一、集群存储算法
分布式存储的常见算法:
- 哈希取余分区
- 一致性哈希算法分区
- 哈希槽分区
1、哈希取余分区

描述:每次读写操作都是根据公式:Hash(key) % N(其中,key是要存入Redis的键名,N是
Redis集群的机器台数),计算出哈希值,用来决定数据映射到哪一个节点。
优点:简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一
段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固
定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:原来规划好的节点,如果进行扩容或者缩容,不管扩缩,每次数据变动导致节点有变动,映
射关系需要重新进行计算。在服务器个数固定不变时没问题,如果需要弹性扩容或故障停机的情
况下,原来取模公式就会发生变化:Hash(key) % N会变成Hash(key)/?。此时经过取余运算
的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机由于台数数量变化,会导致hash取余全部数据重新洗牌。
2、一致性哈希算法分区
背景:一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据
变动和映射问题。当某个机器宕机了,分母数量改变了,自然取余数就不适用。
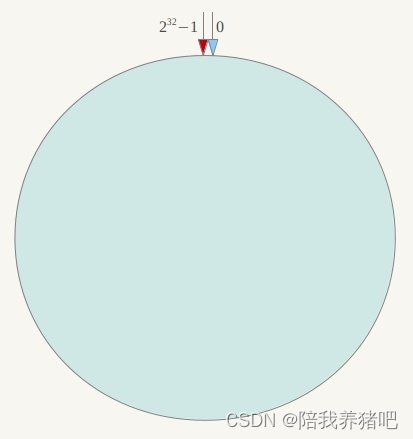
描述:一致性哈希算法必然有个hash函数并按照算法产生Hash值,这个算法的所有可能哈希值会
构成一个全量集,这个集合可以成为一个hash区间[0,2^32-1],这是一个线性空间。但是在这
个算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方式。前面的哈希取余算法是对节点(服务器)的数量进行取模,而一致性
哈希算法是对2^32取模。简单来说,一致性Hash算法将整个哈希值空间组成一个虚拟的圆环。如
假设某个哈希函数H的值空间为 0-(2^32 - 1)(即哈希值是一个32位无符号整形),整个哈希
环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以
此 类推,2、3、4.......直到2^32-1,也就是说0点左侧的第一个点代表 2^32-1。0 和 2^32-1在
零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
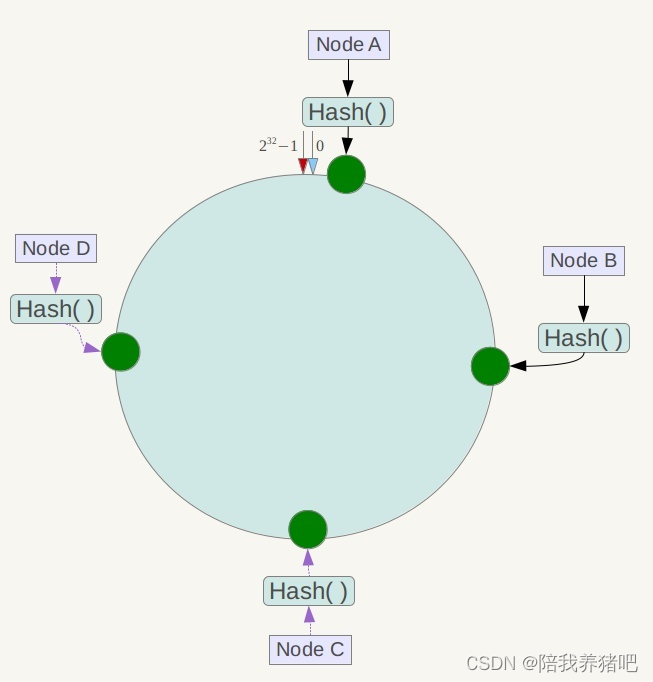
节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,
这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希
函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
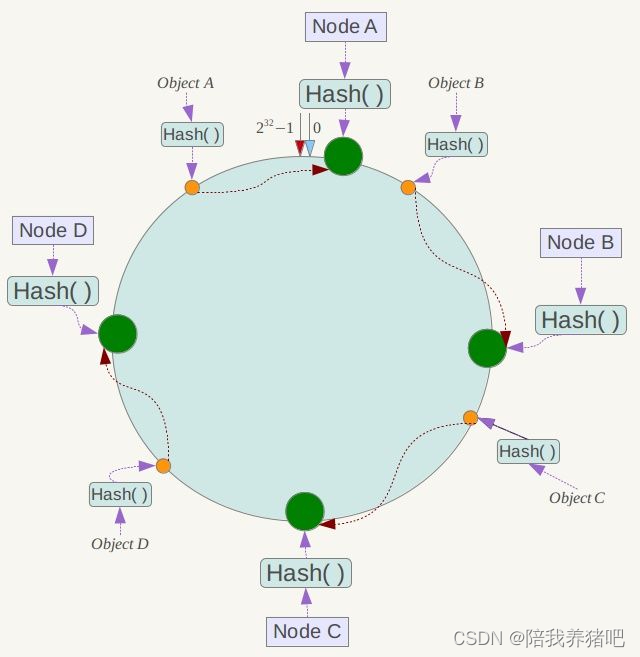
key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数
Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器
就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有ObiectA、ObiectB、Obiectc、obiectD四个数据对象,经过哈希计算后,在环空间上的位
置如下;根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到
NodeC上,D被定为到Node D上。
优点
一致性哈希算法的容错性

假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重新定位到Node D。
一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环
空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间的数据,其他不会受到影
响。
简单说:Node C宕机,受到影响的只是NodeB到NodeC之间的数据,并且这些数据会被转移到
Node D进行存储。
一致性哈希算法的扩展性
假如数据量增加,需要扩容增加一台节点Node X,Node X位于Node B和Node C之间,那受到影
响的就是Node B 到 Node X之间的数据。重新把Node B到Node X的数据录入到Node X上即可,
不会导致Hash取余全部数据重新洗牌。

缺点
一致性哈希算法的数据倾斜问题
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大
部分集中缓存到某一台服务器上)问题。
例如系统中只有两台服务器:

总结
为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储
节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储
时达不到均匀分布的效果。
3、哈希槽分区
为什么出现:哈希槽分区是为了解决一致性哈希算法的数据倾斜问题。
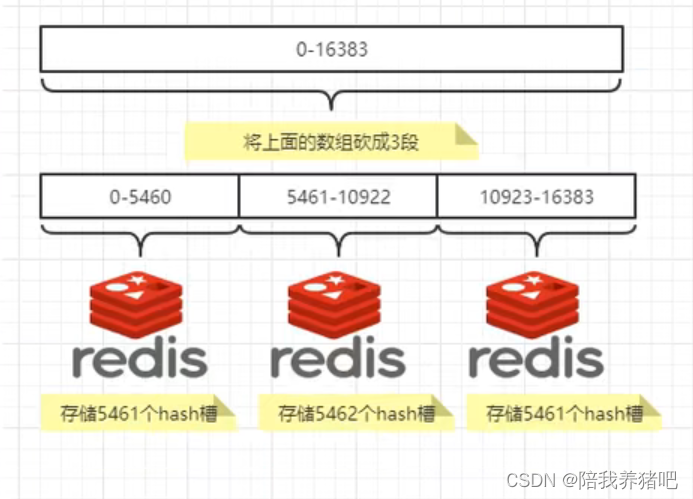
哈希槽实质上就是一个数组,数组[0,2^14-1]形成的hash slot空间。
能干什么:解决均匀分配的问题。在数据和节点之间又加入了一层,把这层称之为槽(slot),用
于管理数据和节点之间的关系。相当于节点上放的是槽,槽里面放的是数据。

槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
有多少个hash槽:
一个集群只能有16384个槽,编号0-16383(0 - 2^14-1)。这些槽会分配给集群中的所有主节
点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点,集群会记录节点和槽的对应关
系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就
落入对应的槽里。
slot = CRC16(key) % 16384以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
哈希槽计算
Redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节
点。当需要在Redis集群中放置一个Key-Value时,redis先对key使用CRC16算法算出一个结果,
然后把结果对16384取余,这样每个key都会对应一个编号在0-16383之间的哈希槽,也就是映射到
某个节点上。如下代码,key之A、B在Node2,key之C落在Node3上。
二 、Redis集群3主3从
1、搭建环境
# 启动第1台节点
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
# 启动第2台节点
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
# 启动第3台节点
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
# 启动第4台节点
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
# 启动第5台节点
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
# 启动第6台节点
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386命令详解:
# docker run 创建并运行docker容器实例
# --name redis-node-1 容器名字
# --net host 使用宿主机的IP和端口,默认
# --privilege=true 获取宿主机root用户权限
# -v /data/redis/share/redis-node-1:/data 容器卷,宿主机地址:docker内部地址
# reids:6.0.8 redis镜像和版本号
# --cluster-enabled yes 开启redis集群
# --appendonly yes 开启持久化
# --port 6381 redis端口号

2、构建集群环境
2.1 进入节点1
docker exec -it redis-node-1 /bin/bash2.2 构建主从关系
redis-cli --cluster create 192.168.100.134:6381 192.168.100.134:6382 192.168.100.134:6383 192.168.100.134:6384 192.168.100.134:6385 192.168.100.134:6386 --cluster-replicas 1# 宿主机IP:端口
# --cluster-replicas 1 表示为每一个master创建一个slave节点

分配完成后,输入yes,确认相关配置
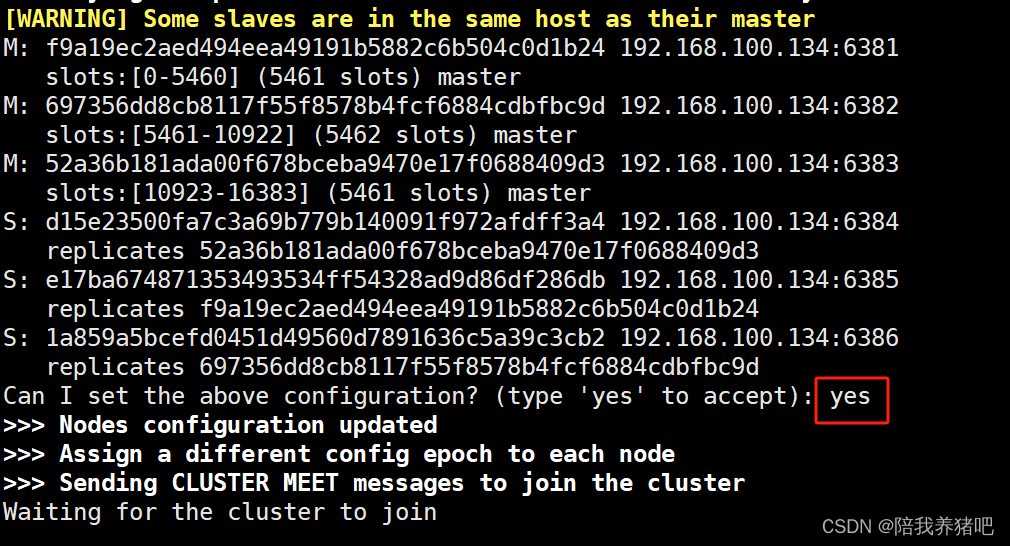
分配情况
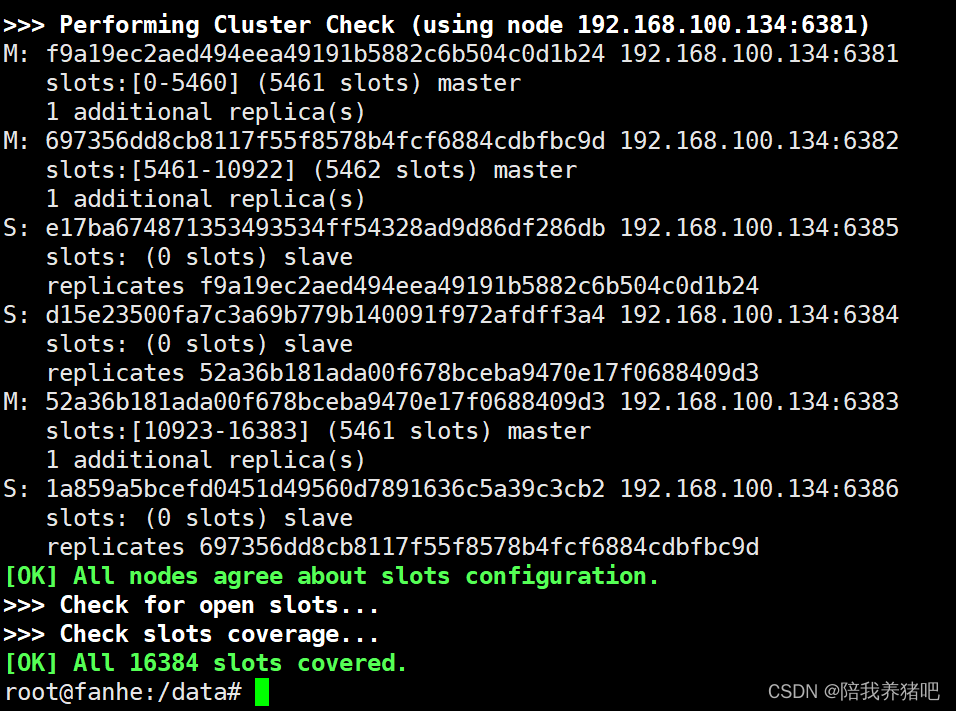
3主3从完成
2.3 查看集群状态
1、进入节点1(任选一个节点)
# 进入节点1
docker exec -it redis-node-1 /bin/bash
# 使用redis-cli连接到6381节点
redis-cli -p 6381
# 查看集群状态
cluster info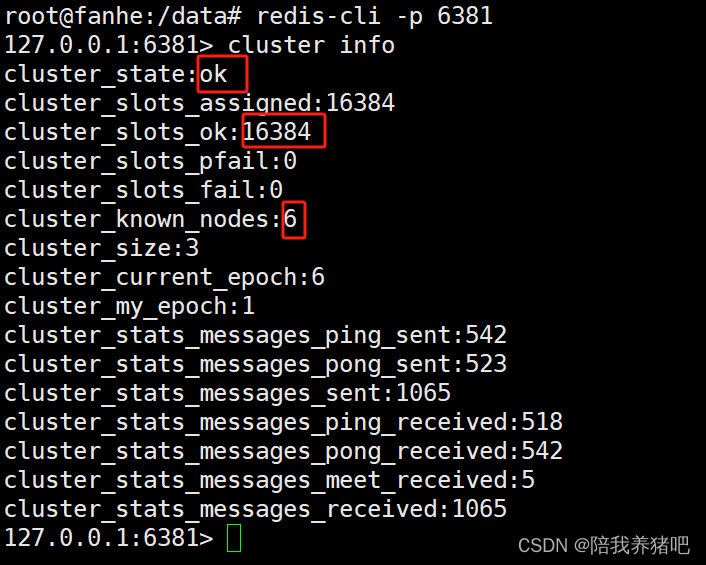
# 分配的哈希槽数量cluster_slots_assigned为16384
# 集群节点数量cluster_known_node为6
2、查看集群节点信息

可知,对应关系为:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 |
三 、主从容错切换迁移案例
1、数据读写存储
1.1 redis集群读写error说明
docker exec -it redis-node-1 /bin/bash
redis-cli -p 6381
keys *
set k1 v1
set k2 v2
set k3 v3
set k4 v4
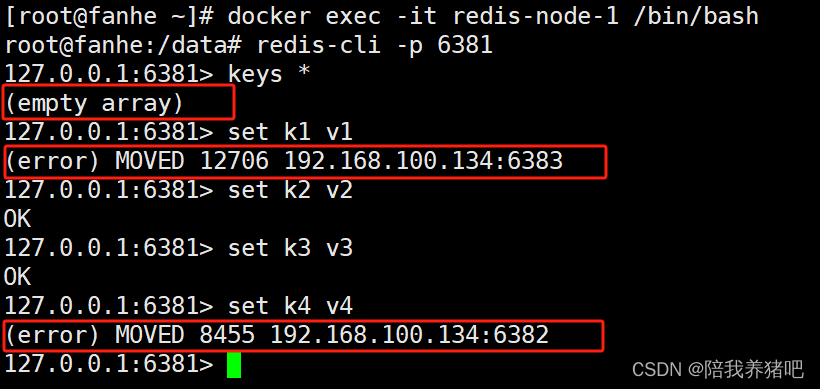
原因:使用单机版的命令连接Redis,当数据没有落到该节点的槽范围内,就会报错
1.2 redis集群读写路由增强正确案例
docker exec -it redis-node-1 /bin/bash
redis-cli -p 6381 -c
flushall
OK
set k1 v1
set k2 v2
set k3 v3
set k4 v4加上参数-c进行路由重定向,使落到相对应的槽内

1.3 查看集群信息
任意节点端口地址端口都可以
redis-cli --cluster check 192.168.100.134:6381
2、容错切换迁移
2.1 主6381和从机5切换
可知,对应关系为:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 |
停止主节点6381
docker stop redis-node-1
docker exec -it redis-node-2 /bin/bash
redis-cli -p 6382 -c
cluster nodes
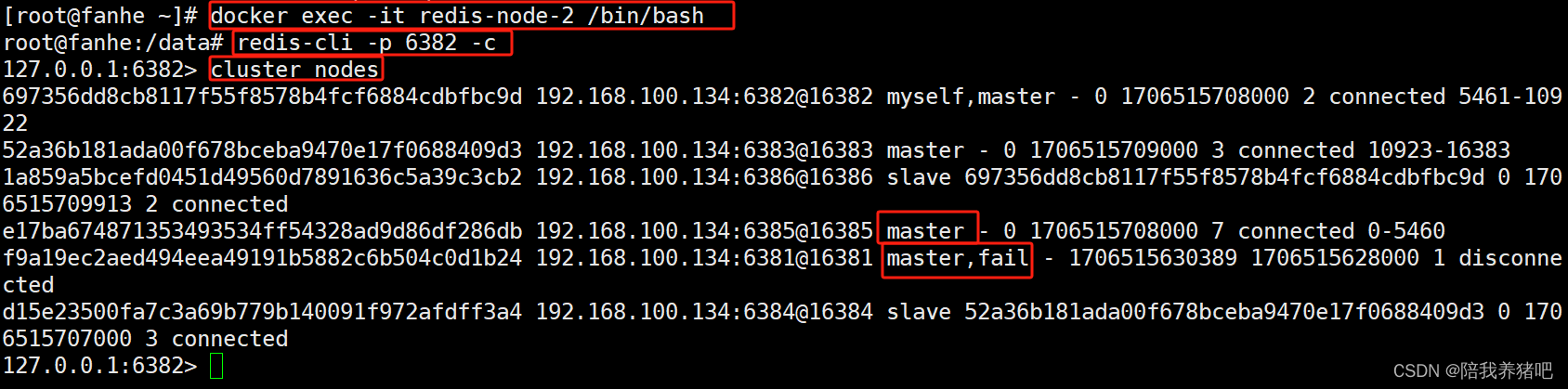
主节点6381宕机,从节点6385成为了新的master
查看
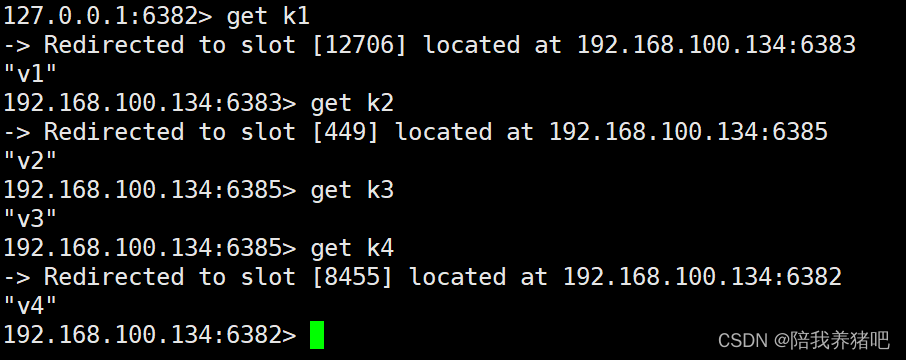
假如节点6381重新启动之后,是否会出现变成主节点
docker start redis-node-1
cluster nodes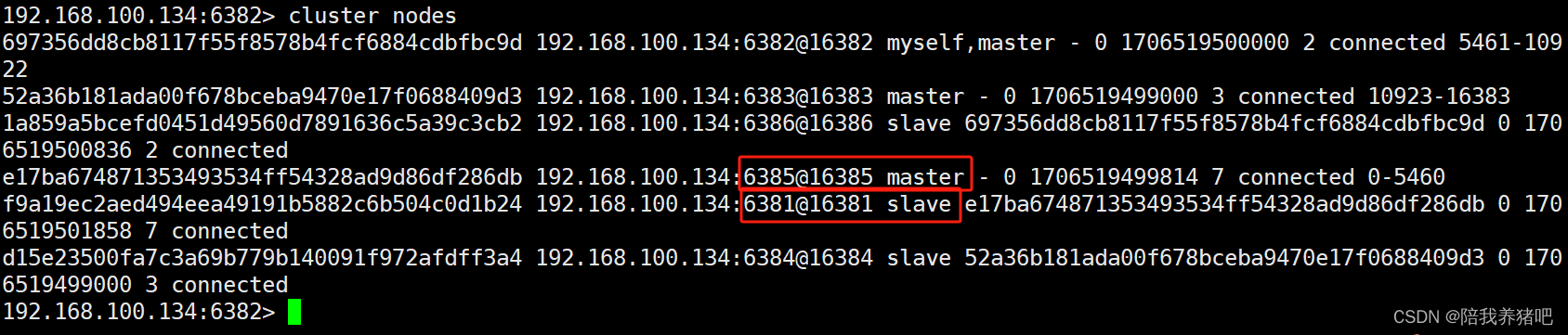
可知,节点6381重新启动之后为从节点
2.2 停止主6385
docker stop redis-node-5
cluster nodes

可知,节点6381重新成为主节点
启动节点6385
docker start redis-node-5
cluster nodes
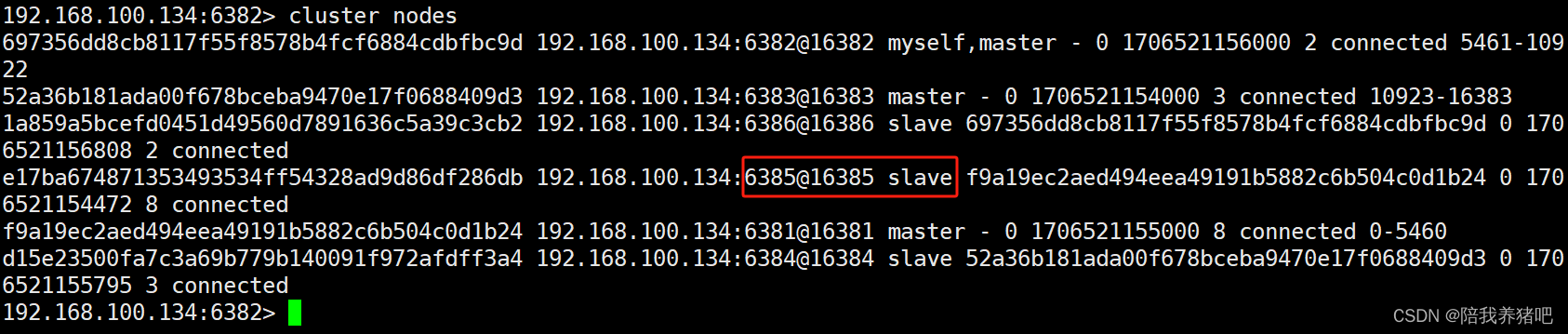
2.3 查看集群状态
docker exec -it redis-node-1 /bin/bash
redis-cli --cluster check 192.168.100.134:6381
四 、主从扩容案例
1、需求分析
可知,目前对应关系为三主三从:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 |
需要扩容为四主四从:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 | |
| 节点7 6387 | 节点8 6388 |
2、案例演示
2.1 新建6387、6388两个节点+新建后启动+查看是否8节点
# 启动第7台节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
# 启动第8台节点
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388docker ps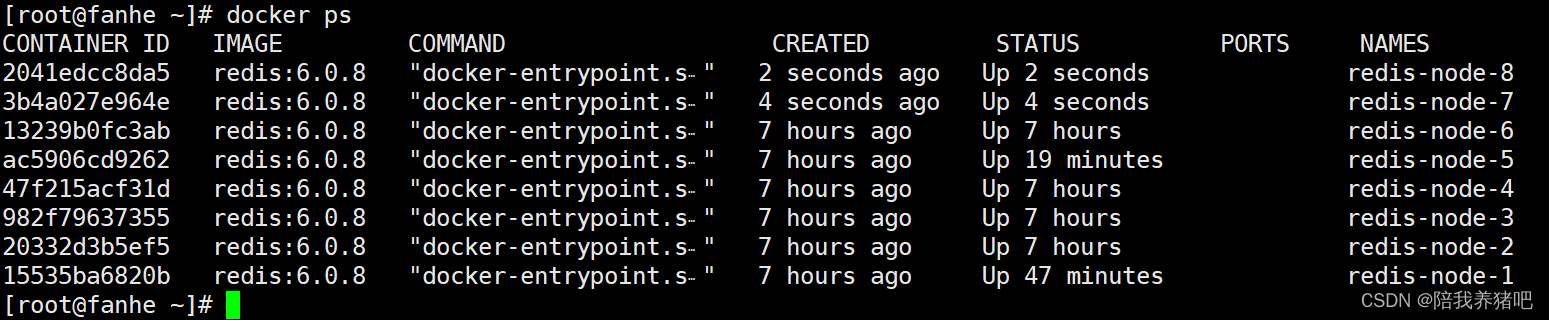
2.2 进入6387容器实例内部
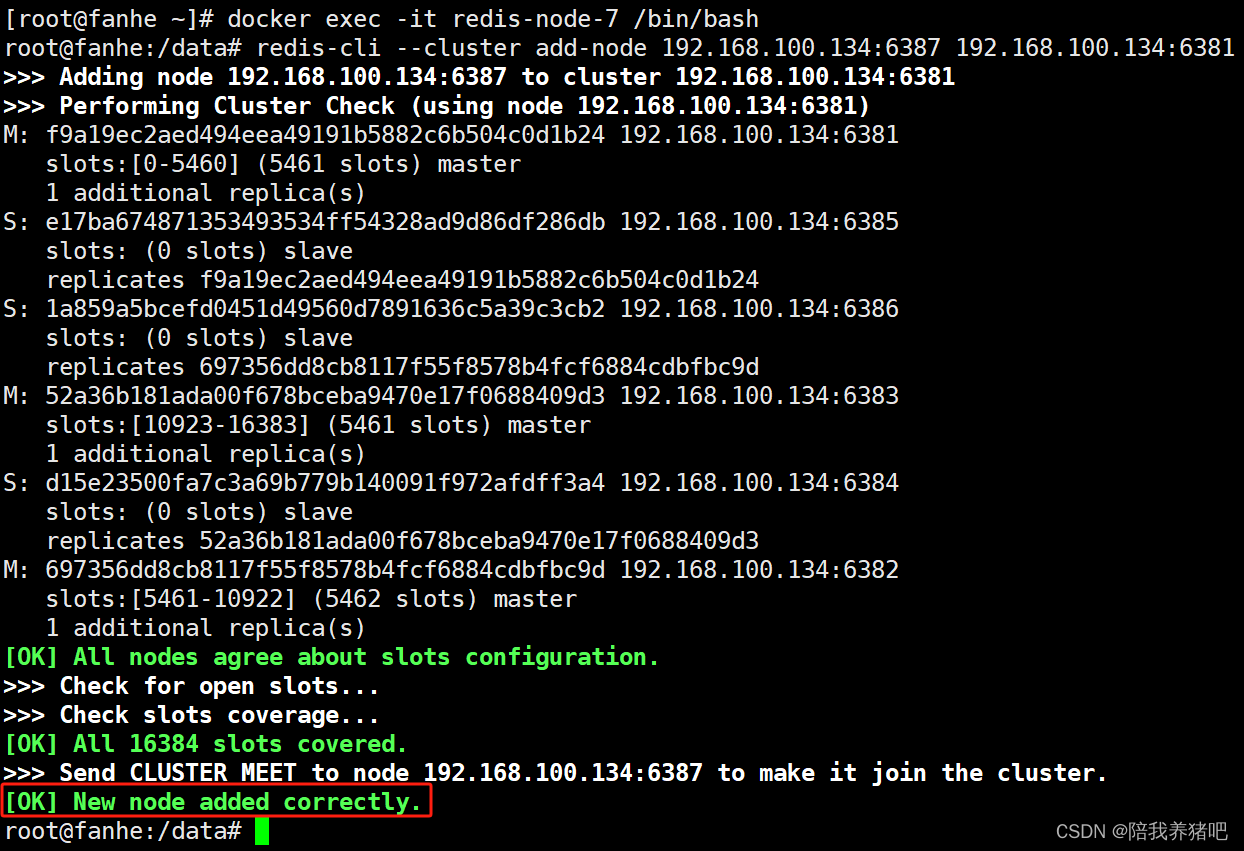
docker exec -it redis-node-7 /bin/bash2.3 将新增的6387节点(空槽号)作为master节点加入原集群
redis-cli --cluster add-node 192.168.100.134:6387 192.168.100.134:6381# redis-cli --cluster add-node 实际IP地址:6387 实际IP地址:6381,实际IP地址即为docker容器节点
的宿主机IP
# 6387 就是将要作为master新增节点
# 6381 就是原来集群节点里面的领路人
2.4 检查集群情况第1次
redis-cli --cluster check 192.168.100.134:6381
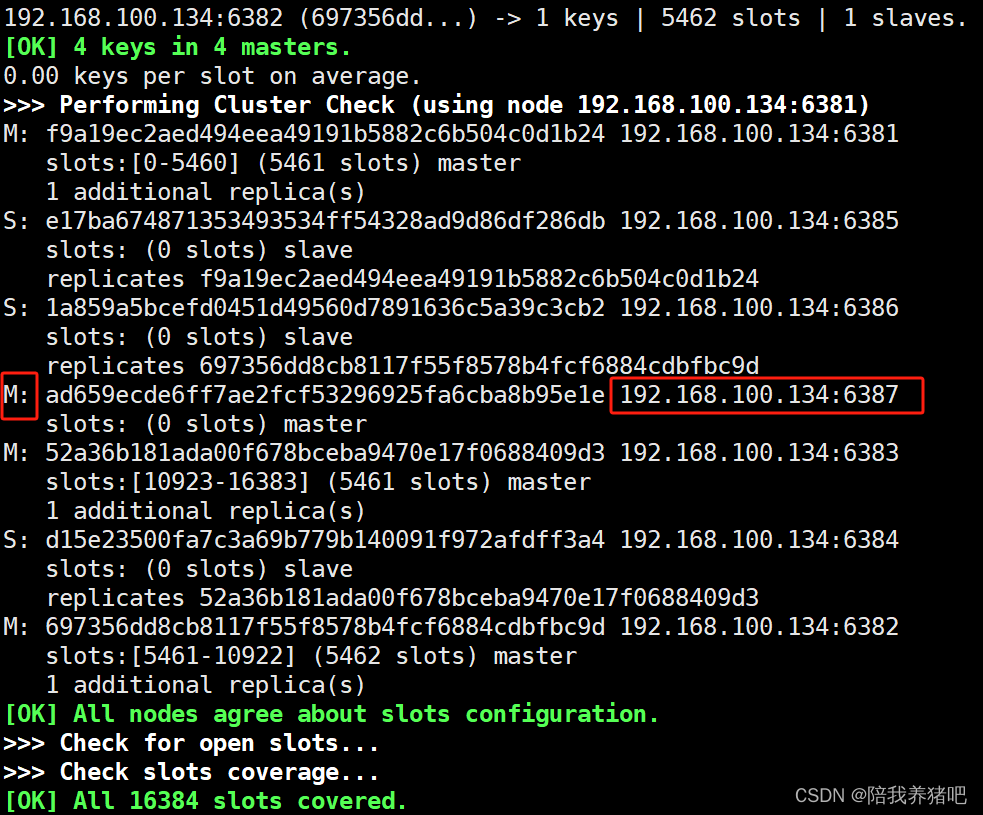
可知,暂时还没有槽位
2.5 重新分配槽号
redis-cli --cluster reshard 192.168.100.134:6381
为什么是4096?
因为槽位共有16384,主节点有4台。16384/4=4096,均等分配槽位。
节点ID填什么?
填新加入的主节点redis-node-7的ID。
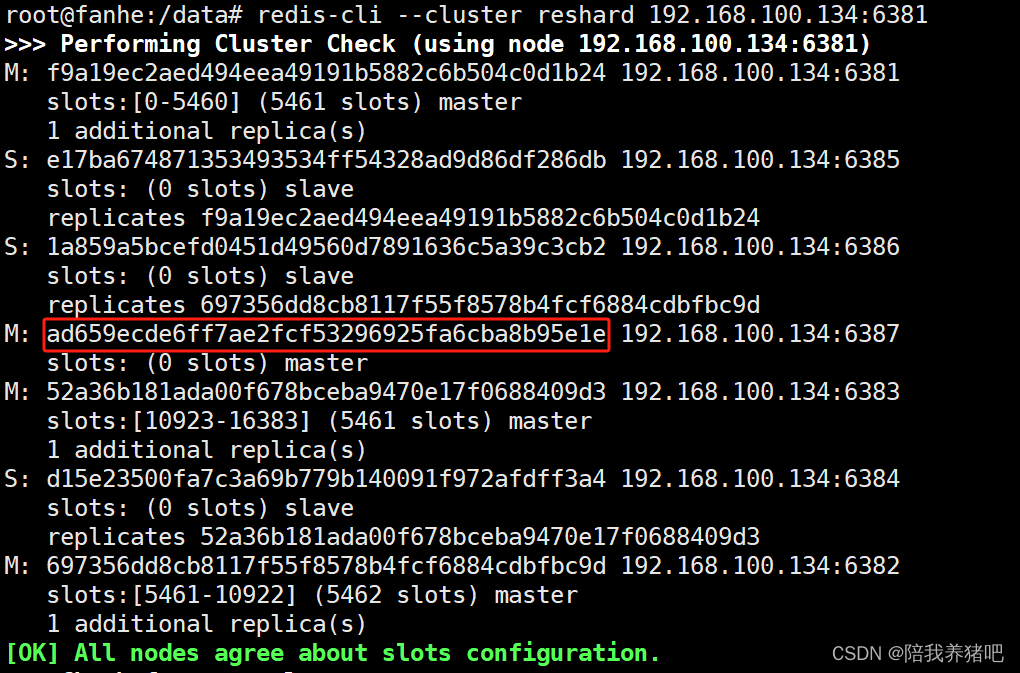
从哪些节点分配出槽位给日reids-node-7?
一般情况下选择all,即对所有槽位都重新分配,每个节点的槽位数将会均等。
确认重新分配,输入yes

2.6 检查集群情况第2次
redis-cli --cluster check 192.168.100.134:6381
为什么6387是3个新的区间,以前的还是连续?
有些槽位已经存储了key,完全重新分配成本太高,3个节点各自匀出1364个槽位给新节点6387
2.7 为主节点6387分配从节点6388
redis-cli --cluster add-node 192.168.100.134:6388 192.168.100.134:6381 --cluster-slave --cluster-master-id ad659ecde6ff7ae2fcf53296925fa6cba8b95e1e
----6387节点的十六进制编号字符串
2.8 检查集群情况第3次
redis-cli --cluster check 192.168.100.134:6383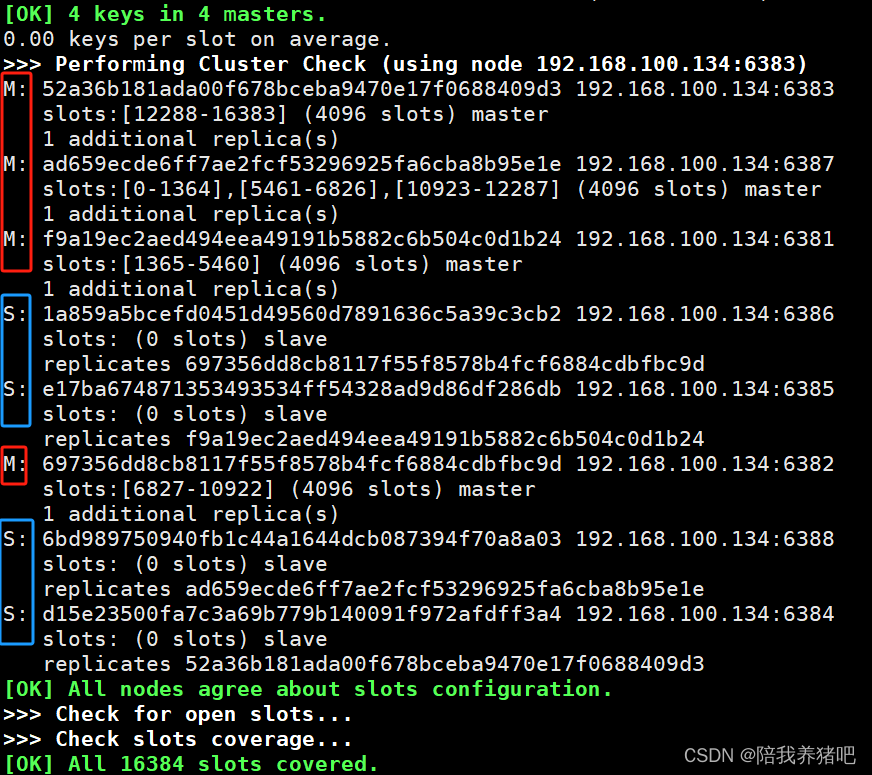
五、主从缩容案例
1、需求分析
可知,目前对应关系为四主四从:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 | |
| 节点7 6387 | 节点8 6388 |
需要缩容为三主三从:
| 主节点 | 对应关系 | 从节点 |
| 节点1 6381 | 节点5 6385 | |
| 节点2 6382 | 节点6 6386 | |
| 节点3 6383 | 节点4 6384 |
2、案例演示
2.1 删除从节点6388
# 进入容器节点node1
docker exec -it redis-node-1 /bin/bash
# 获取6388节点编号
redis-cli --cluster check 192.168.100.134:6381
# 把从节点6388在集群中移除
redis-cli --cluster del-node 192.168.100.134:6388 6bd989750940fb1c44a1644dcb087394f70a8a03 ----6388节点ID
2.2 检查集群情况第1次
redis-cli --cluster check 192.168.100.134:6381
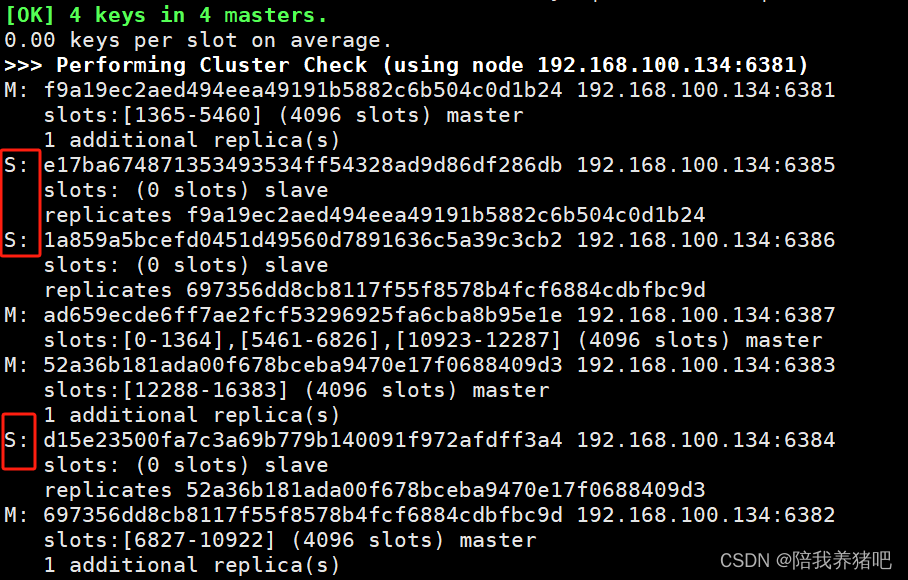
可知,从节点6388已删除
2.3 将6387槽号清空,重新分配,本例全部分配给主节点6381
redis-cli --cluster reshard 192.168.100.134:6381
确认,输入yes

2.4 检查集群情况第2次
redis-cli --cluster check 192.168.100.134:6381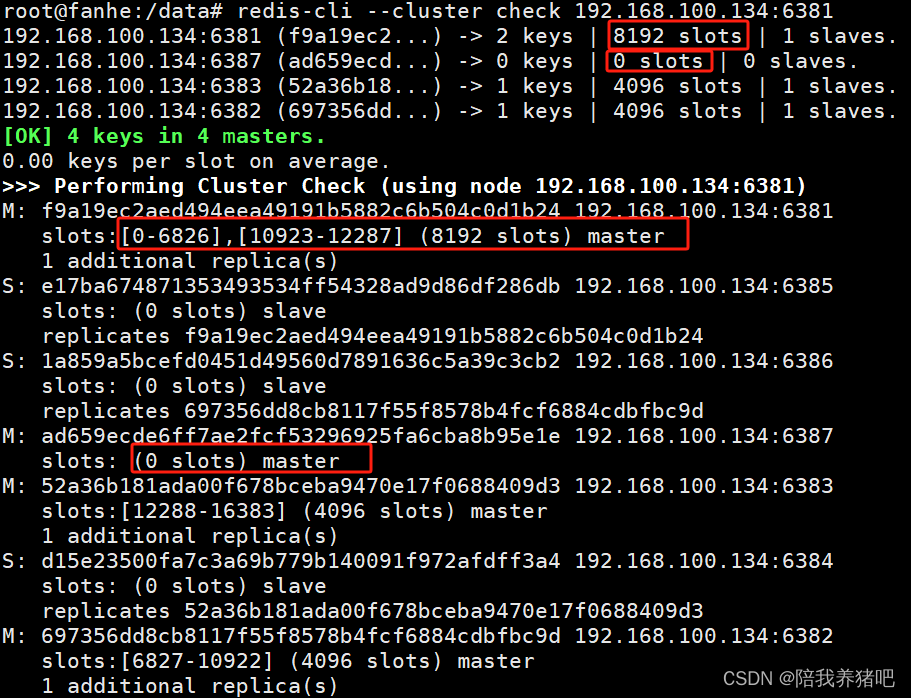
4096个槽位都给了6381,变成了8192个槽位
2.5 删除主节点6387
redis-cli --cluster del-node 192.168.100.134:6387 ad659ecde6ff7ae2fcf53296925fa6cba8b95e1e --主节点6387节点ID 2.6 检查集群情况第3次
2.6 检查集群情况第3次
redis-cli --cluster check 192.168.100.134:6381
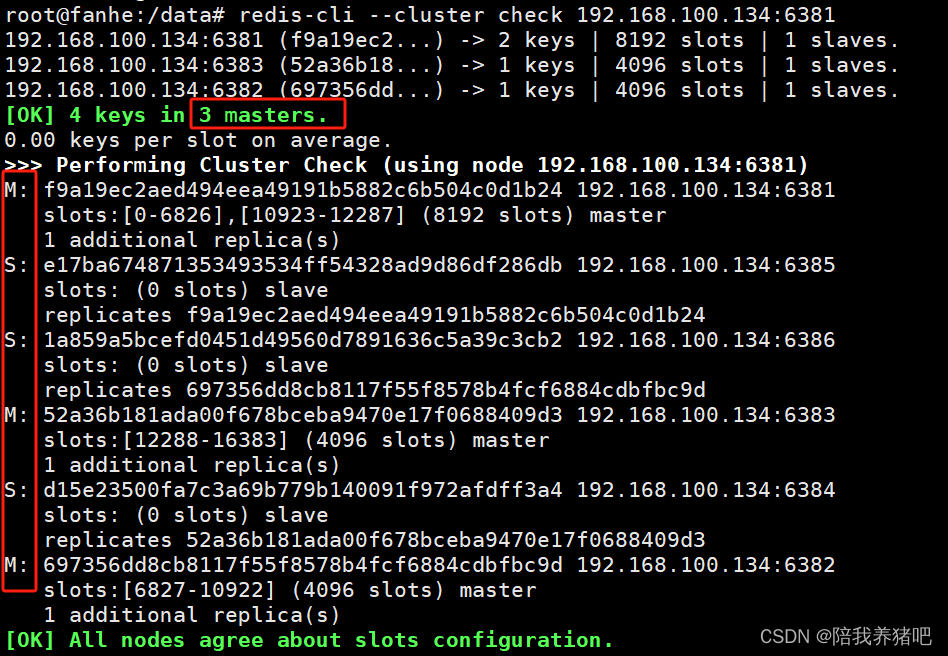
至此,完成