持久化
何为持久化?
MySQL的事务有四个比较核心的特征:原子性、一致性、持久性和隔离性,这里的持久性和持久化说的是一个事,简单来说,数据存储在硬盘上就是持久,存在内存上那就是不持久(重启之后,这个数据还在就是持久),但是redis是一个内存数据库,在内存中想要实现持久化,就需要redis将数据存储到硬盘上。
但是redis一大优势就是快,而快的前提是将数据存储到内存上,似乎二者发生了冲突,于是redis决定:插入数据,内存、硬盘都插入数据,取出数据,只从内存读取数据。redis重启,内存恢复数据就是从硬盘中恢复就ok了。
接下来展示几种具体实现持久化的策略 : RDB和AOF,二者的区别简单来说就是:RDB会定期去更新备份资料,AOF是每次新数据来了,就实时更新备份资料。
RDB
RDB会定期的将内存中的数据,存储到硬盘中,并生成一个快照。何为快照?redis给内存中当前存储的这些数据拍个照片,生成一个文件存储到硬盘中,当redis想要恢复内存的时候,就拿着快照,就找硬盘要之前的数据。
这里说 定期 实际上是有俩个具体操作的 :
1、手动触发 :程序员在redis客户端通过手动的方式,也就是执行特定的命令来实现快照生成,save和bgsave
而save的话,当其执行的时候,redis会全力以赴的执行快照拍取,可能会出现堵塞的情况。
bgsave则是后台运行save,不会影响其他redis命令执行的,这里靠的是多进程实现的。
bgsave实现流程
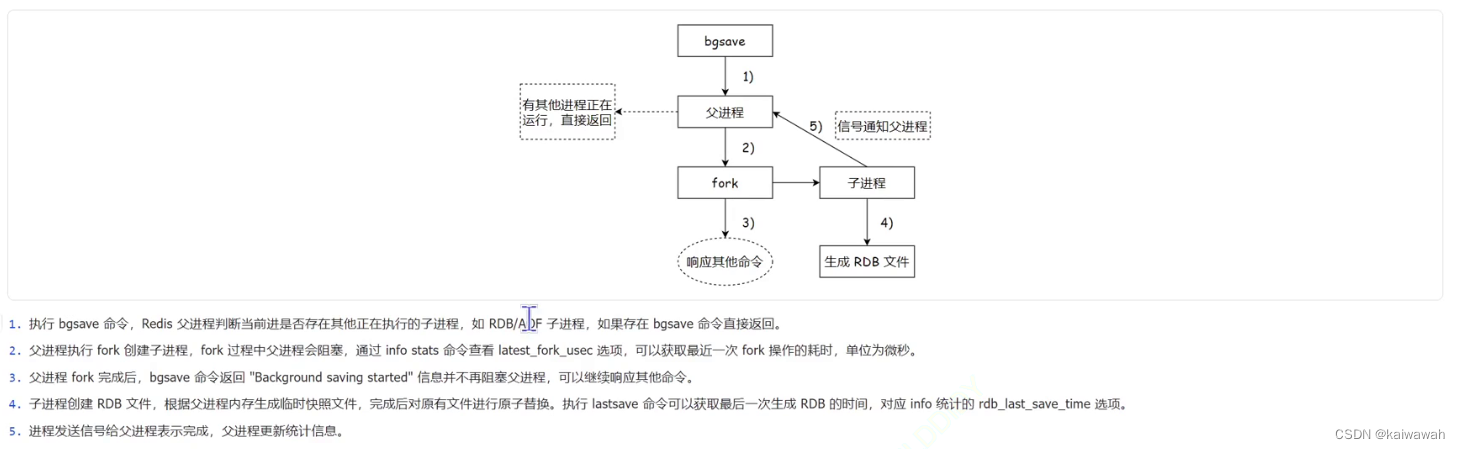
1、判定当前其他进程执行了bgsave命令,有的话直接返回 没必要重复存储
2、如果没有其他子进程执行的话,就fork创建一个子进程出来
fork创建子进程是简单且粗暴的,将父进程完全复制出来一份作为子进程,复制PCB、redis server中的键值对数据等也是完全复制到子进程的,因此将子进程这个克隆体进行持久化操作也就是将父进程这个本体进行持久化咯,并且进行内存拷贝的时候,使用的策略是写时拷贝:如果子进程和父进程数据完全一样,不会真正的去拷贝数据(父子其实用的是一份内存数据),而当某一方想要修改数据的时候(执行写操作),二者的内存空间才会发生真正的复制拷贝,真正的划分了。
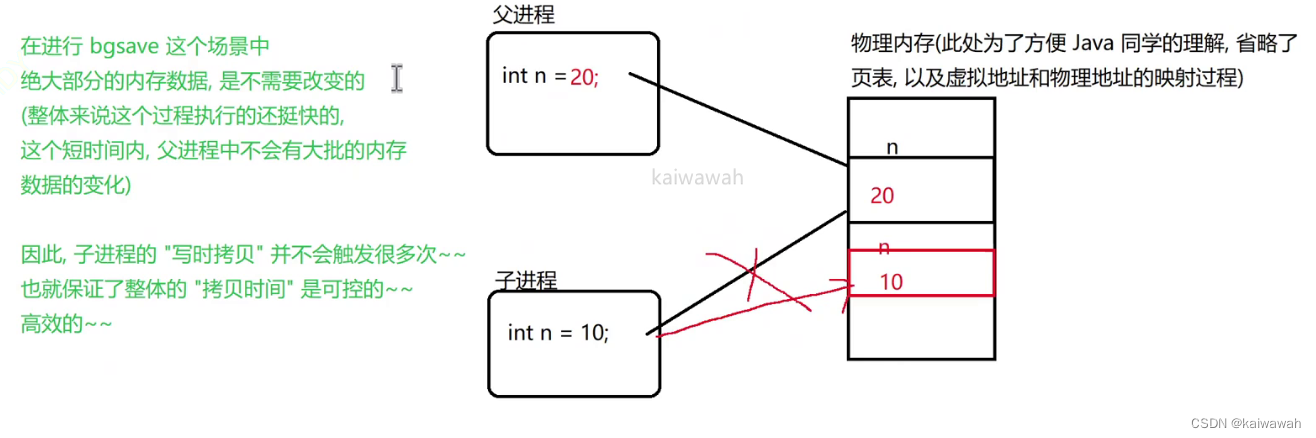
3、子进程负责写文件生成快照,父进程继续接收客户端请求 继续提供服务。
4、子进程完成持久化之后,会通知父进程,父进程会更新一些统计信息,子进程就可以结束销毁了。
RDB文件
RDB文件是存放在redis工作目录中的,rdb机制生成镜像文件,这个文件是二进制的形式(压缩后)出现的。
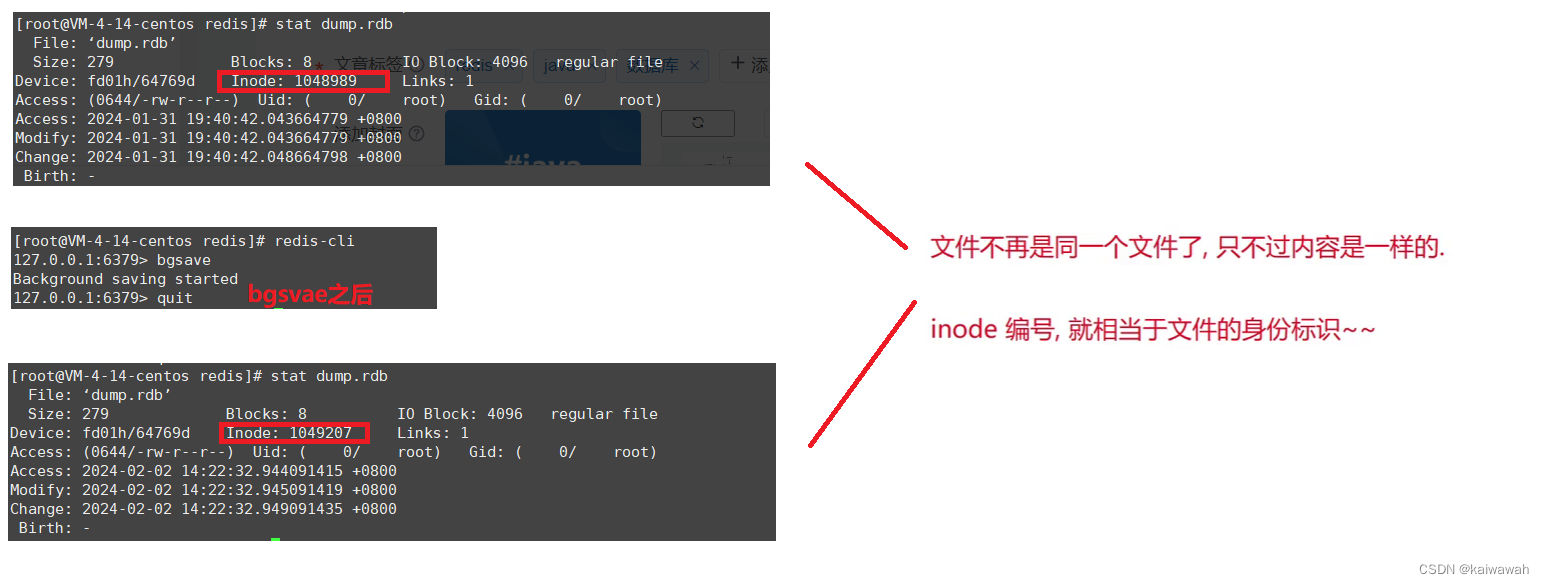
rdb是可以触发多次的:当生成RDB镜像操作的时候,先把这个要生成的快照数据存放到一个临时的文件中,当这个快照文件生成完毕替换之前的rdb文件。确保rbd文件始终只有一个



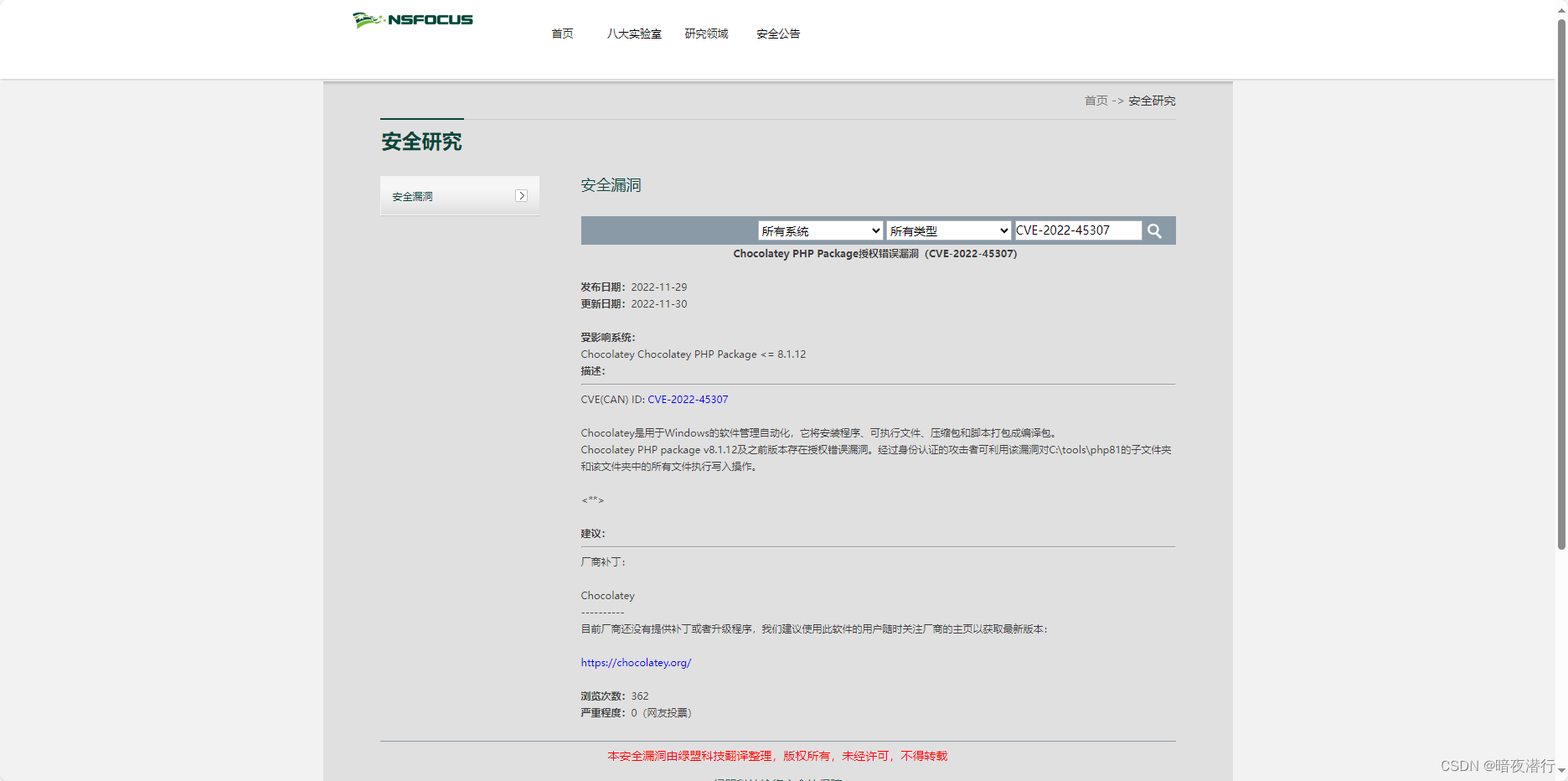
手动执行生成快照之后(实现了持久化)查看rdb文件会发生变化:
2、自动触发:在redis配置文件中,每隔一段时间或者每添加了多少次数据之后进行生成快照。
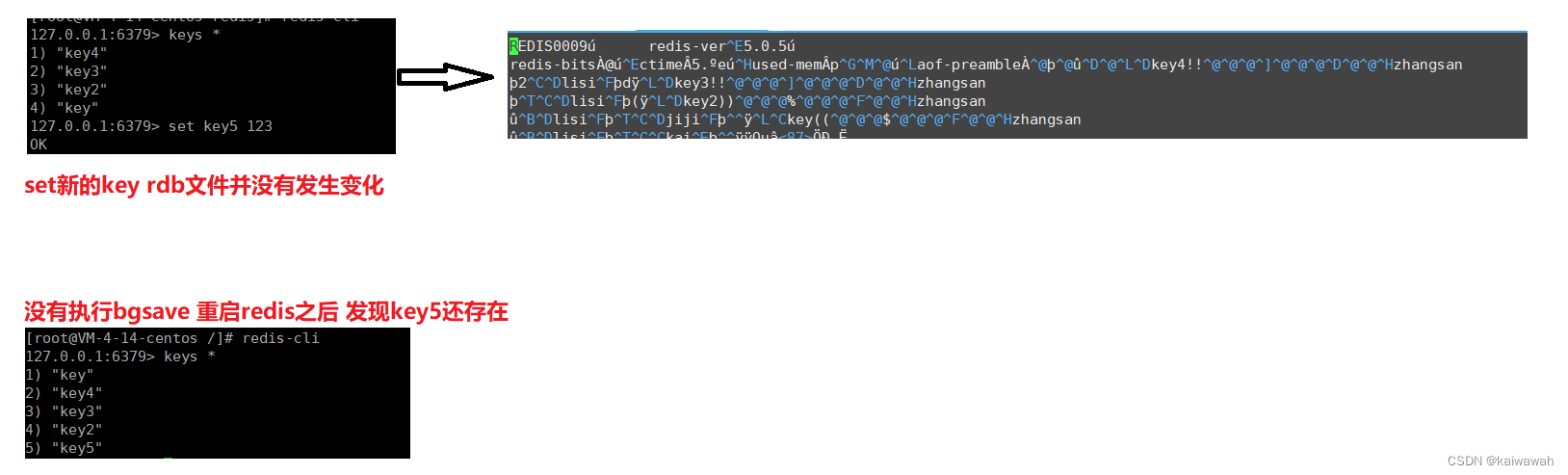

如果是通过正常流程重新启动 redis 服务器,此时 redis 服务器会在退出的时候,自动触发生成 rdb 操作但是如果是异常重启(kill -9 或者 服务器掉电)此时 redis 服务器来不及生成 rdb,内存中尚未保存到快照中的数据,就会随着重启而丢失
通过修改配置文件也可以实现自动生成快照
bgsave操作流程是创建子进程,子进程完成持久化操作。持久化操作会把数据写入新的文件中,然后用新的文件去替换旧的文件。
RDB特点小结
RDB是一个紧凑压缩型二进制文件,它代表某个时间点的数据快照,由于它是全量复制,因此其复制成本较高,属于重量级操作,可以周期性执行bgsave。
恢复数据快于AOF(二进制)。
RDB有多个版本,版本兼容 性不好。
通过以上对RDB的学习,我们可以观察到RDB的一个漏洞,会在俩次快照之间,实时数据可能会随着重启而丢失,因此AOF将发挥作用
AOF:append only file
类似于mysql的binlog,将用户每一步操作,都记录下来到文件中。每次redis重新启动的时候,就读取aof文件,而且当aof开启的时候,redis不再读取rdb文件。
既然会实现记录操作,会影响redis性能吗?
1、AOF机制并非是直接将数据写入硬盘,而是写入一个内存中的缓存区,积累一定大小之后,再写入硬盘。
2、硬盘读写是顺序写入,每次把新的操作写到原有文件的末尾。
缓冲区刷新策略 
重写机制
AOF文件持续增大,会影响到下次redis启动的时间。
AOF会有冗余数据: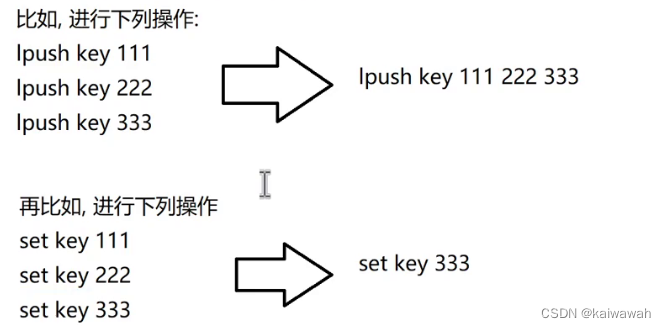
因此redis存在一个机制,针对aof文件进行整理,用于剔除冗余操作,合并一些操作,达到aof瘦身效果。

重写流程
父进程fork一个子进程,父进程仍然接受请求,子进程负责针对aof进行重写,要注意的是,重写的时候,不关系aof文件原来有啥,而是现在内存中最终的数据状态(内存中的数据状态就是将aof文件结果整理之后的了),直接将内存中的最终数据写到新的aof文件即可,这里有点像rdb文件,只不过aof是文本形式生成的。
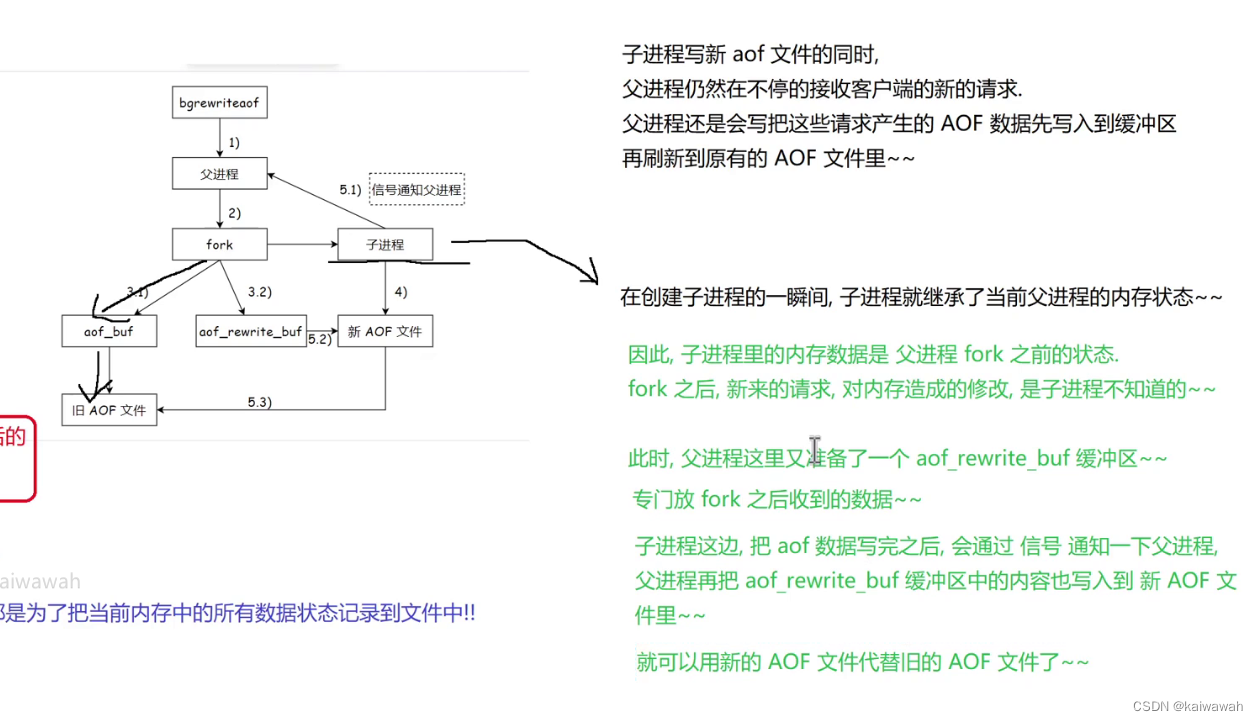
父进程也不闲着,因为可能会有新的请求想要写入,因此父进程会把这些新的请求写入到缓冲区中,再刷新到原来的aof文件,但是子进程只是继承了fork之前的父进程,对于新的请求是没有办法感知的,因此父进程对于新的请求写入到缓冲区还有一个新的缓冲区选哟写入,那就是aof_rewrite_buf,专门存放fork之后的数据,然后子进程把自己的数据写完在新的aof文件之后,再用 信号 通知父进程 将aof_rewrite_buf里面的数据写到新 的aof文件中,最后就可以用新的aof文件去替换旧 的aof文件了。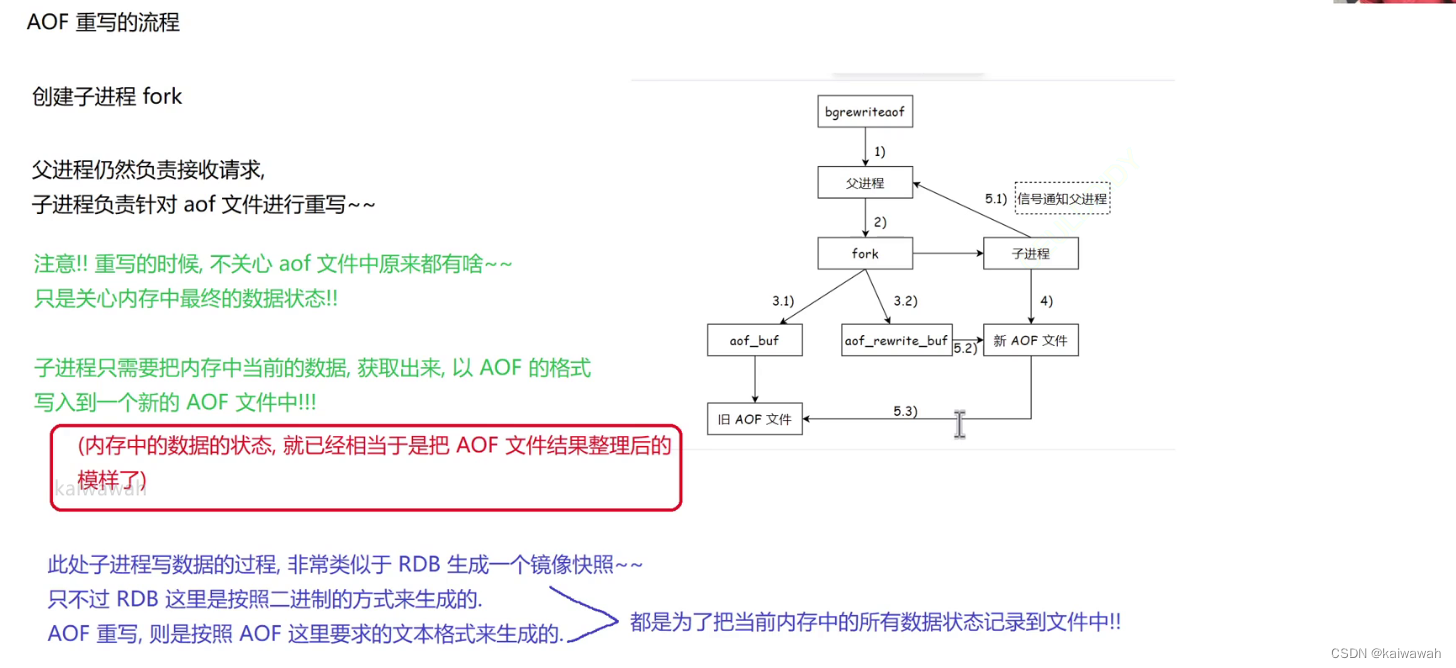
 如果,在执行 bgrewriteaof 的时候,当前 redis 已经正在进行 aof 重写了,会咋样呢?
如果,在执行 bgrewriteaof 的时候,当前 redis 已经正在进行 aof 重写了,会咋样呢?
此时,不会再次执行 aof 重写.直接返回了
如果, 在执行 bgrewriteaof 的时候, 发现当前 redis 在生成 rdb 文件的快照, 会咋样呢?
此时, aof 重写操作就会等待,等待 rdb 快照生成完毕之后,再进行执行 aof重写
混合持久化
AOF 本来是按照文本的方式来写入文件的.但是文本的方式写文件,后续加载的成本是比较高的redis 就引入了"混合持久化" 的方式 结合了 rdb 和 aof 的特点:
按照 aof 的方式,每一个请求/操作, 都记录入文件,在触发 aof 重写之后,就会把当前内存的状态按照 rdb 的二进制格式写入到新的 aof 文件中后续再进行的操作,仍然是按照 aof 文本的方式追加到文件后面