动态查找介绍
1. 动态查找的引入:当查找表以线性表的形式组织时,若对查找表进行插入、删除或排序操作,就必须移动大量的记录,当记录数很多时,这种移动的代价很大。
2. 动态查找表的设计思想:表结构本身是在查找过程中动态生成的
若表中存在其关键字等于给定值key的记录,表明查找成功;否则插入关键字等于key的记录。
利用树的形式组织查找表,可以对查找表进行动态高效的查找。
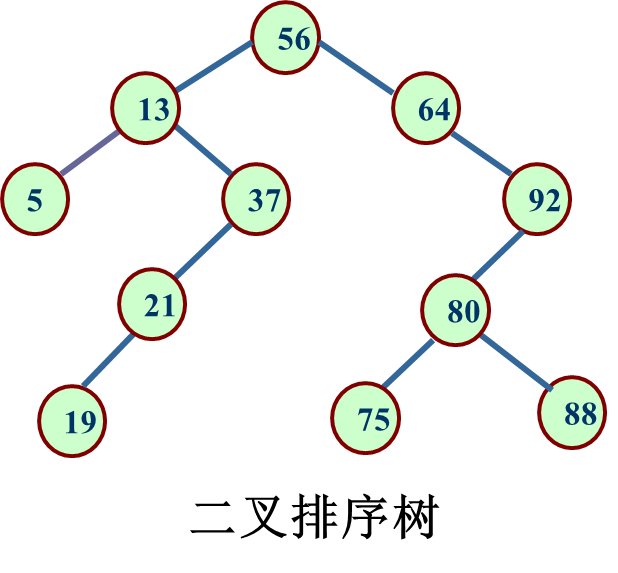
二叉排序树
1. 动态查找表的典型数据结构是二叉排序树,又称二叉查找树,其中序遍历输出为有序序列
二叉排序树是空树或者是具有如下特性的二叉树:
若它的左子树不空,则左子树上所有结点的值均小于根结点的值
若它的右子树不空,则右子树上所有结点的值均大于根结点的值
它的左、右子树也都分别是二叉排序树。
2. 二叉排序树的查找
给定值与根结点比较:
①.若相等,查找成功
②.若小于,查找左子树
③.若大于,查找右子树
实现代码
BSTNode *BST_Serach(BSTNode *T , KeyType key)
{ if (T==NULL) return(NULL) ;
else
{ if (EQ(T->key, key) )
return(T) ;
else if ( LT(key, T->key) )
return(BST_Serach(T->Lchild, key)) ;
else
return(BST_Serach(T->Rchild, key)) ;
}
}
3. 二叉排序树的插入
二叉排序树是一种动态树表
当树中不存在查找的结点时,作插入操作
新插入的结点一定是叶子结点,只需改动一个结点的指针
该叶子结点是查找不成功时路径上访问的最后一个结点左孩子或右孩子(新结点值小于或大于该结点值)
实现代码
void Insert_BST (BSTNode *T , KeyType key)
{ BSTNode *x ;
x=(BSTNode *)malloc(sizeof(BSTNode)) ;
x->key=key;
x->Lchild=x->Rchild=NULL ;
if (T==NULL)
T=x ;
else
{ if (EQ(T->key, x->key) ) return ;/* 已有结点 */
else if (LT(x->key, T->key) )
Insert_BST(T->Lchild, key) ;
else
Insert_BST(T->Rchild, key) ;
}
}
4. 性能分析
在最好的情况下,二叉排序树为一近似完全二叉树时,其查找深度为log2n量级,即其时间复杂性为O(log2n)
在最坏的情况下,二叉排序树为近似线性表时(如以升序或降序输入结点时),其查找深度为n量级,即其时间复杂性为O(n)
5. 其他
一个无序序列可以通过构造一棵二叉排序树而变成一个有序序列(通过中序遍历)
插入新记录时,只需改变一个结点的指针,相当于在有序序列中插入一个记录而不需要移动其它记录
二叉排序树既拥有类似于折半查找的特性O(log2n),又采用了链表作存储结构
当插入记录的次序不当时(如升序或降序),则二叉排序树深度很深O(n),增加了查找的时间
6. 实现代码
#include<iostream>
using namespace std;
class node {
public:
int data;
node *left, *right;
node(int value) {
data = value;
left = right = nullptr;
}
};
class bitree {
private:
bool flag = false;
int l;
node *root;
public:
bitree() {
cin >> l;
root = nullptr;
for (int i = 0; i < l; i++) {
int tmp;
cin >> tmp;
root = insert(root, tmp);
}
pre_order(root);
cout << endl;
}
//二叉树的创建和插入
node *insert(node *q, int t) {
if (q == nullptr) {
q = new node(t);
return q;
}
if (q->data <= t)
q->right = insert(q->right, t);
else
q->left = insert(q->left, t);
return q;
}
//独立插入
void insert_More() {
int t;
cin >> t;
while (t--) {
int tmp;
cin >> tmp;
insert(root, tmp);
pre_order(root);
cout << endl;
}
}
//二叉排序树之查找
void search_start() {
int t;
cin >> t;
while (t--) {
flag = false;
int tmp;
cin >> tmp;
int num = 0;
search(root, tmp, num);
if (flag)
cout << num << endl;
else
cout << -1 << endl;
}
}
void search(node *p, int tmp, int &num) {
if (p == nullptr)
return;
num++;
if (p->data == tmp) {
flag = true;
return;
}
if (tmp > p->data)
search(p->right, tmp, num);
else
search(p->left, tmp, num);
}
//先序遍历
void pre_order(node *p) {
if (p == nullptr)
return;
pre_order(p->left);
cout << p->data << " ";
pre_order(p->right);
}
};
平衡二叉树
1. 为解决而擦汗排序树的插入记录次序不当问题, 我们引入了二叉排序(查找)树的另一种形式—平衡二叉树,又被称为AVL树,其特点在于树中每个结点的左右子树深度之差的绝对值不大于1
2. 平衡因子
每个结点附加一个数字, 给出该结点左子树的高度减去右子树的高度所得的高度差,这个数字即为结点的平衡因子balance
AVL树任一结点平衡因子只能取 -1, 0, 1
3. 平衡化旋转,又称为平衡化处理,如果在一棵平衡的二叉查找树中插入一个新结点或者删除一个旧结点,造成了不平衡,此时必须调整树的结构,使之平衡化
平衡化旋转的操作:
每插入一个新结点时, AVL树中相关结点的平衡状态会发生改变
在插入一个新结点后,需要从插入位置沿通向根的路径回溯,检查各结点的平衡因子
如果在某一结点发现高度不平衡,停止回溯。
从发生不平衡的结点起,沿刚才回溯的路径取下两层的结点。对这三个结点进行平衡化处理
平衡化旋转有四种:
单向右旋,LL型,LL是指不平衡的三结点是双亲-左孩子-左孩子
单向左旋,RR型,RR是指不平衡的三结点是双亲-右孩子-右孩子
先左后右双向旋转,LR型,LR是指不平衡的三结点是双亲-左孩子-右孩子
先右后左双向旋转,RL型,RL是指不平衡的三结点是双亲-右孩子-左孩子
注意:英文类型简称是指不平衡状态,不是指旋转方向
注意:中文旋转名称是指旋转方向
B树
B树是一种多路平衡查找树,应用内存和磁盘间的查找
B树又分B-树、B+树,一般把B-树称为B树
B-树
1. m阶B-树规定:
⑴ 根结点或者是叶子,或者至少有两棵子树,至多有m棵子树;
⑵ 除根结点外,所有非终端结点至少有ém/2ù棵子树,至多有m棵子树
⑶ 所有叶子结点都在树的同一层上;
⑷ 每个结点应包含如下信息:
(n,A0,K1,A1,K2,A2,… ,Kn,An)
n是n个关键字,A是孩子指针,K是关键字
(5) Ki<Ki+1 且Ai所指向的子树中所有结点的关键字都在Ki和Ki+1之间
2. B-树的特点
m阶B-树即m叉树,m是树的度
m是指树结点最多包含m个孩子指针
每个树结点中,关键字的数量比孩子指针数量少1
根结点可以有2到m个孩子指针
叶子结点的关键字数量不受限制,孩子指针都是空指针,数量无意义
中间结点包含ém/2ù到m个孩子指针,即包含ém/2ù-1到m-1个关键字
B+树
1. 基本概念
在实际的文件系统中,基本上不使用B-树,而是使用B-树的一种变体,称为m阶B+树。
B+树与B-树的主要不同是叶子结点中存储记录。
在B+树中,所有的非叶子结点可以看成是索引,而其中的关键字是作为“分界关键字”,用来界定某一关键字的记录所在的子树。
即B+树中,所有结果信息都在叶子,查找结束必定在叶子
2. B+树的特点
与B-树相比,对B+树不仅可以从根结点开始按关键字随机查找,而且可以从最小关键字起,按叶子结点的链接顺序进行顺序查找。
在B+树上进行随机查找、插入、删除的过程基本上和B-树类似。
在B+树上进行随机查找时,若非叶子结点的关键字等于给定的K值,并不终止,而是继续向下直到叶子结点(只有叶子结点才存储记录), 即无论查找成功与否,都走了一条从根结点到叶子结点的路径。
平衡二叉树AVL-Tree的改进——红黑树RB-Tree
红黑树是一种不那么严格的平衡二叉树
它允许不平衡达到一倍,即左右子树高度差可以达到一倍
RBT是用非严格的平衡来换取增删结点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决
AVL是严格平衡树,因此在增加或者删除结点的时候,根据不同情况,旋转的次数比红黑树要多。所以红黑树的插入效率更高!!