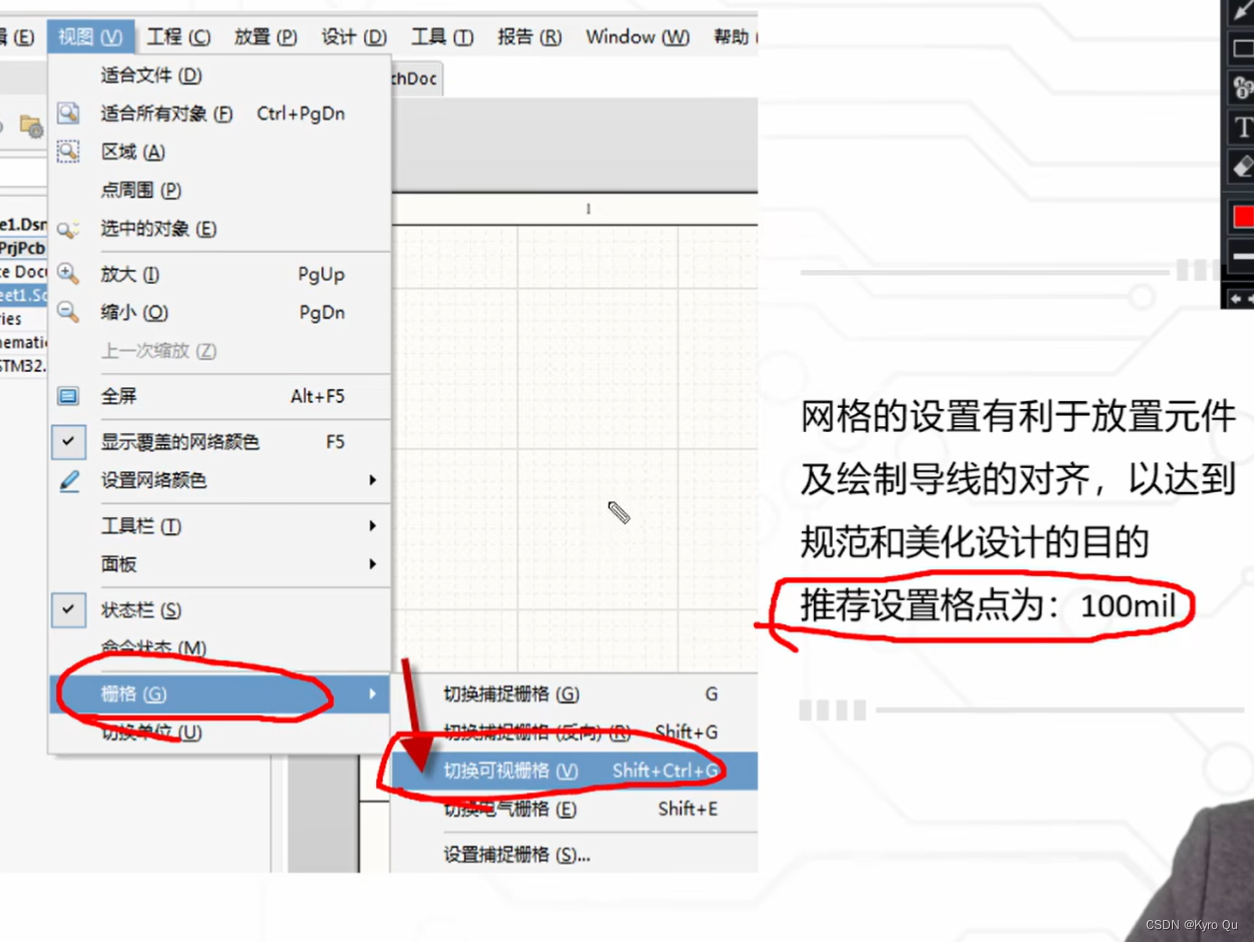
目录
一、Flink应用分析
1.1 Flink任务生命周期
1.2 Flink应用告警视角分析
二、监控告警方案说明
2.1 监控消息队中间件消费者偏移量
2.2 通过调度系统监控Flink任务运行状态
2.3 引入开源服的SDK工具实现
2.4 调用FlinkRestApi实现任务监控告警
2.5 定时去查询目标库最大时间和当前时间做对比
2.6 自定义指标Reporter的SDK
2.7 任务日志告警
2.8 运行任务探活
三、总结
前言:Flink作为一个高性能实时计算引擎,可灵活的嵌入各种场景,许多团队为了实现业务交付,选择了Flink作为解决方案;但是随着Flink应用的增多且出现线上事故,对Flink任务异常的监控告警成为迫切需求;但是如何实现Flink任务异常监控告警,成为了新的问题;本文将从多个角度讲述Flink任务监控告警实现方案。
一、Flink应用分析
告警可以从多个角度实现;我们先分析Flink任务运行的生命周期,然后拆解每个部分,分析可以从那些角度去监控Flink任务的异常。
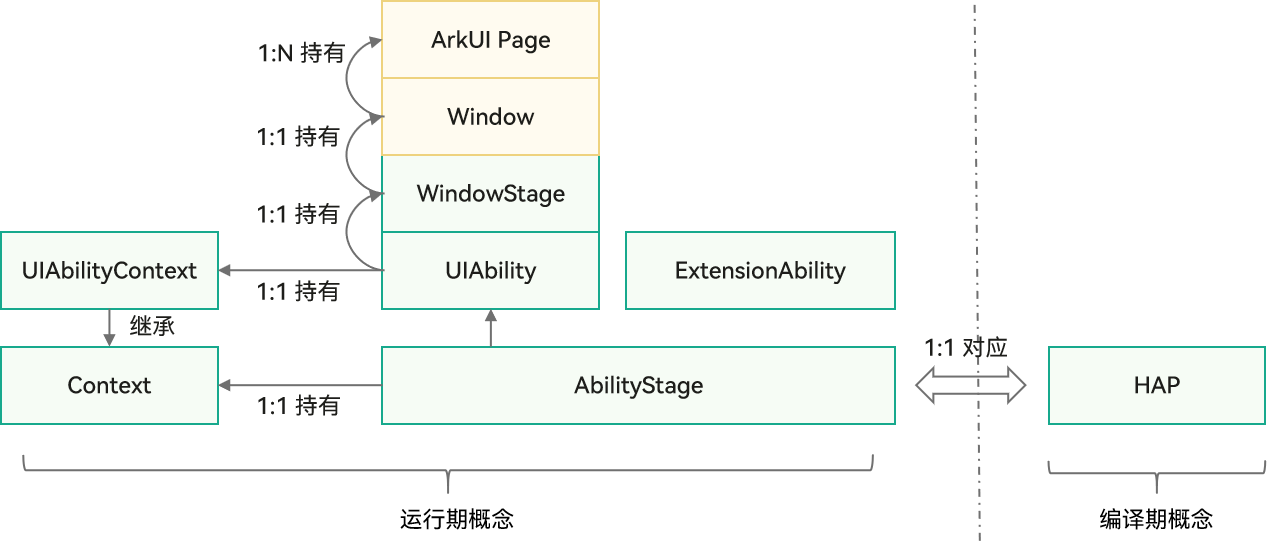
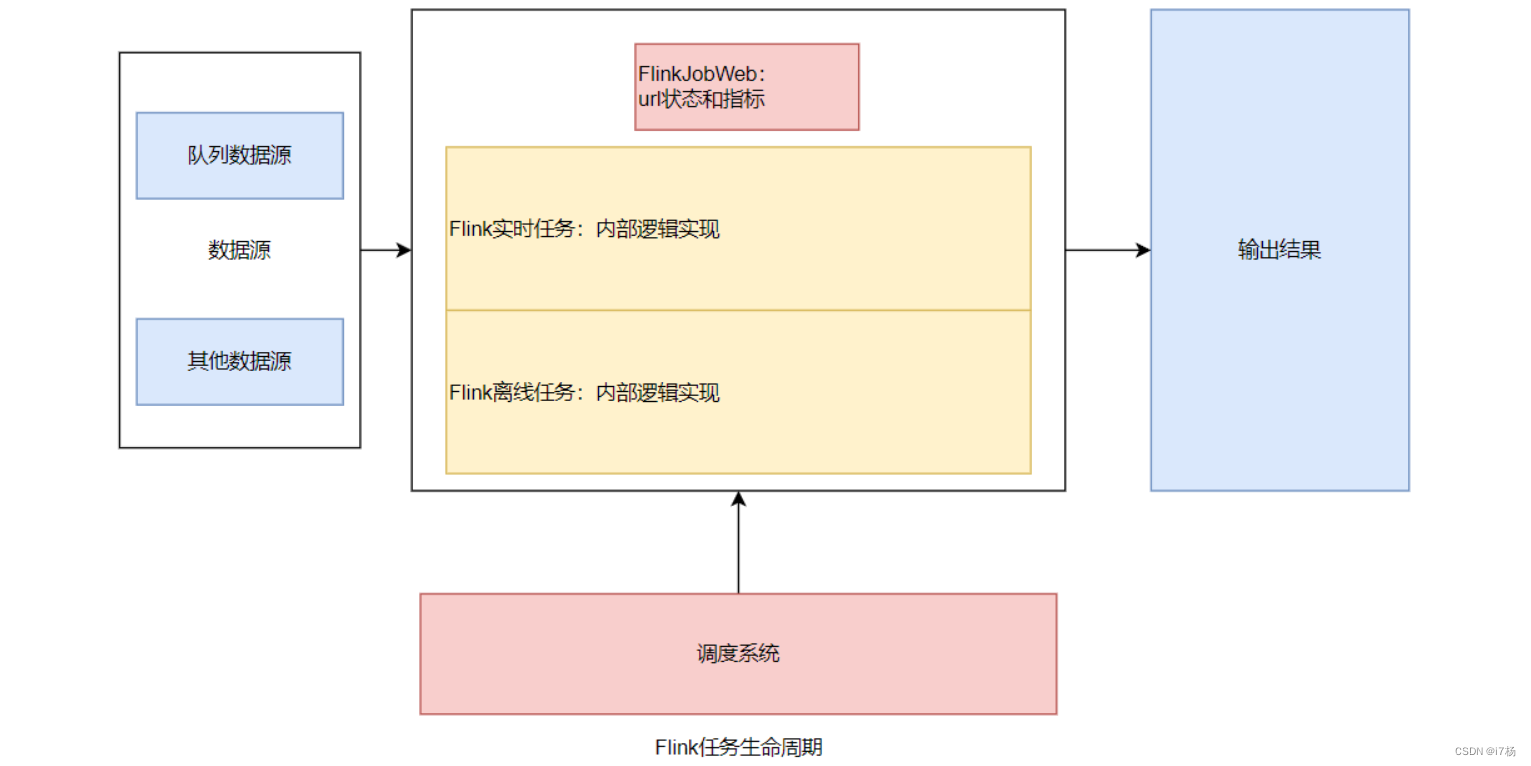
1.1 Flink任务生命周期
按读取数据源:有如Kafka、RocketMq、Pulsar等消息队列,还有其他数据源;区别在是否有记录消费者信息的数据标识;
Flink的运行模式:session、per-job、application;三类运行模式可以分为两类场景:单独运行的任务(per和application),还有Flink集群统一提供资源运行的任务(session);
任务场景:离线任务还是实时任务;
Flink任务应用结构图如下:
1.2 Flink应用告警视角分析
从数据源头:
1.对于消息队列这种,本身拥有记录消费者偏移量概念的中间件,可以通过监控消费者偏移量的变化来监控Flink任务运行的异常情况;
从任务运行时:
2.任务层可以通过调度系统的告警插件,监控任务运行结果和任务运行状态而监控任务;
3.也可以在Flink任务内部引入开源SDK配置开源工具实现;
4.或者调用FlinkRestApi实现任务监控告警;
从输出结果上:
5.可以定时去查询输出结果最后的时间;
6.或者在Flink任务里引入Flink的指标SDK,自定义Flink任务的指标采集,将结果测流输出到目标端,自定义监控告警和分析;
其他的方式:
7.日志告警,捕捉运行日志,通过关键词监控告警;
8.运行任务定时探活;
二、监控告警方案说明
钉钉、微信、邮件、电话、http等属于告警方式的选择,这里侧重讲对于运行异常事件信息的捕捉。
2.1 监控消息队中间件消费者偏移量
类似Kafka或者RocketMQ这类拥有记录消费者消费队列信息的中间件,可以通过服务自身的RestAPI,定时计算消费者消费数据lag条数;
以下是Kafka消费者告警配置页面:

这需要后端自定义实现;
实现方式如下:定时通过调用Kafka自己提供的RestApi将Topic和各消费者同步到Mysql,然后配置要监控Topic的消费者告警阈值和告警人员,每隔一分钟定时计算该消费者的lag,如果Flink任务出现异常,本身不提交offset了,数据积压量大于阈值就告警。
2.2 通过调度系统监控Flink任务运行状态
市场上有一些任务调度系统,比如dolphinscheduler、StreamX等,除了提供任务发布的能力,还自带监控告警功能,通过使用这类产品,也能做到监控告警能力。
比如dolphinscheduler:
Flink任务发布功能:
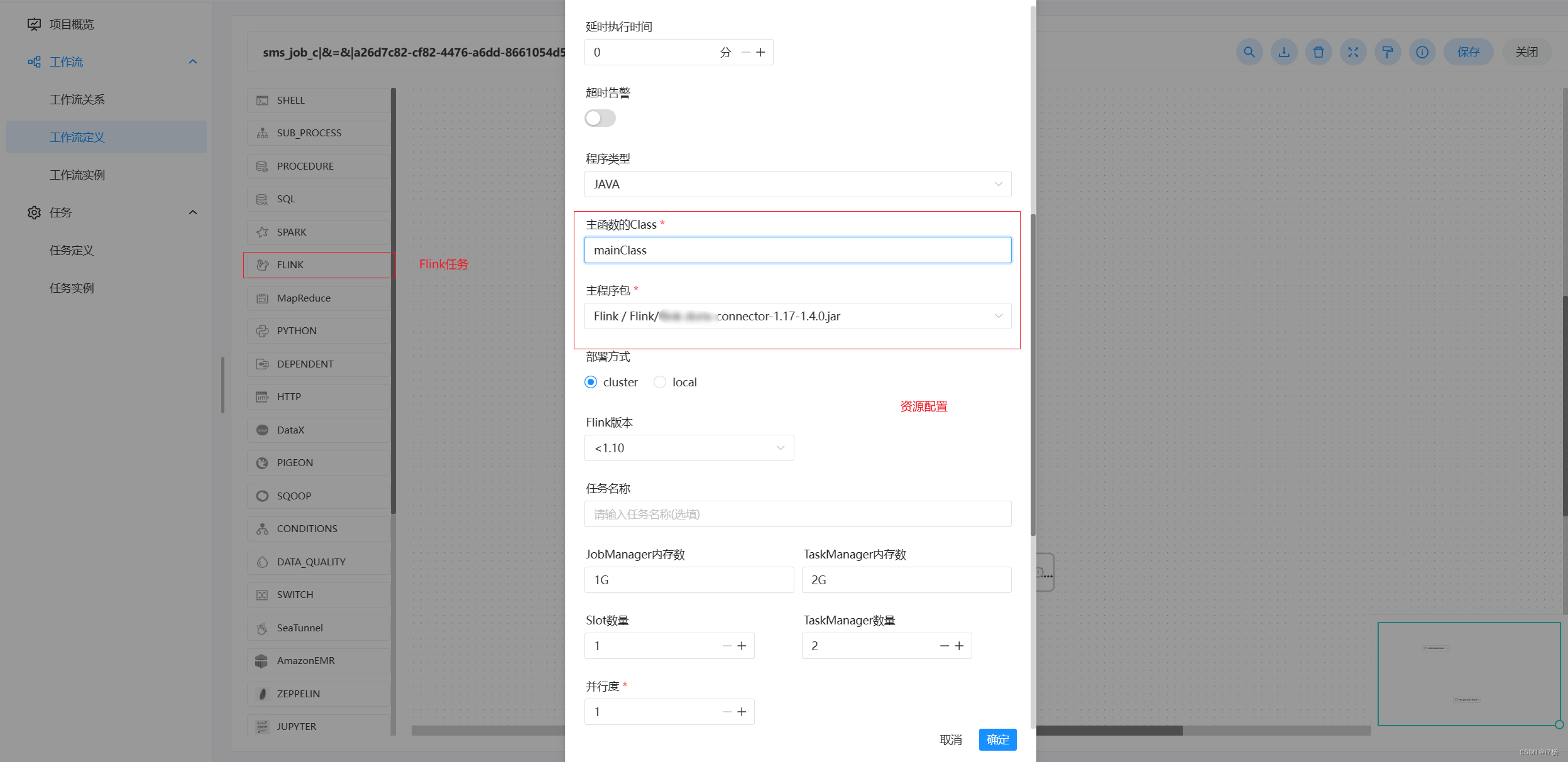
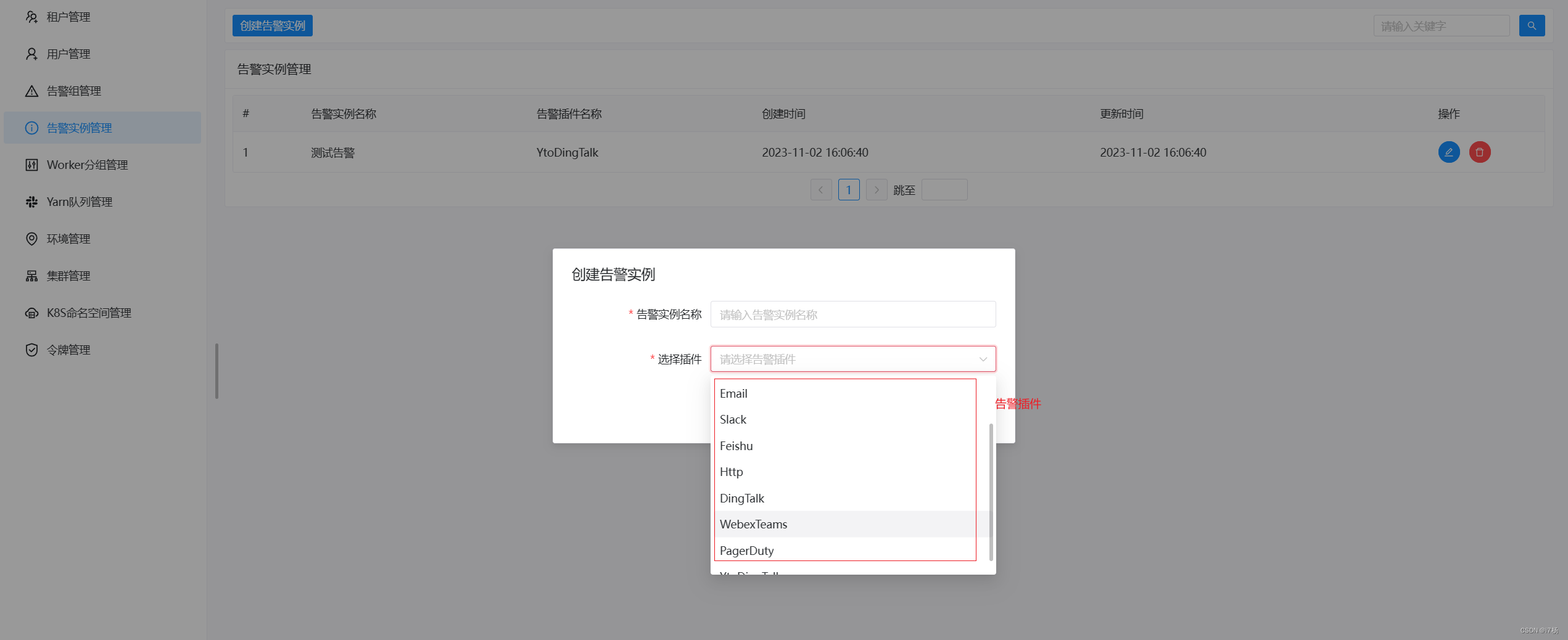
告警功能插件:
比如StreamPark:
Flink任务发布能力:
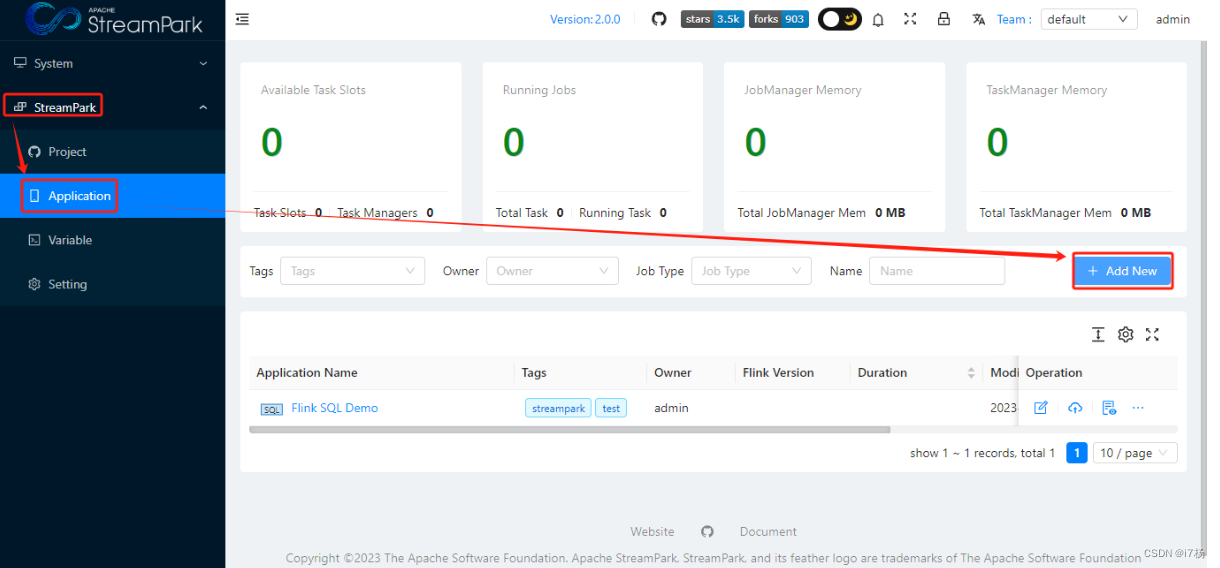
告警功能插件:
2.3 引入开源服务的SDK工具实现
博客上对于Flink监控告警推荐最多的一种方式就是,prometheus + pushgateway + grafana这套方案;这套方案需要安装维护prometheus和grafana这两个产品,比较重,但是这套方案除了可以做到任务监控,还可以做到任务指标级的分析,这对于后续的任务性能优化有比较好的支持。
具体操作步骤如下:
1.安装好prometheus + pushgateway这两个服务;
2.在Flink代码里加入以下依赖:
<!-- Prometheus Metrics Reporter -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-metrics-prometheus</artifactId>
<version>${flink-version}</version>
</dependency>3.在部署Flink的配置文件里
将flink-metrics-prometheus-1.14.3.jar 包放入到flink安装目录/lib下
修改flink-conf.yaml配置文件,设置属性如下:
Example configuration: metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter metrics.reporter.promgateway.host: localhost metrics.reporter.promgateway.port: 9091 metrics.reporter.promgateway.jobName: myJob metrics.reporter.promgateway.randomJobNameSuffix: true metrics.reporter.promgateway.deleteOnShutdown: false metrics.reporter.promgateway.groupingKey: k1=v1;k2=v2 metrics.reporter.promgateway.interval: 60 SECONDS
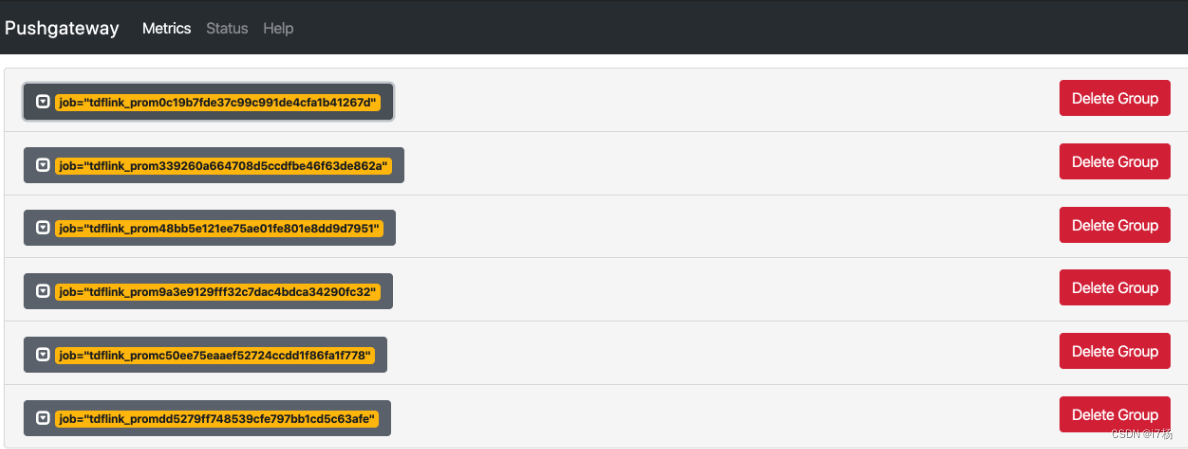
然后启动运行任务,指标数据就自动推送到pushgateway里了,prometheus会从CC里拉取数据到自己的服务里,如下:
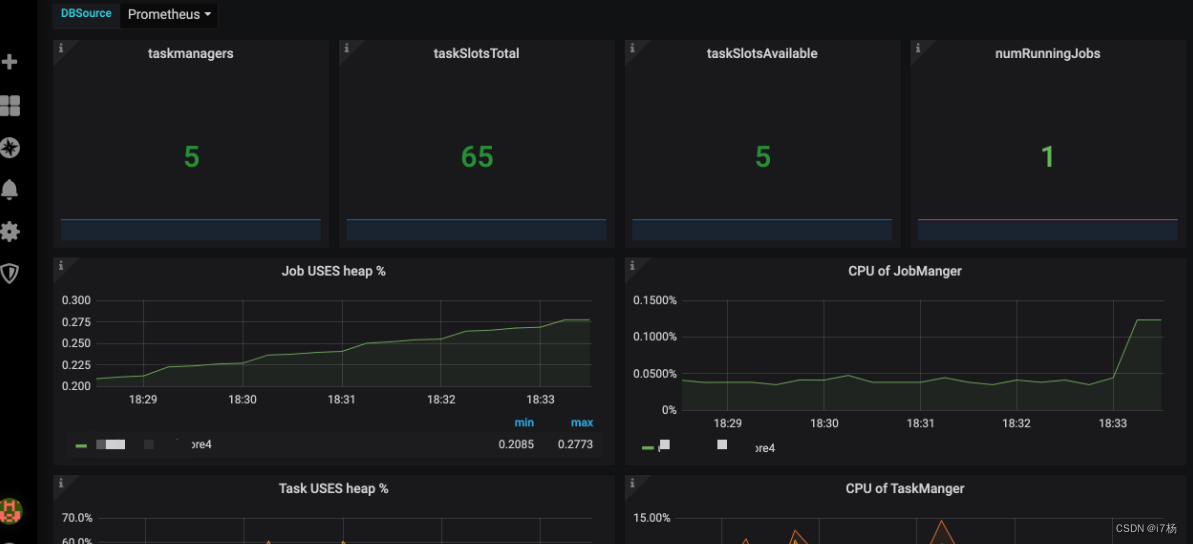
在grafana里导入prometheus源,配置指标就可以看到各种指标的运行状态:
总结:这种方案需要四个步骤:
1.启动prometheus+pushgateway+grafana服务;
2.配置Flink安装目录的配置文件、导入prometheus的lib包;
3.然后在Flink任务里引入一个prometheus的SDK,一起打包启动,指标就可以在prometheus看到;
4.通过grafana做分析看板和配置告警规则,驱动事件告警;
这种方式都是开源服务功能,但是需要维护和理解成本,对于一些轻业务团队有负担,但是对有很多Flink任务的团队,这是一种可用的方案,后续还可以基于历史指标分析,做到内存级的性能优化;
2.4 调用FlinkRestApi实现任务监控告警
这里要搞清楚Flink集群的生命和Flink任务的生命周期这两个概念;Flink集群按生命周期来分,运行方式可以分为session模式和其他模式两种;这两种的区别分别是,Flink集群和Flink任务的资源是否一起释放;这关系到是否可以稳定的通过FlinkRestApi捕捉到任务运行状态;
对于Flink Sesion集群,Flink任务可以反复提交,集群的URL是不会变的,可以通过固定的URL监控到Flink任务的运行状态;
对于per-job和application运行方式,Flink任务web的URL是不固定的,需要每次都捕捉到启动时的Url才能通过url调用RestAPI返回查询指标;
sesion集群样式:
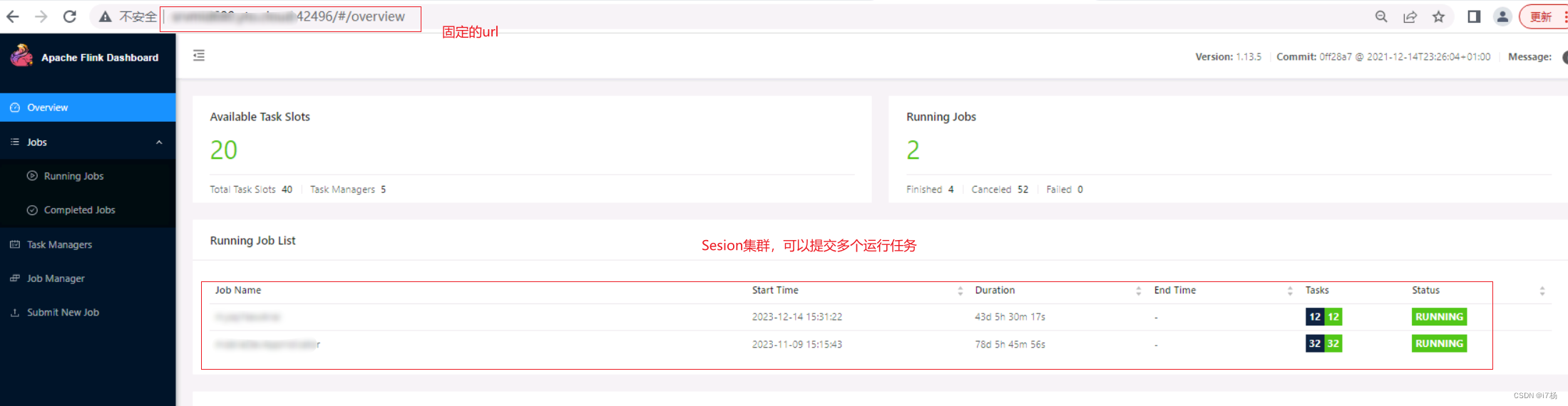
per-job和application运行模式提交的任务,只会有一个任务,且url是随机的。
2.5 定时去查询目标库最大时间和当前时间做对比
这种方式是公司的DB团队给我的想法,并且他们最初也是这么做的,虽然操作上不美观,无法大面积,且性能上会造成一些影响,但确实可以轻量级的实现对任务异常的监控;
具体是怎么做的呢?
对于实时任务,数据都是实时捕捉的,写入目标库的时候,数据带有当前时间字段,业务理想状态下,数据会一直产生,查询目标库时间最大的数据与当前时间匹配,超出阈值时间范围就告警;不理想状态,将特殊时间段监控去掉就行;这种方式在生成业务种确实能满足任务的异常监控告警需求。
要查询最大时间的数据,可以使用如下的 SQL 语句:
SELECT time_column FROM table_name ORDER BY time_column DESC LIMIT 1;2.6 自定义指标Reporter的SDK
1.引入Flink自带的指标SDK:
<!-- Prometheus Metrics Reporter -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-metrics-prometheus</artifactId>
<version>${flink-version}</version>
</dependency>2.类似prometheus,将指标类的一些参数,自定义捕捉写到目标库(将推送到pushgateway改成推送到Kafka),然后通过目标库的数据自己做任务异常监控分析;
这种方式就是避免了开源维护的成本,可以使用产品线自研的一套UI和采集中间件做数据管理,减轻了维护成本。
大致步骤是:
1.自定义 ReporterFactory 实现 MetricReporterFactory 接口中的 createMetricReporter 方法。
2.自定义 Reporter 继承 AbstractReporter 实现 Scheduled 接口中的相关方法
3.在 META-INF/services 下的配置文件中添加对应的实现类,然后在Flink配置里自定义参数。
以写入Kafka为例:
实现KafkaReporterFactory:
package org.apache.flink.metrics.kafka;
import org.apache.flink.metrics.reporter.MetricReporter;
import org.apache.flink.metrics.reporter.MetricReporterFactory;
import java.util.Properties;
/**
* @Description:
* @author:i7Yang
* @create 2024-01-26 20:19
**/
public class KafkaReporterFactory implements MetricReporterFactory {
@Override
public MetricReporter createMetricReporter(Properties properties) {
return new KafkaReporter();
}
}
实现自定义KafkaReporter:
package org.apache.flink.metrics.kafka;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.metrics.Metric;
import org.apache.flink.metrics.MetricConfig;
import org.apache.flink.metrics.MetricGroup;
import org.apache.flink.metrics.reporter.AbstractReporter;
import org.apache.flink.metrics.reporter.MetricReporter;
import org.apache.flink.metrics.reporter.Scheduled;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import java.util.stream.Collectors;
/**
* {@link MetricReporter} that exports {@link Metric Metrics} via Kafka.
*/
public class KafkaReporter extends AbstractReporter implements Scheduled {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaReporter.class);
static final String JOB_ID_VARIABLE = "<job_id>";
static final String JOB_NAME_VARIABLE = "<job_name>";
private KafkaProducer<String, String> kafkaProducer;
private List<String> metricsFilter = new ArrayList<>();
private String topic;
private String jobName;
private String jobId;
@Override
public void open(MetricConfig metricConfig) {
String bootstrapServer = metricConfig.getString("bootstrapServers", "master:9092,storm1:9092,storm2:9092");
String filter = metricConfig.getString("filter", "");
String chunkSize = metricConfig.getString("chunkSize", "5");
String topic = metricConfig.getString("topic", "flink_metric");
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", bootstrapServer);
properties.setProperty("acks", "all");
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
Thread.currentThread().setContextClassLoader(null);
kafkaProducer = new KafkaProducer<>(properties);
Thread.currentThread().setContextClassLoader(classLoader);
if (StringUtils.isNotEmpty(filter)) {
this.metricsFilter.addAll(Arrays.asList(filter.split(",")));
}
this.chunkSize = Integer.parseInt(chunkSize);
this.topic = topic;
// 获取任务的 jobName
this.jobName = metricConfig.getString("FLINK_JOB_NAME", null);
LOGGER.info("job name: {}", jobName);
}
@Override
public void notifyOfAddedMetric(Metric metric, String metricName, MetricGroup group) {
Map<String, String> allVariables = group.getAllVariables();
String jobID = allVariables.get(JOB_ID_VARIABLE);
if (jobID != null && this.jobId == null) {
this.jobId = jobID;
}
String jobName = allVariables.get(JOB_NAME_VARIABLE);
if (jobName != null && this.jobName == null) {
this.jobName = jobName;
}
LOGGER.info("job id: {}, job name: {}", this.jobId, this.jobName);
LOGGER.info("metric group name: {}, metric name: {}", group.getAllVariables(), metricName);
// 只有在 filter 里面的 metric 才会被添加
super.notifyOfAddedMetric(metric, metricName, group);
}
@Override
public void notifyOfRemovedMetric(Metric metric, String metricName, MetricGroup group) {
super.notifyOfRemovedMetric(metric, metricName, group);
}
@Override
public void close() {
if (kafkaProducer != null) {
kafkaProducer.close();
}
}
@Override
public void report() {
synchronized (this) {
tryReport();
}
}
private void tryReport() {
Map<String, Object> metricMap = new HashMap<>();
metricMap.put("jobId", this.jobId);
metricMap.put("jobName", this.jobName);
JSONArray jsonArray = new JSONArray();
gauges.forEach((gauge, metricName) -> {
JSONObject jsonObject = new JSONObject();
jsonObject.put("metricName", metricName);
jsonObject.put("value", gauge.getValue());
jsonObject.put("type", "Gauge");
jsonArray.add(jsonObject);
});
counters.forEach((counter, metricName) -> {
JSONObject jsonObject = new JSONObject();
jsonObject.put("metricName", metricName);
jsonObject.put("value", counter.getCount());
jsonObject.put("type", "Counter");
jsonArray.add(jsonObject);
});
histograms.forEach((histogram, metricName) -> {
JSONObject jsonObject = new JSONObject();
jsonObject.put("metricName", metricName);
jsonObject.put("value", histogram.getCount());
jsonObject.put("type", "Histogram");
jsonArray.add(jsonObject);
});
meters.forEach((meter, metricName) -> {
JSONObject jsonObject = new JSONObject();
jsonObject.put("metricName", metricName);
jsonObject.put("value", meter.getCount());
jsonObject.put("type", "Meter");
jsonArray.add(jsonObject);
});
metricMap.put("metrics", jsonArray);
ProducerRecord<String, String> record = new ProducerRecord<>(this.topic, this.jobId, JSONObject.toJSONString(metricMap));
kafkaProducer.send(record);
}
@Override
public String filterCharacters(String input) {
return input;
}
}
flink 的配置文件中设置一下 kafka reporter:
metrics.reporter.kafka.factory.class: org.apache.flink.metrics.kafka.KafkaReporterFactory
metrics.reporter.kafka.bootstrapServers: master:9092,storm1:9092,storm2:9092
metrics.reporter.kafka.topic: flink_metric
metrics.reporter.kafka.filter: inPoolUsage,outPoolUsage,numberOfCompletedCheckpoints,lastCheckpointFullSize,numBytesOutPerSecond,numBuffersOutPerSecond,numRecordsInPerSecond
metrics.reporter.kafka.interval: 20 SECONDS
2.7 任务日志告警
将Flink的运行任务集中采集,文件日志用LogStagsh,指标日志可在应用里埋点,然后通过日志做告警管理。
2.8 运行任务探活
上面2.4节讲了Flink的sesion运行模式,可以通过FlinkRestApi获取运行状态和指标;但是对于per-job和applicaiton运行方式,任务异常失败后,restApi是不存在,但是对于其使用的资源管理器,可以捕捉到任务运行状态;比如yarn,可以通过shell查询到任务的存活情况,可以定时去探活或获取url获取运行时指标。
使用yarn做Flink任务资源管理的命令:
定时监控flink任务状态:
yarn application -list | grep -w flink任务名 字 | awk '{print $1}'
返回flink任务url链接:
yarn application -list | grep -w flink 任务名字 | awk '{print $10}'

三、总结
Flink任务告警方式的选择,要从任务的使用情况和期盼来考量;简单的使用,且任务少,可以用监控目标数据库的数据写入情况、per-job和application运行任务探活、Sesion运行方式通过RestApi来告警;特定场景的业务可以靠监控存储中间偏移量来告警;通用大规模应用场景可以通过采集运行时日志、使用调度平台,使用调度平台、引入开源SDK方式、自定义SDK写入通用系统通用系统里方式选择。
![[网络安全] IIS----WEB服务器](https://img-blog.csdnimg.cn/direct/f78ac2f4b9db4d3391c5daca39665d52.png)
![[数据结构与算法]贪心算法(原理+代码)](https://img-blog.csdnimg.cn/direct/628f3f0c05f344bbb226a4c044bef3d9.png)