1 前言
1-1 简介
由于对图数据库需要经常维护,图数据库建设初期,需要经常对数据写入删除等操作。
1-2 任务背景
再将1100万数据写入Neo4j后,由于需要对每个实体的label做精细化处理,之前写入的时候每个实体的label全部都为‘Common_test’,但是由于实体中是存在标签的,所以再后来的维护中需要将图数据库中的节点全部删除,重新写入。
1-3 图数据库来源
之前部署在服务器中的Neo4j图数据库。
2 任务实现
在删除图数据库节点时,有以下两种方案,分别是应对少数据量和千万级大数据量两种。
2-1 少数据量
数据量少时可直接批量删除。
from py2neo import Graph
graph = Graph('http://xx.xx.xx.xxx:7474/browser/', auth=('neo4j', 'password'))
#直接删除
graph.delete_all()
# 删除节点及其子图
node = NodeMatcher(graph=graph).match("Test", name='test1').first()
result = graph.delete(node)2-2 大批量数据
对于大批量数据,在直接删除时会爆出内存不足的错误。借助APOC工具包,可以进行分批次删除。
graph.delete_all()
DatabaseError: [Statement.ExecutionFailed] Java heap space2-2-1 下载
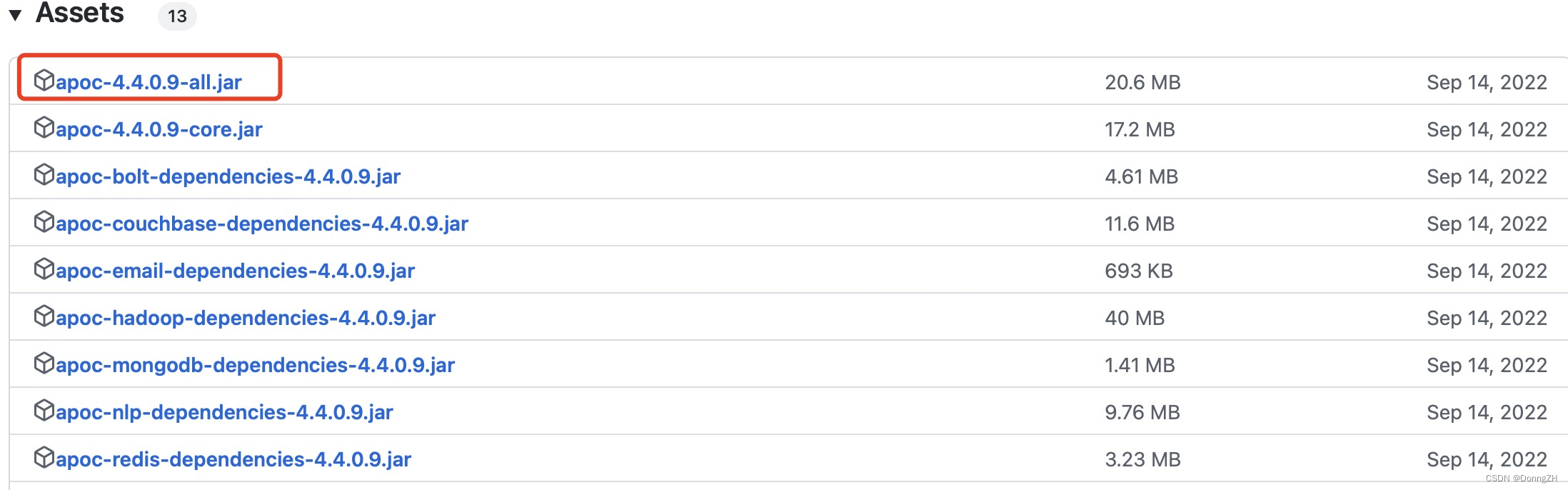
jar包下载地址:https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/![]() https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/
https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/
根据neo4j的版本下载合适的jar包。
2-2-2 安装
1. 下载apoc jar包,放到 neo4j安装目录plugins下目录

2.修改配置文件

dbms.security.procedures.unrestricted=apoc.*,algo.*
apoc.import.file.enabled=true
apoc.export.file.enabled=true
##下面这条配置是可选的,表示使用neo4j的配置,比如导入数据的路径
##apoc.import.file.use_neo4j_config=true
3.重启Neo4j
2-2-3 执行代码
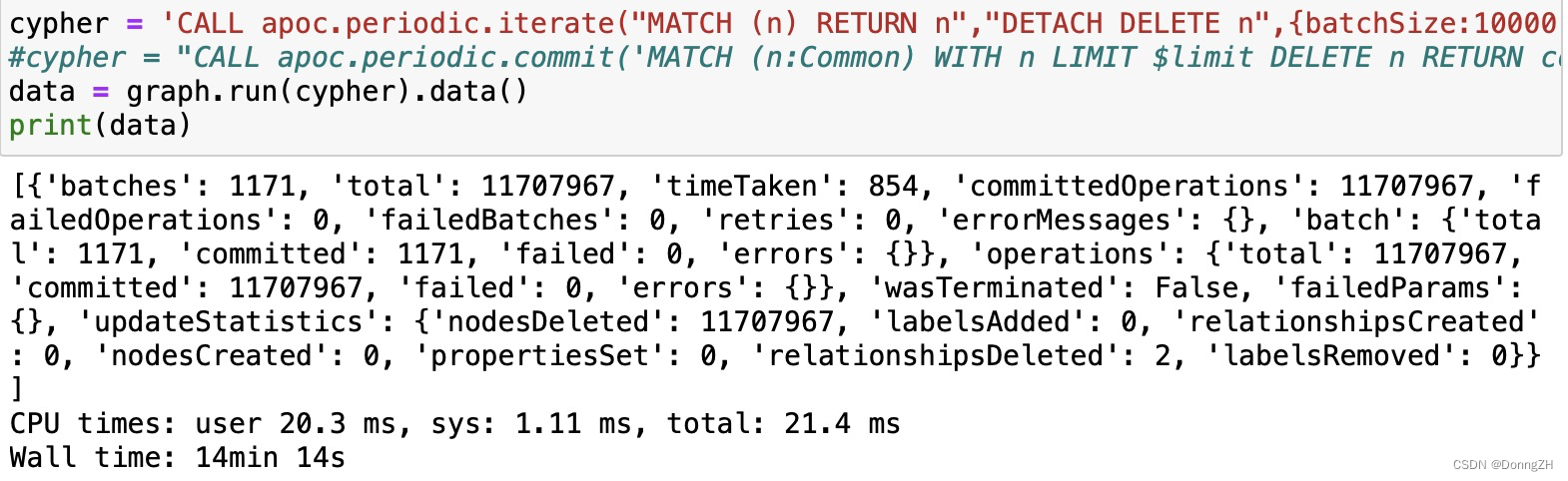
cypher = 'CALL apoc.periodic.iterate("MATCH (n) RETURN n","DETACH DELETE n",{batchSize:10000, parallel:false})'
#cypher = "CALL apoc.periodic.commit('MATCH (n:Common) WITH n LIMIT $limit DELETE n RETURN count(*)',{limit: 10000}) YIELD updates, executions, runtime, batches RETURN updates, executions, runtime, batches;"
data = graph.run(cypher).data()
print(data)