【自然语言处理(NLP)】基于注意力机制的中-英机器翻译

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于注意力机制的中-英机器翻译
- 前言
- (一)、任务描述
- (二)、环境配置
- 一、数据准备
- (一)、数据集下载
- (二)、构建双语句对的数据结构
- (三)、创建词表
- (四)、创建padding过的数据集
- 二、网络构建
- (一)、Encoder部分
- (二)、AttentionDecoder部分
- 三、模型训练
- 四、使用模型进行机器翻译
- 总结
前言
(一)、任务描述
本示例教程介绍如何使用飞桨完成一个机器翻译任务。
我们将会使用飞桨提供的LSTM的API,组建一个sequence to sequence with attention的机器翻译的模型,并在示例的数据集上完成从英文翻译成中文的机器翻译。
(二)、环境配置
本示例基于飞桨开源框架2.0版本。
import paddle
import paddle.nn.functional as F
import re
import numpy as np
print(paddle.__version__)
# cpu/gpu环境选择,在 paddle.set_device() 输入对应运行设备。
# device = paddle.set_device('gpu')
输出结果如下图1所示:

一、数据准备
(一)、数据集下载
我们将使用 http://www.manythings.org/anki/ 提供的中英文的英汉句对作为数据集,来完成本任务。该数据集含有23610个中英文双语的句对。
!wget -c https://www.manythings.org/anki/cmn-eng.zip && unzip cmn-eng.zip
!wc -l cmn.txt
输出结果如下图2所示:

(二)、构建双语句对的数据结构
接下来我们通过处理下载下来的双语句对的文本文件,将双语句对读入到python的数据结构中。这里做了如下的处理。
- 对于英文,会把全部英文都变成小写,并只保留英文的单词。
- 对于中文,为了简便起见,未做分词,按照字做了切分。
- 为了后续的程序运行的更快,我们通过限制句子长度,和只保留部分英文单词开头的句子的方式,得到了一个较小的数据集。这样得到了一个有5508个句对的数据集。
MAX_LEN = 10
lines = open('cmn.txt', encoding='utf-8').read().strip().split('\n')
words_re = re.compile(r'\w+')
pairs = []
for l in lines:
en_sent, cn_sent, _ = l.split('\t')
pairs.append((words_re.findall(en_sent.lower()), list(cn_sent)))
# create a smaller dataset to make the demo process faster
filtered_pairs = []
for x in pairs:
if len(x[0]) < MAX_LEN and len(x[1]) < MAX_LEN and \
x[0][0] in ('i', 'you', 'he', 'she', 'we', 'they'):
filtered_pairs.append(x)
print(len(filtered_pairs))
for x in filtered_pairs[:10]: print(x)
输出结果如下图3所示:

(三)、创建词表
接下来我们分别创建中英文的词表,这两份词表会用来将英文和中文的句子转换为词的ID构成的序列。词表中还加入了如下三个特殊的词: - : 用来对较短的句子进行填充。 - : “begin of sentence”, 表示句子的开始的特殊词。 - : “end of sentence”, 表示句子的结束的特殊词。
Note: 在实际的任务中,可能还需要通过(或者)特殊词来表示未在词表中出现的词。
en_vocab = {}
cn_vocab = {}
# create special token for pad, begin of sentence, end of sentence
en_vocab['<pad>'], en_vocab['<bos>'], en_vocab['<eos>'] = 0, 1, 2
cn_vocab['<pad>'], cn_vocab['<bos>'], cn_vocab['<eos>'] = 0, 1, 2
en_idx, cn_idx = 3, 3
for en, cn in filtered_pairs:
for w in en:
if w not in en_vocab:
en_vocab[w] = en_idx
en_idx += 1
for w in cn:
if w not in cn_vocab:
cn_vocab[w] = cn_idx
cn_idx += 1
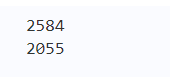
print(len(list(en_vocab)))
print(len(list(cn_vocab)))
输出结果如下图4所示:
(四)、创建padding过的数据集
接下来根据词表,我们将会创建一份实际的用于训练的用numpy array组织起来的数据集。 - 所有的句子都通过补充成为了长度相同的句子。 - 对于英文句子(源语言),我们将其反转了过来,这会带来更好的翻译的效果。 - 所创建的padded_cn_label_sents是训练过程中的预测的目标,即,每个中文的当前词去预测下一个词是什么词。
padded_en_sents = []
padded_cn_sents = []
padded_cn_label_sents = []
for en, cn in filtered_pairs:
# reverse source sentence
padded_en_sent = en + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(en))
padded_en_sent.reverse()
padded_cn_sent = ['<bos>'] + cn + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(cn))
padded_cn_label_sent = cn + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(cn) + 1)
padded_en_sents.append([en_vocab[w] for w in padded_en_sent])
padded_cn_sents.append([cn_vocab[w] for w in padded_cn_sent])
padded_cn_label_sents.append([cn_vocab[w] for w in padded_cn_label_sent])
train_en_sents = np.array(padded_en_sents)
train_cn_sents = np.array(padded_cn_sents)
train_cn_label_sents = np.array(padded_cn_label_sents)
print(train_en_sents.shape)
print(train_cn_sents.shape)
print(train_cn_label_sents.shape)
输出结果如下图5所示:

二、网络构建
我们将会创建一个Encoder-AttentionDecoder架构的模型结构用来完成机器翻译任务。 首先我们将设置一些必要的网络结构中用到的参数。
embedding_size = 128
hidden_size = 256
num_encoder_lstm_layers = 1
en_vocab_size = len(list(en_vocab))
cn_vocab_size = len(list(cn_vocab))
epochs = 20
batch_size = 16
(一)、Encoder部分
在编码器的部分,我们通过查找完Embedding之后接一个LSTM的方式构建一个对源语言编码的网络。飞桨的RNN系列的API,除了LSTM之外,还提供了SimleRNN, GRU供使用,同时,还可以使用反向RNN,双向RNN,多层RNN等形式。也可以通过dropout参数设置是否对多层RNN的中间层进行dropout处理,来防止过拟合。
除了使用序列到序列的RNN操作之外,也可以通过SimpleRNN, GRUCell, LSTMCell等API更灵活的创建单步的RNN计算,甚至通过继承RNNCellBase来实现自己的RNN计算单元。
# encoder: simply learn representation of source sentence
class Encoder(paddle.nn.Layer):
def __init__(self):
super(Encoder, self).__init__()
self.emb = paddle.nn.Embedding(en_vocab_size, embedding_size,)
self.lstm = paddle.nn.LSTM(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_encoder_lstm_layers)
def forward(self, x):
x = self.emb(x)
x, (_, _) = self.lstm(x)
return x
(二)、AttentionDecoder部分
在解码器部分,我们通过一个带有注意力机制的LSTM来完成解码。
-
单步的LSTM:在解码器的实现的部分,我们同样使用LSTM,与Encoder部分不同的是,下面的代码,每次只让LSTM往前计算一次。整体的recurrent部分,是在训练循环内完成的。
-
注意力机制:这里使用了一个由两个Linear组成的网络来完成注意力机制的计算,它用来计算出目标语言在每次翻译一个词的时候,需要对源语言当中的每个词需要赋予多少的权重。
-
对于第一次接触这样的网络结构来说,下面的代码在理解起来可能稍微有些复杂,你可以通过插入打印每个tensor在不同步骤时的形状的方式来更好的理解。
# only move one step of LSTM,
# the recurrent loop is implemented inside training loop
class AttentionDecoder(paddle.nn.Layer):
def __init__(self):
super(AttentionDecoder, self).__init__()
self.emb = paddle.nn.Embedding(cn_vocab_size, embedding_size)
self.lstm = paddle.nn.LSTM(input_size=embedding_size + hidden_size,
hidden_size=hidden_size)
# for computing attention weights
self.attention_linear1 = paddle.nn.Linear(hidden_size * 2, hidden_size)
self.attention_linear2 = paddle.nn.Linear(hidden_size, 1)
# for computing output logits
self.outlinear =paddle.nn.Linear(hidden_size, cn_vocab_size)
def forward(self, x, previous_hidden, previous_cell, encoder_outputs):
x = self.emb(x)
attention_inputs = paddle.concat((encoder_outputs,
paddle.tile(previous_hidden, repeat_times=[1, MAX_LEN+1, 1])),
axis=-1
)
attention_hidden = self.attention_linear1(attention_inputs)
attention_hidden = F.tanh(attention_hidden)
attention_logits = self.attention_linear2(attention_hidden)
attention_logits = paddle.squeeze(attention_logits)
attention_weights = F.softmax(attention_logits)
attention_weights = paddle.expand_as(paddle.unsqueeze(attention_weights, -1),
encoder_outputs)
context_vector = paddle.multiply(encoder_outputs, attention_weights)
context_vector = paddle.sum(context_vector, 1)
context_vector = paddle.unsqueeze(context_vector, 1)
lstm_input = paddle.concat((x, context_vector), axis=-1)
# LSTM requirement to previous hidden/state:
# (number_of_layers * direction, batch, hidden)
previous_hidden = paddle.transpose(previous_hidden, [1, 0, 2])
previous_cell = paddle.transpose(previous_cell, [1, 0, 2])
x, (hidden, cell) = self.lstm(lstm_input, (previous_hidden, previous_cell))
# change the return to (batch, number_of_layers * direction, hidden)
hidden = paddle.transpose(hidden, [1, 0, 2])
cell = paddle.transpose(cell, [1, 0, 2])
output = self.outlinear(hidden)
output = paddle.squeeze(output)
return output, (hidden, cell)
三、模型训练
接下来我们开始训练模型。
-
在每个epoch开始之前,我们对训练数据进行了随机打乱。
-
我们通过多次调用atten_decoder,在这里实现了解码时的recurrent循环。
-
teacher forcing策略: 在每次解码下一个词时,我们给定了训练数据当中的真实词作为了预测下一个词时的输入。相应的,你也可以尝试用模型预测的结果作为下一个词的输入。(或者混合使用)
encoder = Encoder()
atten_decoder = AttentionDecoder()
opt = paddle.optimizer.Adam(learning_rate=0.001,
parameters=encoder.parameters()+atten_decoder.parameters())
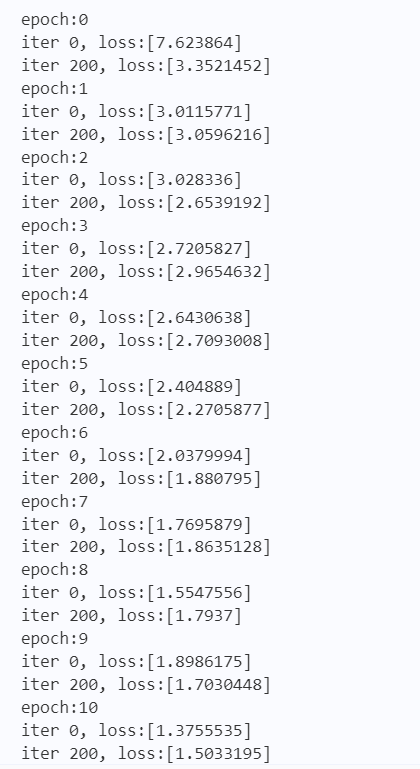
for epoch in range(epochs):
print("epoch:{}".format(epoch))
# shuffle training data
perm = np.random.permutation(len(train_en_sents))
train_en_sents_shuffled = train_en_sents[perm]
train_cn_sents_shuffled = train_cn_sents[perm]
train_cn_label_sents_shuffled = train_cn_label_sents[perm]
for iteration in range(train_en_sents_shuffled.shape[0] // batch_size):
x_data = train_en_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
x_cn_data = train_cn_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
x_cn_label_data = train_cn_label_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
# shape: (batch, num_layer(=1 here) * num_of_direction(=1 here), hidden_size)
hidden = paddle.zeros([batch_size, 1, hidden_size])
cell = paddle.zeros([batch_size, 1, hidden_size])
loss = paddle.zeros([1])
# the decoder recurrent loop mentioned above
for i in range(MAX_LEN + 2):
cn_word = paddle.to_tensor(x_cn_data[:,i:i+1])
cn_word_label = paddle.to_tensor(x_cn_label_data[:,i])
logits, (hidden, cell) = atten_decoder(cn_word, hidden, cell, en_repr)
step_loss = F.cross_entropy(logits, cn_word_label)
loss += step_loss
loss = loss / (MAX_LEN + 2)
if(iteration % 200 == 0):
print("iter {}, loss:{}".format(iteration, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
输出结果如下图6所示:
四、使用模型进行机器翻译
根据你所使用的计算设备的不同,上面的训练过程可能需要不等的时间。(在一台Mac笔记本上,大约耗时15~20分钟) 完成上面的模型训练之后,我们可以得到一个能够从英文翻译成中文的机器翻译模型。接下来我们通过一个greedy search来实现使用该模型完成实际的机器翻译。(实际的任务中,你可能需要用beam search算法来提升效果)
encoder.eval()
atten_decoder.eval()
num_of_exampels_to_evaluate = 10
indices = np.random.choice(len(train_en_sents), num_of_exampels_to_evaluate, replace=False)
x_data = train_en_sents[indices]
sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
word = np.array(
[[cn_vocab['<bos>']]] * num_of_exampels_to_evaluate
)
word = paddle.to_tensor(word)
hidden = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
cell = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
decoded_sent = []
for i in range(MAX_LEN + 2):
logits, (hidden, cell) = atten_decoder(word, hidden, cell, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
results = np.stack(decoded_sent, axis=1)
for i in range(num_of_exampels_to_evaluate):
en_input = " ".join(filtered_pairs[indices[i]][0])
ground_truth_translate = "".join(filtered_pairs[indices[i]][1])
model_translate = ""
for k in results[i]:
w = list(cn_vocab)[k]
if w != '<pad>' and w != '<eos>':
model_translate += w
print(en_input)
print("true: {}".format(ground_truth_translate))
print("pred: {}".format(model_translate))
输出结果如下图7所示:

总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~

![[附源码]java毕业设计旅游管理系统](https://img-blog.csdnimg.cn/d810b775759d408d827bffb3db1f18f4.png)
![[数据结构]二叉树之堆的实现](https://img-blog.csdnimg.cn/66b4d8d77691495bbaf165ab164f6d44.png)








![[Games 101] Lecture 13-16 Ray Tracing](https://img-blog.csdnimg.cn/8058414ed2c4402e9620c1a9c082d7d2.png)