1.摘要
从判别局部区域学习特征表示在细粒度视觉分类中起着关键作用。利用注意机制提取零件特征已成为一种趋势。然而,这些方法有两个主要的局限性:第一,它们往往只关注最突出的部分,而忽略了其他不明显但可区分的部分。其次,他们孤立地对待不同的部分特征,而忽略了它们之间的关系。
为了解决这些限制,我们建议定位多个不同的可区分部分,并以明确的方式探索它们之间的关系。在这个过程中,我们引入了两个轻量级模块,它们可以很容易地插入到现有的卷积神经网络中。一方面,我们引入了一个特征增强和抑制模块,该模块增强特征映射中最显著的部分以获得特定于部件的表示,并抑制它以迫使后续网络挖掘其他潜在部件。另一方面,我们引入了一个特征多样化模块,从相关的特定部件表示中学习语义互补信息。
我们的方法不需要边界框/部分注释,可以端到端进行训练。大量的实验结果表明,我们的方法在几个基准细粒度数据集上取得了最先进的性能。源代码可从https://github.com/chaomaer/FBSD获得。
2.问题
细粒度视觉分类(Fine-grained visual classification, FGVC)侧重于在基本类别中区分细微的视觉差异,例如鸟类[1]和狗[2]的种类,以及飞机[3]和汽车[4]的模型。近年来,卷积神经网络(convolutional neural networks, cnn)在人脸识别[5]、自动驾驶[6]、行人再识别[7]、IOT中的智能物流等许多任务上都取得了很大的进展。
然而,如图1所示,由于类内变化大,类间变化小,传统的cnn不足以捕获细微的区别特征,这使得FGVC仍然是一项具有挑战性的任务。

2.1发现
因此,如何使cnn找到可区分的部分并学习判别特征是需要解决的重要问题。早期的作品[8][9][10][11]依赖于预定义的边界框和部分注释来捕捉视觉差异。然而,收集额外的注释信息是劳动密集型的,需要专业知识,这使得这些方法不太实用。因此,研究人员最近将更多的注意力集中在弱监督的FGVC上,这种FGVC只需要图像标签作为监督。
2.2发展
在这个方向上有两个范例。一种是基于局部特征,这些方法[12][13][14][15][16]通常由两个不同的子网组成。具体来说,设计了一个带有注意机制的定位子网络来定位有区别的部分,遵循一个分类子网络来识别。专门的损失函数设计用于优化两个子网。这些方法的局限性在于由于注意模块和损失函数的特殊设计而难以优化。另一种是基于高阶信息,这些方法[17][18][19][20][21]认为一阶信息不足以对差异进行建模,而是使用高阶信息对区分进行编码。这些方法的局限性是占用大量GPU资源,可解释性差。
2.3创新
我们提出了特征增强,抑制和多样化,以提高效率和可解释性。我们认为,基于注意力的方法倾向于关注最显著的部分,因此其他不显著但可区分的部分没有机会脱颖而出[22]。然而,当屏蔽或抑制最突出的部分时,网络将被迫挖掘其他潜在的部分。基于这一简单有效的思想,我们引入了一个特征增强和抑制模块(FBSM),该模块突出当前阶段特征映射中最突出的部分以获得特定于部分的表示,并对其进行抑制以迫使下一阶段挖掘其他潜在的arXiv:2103.02782v2 [cs]。2021年5月5日零件。通过将fbsm插入到cnn的中间层中,我们可以得到多个特定于部件的特征表示,这些特征表示明确地集中在不同的对象部件上。
直观地说,单个部件特定的特征表示忽略了来自整个对象的知识,可能只见树木不见森林。为了消除偏差,我们引入了特征多样化模块(FDM)来多样化每个部件特定的特征表示。具体来说,给定特定于某个部分的表示,我们通过聚合从其他部分发现的互补信息来增强它。通过对零件交互过程进行FDM建模,使零件特定特征的表示更具判别性和丰富性。
最后,对FBSM和FDM进行联合优化,如图2所示。我们的方法不需要边界框/部分注释,并且在几个标准基准数据集上报告了最先进的性能。此外,我们的模型轻量级且易于训练,因为它不涉及多群机制[12][23][13]
我们的贡献总结如下:
•我们提出了一个特征增强和抑制模块,它可以显式地强制网络关注多个有区别的部分。
•我们提出了一个特征多样化模块,该模块可以为零件交互建模,并使每个零件特定的表示多样化。
2.4补充
A. Fine-Grained Feature Learning
Ding等[16]提出了稀疏选择性采样学习,以获得判别区和互补区。Sun等[24]提出了一种挤压多激励模块来学习多个部件,然后对这些部件应用多注意多类约束。Zhang等[25]提出通过对比图像对来发现对比线索。yang等[14]引入了一个导航员-教师-审查员网络来获得判别区域。Luo等[26]提出了Cross-X学习来探索不同图像和不同层之间的关系。Gao等人[27]提出对渠道相互作用进行建模,以捕捉细微的差异。Li等[19]提出了通过矩阵平方根归一化捕获判别,并引入了快速端到端训练的迭代方法。Shi等[28]从可区分的部分中去除易混淆的特征,以促进细粒度分类。
He等人[29]提出了渐进式关注,以在不同尺度上定位部位。我们的方法利用特征增强和抑制来明确地学习不同的部件表示,这与以前的方法有很大的不同。
B. Feature Fusion
FPN[30]和SSD[31]对不同层的特征图进行聚合,在目标检测领域取得了很大的成功。但是,它们使用元素加法作为聚合操作,这使得这些方法的功能仍然有限。王很高兴。[32]提出了一种非局部运算,将空间位置的响应计算为特征映射中所有位置的特征的加权和。SG-Net[33]利用非局部操作来融合来自不同层的特征图。CIN[27]采用非局部运算从不同的特征通道中挖掘语义互补信息。我们的FDM与[33]和[27]相似,但存在本质区别:(1)SG-Net倾向于探索正相关性以捕获长期依赖关系,而FDM倾向于探索负相关性以使特征表示多样化。(2) CIN沿着通道维度挖掘互补信息,而FDM沿着空间维度挖掘互补信息。
3.网络
3.1整体结构
在本节中,我们将详细介绍所建议的方法。该框架的概述如图2所示。我们的模型由两个轻量级模块组成:(1)特征增强和抑制模块(FBSM),旨在学习尽可能不同的多个区别性部件特定表示。(2)基于部件交互建模的特征多样化模块(FDM),增强部件的具体表示。
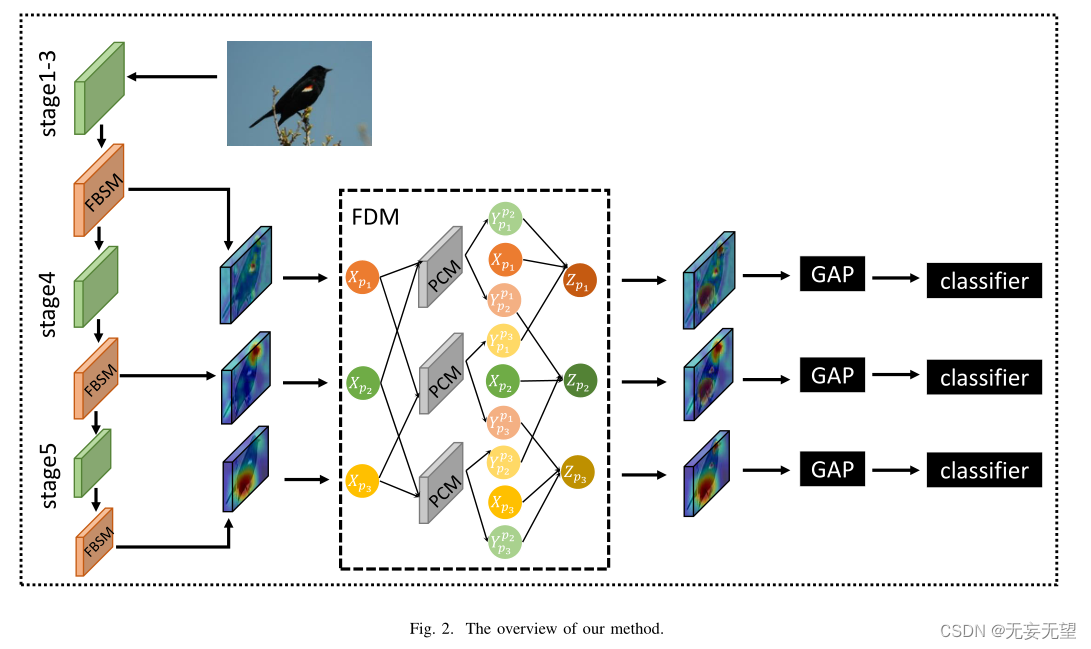
3.2 Feature Boosting and Suppression Module
给定某一层的特征映射X∈RC×W ×H,其中C、W、H分别表示通道数、宽度和高度。受[7]的启发,我们简单地沿宽度维度将X平均分成k个部分,并将每个条纹部分表示为X(i)∈rcx (W/k)×H, i∈[1,k]。然后我们使用一个1 × 1的卷积φ来探索每个部分的重要性:

采用非线性函数Relu[34]去除负激活。φ在不同的条纹部分之间共享,并作为分级器。然后取A(i)的平均值作为X(i)的重要因子b0i,即:
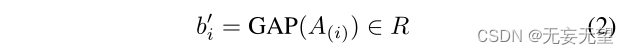
其中GAP表示全球平均池。我们使用softmax对B0 = (b01,···,b0k)T进行归一化:

通过归一化的重要因子B = (b1,···,bk)T,可以立即确定最突出的部分。然后,通过对最显著部分进行增强,得到增强特征Xb:

其中α是控制升压程度的超参数,⊗表示逐元素乘法。在Xb上应用卷积层h,得到部分特定表示Xp:
![]()
通过抑制条纹最多的部分,我们可以得到抑制特征Xs:
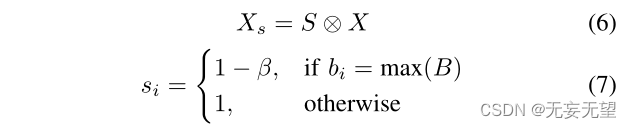
其中S = (s1,···,sk)T, β是控制抑制程度的超参数。
简言之,FBSM的功能可以表示为:FBSM(X) = (Xp, Xs)。给定特征映射X, FBSM输出部分特定的特征Xp和潜在的特征映射X。由于Xs在当前阶段抑制了最突出的部分,所以在将Xs输入到下一阶段后,其他潜在的部分将会脱颖而出。FBSM的示意图如图3所示。
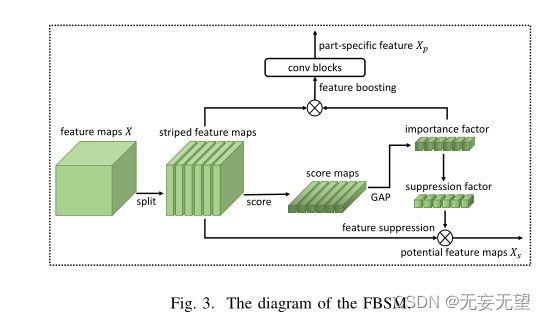
用类似于分组卷积的方式获取分条特征,使用1*1卷积获取重要部分,在之后通过GAP来获取显著部分权重,与输入进行矩阵相乘获得显著特征;另一方面,通过对显著权重抑制,从而得到次显著权重,再次与输入进行矩阵相乘获得次显著特征。
这个通过显著特征权重,得到次显著权重的方法,理论上来说是可以的。但是实际用代码实现,是拿1-显著权重,结果为次显著权重。
3.3 Feature Diversification Module
由于学习区别性和多样性特征在FGVC中起着关键作用[35][24][23],我们提出了一个特征多样化模块,该模块通过聚合从其他部分特定表示中挖掘的互补信息来增强每个部分特定特征。
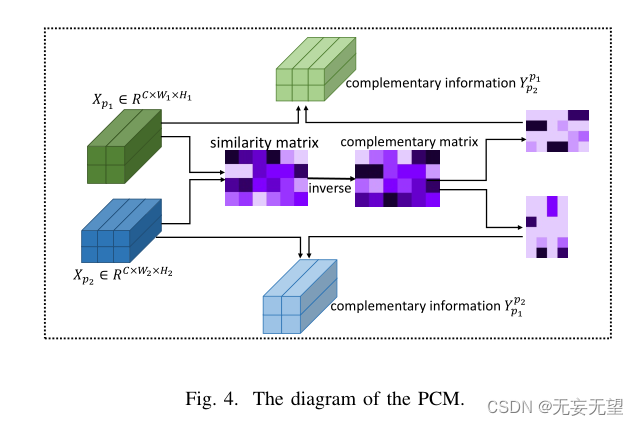
我们首先讨论了两个特定于零件的特征如何通过配对互补模块(PCM)相互多样化。图4显示了PCM的一个简单示例。在不失一般性的前提下,我们将两个不同的局部特征表示为Xp1∈RC×W1H1和Xp2∈RC×W2H2,其中C表示通道数量,W1H1和W2H2分别表示通道的空间大小。我们使用下标pi表示Xpi聚焦于对象的第i部分,当没有歧义时将省略下标。我们将通道维度上每个空间位置的特征向量表示为一个像素,即:
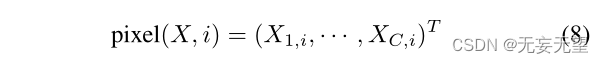
我们首先计算Xp1和Xp2像素之间的相似度:
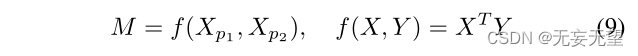
这里,我们使用内积来计算相似度。元素Mi,j表示Xp1的第i个像素与Xp2的第j个像素的相似度。两个像素点的相似度越低,表示它们的互补性越强,因此我们采用−M作为互补矩阵。然后分别对- M行和列进行归一化操作:
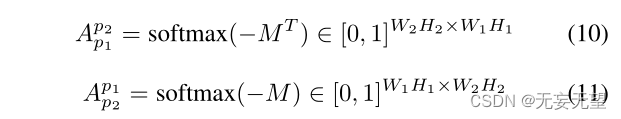
其中softmax是按列执行的。然后我们可以得到互补信息:
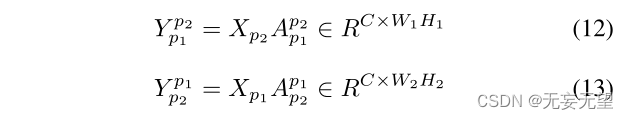
其中,Y pjpi表示Xpi相对于Xpj的互补信息。值得注意的是,Y p2p1的每个像素可以写成:

即Y p2p1的每个像素都以Xp2的所有像素为参照,像素(Xp1, i)与像素(Xp2, j)的互补性越高,像素(Xp2, j)对像素(Y p2p1, i)的贡献越大。这样,这两个部分特定特征中的每个像素都可以相互挖掘语义互补信息。
现在我们讨论一般情况。形式上,给定一个局部特征集合P = {Xp1, Xp2, Xp3···,Xpn},则Xpi的互补信息为:
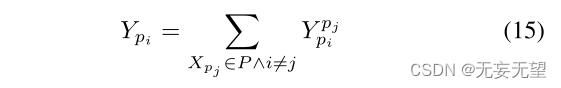
其中,将Xpi和Xpj分别作用于(9)、(10)、(12),得到Y pjpi。在实践中,我们可以同时计算Y pjpi和Y pipjj,如图4所示。然后我们得到了增强的部分特定特性:
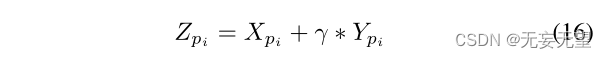
其中γ是控制多样化程度的超参数。
属于特征融合的一种方法
3.4 Network Design
我们的方法可以很容易地在各种卷积神经网络上实现。如图2所示,我们以Resnet[36]为例。Resnet的特征提取分为五个阶段,每个阶段后特征图的空间大小减半。考虑到深层有更多的语义信息,我们将fbsm插入到stage3, stage4, stage5的末尾。由fbsm生成的不同部件特定表示被馈送到FDM中,以使每种表示多样化。
我们的方法具有高度的可定制性,可以通过直接调整fbsm的数量来适应不同粒度的分类。在训练时,我们计算每个增强部件特定特征Zpi的分类损失:
![]()
其中y为输入图像的ground-truth标签,用one-hot向量表示,clsi为第i部分的分类器,pi∈RN为预测评分向量,N为对象类别的个数。最终优化目标为:
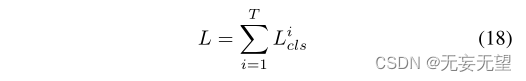
其中T = 3是增强的部件特定特征的数量。在推理时,我们将所有增强部分特定特征的预测分数的平均值作为最终的预测结果
4.实验
4.1实验设置
4.1.1数据集
CUB-200-2011 [1], FGVC-Aircraft [3], Stanford Cars [4],Stanford Dogs [2]
4.1.2实验细节
我们在Resnet50, Resnet101[36]和Densenet161[40]上验证了我们的方法的性能,它们都是在ImageNet数据集[41]上预训练的。我们在阶段3、阶段4和阶段5的末尾插入fbsm。在训练过程中,输入图像被调整为550 × 550,随机裁剪为448 × 448。我们应用随机水平翻转来扩大列车集。在测试期间,输入图像被调整为550 × 550,并从中心裁剪为448 × 448。我们设置超参数α = 0.5, β = 0.5和γ = 1。
我们的模型采用随机梯度下降优化,动量为0.9,epoch数为200,权重衰减为0.00001,mini-batch为20。骨干层学习率设置为0.002,新增层学习率设置为0.02。学习率由余弦退火调度器调节[42]。
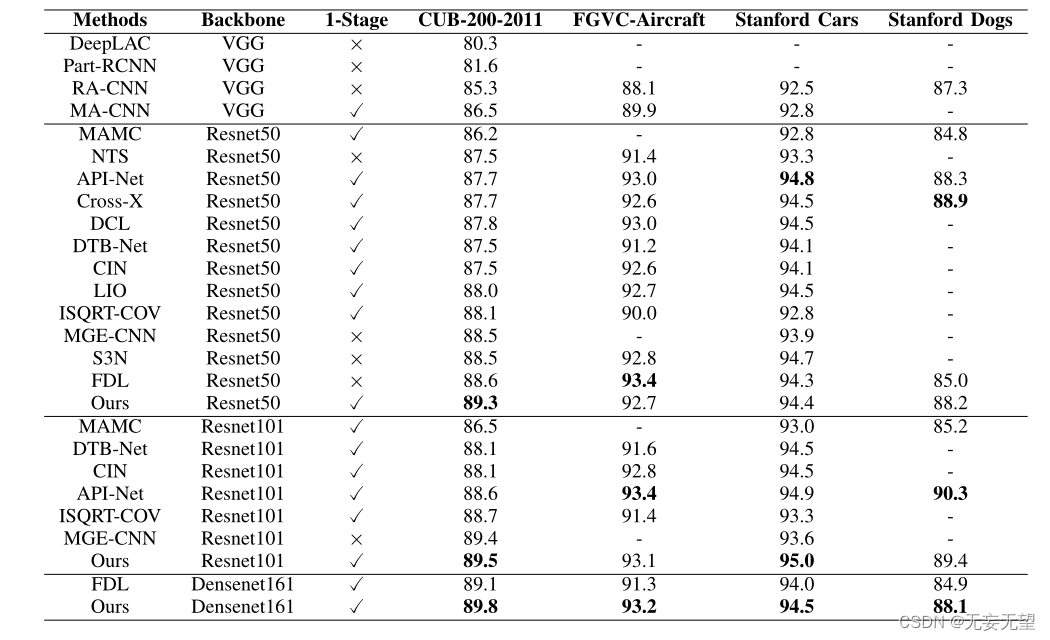
4.2对比试验
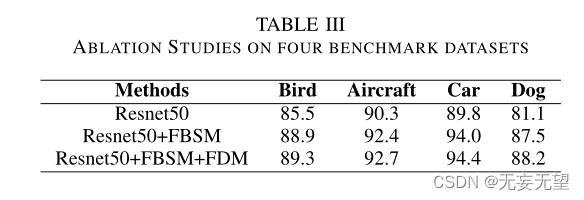
4.3消融实验
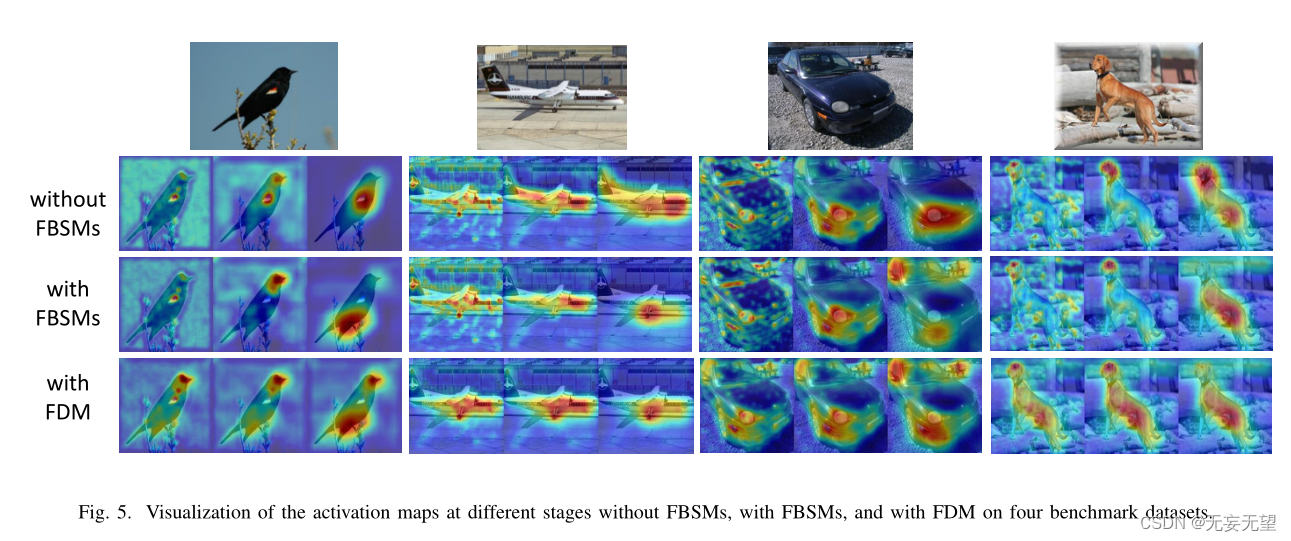
4.4可视化
5.结语
在本文中,我们提出学习特征增强、抑制和多样化来进行细粒度视觉分类。具体来说,我们引入了两个轻量级模块:一个是特征增强和抑制模块,它对特征映射中最突出的部分进行增强以获得特定于零件的特征,并对其进行抑制以显式地强制后续阶段挖掘其他潜在零件。另一个是特征多样化模块,它将来自其他对象部件的语义互补信息聚合到每个特定部件的表示中。这两个模块之间的协同作用有助于网络学习更具判别性和多样性的特征表示。我们的方法可以端到端训练,不需要边界框/部分注释。
在几个基准数据集上获得了最先进的结果,烧蚀研究进一步证明了每个提出模块的有效性。在未来,我们将研究如何自适应地将特征映射划分为合适的补丁来增强和抑制,而不是简单的条纹部分。