写在前面
Redis作为我们日常工作中最常使用的缓存数据库,其重要性不言而喻,作为普通开发者,我们在日常开发中使用Redis,主要聚焦于Redis的基层数据结构的命令使用,很少会有人对Redis的内部实现机制进行了解,对于我而言,也是如此,但一直以来,我对于Redis的内部实现都很好奇,它为什么会如此高效,本系列文章是旨在对Redis源代码分析拆解,通过阅读Redis源代码,了解Redis基础数据结构的实现机制。
关于Redis的源码分析,已经有非常多的大佬写过相关的内容,最为著名的是《Redis设计与实现》,对于Redis源码的分析已经非常出色,本系列文章对于源码拆解时,并不会那么详细,相信大部分读者应该不是从事Redis的二次开发工作,对于源码细节过于深入,会陷入细节的泥潭,这是我在阅读源码时尽量避免的,我尽量做到对大体的脉络进行梳理,讲清楚主干逻辑,细节部分,如果读者有兴趣,可以自行参阅源码或相关资料。
本系列源代码,基于Redis 3.2.6
前言
在上两篇中
浅析Redis①:命令处理核心源码分析(上)
浅析Redis②:命令处理之epoll实现(中)
我们大致了解了Redis客户端命令请求的处理流程,在整个流程中,我们了解了Redis是如何处理来自客户端的命令请求,epoll的执行逻辑,我们还有最后一个问题没有解释,Redis是如何将数据写回Client端的?
本篇我们就围绕第一个问题,寻找答案,继续看Redis客户端命令请求的处理流程。
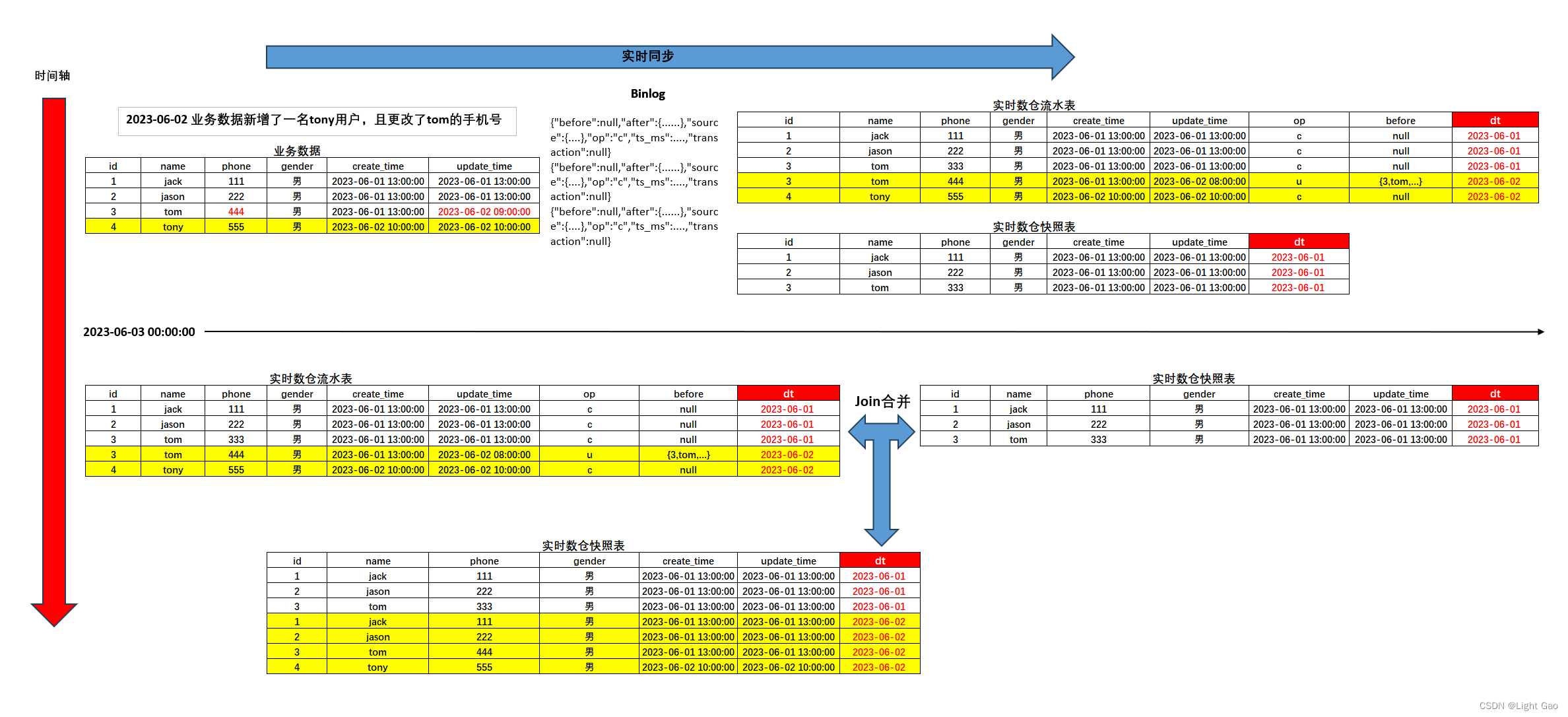
Redis数据返回Client端流程
Redis在命令处理时,在命令执行的末尾,都会调用一个addReply(),这里我们以最简单的STRING get为例:
t_string.c getGenericCommand()
int getGenericCommand(client *c) {
robj *o;
// 从字典中查询数据
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)
return C_OK;
// 将数据返回Client
if (o->type != OBJ_STRING) {
addReply(c,shared.wrongtypeerr);
return C_ERR;
} else {
addReplyBulk(c,o);
return C_OK;
}
}
void addReplyBulk(client *c, robj *obj) {
addReplyBulkLen(c,obj);
addReply(c,obj);
addReply(c,shared.crlf);
}
继续看addReply()的实现:
networking.c addReply()
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
// 核心,将数据写入内存缓存区,等待后续流程处理,写回Client Socket
if (sdsEncodedObject(obj)) {
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyObjectToList(c,obj);
} else if (obj->encoding == OBJ_ENCODING_INT) {
if (listLength(c->reply) == 0 && (sizeof(c->buf) - c->bufpos) >= 32) {
char buf[32];
int len;
len = ll2string(buf,sizeof(buf),(long)obj->ptr);
if (_addReplyToBuffer(c,buf,len) == C_OK)
return;
}
obj = getDecodedObject(obj);
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyObjectToList(c,obj);
decrRefCount(obj);
} else {
serverPanic("Wrong obj->encoding in addReply()");
}
}
上述流程,是string get命令执行后,数据处理的流程,可以发现,Redis并没有将数据直接返回Client端,而是将数据写入了一个叫做缓冲区的内存区域,那么缓冲区是什么?
Redis的内存缓冲区
在 Redis 中,缓冲区(buffer)是用于存储数据的内存区域。Redis 使用缓冲区来管理数据的读取、写入和传输过程。
Redis 的缓冲区主要有两个方面的应用:
- 输入缓冲区(Input Buffer):当 Redis 接收到客户端发送的命令请求时,会先将请求数据存储在输入缓冲区中,然后再进行解析和处理。输入缓冲区用于临时存储从网络或其他输入源接收到的原始数据。
- 输出缓冲区(Output Buffer):当 Redis 响应客户端的命令请求时,会先将响应数据存储在输出缓冲区中,然后再发送给客户端。输出缓冲区用于临时存储待发送的数据。
缓冲区在 Redis 中的作用是提高数据的处理效率和性能。通过使用缓冲区,Redis 可以批量读取和写入数据,减少了频繁的系统调用和网络传输开销。此外,缓冲区还可以用于临时存储数据,以便进行数据的加工和处理。
需要注意的是,Redis 缓冲区大小是有限的,它受到配置参数 client-output-buffer-limit 和 client-query-buffer-limit 的影响。
如果缓冲区已满,而输入或输出数据仍在不断到达,则可能导致连接被拒绝或数据丢失。
因此,在高并发或大数据量的场景中,需要根据实际情况调整缓冲区大小以保证系统的稳定性和性能。
OK,命令处理部分流程结束,我们把逻辑拉回到main函数中,聚焦aeMain():
ae.c aeMain()
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
在前两篇中,我们介绍过aeMain(),这里使用一个死循环,aeProcessEvents()轮询epoll是否存在就绪的事件,在aeProcessEvents()之前,我们需要关注beforesleep():
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
在轮询之前,都会执行beforesleep(),这个函数就是我们要关注的核心,继续看beforesleep()实现:
server.c beforeSleep()
void beforeSleep(struct aeEventLoop *eventLoop) {
....
....
此处省略部分非核心代码
....
/* Write the AOF buffer on disk */
flushAppendOnlyFile(0);
// 将数据写回Client
handleClientsWithPendingWrites();
}
networking.c handleClientsWithPendingWrites()
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
......
省略部分非核心代码
// 核心,将数据通过socket返回Client
if (writeToClient(c->fd,c,0) == C_ERR) continue;
// 还有部分数据没有写完,加入epoll,等待异步执行
if (clientHasPendingReplies(c) &&
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,
sendReplyToClient, c) == AE_ERR)
{
// 释放内存
freeClientAsync(c);
}
}
return processed;
}
上述代码是执行数据返回Client的核心逻辑,可以参见代码注释,令人疑惑的部分是,为什么这段代码中,writeToClient()可能会执行两次?
原因如下:
第一次调用 writeToClient() 是为了尝试向客户端套接字写入数据。这里的目的是将服务器待发送的数据写入到套接字缓冲区中,以便后续通过网络发送给客户端。如果写入成功,则会继续判断该客户端是否还有待发送的数据。
第二次调用 writeToClient() 是在判断客户端是否还有待发送的数据后执行的。如果客户端仍然有待发送的数据,那么说明套接字的发送缓冲区已满,无法一次性将所有数据发送出去。此时,为了确保后续的数据能够被及时发送,需要将该客户端的套接字注册到可写事件上,以便在套接字可写时继续发送剩余的数据。
需要注意的是,第二次调用 writeToClient() 并不会立即执行数据的发送,而是在套接字变为可写时由事件循环机制触发相应的写入操作。
这样可以避免在套接字无法写入数据时出现阻塞的情况,提高服务器的并发性能。
OK,我们继续看writeToClient() 的实现逻辑。
networking.c writeToClient()
int writeToClient(int fd, client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
size_t objlen;
size_t objmem;
robj *o;
// 循环读取内存缓冲区的数据,写回socket,返回Client端
while(clientHasPendingReplies(c)) {
if (c->bufpos > 0) {
// 核心,执行socket写回
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
/* If the buffer was sent, set bufpos to zero to continue with
* the remainder of the reply. */
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
} else {
o = listNodeValue(listFirst(c->reply));
objlen = sdslen(o->ptr);
objmem = getStringObjectSdsUsedMemory(o);
if (objlen == 0) {
listDelNode(c->reply,listFirst(c->reply));
c->reply_bytes -= objmem;
continue;
}
nwritten = write(fd, ((char*)o->ptr)+c->sentlen,objlen-c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
/* If we fully sent the object on head go to the next one */
if (c->sentlen == objlen) {
listDelNode(c->reply,listFirst(c->reply));
c->sentlen = 0;
c->reply_bytes -= objmem;
}
}
.........
省略部分非核心代码
.........
}
.........
省略部分非核心代码
.........
return C_OK;
}
writeToClient()就是核心写入的部分了,这里获取redisClient对象的bufpos,可以理解为缓冲区中的标记位置,如果存在待写入的数据,循环调用系统方法write写入socket的FD中。
write() 函数用于向文件描述符(包括套接字)写入数据。在这段代码中,write() 函数被用于将数据写入到客户端的套接字中,即向客户端发送数据。
就此,Redis将数据返回Client的流程,我们就了解完毕。
老规矩,我们还是用一张流程图来简略描述整个过程: