欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
12306 架构设计难点
坐过高铁吧,有抢过票吗?你说说抢票会有哪些情况?
抢票会存在线程安全的问题,因为高铁票是作为一个共享的数据存在,多个线程去读写共享的数据,就会存现线程安全的问题
具体的线程不安全问题就是:高铁票的 少卖 和 超卖
先说一下整个抢票中所涉及的流程:生成订单、扣减库存、用户支付
那么为了保证高并发,扣减库存的操作可以放在本地去做,生成订单的操作通过异步,可以大幅提高系统并发度
接下来先说一下如何 优化抢票性能 :
将库存放在每台机器的本地,比如总共有 1w 个余票库存,共有 100 台机器,那么就在每台机器上方 100 个库存
当用户抢票之后,就会在本地先扣减库存,如果本地库存不足,此时可以给用户返回一个友好提示,让用户稍后再重试抢票,再将用户抢票的请求路由到其他有库存的机器上去
如果本地库存足够的话,就先扣除本地库存,之后再发送一个 MQ 消息异步的生成高铁票的订单,等待用户支付,如果用户十分钟内不支付的话,订单就失效,返还库存
接下来分析一下上边的流程是否会出现少卖和超卖的问题:
对于超卖来说,每次用户请求时,先扣除库存,再去生成订单,这样当库存不足时,就不会再生成订单了,因此肯定不会出现超卖的问题
对于少卖来说,总共有 100 台机器,每台机器有 100 个库存,如果其中的几台机器宕机了,那么宕机的机器上的库存就没办法继续售卖,就会出现少卖的问题
解决少卖问题:
可以在每台机器上放一些冗余的库存,如果其他机器发生了宕机,就将宕机的机器上的库存给放到健康的机器上去,就可以避免机器宕机而导致一部分库存卖不出去的问题了
那么这样的话,就需要使用 Redis 来统一管理每台机器上的库存,也就是在分布式缓存 Redis 中存储一份缓存,在每台机器的本地也存储一份缓存,当扣减完机器本地的库存之后,再去发送一个远程请求扣减 Redis 上的库存
最后完整的抢票流程:
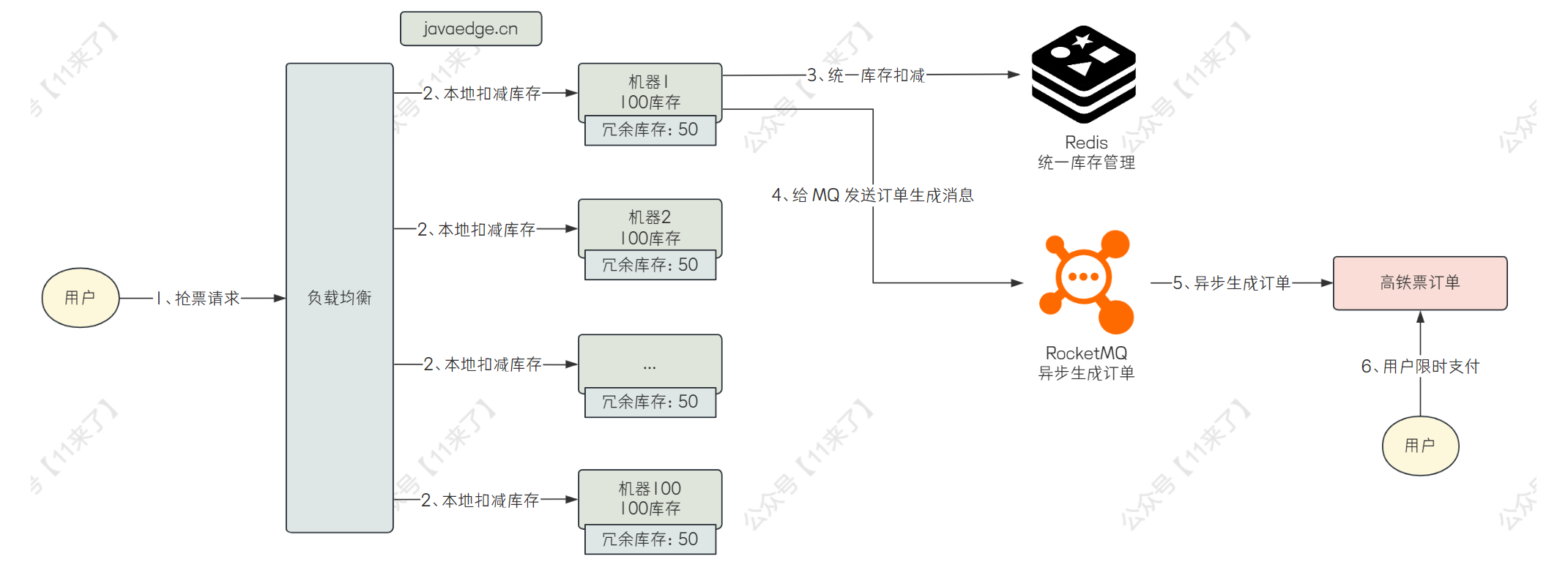
- 用户发出抢票请求,在本地进行扣减库存操作
- 如果本地库存不足,返回用户友好提示,可以稍后重试,如果所有机器上的库存都不足的话,可以直接返回用户已售罄的提示
- 如果本地库存充足,在本地扣减库存之后,再向 Redis 中发送网络请求,进行库存扣减(这里 Redis 的作用就是统一管理所有机器上的库存数量)
- 扣减库存之后,再发送 MQ 消息,异步的生成订单,之后等待用户支付即可
如有不足,欢迎指出
现在我们来给 12306 抢票系统设计一个缓存,kv 存什么?
在回答的时候,要先给面试官分析一下业务场景,再说怎么去设计缓存
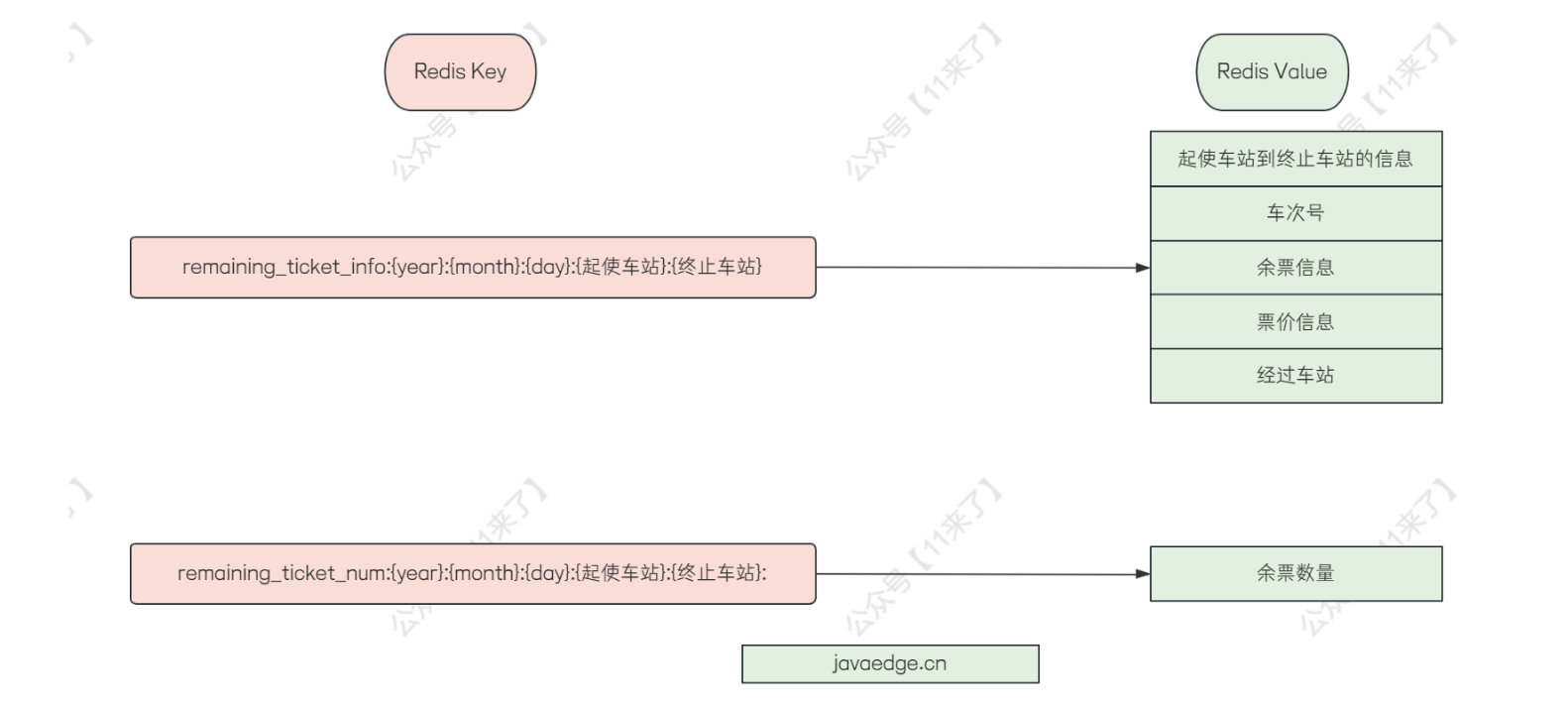
在 12306 中如果要设计缓存的话,可以考虑给余票设计一个缓存,因为余票信息是读取比较多的数据,并且在首页,放在缓存中可以大大加快用户查询的速度,如下图
- 余票信息缓存
余票信息缓存的话,将车站到车站之间的信息以及余票信息给存储到缓存中,比如当用户查询 A 车站到 B 车站的车票信息时,直接从缓存中获取,如果缓存中没有的话,去数据库中查询,并且在 Redis 缓存中构建一份缓存数据
key 设计为站点的信息,比如查询 2023 年 12 月 15 日 A 车站到 B 车站的车票信息:remaining_ticket_info:{year}:{month}:{day}:{起使车站}:{终止车站}
value 为起使车站到终止车站的信息,比如车次号、余票信息、票价信息、经过车站等一些信息
这里我觉得余票数量可以和其他缓存给分开存储,因为像余票信息的话,用户购买后是需要修改的,如果将余票数量和其他缓存数据放在一起的话,每次修改的时候,都要重新构建很多数据,比较麻烦
- 余票数量缓存
余票数量缓存的 key 设计为:remaining_ticket_num:{year}:{month}:{day}:{起使车站}:{终止车站}
value :存储余票的数量










![Flink 1.18.1 部署与配置[CentOS7]](https://img-blog.csdnimg.cn/direct/e06e1abfbca04bbf9c19452edeb41f08.png)