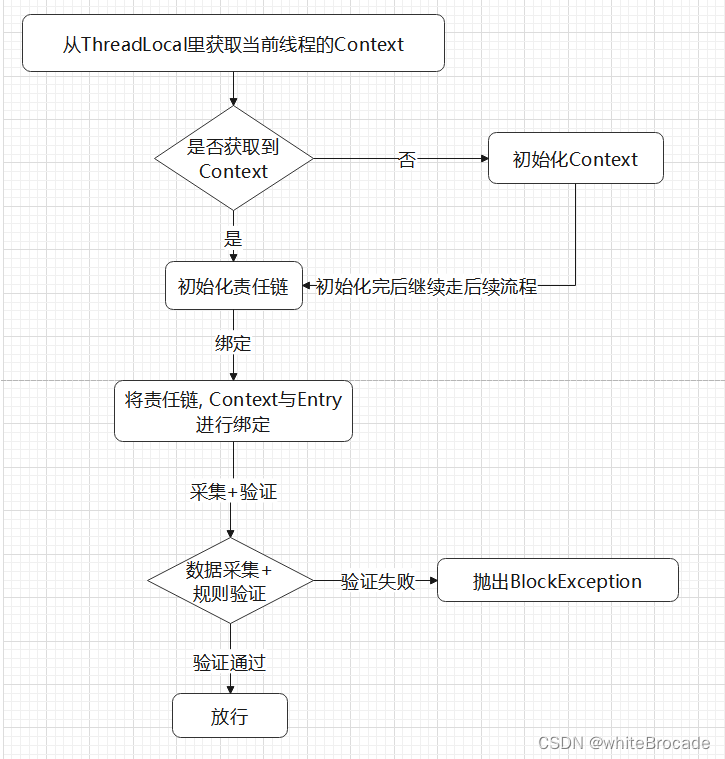
流程对应的源代码如下
// 这个代码是经过简化的, 把非核心的代码进行删除
// sentinel中源码位置为com.alibaba.csp.sentinel.CtSph#entryWithPriority(com.alibaba.csp.sentinel.slotchain.ResourceWrapper, int, boolean, java.lang.Object...)
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 从当前线程中获取Context
Context context = ContextUtil.getContext();
// 如果没获取到 Context,就创建一个名为sentinel_default_context的 Context,并且与当前线程绑定
if (context == null) {
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
// 初始化责任链
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
// 设置 Entry
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 针对资源操作
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) { // 被流控、熔断降级等限制
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
1. 从当前 ThreadLocal 里获取 Context
2. if (没获取到) {
双重检测锁 + 缓存机制创建 Context,且初始化负责收集Context的Node。
将 Context 放到 ThreadLocal 里,与当前请求线程绑定
}
3. 初始化责任链
4. 将责任链、Context 与 Entry 绑定
5. 执行每一个链条的逻辑(数据采集+规则验证)
6. 验证失败抛出 BlockException
总的概括entryWithPriority做了什么:
- 初始化 Context 以及 Entry,
- 然后执行责任链 ProcessorSlot的每一个 Filter 对资源进行数据采集以及规则验证
Context的EntranceNode
Context中含有一个字段Node, Node有一个子类EntranceNode, EntranceNode作用: 负责统计当前 Context 下的指标数据, 即EntranceNode是专门服务于Context的, 那么在创建 Context 之前就需要先把 EntranceNode 给创建好
什么时候创建EntranceNode?
在创建Context之前就需要先把EntranceNode给创建好
EntranceNode如何创建呢?
构造器进行创建, 如下
EntranceNode node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
创建前的非空检查
核心步骤就这么简单,但是存在很多性能和安全问题
出于最基本的安全考虑,在真正创建之前,需要额外检查一下, 例如看看是不是已经创建完了
// 从 ThreadLocal 中获取当前线程绑定的 Context
Context context = contextHolder.get();
// 如果当前 Context 为空,则创建 Context
if (context == null) {
// 创建 Context
} else {
// 如果获取到了 Context,则直接返回
return context;
}
流程如下
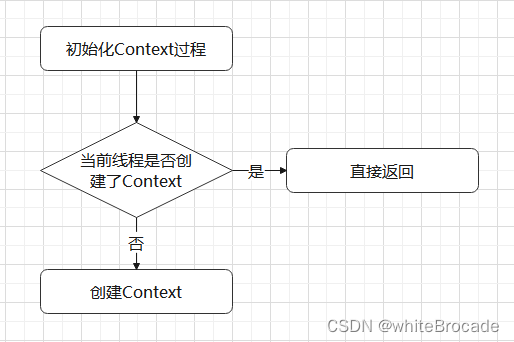
本地缓存优化反复创建
问题: 创建对象的过程是比较消耗资源,我们也知道Context需要EntranceNode,所以在创建 Context 的时候,每次都需要创建一个新的EntranceNode,这会带来很多性能问题
方案: Map本地缓存, 使用一个Map来缓存EntranceNode,以Context的name作为key,EntranceNode作为value, 即Map<String, EntranceNode>,当创建一个新的 Context 时,我们可以先去缓存中查找对应的EntranceNode,如果没有则创建一个新的EntranceNode并加入到缓存中
// 以 Context 的 name 作为 key, EntranceNode 作为 value 缓存到 HashMap 中
private static volatile Map<String, DefaultNode> contextNameNodeMap = new HashMap<>();
// 从缓存获取 EntranceNode
EntranceNode node = contextNameNodeMap.get(name);
// 如果没获取到
if (node == null) {
// 创建 EntranceNode,缓存到 contextNameNodeMap 当中。
}
// 如果获取到了,则直接放到 Context 里即可
上述方案在高并发情况下可以显著减少EntranceNode 的创建,从而提高系统性能和吞吐量。
CopyOnWrite实现读写分离
上述方案也有一些潜在风险,因为contextNameNodeMap 缓存是全局的,且缓存是个HashMap,也就是任何线程都可以修改此缓存,那很可能在我们contextNameNodeMap.get(name)的时候缓存已经被人修改了,例如如果 Context 的 name 被修改或者被删除,就会导致缓存失效。
因此,为了解决这个问题,我们可以先将全局缓存 contextNameNodeMap 赋值给一个临时变量,也就是快照变量,这样就可以保证在操作过程中,不会因为有其他线程修改contextNameNodeMap导致数据不一致的问题。这种做法称为读写分离,是一种常见的并发优化手段,可以提升程序的性能和可靠性
- 这里使用的
读写分离思想实现的, 也称为CopyOnWrite, 常应用于读多写少的情况
// 以 Context 的 name 作为 key, EntranceNode 作为 value 缓存到 HashMap 中
private static volatile Map<String, DefaultNode> contextNameNodeMap = new HashMap<>();
// 将全局缓存 contextNameNodeMap 赋值给一个临时变量 localCacheNameMap
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 用临时变量 localCacheNameMap 获取 EntranceNode
EntranceNode node = localCacheNameMap.get(name);
// 如果没获取到
if (node == null) {
// 创建 EntranceNode,缓存到 contextNameNodeMap 当中。
}
// 将 EntranceNode 放到 Context 里
context = new Context(node, name);
到此为止流程如下
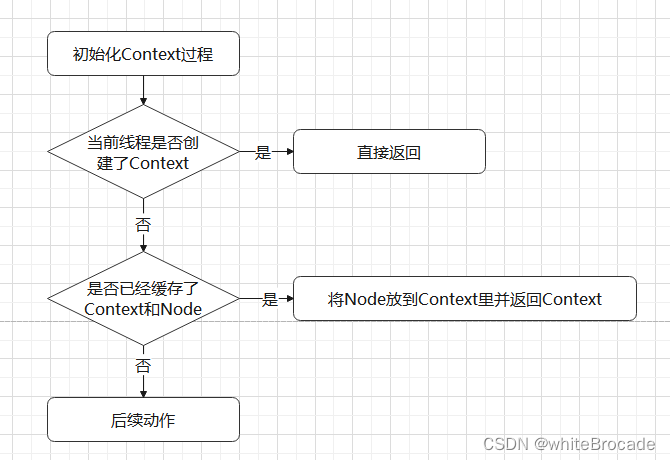
本地缓存Context数量限制
缓存已经实现好了,为了防止缓存无限制地增长,导致内存占用过高,我们需要设置一个上限。只要超过上限,就直接返回一个 NullContext。
private static final Context NULL_CONTEXT = new NullContext();
// 2000阈值, Constants.MAX_CONTEXT_NAME_SIZE=2000
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
// 给当前线程绑定一个 NULL_CONTEXT
contextHolder.set(NULL_CONTEXT);
return NULL_CONTEXT;
}
到此为止流程如下
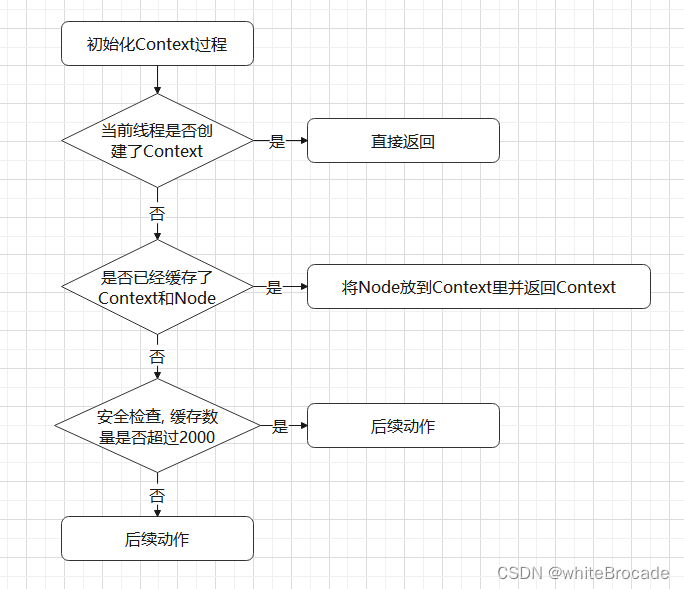
Lock保证线程安全
如果Context还没创建,缓存里也没有当前Context名称对应的EntranceNode,并且缓存数量尚未达到2000,那么就可以创建Node等逻辑了,创建需要加锁,否则有线程不安全问题,因为此方法我们希望只有一个线程在创建,创建完成后就将EntranceNode放到HashMap当中进行缓存。所以需要lock加锁
// 加锁,确保线程安全。当多个线程访问共享资源(如contextNameNodeMap)时,锁可以防止数据竞争和不一致的状态。
// 使用try-finally代码块确保在发生异常时仍能解锁,以防止死锁。
LOCK.lock();
try {
// ...
} finally {
// 解锁
LOCK.unlock();
}
DCL机制保证线程安全
接下来,我们就能在try的逻辑块里创建EntranceNode且放到缓存了,因为try是加锁的,所以创建 EntranceNode和放到缓存的动作是线程安全的。为了安全性,这里需要使用DCL机制
- 因为抢到锁的线程很可能是还没有创建的, 所以必须要再次检查
// 加锁
LOCK.lock();
try {
// 重新从缓存里检查下看看当前 name 是不是被创建了,如果是,则直接返回
node = contextNameNodeMap.get(name);
// 如果缓存里没有node,则创建,但是为了安全起见,我们还需要再次检查缓存数量是不是超过2000的阈值
if (node == null) {
// 为了尽可能的保证线程安全性,我们需要DCL缓存数量是否超过阈值(2000)
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
contextHolder.set(NULL_CONTEXT);
return NULL_CONTEXT;
} else {
// 如果缓存里没有当前 Context name 对应的 EntranceNode,则进行创建以及放到缓存里。
// 通过构造器新建 EntranceNode
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// 将新建的 EntranceNode 添加到 ROOT 中
Constants.ROOT.addChild(node);
// 将新建的EntranceNode添加到缓存中
// 这里也有个很巧妙的设计:创建新的HashMap以实现不可变性:通过创建新的HashMap并替换旧的contextNameNodeMap,可以在一定程度上实现不可变性,从而减少错误和意外更改的风险。
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
} finally {
LOCK.unlock();
}
}
// 返回node
return node;
补充: DCL是一个很常用也很牛的方式,比如如何创建一个线程安全的单例模式?这个问题也可以用 DCL来解决
初始化Context
现在EntranceNode也创建完了,可以说是万事俱备,只欠Context了。我们通过Context的构造器和Set方法来初始化 Context,如下
// node是上述刚创建的EntryNode,name不传会有默认值。前面都讲过。
context = new Context(node, name);
// 默认是空字符串
context.setOrigin(origin);
// 将 Context 放到 ThreadLocal 当中,与当前线程进行绑定。
contextHolder.set(context);
return context;
Context创建源码汇总以及总流程
// com.alibaba.csp.sentinel.context.ContextUtil#trueEnter
protected static Context trueEnter(String name, String origin) {
// 从 ThreadLocal 中获取当前线程绑定的 Context
Context context = contextHolder.get();
// 如果当前线程还没绑定 Context,则进行初始化 Context 并且与当前线程进行绑定
if (context == null) {
// 将全局缓存 contextNameNodeMap 赋值给一个临时变量 localCacheNameMap
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 在缓存中获取 EntranceNode
DefaultNode node = localCacheNameMap.get(name);
// 如果node为空
if (node == null) {
// 为了防止缓存无限制地增长,导致内存占用过高,我们需要设置一个上限。只要超过上限,就直接返回一个 NULL_CONTEXT
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else { // 如果 Context 还没创建,缓存里也没有当前 Context 名称对应的 EntranceNode,并且缓存数量尚未达到 2000,那么就可以创建 Node 等逻辑了,创建需要加锁,否则有线程不安全问题
// 加锁
LOCK.lock();
try {
// 这里两次判断是采用了双重检测锁的机制:为了防止并发带来的线程不安全问题
node = contextNameNodeMap.get(name);
if (node == null) {
// 二次检查,这都是DCL机制
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
// 真正创建 EntranceNode 的步骤
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// 将新建的 EntranceNode 添加到 ROOT 中,ROOT 就是每个 Node 的根结点。
Constants.ROOT.addChild(node);
// 将新建的 EntranceNode 添加到缓存中
// 通过创建新的HashMap并替换旧的,可以规避由于缓存是共享变量带来的线程不安全问题。
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
// 解锁
LOCK.unlock();
}
}
}
// 初始化 Context,将刚创建的 EntranceNode 放到 Context 中
context = new Context(node, name);
context.setOrigin(origin);
// 将 Context 写入到当前线程对应的 ThreadLocal 当中
contextHolder.set(context);
}
// 返回Context
return context;
}
Context创建的完整流程如下
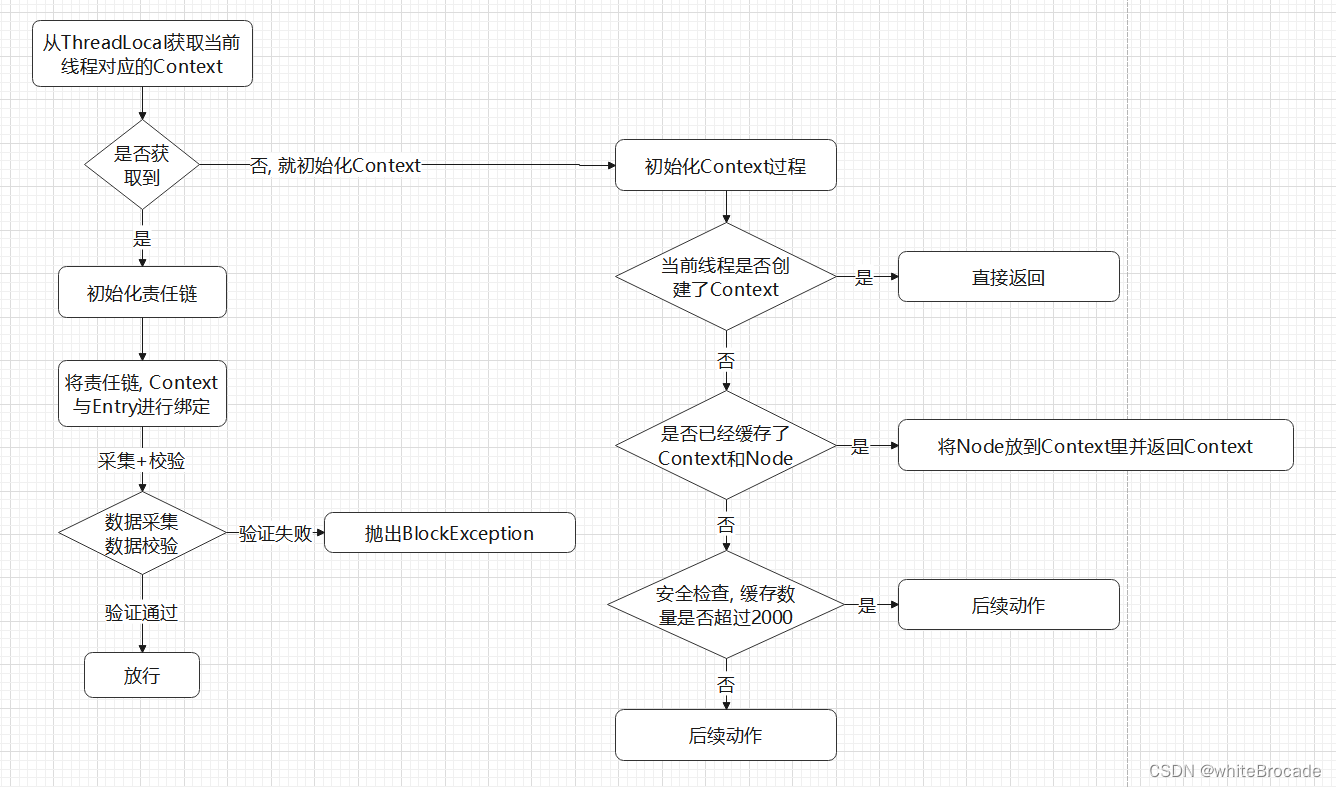
Context涉及到的一些点
- 线程安全:为了确保线程安全,在访问共享资源(如缓存)时使用了
Lock锁机制。这样可以防止多个线程同时修改共享资源,导致数据不一致。 - DCL 机制:在创建新的Context时,使用了
双重检测锁机制。这是一种用于在多线程环境中实现延迟初始化的同步策略,可以避免不必要的同步开销。在本文例子中,先检查缓存中是否存在对应的 Context,如果不存在,则加锁后再次检查。这样可以确保只有一个线程创建新的 Context。 - CopyOnWrite机制更新缓存:在添加新的Context 到缓存时,首先创建一个新的缓存映射,然后将原来的缓存映射的数据复制到新的映射中,最后再将新的Context添加到新映射。这样可以避免在更新缓存时影响其他线程对缓存的访问。
- 控制Context数量:限制可创建的最大Context数量,以避免过多的 Context 对象消耗内存资源。这是一种防御性设计,确保系统在资源受限的情况下能正常运行。
我们用一段话对 Context的知识进行收尾:一个请求对应一个Context,默认情况下,Context的name采用统一的默认值,这意味着许多线程共享一个Context。然而,在某些场景下,我们可能需要根据特定的业务逻辑或需求来自定义Context的name。这样做的好处是可以让我们更加精细地控制和管理不同线程之间的资源访问和隔离。
例如,在一个多租户系统中,为了确保每个租户之间的数据隔离和安全性,可以为每个租户分配一个单独的 Context,通过自定义Context的name实现。
再例如:一个项目中有很多需要流控的接口,我们可以为每个接口都单独分配一个不同name的Context,这样就做到了接口的资源隔离。
参考资料
通关 Sentinel 流量治理框架 - 编程界的小學生