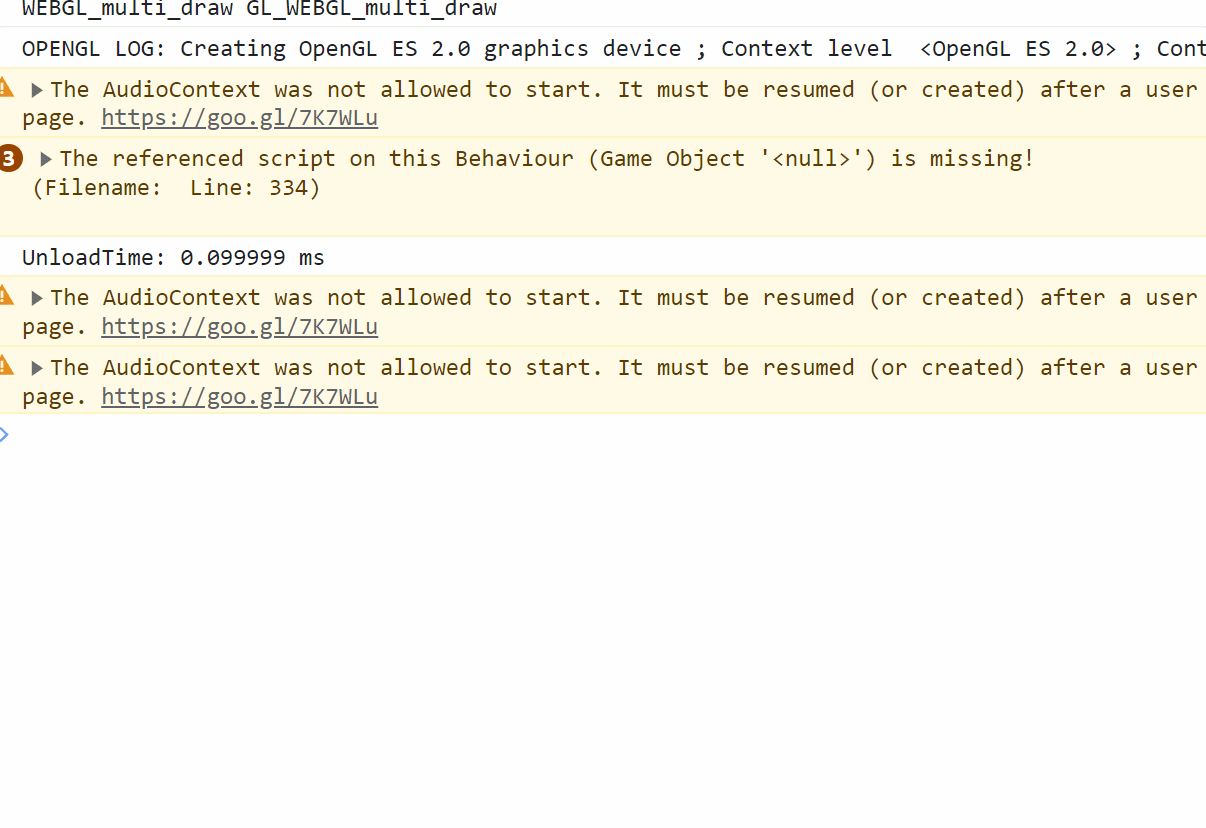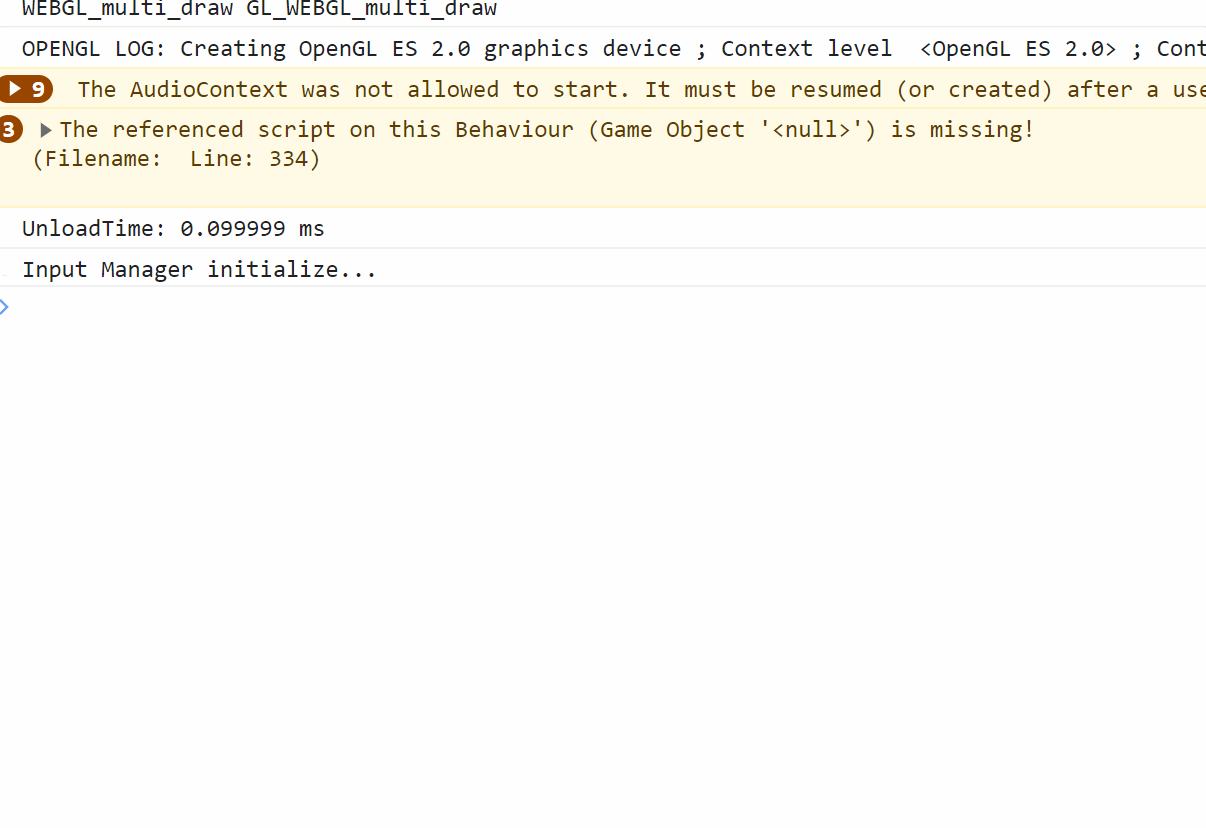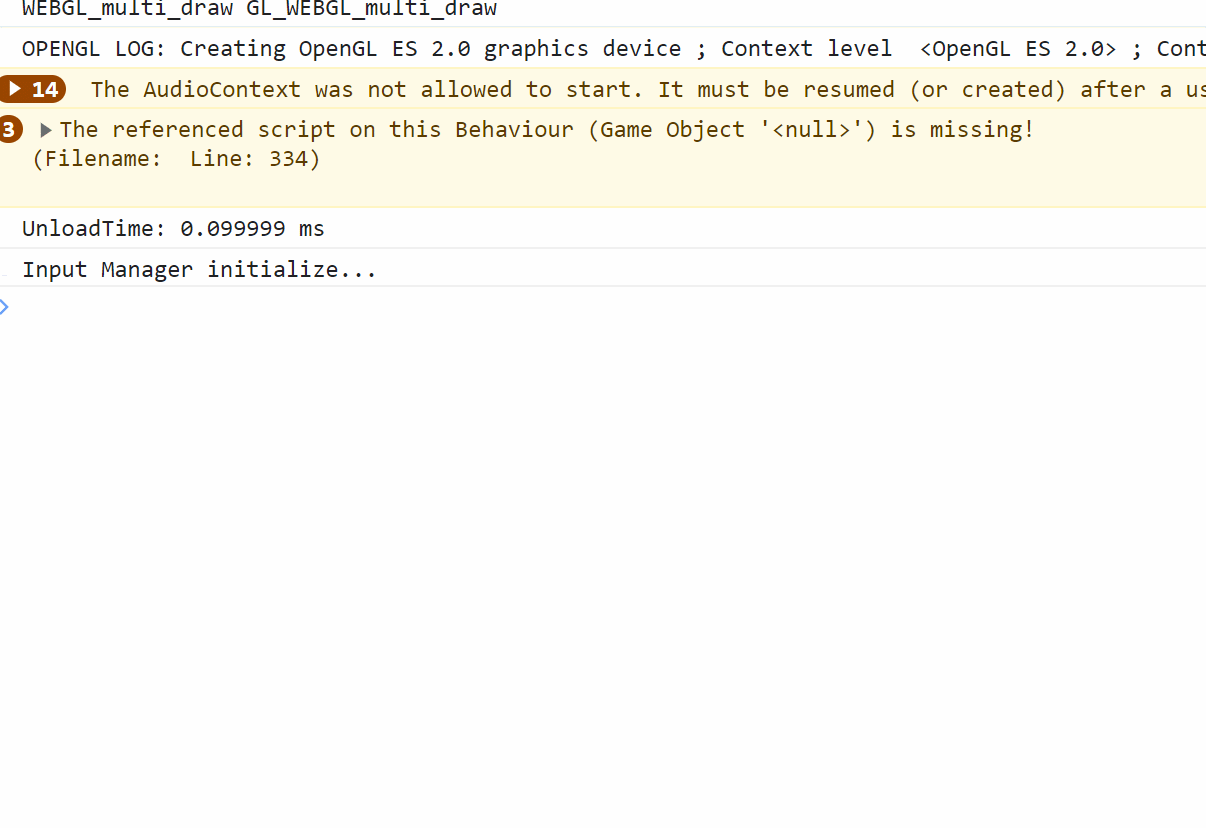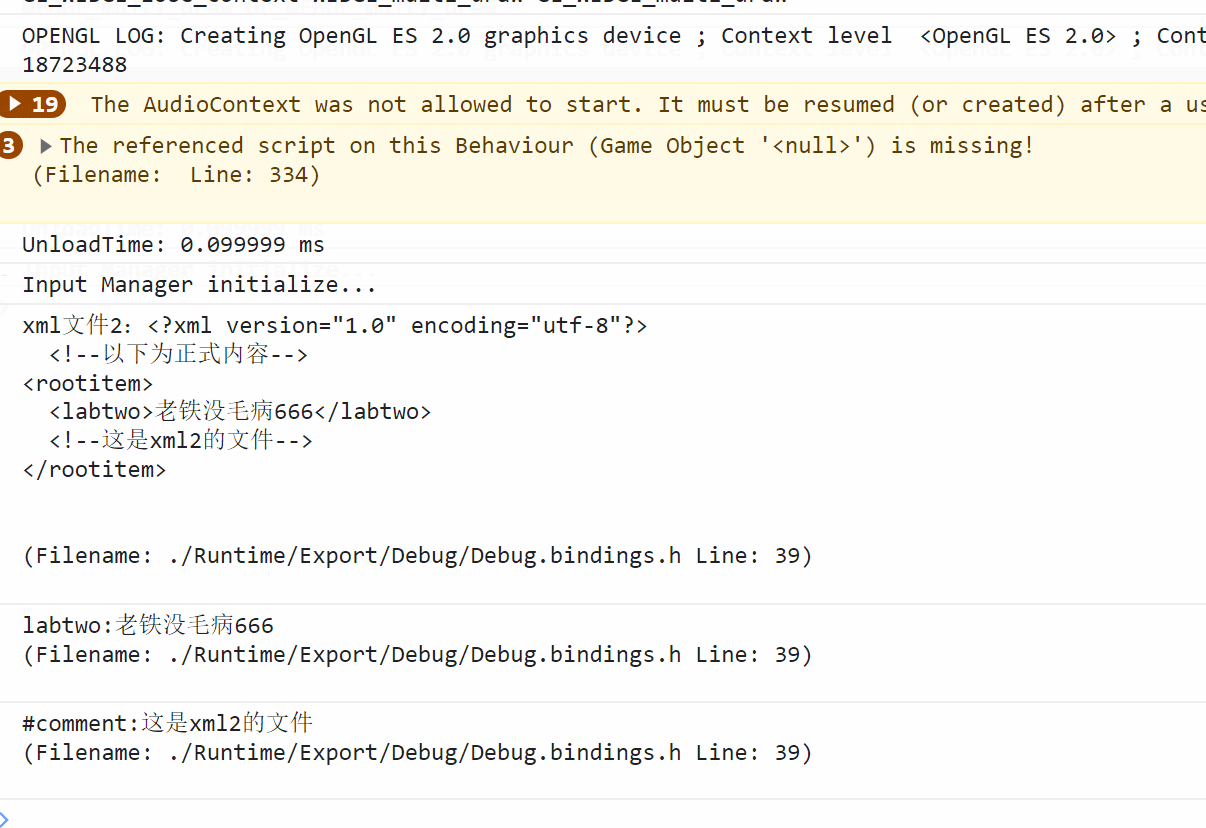
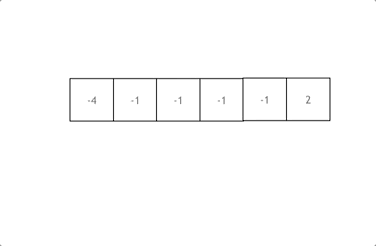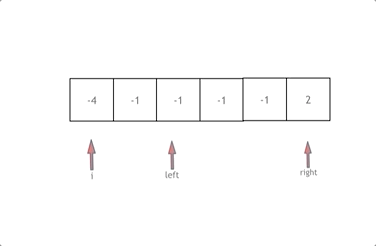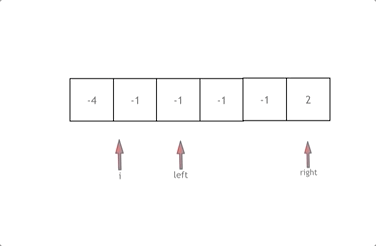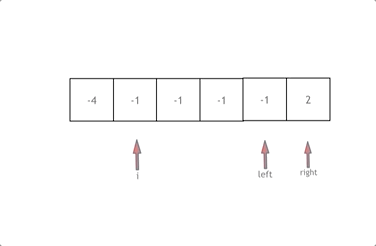
本文重点分析 Nebula Siwi 智能问答思路,具体代码可参考[2],使用的数据集为 Basketballplayer[3]。部分数据和 schema 如下所示:

一.智能问答可实现的功能
1.Nebula Siwi 源码整体结构
主要包括前段(Vue)和后端(Flask)代码结构,整体结构如下所示:

2.Basketballplayer 数据集介绍
Basketballplayer 数据集简介可参考文献[7]NebulaGraph 手工和 Python 操作,将该数据集通过 Python 脚本导入 NebulaGraph 中参考脚本 import_data.py,当然也可以通过 NebulaGraph 命令进行导入(不做介绍,参考文献[8]什么是 nGQL - NebulaGraph Database 手册)。如下所示:

说明:因为本地数据库已经有了一个 basketballplayer 的图空间了,索引本次导入数据使用的是 basketballplayers 图空间。
3.QA 可实现的功能
"""
Sorry I don't understand your questions for now. Here are supported question patterns:
# 对不起,我现在还不明白你的问题。以下是支持的问题模式:
relation: # 关系
- What is the relationship between Yao Ming and Lakers? # 姚明和湖人的关系是什么?
- How does Yao Ming and Lakers connected? # 姚明和湖人是怎么连接的?
serving: # 服务
- Which team had Yao Ming served? # 姚明曾经效力过哪些球队?
friendship: # 友谊
- Whom does Tim Duncan follow? # 邓肯关注了哪些人?
- Who are Yao Ming's friends? # 姚明的朋友有哪些?
"""
使用微信开发工具测试效果,如下所示:

二.智能问题功能实现思路
1.前端实现思路[4]
1.1 安装依赖包
WebStorm 打开 Vue 项目后,执行命令安装包 npm install --save-dev @vue/cli-service,然后再执行命令 npm install 和 npm run dev,如下所示:

1.2 修改 package.json 文件
需要说明的是需要修改 package.json,如下所示:
{
"name": "siwi_frontend",
"version": "1.0.0",
"description": "",
"scripts": {
"i": "npm install",
"dev": "vue-cli-service serve",
"build": "vue-cli-service build"
},
"dependencies": {
"@vue/cli-service-global": "^4.5.19",
"axios": "^0.21.1",
"vue-bot-ui": "^0.2.6",
"vue-web-speech": "^0.2.3"
},
"devDependencies": {
"@vue/cli-service": "^5.0.8"
}
}
1.3 增加vue.config.js文件
同时还需要增加一个 vue.config.js 文件,用来解决前端 8080 端口到后端 5000 端口的跨域问题,如下所示:
module.exports = {
devServer: {
proxy: 'http://localhost:5000',
},
};
1.4 通过浏览器进行对话
使用浏览器打开链接 http://localhost:8080/,如下所示:

2.后端实现思路[2]
PyCharm 打开 Flask 项目,直接运行 python F:/ConversationSystem/nebula-siwi/src/siwi/app/__init__.py,如下所示:

三.后端代码具体实现
1.整体思路
整体流程应该从 F:\ConversationSystem\nebula-siwi\src\siwi\app\__init__.py 看起,初始化连接池和机器人(初始化分类器和动作),然后启动 Flask 服务。如下所示:

其中,初始化连接池使用的 Python 类库为 nebula3,目录结构如下所示:

初始化机器人又包括初始化分类器(classifier)和动作(action)2 个部分。
2.分类器(classifier)实现思路
2.1 增加 main()函数
加了一个 main()函数来测试分类器类,如下所示:

2.2 根据 sentence 识别 intent
分类器实现比较简单,主要是根据 sentence 识别 intent,实现代码如下所示:
def get_matched_intents(self, sentence: str) -> tuple:
"""
根据sentence识别intent
"""
intents_matched = set()
for word in self.intents_map.keys():
if word in sentence:
intents_matched.add(
self.intents_map[word])

2.3 根据 sentence 返回 entity
除此之外,还有根据 sentence 返回 entity。如下所示:
def get_matched_entities(self, sentence: str) -> dict:
"""
消耗一个句子与ahocorasick匹配
返回一个dict:{entity: entity_type}
"""
entities_matched = []
for item in self.entity_tree.iter(sentence):
entities_matched.append(item[1][1])
return {
entity: self.entity_type_map[entity] for entity in entities_matched
}
self.entity_tree.iter(sentence) 是 ahocorasick.Automaton() 类的一个方法,用于在 Aho-Corasick 自动机中迭代搜索输入的字符串。在这段代码中,self.entity_tree 是一个 Aho-Corasick 自动机,sentence 是要搜索的字符串。iter() 方法会在自动机中搜索 sentence,并返回一个迭代器。这个迭代器的每个元素都是一个元组,包含两个元素:匹配的单词在 sentence 中的结束位置和该单词在 add_word() 方法中设置的值。
例如,如果在自动机中添加了单词 “apple”,并将其值设置为 (0, "apple"),然后在字符串 “I have an apple” 中搜索,那么 iter() 方法将返回一个迭代器,其中包含一个元组 (13, (0, "apple"))。这表示 “apple” 在 “I have an apple” 中的结束位置是 13,其值是 (0, "apple")。
因此,self.entity_tree.iter(sentence) 被用于在输入的句子中搜索实体,这段代码将在句子中搜索所有的实体,并将找到的实体添加到 entities_matched 列表中。这里的实体类型包括球员(player)和球队(team)2 种类型。
2.4 自动机实现过程
(1)self.entity_tree 自动机对象
重点详细介绍下 self.entity_tree 是实现过程,如下所示:
self.entity_tree = ahocorasick.Automaton() # 构建实体树,自动机
for index, entity in enumerate(self.entity_type_map.keys()): # 遍历实体类型映射
self.entity_tree.add_word(entity, (index, entity)) # 添加实体
self.entity_tree.make_automaton() # 构建自动机

(2)ahocorasick.Automaton()自动机介绍
ahocorasick.Automaton() 是一个来自 pyahocorasick 库的方法,用于创建一个 Aho-Corasick 自动机。Aho-Corasick 算法是一种用于在输入文本中查找多个模式串的高效算法。
在这段代码中,self.entity_tree = ahocorasick.Automaton() 创建了一个 Aho-Corasick 自动机实例,并将其赋值给 self.entity_tree。这个自动机将用于后续的实体识别和意图识别。
Aho-Corasick 自动机的工作原理是,首先构建一个有向图(通常称为 “trie” 或 “前缀树”),其中每个节点代表一个模式串的前缀。然后,对于输入文本中的每个字符,自动机都会沿着图的边移动,匹配尽可能长的模式串。
这种方法的优点是,无论模式串的数量或长度如何,匹配过程的时间复杂度都是线性的,即与输入文本的长度成正比。这使得 Aho-Corasick 算法非常适合于处理大量模式串和大量输入文本的情况。
(3)add_word()方法介绍
add_word() 是 ahocorasick.Automaton() 类的一个方法,用于向 Aho-Corasick 自动机中添加单词(或者说模式串)。
在 add_word() 方法中,需要传入两个参数:word 和 value。word 是想要添加到自动机中的单词,value 是与这个单词关联的值。这个值可以是任何想要的数据类型,它将在后续的搜索过程中返回。add_word() 方法被用于添加实体到自动机中:
for index, entity in enumerate(self.entity_type_map.keys()): # 遍历实体类型映射
self.entity_tree.add_word(entity, (index, entity)) # 添加实体
在这段代码中,entity 是要添加的单词,(index, entity) 是与这个单词关联的值。这样,在后续的搜索过程中,当匹配到这个单词时,就可以返回这个值,从而知道这个单词在原始数据中的位置和内容。
(4)make_automaton()方法介绍
make_automaton() 是 ahocorasick.Automaton() 类的一个方法,用于构建 Aho-Corasick 自动机。在添加所有单词(或模式串)到 Aho-Corasick 自动机后,需要调用 make_automaton() 方法来构建自动机。这个方法会创建额外的失败链接,这些链接在搜索过程中用于在不匹配的情况下跳转到其它可能的匹配位置。
在本文的代码中,make_automaton() 方法在添加所有实体到自动机后被调用:
self.entity_tree.make_automaton() # 构建自动机
这段代码将构建一个完整的 Aho-Corasick 自动机,该自动机可以用于在输入文本中高效地查找实体。
2.5 意图(intent)到动作(action)映射


3.动作(action)实现思路
3.1 增加 main()函数
加了一个 main()函数来测试各种动作类,如下所示:

然后就是根据意图(intent)+ 实体(entity)得到动作(action)的类型,包括 FallbackAction(SiwiActionBase)、RelationshipAction(SiwiActionBase)、ServeAction(SiwiActionBase)和FollowAction(SiwiActionBase)。
其中,self.intent_map 对应的数据结构和内容,如下所示:

3.2 FallbackAction(SiwiActionBase) 类
class FallbackAction(SiwiActionBase):
def __init__(self, intent):
super().__init__(intent) # 使用intent初始化SiwiActionBase
def execute(self, connection_pool=None):
"""
TBD: query some information via nbi_api in fallback case:
https://github.com/swar/nba_api/blob/master/docs/examples/Basics.ipynb
"""
return """
Sorry I don't understand your questions for now. Here are supported question patterns:
# 对不起,我现在还不明白你的问题。以下是支持的问题模式:
relation: # 关系
- What is the relationship between Yao Ming and Lakers? # 姚明和湖人的关系是什么?
- How does Yao Ming and Lakers connected? # 姚明和湖人是怎么连接的?
serving: # 服务
- Which team had Yao Ming served? # 姚明曾经效力过哪些球队?
friendship: # 友谊
- Whom does Tim Duncan follow? # 邓肯关注了哪些人?
- Who are Yao Ming's friends? # 姚明的朋友有哪些?
"""
这个是 fallback 对应的动作 FallbackAction,就是当 intent 不在 relation、serving 和 friendship 中时,要提示用户应该怎么提问。
3.3 RelationshipAction(SiwiActionBase) 类
以"Yao Ming 和 Rockets 的关系是什么?"为例进行介绍,核心代码如下所示:
query = ( # 查询语句,查找两个实体之间的关系
f'USE basketballplayer;'
f'FIND NOLOOP PATH '
f'FROM "{self.left_vid}" TO "{self.right_vid}" '
f'OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;'
)
# 举个例子
USE basketballplayer;
FIND NOLOOP PATH FROM "player133" TO "team202" OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;
在图中查找从球员"player133"到球队"team202"的最长 4 步内无循环路径,并将路径存储在变量"path"中,以别名"p"返回。详细命令解释如下所示:
| 命令 | 解释 |
|---|---|
FIND NOLOOP PATH | 这部分指定了查询的类型,即查找无循环路径的图查询。 |
FROM "player133" TO "team202" | 指定了查询的起始点和终点,即从"player133"(球员编号为 133)出发,找到通往"team202"(球队编号为 202)的路径。 |
OVER * | 这部分表示沿着所有类型的边进行遍历。通常,"*"用于表示所有边的类型(follow 和 serve)。 |
BIDIRECT | 表示查询是双向的,即可以沿着边的两个方向进行遍历。 |
UPTO 4 STEPS | 限定了路径的最大步数为 4 步,即查找包括最多 4 个边的路径。 |
YIELD path AS p | 这部分定义了查询结果的输出格式,将路径存储在一个名为"path"的变量中,并使用别名"p"返回。 |
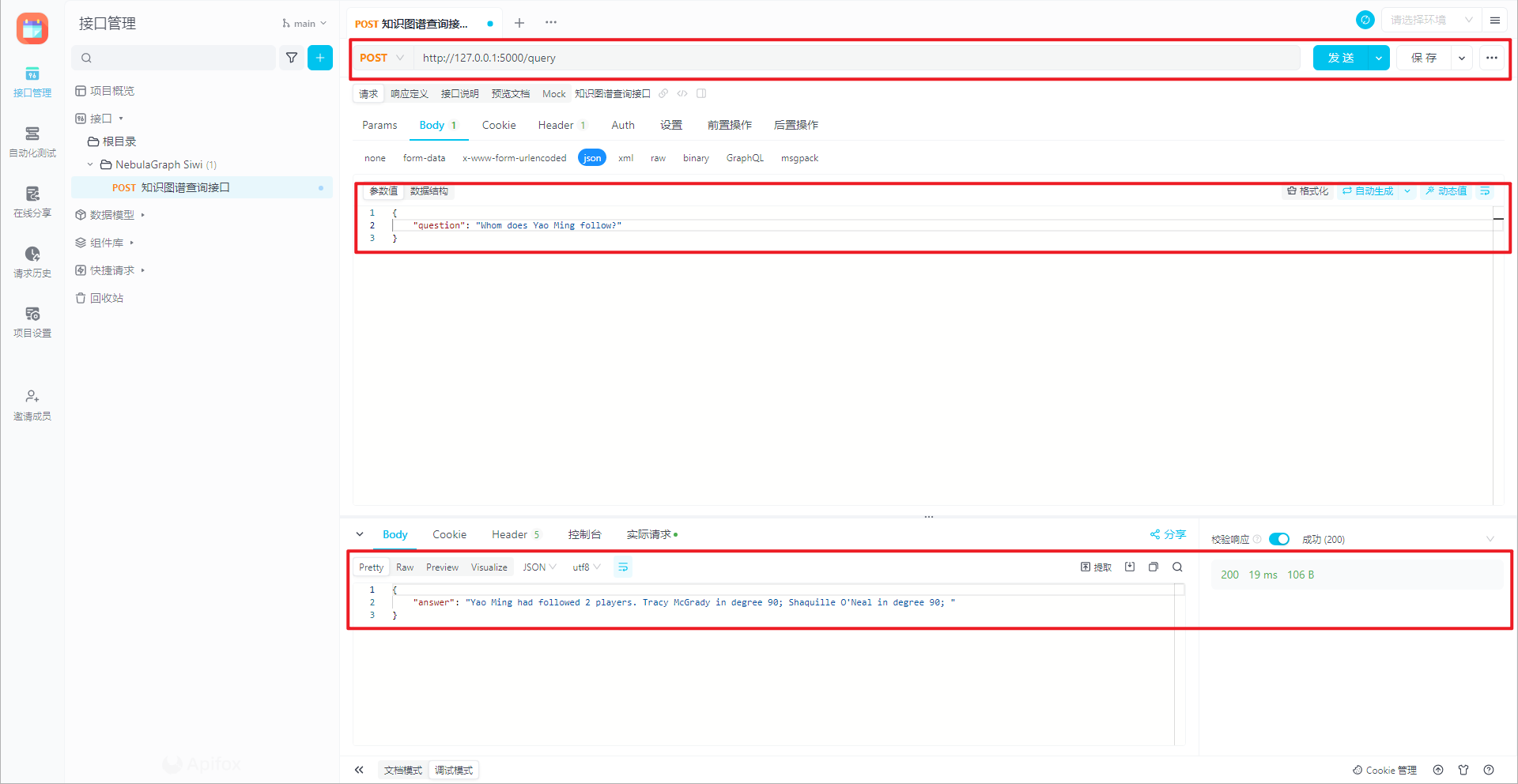
输出结果如下所示:
[DEBUG] RelationshipAction intent: {'entities': {'Yao Ming': 'player133', 'Rockets': 'team202'}, 'intents': ['relationship']}
[DEBUG] query for RelationshipAction :
USE basketballplayers;FIND NOLOOP PATH FROM "player133" TO "team202" OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;
There are at least 6 relations between Yao Ming and Rockets, one relation path is: Yao Ming serves Rockets.
使用 NebulaGraph Studio 查询结果,如下所示:

3.4 ServeAction(SiwiActionBase) 类
以"姚明曾经效力过哪些球队?"为例进行介绍,核心代码如下所示:
query = (
f'USE basketballplayers;'
f'MATCH p=(v)-[e:serve*1]->(v1) '
f'WHERE id(v) == "{ self.player0_vid }" '
f' RETURN p LIMIT 100;'
)
#举个例子
USE basketballplayers;
MATCH p=(v)-[e:serve*1]->(v1) WHERE id(v) == "player133" RETURN p LIMIT 100;
这个 Nebula Graph 查询的目的是查找从指定球员节点(ID 为"player133")出发,通过"serve"边到达其他节点的路径,并返回这些路径。查询结果将包含路径信息,其中路径由节点 v、边 e 和节点 v1 组成。这个查询最多返回 100 条符合条件的路径。详细命令解释,如下所示:
| 命令 | 解释 |
|---|---|
MATCH p=(v)-[e:serve*1]->(v1) | 这部分指定了查询的模式。它创建了一个模式 p,其中包含了一个从节点 v 出发、经过边 e(带有 serve 标签,*1 表示 1 跳,即一步)到达节点 v1 的路径。这表示查询从一个球员节点(v)通过"serve"边到达另一个节点(v1)的路径。 |
WHERE id(v) == "player133" | 这部分是一个过滤条件,限定了节点 v 的 ID 必须等于"player133"。这用于筛选起始节点是"player133"的路径。 |
RETURN p | 这部分指定了要返回的结果。在这里,返回整个路径 p。 |
LIMIT 100 | 这是一个可选的限制条件,用于限制返回的结果数量,防止返回太多结果。 |
接口调用如下所示:

3.5 FollowAction(SiwiActionBase) 类
以"姚明的朋友有哪些?或姚明关注了哪些人?"为例进行介绍,核心代码如下所示:
query = (
f'USE basketballplayers;'
f'MATCH p=(v)-[e:follow*1]->(v1) '
f'WHERE id(v) == "{ self.player0_vid }" '
f' RETURN p LIMIT 100;'
)
# 举个例子
USE basketballplayers;
MATCH p=(v)-[e:follow*1]->(v1) WHERE id(v) == "player133" RETURN p LIMIT 100;
这个 Nebula Graph 查询的目的是查找从指定球员节点(ID 为"player133")出发,通过"follow"边到达其它节点的路径,并返回这些路径。查询结果将包含路径信息,其中路径由节点 v、边 e 和节点 v1 组成。这个查询最多返回 100 条符合条件的路径。详细命令解释,如下所示:
| 命令 | 解释 |
|---|---|
MATCH p=(v)-[e:follow*1]->(v1) | 这部分指定了查询的模式。它创建了一个模式 p,其中包含了一个从节点 v 出发、经过边 e(带有 follow 标签,*1 表示 1 跳,即一步)到达节点 v1 的路径。这表示查询从一个球员节点(v)通过"follow"边到达另一个节点(v1)的路径。 |
WHERE id(v) == "player133" | 这部分是一个过滤条件,限定了节点 v 的 ID 必须等于"player133"。这用于筛选起始节点是"player133"的路径。 |
RETURN p | 这部分指定了要返回的结果。在这里,返回整个路径 p。 |
LIMIT 100: | 这是一个可选的限制条件,用于限制返回的结果数量,防止返回太多结果。 |
接口调用如下所示:
参考文献
[1] Nebula Siwi 基于图数据库的智能问答助手:https://siwei.io/nebula-siwi/
[2] Nebula Siwi GitHub:https://github.com/wey-gu/nebula-siwi/
[3] 示例数据 Basketballplayer:https://docs.nebula-graph.com.cn/2.6.2/3.ngql-guide/1.nGQL-overview/1.overview/#basketballplayer
[4] Siwi Frontend:https://github.com/wey-gu/nebula-siwi/tree/main/src/siwi_frontend
[5] pyahocorasick:https://pyahocorasick.readthedocs.io/en/latest/#aho-corasick-methods
[6] NLP 模式高效匹配技术总结:https://hub.baai.ac.cn/view/22048
[7] NebulaGraph 手工和 Python 操作:https://z0yrmerhgi8.feishu.cn/wiki/YnYDwyU05iT0SAkZNtocArffniM
[8] 什么是 nGQL:https://docs.nebula-graph.com.cn/3.6.0/3.ngql-guide/1.nGQL-overview/1.overview/
[9] Nebula Siwi:基于图数据库的智能问答助手思路分析(源码链接):https://github.com/ai408/nlp-engineering/tree/main/``知识工程-知识图谱/NebulaGraph实战/19-Nebula Siwi:基于图数据库的智能问答助手思路分析
[10] Nebula Siwi:基于图数据库的智能问答助手思路分析:https://www.bilibili.com/video/BV1A6421V7cH/