概述
k8s的后端存储中ceph应用较为广泛,当前的存储市场仍然是由一些行业巨头垄断,但在开源市场还是有一些不错的分布式存储,其中包括了Ceph、Swift、sheepdog、glusterfs等
什么是ceph?
Ceph需要具有可靠性(reliability)、可扩展性(scalability)、统一性(unified)和可分布式(distributed)存储特性。
可靠性主要分为两点,
- 第一,写入数据的强一致性,它并非是最终一致性,必须完成多副本的成功写入才能提交
- 第二,通过多副本保证数据不丢失,避免因为单个服务器或者单个机架的故障导致数据丢失。
可扩展性
- 主要指通过增加系统节点数,扩大系统规模的同时,系统的存储容量也相应提高,当然在理想情况下应该成线性关系,Ceph的OSD支持动态添加,
- 当集群容量不足时,通过增加OSD节点便可以扩展集群的容量,并且Ceph能够自动完成数据重新分配。
统一性
- Ceph能够同时支持文件存储、对象存储和块存储。这些特点最终都得利用Ceph分布式的架构设计和去中心化的设计思想
回想当时Sage博士的论文,在传统的通过HA保障高可用的大众方案里面,Ceph超前地使用了CRUSH和Hash环的方案,极具创意
这个视频讲得不错
ceph的架构
分布式存储可以搭建在普通x86服务器集群之上,主要依靠多副本完成数据高可靠性,它提供了Ceph FS(Ceph File System)文件存储系统和POSIX接口、RADOSGW(Reliable Antonomic Distributed Object Storage Gateway)的对象存储,以及最常用的块存储RDB(Rados Block Device)。
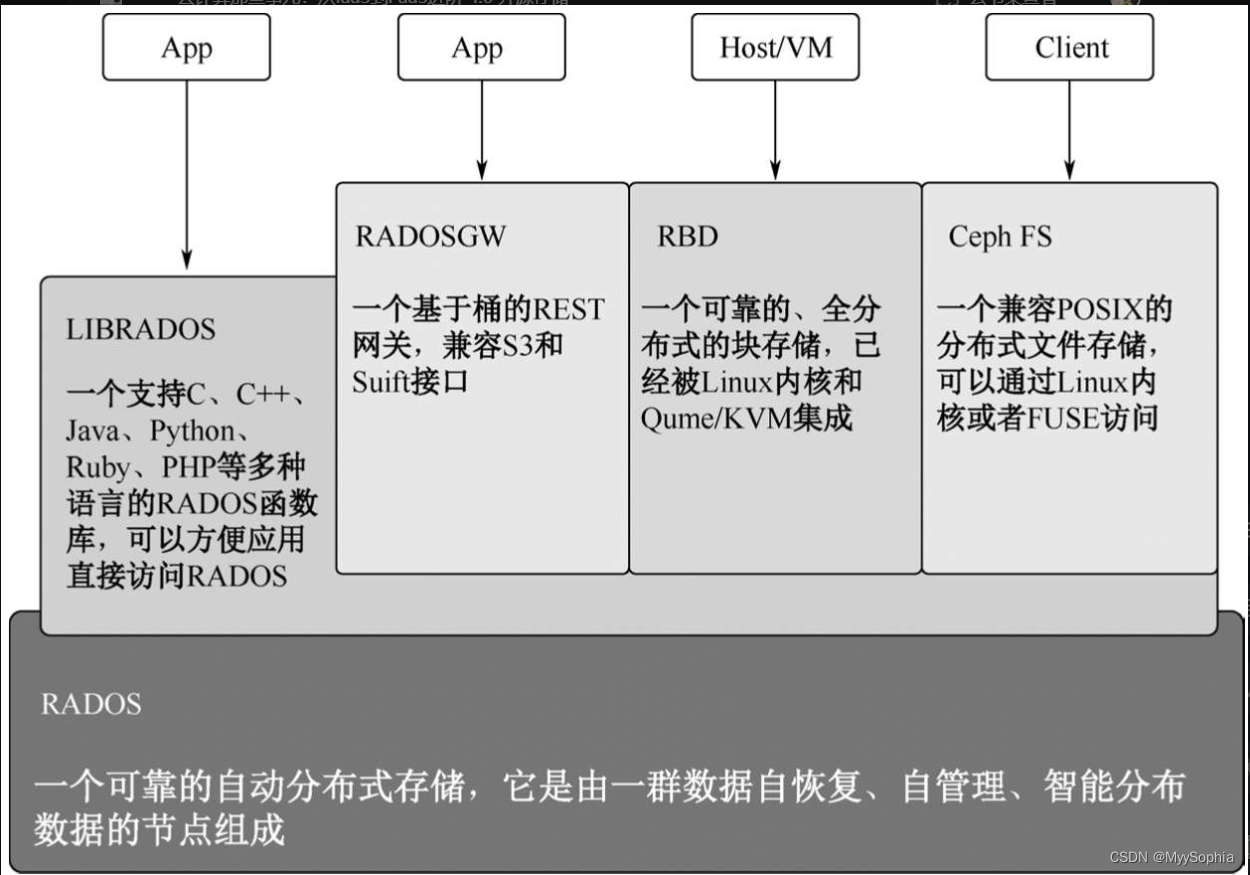
整个Ceph存储模块,最底层是RODOS对象存储系统,上面分别通过四种接口对外暴露不同的服务。
1)通过RADOSGW实现AWS的S3接口和OpenStack的Swift接口,提供对象存储服务;
2)通过LIBRADOS提供编程调用的API,支持C++、Python、Java等编程接口;
3)实现POSIX协议的文件存储;
4)通过Librbd块存储库提供块存储接口,可以为虚拟机或者物理机提供虚拟块存储服务。
Ceph OSD
Ceph OSD:Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph存储集群,要求至少有两个Ceph OSD,才能有效地保存两份数据。注意,这里两个Ceph OSD是指运行在两台物理服务器上的,并不是在一台物理服务器上开两个Ceph OSD的守护进程。
Ceph的数据并非直接保存在OSD节点上,需要一定组织形式,这里引入三个概念,既然是对象存储,
第一个概念当然是对象(Object),Ceph最底层的存储单元是对象,默认4MB的存储大小,每个Object包含唯一标识ID、元数据和对象内容。但Ceph并不直接维护object,而是将它们分成逻辑组,这就引出了第二个概念PG(Placement Group,放置组),PG是一个逻辑概念,引入PG这一层其实是为了更好地分配和定位数据,它是数据迁移的最小单位,从图中可以看出一个文件会拆分出很多Object对象,每个对象都有一个ID,称为oid。通过Hash取模确定所属PG,每个对象只属于一个PG,然后将PG分配到一个OSD中,如果对象的副本数是3个,那么这个PG会通CRUSH算法分布到三个OSD中,其中一个OSD的PG是Primary PG(主副本),另外两个OSD上面的是Replicated PG(从副本),Primary PG负责PG中对象读写操作,而Replicated PG是只读的。每个OSD上面都会承载多个PG。整个分布流程图如图
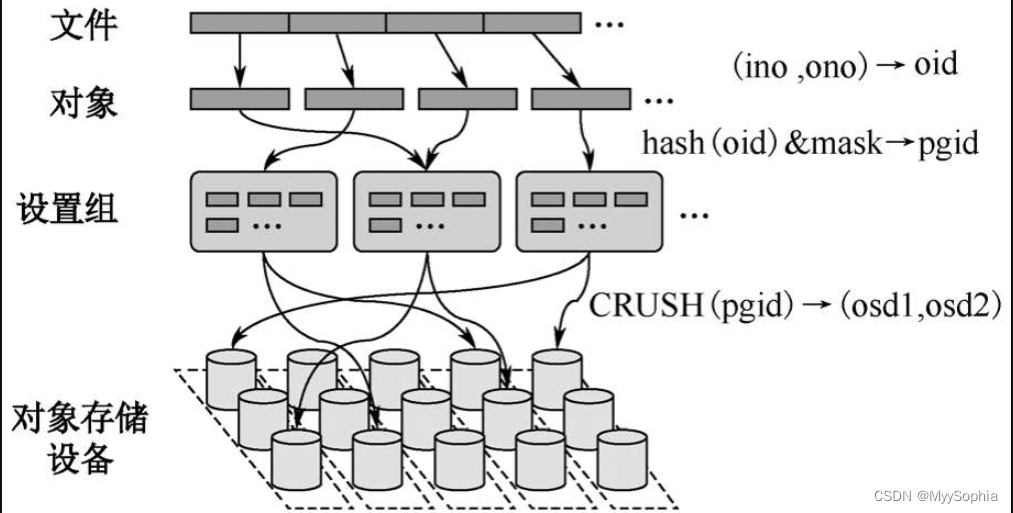
当一个OSD设备发生故障时(主机宕机或者存储设备损坏),这个OSD所有的PG都会处于Degraded(降级)状态,此时数据是可以继续读写的。如果OSD长时间(默认5分钟)无法启动,该OSD会被“踢出”Ceph集群,这些PG会被Monitor根据Crush算法重新分配到其他OSD上。
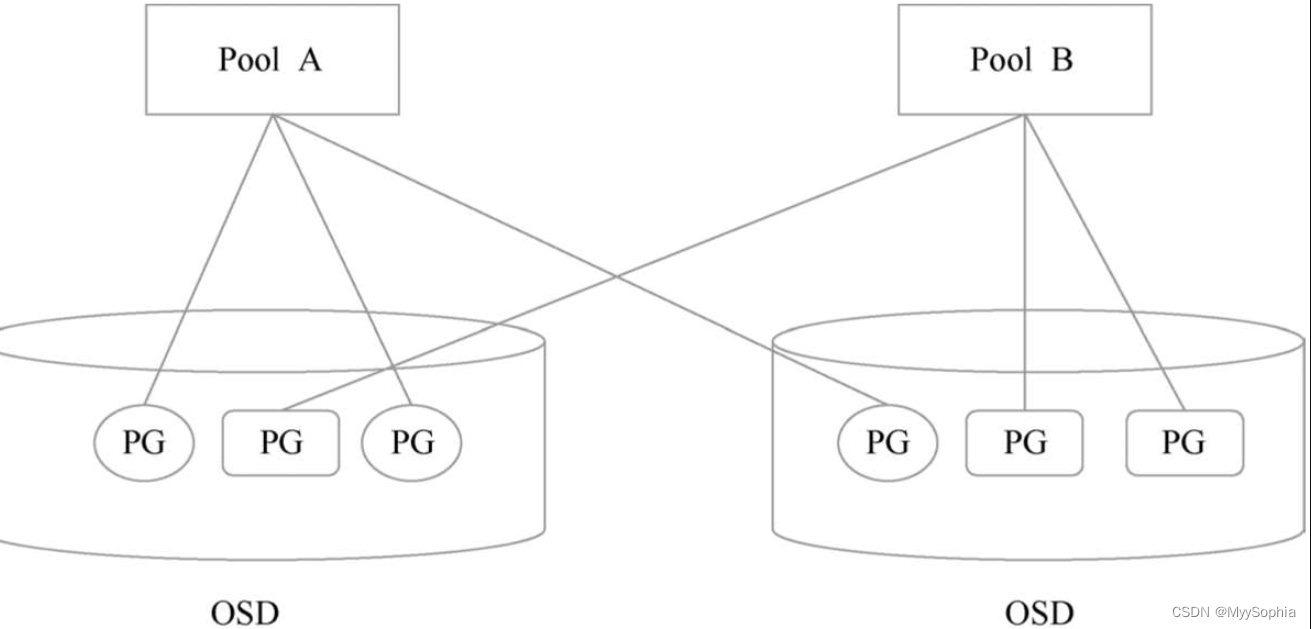
第三个概念是Pool。Pool是Ceph存储数据时的逻辑分区,它定义了数据的冗余方式(差错码、副本)和副本的分布策略,如下图所示。不同的Pool可以定义不同的数据处理方式,如Replicated Size(副本数)、PG个数、Crush规则等。
Ceph Monitor
Ceph的Monitor是一个守护进程,主要功能是维护集群状态的表,主要是Monitor Map、OSD Map、PG Map等。这些表记录了整个集群的信息。
OSD Map
OSD Map负责记录Ceph集群中所有OSD的信息。OSD节点的变化如节点的加入和退出、OSD运行状态,以及节点权重的变化都会被定时上报到Monitor,并记录到OSD Map里。当新的OSD启动时,此时OSD Map并没有该OSD的情况,OSD会向Monitor申请加入,Monitor在验证其信息后会将其加入到OSD Map中,这里还涉及多个Monitor之间通过Paxos一致性协议保持OSD Map数据在多个Monitor之间数据的一致性。
PG Map
PG Map是由Monitor维护所有PG的状态,每个OSD都会掌握自己所拥有的PG状态。PG迁移需要Monitor通过CRUSH算法做出决定后修改PG Map,相关OSD会得到通知去改变其PG状态。在一个新的OSD启动并加入OSD Map后,Monitor会通知这个OSD需要创建和维护PG。当存在多个副本时,PG的Primary OSD会主动与Replicated角色的PG通信,并且沟通PG的状态。
CRUSH算法
CRUSH可译为可控的、可扩展的、分布式的副本数据放置算法。
通过CRUSH算法计算数据存储位置来确定如何存储和检索,从而Ceph客户端可以直接连接OSD读写数据,而非通过一个中央服务器或代理。数据存储、检索算法的使用,使Ceph避免了单点故障、性能瓶颈和伸缩的物理限制。
CRUSH算法决策需要两个因素
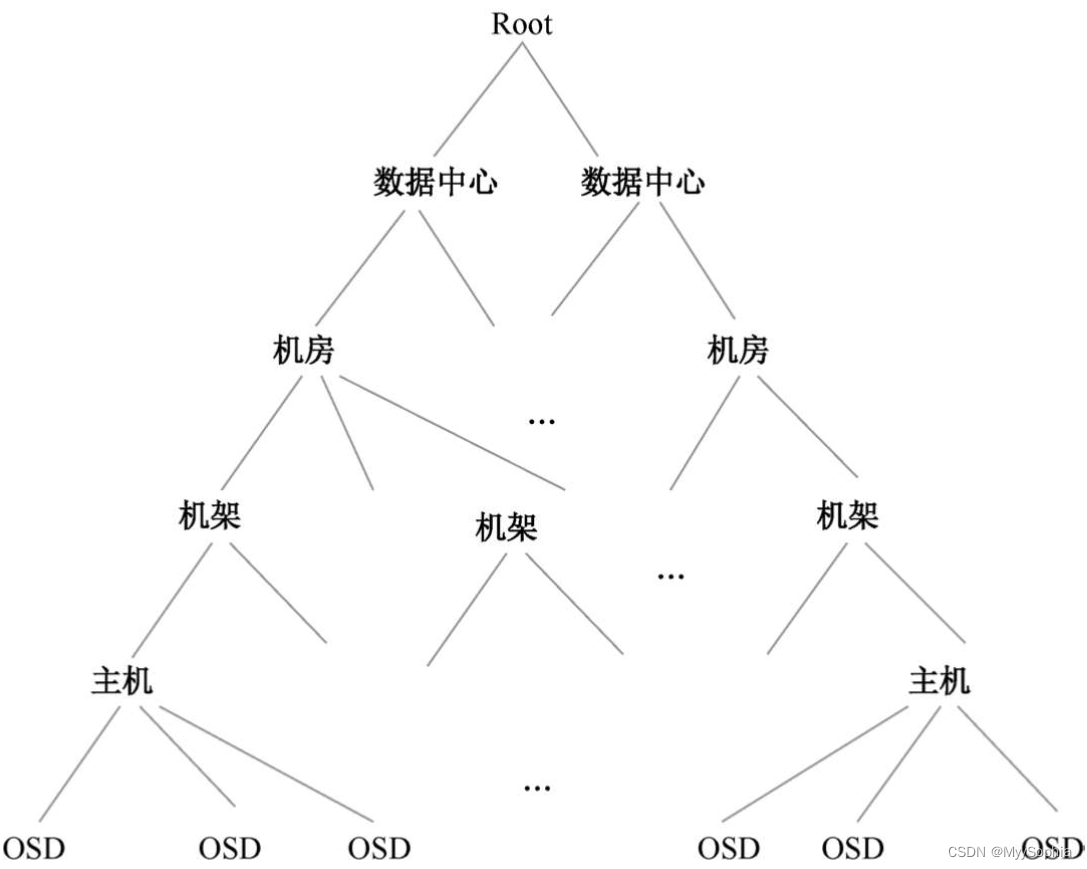
- 第一个因素是需要集群的完整拓扑结构Cluster Map,如图,定义整个OSD层次结构和静态拓扑。一方面CRUSH算法把数据伪随机、尽量平均地分布到整个集群的OSD上;另一方面,OSD层级使CRUSH算法在选择OSD时实现了机架感知能力,也就是通过规则定义,使得副本可以分布在不同的机架、不同的机房中,提供数据的可靠性。
- 第二个因素是放置规则列表,放置规则(CRUSH Rule)定义了从哪个节点开始查找,以及定义查找的方式。
Ceph的文件存储
Ceph的文件存储是建立在底层RADOS存储之上的,它是通过Ceph的Metadata Server (MDS)管理的。
Ceph的MDS
MDS:Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph FileSystem的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。只有使用Ceph FS的时候才需要安装。Ceph MDS基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等。Ceph FS读写数据示意图如图所示。
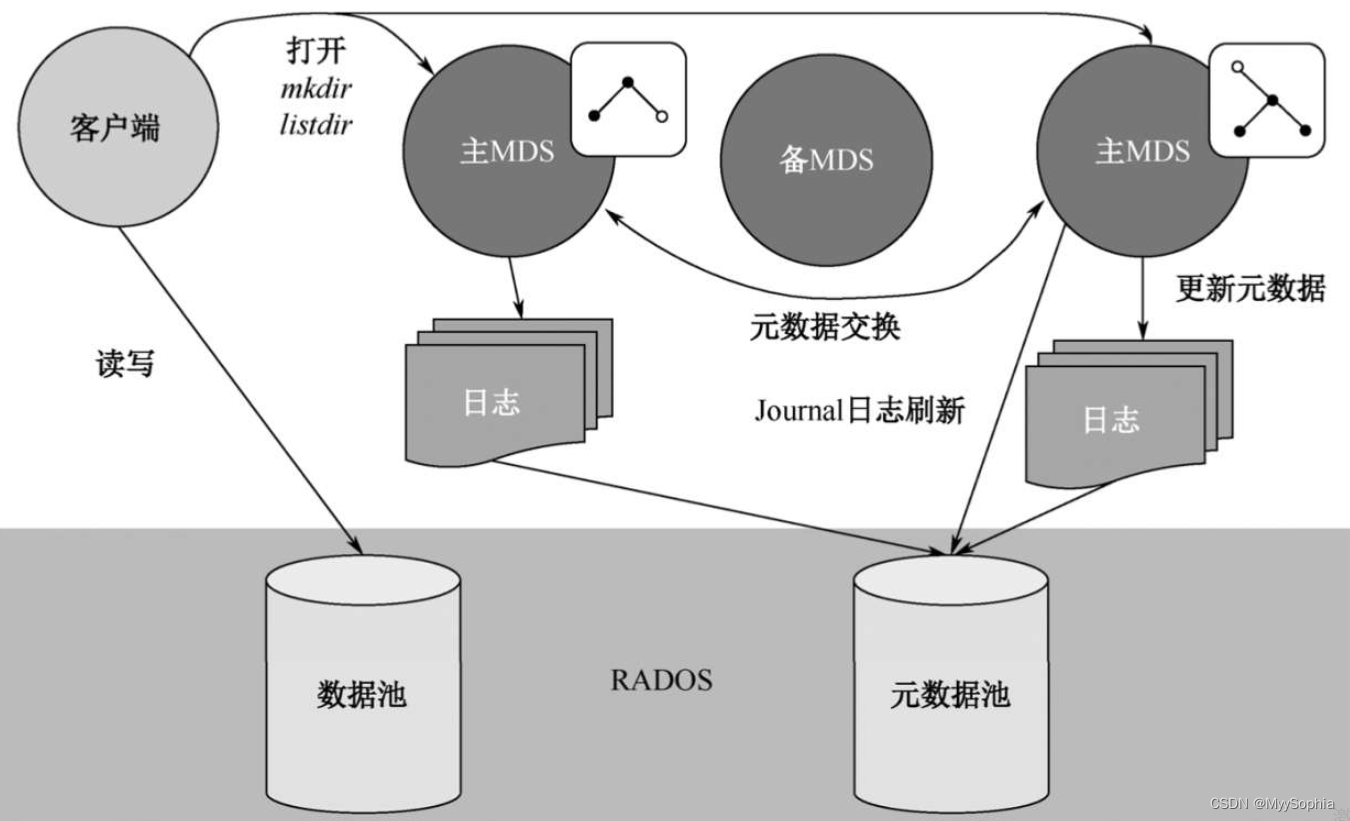
当客户端打开一个文件时,客户端向MDS发送请求,这里需要注意MDS只是负责接受用户的元数据请求,不是文件内容,然后MDS从OSD中把元数据取出来映射进自己的内存中供客户访问。
所以,MDS其实类似一个代理缓存服务器,在这个缓存服务器里面构建了一个目录树,并且可以获取目录下面文件的inode信息。当客户端获取MDS返回的文件后就可以直接与OSD交换了,真正完成数据的读写操作,这样就可以分担用户对OSD的访问压力。
ceph的不足
Ceph本身也存在自身缺陷,开源版本的Ceph部署和维护成本比较高,
Ceph的底层是对象存储,而对象又通过文件系统保存,这样过长地读写I/O路径对性能造成很大影响,并且一致Hash算法并不能保证数据完全均衡和负载。
所以,Ceph更建议在私有云的环境中,部署规模不要超过百台的场景中使用。
Ceph命令和使用
ceph部署
官方建议的机种部署方式
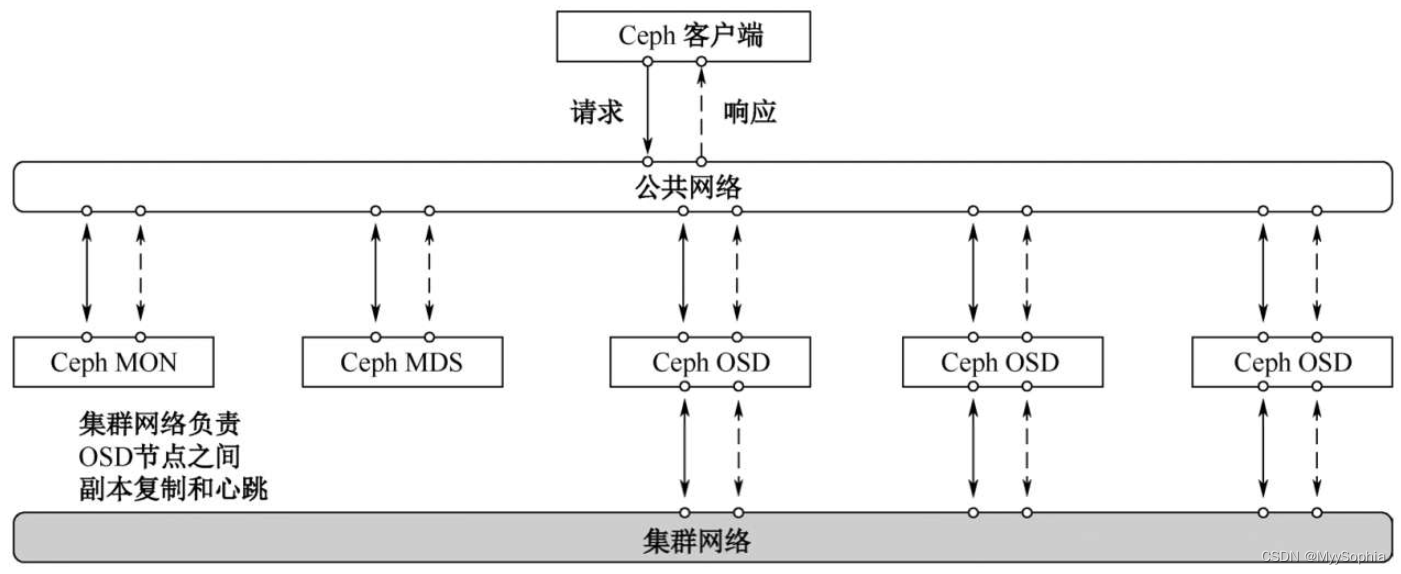
Ceph集群网络拓扑图
ceph 命令

Ceph 块存储的挂载
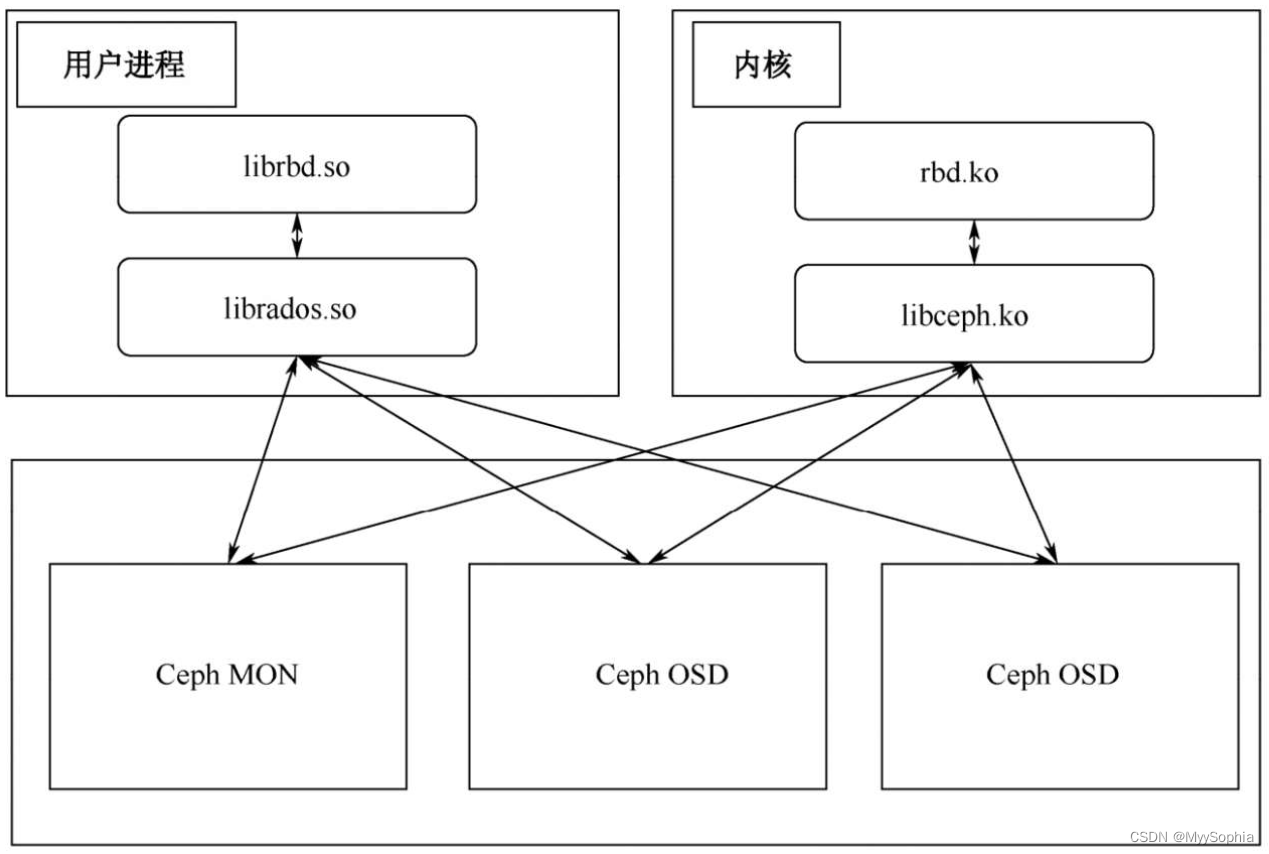
Ceph最常用的场景是它的RBD块存储。RBD块存储的使用有两种挂载方式,一种是通过nbd,再经过用户态的librbd挂载;另一种是通过内核模块的krdb,这种方式对内核版本有一定要求。Ceph RDB示意图如图
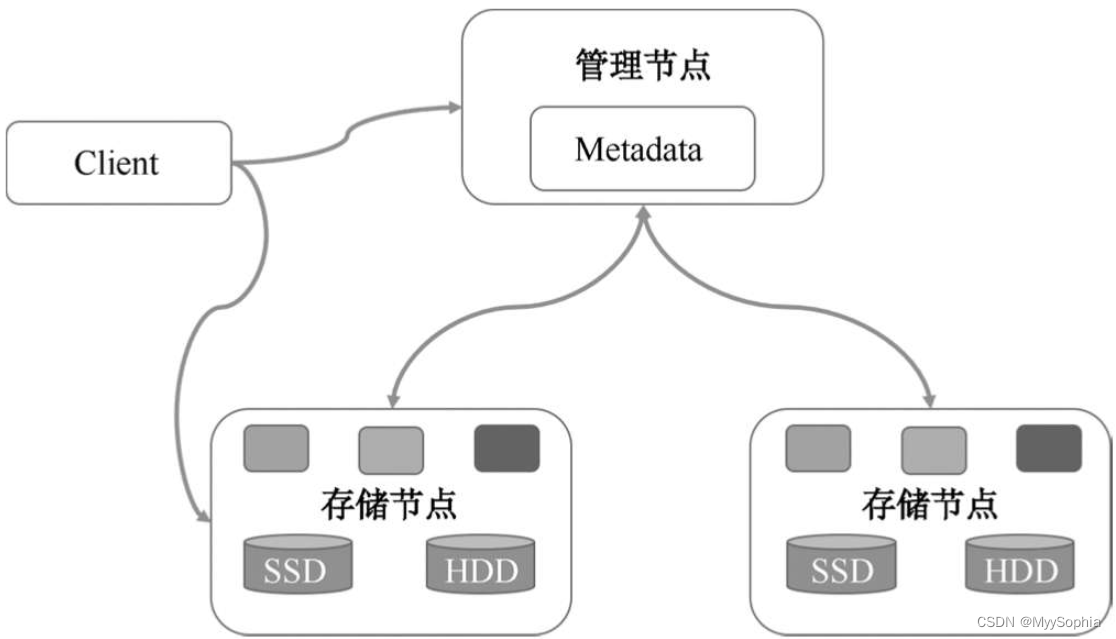
分布式存储架构
基本的原理
基本的原理的都是将文件拆分很多小块,成为条带化,然后将这些数据块通过多副本的方式保存到不同机器上,并记录这些块和文件的对应关系,以及块和机器的对应关系。
Master如何高可用?
为了保持数据的一致性,通常只有一个活动的Master,但单点的Master可靠性会大大降低,所以通常的做法是借助Zookeeper或者etcd,在Master宕机后,备用的Master成为活动的Master并接管之前Master的任务。例如,在HDFS存储中,Master叫作NameNode,分为Active NameNode和Standby NameNode,之间形成互备。其中有一个NameNode处于Active状态,为主NameNode,另外的处于Standby状态,为备NameNode,只有主NameNode才能对外提供读写服务,通过Zookeeper完成主备切换。
数据如何保持高可靠?
在分布式存储中,数据的高可靠通常不依赖底层的RAID,通过多副本或者erasure code的方式保证数据的可靠性。如果一个副本丢失,会拷贝一份其他节点的副本,通常是3副本的方式保存,一个主副本可读可写,而从副本只读。所有分布式系统都不能违背CAP定理,C(Consistency)的一致性,在这里指多副本数据的一致性;A(Availability)即可用性,这里指能够随时读写数据;P(Partition tolerance)即分区容错性,这里指能够容忍网络中断出现分区的情况。
在分布式系统中,P通常是必须要保证的,所以基本是在C和A中权衡。如果选择C则放弃可用性,当集群数据出现一致性问题后则停止对外提供数据写服务;如果是选择A,则可能会出现多副本数据不一致情况。但CAP现在已经有点过时了,因为A并不是绝对的可用或者不可用,而C也并不是一直保持强一致性。通常在一些要求不高的场景下,保证基本可用和弱一致即可,对应的是eBay工程师提出的BASE理论。BASE指基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventual Consistency),放弃了强一致,保证高可用。
数据如何分布?
这里通常有两种方式,一种是通过元数据的方式标识数据的分布的,例如,在HDFS中,NameNode里面保存所有块的元数据,元数据记录了块的名称,副本数,副本分布DataNode存储路径。另一种是通过DHT等算法计算并得到数据的分布,例如Swift采用的一致性Hash环算法,还有Ceph采用的rados算法。他们各有利弊,通过元数据的方式,避免在添加节点时数据迁移,但需要额外维护一套元数据,而通过算法的方式可以避免使用元数据,但在增减节点的时候,整个算法需要重新计算,导致大量数据重新分布,不仅影响集群性能,还有可能造成集群暂时不可用。
故障如何恢复?
首先是故障检测,master的故障检测上面已经介绍了,如果采用Metadata服务,需要将Metadata保存在高可用的数据存储中,如MySQL或者etcd中,从而避免切换master导致数据的丢失情况。如果是存储节点的检测则分为两种情况,第一种是整个计算节点宕机,这种情况一般是通过心跳解决,存储节点定时上报自己的状态和节点上面副本的情况,如果超时上报则认为节点故障,需要恢复整个节点的数据副本;第二种情况是磁盘故障,如果读写I/O报错、磁盘检查工具检查磁盘故障等,这种情况通常需要将磁盘隔离,并复制故障盘的数据。







![[Linux] 如何查看内核 Kernel 版本(查多个Kernel的方法)](https://img-blog.csdnimg.cn/bca860ba942e46f2a937c7845c085b72.png)