在 C++中注册一个分发的运算符
原文:
pytorch.org/tutorials/advanced/dispatcher.html译者:飞龙
协议:CC BY-NC-SA 4.0
分发器是 PyTorch 的一个内部组件,负责确定在调用诸如torch::add这样的函数时实际运行哪些代码。这可能并不简单,因为 PyTorch 操作需要处理许多“层叠”在彼此之上的交叉关注点。以下是它处理的一些事项的示例:
-
根据输入张量的设备在 CPU 和 CUDA 实现之间切换运算符。
-
在是否需要自动微分处理的情况下,在运算符的自动微分和后端实现之间切换。
-
在需要自动混合精度时应用自动转换。
-
在
vmap调用下运行运算符时应用批处理规则。 -
跟踪操作的执行,如果您正在跟踪一个模型以进行导出。
如果在您的自定义运算符代码中发现自己手动编写 if 语句来处理这些情况,分发器 API 可以帮助组织您的代码。(相反,如果您的自定义运算符非常简单且仅用于 CPU 推断,则可能不需要使用分发器,只需使用基本 API。)
在本教程中,我们将描述如何结构化自定义运算符注册以使用分发器来组织各种组件。我们假设您已经熟悉如何注册运算符以及如何编写自定义自动微分函数。
定义模式和后端实现
分发器背后的一般原则是将运算符的实现分成多个内核,每个内核为特定的分发键实现功能,例如 CPU、CUDA。分发器确定在调用运算符时最高优先级的分发键是什么(这是通过查看张量参数以及一些线程本地状态来完成的),并将控制权转移到该分发键的内核。最终效果是当您调用一个运算符时,我们首先执行自动微分内核,然后根据传入张量的设备类型重新分发到后端内核。
让我们看看使这一切发生所涉及的各个部分。首先,我们必须为所讨论的运算符定义模式。与简单的 pybind11 风格的运算符注册不同,我们此时实际上并没有提供我们运算符的实现;我们只提供一个模式字符串,指定所有其他内核将遵守的运算符类型签名:
TORCH_LIBRARY(myops, m) {
m.def("myadd(Tensor self, Tensor other) -> Tensor");
}
接下来,我们需要实际提供一些这个运算符的实现。具体来说,这是一个在 CPU 上进行加法的非常简单的实现:
Tensor myadd_cpu(const Tensor& self_, const Tensor& other_) {
TORCH_CHECK(self_.sizes() == other_.sizes());
TORCH_INTERNAL_ASSERT(self_.device().type() == DeviceType::CPU);
TORCH_INTERNAL_ASSERT(other_.device().type() == DeviceType::CPU);
Tensor self = self_.contiguous();
Tensor other = other_.contiguous();
Tensor result = torch::empty(self.sizes(), self.options());
const float* self_ptr = self.data_ptr<float>();
const float* other_ptr = other.data_ptr<float>();
float* result_ptr = result.data_ptr<float>();
for (int64_t i = 0; i < result.numel(); i++) {
result_ptr[i] = self_ptr[i] + other_ptr[i];
}
return result;
}
我们想要将这个函数注册为myops::myadd的实现。然而,简单的注册方式(def("myadd", myadd_cpu))会注册内核在所有情况下运行,即使张量不是 CPU 张量!(在内部,我们将这些称为“全能”内核,因为它们涵盖所有情况。)为了确保myadd_cpu仅在 CPU 张量上运行,我们可以使用TORCH_LIBRARY_IMPL宏:
TORCH_LIBRARY_IMPL(myops, CPU, m) {
m.impl("myadd", myadd_cpu);
}
TORCH_LIBRARY_IMPL让我们为特定分发键(在本例中为 CPU)上的运算符注册实现。每次调用impl都会将 CPU 内核与相应的运算符关联起来(我们之前在TORCH_LIBRARY块中定义)。如果我们还有一个 CUDA 实现myadd_cuda,我们可以在单独的TORCH_LIBRARY_IMPL块中注册它:
TORCH_LIBRARY_IMPL(myops, CUDA, m) {
m.impl("myadd", myadd_cuda);
}
这些注册可以跨文件或甚至跨库边界拆分;例如,您可以将这两个TORCH_LIBRARY_IMPL块编译到单独的myops_cpu和myops_cuda动态库中。一般来说,您的注册结构将如下所示:
-
一个单独的
TORCH_LIBRARY,列出您命名空间中的每个自定义操作符,集中在一个地方。 -
每个调度键注册一个
TORCH_LIBRARY_IMPL,为该键(例如,CPU 或 CUDA)注册实现。如果愿意,您还可以将TORCH_LIBRARY_IMPL块进一步细分为每个操作符的块。如果您有一个单独的文件用于每个操作符的实现,但不想在头文件中公开这些操作符,您可以将注册放在定义操作符的 cpp 文件中。
注意
您知道吗,您还可以为 PyTorch 中现有核心操作符编写TORCH_LIBRARY_IMPL块吗?这就是 PyTorch 对 XLA 的支持是如何实现的:torch_xla库包含一个TORCH_LIBRARY_IMPL,为 XLA 调度键上的所有基本操作符提供实现。
对于不需要自动求导的操作符
注意:此部分仅适用于 PyTorch 版本>= 1.10。
在下一节中,我们将讨论如何为操作符添加自动求导支持。但对于不需要自动求导支持的操作符,应注册以下内核以提高可用性,并使您的操作符的行为类似于 PyTorch 的内置操作符。
TORCH_LIBRARY_IMPL(myops, Autograd, m) {
m.impl(op, autogradNotImplementedFallback());
}
上面的代码注册了一个Autograd内核,该内核在前向传播时附加一个虚拟的NotImplemented节点(保留输入的require_grad属性)。在反向传播中,NotImplemented节点会引发错误。在较大模型中进行调试时,这可能有助于确定在前向传播过程中确切丢失requires_grad属性的位置。
原地或视图操作
为确保正确性和最佳性能,如果您的操作在原地更改输入或返回一个与输入之一别名的张量,则应采取两个额外步骤:
- 除了上面的
Autograd内核外,还注册一个ADInplaceOrView内核。该内核处理必要的记录工作,以确保原地或视图操作的正确性。重要的是要注意,此 ADInplaceOrView 内核应仅与autogradNotImplementedFallback一起使用。
TORCH_LIBRARY_IMPL(myops, Autograd, m) {
m.impl(op, autogradNotImplementedFallback());
}
TORCH_LIBRARY_IMPL(myops, ADInplaceOrView, m) {
m.impl(op, autogradNotImplementedInplaceOrViewFallback());
}
- 上面注册的
Autograd或ADInplaceOrView封装的内核依赖于其逻辑中的运算符模式信息。如果您的操作在原地对输入进行了更改,或者返回一个与输入之一别名的张量,那么确保您的模式正确反映这一点非常重要。请参阅此处以获取有关如何注释模式的更多信息。
添加自动求导支持
到目前为止,我们有一个既有 CPU 实现又有 CUDA 实现的操作符。我们如何为其添加自动求导支持?正如您可能猜到的那样,我们将注册一个自动求导内核(类似于自定义自动求导函数教程中描述的内容)!但是,有一个转折:与 CPU 和 CUDA 内核不同,自动求导内核需要重新调度:它需要回调到调度程序以获取推断内核,例如 CPU 或 CUDA 实现。
因此,在编写自动求导内核之前,让我们编写一个调度函数,该函数调用调度程序以找到适合您操作符的正确内核。这个函数构成了您操作符的公共 C++ API - 实际上,PyTorch 的 C++ API 中的所有张量函数都在底层以相同的方式调用调度程序。调度函数如下所示:
Tensor myadd(const Tensor& self, const Tensor& other) {
static auto op = torch::Dispatcher::singleton()
.findSchemaOrThrow("myops::myadd", "")
.typed<decltype(myadd)>();
return op.call(self, other);
}
让我们来详细了解一下:
-
在第一行中,我们从调度程序中查找与我们要分派的运算符对应的类型化运算符句柄。
findSchemaOrThrow接受两个参数:运算符的(命名空间限定的)名称和运算符的重载名称(通常为空字符串)。typed将动态类型的句柄转换为静态类型的句柄(进行运行时测试以确保您提供了正确的 C++类型),以便我们可以对其进行正常的 C++调用。我们传递decltype(myadd),因为分派函数的类型与注册到调度程序的基础内核的类型相同。为了性能,此计算是在静态变量中完成的,因此我们只需要进行一次(慢速)查找。如果您拼错了要调用的运算符的名称,那么在第一次调用此函数时,此查找将出错。
-
在第二行中,我们简单地使用传递给分派函数的所有参数“调用”运算符句柄。这将实际调用调度程序,最终控制将转移到适用于此调用的任何内核。
有了分派函数,我们现在可以编写自动微分内核了:
class MyAddFunction : public torch::autograd::Function<MyAddFunction> {
public:
static Tensor forward(
AutogradContext *ctx, torch::Tensor self, torch::Tensor other) {
at::AutoNonVariableTypeMode g;
return myadd(self, other);
}
static tensor_list backward(AutogradContext *ctx, tensor_list grad_outputs) {
auto grad_output = grad_outputs[0];
return {grad_output, grad_output};
}
};
Tensor myadd_autograd(const Tensor& self, const Tensor& other) {
return MyAddFunction::apply(self, other)[0];
}
自动微分函数是使用torch::autograd::Function正常编写的,只是在forward()中不直接编写实现,而是:
-
使用
at::AutoNonVariableTypeModeRAII 保护关闭自动微分处理,然后 -
调用分派函数
myadd以回调到调度程序。
没有(1),您的调用将无限循环(并堆栈溢出),因为myadd将将您发送回此函数(因为最高优先级的调度键仍然是自动微分)。有了(1),自动微分将从考虑的调度键集合中排除,我们将转到下一个处理程序,这将是 CPU 和 CUDA。
我们现在可以以与注册 CPU/CUDA 函数相同的方式注册此函数:
TORCH_LIBRARY_IMPL(myops, Autograd, m) {
m.impl("myadd", myadd_autograd);
}
注意
在此示例中,我们将内核注册到Autograd,这将将其安装为所有后端的自动微分内核。您还可以通过使用相应的特定于后端的调度键(例如AutogradCPU或AutogradCUDA)为特定后端注册优化内核。要更详细地探索这些和其他调度键选项,请查看torch/_python_dispatcher.py中提供的PythonDispatcher工具。
超越自动微分
在某种意义上,调度程序并没有做太多事情:它只是实现了一个类似于这样的 if 语句:
class MyAddFunction : ... {
public:
static Tensor forward(
AutogradContext *ctx, torch::Tensor self, torch::Tensor other) {
if (self.device().type() == DeviceType::CPU) {
return add_cpu(self, other);
} else if (self.device().type() == DeviceType::CUDA) {
return add_cuda(self, other);
} else {
TORCH_CHECK(0, "Unsupported device ", self.device().type());
}
}
...
}
为什么要使用调度程序?有几个原因:
-
它是分散的。您可以组装运算符的所有部分(CPU、CUDA、Autograd)而无需编写一个引用所有这些部分的单个集中 if 语句。重要的是,第三方可以注册其他方面的额外实现,而无需修补运算符的原始定义。我们将在扩展调度程序以支持新后端中更多地讨论扩展调度程序。
-
它支持比 CPU、CUDA 和 Autograd 更多的调度键。您可以在 PyTorch 中当前实现的
c10/core/DispatchKey.h中看到当前实现的所有调度键的完整列表。这些调度键为运算符实现了各种可选功能,如果您决定希望您的自定义运算符支持此功能,您只需为适当的键注册一个内核。 -
调度程序实现了对装箱回退函数的支持,这些函数可以一次实现并应用于系统中的所有运算符。装箱回退可用于为调度键提供默认行为;如果您使用调度程序来实现您的运算符,您还可以选择为所有这些操作启用回退。
以下是一些您可能需要为其定义运算符的特定调度键。
自动转换
Autocast 分派键实现了对自动混合精度(AMP)的支持。自动转换包装器内核通常会将传入的float16或float32 CUDA 张量转换为某种首选精度,然后运行操作。例如,在浮点 CUDA 张量上运行的矩阵乘法和卷积通常在float16中运行更快,使用更少的内存,而不会影响收敛。自动转换包装器仅在启用自动转换的上下文中起作用。
以下是一个假设的自定义矩阵乘法的自动转换包装器,以及其注册:
// Autocast-specific helper functions
#include <ATen/autocast_mode.h>
Tensor mymatmul_autocast(const Tensor& self, const Tensor& other) {
c10::impl::ExcludeDispatchKeyGuard no_autocast(c10::DispatchKey::Autocast);
return mymatmul(at::autocast::cached_cast(at::kHalf, self),
at::autocast::cached_cast(at::kHalf, other));
}
TORCH_LIBRARY_IMPL(myops, Autocast, m) {
m.impl("mymatmul", mymatmul_autocast);
}
cached_cast(kHalf, tensor)将tensor转换为float16,如果tensor是 CUDA 且为float32,否则将tensor保持不变(参见natively autocasted ops 的资格政策)。这确保了如果网络在任何混合float16和float32 CUDA 张量上调用mymatmul,mymatmul将以float16运行。同时,对于非 CUDA、整数类型或float64输入的mymatmul调用不受影响。建议在自己的自动转换包装器中使用cached_cast遵循本机资格政策,但不是必需的。例如,如果您想要强制所有输入类型执行float16,您可以使用return mymatmul(self.half(), other.half());而不是使用cached_cast。
请注意,与我们的自动求导内核一样,在重新分派之前,我们将Autocast键排除在分派之外。
默认情况下,如果没有提供自动转换包装器,我们将直接转到常规操作员实现(不会发生自动转换)。(我们没有在此示例中使用myadd,因为逐点加法不需要自动转换,应该直接通过。)
何时应注册自动转换包装器?不幸的是,没有关于操作首选精度的明确规则。您可以通过查看cast lists来了解一些本机操作的首选精度。一般指导:
-
执行减少的操作可能应该以
float32执行, -
在底层执行卷积或 gemm 的任何操作可能应该以
float16执行, -
具有多个浮点张量输入的其他操作应将它们标准化为公共精度(除非实现支持具有不同精度的输入)。
如果您的自定义操作属于第三类别,则promote_type模板有助于确定输入张量中存在的最宽浮点类型,这是执行类型的最安全选择:
#include <ATen/autocast_mode.h>
Tensor my_multiple_input_op_autocast(const Tensor& t0, const Tensor& t1) {
c10::impl::ExcludeDispatchKeyGuard no_autocast(c10::DispatchKey::Autocast);
// The required at::kHalf argument is an optimistic initial guess.
auto exec_type = at::autocast::promote_type(at::kHalf, t0, t1);
return my_multiple_input_op(at::autocast::cached_cast(exec_type, t0),
at::autocast::cached_cast(exec_type, t1));
}
如果您的自定义操作是自动求导启用的,您只需要为与自动求导包装器注册的相同名称编写并注册一个自动转换包装器。例如,如果您想要一个myadd函数的自动转换包装器,只需
Tensor myadd_autocast(const Tensor& self, const Tensor& other) {
c10::impl::ExcludeDispatchKeyGuard no_autocast(c10::DispatchKey::Autocast);
return myadd(at::autocast::cached_cast(<desired dtype>, self),
at::autocast::cached_cast(<desired dtype>, other));
}
TORCH_LIBRARY_IMPL(myops, Autocast, m) {
m.impl("myadd", myadd_autocast);
}
没有单独的技巧使得反向方法与自动转换兼容。但是,您自定义的自动求导函数中定义的反向方法将以与自动转换为前向方法设置的相同 dtype 运行,因此您应该选择一个适合您的前向和反向方法的<desired dtype>。
批处理
批处理张量允许您以每个示例的方式编写代码,然后在vmap调用下运行时自动批处理它们。编写批处理规则的 API 目前正在开发中,但一旦稳定下来,您可以通过在批处理分派键上注册一个内核来为您的操作添加对vmap的支持。
追踪器
追踪器分派键实现了在运行torch.jit.trace时将操作调用记录到跟踪中的支持。我们打算提供一个包装回退,用于实现任意操作的跟踪,参见issue#41478以跟踪进展。
在 C++中为新后端扩展调度程序
原文:
pytorch.org/tutorials/advanced/extend_dispatcher.html译者:飞龙
协议:CC BY-NC-SA 4.0
在本教程中,我们将逐步介绍扩展调度程序的所有必要步骤,以添加一个位于pytorch/pytorch存储库之外的新设备,并保持与原生 PyTorch 设备同步。在这里,我们假设您熟悉如何在 C++中注册调度运算符以及如何编写自定义自动微分函数。
注意
本教程涉及 PyTorch 内部许多正在积极改进的组件,请在决定跟随本教程时预期 API 的更改。我们将保持本教程与最新的 API 保持同步。
什么是新后端?
向 PyTorch 添加一个新后端需要来自后端扩展者的大量开发和维护。在添加新后端之前,让我们首先考虑一些常见用例和推荐的解决方案:
-
如果您有现有 PyTorch 运算符的新算法,请向 PyTorch 发送一个 PR。
-
如果您想提出一个新的运算符,请向 PyTorch 发送一个功能请求/PR。
-
如果您想为新设备/硬件(如 Google TPU 和定制芯片)添加支持,通常需要使用特定于硬件的 API 来编写内核,请按照本教程并向 PyTorch 添加一个树外后端。
-
如果您想为现有运算符添加支持,但使用不同的张量布局/表示,如稀疏和量化,这将强制您的内核以更有效的方式编写,考虑到布局/表示限制,请按照本教程并向 PyTorch 添加一个树外后端。
在本教程中,我们将主要关注添加一个新的树外设备。为不同张量布局添加树外支持可能与设备共享许多常见步骤,但我们尚未看到这种集成的示例,因此可能需要 PyTorch 进行额外的工作来支持它。
为您的后端获取一个调度键
PyTorch 运算符是用 C++实现的,并通过 Python 绑定在 Python 前端中提供。PyTorch 调度程序将运算符的实现分为多个内核,每个内核与特定的调度键相关联。在 PyTorch 中支持一个新后端基本上意味着为 C++中的每个 PyTorch 运算符编写一个内核,然后将它们注册到调度程序中代表您定制后端的调度键。
调度键是调度系统中的标识符。调度程序查看输入张量上携带的调度键,并相应地调用正确的内核。PyTorch 为原型化树外后端扩展提供了三个预留的调度键(以及它们对应的 Autograd 键):
-
PrivateUse1/AutogradPrivateUse1
-
PrivateUse2/AutogradPrivateUse2
-
PrivateUse3/AutogradPrivateUse3
您可以选择上述任何键来原型化您的定制后端。要在PrivateUse1后端上创建一个张量,您需要在TensorImpl构造函数中设置调度键。
/* Example TensorImpl constructor */
TensorImpl(
Storage&& storage,
DispatchKeySet ks,
const caffe2::TypeMeta data_type);
// To create a TensorImpl on PrivateUse1 backend, pass in the following ks to TensorImpl creation.
DispatchKeySet ks = c10::DispatchKeySet{c10::DispatchKey::PrivateUse1, c10::DispatchKey::AutogradPrivateUse1};
请注意,上面的TensorImpl类假定您的张量由类似 CPU/CUDA 的存储支持。我们还提供了OpaqueTensorImpl,用于没有存储的后端。您可能需要调整/覆盖某些方法以适应您的定制硬件。PyTorch 存储库中的一个示例是Vulkan TensorImpl。
注意
一旦原型完成,并且您计划为您的后端扩展进行定期发布,请随时向pytorch/pytorch提交一个 PR,以保留一个专用的调度键给您的后端。
获取 PyTorch 运算符的完整列表
PyTorch 提供了一个生成文件build/aten/src/ATen/RegistrationDeclarations.h中的可扩展 C++运算符的完整列表。此文件仅在从源代码构建 PyTorch 后才可用。以下是文件的一部分:
Tensor abs(const Tensor & self); // {"schema": "aten::abs(Tensor self) -> Tensor", "dispatch": "True", "default": "True"}
Tensor & abs_(Tensor & self); // {"schema": "aten::abs_(Tensor(a!) self) -> Tensor(a!)", "dispatch": "True", "default": "True"}
Tensor & abs_out(Tensor & out, const Tensor & self); // {"schema": "aten::abs.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)", "dispatch": "True", "default": "False"}
Tensor absolute(const Tensor & self); // {"schema": "aten::absolute(Tensor self) -> Tensor", "dispatch": "False", "default": "False"}
Tensor & absolute_(Tensor & self); // {"schema": "aten::absolute_(Tensor(a!) self) -> Tensor(a!)", "dispatch": "False", "default": "False"}
Tensor & absolute_out(Tensor & out, const Tensor & self); // {"schema": "aten::absolute.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)", "dispatch": "False", "default": "False"}
Tensor angle(const Tensor & self); // {"schema": "aten::angle(Tensor self) -> Tensor", "dispatch": "True", "default": "True"}
Tensor & angle_out(Tensor & out, const Tensor & self); // {"schema": "aten::angle.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)", "dispatch": "True", "default": "False"}
Tensor sgn(const Tensor & self); // {"schema": "aten::sgn(Tensor self) -> Tensor", "dispatch": "True", "default": "True"}
与单个运算符相关联的多个字段。让我们以 abs_out 为例进行详细说明:
-
Tensor & abs_out(Tensor & out, const Tensor & self);是运算符的 C++ 签名,您的 C++ 内核应该与此签名完全匹配。 -
aten::abs.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)是表示运算符的唯一模式,与 C++ 签名相比,还包含别名和突变注释。这是调度器用来查找运算符的唯一标识符。 -
dispatch和default是布尔字段,提供了关于原生 PyTorch 内核能够做什么的信息,因此暗示了是否需要后端扩展者实现该内核。更多细节可以在 为新后端注册内核 中找到。
为新后端注册内核
要将您的内核注册到 PyTorch 调度器中,您可以使用 在 C++ 中注册分发运算符 中描述的 TORCH_LIBRARY_IMPL API:
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
m.impl(<schema_my_op1>, &my_op1);
m.impl(<schema_my_op2>, &my_op2);
m.impl(<schema_my_op2_backward>, &my_op2_backward);
}
现在让我们深入了解哪些运算符需要来自定制后端的内核以及这些内核的具体内容。
PyTorch 目前有超过 1600 个运算符,而且仍在增长。对于后端扩展来说,跟上这种速度是不现实的。即使对于像 CPU 或 CUDA 这样的原生后端,通常也需要大量工作为每个新运算符编写专用内核。
幸运的是,一些原生 PyTorch 内核是以一种方式编写的,它们分解为几个已知运算符的组合。换句话说,您只需要实现一组已知运算符(下面需要注册的运算符)而不是所有 PyTorch 运算符。
PyTorch 运算符可以分为两类:
-
需要注册的运算符:这些运算符的 PyTorch 原生实现是特定于后端的,因此需要为定制后端提供内核。否则,在定制后端上调用此类运算符将导致错误。
- 在
RegistrationDeclarations.h中,这些运算符在其附带的注释中的元数据中,dispatch设置为 True 并且default设置为 False。
- 在
-
注册是可选的:后端扩展者可以跳过为这些操作注册而不会牺牲任何支持。然而,如果后端扩展者想要覆盖 PyTorch 提供的默认内核,他们仍然可以将他们定制的内核注册到他们的后端,调度器将仅在您的后端中使用它。例如,PyTorch 的
max_pool2d的当前实现返回indices作为前向输出的一部分,这在 torch_xla 中创建了开销,因此 torch_xla 为max_pool2d注册了自己的内核。- 在
RegistrationDeclarations.h中,这些运算符在其附带的注释中的元数据中,dispatch设置为 False 或default设置为 True。
- 在
新后端的自动求导支持
梯度公式大多是纯数学的,因此对于所有后端都是通用的。PyTorch 经常注册一个用于别名调度键 Autograd 的内核,这意味着它可以被所有后端使用。
对于这些运算符,您不必担心它们的导数公式,您只需在 RegistrationDeclarations.h 中为运算符编写前向定义,PyTorch 将自动为您处理后向。
Tensor my_op1(const Tensor& self, const Tensor& other) {
// call your backend-specific APIs to implement my_op so that
// it matches PyTorch's native behavior
}
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
m.impl(<schema_my_op1>, &my_op);
}
在某些情况下,PyTorch 的反向内核实现也是特定于设备的,以便从每个后端中挤出最大性能。对于这些运算符,您将在 RegistrationDeclarations.h 中看到 op_backward 出现为 必需注册。
Tensor my_op2_backward(const Tensor& self, const Tensor& other) {
// call your backend-specific APIs to implement my_op2_backward so that
// it matches PyTorch's native behavior
}
// Note backward kernel is still registered to PrivateUse1 instead of AutogradPrivateUse1.
// PyTorch will wrap your backward kernel with proper autograd setup and then link to it in
// my_op2's AutogradPrivateUse1 kernel.
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
m.impl(<schema_my_op2>, &my_op2);
m.impl(<schema_my_op2_backward>, &my_op2_backward);
}
在一些 罕见 情况下,PyTorch 对于某些运算符的梯度公式可能有不适用于所有后端的假设。在这些情况下,后端扩展者可以选择通过将来自 torch::autograd::Function 的内核注册到相应的调度键(例如,如果您的后端使用 PrivateUse1,则为 AutogradPrivateUse1)来覆盖 PyTorch 的 Autograd 层:
class MyAddFunction : public torch::autograd::Function<MyAddFunction> {
public:
static Tensor forward(AutogradContext *ctx, torch::Tensor self, torch::Tensor other) {
at::AutoNonVariableTypeMode g;
return myadd(self, other);
}
static tensor_list backward(AutogradContext *ctx, tensor_list grad_outputs) {
auto grad_output = grad_outputs[0];
return {grad_output, grad_output};
}
};
Tensor myadd_autograd(const Tensor& self, const Tensor& other) {
return MyAddFunction::apply(self, other)[0];
}
// Register the autograd kernel to AutogradPrivateUse1
TORCH_LIBRARY_IMPL(aten, AutogradPrivateUse1, m) {
m.impl(<myadd_schema>, &myadd_autograd);
}
// Register the inference kernel to PrivateUse1
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
m.impl(<myadd_schema>, &myadd);
}
通过这种技巧,您可以完全控制后端中my_add运算符的训练和推理行为。这里是pytorch/xla存储库中的一个示例。
构建扩展
通过向 PyTorch 添加 C++扩展来支持外部后端。一旦您准备好内核和注册,您可以通过编写一个使用setuptools编译 C++代码的setup.py脚本来构建 C++扩展。以下是来自pytorch/xla 存储库的一个简化示例:
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CppExtension
setup(
name='torch_xla',
ext_modules=[
CppExtension(
'_XLAC',
torch_xla_sources,
include_dirs=include_dirs,
extra_compile_args=extra_compile_args,
library_dirs=library_dirs,
extra_link_args=extra_link_args + \
[make_relative_rpath('torch_xla/lib')],
),
],
cmdclass={
'build_ext': Build, # Build is a derived class of BuildExtension
}
# more configs...
)
有关更多详细信息,请参阅我们的 C++扩展教程。
自定义运算符支持
您的新后端应该与在 Python 中扩展的自定义运算符无缝配合,而无需编写任何新的内核,只要自定义运算符由现有 PyTorch 运算符组成(这些运算符已受到您的后端支持)。
对于在 C++中扩展的自定义运算符,它们通常带有后端特定的 C++内核实现,例如 torchvsion 中的 nms 内核,以及自定义的 Python API,例如 torch.ops.torchvision.nms。为了支持这些运算符,后端扩展者需要为您的后端编写一个 C++内核,并将其正确注册到分发器中的相应命名空间,类似于支持 PyTorch 原生运算符。或者,您还可以在您的扩展中添加一个自定义 API,例如torch_xla.core.functions.nms,以满足这些临时请求。
JIT 支持
正如我们在在 C++中注册分发运算符中提到的,通过 m.impl() API 注册的内核支持以未装箱和装箱方式调用。换句话说,您的定制后端也可以与我们的 JIT 跟踪/脚本前端一起工作,就像树内后端(如 CPU 或 CUDA)一样。您还可以为 JIT 图编写专门的优化传递,但我们不会在这里讨论,因为我们尚未确定 JIT 中的集成点,因此当前后端支持将重点放在急切的前端上。
针对原生 PyTorch 后端进行测试
PyTorch 允许使用其通用设备类型测试框架在多种设备类型上运行测试。您可以在测试如何使用它以及如何添加新设备类型方面找到详细信息。一旦添加,使用通用设备类型测试框架的 PyTorch 测试也将使用您的设备类型运行。查看此 Wiki 页面以了解测试如何实例化的示例。
使用您的设备类型运行 PyTorch 现有的测试套件非常重要,以确保正确性,但并非所有 PyTorch 功能都受到每种设备类型的支持。通用设备类型测试框架允许进行相当大的定制,以便设备类型可以选择运行哪些测试,支持哪些数据类型,甚至在比较张量相等性时使用哪些精度。
使用通用设备类型测试框架并且不随 PyTorch 一起提供的示例设备类型是 XLA。请参阅其对通用设备类型测试框架的扩展,其中包含了测试块列表、数据类型块列表和覆盖测试精度的示例。
通用设备类型测试框架正在积极开发中。要请求功能,请在 PyTorch 的 Github 上提交问题。
向后兼容性
目前,PyTorch 无法保证已注册运算符的向后兼容性。运算符及其模式可能会根据需要进行添加/修改/删除。注册的内核必须与 PyTorch 版本完全相同。如果 PyTorch 为运算符添加更多参数(即使有默认值),您的旧注册将无法工作,直到更新以匹配 PyTorch 的新签名为止。
因此,我们强烈建议独立存储后端扩展器仅与主要的 PyTorch 发布同步,以最大程度地减少开发中的中断。PyTorch 按季度发布。后端扩展器应该加入 #announcement 频道,以获取有关发布的最新更新。
已知问题和其他说明
-
并非所有测试套件都是设备通用的。可以通过在 PyTorch 代码库中搜索
instantiate_device_type_tests来找到可扩展的测试类,例如TestTorchDeviceType, TestViewOps, TestTensorDeviceOps, TestTypePromotion等。 -
在 C++ 中没有扩展点用于在自定义后端上序列化 Python 张量对象。目前,您只能通过修改 PyTorch 张量 reduce_ex 方法 或在独立存储库中进行 monkey patching 来扩展它。
-
如果您的后端不允许直接访问内存,则应特别注意支持视图操作,因为它们应该共享存储。对视图张量的更改需要传播到其基张量,反之亦然。
-
如果您的后端无法与原生 PyTorch 优化器一起使用,则在 C++ 中没有优化器的扩展点,例如需要在向后传递时携带状态以更新像 torch-xla 这样的优化器。目前,这种用例只能通过添加自定义 API 或在独立存储库中进行 monkey patching 来实现。
未来工作
使 PyTorch 中的每个组件都对于独立存储后端无缝扩展需要对 PyTorch 内部进行大量更改。以下是我们正在积极努力改进的一些项目,可能会在未来改善体验:
-
改进通用测试框架的测试覆盖率。
-
改进
Math内核覆盖率和更全面的测试,以确保Math内核行为与其他后端(如CPU/CUDA)匹配。 -
重构
RegistrationDeclarations.h,尽可能携带最少的信息并重复使用 PyTorch 的代码生成。 -
支持后端回退内核,自动将输入转换为 CPU 并将结果转换回自定义后端。这将允许“完整”运算符覆盖,即使您没有为每个运算符编写内核。
保持联系
请使用 PyTorch 开发讨论 进行问题和讨论。如果您有任何功能请求或错误报告,请在 github 上提交问题(https://github.com/pytorch/pytorch/issues)。
如果您有兴趣帮助上述任何未来工作项目(例如在 C++ 中为 PyTorch 运算符添加更多 Math 内核),请通过 Github 或 Slack 与我们联系!
通过 PrivateUse1 促进新后端集成
原文:
pytorch.org/tutorials/advanced/privateuseone.html译者:飞龙
协议:CC BY-NC-SA 4.0
在本教程中,我们将逐步介绍通过PrivateUse1将存放在pytorch/pytorch存储库之外的新后端集成的一些必要步骤。请注意,本教程假定您已经对 PyTorch 有基本的了解,您是 PyTorch 的高级用户。
注意
本教程仅涉及与 PrivateUse1 机制相关的部分,以促进新设备的集成,其他部分将不予涵盖。同时,并非所有本教程涉及的模块都是必需的,您可以根据实际需求选择对您有帮助的模块。
PrivateUse1 是什么?
在 Pytorch 2.0 之前,PyTorch 为原型外后端扩展提供了三个保留的调度键(及其对应的 Autograd 键),这三个调度键如下:
-
PrivateUse1/AutogradPrivateUse1 -
PrivateUse2/AutogradPrivateUse2 -
PrivateUse3/AutogradPrivateUse3
原型验证通过后,可以申请新后端的私钥,如 CUDA、XLA、MPS 等。
然而,随着 PyTorch 的快速发展,越来越多的硬件制造商尝试将他们的后端集成到 PyTorch 中,这可能会引发以下问题:
-
每个新后端集成都涉及大量文件修改
-
目前对调度键数量(DispatchKeySet 64 位限制)有硬性限制
注意
通过 PrivateUse1 Key 将新后端集成到 PyTorch 中也存在问题,因为不可能同时集成多个后端。幸运的是,这些原型外后端很少同时使用。
鉴于上述原因,社区开始建议通过PrivateUse1将新后端集成到 PyTorch 中。
然而,之前的PrivateUse1机制并不能完全与新后端集成,因为在某些模块中缺乏相关支持,如 Storage、AMP、Distributed 等。
随着 Pytorch 2.1.0 的到来,针对PrivateUse1的一系列优化和增强已经针对新后端集成进行了,现在可以快速高效地支持新设备的集成。
如何通过 PrivateUse1 集成新后端
在本节中,我们将讨论通过PrivateUse1将新后端集成到 Pytorch 中的细节,主要包括以下部分:
-
为新后端注册内核。
-
为新后端注册生成器。
-
为新后端注册设备保护。
-
为新后端元数据注册序列化和反序列化函数。
-
其他模块。
为新后端注册内核
新后端可能具有一些高性能的运算符实现,可以通过TORCH_LIBRARY_IMPL API 在 Registering a Dispatched Operator in C++中描述的方式注册到调度程序。这涉及几种情况:
- 为新后端支持的所有前向运算符注册到调度程序,并同时注册回退,以便当新后端不支持某些运算符时,这些运算符可以回退到 CPU 执行,以确保功能的可用性。
at::Tensor wrapper_Custom_Tensor_add(const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {
// Implementation of add kernel in new backend
...
}
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
...
m.impl("add.Tensor", TORCH_FN(wrapper_Custom_Tensor_add));
...
}
void custom_cpu_fallback(const c10::OperatorHandle& op, torch::jit::Stack* stack) {
// Add some hints about new devices that do not support and need to fall back to cpu
at::native::cpu_fallback(op, stack);
}
TORCH_LIBRARY_IMPL(_, PrivateUse1, m) {
m.fallback(torch::CppFunction::makeFromBoxedFunction<&custom_cpu_fallback>());
}
- 如果新后端需要覆盖
PyTorch Autograd layer,则通过AutogradPrivateUse1将torch::autograd::Function的内核注册到调度程序,调度程序和自动求导系统将自动调用这些运算符的前向和后向实现。
class CumtomSeluFunction : public torch::autograd::Function<CumtomSeluFunction> {
// Implementation of selu kernel in new backend
}
at::Tensor wrapper_AutogradCumstom__selu(const at::Tensor & self) {
return CumtomSeluFunction::apply(self);
}
TORCH_LIBRARY_IMPL(aten, AutogradPrivateUse1, m) {
...
m.impl("selu", TORCH_FN(wrapper_AutogradCustom__selu));
...
}
- 通过
AutocastPrivateUse1将想要支持自动混合精度(AMP)和回退机制的内核注册到调度程序,当需要时,自动转换系统将自动调用这些内核。
TORCH_LIBRARY_IMPL(aten, AutocastPrivateUse1, m) {
...
KERNEL_PRIVATEUSEONE(<operator>, <policy>)
...
}
TORCH_LIBRARY_IMPL(_, AutocastPrivateUse1, m) {
m.fallback(torch::CppFunction::makeFallthrough());
}
需要补充的是,如果要在新后端支持 AMP,需要通过torch._register_device_module("backend_name", BackendModule)注册一个新的BackendModule,并且BackendModule需要具有以下 API:
-
get_amp_supported_dtype() -> List[torch.dtype]在 AMP 中获取新后端支持的
dtype,可能支持一个以上的dtype。 -
is_autocast_enabled() -> bool检查新后端是否启用 AMP。
-
get_autocast_dtype() -> torch.dtype在 AMP 中获取新后端支持的
dtype,该dtype由set_autocast_dtype或默认dtype设置,而默认dtype为torch.float16。 -
set_autocast_enabled(bool) -> None在新后端上启用或禁用 AMP。
-
set_autocast_dtype(dtype) -> None在 AMP 中设置新后端支持的
dtype,并且dtype包含在从get_amp_supported_dtype获取的dtypes中。
为新后端注册生成器
需要支持与新设备对应的生成器。目前,PrivateUse1可以动态注册自定义生成器,主要分为以下几个步骤。
-
继承
GeneratorImpl类以实现与新后端对应的生成器类,并实现各种通用方法。 -
定义一个带有单个参数
device index的新后端builder。 -
调用
REGISTER_GENERATOR_PRIVATEUSE1宏完成动态注册。
struct CustomGeneratorImpl : public c10::GeneratorImpl {
// Implementation of generator in new backend
}
at::Generator make_custom_generator(c10::DeviceIndex device_index) {
return at::make_generator<CustomGeneratorImpl>(device_index);
}
REGISTER_GENERATOR_PRIVATEUSE1(make_cumstom_generator)
为新后端注册设备保护
PyTorch 通过DeviceGuard提供了与设备、流和事件切换相关的功能。这个功能也适用于PrivateUse1关键。
-
继承
DeviceGuardImplInterface类以实现与新后端对应的各种通用方法。 -
调用
C10_REGISTER_GUARD_IMPL宏完成动态注册。
struct CustomGuardImpl final : public c10::impl::DeviceGuardImplInterface {
// Implementation of guard in new backend
}
C10_REGISTER_GUARD_IMPL(PrivateUse1, CustomGuardImpl);
为新后端元数据注册序列化和反序列化函数
PyTorch 目前能够动态注册序列化/反序列化函数,以支持在TensorImpl.ExtraMeta类中命名为backend_meta_的新后端附加元数据的序列化和反序列化。您可以参考以下步骤:
-
继承
BackendMeta类以实现与新后端对应的CustomBackendMetadata,并且新后端的各个字段可以在类中自定义。 -
实现新后端的序列化和反序列化函数,函数签名为
void(const at::Tensor&, std::unordered_map<std::string, bool>&)。 -
调用
TensorBackendMetaRegistry宏完成动态注册。
struct CustomBackendMetadata : public c10::BackendMeta {
// Implementation of backend metadata in new backend
}
void for_serialization(const at::Tensor& t, std::unordered_map<std::string, bool>& m) {
// Implementation of serialization
}
void for_deserialization(const at::Tensor& t, std::unordered_map<std::string, bool>& m) {
// Implementation of deserialization
}
TensorBackendMetaRegistry(c10::DeviceType::PrivateUse1, &for_serialization, &for_deserialization);
其他模块
除了上述部分外,还有一些其他模块可以通过PrivateUse1进行扩展,例如分布式集体通信、基准计时器等,这些将在未来添加。关于PrivateUse1集成的一个示例是Ascend NPU。
如何通过 Privateuse1 改进用户体验
通过PrivateUse1集成新设备的主要目标是满足基本的功能要求,接下来要做的是改进可用性,主要涉及以下几个方面。
-
向 PyTorch 注册新的后端模块。
-
生成与新后端相关的方法和属性。
-
生成与新后端相关的方法和属性。
向 PyTorch 注册新的后端模块
PyTorch 中的一些与 CUDA 相关的接口可以通过以下形式调用:torch.cuda.xxx。因此,为了符合用户习惯,通过PrivateUse1机制实现的新后端也应该提供类似的接口。
例如,使用Ascend NPU:
torch._register_device_module('npu', torch_npu.npu)
完成上述操作后,用户可以通过torch.npu.xxx调用Ascend NPU的一些独有 API。
将 PrivateUse1 重命名为新后端的自定义名称
PrivateUse1 键是集成到 PyTorch 中的新后端的内部机制。对于用户来说,与 PrivateUse1 相比,与新后端密切相关的自定义名称应该更加友好。
以 Ascend NPU 为例,第一种用法将更加用户友好。
torch.rand((2,2),device='npu:0')
torch.rand((2,2),device='privateuse1:0')
现在,PyTorch 为自命名的 PrivateUse1 后端提供了一个新的 C++/Python API,非常简单易用。
torch.rename_privateuse1_backend("npu")
c10::register_privateuse1_backend("npu")
生成与新后端相关的方法和属性
将 PrivateUse1 重命名为自定义名称后,在新后端的 Tensor, nn, Storage 模块中自动生成与新后端名称相关的属性和方法。
这里以 Ascend NPU 为例:
torch.rename_privateuse1_backend("npu")
unsupported_dtype = [torch.quint8]
torch.utils.generate_methods_for_privateuse1_backend(for_tensor=True, for_module=True, for_storage=True, unsupported_dtype=unsupported_dtype)
然后,您可以使用以下方法和属性:
torch.Tensor.npu()
torch.Tensor.is_npu
torch.Storage.npu()
torch.Storage.is_npu
...
未来工作
PrivateUse1 机制的改进仍在进行中,因此新模块的 PrivateUse1 集成方法将逐步添加。以下是我们正在积极开展的几个项目:
-
添加
分布式集体通信的集成方法。 -
添加
基准计时器的集成方法。
结论
本教程指导您通过 PrivateUse1 将新后端集成到 PyTorch 中的过程,包括但不限于运算符注册、生成器注册、设备保护注册等。同时,介绍了一些方法来改善用户体验。
模型优化
使用 TensorBoard 的 PyTorch 分析器
原文:
pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
本教程演示了如何使用 TensorBoard 插件与 PyTorch 分析器来检测模型的性能瓶颈。
介绍
PyTorch 1.8 包括一个更新的分析器 API,能够记录 CPU 端操作以及 GPU 端的 CUDA 内核启动。分析器可以在 TensorBoard 插件中可视化这些信息,并提供性能瓶颈的分析。
在本教程中,我们将使用一个简单的 Resnet 模型来演示如何使用 TensorBoard 插件来分析模型性能。
设置
要安装torch和torchvision,请使用以下命令:
pip install torch torchvision
步骤
-
准备数据和模型
-
使用分析器记录执行事件
-
运行分析器
-
使用 TensorBoard 查看结果并分析模型性能
-
通过分析器提高性能
-
使用其他高级功能分析性能
-
额外练习:在 AMD GPU 上对 PyTorch 进行分析
1. 准备数据和模型
首先,导入所有必要的库:
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
然后准备输入数据。在本教程中,我们使用 CIFAR10 数据集。将其转换为所需的格式,并使用DataLoader加载每批数据。
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)
接下来,创建 Resnet 模型、损失函数和优化器对象。要在 GPU 上运行,请将模型和损失移动到 GPU 设备。
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
为每批输入数据定义训练步骤。
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2. 使用分析器记录执行事件
通过上下文管理器启用分析器,并接受几个参数,其中一些最有用的是:
-
schedule- 接受步骤(int)作为单个参数并返回每个步骤执行的分析器操作的可调用函数。在此示例中,使用
wait=1, warmup=1, active=3, repeat=1,分析器将跳过第一步/迭代,从第二步开始热身,记录接下来的三次迭代,之后跟踪将变为可用,并调用 on_trace_ready(如果设置)。总共,循环重复一次。在 TensorBoard 插件中,每个循环称为“span”。在
wait步骤期间,分析器被禁用。在warmup步骤期间,分析器开始跟踪,但结果被丢弃。这是为了减少分析的开销。在分析开始时,开销很高,容易给分析结果带来偏差。在active步骤期间,分析器工作并记录事件。 -
on_trace_ready- 在每个周期结束时调用的可调用函数;在本示例中,我们使用torch.profiler.tensorboard_trace_handler生成 TensorBoard 的结果文件。分析后,结果文件将保存在./log/resnet18目录中。将此目录指定为logdir参数以在 TensorBoard 中分析配置文件。 -
record_shapes- 是否记录操作符输入的形状。 -
profile_memory- 跟踪张量内存分配/释放。请注意,对于旧版本的 PyTorch(1.10 之前的版本),如果遇到长时间的分析时间,请禁用它或升级到新版本。 -
with_stack- 记录操作的源信息(文件和行号)。如果在 VS Code 中启动了 TensorBoard(参考链接),点击堆栈帧将导航到特定的代码行。
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
prof.step() # Need to call this at each step to notify profiler of steps' boundary.
if step >= 1 + 1 + 3:
break
train(batch_data)
另外,也支持以下非上下文管理器的启动/停止。
prof = torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
with_stack=True)
prof.start()
for step, batch_data in enumerate(train_loader):
prof.step()
if step >= 1 + 1 + 3:
break
train(batch_data)
prof.stop()
3. 运行分析器
运行上述代码。分析结果将保存在./log/resnet18目录下。
4. 使用 TensorBoard 查看结果并分析模型性能
注意
TensorBoard 插件支持已被弃用,因此一些这些功能可能不再像以前那样工作。请查看替代方案,HTA。
安装 PyTorch 分析器 TensorBoard 插件。
pip install torch_tb_profiler
启动 TensorBoard。
tensorboard --logdir=./log
在 Google Chrome 浏览器或 Microsoft Edge 浏览器中打开 TensorBoard 配置文件 URL(不支持 Safari)。
http://localhost:6006/#pytorch_profiler
您可以看到如下所示的 Profiler 插件页面。
- 概述

概述显示了模型性能的高级摘要。
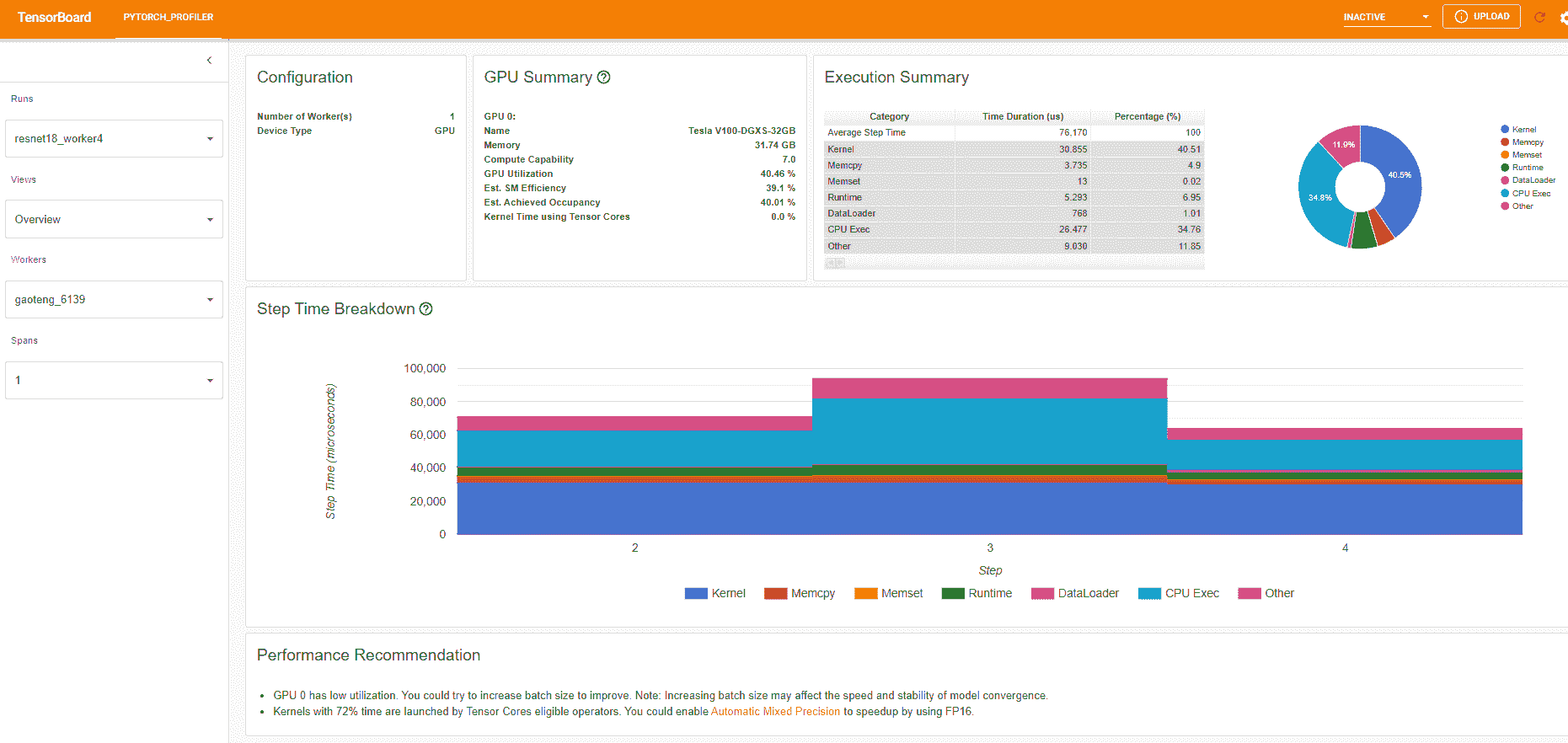
“GPU 摘要”面板显示 GPU 配置、GPU 使用情况和张量核心使用情况。在此示例中,GPU 利用率较低。这些指标的详细信息在这里。
“步骤时间分解”显示在不同执行类别上花费在每个步骤中的时间的分布。在此示例中,您可以看到DataLoader的开销很大。
底部的“性能建议”使用分析数据自动突出显示可能的瓶颈,并为您提供可操作的优化建议。
您可以在左侧的“视图”下拉列表中更改视图页面。

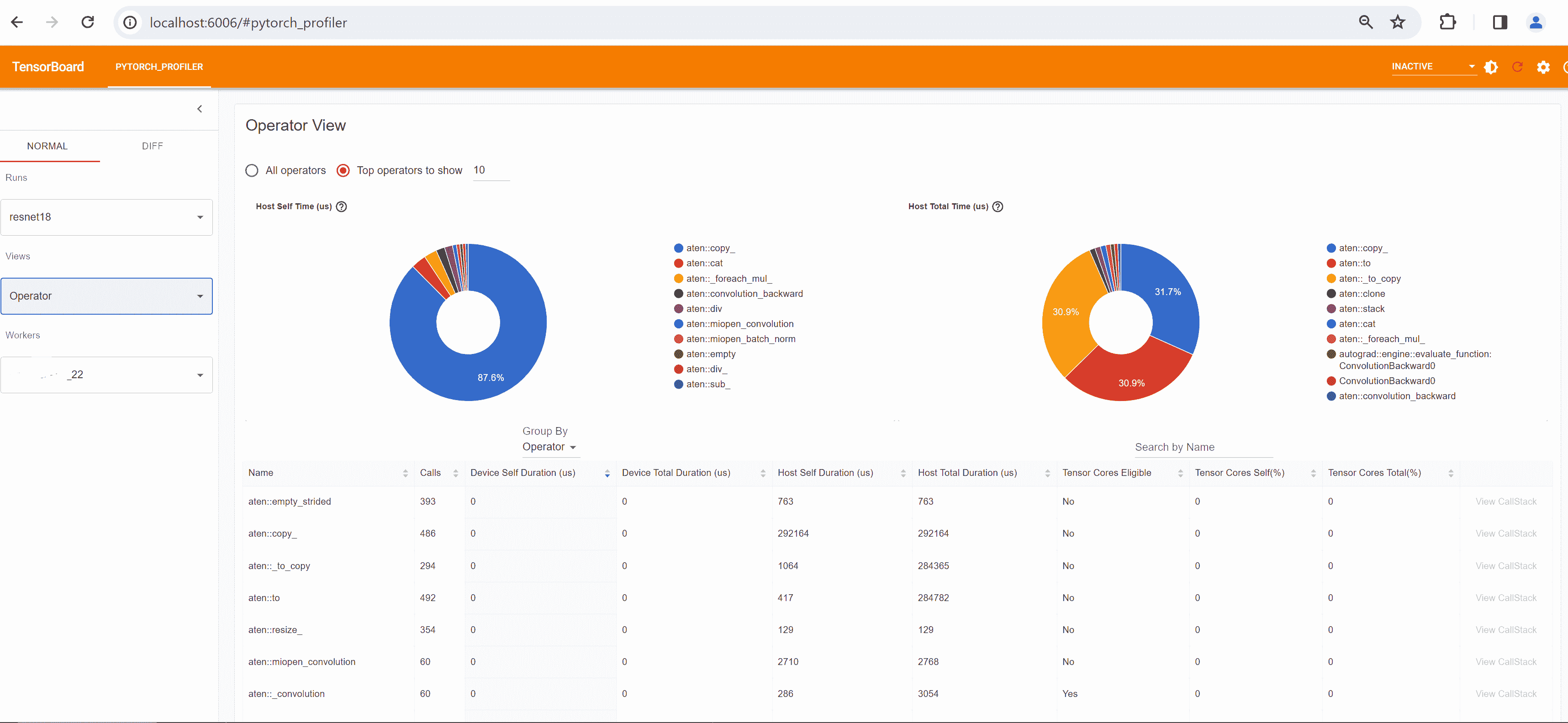
- 操作员视图
操作员视图显示了在主机或设备上执行的每个 PyTorch 操作员的性能。

“自身”持续时间不包括其子操作员的时间。“总”持续时间包括其子操作员的时间。
- 查看调用堆栈
单击操作员的“查看调用堆栈”,将显示具有相同名称但不同调用堆栈的操作员。然后单击此子表中的“查看调用堆栈”,将显示调用堆栈帧。
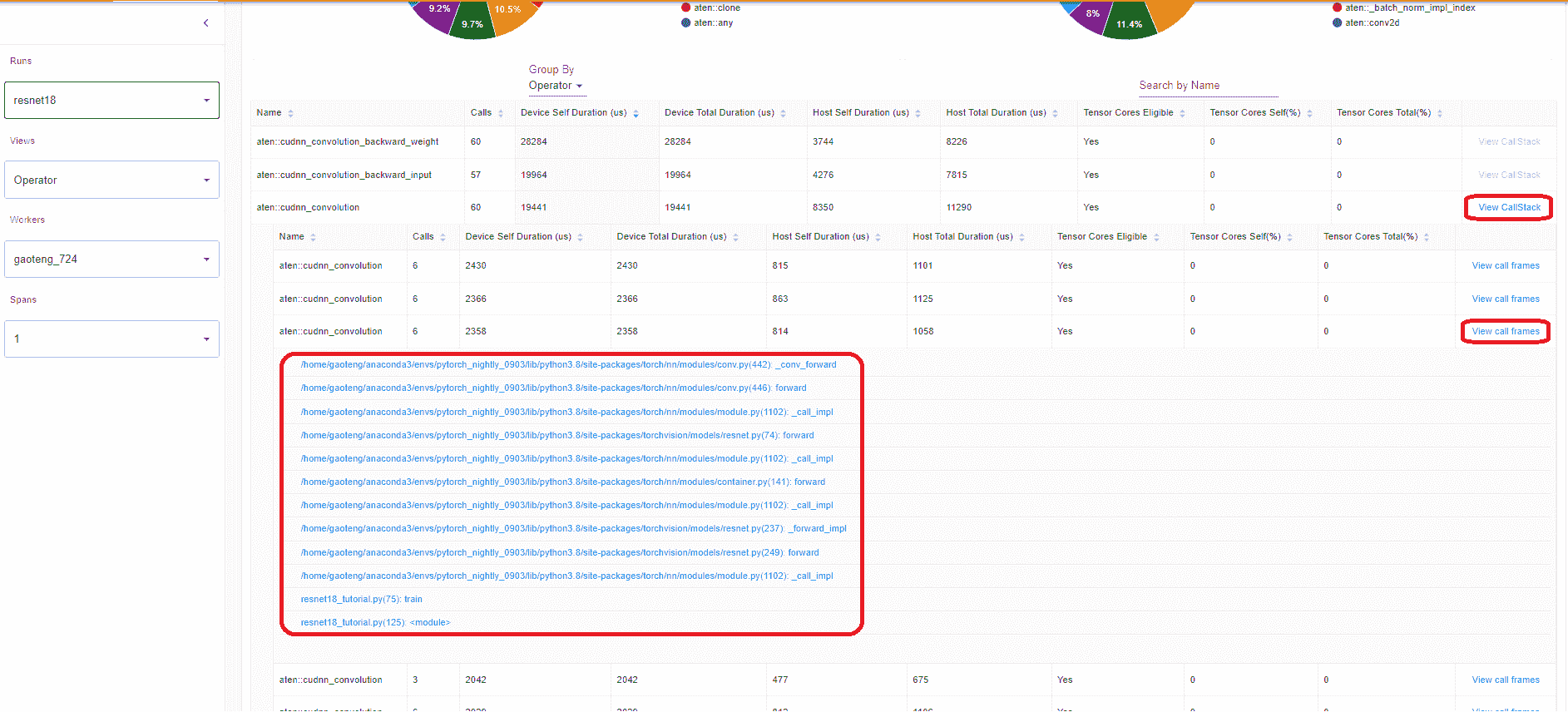
如果在 VS Code 中启动了 TensorBoard(启动指南),单击调用堆栈帧将导航到特定的代码行。
- 内核视图
GPU 内核视图显示 GPU 上花费的所有内核时间。
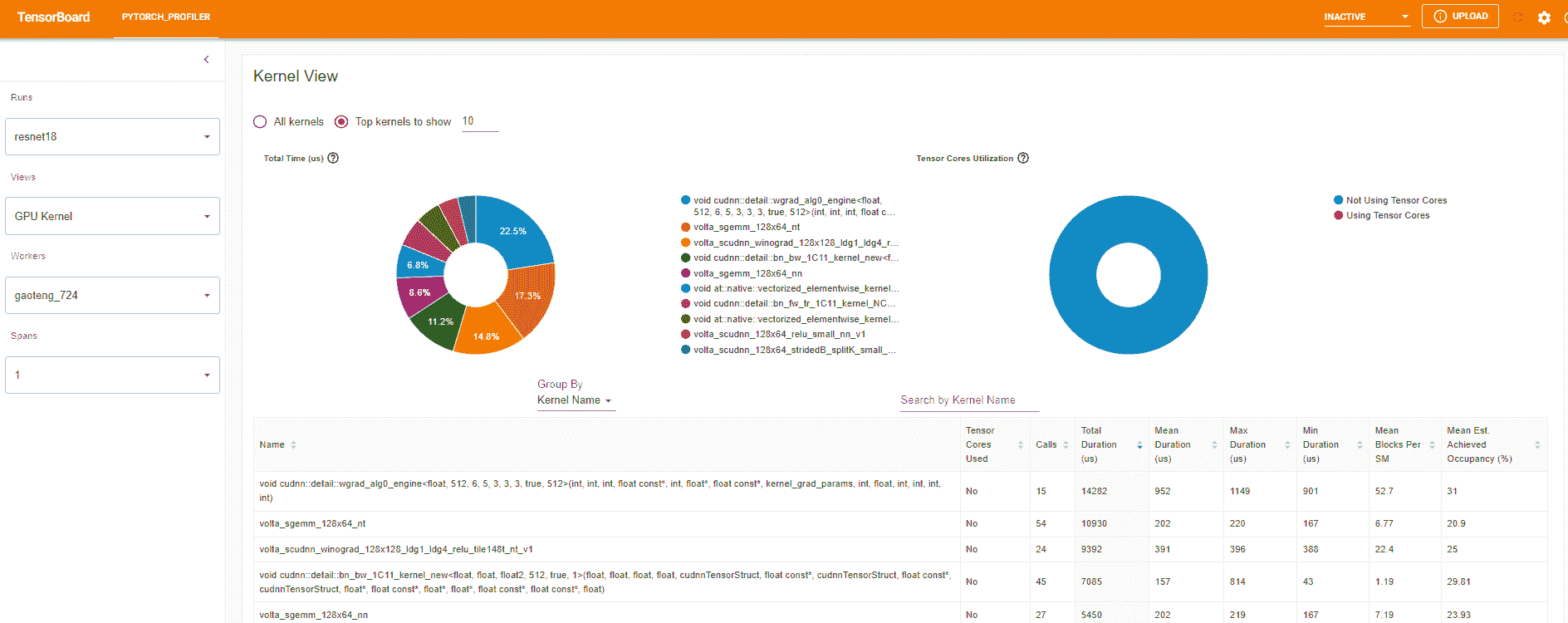
是否使用张量核心:此内核是否使用张量核心。
每个 SM 的平均块数:每个 SM 的块数=此内核的块数/此 GPU 的 SM 数。如果此数字小于 1,则表示 GPU 多处理器未充分利用。“每个 SM 的平均块数”是此内核名称的所有运行的加权平均值,使用每次运行的持续时间作为权重。
平均估计实现占用率:此列的工具提示中定义了估计实现占用率。对于大多数情况,如内存带宽受限的内核,数值越高越好。“平均估计实现占用率”是此内核名称的所有运行的加权平均值,使用每次运行的持续时间作为权重。
- 跟踪视图
跟踪视图显示了受监视的操作员和 GPU 内核的时间轴。您可以选择它以查看以下详细信息。
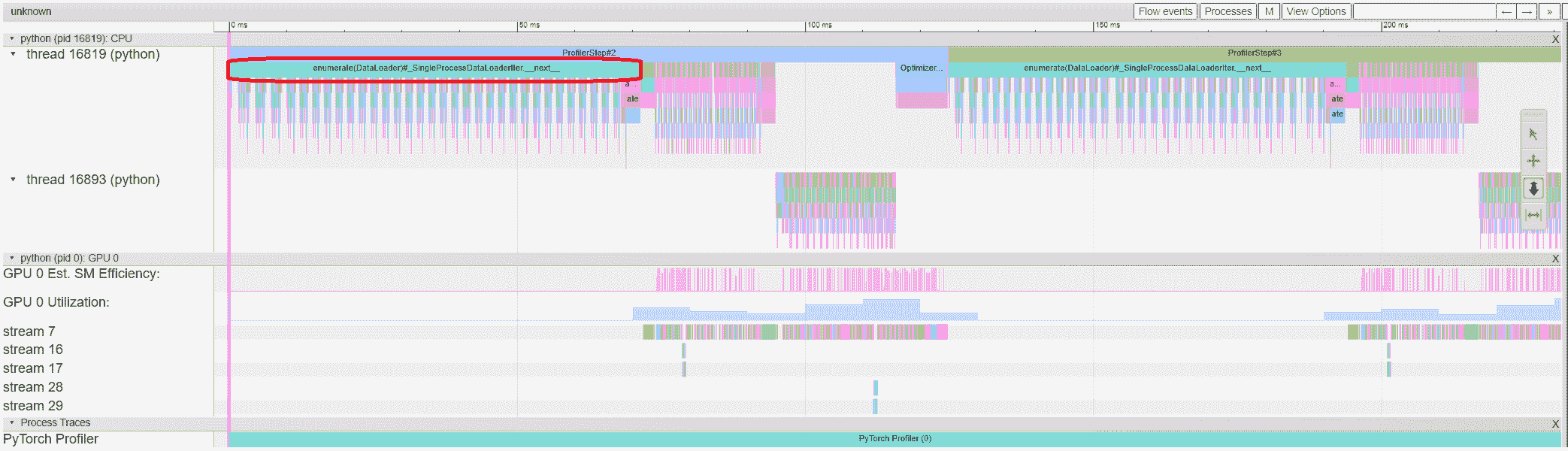
您可以使用右侧工具栏移动图形并放大/缩小。键盘也可以用于在时间轴内部缩放和移动。‘w’和‘s’键以鼠标为中心放大,‘a’和‘d’键将时间轴向左或向右移动。您可以多次按这些键,直到看到可读的表示。
如果后向操作员的“传入流”字段的值为“前向对应后向”,则可以单击文本以获取其启动前向操作员。
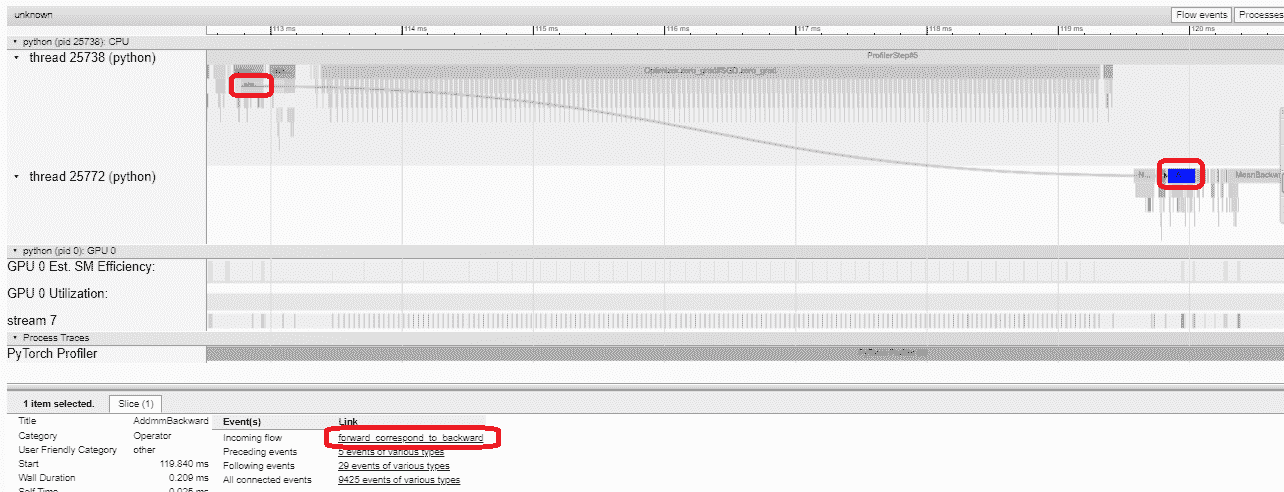
在这个例子中,我们可以看到以enumerate(DataLoader)为前缀的事件耗费了大量时间。在大部分时间内,GPU 处于空闲状态。因为这个函数正在主机端加载数据和转换数据,期间 GPU 资源被浪费。
5. 借助分析器提高性能
在“概览”页面的底部,“性能建议”中的建议提示瓶颈是DataLoader。PyTorch 的DataLoader默认使用单进程。用户可以通过设置参数num_workers来启用多进程数据加载。这里有更多细节。
在这个例子中,我们遵循“性能建议”,将num_workers设置如下,将不同的名称传递给tensorboard_trace_handler,然后再次运行。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=4)
然后在左侧的“Runs”下拉列表中选择最近分析的运行。
从上述视图中,我们可以看到步骤时间与之前的运行相比减少到约 76ms,而DataLoader的时间减少主要起作用。
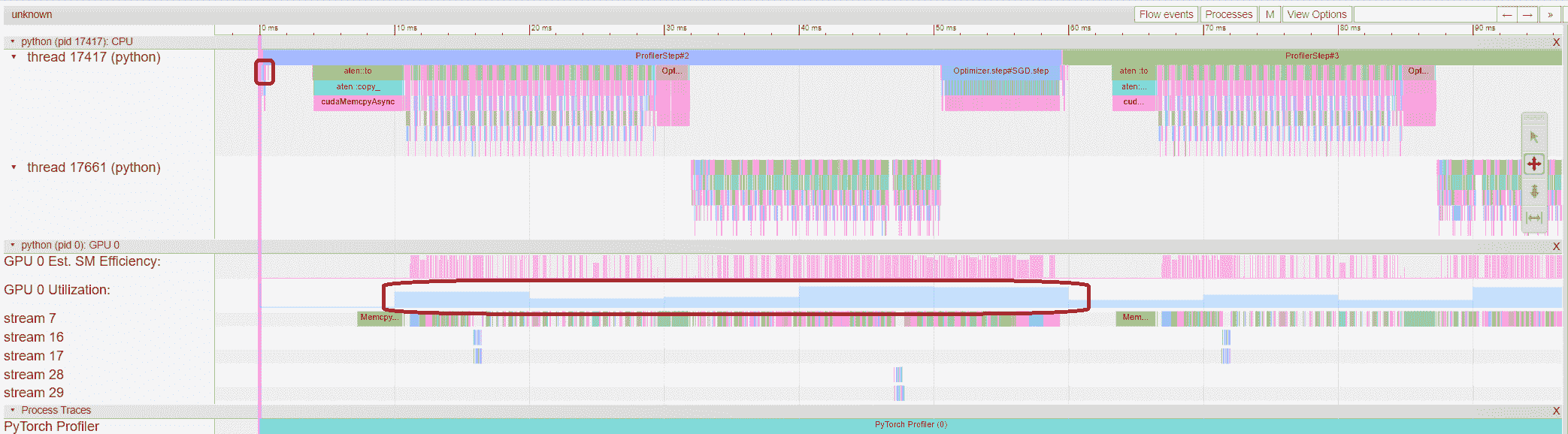
从上述视图中,我们可以看到enumerate(DataLoader)的运行时间减少了,GPU 利用率增加了。
6. 使用其他高级功能进行性能分析
- 内存视图
为了对内存进行分析,必须在torch.profiler.profile的参数中将profile_memory设置为True。
您可以尝试在 Azure 上使用现有示例
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/memory_demo_1_10
分析器在分析过程中记录所有内存分配/释放事件和分配器的内部状态。内存视图由以下三个组件组成。
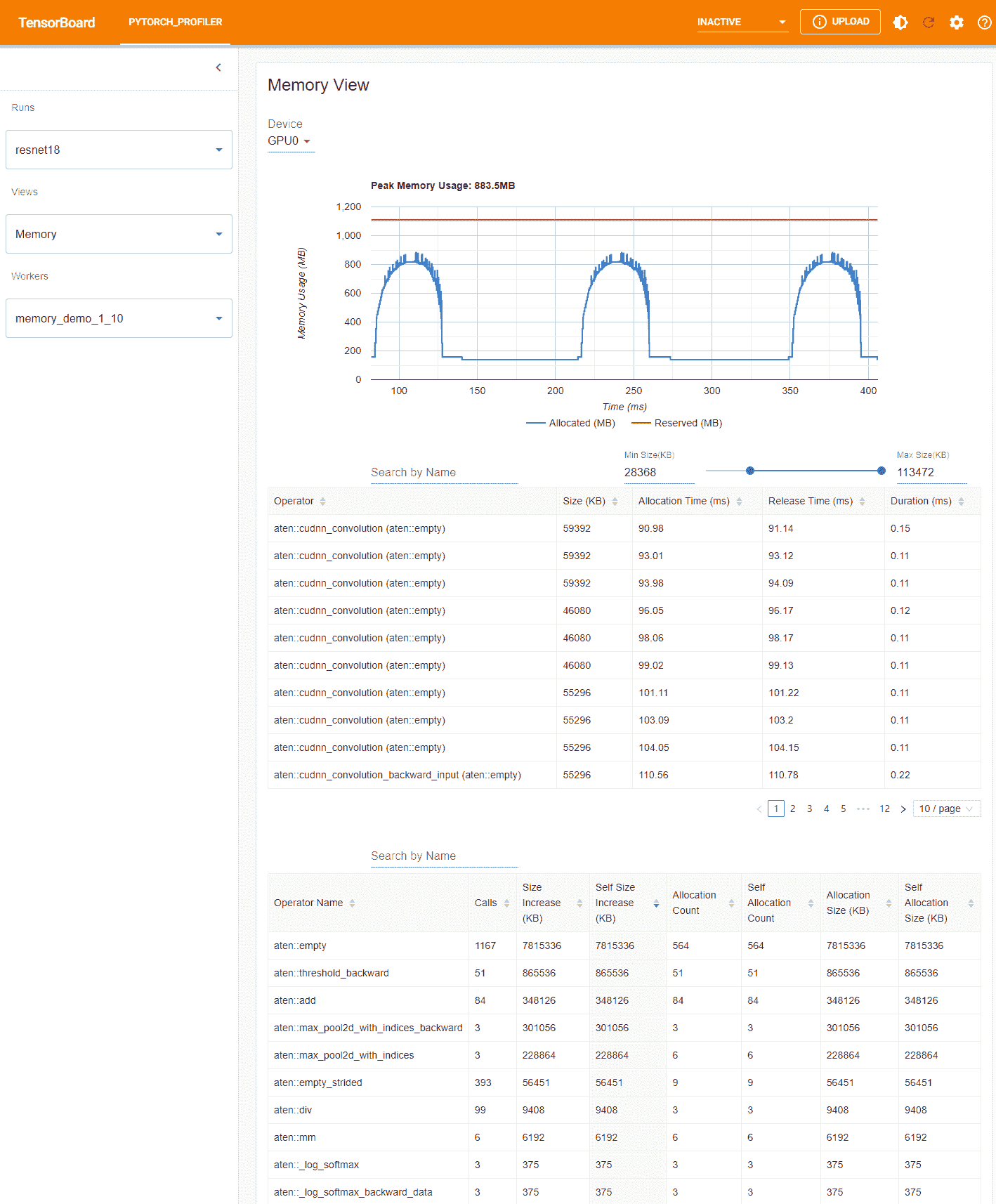
这些组件分别是内存曲线图、内存事件表和内存统计表,从上到下依次排列。
内存类型可以在“设备”选择框中选择。例如,“GPU0”表示以下表格仅显示 GPU 0 上每个操作符的内存使用情况,不包括 CPU 或其他 GPU。
内存曲线显示内存消耗的趋势。“已分配”曲线显示实际使用的总内存,例如张量。在 PyTorch 中,CUDA 分配器和一些其他分配器采用了缓存机制。“保留”曲线显示分配器保留的总内存。您可以在图表上左键单击并拖动以选择所需范围内的事件:

选择后,这三个组件将针对受限时间范围进行更新,以便您可以获取更多信息。通过重复这个过程,您可以深入了解非常细微的细节。右键单击图表将重置图表到初始状态。
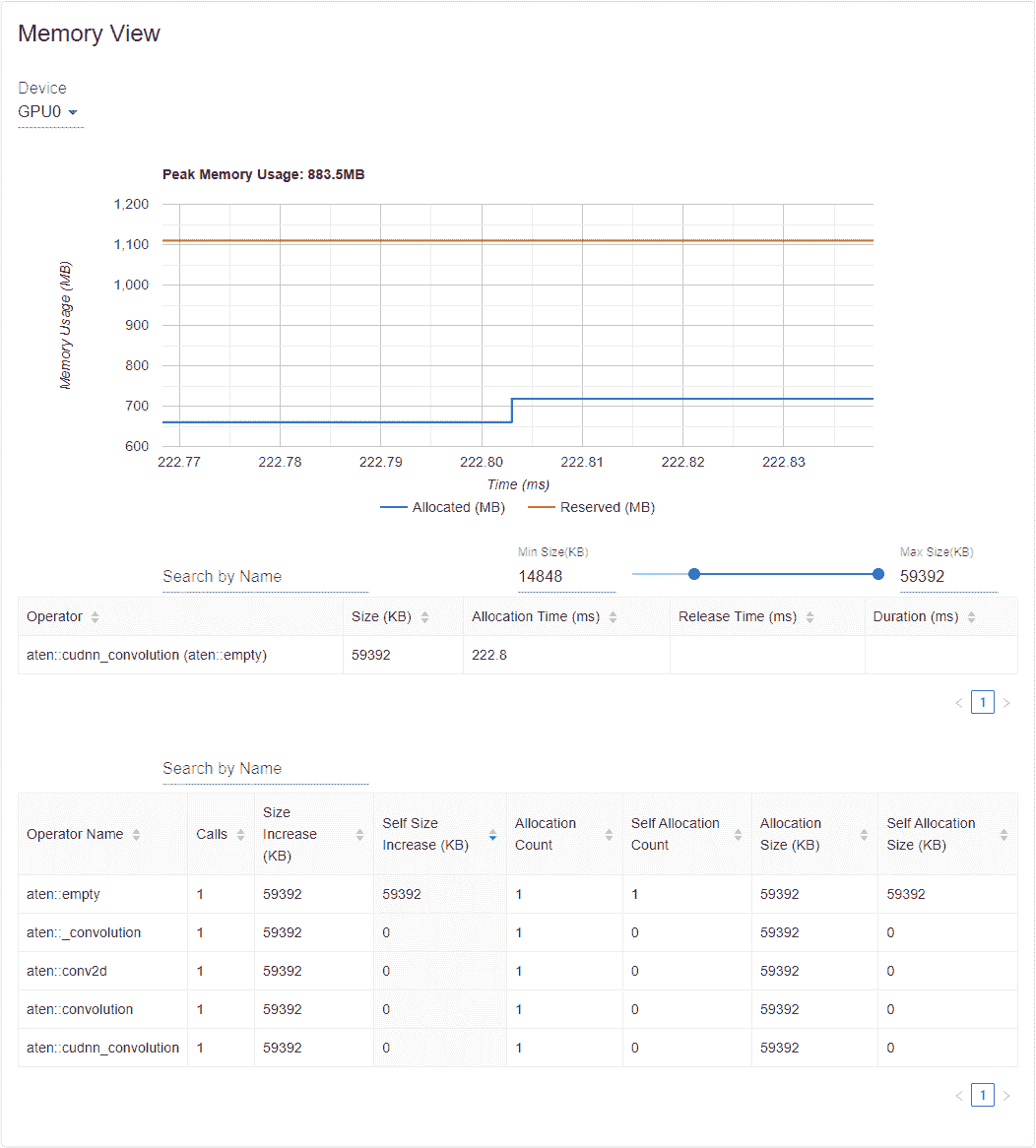
在内存事件表中,分配和释放事件成对显示在一个条目中。“operator”列显示导致分配的即时 ATen 操作符。请注意,在 PyTorch 中,ATen 操作符通常使用aten::empty来分配内存。例如,aten::ones实际上是由aten::empty后跟一个aten::fill_实现的。仅显示aten::empty操作符名称并没有太大帮助。在这种特殊情况下,它将显示为aten::ones (aten::empty)。如果事件发生在时间范围之外,则“分配时间”、“释放时间”和“持续时间”列的数据可能会丢失。
在内存统计表中,“大小增加”列总结了所有分配大小并减去所有内存释放大小,即在此运算符之后内存使用量的净增加。“自身大小增加”列类似于“大小增加”,但它不计算子运算符的分配。关于 ATen 运算符的实现细节,一些运算符可能调用其他运算符,因此内存分配可以发生在调用堆栈的任何级别。也就是说,“自身大小增加”仅计算当前调用堆栈级别的内存使用量增加。最后,“分配大小”列总结了所有分配,而不考虑内存释放。
- 分布式视图
插件现在支持使用 NCCL/GLOO 作为后端在分布式 DDP 上进行性能分析。
您可以通过在 Azure 上使用现有示例来尝试:
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/distributed_bert
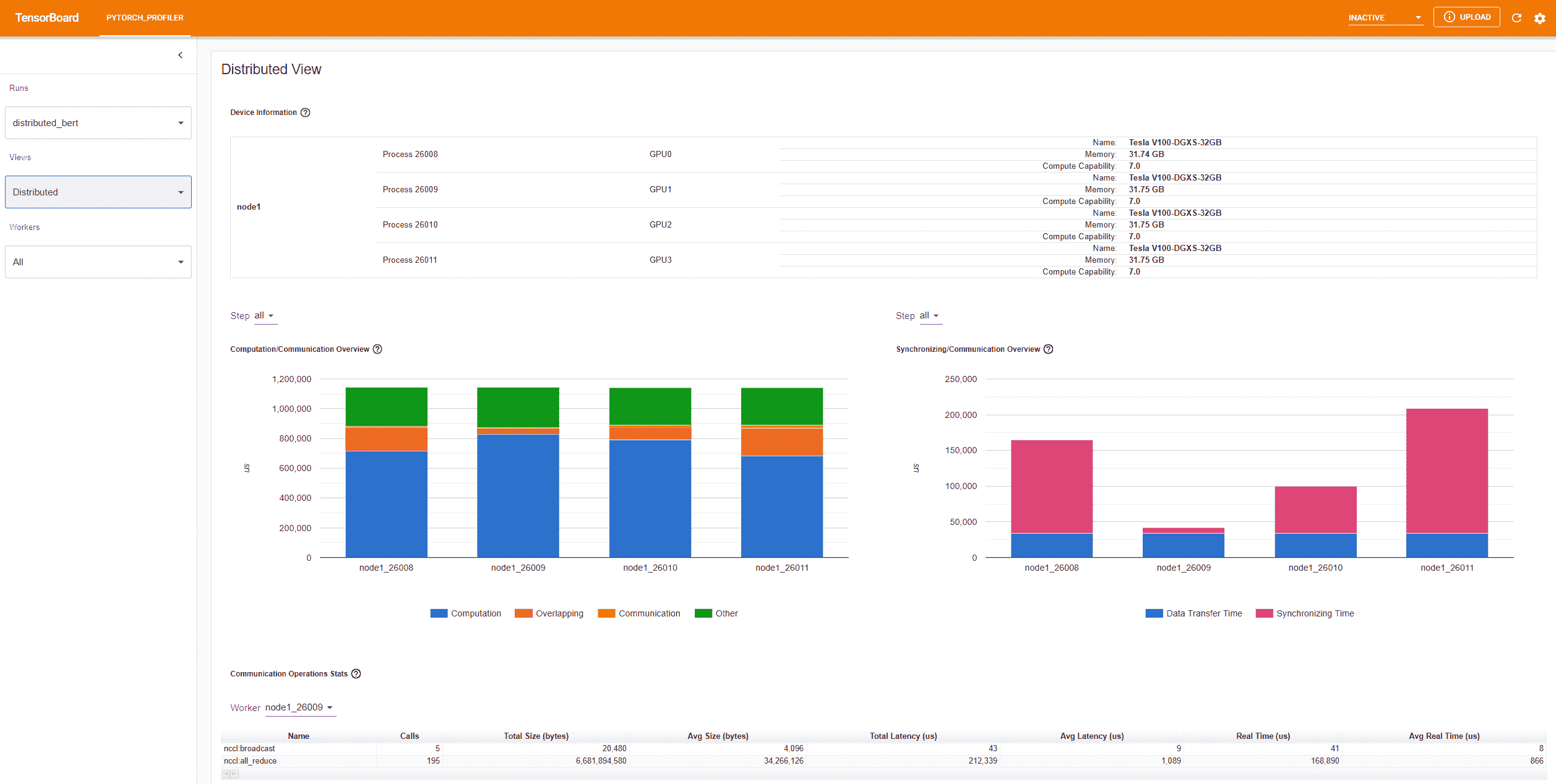
“计算/通信概述”显示了计算/通信比和它们的重叠程度。从这个视图中,用户可以找出工作人员之间的负载平衡问题。例如,如果一个工作人员的计算+重叠时间比其他工作人员的大得多,那么可能存在负载平衡问题,或者这个工作人员可能是一个慢工作者。
“同步/通信概述”显示了通信的效率。“数据传输时间”是实际数据交换的时间。“同步时间”是等待和与其他工作人员同步的时间。
如果一个工作人员的“同步时间”比其他工作人员的短得多,那么这个工作人员可能是一个比其他工作人员有更多计算工作量的慢工作者。
“通信操作统计”总结了每个工作人员中所有通信操作的详细统计信息。
7. 附加实践:在 AMD GPU 上对 PyTorch 进行性能分析
AMD ROCm 平台是一个为 GPU 计算设计的开源软件堆栈,包括驱动程序、开发工具和 API。我们可以在 AMD GPU 上运行上述提到的步骤。在本节中,我们将使用 Docker 在安装 PyTorch 之前安装 ROCm 基础开发镜像。
为了示例,让我们创建一个名为profiler_tutorial的目录,并将步骤 1中的代码保存为test_cifar10.py在这个目录中。
mkdir ~/profiler_tutorial
cd profiler_tutorial
vi test_cifar10.py
在撰写本文时,ROCm 平台上 PyTorch 的稳定(2.1.1)Linux 版本是ROCm 5.6。
- 从Docker Hub获取安装了正确用户空间 ROCm 版本的基础 Docker 镜像。
它是rocm/dev-ubuntu-20.04:5.6。
- 启动 ROCm 基础 Docker 容器:
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 8G -v ~/profiler_tutorial:/profiler_tutorial rocm/dev-ubuntu-20.04:5.6
- 在容器内,安装安装 wheels 包所需的任何依赖项。
sudo apt update
sudo apt install libjpeg-dev python3-dev -y
pip3 install wheel setuptools
sudo apt install python-is-python3
- 安装 wheels:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
- 安装
torch_tb_profiler,然后运行 Python 文件test_cifar10.py:
pip install torch_tb_profiler
cd /profiler_tutorial
python test_cifar10.py
现在,我们有了在 TensorBoard 中查看所需的所有数据:
tensorboard --logdir=./log
选择不同的视图,如步骤 4中所述。例如,下面是操作员视图:
在撰写本节时,跟踪视图不起作用,不显示任何内容。您可以通过在 Chrome 浏览器中输入chrome://tracing来解决问题。
- 将
trace.json文件复制到~/profiler_tutorial/log/resnet18目录下的 Windows。
如果文件位于远程位置,您可能需要使用scp来复制文件。
- 点击加载按钮,从浏览器中的
chrome://tracing页面加载跟踪 JSON 文件。
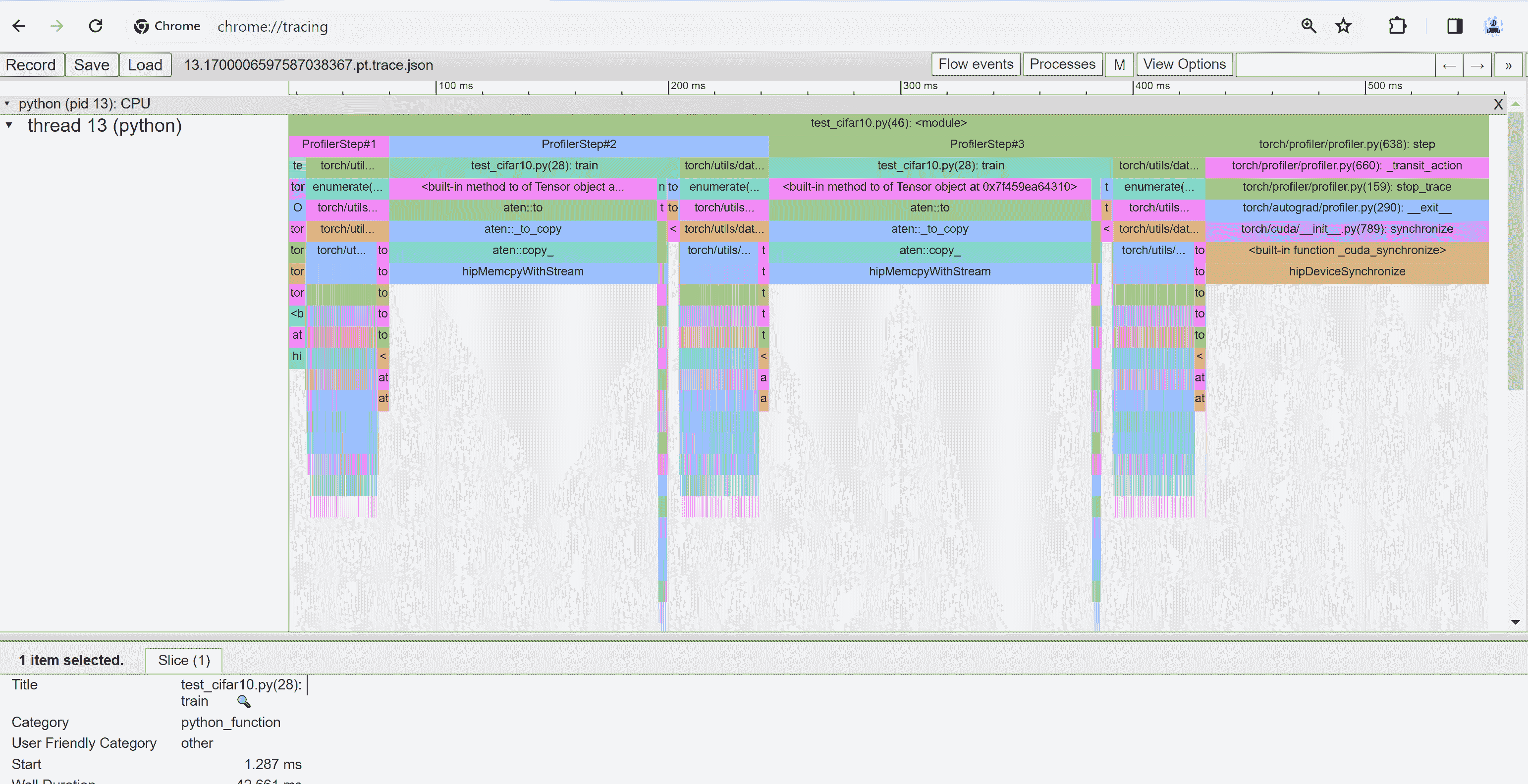
如前所述,您可以移动图形并放大或缩小。您还可以使用键盘在时间轴内部放大和移动。 w和s键以鼠标为中心放大,a和d键将时间轴向左或向右移动。您可以多次按这些键,直到看到可读的表示。
了解更多
查看以下文档以继续学习,并随时在此处提出问题。
-
PyTorch TensorBoard Profiler Github
-
torch.profiler API
-
HTA
脚本的总运行时间:(0 分钟 0.000 秒)
下载 Python 源代码:tensorboard_profiler_tutorial.py
下载 Jupyter 笔记本:tensorboard_profiler_tutorial.ipynb
Sphinx-Gallery 生成的画廊
使用 Ray Tune 进行超参数调整
原文:
pytorch.org/tutorials/beginner/hyperparameter_tuning_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整的示例代码
超参数调整可以使普通模型和高度准确的模型之间产生巨大差异。通常简单的事情,比如选择不同的学习率或改变网络层大小,都可以对模型性能产生显著影响。
幸运的是,有一些工具可以帮助找到最佳参数组合。Ray Tune是一个行业标准的分布式超参数调整工具。Ray Tune 包括最新的超参数搜索算法,与 TensorBoard 和其他分析库集成,并通过Ray 的分布式机器学习引擎原生支持分布式训练。
在本教程中,我们将向您展示如何将 Ray Tune 集成到 PyTorch 训练工作流程中。我们将扩展来自 PyTorch 文档的这个教程,用于训练 CIFAR10 图像分类器。
正如您将看到的,我们只需要添加一些轻微的修改。特别是,我们需要
-
将数据加载和训练封装在函数中,
-
使一些网络参数可配置,
-
添加检查点(可选),
-
并定义模型调优的搜索空间
要运行此教程,请确保安装了以下软件包:
-
ray[tune]:分布式超参数调整库 -
torchvision:用于数据转换器
设置/导入
让我们从导入开始:
from functools import partial
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import random_split
import torchvision
import torchvision.transforms as transforms
from ray import tune
from ray.air import Checkpoint, session
from ray.tune.schedulers import ASHAScheduler
大部分导入都是用于构建 PyTorch 模型。只有最后三个导入是为了 Ray Tune。
数据加载器
我们将数据加载器封装在自己的函数中,并传递一个全局数据目录。这样我们可以在不同的试验之间共享一个数据目录。
def load_data(data_dir="./data"):
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = torchvision.datasets.CIFAR10(
root=data_dir, train=True, download=True, transform=transform
)
testset = torchvision.datasets.CIFAR10(
root=data_dir, train=False, download=True, transform=transform
)
return trainset, testset
可配置的神经网络
我们只能调整可配置的参数。在这个例子中,我们可以指定全连接层的层大小:
class Net(nn.Module):
def __init__(self, l1=120, l2=84):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, l1)
self.fc2 = nn.Linear(l1, l2)
self.fc3 = nn.Linear(l2, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
训练函数
现在变得有趣了,因为我们对示例进行了一些更改来自 PyTorch 文档。
我们将训练脚本封装在一个函数train_cifar(config, data_dir=None)中。config参数将接收我们想要训练的超参数。data_dir指定我们加载和存储数据的目录,以便多次运行可以共享相同的数据源。如果提供了检查点,我们还会在运行开始时加载模型和优化器状态。在本教程的后面部分,您将找到有关如何保存检查点以及它的用途的信息。
net = Net(config["l1"], config["l2"])
checkpoint = session.get_checkpoint()
if checkpoint:
checkpoint_state = checkpoint.to_dict()
start_epoch = checkpoint_state["epoch"]
net.load_state_dict(checkpoint_state["net_state_dict"])
optimizer.load_state_dict(checkpoint_state["optimizer_state_dict"])
else:
start_epoch = 0
优化器的学习率也是可配置的:
optimizer = optim.SGD(net.parameters(), lr=config["lr"], momentum=0.9)
我们还将训练数据分成训练集和验证集。因此,我们在 80%的数据上进行训练,并在剩余的 20%上计算验证损失。我们可以配置通过训练和测试集的批处理大小。
使用 DataParallel 添加(多)GPU 支持
图像分类在很大程度上受益于 GPU。幸运的是,我们可以继续在 Ray Tune 中使用 PyTorch 的抽象。因此,我们可以将我们的模型包装在nn.DataParallel中,以支持在多个 GPU 上进行数据并行训练:
device = "cpu"
if torch.cuda.is_available():
device = "cuda:0"
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net)
net.to(device)
通过使用device变量,我们确保在没有 GPU 可用时训练也能正常进行。PyTorch 要求我们明确将数据发送到 GPU 内存,就像这样:
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
现在的代码支持在 CPU 上、单个 GPU 上和多个 GPU 上进行训练。值得注意的是,Ray 还支持分数 GPU,因此我们可以在试验之间共享 GPU,只要模型仍适合 GPU 内存。我们稍后会回到这个问题。
与 Ray Tune 通信
最有趣的部分是与 Ray Tune 的通信:
checkpoint_data = {
"epoch": epoch,
"net_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
}
checkpoint = Checkpoint.from_dict(checkpoint_data)
session.report(
{"loss": val_loss / val_steps, "accuracy": correct / total},
checkpoint=checkpoint,
)
在这里,我们首先保存一个检查点,然后将一些指标报告给 Ray Tune。具体来说,我们将验证损失和准确率发送回 Ray Tune。然后,Ray Tune 可以使用这些指标来决定哪种超参数配置会产生最佳结果。这些指标也可以用来及早停止表现不佳的试验,以避免浪费资源在这些试验上。
检查点保存是可选的,但是如果我们想要使用高级调度程序(如基于种群的训练),则是必要的。此外,通过保存检查点,我们可以稍后加载训练好的模型并在测试集上验证。最后,保存检查点对于容错性很有用,它允许我们中断训练并稍后继续训练。
完整的训练函数
完整的代码示例如下:
def train_cifar(config, data_dir=None):
net = Net(config["l1"], config["l2"])
device = "cpu"
if torch.cuda.is_available():
device = "cuda:0"
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net)
net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=config["lr"], momentum=0.9)
checkpoint = session.get_checkpoint()
if checkpoint:
checkpoint_state = checkpoint.to_dict()
start_epoch = checkpoint_state["epoch"]
net.load_state_dict(checkpoint_state["net_state_dict"])
optimizer.load_state_dict(checkpoint_state["optimizer_state_dict"])
else:
start_epoch = 0
trainset, testset = load_data(data_dir)
test_abs = int(len(trainset) * 0.8)
train_subset, val_subset = random_split(
trainset, [test_abs, len(trainset) - test_abs]
)
trainloader = torch.utils.data.DataLoader(
train_subset, batch_size=int(config["batch_size"]), shuffle=True, num_workers=8
)
valloader = torch.utils.data.DataLoader(
val_subset, batch_size=int(config["batch_size"]), shuffle=True, num_workers=8
)
for epoch in range(start_epoch, 10): # loop over the dataset multiple times
running_loss = 0.0
epoch_steps = 0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
epoch_steps += 1
if i % 2000 == 1999: # print every 2000 mini-batches
print(
"[%d, %5d] loss: %.3f"
% (epoch + 1, i + 1, running_loss / epoch_steps)
)
running_loss = 0.0
# Validation loss
val_loss = 0.0
val_steps = 0
total = 0
correct = 0
for i, data in enumerate(valloader, 0):
with torch.no_grad():
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
val_loss += loss.cpu().numpy()
val_steps += 1
checkpoint_data = {
"epoch": epoch,
"net_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
}
checkpoint = Checkpoint.from_dict(checkpoint_data)
session.report(
{"loss": val_loss / val_steps, "accuracy": correct / total},
checkpoint=checkpoint,
)
print("Finished Training")
正如您所看到的,大部分代码直接从原始示例中适应而来。
测试集准确率
通常,机器学习模型的性能是在一个保留的测试集上测试的,该测试集包含未用于训练模型的数据。我们也将这包装在一个函数中:
def test_accuracy(net, device="cpu"):
trainset, testset = load_data()
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=False, num_workers=2
)
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
该函数还期望一个device参数,因此我们可以在 GPU 上对测试集进行验证。
配置搜索空间
最后,我们需要定义 Ray Tune 的搜索空间。这是一个示例:
config = {
"l1": tune.choice([2 ** i for i in range(9)]),
"l2": tune.choice([2 ** i for i in range(9)]),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}
tune.choice()接受一个从中均匀抽样的值列表。在这个例子中,l1和l2参数应该是介于 4 和 256 之间的 2 的幂次方,因此可以是 4、8、16、32、64、128 或 256。lr(学习率)应该在 0.0001 和 0.1 之间均匀抽样。最后,批量大小是 2、4、8 和 16 之间的选择。
在每次试验中,Ray Tune 现在将从这些搜索空间中随机抽样一组参数的组合。然后,它将并行训练多个模型,并在其中找到表现最佳的模型。我们还使用ASHAScheduler,它将及早终止表现不佳的试验。
我们使用functools.partial将train_cifar函数包装起来,以设置常量data_dir参数。我们还可以告诉 Ray Tune 每个试验应该有哪些资源可用:
gpus_per_trial = 2
# ...
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 8, "gpu": gpus_per_trial},
config=config,
num_samples=num_samples,
scheduler=scheduler,
checkpoint_at_end=True)
您可以指定 CPU 的数量,然后可以将其用于增加 PyTorch DataLoader实例的num_workers。所选数量的 GPU 在每个试验中对 PyTorch 可见。试验没有访问未为其请求的 GPU - 因此您不必担心两个试验使用相同的资源集。
在这里,我们还可以指定分数 GPU,因此像gpus_per_trial=0.5这样的东西是完全有效的。试验将在彼此之间共享 GPU。您只需确保模型仍适合 GPU 内存。
训练模型后,我们将找到表现最佳的模型,并从检查点文件中加载训练好的网络。然后,我们获得测试集准确率,并通过打印报告所有内容。
完整的主函数如下:
def main(num_samples=10, max_num_epochs=10, gpus_per_trial=2):
data_dir = os.path.abspath("./data")
load_data(data_dir)
config = {
"l1": tune.choice([2**i for i in range(9)]),
"l2": tune.choice([2**i for i in range(9)]),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16]),
}
scheduler = ASHAScheduler(
metric="loss",
mode="min",
max_t=max_num_epochs,
grace_period=1,
reduction_factor=2,
)
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 2, "gpu": gpus_per_trial},
config=config,
num_samples=num_samples,
scheduler=scheduler,
)
best_trial = result.get_best_trial("loss", "min", "last")
print(f"Best trial config: {best_trial.config}")
print(f"Best trial final validation loss: {best_trial.last_result['loss']}")
print(f"Best trial final validation accuracy: {best_trial.last_result['accuracy']}")
best_trained_model = Net(best_trial.config["l1"], best_trial.config["l2"])
device = "cpu"
if torch.cuda.is_available():
device = "cuda:0"
if gpus_per_trial > 1:
best_trained_model = nn.DataParallel(best_trained_model)
best_trained_model.to(device)
best_checkpoint = best_trial.checkpoint.to_air_checkpoint()
best_checkpoint_data = best_checkpoint.to_dict()
best_trained_model.load_state_dict(best_checkpoint_data["net_state_dict"])
test_acc = test_accuracy(best_trained_model, device)
print("Best trial test set accuracy: {}".format(test_acc))
if __name__ == "__main__":
# You can change the number of GPUs per trial here:
main(num_samples=10, max_num_epochs=10, gpus_per_trial=0)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to /var/lib/jenkins/workspace/beginner_source/data/cifar-10-python.tar.gz
0% 0/170498071 [00:00<?, ?it/s]
0% 491520/170498071 [00:00<00:34, 4901426.98it/s]
4% 7307264/170498071 [00:00<00:03, 42047898.29it/s]
10% 17629184/170498071 [00:00<00:02, 69798204.67it/s]
16% 27820032/170498071 [00:00<00:01, 82407622.17it/s]
22% 38338560/170498071 [00:00<00:01, 90604441.34it/s]
29% 48726016/170498071 [00:00<00:01, 95049915.99it/s]
35% 59342848/170498071 [00:00<00:01, 98624828.60it/s]
41% 69828608/170498071 [00:00<00:01, 100103452.88it/s]
47% 80707584/170498071 [00:00<00:00, 102701251.79it/s]
54% 91226112/170498071 [00:01<00:00, 103410219.64it/s]
60% 101842944/170498071 [00:01<00:00, 104217418.28it/s]
66% 112394240/170498071 [00:01<00:00, 104577303.94it/s]
72% 122912768/170498071 [00:01<00:00, 104690232.44it/s]
78% 133464064/170498071 [00:01<00:00, 104835011.32it/s]
84% 144015360/170498071 [00:01<00:00, 104975230.73it/s]
91% 154566656/170498071 [00:01<00:00, 105068640.23it/s]
97% 165085184/170498071 [00:01<00:00, 104644047.95it/s]
100% 170498071/170498071 [00:01<00:00, 96529746.41it/s]
Extracting /var/lib/jenkins/workspace/beginner_source/data/cifar-10-python.tar.gz to /var/lib/jenkins/workspace/beginner_source/data
Files already downloaded and verified
2024-02-03 05:16:34,052 WARNING services.py:1816 -- WARNING: The object store is using /tmp instead of /dev/shm because /dev/shm has only 2147479552 bytes available. This will harm performance! You may be able to free up space by deleting files in /dev/shm. If you are inside a Docker container, you can increase /dev/shm size by passing '--shm-size=10.24gb' to 'docker run' (or add it to the run_options list in a Ray cluster config). Make sure to set this to more than 30% of available RAM.
2024-02-03 05:16:34,193 INFO worker.py:1625 -- Started a local Ray instance.
2024-02-03 05:16:35,349 INFO tune.py:218 -- Initializing Ray automatically. For cluster usage or custom Ray initialization, call `ray.init(...)` before `tune.run(...)`.
(pid=2669) /opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
(pid=2669) _torch_pytree._register_pytree_node(
== Status ==
Current time: 2024-02-03 05:16:40 (running for 00:00:05.27)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 2.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (9 PENDING, 1 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | PENDING | | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | PENDING | | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | PENDING | | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | PENDING | | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | PENDING | | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | PENDING | | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | PENDING | | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=2669) Files already downloaded and verified
(func pid=2669) Files already downloaded and verified
(pid=2758) _torch_pytree._register_pytree_node(
(pid=2758) _torch_pytree._register_pytree_node(
(pid=2765) /opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
(pid=2765) _torch_pytree._register_pytree_node(
== Status ==
Current time: 2024-02-03 05:16:46 (running for 00:00:11.10)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 14.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (3 PENDING, 7 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | PENDING | | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=2756) Files already downloaded and verified
(func pid=2765) Files already downloaded and verified
(pid=3549) /opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. [repeated 5x across cluster] (Ray deduplicates logs by default. Set RAY_DEDUP_LOGS=0 to disable log deduplication, or see https://docs.ray.io/en/master/ray-observability/ray-logging.html#log-deduplication for more options.)
(pid=3549) _torch_pytree._register_pytree_node( [repeated 5x across cluster]
(func pid=2669) [1, 2000] loss: 2.332
(func pid=2758) Files already downloaded and verified [repeated 10x across cluster]
== Status ==
Current time: 2024-02-03 05:16:53 (running for 00:00:18.39)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
== Status ==
Current time: 2024-02-03 05:16:58 (running for 00:00:23.40)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=2756) [1, 2000] loss: 2.311
(func pid=3549) Files already downloaded and verified [repeated 2x across cluster]
(func pid=2764) [1, 2000] loss: 2.303
== Status ==
Current time: 2024-02-03 05:17:03 (running for 00:00:28.41)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
== Status ==
Current time: 2024-02-03 05:17:08 (running for 00:00:33.42)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=3549) [1, 2000] loss: 1.855 [repeated 6x across cluster]
== Status ==
Current time: 2024-02-03 05:17:13 (running for 00:00:38.43)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=2760) [1, 4000] loss: 1.031 [repeated 7x across cluster]
== Status ==
Current time: 2024-02-03 05:17:18 (running for 00:00:43.44)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
== Status ==
Current time: 2024-02-03 05:17:23 (running for 00:00:48.45)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
(func pid=2756) [1, 6000] loss: 0.770
(func pid=2764) [1, 6000] loss: 0.681
== Status ==
Current time: 2024-02-03 05:17:28 (running for 00:00:53.46)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: None
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr |
|-------------------------+----------+-----------------+--------------+------+------+-------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 |
+-------------------------+----------+-----------------+--------------+------+------+-------------+
Result for train_cifar_668d1_00006:
accuracy: 0.1208
date: 2024-02-03_05-17-29
done: false
hostname: 8642c088913e
iterations_since_restore: 1
loss: 2.293956341743469
node_ip: 172.17.0.2
pid: 2765
should_checkpoint: true
time_since_restore: 43.53398323059082
time_this_iter_s: 43.53398323059082
time_total_s: 43.53398323059082
timestamp: 1706937449
training_iteration: 1
trial_id: 668d1_00006
Result for train_cifar_668d1_00003:
accuracy: 0.2079
date: 2024-02-03_05-17-31
done: false
hostname: 8642c088913e
iterations_since_restore: 1
loss: 2.028138545417786
node_ip: 172.17.0.2
pid: 2760
should_checkpoint: true
time_since_restore: 45.46037745475769
time_this_iter_s: 45.46037745475769
time_total_s: 45.46037745475769
timestamp: 1706937451
training_iteration: 1
trial_id: 668d1_00003
(func pid=2669) [1, 10000] loss: 0.461 [repeated 5x across cluster]
== Status ==
Current time: 2024-02-03 05:17:37 (running for 00:01:01.57)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | | | | |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | | | | |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | | | | |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 | | | | |
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
Result for train_cifar_668d1_00007:
accuracy: 0.4793
date: 2024-02-03_05-17-40
done: false
hostname: 8642c088913e
iterations_since_restore: 1
loss: 1.4310961763858796
node_ip: 172.17.0.2
pid: 3549
should_checkpoint: true
time_since_restore: 46.97845983505249
time_this_iter_s: 46.97845983505249
time_total_s: 46.97845983505249
timestamp: 1706937460
training_iteration: 1
trial_id: 668d1_00007
(func pid=2758) [1, 8000] loss: 0.575 [repeated 4x across cluster]
== Status ==
Current time: 2024-02-03 05:17:45 (running for 00:01:10.40)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.028138545417786
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | | | | |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | | | | |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 | | | | |
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=2762) [1, 10000] loss: 0.468 [repeated 6x across cluster]
== Status ==
Current time: 2024-02-03 05:17:50 (running for 00:01:15.41)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.028138545417786
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | | | | |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | | | | |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 | | | | |
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
== Status ==
Current time: 2024-02-03 05:17:55 (running for 00:01:20.42)
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.028138545417786
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (2 PENDING, 8 RUNNING)
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00001 | RUNNING | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00004 | RUNNING | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | | | | |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | | | | |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | PENDING | | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | PENDING | | 2 | 2 | 16 | 0.0286986 | | | | |
+-------------------------+----------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=3549) [2, 2000] loss: 1.406
(func pid=2669) [1, 14000] loss: 0.329
Result for train_cifar_668d1_00001:
accuracy: 0.1009
date: 2024-02-03_05-17-58
done: true
hostname: 8642c088913e
iterations_since_restore: 1
loss: 2.3118444224357604
node_ip: 172.17.0.2
pid: 2756
should_checkpoint: true
time_since_restore: 72.15020895004272
time_this_iter_s: 72.15020895004272
time_total_s: 72.15020895004272
timestamp: 1706937478
training_iteration: 1
trial_id: 668d1_00001
Trial train_cifar_668d1_00001 completed.
Result for train_cifar_668d1_00005:
accuracy: 0.3539
date: 2024-02-03_05-17-58
done: false
hostname: 8642c088913e
iterations_since_restore: 1
loss: 1.7180780637741089
node_ip: 172.17.0.2
pid: 2764
should_checkpoint: true
time_since_restore: 72.5149827003479
time_this_iter_s: 72.5149827003479
time_total_s: 72.5149827003479
timestamp: 1706937478
training_iteration: 1
trial_id: 668d1_00005
(func pid=2756) Files already downloaded and verified
Result for train_cifar_668d1_00004:
accuracy: 0.1042
date: 2024-02-03_05-17-59
done: true
hostname: 8642c088913e
iterations_since_restore: 1
loss: 2.317199463367462
node_ip: 172.17.0.2
pid: 2762
should_checkpoint: true
time_since_restore: 73.49483036994934
time_this_iter_s: 73.49483036994934
time_total_s: 73.49483036994934
timestamp: 1706937479
training_iteration: 1
trial_id: 668d1_00004
Trial train_cifar_668d1_00004 completed.
(func pid=2756) Files already downloaded and verified
== Status ==
Current time: 2024-02-03 05:18:04 (running for 00:01:29.51)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=2669) [1, 16000] loss: 0.288 [repeated 4x across cluster]
(func pid=2762) Files already downloaded and verified [repeated 2x across cluster]
== Status ==
Current time: 2024-02-03 05:18:09 (running for 00:01:34.53)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: None | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 1 | 43.534 | 2.29396 | 0.1208 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
Result for train_cifar_668d1_00006:
accuracy: 0.1824
date: 2024-02-03_05-18-11
done: false
hostname: 8642c088913e
iterations_since_restore: 2
loss: 2.1994362588882446
node_ip: 172.17.0.2
pid: 2765
should_checkpoint: true
time_since_restore: 84.67864155769348
time_this_iter_s: 41.14465832710266
time_total_s: 84.67864155769348
timestamp: 1706937491
training_iteration: 2
trial_id: 668d1_00006
(func pid=2756) [1, 2000] loss: 2.138 [repeated 5x across cluster]
== Status ==
Current time: 2024-02-03 05:18:16 (running for 00:01:40.64)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -2.1994362588882446 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 1 | 45.4604 | 2.02814 | 0.2079 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
Result for train_cifar_668d1_00003:
accuracy: 0.2459
date: 2024-02-03_05-18-16
done: false
hostname: 8642c088913e
iterations_since_restore: 2
loss: 1.9869435796737671
node_ip: 172.17.0.2
pid: 2760
should_checkpoint: true
time_since_restore: 90.14830899238586
time_this_iter_s: 44.687931537628174
time_total_s: 90.14830899238586
timestamp: 1706937496
training_iteration: 2
trial_id: 668d1_00003
== Status ==
Current time: 2024-02-03 05:18:21 (running for 00:01:46.25)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -2.0931899192810057 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 2 | 90.1483 | 1.98694 | 0.2459 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 1 | 46.9785 | 1.4311 | 0.4793 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=2764) [2, 4000] loss: 0.814 [repeated 2x across cluster]
Result for train_cifar_668d1_00007:
accuracy: 0.5056
date: 2024-02-03_05-18-25
done: false
hostname: 8642c088913e
iterations_since_restore: 2
loss: 1.4163358207702637
node_ip: 172.17.0.2
pid: 3549
should_checkpoint: true
time_since_restore: 91.53078818321228
time_this_iter_s: 44.55232834815979
time_total_s: 91.53078818321228
timestamp: 1706937505
training_iteration: 2
trial_id: 668d1_00007
(func pid=2758) [1, 14000] loss: 0.310 [repeated 3x across cluster]
== Status ==
Current time: 2024-02-03 05:18:30 (running for 00:01:54.95)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -1.9869435796737671 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 2 | 90.1483 | 1.98694 | 0.2459 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 2 | 91.5308 | 1.41634 | 0.5056 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
== Status ==
Current time: 2024-02-03 05:18:35 (running for 00:01:59.96)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -1.9869435796737671 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 2 | 90.1483 | 1.98694 | 0.2459 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 2 | 91.5308 | 1.41634 | 0.5056 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=2762) [1, 6000] loss: 0.779 [repeated 4x across cluster]
== Status ==
Current time: 2024-02-03 05:18:40 (running for 00:02:04.97)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -1.9869435796737671 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 2 | 90.1483 | 1.98694 | 0.2459 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 2 | 91.5308 | 1.41634 | 0.5056 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
(func pid=3549) [3, 2000] loss: 1.268 [repeated 3x across cluster]
== Status ==
Current time: 2024-02-03 05:18:45 (running for 00:02:09.98)
Using AsyncHyperBand: num_stopped=2
Bracket: Iter 8.000: None | Iter 4.000: None | Iter 2.000: -1.9869435796737671 | Iter 1.000: -2.1610474435806273
Logical resource usage: 16.0/16 CPUs, 0/1 GPUs (0.0/1.0 accelerator_type:M60)
Result logdir: /var/lib/jenkins/ray_results/train_cifar_2024-02-03_05-16-35
Number of trials: 10/10 (8 RUNNING, 2 TERMINATED)
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
| Trial name | status | loc | batch_size | l1 | l2 | lr | iter | total time (s) | loss | accuracy |
|-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------|
| train_cifar_668d1_00000 | RUNNING | 172.17.0.2:2669 | 2 | 16 | 1 | 0.00213327 | | | | |
| train_cifar_668d1_00002 | RUNNING | 172.17.0.2:2758 | 2 | 256 | 64 | 0.0113784 | | | | |
| train_cifar_668d1_00003 | RUNNING | 172.17.0.2:2760 | 8 | 64 | 256 | 0.0274071 | 2 | 90.1483 | 1.98694 | 0.2459 |
| train_cifar_668d1_00005 | RUNNING | 172.17.0.2:2764 | 4 | 8 | 64 | 0.000353097 | 1 | 72.515 | 1.71808 | 0.3539 |
| train_cifar_668d1_00006 | RUNNING | 172.17.0.2:2765 | 8 | 16 | 4 | 0.000147684 | 2 | 84.6786 | 2.19944 | 0.1824 |
| train_cifar_668d1_00007 | RUNNING | 172.17.0.2:3549 | 8 | 256 | 256 | 0.00477469 | 2 | 91.5308 | 1.41634 | 0.5056 |
| train_cifar_668d1_00008 | RUNNING | 172.17.0.2:2756 | 8 | 128 | 256 | 0.0306227 | | | | |
| train_cifar_668d1_00009 | RUNNING | 172.17.0.2:2762 | 2 | 2 | 16 | 0.0286986 | | | | |
| train_cifar_668d1_00001 | TERMINATED | 172.17.0.2:2756 | 4 | 1 | 2 | 0.013416 | 1 | 72.1502 | 2.31184 | 0.1009 |
| train_cifar_668d1_00004 | TERMINATED | 172.17.0.2:2762 | 4 | 16 | 2 | 0.056666 | 1 | 73.4948 | 2.3172 | 0.1042 |
+-------------------------+------------+-----------------+--------------+------+------+-------------+--------+------------------+---------+------------+
Result for train_cifar_668d1_00008:
accuracy: 0.2278
date: 2024-02-03_05-18-45
done: false
hostname: 8642c088913e
iterations_since_restore: 1
loss: 2.150844239425659
node_ip: 172.17.0.2
pid: 2756
should_checkpoint: true
time_since_restore: 47.30649995803833
time_this_iter_s: 47.30649995803833
time_total_s: 47.30649995803833
timestamp: 1706937525
training_iteration: 1
trial_id: 668d1_00008
如果您运行代码,示例输出可能如下所示:
Number of trials: 10/10 (10 TERMINATED)
+-----+--------------+------+------+-------------+--------+---------+------------+
| ... | batch_size | l1 | l2 | lr | iter | loss | accuracy |
|-----+--------------+------+------+-------------+--------+---------+------------|
| ... | 2 | 1 | 256 | 0.000668163 | 1 | 2.31479 | 0.0977 |
| ... | 4 | 64 | 8 | 0.0331514 | 1 | 2.31605 | 0.0983 |
| ... | 4 | 2 | 1 | 0.000150295 | 1 | 2.30755 | 0.1023 |
| ... | 16 | 32 | 32 | 0.0128248 | 10 | 1.66912 | 0.4391 |
| ... | 4 | 8 | 128 | 0.00464561 | 2 | 1.7316 | 0.3463 |
| ... | 8 | 256 | 8 | 0.00031556 | 1 | 2.19409 | 0.1736 |
| ... | 4 | 16 | 256 | 0.00574329 | 2 | 1.85679 | 0.3368 |
| ... | 8 | 2 | 2 | 0.00325652 | 1 | 2.30272 | 0.0984 |
| ... | 2 | 2 | 2 | 0.000342987 | 2 | 1.76044 | 0.292 |
| ... | 4 | 64 | 32 | 0.003734 | 8 | 1.53101 | 0.4761 |
+-----+--------------+------+------+-------------+--------+---------+------------+
Best trial config: {'l1': 64, 'l2': 32, 'lr': 0.0037339984519545164, 'batch_size': 4}
Best trial final validation loss: 1.5310075663924216
Best trial final validation accuracy: 0.4761
Best trial test set accuracy: 0.4737
为了避免浪费资源,大多数试验都被提前停止了。表现最好的试验实现了约 47%的验证准确率,这可以在测试集上得到确认。
就是这样!您现在可以调整 PyTorch 模型的参数了。
脚本的总运行时间:(9 分钟 49.698 秒)
下载 Python 源代码:hyperparameter_tuning_tutorial.py
下载 Jupyter 笔记本:hyperparameter_tuning_tutorial.ipynb
Sphinx-Gallery 生成的画廊