数据库database的包:
Python操作Mysql数据库-CSDN博客
效果:
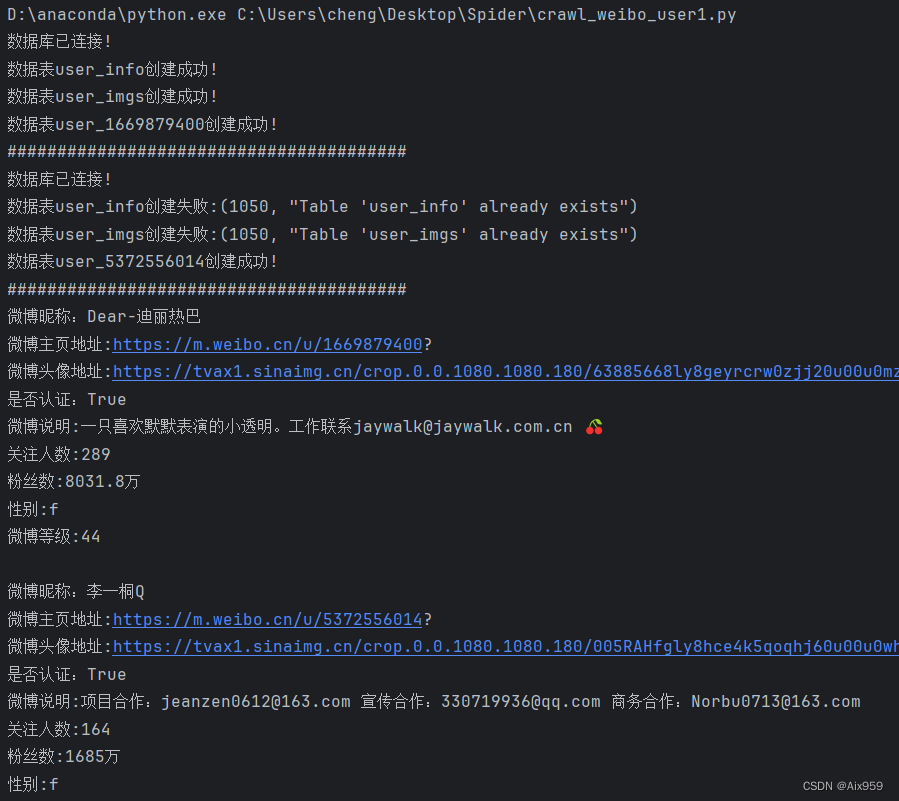
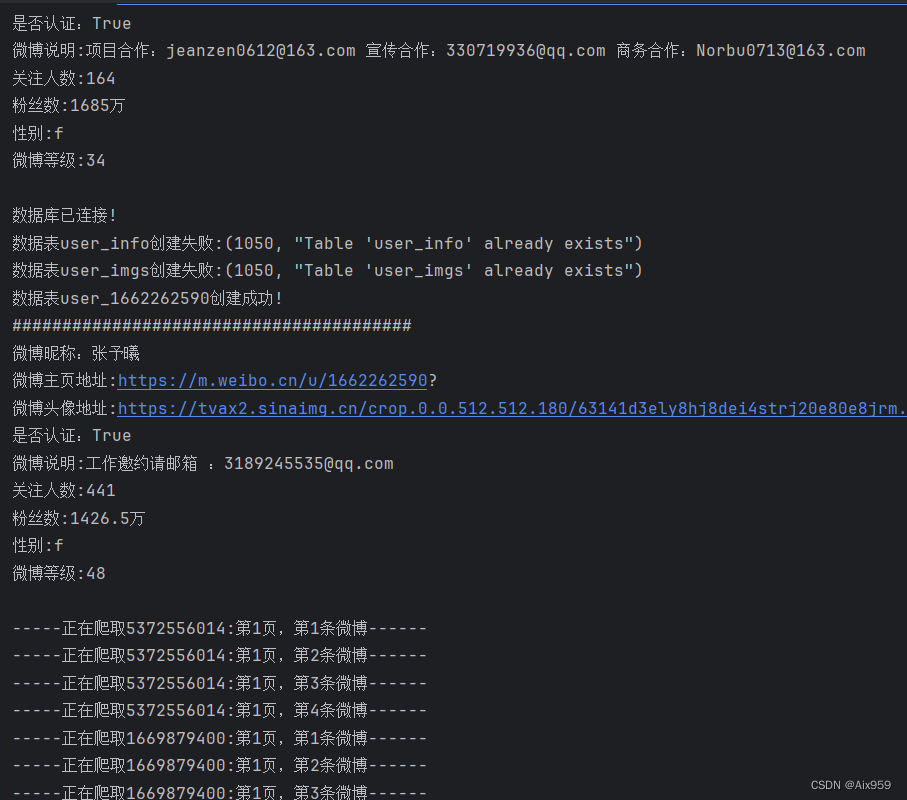
控制台输出:

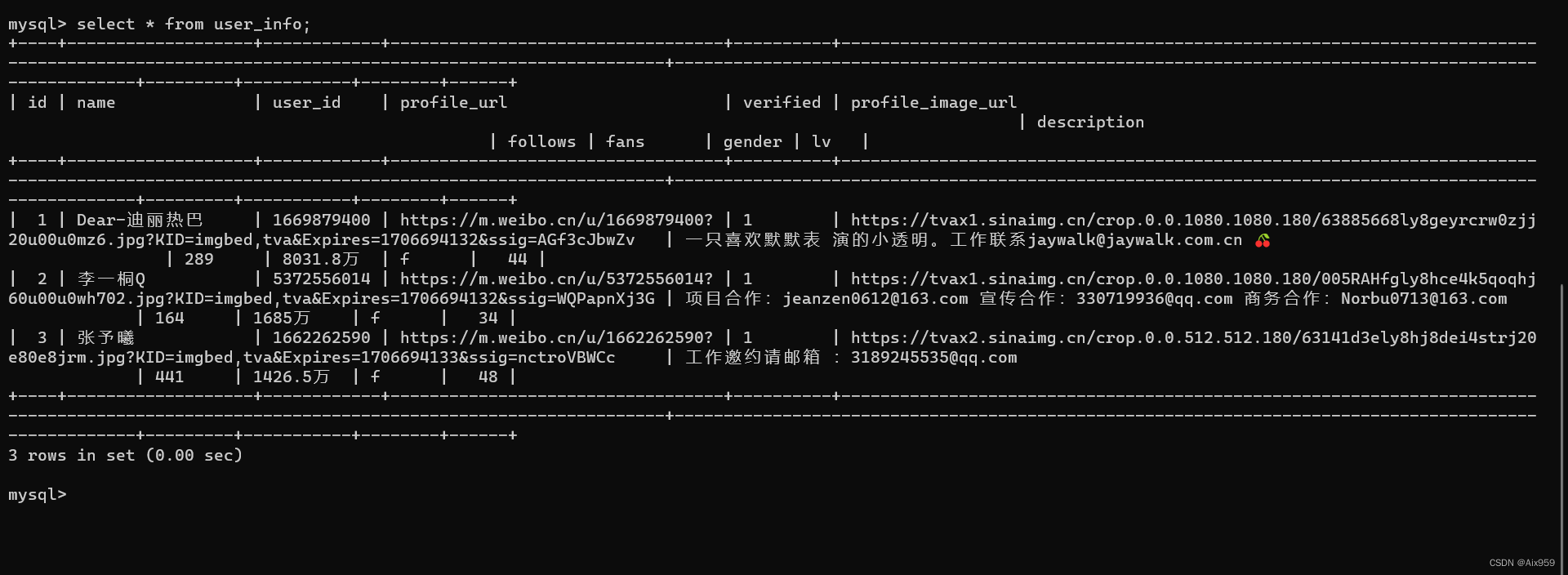
数据库记录:

全部代码:
import json
import os
import threading
import traceback
import requests
import urllib.request
from utils import make_headers, base64_encode_img, url_img_cv2img
from database import MyDataBase
class WeiboUserCrawler(threading.Thread):
def __init__(self, user_id: str, path: str = "weibo", proxy_addr: str = "122.241.72.191:808"):
super(WeiboUserCrawler, self).__init__(target=self.run)
self.user_id = user_id
self.path = path
self.proxy_addr = proxy_addr
self.url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + self.user_id
self.container_id = self.get_container_id(self.url)
self.page = 1 # 微博页数
self.pic_num = 0 # 图片编号
self.flag = True
self.wb_db = MyDataBase("localhost", "123456", charset="utf8mb4")
self.users_sheet = "user_info" # 所有用户信息表
self.user_sheet = "user_" + self.user_id # 单个用户内容表
self.imgs_sheet = "user_imgs" # 所有用户图片表
self.create_file()
self.create_db_tables()
print("####" * 10)
# 创建文件夹
def create_file(self):
if not os.path.exists(self.path):
os.makedirs(self.path)
if not os.path.exists(self.path + "/" + self.user_id):
os.makedirs(self.path + "/" + self.user_id)
# 创建三张表
def create_db_tables(self):
self.wb_db.connect()
kwargs = {
"id": "int primary key auto_increment",
"name": "varchar(128)",
"user_id": "varchar(20)",
"profile_url": "varchar(200)",
"verified": "varchar(50)",
"profile_image_url": "varchar(200)",
"description": "text",
"follows": "varchar(50)",
"fans": "varchar(50)",
"gender": "varchar(8)",
"lv": "tinyint"
}
self.wb_db.create_table(self.users_sheet, kwargs)
kwargs = {
"id": "int primary key auto_increment",
"u_id": "varchar(20)",
"url": "varchar(200)",
}
self.wb_db.create_table(self.imgs_sheet, kwargs)
kwargs = {
"id": "int primary key auto_increment",
"page": "int",
"locate": "varchar(128)",
"created_time": "varchar(128)",
"content": "text",
"praise": "varchar(50)",
"comments": "text",
"reposts": "varchar(50)",
}
self.wb_db.create_table(self.user_sheet, kwargs)
def use_proxy(self, url):
req = urllib.request.Request(url)
req.add_header("User-Agent", make_headers()["User-Agent"])
proxy = urllib.request.ProxyHandler({'http': self.proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read().decode('utf-8', 'ignore')
return data # 返回的是字符串
def get_container_id(self, url):
data = self.use_proxy(url)
# 通过json从获取的网页数据中,找到data
content = json.loads(data).get('data')
# 从data中找到container_id
for data in content.get('tabsInfo').get('tabs'):
if data.get('tab_type') == 'weibo':
container_id = data.get('containerid')
return container_id
def get_user_info(self):
data = self.use_proxy(self.url)
# 通过json从获取的网页数据中,找到data
content = json.loads(data).get('data')
# 从data数据中获取下列信息
profile_image_url = content.get('userInfo').get('profile_image_url')
description = content.get('userInfo').get('description')
profile_url = content.get('userInfo').get('profile_url')
verified = content.get('userInfo').get('verified')
follows = content.get('userInfo').get('follow_count')
name = content.get('userInfo').get('screen_name')
fans = content.get('userInfo').get('followers_count')
gender = content.get('userInfo').get('gender')
lv = content.get('userInfo').get('urank')
data = f"微博昵称:{name}\n微博主页地址:{profile_url}\n微博头像地址:{profile_image_url}\n" \
f"是否认证:{verified}\n微博说明:{description}\n关注人数:{follows}\n" \
f"粉丝数:{fans}\n性别:{gender}\n微博等级:{lv}\n"
print(data)
path = f"{self.path}/{self.user_id}/{self.user_id}.txt"
with open(path, 'a', encoding='utf-8') as f:
f.write(data)
# 数据库存用户
users_sheet_field = (
"name", "user_id", "profile_url", "verified", "profile_image_url", "description", "follows",
"fans", "gender", "lv")
data = [name, self.user_id, profile_url, verified, profile_image_url, description, follows, fans, gender,
lv]
res = self.wb_db.select_table_record(self.users_sheet, f"where user_id={self.user_id}")
for i in res:
if self.user_id in i:
print("该用户已在数据库!")
return
self.wb_db.insert_data(self.users_sheet, users_sheet_field, data)
# 存图下载图
def save_img(self, mblog):
try:
if mblog.get('pics'):
pic_archive = mblog.get('pics')
for _ in range(len(pic_archive)):
self.pic_num += 1
img_url = pic_archive[_]['large']['url']
img_data = requests.get(img_url)
path = f"{self.path}/{self.user_id}/{self.user_id}_{self.pic_num}{img_url[-4:]}"
with open(path, "wb") as f:
f.write(img_data.content)
# 数据库存图
imgs_sheet_field = ("u_id", "url")
data = [self.user_id, img_url]
self.wb_db.insert_data(self.imgs_sheet, imgs_sheet_field, data)
except Exception as err:
traceback.print_exc()
def save_data(self, j, mblog, cards):
path = f"{self.path}/{self.user_id}/{self.user_id}.txt"
attitudes_count = mblog.get('attitudes_count')
comments_count = mblog.get('comments_count')
created_at = mblog.get('created_at')
reposts_count = mblog.get('reposts_count')
scheme = cards[j].get('scheme')
text = mblog.get('text')
with open(path, 'a', encoding='utf-8') as f:
f.write(f"----第{self.page}页,第{j}条微博----" + "\n")
f.write(f"微博地址:{str(scheme)}\n发布时间:{str(created_at)}\n微博内容:{text}\n"
f"点赞数:{attitudes_count}\n评论数:{comments_count}\n转发数:{reposts_count}\n")
# 数据库存微博内容
user_sheet_field = ("page", "locate", "created_time", "content", "praise", "comments", "reposts")
data = [self.page, scheme, created_at, text, attitudes_count, comments_count, reposts_count]
self.wb_db.insert_data(self.user_sheet, user_sheet_field, data)
def process_data(self, data):
content = json.loads(data).get('data')
cards = content.get('cards')
if len(cards) > 0:
for j in range(len(cards)):
print(f"-----正在爬取{self.user_id}:第{self.page}页,第{j + 1}条微博------")
card_type = cards[j].get('card_type')
if card_type == 9:
mblog = cards[j].get('mblog')
self.save_img(mblog)
self.save_data(j, mblog, cards)
self.page += 1
else:
self.flag = False
def run(self):
try:
self.get_user_info()
while True:
weibo_url = f"{self.url}&containerid={self.container_id}&page={self.page}"
try:
data = self.use_proxy(weibo_url)
self.process_data(data)
if not self.flag:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>已完成{self.user_id}")
self.wb_db.close()
break
except Exception as err:
print(err)
except Exception as err:
print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>异常退出!')
self.wb_db.close()
if __name__ == '__main__':
# 1669879400 # 热巴
# 5372556014 # 李一桐
# 1662262590 # 张予曦
# uid = "1669879400"
# wb = WeiboUserCrawler(uid)
# wb.start()
uids = ["1669879400", "5372556014", "1662262590"]
for uid in uids:
t = WeiboUserCrawler(uid)
t.start()