文章目录
- 一、前言
- 二、项目背景
- 三、实现方案
- 四、思路延伸
- 1. 优先级队列
- 1.1 concurrent 包下的 PriorityBlockingQueue
- 1.2 Redisson 的优先级阻塞队列
- 2. jvisualvm 远程连接
- 3. Jstack 高 CPU 排查
- 五、参考内容
一、前言
本系列用来记录一些在实际项目中的小东西,并记录在过程中想到一些小东西,因为是随笔记录,所以内容不会过于详细。
二、项目背景
项目存在一个功能:对PDF文件进行压缩,且要求PDF 每页大小小于400KB。由于无法判断PDF 每页的大小,所以项目实现方案是将PDF 每页读取后转成图片再进行压缩到合适大小,最后将压缩后的图片再重新生成为 PDF。
在一通实现(东抄西抄 )后,上述功能实现后便直接上线,但是上线后暴露出如下问题:
- 对于多页数 PDF 的压缩效率太低:由于无法判定PDF每页是否满足大小,所以只能将PDF每页都进行 转图片、压缩、转PDF的操作。对于客户动辄50+页数的PDF,处理效率太低。并且由于存在压缩超时的判定限制,大页数PDF极有可能被判定为压缩超时。
为了解决上述问题,准备开启多线程以页为维度进行压缩,提高多页数PDF的解析效率。但经过测试,上述的PDF处理过程极其耗费资源,本地在测试时直接OOM,因此也要控制并发量。
三、实现方案
基础实现依托于下面的工具类,调用 ImgToPdfUtils#compressPdf 方法可完成压缩功能。
package com.kingfish.springcommondemo.docs;
import com.google.common.collect.Lists;
import com.itextpdf.text.Document;
import com.itextpdf.text.Image;
import com.itextpdf.text.PageSize;
import com.itextpdf.text.pdf.*;
import com.kingfish.common.api.CommonBizException;
import com.kingfish.common.utils.ThreadUtil;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.math.BigDecimal;
import java.util.List;
import java.util.Objects;
import java.util.concurrent.CompletableFuture;
import java.util.stream.Collectors;
/**
* @Author : kingfish
* @Email : kingfishx@163.com
* @Date : 2024/1/28 15:16
* @Desc :
*/
@Slf4j
public class PdfCompressUtils {
/**
* 每页最大
*/
private static final int SINGLE_PDF_MAX_SIZE = 350 * 1000;
/**
* PDF 压缩
*
* @param pdfBytes
* @return
*/
public static byte[] syncCompressPdf(byte[] pdfBytes) throws Exception {
final List<byte[]> imageBytesList = pdf2Images(pdfBytes);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Document doc = new Document();
PdfCopy pdfCopy = new PdfCopy(doc, bos);
pdfCopy.setFullCompression();
pdfCopy.setCompressionLevel(PdfStream.BEST_COMPRESSION);
doc.open();
imageBytesList.forEach(imageBytes ->
copyFileToPdf(pdfCopy, compressImage2Pdf(imageBytes, SINGLE_PDF_MAX_SIZE)));
pdfCopy.close();
doc.close();
return bos.toByteArray();
}
/**
* PDF 压缩
*
* @param pdfBytes
* @return
*/
public static byte[] asyncCompressPdf(byte[] pdfBytes) throws Exception {
final List<byte[]> imageBytesList = pdf2Images(pdfBytes);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Document doc = new Document();
PdfCopy pdfCopy = new PdfCopy(doc, bos);
pdfCopy.setFullCompression();
pdfCopy.setCompressionLevel(PdfStream.BEST_COMPRESSION);
doc.open();
final List<CompletableFuture<byte[]>> completableFutures =
imageBytesList
.stream()
.map(imageBytes ->
CompletableFuture.supplyAsync(() ->
compressImage2Pdf(imageBytes, SINGLE_PDF_MAX_SIZE),
ThreadUtil.getIoPool()))
.collect(Collectors.toList());
CompletableFuture.allOf(
completableFutures.toArray(new CompletableFuture[0]))
.join();
completableFutures.stream()
.filter(Objects::nonNull)
.map(CompletableFuture::join)
.forEach(pageBytes -> copyFileToPdf(pdfCopy, pdfBytes));
pdfCopy.close();
doc.close();
return bos.toByteArray();
}
/**
* pdf 转图片
*
* @param pdfBytes
* @return
*/
private static List<byte[]> pdf2Images(byte[] pdfBytes) {
List<byte[]> results = Lists.newArrayList();
try (PDDocument document = PDDocument.load(pdfBytes)) {
PDFRenderer renderer = new PDFRenderer(document);
for (int i = 0; i < document.getNumberOfPages(); ++i) {
// DPI 越大,清晰度越高
BufferedImage bufferedImage = renderer.renderImageWithDPI(i, 300);
ByteArrayOutputStream out = new ByteArrayOutputStream();
ImageIO.write(bufferedImage, "jpeg", out);
results.add(out.toByteArray());
}
} catch (IOException e) {
log.error("pdf转图片出错", e);
}
return results;
}
/**
* 生成PDF
*
* @param pdfCopy
* @param pdfBytes
* @throws IOException
* @throws BadPdfFormatException
*/
@SneakyThrows
public static void copyFileToPdf(PdfCopy pdfCopy, byte[] pdfBytes) {
PdfReader reader = new PdfReader(pdfBytes);
int totalPages = reader.getNumberOfPages();
for (int j = 1; j <= totalPages; j++) {
pdfCopy.addPage(pdfCopy.getImportedPage(reader, j));
}
reader.close();
}
/**
* 图片压缩
*
* @param imageBytes
* @param maxSize
* @return
*/
public static byte[] compressImage2Pdf(byte[] imageBytes, int maxSize) {
try (ByteArrayOutputStream resultBos = new ByteArrayOutputStream()) {
Document document;
if (imageBytes.length > maxSize) {
// 递归压缩
imageBytes = compressImageCycle(imageBytes, maxSize, 0);
}
// 绘制图片转为 PDF
Image image = Image.getInstance(imageBytes);
image.setCompressionLevel(PdfStream.BEST_COMPRESSION);
float scaledWidth = image.getScaledWidth();
float scaledHeight = image.getScaledHeight();
if (scaledWidth > scaledHeight) {
image.scaleToFit(842.0F, 575.0F);
document = new Document(PageSize.A4.rotate(), 0, 0, 0, 0);
} else {
image.scaleToFit(575.0F, 842.0F);
document = new Document(PageSize.A4, 0, 0, 0, 0);
}
PdfWriter writer = PdfWriter.getInstance(document, resultBos);
writer.setCompressionLevel(PdfStream.BEST_COMPRESSION);
writer.setFullCompression();
document.open();
document.add(image);
document.close();
return resultBos.toByteArray();
} catch (Exception exception) {
throw new CommonBizException(exception);
}
}
/**
* @param bytes 原图片字节数组
* @return
*/
private static byte[] compressImageCycle(byte[] bytes, int maxSize, int cycle) throws IOException {
double accuracy = getAccuracy(bytes.length / 1000);
//计算宽高
BufferedImage bim = ImageIO.read(new ByteArrayInputStream(bytes));
int imgWidth = bim.getWidth();
int imgHeight = bim.getHeight();
int desWidth = new BigDecimal(imgWidth).multiply(new BigDecimal(accuracy)).intValue();
int desHeight = new BigDecimal(imgHeight).multiply(new BigDecimal(accuracy)).intValue();
// 构造一个类型为预定义图像类型之一的 BufferedImage
BufferedImage tag = new BufferedImage(desWidth, desHeight, BufferedImage.TYPE_INT_RGB);
// 这边是压缩的模式设置
tag.getGraphics().drawImage(bim.getScaledInstance(desWidth, desHeight, java.awt.Image.SCALE_SMOOTH), 0, 0,
null);
//将图片按JPEG压缩,保存到out中
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ImageIO.write(tag, "jpeg", baos);
cycle++;
int srcSize = baos.size();
if (srcSize > maxSize && cycle < 6) {
// log.info(srcSize / 1000 + "KB文件大于" + maxSize / 1000 + "KB,第" + (cycle + 1) + "次进行压缩");
return compressImageCycle(baos.toByteArray(), maxSize, cycle);
}
return baos.toByteArray();
}
/**
* 自动调节精度
*
* @param size 源图片大小
* @return 图片压缩质量比
*/
private static double getAccuracy(long size) {
double accuracy;
if (size < 900) {
accuracy = 0.85;
} else if (size < 2047) {
accuracy = 0.6;
} else if (size < 3275) {
accuracy = 0.44;
} else {
accuracy = 0.4;
}
return accuracy;
}
}
使用20个PDF 文件 模拟测试调用,方法如下:
public class PdfDemoMain {
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.INFO);
});
}
public static void main(String[] args) throws Exception {
sync();
async();
}
/**
* 同步调用
*/
private static void sync() {
final File[] files = new File("C:\\Users\\Administrator\\Desktop\\compress\\压缩前").listFiles();
FileUtil.del("C:\\Users\\Administrator\\Desktop\\compress\\压缩后\\");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 模拟并发调用
final CompletableFuture[] cfs = Arrays.stream(files)
.map(file ->
CompletableFuture.runAsync(() -> {
try {
// 同步压缩
byte[] compressBytes = PdfCompressUtils.syncCompressPdf(FileUtil.readBytes(file));
FileUtil.writeBytes(compressBytes, "C:\\Users\\Administrator\\Desktop\\compress\\压缩后\\" + file.getName() + ".pdf");
} catch (Exception e) {
throw new RuntimeException(e);
}
})).toArray(CompletableFuture[]::new);
CompletableFuture.allOf(cfs).join();
stopWatch.stop();
System.out.println("同步花费时长: " + stopWatch.getTotalTimeSeconds());
}
/**
* 异步调用
*/
private static void async() {
final File[] files = new File("C:\\Users\\Administrator\\Desktop\\compress\\压缩前").listFiles();
FileUtil.del("C:\\Users\\Administrator\\Desktop\\compress\\压缩后\\");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 模拟并发调用
final CompletableFuture[] cfs = Arrays.stream(files)
.map(file ->
CompletableFuture.runAsync(() -> {
try {
// 异步压缩
byte[] compressBytes = PdfCompressUtils.asyncCompressPdf(FileUtil.readBytes(file));
FileUtil.writeBytes(compressBytes, "C:\\Users\\Administrator\\Desktop\\compress\\压缩后\\" + file.getName() + ".pdf");
} catch (Exception e) {
throw new RuntimeException(e);
}
})).toArray(CompletableFuture[]::new);
CompletableFuture.allOf(cfs).join();
stopWatch.stop();
System.out.println("异步花费时长: " + stopWatch.getTotalTimeSeconds());
}
}
测试结果如下:

可以看到效率具有非常明显的提升,但是需要注意的是:
- PdfCompressUtils 的异步方法并非是所有情况都适用。当观察机器的CPU,如果CPU本身已经接近满载,再使用异步方法可能并不会提升效率。
- PdfCompressUtils 压缩方法的目的是将PDF 每页大小压缩尽量接近400Kb,因此压缩后的PDF大小可能会变更大,因为原先一页可能只有20KB,压缩后可能变成了380KB。
- PdfCompressUtils 压缩过程中对于PDF 可能会存在多次压缩,因为无法把握合适的压缩系数。比如500KBPDF 压缩一次后可能是420KB,则需要再次压缩。
四、思路延伸
PdfCompressUtils 中提供的压缩功能个人感觉并非最优解,效率低且占用资源非常高,在本地测试的时候因为过高的并发度导致 OOM 的发生,因此还需要控制 PdfCompressUtils 方法请求的并发度,否则可能会导致OOM的发送。而并发度的控制有两个方面:
- 异步压缩开启的线程数量:这个可以直接通过 ThreadUtil.getIoPool() 的线程池来控制。
- 服务接口被请求的并发控制:这个首先想到的就是队列,对于有优先级要求的情况下,单节点的情况下可以使用java.util.concurrent.PriorityBlockingQueue,而多节点则可以使用 Redisson 提供的 PriorityBlockingQueue。
1. 优先级队列
1.1 concurrent 包下的 PriorityBlockingQueue
下面以 java.util.concurrent.PriorityBlockingQueue 为例,在 PdfCompressUtils 中增加如下内容:
@Slf4j
public class PdfCompressUtils {
...
/**
* 文件队列
*/
private static final PriorityBlockingQueue<PriorityFile> FILE_QUEUES = Queues.newPriorityBlockingQueue();
static {
// 可以通过线程池的线程数量来控制队列消费的并发度,这里使用单线程是为了方便测试
final ExecutorService executorService =
Executors.newSingleThreadExecutor();
executorService.submit(PdfCompressUtils::runCompressTask);
}
private static void runCompressTask() {
while (true) {
try {
// 睡眠10s 也是为了方便测试,让所有PDF都入队后再出队
Thread.sleep(10000);
// 从队列中取出
final PriorityFile priorityFile = FILE_QUEUES.take();
log.info("文件 {} 优先级为 {} 从队列中取出", priorityFile.getFile().getName(), priorityFile.getPriority());
// 压缩
final byte[] results = asyncCompressPdf(FileUtil.readBytes(priorityFile.getFile()));
// 压缩完成回调
priorityFile.getCallback().accept(results);
} catch (Exception e) {
// TODO : 文件压缩失败之后的处理
}
}
}
/**
* PDF 压缩
* @param file 要压缩的PDF
* @param priority 优先级,越大优先级越高
* @param callback 压缩回调,因为附件的优先级可能比较低导致一直没有压缩,因此使用回调的方式,当附件压缩完成时调用 callback 方法
* @throws Exception
*/
public static void asyncCompressPdf(File file, int priority, Consumer<byte[]> callback) throws Exception {
log.info("文件 {} 优先级为 {} 投递到队列", file.getName(), priority);
FILE_QUEUES.offer(new PriorityFile(file, priority, callback));
}
/**
* 优先级文件
*/
@Getter
static class PriorityFile implements Comparable<PriorityFile> {
/**
* 文件
*/
private File file;
/**
* 优先级
*/
private int priority;
/**
* 结果回调
*/
private Consumer<byte[]> callback;
public PriorityFile(File file, int priority, Consumer<byte[]> callback) {
this.file = file;
this.priority = priority;
this.callback = callback;
}
@Override
public int compareTo(PriorityFile o) {
return o.getPriority() - this.priority;
}
}
...
}
可以看到压缩结果是按照优先级的顺序压缩的

总结:
- 通过静态代码块中的线程池来控制压缩的并发度,防止OOM
- 通过FILE_QUEUES 来控制压缩的优先级。
- 这里其实存在一个问题,当PDF入队后,服务宕机重启,队列中就没有该PDF记录了,解决方式可以是在当PDF入队后将PDF记录到Redis 或数据库中,当压缩成功后再移除,每次服务启动时加载Redis或数据库中的PDF压缩记录即可。
1.2 Redisson 的优先级阻塞队列
如果要使用 Redisson 的 优先级阻塞队列,则进行如下改造:
@Slf4j
public class PdfCompressUtils {
...
private static RPriorityBlockingQueue<PriorityFile> FILE_QUEUES = null;
private static RedissonClient REDISSON_CLIENT = null;
static {
Config config = new Config();
config.useSingleServer()
.setTimeout(1000000)
.setDatabase(0)
.setAddress("redis://127.0.0.1:6379");
REDISSON_CLIENT = Redisson.create(config);
FILE_QUEUES = REDISSON_CLIENT.getPriorityBlockingQueue("FILE_QUEUE");
// 可以通过线程池的线程数量来控制队列消费的并发度,这里使用单线程是为了方便测试
final ExecutorService executorService =
Executors.newSingleThreadExecutor();
executorService.submit(PdfCompressUtils::runCompressTask);
}
private static void runCompressTask() {
while (true) {
try {
// 睡眠10s 也是为了方便测试,让所有PDF都入队后再出队
Thread.sleep(10000);
final PriorityFile priorityFile = FILE_QUEUES.take();
final File file = priorityFile.getFile();
log.info("文件 {} 优先级为 {} 从队列中取出", file.getName(), priorityFile.getPriority());
final byte[] results = asyncCompressPdf(FileUtil.readBytes(file));
// 因为队列内容需要序列化到Redis中,所以无法使用回调函数,因此结果处理直接在这里处理
FileUtil.writeBytes(results, "C:\\Users\\Administrator\\Desktop\\compress\\压缩后\\" + file.getName() + ".pdf");
log.info("文件 {} 压缩完成", file.getName());
} catch (Exception e) {
// TODO : 文件压缩失败之后的处理
log.info("文件压缩失败", e);
}
}
}
/**
* PDF 压缩
*
* @param file
* @param priority
* @throws Exception
*/
public static void asyncCompressPdf(File file, int priority) throws Exception {
log.info("文件 {} 优先级为 {} 投递到队列", file.getName(), priority);
FILE_QUEUES.offer(new PriorityFile(file, priority));
}
/**
* 优先级文件
*/
@Getter
static class PriorityFile implements Comparable<PriorityFile>, Serializable {
/**
* 文件
*/
private File file;
/**
* 优先级
*/
private int priority;
public PriorityFile() {
}
public PriorityFile(File file, int priority) {
this.file = file;
this.priority = priority;
}
@Override
public int compareTo(PriorityFile o) {
return o.getPriority() - this.priority;
}
}
...
}
总结:
-
如果真的要使用,Redis 中建议保存的是文件上传到 OSS的文件地址或者数据库中Id,而不是直接保存 File 或 byte[]
-
Redisson 的优先级阻塞队列使用的并不是 sorted set 做数据结构, 而是使用 list 结构。这一点可以在元素入队时看到,如下:
@Override public boolean offer(V e) { return add(e); } @Override public boolean add(V value) { lock.lock(); try { checkComparator(); // 二分查找,根据优先级确定当前元素入队的位置 BinarySearchResult<V> res = binarySearch(value, codec); int index = 0; if (res.getIndex() < 0) { index = -(res.getIndex() + 1); } else { index = res.getIndex() + 1; } // lua 语句保证并发性在队列指定位置插入元素 commandExecutor.evalWrite(getName(), RedisCommands.EVAL_VOID, "local len = redis.call('llen', KEYS[1]);" + "if tonumber(ARGV[1]) < len then " + "local pivot = redis.call('lindex', KEYS[1], ARGV[1]);" + "redis.call('linsert', KEYS[1], 'before', pivot, ARGV[2]);" + "return;" + "end;" + "redis.call('rpush', KEYS[1], ARGV[2]);", Arrays.<Object>asList(getName()), index, encode(value)); return true; } finally { lock.unlock(); } }
2. jvisualvm 远程连接
jvisualvm 是 JDK 提供的监控 Java 程序的工具,当使用如下命令进行启动服务时,可以使用 jvisualvm 远程连接服务。(这块内容如有需要可详参
https://blog.csdn.net/zhou920786312/article/details/123572662)
java - jar -Djava.rmi.server.hostname=[serverIp] -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=[serverPort] -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false demo.jar
这里注意两个变量:
- serverIp 指的是当前服务部署的机器的ip地址
- serverPort 指的是当前服务部署的机器暴露给外部的端口,jvisualvm 将通过此端口来远程连接。所以服务器需要开放serverPort 端口,否则也是无法连接。
以下为举例:
-
使用该命令启动服务, 其中 192.168.72.128 为服务器本地地址, 10081 为服务器暴露的端口
[root@localhost app]# java -jar -Djava.rmi.server.hostname=192.168.72.128 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=10081 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false spring-simple-demo-1.0-SNAPSHOT.jar -
jvisualvm 建立连接 : 如下,直接建立连接,名称可以随便写

建立后再新增 JMX 连接,如下,连接内容填写服务器地址和暴露的端口。
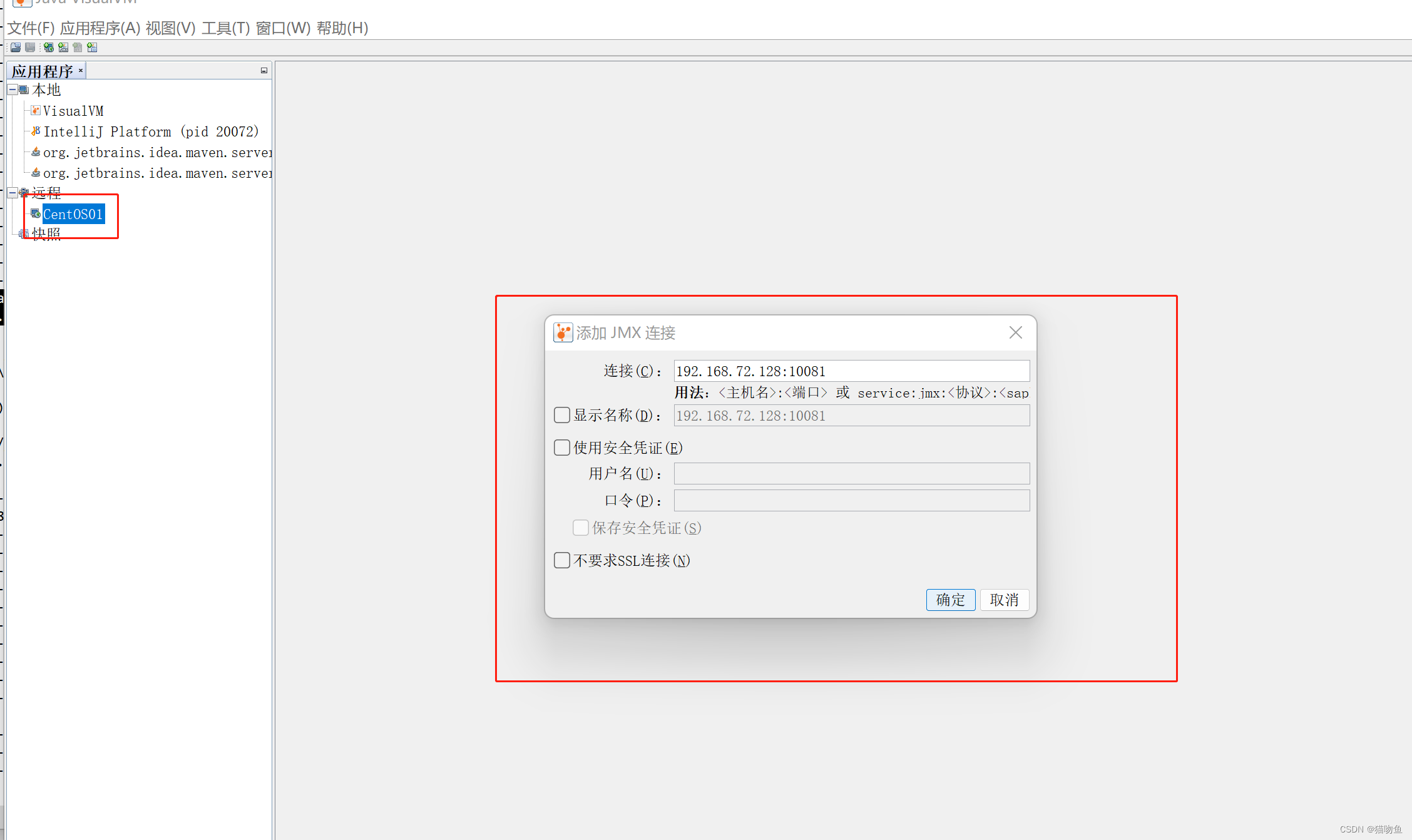
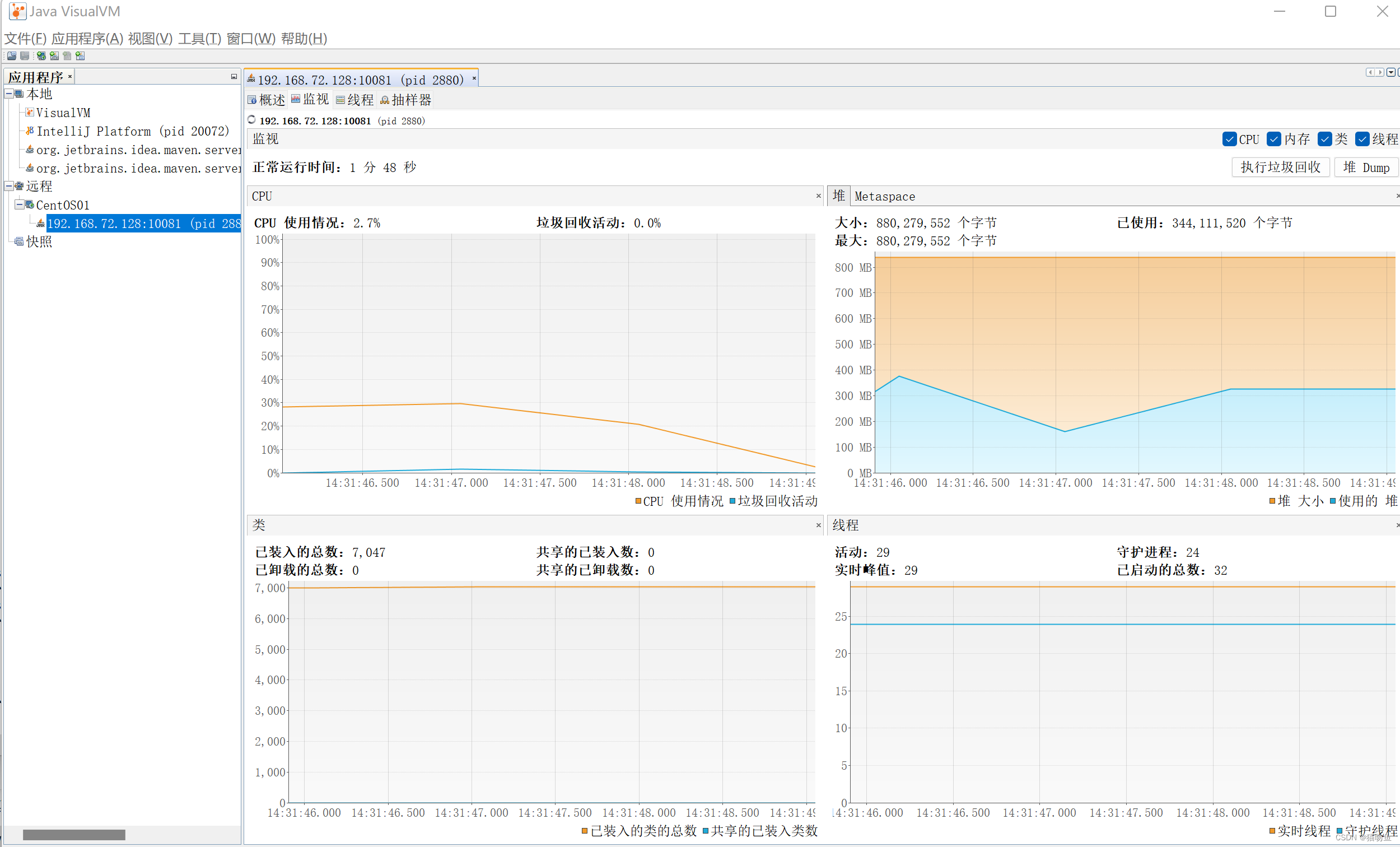
连接后的效果如下:
3. Jstack 高 CPU 排查
在使用上述 PDF 压缩时,会出现 CPU 使用率过高的情况,借此再总结下通过 jstack 命令排查 CPU使用率过高的情况,如下(这块内容如有需要详参 https://blog.csdn.net/weixin_44588186/article/details/124680586):
-
top:通过 top 命令确定 服务器上 CPU 占用较高的进程是哪个, top 命令默认按照CPU 排序,可以铜鼓 top c 可以更清晰的看到进程信息,如下:

-
top -Hp pid:确定好哪个进程 CPU 占用高后,可以通过 top -Hp pid 命令查看指定进程的每个线程的 CPU 占用情况。需要注意的是top -Hp pid中的 pid 指的是第一步中确定的进程的pid,而 命令输出中的 pid 则是指的进程中的 线程id。如下图中
top -Hp 2150, 这里的 2150 指的是进程id,而输出中CPU 占用最高的 PID 为 2183,这个PID 为 线程id。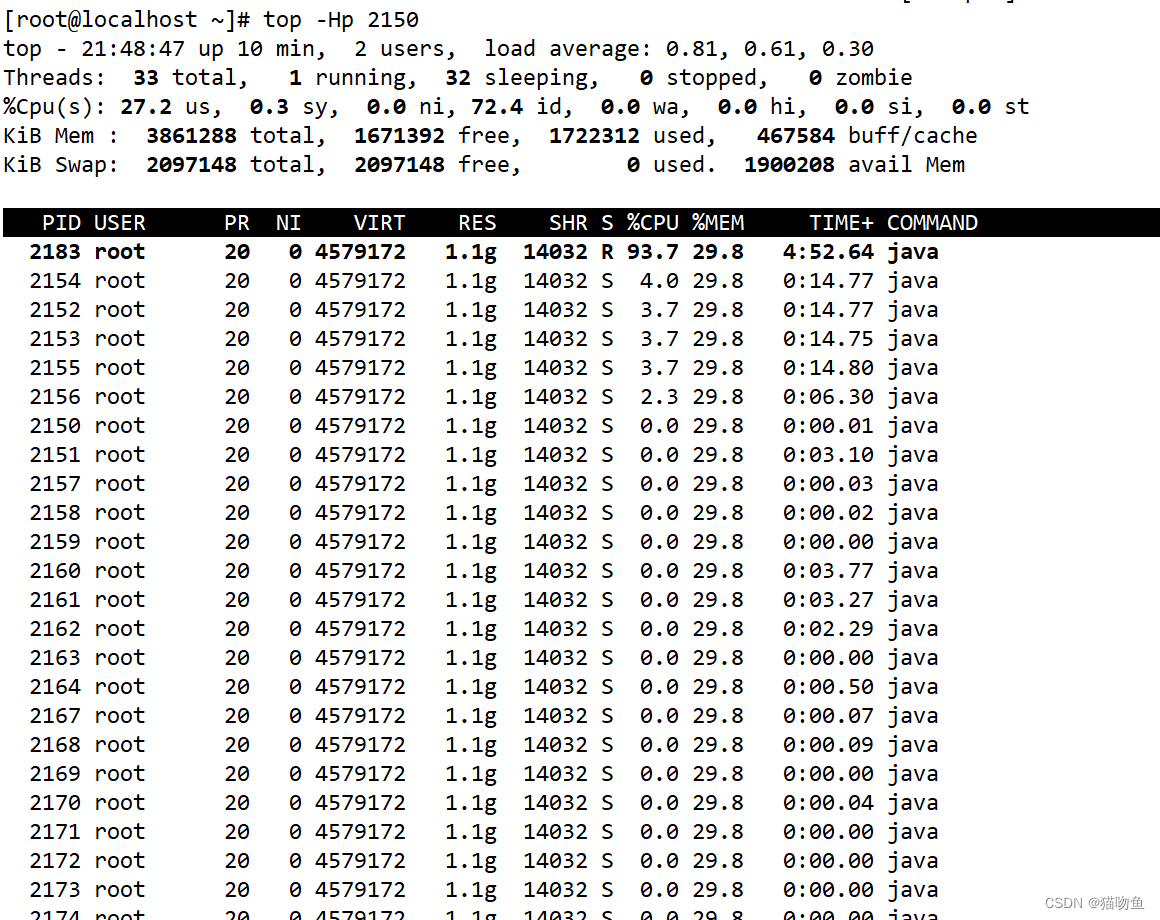
-
jstack pid: 通过 jstack pid 可以查看线程的具体信息( 可以通过jstack pid >/tmp/log.txt命令将内容输出到文件)。但我在本地测试的时候输出如下信息,无法输出正常数据,但所幸服务本身日志输出了对应内容 (因此次问题这里不做深究)。

jstack 命令正常输出线程信息如下:
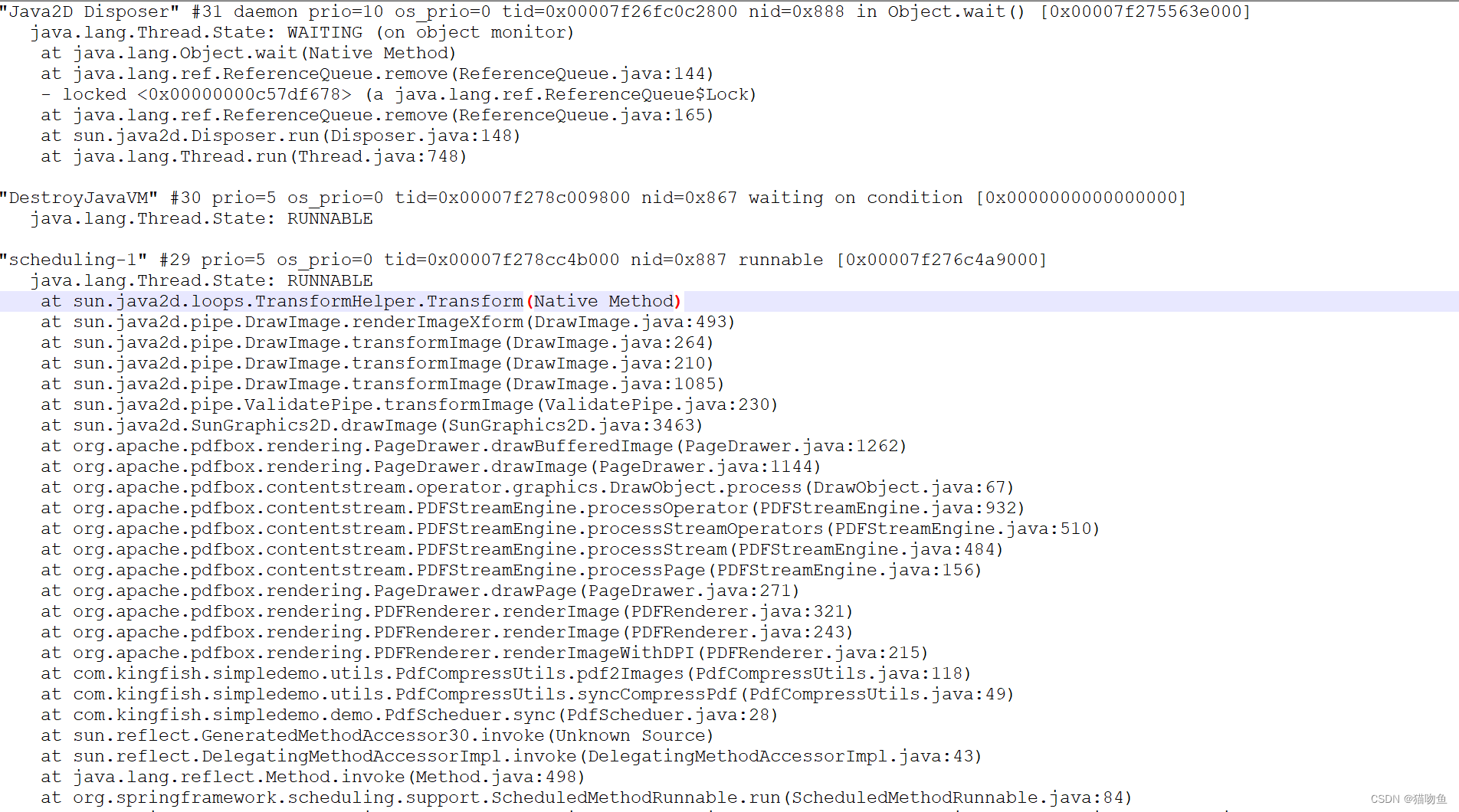
-
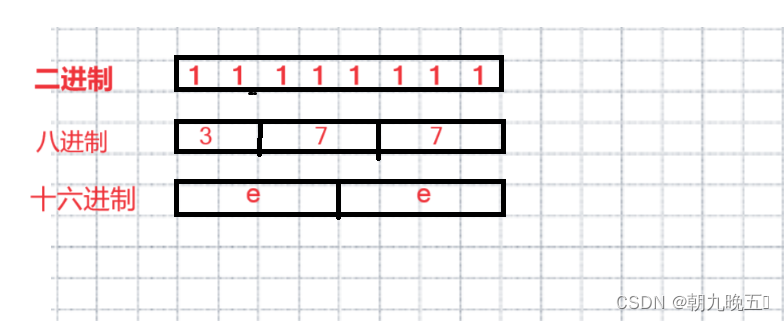
分析堆栈信息 :将
top -Hp pid记录下来的pid 转为十六进制,去 jstack日志文件中找,可以找到对应线程的代码,从而修改代码。
如 上面通过top -Hp 2150命令确定 pid 为 2183 的线程CPU占用较高,所以将 2183 转为十六进制为887,在 jstack 的日志中搜索 887 ,便可以根据搜索结果可以确定问题代码

五、参考内容
https://blog.csdn.net/zhou920786312/article/details/123572662
https://blog.csdn.net/weixin_44588186/article/details/124680586
https://zhuanlan.zhihu.com/p/657006095