文章目录
- UniMSE:实现统一的多模态情感分析和情绪识别
- 文章信息
- 研究目的
- 研究内容
- 研究方法
- 1.总体架构
- 2.Task Formalization
- 3.Pre-trained Modality Fusion (PMF)
- 4.Inter-modality Contrastive Learning
- 5.总体损失函数
- 6.Decoding Algorithm
- 结果与讨论
- 代码和数据集
- 符号含义
UniMSE:实现统一的多模态情感分析和情绪识别
总结:提出了一个 UniMSE 的框架,利用该框架将情感和情绪联合建模(将 MSA 任务和 ERC 任务统一起来),通过将 PMF 嵌入 T5 架构中去实现多模态融合表征的获取。
文章信息
作者:Guimin Hu;Yi Zhao
单位:Harbin Institute of Technology(哈尔滨工业大学)
会议/期刊:Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing(EMNLP 2022)【CCF B】
题目:UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition
年份:2022
研究目的
探究将 MSA 任务(Multimodal sentiment analysis)和 ERC 任务(Emotion recognition in conversation)统一起来,将情感和情绪联合建模,是否可以实现更好的效果。
研究内容
- 提出了一个多模态情感知识共享框架 UniMSE,将 MSA 和 ERC 任务统一起来。
- 提出了一个预训练的多模态融合层 PMF,并将其嵌入到 T5 模型的 transformer 层中,通过向 T5 模型注入声音和视觉信号,从多层次文本信息中融合多模态表征。
- 利用跨模态对比学习,获得具有区分性的多模态表征。(样本间区分)
研究方法
UniMSE 框架包含三个部分:任务形式化、预训练模态融合和模态间对比学习。
1.总体架构
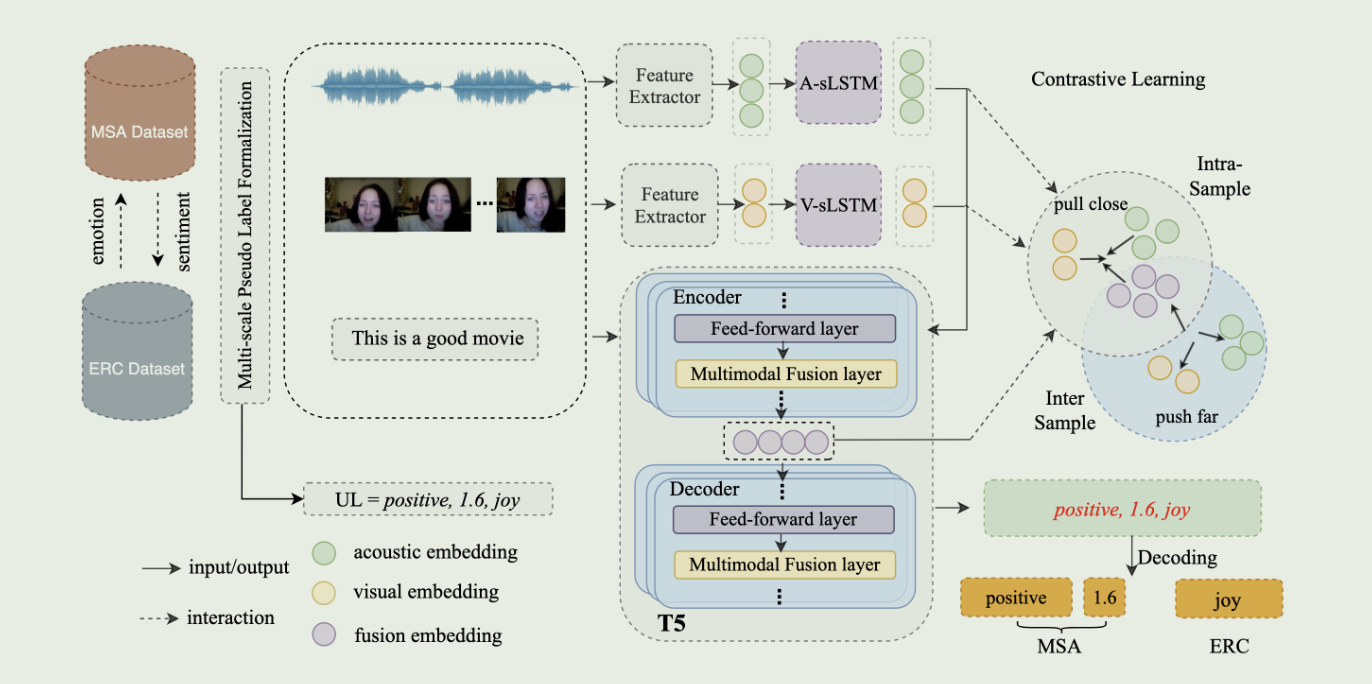
首先将 MSA 任务和 ERC 任务的标签处理为通用标签格式(图中的 UL 格式),然后获取不同模态的上下文信息1,接着将提取的特征送入嵌入了多模态融合层的 T5 架构中2,通过 T5 得到一个UL 格式的输出,最后对其解码,就得到了 MSA 和 ERC 任务相应的输出。
此外,该框架还进行了跨模态对比学习,以区分样本间的多模态融合表征。具体来说,旨在缩小同一样本模态之间的差距(pull close),并将不同样本模态表征进一步推开(push far)。
2.Task Formalization
任务形式化包括输入形式化和标签形式化。输入形式化用于处理对话文本和模态特征,标签形式化用于将 MSA 任务和 ERC 任务的标签转换为通用标签,从而统一这两种任务。
形式化后,数据集的形式可以表示为: { ( I 0 , y 0 ) , ( I 1 , y 1 ) . . . ( I N , y N ) } \{(I_0,y_0),(I_1,y_1)...(I_N,y_N)\} {(I0,y0),(I1,y1)...(IN,yN)}。符号含义查看
输入形式化:
对于文本模态,将当前语句
u
i
u_i
ui与前两轮语句
{
u
i
−
1
,
u
i
−
2
}
\{u_{i-1},u_{i-2}\}
{ui−1,ui−2}和后两轮语句
{
u
i
+
1
,
u
i
+
2
}
\{u_{i+1},u_{i+2}\}
{ui+1,ui+2}进行拼接,形成原始文本序列。并且利用segment id(
S
i
t
S_i^t
Sit)去区分当前语句及其上下文。
I
i
t
=
[
u
i
−
2
,
u
i
−
1
,
u
i
,
u
i
+
1
,
u
i
+
2
]
S
i
t
=
[
0
,
⋯
,
0
⏟
u
i
−
2
,
u
i
−
1
,
1
,
⋯
,
1
⏟
u
i
,
0
,
⋯
,
0
⏟
u
i
+
1
,
u
i
+
2
]
\begin{gathered} I_i^t=[u_{i-2},u_{i-1},u_i,u_{i+1},u_{i+2}] \\ \begin{aligned}S_i^t=[\underbrace{0,\cdots,0}_{u_{i-2},u_{i-1}},\underbrace{1,\cdots,1}_{u_i},\underbrace{0,\cdots,0}_{u_{i+1},u_{i+2}}]\end{aligned} \end{gathered}
Iit=[ui−2,ui−1,ui,ui+1,ui+2]Sit=[ui−2,ui−1
0,⋯,0,ui
1,⋯,1,ui+1,ui+2
0,⋯,0]
对于音频模态,利用 librosa 获取音频特征。对于视频模态,利用 effecientNet 获取视频特征。
标签形式化:
设计了一种通用标签(UL),并将 UL 作为 UniMSE 的目标序列。
首先,根据情感极性将 MSA 和 ERC 样本分为正面、中性和负面样本集。然后在每一个样本集下,计算属于不同注释方案的两个样本的语义相似度3。最后根据语义相似度最高的样本补全通用标签中缺失的部分。

3.Pre-trained Modality Fusion (PMF)
使用 T5 作为 UniMSE 的骨干,并将 PMF 插入 T5 的每一个 transformer 层的 Feed-forward 后面。对于第
j
j
j个PMF,多模态融合的过程如下:
F
i
(
0
)
=
X
i
t
F
i
=
[
F
i
(
j
−
1
)
⋅
X
i
a
,
l
a
⋅
X
i
v
,
l
v
]
F
i
d
=
σ
(
W
d
F
i
+
b
d
)
F
i
u
=
W
u
F
i
d
+
b
u
F
i
(
j
)
=
W
(
F
i
u
⊙
F
i
(
j
−
1
)
)
\begin{aligned} &F_i^{(0)}=X_i^t \\ &F_i=[F_i^{(j-1)}\cdot X_i^{a,l_a}\cdot X_i^{v,l_v}] \\ &F_i^d=\sigma(W^dF_i+b^d) \\ &F_i^u=W^uF_i^d+b^u \\ &F_i^{(j)}=W(F_i^u\odot F_i^{(j-1)}) \end{aligned}
Fi(0)=XitFi=[Fi(j−1)⋅Xia,la⋅Xiv,lv]Fid=σ(WdFi+bd)Fiu=WuFid+buFi(j)=W(Fiu⊙Fi(j−1))
【注】:防止文本序列的编码扰乱以及模型过拟合,使用前
j
j
j 个 transformer 层只对文本进行编码(没有注入声音和视觉表征),剩余的 transformer 层通过注入声音和视觉表征实现多模态融合。而且根据公式,可以观察到,这些剩余的 transformer 层,每一层都注入了声音和视觉表征。可以理解为反复用声音和视觉表征,强化每一层的融合表征。(反复加强文本表征)
4.Inter-modality Contrastive Learning
通过跨模态对比学习4,以加强模态之间的互动,放大样本之间融合表征的差异。
准备工作:首先将音频表征
X
i
a
X_i^a
Xia,视频表征
X
i
v
X_i^v
Xiv以及融合表征
F
i
(
j
)
F_i^{(j)}
Fi(j)通过Conv1D将各表征处理为相同的序列长度。然后用 K 个样本构建每个迷你批次。
X
^
i
u
=
Conv
1
D
(
X
i
u
,
k
u
)
,
u
∈
{
a
,
v
}
F
^
i
(
j
)
=
Conv
1
D
(
F
i
(
j
)
,
k
f
)
\begin{aligned} &\hat{X}_i^{\boldsymbol{u}}=\text{Conv}1\text{D}(X_i^{\boldsymbol{u}},k^{\boldsymbol{u}}),u\in\{a,v\} \\ &\hat{F}_i^{(j)}=\text{Conv}1\text{D}(F_i^{(j)},k^f) \end{aligned}
X^iu=Conv1D(Xiu,ku),u∈{a,v}F^i(j)=Conv1D(Fi(j),kf)
核心:每个锚点5的一批随机采样对由 2 对正样本和 2K 对负样本组成。其中,正样本是指同一样本中由文字和相应声音组成的模态对,以及同一样本中由文字和相应视觉组成的模态对。负样本是由文本和其他样本中的其他两种模态组成的模态对。对于每个锚样本,自监督对比损失的计算公式如下:
L
t
a
,
j
=
−
log
exp
(
F
^
i
(
j
)
X
^
i
a
)
exp
(
F
^
i
(
j
)
X
^
i
a
)
+
∑
k
=
1
K
exp
(
F
^
i
(
j
)
X
^
k
a
)
L
t
v
,
j
=
−
log
exp
(
F
^
i
(
j
)
X
^
i
v
)
exp
(
F
^
i
(
j
)
X
^
i
v
)
+
∑
k
=
1
K
exp
(
F
^
i
(
j
)
X
^
k
v
)
\begin{gathered} L^{ta,j} =-\log\frac{\exp(\hat{F}_i^{(j)}\hat{X}_i^a)}{\exp(\hat{F}_i^{(j)}\hat{X}_i^a)+\sum_{k=1}^K\exp(\hat{F}_i^{(j)}\hat{X}_k^a)} \\ L^{tv,j} =-\log\frac{\exp(\hat{F}_i^{(j)}\hat{X}_i^v)}{\exp(\hat{F}_i^{(j)}\hat{X}_i^v)+\sum_{k=1}^K\exp(\hat{F}_i^{(j)}\hat{X}_k^v)} \end{gathered}
Lta,j=−logexp(F^i(j)X^ia)+∑k=1Kexp(F^i(j)X^ka)exp(F^i(j)X^ia)Ltv,j=−logexp(F^i(j)X^iv)+∑k=1Kexp(F^i(j)X^kv)exp(F^i(j)X^iv)
5.总体损失函数
L = L t a s k + α ( ∑ j L t a , j ) + β ( ∑ j L t v , j ) L=L^{task}+\alpha(\sum_jL^{ta,j})+\beta(\sum_jL^{tv,j}) L=Ltask+α(j∑Lta,j)+β(j∑Ltv,j)
符号含义查看
6.Decoding Algorithm
使用解码算法,将整体输出转变为 MSA 的情感强度和 ERC 的情绪类别。

结果与讨论
- 通过与 SOTA 模型进行比较,证明了 UniMSE 不管是对于 MSA 任务还是 ERC 任务都可以实现优越的结果。
- 消融实验1,通过剔除一种或者几种模态,验证了模态对模型的性能是有影响的,证明了文本模态、听觉模态以及视觉模态之间具有互补性。
- 消融实验2,通过移除 PMF 和 CL 模块,证明了这两个模块在多模态表征学习中是有效的。
- 消融实验3,通过将 IEMOCAP、MELD 或 MOSEI 从训练集中移除,并在 MOSI 测试集中评估模型性能,验证数据集对 UniMSE 的影响。证明了将情感与情绪结合起来分析,可以实现信息互补的效果。
- 通过对最后一个 transformer 层的多模态融合表征进行可视化,验证了 UniMSE 在跨样本表征学习方面的优势,并证明了情感和情绪之间的互补性。
代码和数据集
代码:https://github.com/LeMei/UniMSE
数据集:MOSI,MOSEI,MELD,IEMOCAP

实验环境:NVIDIA RTX A100 和 NVIDIA RTX V100
符号含义
| 符号 | 含义 |
|---|---|
| I i m , m ∈ { t , a , v } I_i^m,m\in\{t,a,v\} Iim,m∈{t,a,v} | 从视频片段 i 中提取的单模态原始序列, { t , a , v } \{t,a,v\} {t,a,v}分别代表文本模态、语音模态、视频模态。 |
| I i = { I i t , I i a , I i v } I_i=\{I_i^t,I_i^a,I_i^v\} Ii={Iit,Iia,Iiv} | I i I_i Ii代表多模态信号,即模型的输入。 |
| y i = { y i p , y i r , y i c } y_i=\{y_i^p,y_i^r,y_i^c\} yi={yip,yir,yic} | y i y_i yi代表通用标签, y i p y_i^p yip代表情感极性 y i p ∈ { positive, negative and neutral } y_i^p\in\{\text{positive, negative and neutral}\} yip∈{positive, negative and neutral}, y i r y_i^r yir代表情感强度(是一个真实的值,范围 -3 ~ +3), y i c y_i^c yic代表情绪类别。 |
| X i m ∈ R l m × d m X_i^m\in R^{l_m\times d_m} Xim∈Rlm×dm | X i m X_i^m Xim为 I i m I_i^m Iim的单模态表征, l m l_m lm代表序列长度, d m d_m dm代表维度。 |
| X i a , l a ∈ R 1 × d a X_i^{a,l_a}~\in~R^{1\times d_a}~\mathrm~ Xia,la ∈ R1×da | X i a X_i^a Xia最后一个时间步的隐藏状态 |
| X i v , l v ∈ R 1 × d v X_i^{v,l_v}~\in~R^{1\times d_v} Xiv,lv ∈ R1×dv | X i v X_i^v Xiv最后一个时间步的隐藏状态 |
| [ . ] \left[.\right] [.] | 连接操作,concatenation operation |
| σ {\sigma} σ | sigmoid函数 |
| F i ( j − 1 ) F_i^{(j-1)} Fi(j−1) | (j-1)个 transformer 层之后的融合表征 |
| ⨀ \bigodot ⨀ | 元素加法操作 |
| k u , k f k^u,k^f ku,kf | 卷积核的大小 |
| L t a , j L^{ta,j} Lta,j, L t v , j L^{tv,j} Ltv,j | 编码器的第 j j j个transformer层上,文本-语音和文本-视觉的对比损失。 |
| L t a s k L^{task} Ltask | 生成任务的损失,也就是预测标签与通用标签之间的差异。 |
😃😃😃
对于音频模态和视频模态,使用特征提取器分别提取音频和视频特征。然后将其送入到两个单独的 LSTM 获取上下文信息,得到音频模态表征 X i a X_i^a Xia和视频模态表征 X i v X_i^v Xiv。对于文本模态,使用 T5 的第一个transformer层来学习序列的上下文信息,得到文本模态 X i t X_i^t Xit。 ↩︎
T5 的全称为 Text to Text Transfer Transformer,论文地址。是谷歌提出的预训练语言模型领域的通用模型,该模型将所有自然语言问题都转化成文本到文本的形式,并用一个统一的模型解决。在 T5 中的每个 transformer 层的 Feed-forward 层后面嵌入了预训练的多模态融合层 PMF。 ↩︎
由于文本模态相比其他模态更重要,所以采用文本相似度作为样本之间的语义相似度。利用强句子嵌入框架 SimSCE 计算文本之间的语义相似度。 ↩︎
Contrastive Learning(CL),对比学习的原理是,在特征空间中,锚和正样本应拉近,而锚和负样本应拉远。 ↩︎
文本模态作为锚点,其余两种模态用于增强锚点。在 T5 架构的 j j j 层后,文本表征某种意义上就是融合后的表征,因此融合表征和文本表征是道理一致的。所以公式中用的是融合表征 F ^ i ( j ) \hat{F}_i^{(j)} F^i(j)。 ↩︎