目录
- 7.共享模型之工具
- 7.1.线程池
- 7.1.1.自定义线程池
- 7.1.2.ThreadPoolExecutor
- 7.1.2.1.线程池状态
- 7.1.2.2.构造方法
- 7.1.2.3.newFixedThreadPool
- 7.1.2.4.newCachedThreadPool
- 7.1.2.5.newSingleThreadExecutor
- 7.1.2.6.提交任务
- 7.1.2.7.关闭线程池
- 7.1.2.9.异步模式之工作线程
- 7.1.2.10.任务调度线程池
- 7.1.2.11.正确处理执行任务异常
- 7.1.2.12.应用之定时任务
- 7.1.2.13.Tomcat 线程池
- 7.1.3.Fork/Join
- 7.1.3.1.概述
- 7.1.3.2.应用
- 7.2.JUC
- 7.2.1.AQS 原理
- 7.2.1.1.概述
- 7.2.1.3.实现不可重入锁
- 7.2.2.ReentrantLock 原理
- 7.2.2.1.非公平锁实现原理
- 7.2.2.1.1.加锁解锁流程
- 7.2.2.1.2.加锁源码
- 7.2.2.1.3.解锁源码
- 7.2.2.2.可重入原理
- 7.2.2.3.可打断原理
- 7.2.2.3.1.不可打断模式
- 7.2.2.3.2.可打断模式
- 7.2.2.4.公平锁实现原理
- 7.2.2.5.条件变量实现原理
- 7.2.2.5.1.await 流程
- 7.2.2.5.2.signal 流程
- 7.2.2.5.3.源码
- 7.2.3.读写锁
- 7.2.3.1.ReentrantReadWriteLock
- 7.2.3.2.StampedLock
- 7.2.4.Semaphore
- 7.2.4.1.基本使用
- 7.2.4.2.应用
- 7.2.4.3.原理——加锁解锁流程
- 7.2.5.CountdownLatch
- 7.2.5.1.概述
- 7.2.5.2.案例
- 7.2.5.3.应用之同步等待多线程准备完毕
- 7.2.6.CyclicBarrier
- 7.2.7.线程安全集合类概述
- 7.2.8.ConcurrentHashMap
- 7.2.9.BlockingQueue
- 7.2.10.ConcurrentLinkedQueue
- 7.2.11.11.CopyOnWriteArrayList
本文笔记整理来自黑马视频https://www.bilibili.com/video/BV16J411h7Rd/?p=187,相关资料可在视频评论区进行获取。
7.共享模型之工具
7.1.线程池
7.1.1.自定义线程池
阻塞队列
@Slf4j(topic = "c.BlockingQueue")
class BlockingQueue<T> {
//1.任务队列
private Deque<T> queue = new ArrayDeque<>();
//2.锁
private ReentrantLock lock = new ReentrantLock();
//3.生产者条件变量
private Condition fullWaitSet = lock.newCondition();
//4.消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
//5.容量
private int capacity;
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
//带超时的阻塞获取
public T poll(long timeout, TimeUnit unit) {
lock.lock();
try {
//将 timeout 统一转换为纳秒
long nanos = unit.toNanos(timeout);
while (queue.isEmpty()) {
try {
if (nanos <= 0) {
return null;
}
//返回剩余时间,解决虚假唤醒问题
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
//阻塞获取
public T take() {
lock.lock();
try {
while (queue.isEmpty()) {
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
//阻塞添加
public void put(T task) {
lock.lock();
try {
while (queue.size() == capacity) {
try {
log.debug("等待加入任务队列 {}...", task);
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
//带超时时间的阻塞添加
public boolean offer(T task, long timeout, TimeUnit unit) {
lock.lock();
try {
//将 timeout 统一转换为纳秒
long nanos = unit.toNanos(timeout);
while (queue.size() == capacity) {
try {
log.debug("等待加入任务队列 {}...", task);
if (nanos <= 0) {
return false;
}
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
return true;
} finally {
lock.unlock();
}
}
//获取队列大小
public int size() {
lock.lock();
try {
return queue.size();
} finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
//判断队列是否已满
if (queue.size() == capacity) {
rejectPolicy.reject(this, task);
} else {
//有空闲
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
}
拒绝策略
//拒绝策略
@FunctionalInterface
interface RejectPolicy<T> {
void reject(BlockingQueue<T> queue, T task);
}
线程池
@Slf4j(topic = "c.ThreadPool")
class ThreadPool {
//任务队列
private BlockingQueue<Runnable> taskQueue;
//线程集合
private HashSet<Worker> workers = new HashSet<>();
//核心线程数
private int coreSize;
//获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
//执行任务
public void execute(Runnable task) {
synchronized (workers) {
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
log.debug("新增 worker {}, {}", worker, task);
workers.add(worker);
worker.start();
} else {
//taskQueue.put(task);
// 1) 死等
// 2) 带超时等待
// 3) 让调用者放弃任务执行
// 4) 让调用者抛出异常
// 5) 让调用者自己执行任务
taskQueue.tryPut(rejectPolicy, task);
}
}
}
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
class Worker extends Thread {
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
//执行任务
//while (task != null || (task = taskQueue.take()) != null) {
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
log.debug("正在执行...{}", task);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
synchronized (workers) {
log.debug("worker 被移除 {}", this);
workers.remove(task);
}
}
}
}
测试
@Slf4j(topic = "c.TestPool")
public class TestPool {
public static void main(String[] args) {
// ThreadPool threadPool = new ThreadPool(2, 1000, TimeUnit.MILLISECONDS, 10);
// for (int i = 0; i < 5; i++) {
// int j = i;
// threadPool.execute(() -> {
// log.debug("{}", j);
// });
// }
ThreadPool threadPool = new ThreadPool(1, 1500, TimeUnit.MILLISECONDS, 1,
(queue, task) -> {
// 1) 死等
//queue.put(task);
// 2) 带超时等待
//queue.offer(task, 500, TimeUnit.MILLISECONDS);
// 3) 让调用者放弃任务执行
//log.debug("放弃 {}", task);
// 4) 让调用者抛出异常
throw new RuntimeException("任务执行失败!" + task);
// 5) 让调用者自己执行任务
//task.run();
});
for (int i = 0; i < 3; i++) {
int j = i;
threadPool.execute(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("{}", j);
});
}
}
}
7.1.2.ThreadPoolExecutor
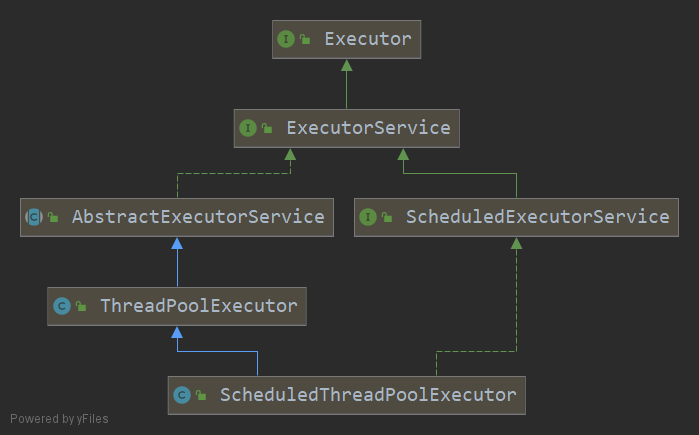
7.1.2.1.线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量。
| 状态名 | 高 3 位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | |
| SHUTDOWN | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 会中断正在执行的任务,并抛弃阻塞队列任务 |
| TIDYING | 010 | - | - | 任务全执行完毕,活动线程为 0 即将进入终结 |
| TERMINATED | 011 | - | - | 终结状态 |
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING。这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 CAS 原子操作进行赋值。
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
7.1.2.2.构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
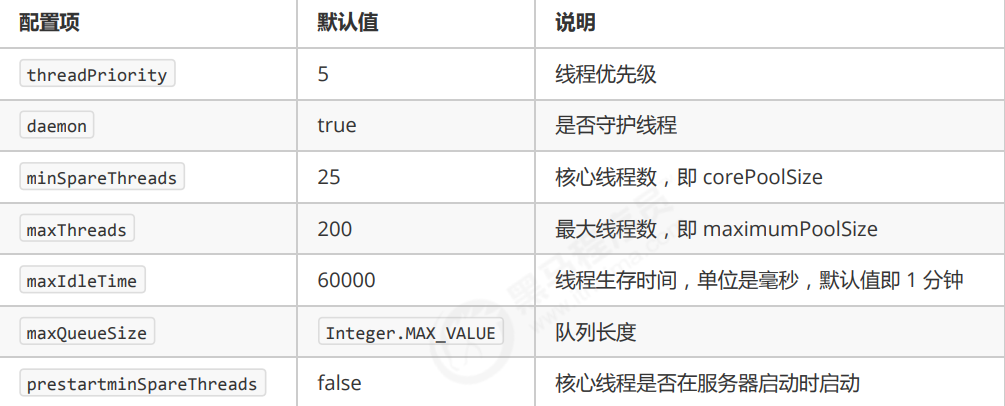
| 参数 | 含义 |
|---|---|
| corePoolSize | 核心线程数目(最多保留的线程数) |
| maximumPoolSize | 最大线程数目 |
| keepAliveTime | 生存时间,针对救急线程 |
| unit | 时间单位,针对救急线程 |
| workQueue | 阻塞队列 |
| threadFactory | 线程工厂,可以为线程创建时起个好名字 |
| handler | 拒绝策略 |
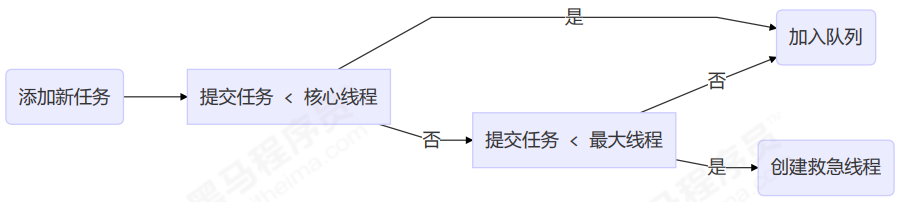
工作方式:
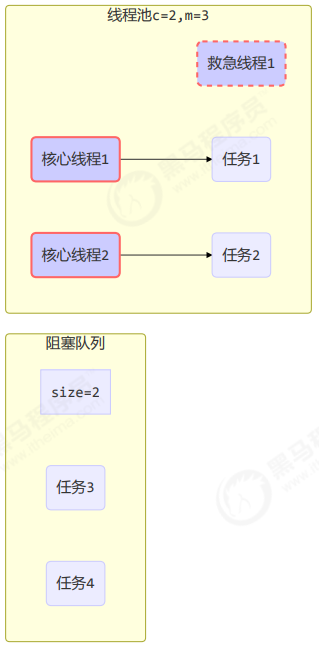
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急。
- 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它著名框架也提供了实现。
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略;
- CallerRunsPolicy 让调用者运行任务;
- DiscardPolicy 放弃本次任务;
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之;
- Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题;
- Netty 的实现,是创建一个新线程来执行任务;
- ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略;
- PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略;
- 当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由 keepAliveTime 和 unit 来控制。

根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池。
7.1.2.3.newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间;
- 阻塞队列是无界的,可以放任意数量的任务;
适用于任务量已知,相对耗时的任务。
package cn.itcast.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j(topic = "c.TestThreadPoolExecutor")
public class TestThreadPoolExecutor {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2, new ThreadFactory() {
private AtomicInteger t = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "mypool_t" + t.getAndIncrement());
}
});
pool.execute(() -> {
log.debug("1");
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
}
输出结果如下:
15:22:25 [mypool_t1] c.TestThreadPoolExecutor - 1
15:22:25 [mypool_t2] c.TestThreadPoolExecutor - 2
15:22:25 [mypool_t1] c.TestThreadPoolExecutor - 3
7.1.2.4.newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着:
- 全部都是救急线程(60s 后可以回收);
- 救急线程可以无限创建;
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货);
@SneakyThrows
public static void main(String[] args) {
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
Thread.sleep(1000);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
Thread.sleep(1000);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t3").start();
}
输出结果如下:
15:28:05 [t1] c.TestThreadPoolExecutor - putting 1
15:28:06 [t2] c.TestThreadPoolExecutor - taking 1
15:28:06 [t1] c.TestThreadPoolExecutor - 1 putted...
15:28:06 [t1] c.TestThreadPoolExecutor - putting...2
15:28:07 [t3] c.TestThreadPoolExecutor - taking 2
15:28:07 [t1] c.TestThreadPoolExecutor - 2 putted...
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况。
7.1.2.5.newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
使用场景:
- 希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改;
- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法;
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改;
- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改;
public static void main(String[] args) {
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
log.debug("1");
int i = 1 / 0;
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
输出结果如下:
15:51:23 [pool-1-thread-1] c.TestThreadPoolExecutor - 1
15:51:23 [pool-1-thread-2] c.TestThreadPoolExecutor - 2
15:51:23 [pool-1-thread-2] c.TestThreadPoolExecutor - 3
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
at cn.itcast.test.TestThreadPoolExecutor.lambda$main$0(TestThreadPoolExecutor.java:14)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
7.1.2.6.提交任务
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
(1)测试 submit
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<String> future = pool.submit(() -> {
log.debug("running");
Thread.sleep(1000);
return "OK";
});
log.debug("{}", future.get());
}
输出结果如下:
16:32:35 [pool-1-thread-1] c.TestThreadPoolExecutor - running
16:32:36 [main] c.TestThreadPoolExecutor - OK
(2)测试
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
List<Future<String>> futures = pool.invokeAll(Arrays.asList(
() -> {
log.debug("begin");
Thread.sleep(1000);
return "1";
},
() -> {
log.debug("mid");
Thread.sleep(500);
return "2";
},
() -> {
log.debug("end");
Thread.sleep(2000);
return "3";
}
));
futures.forEach(f -> {
try {
log.debug("{}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
输出结果如下:
16:44:40 [pool-1-thread-1] c.TestSubmit - begin
16:44:40 [pool-1-thread-2] c.TestSubmit - mid
16:44:40 [pool-1-thread-2] c.TestSubmit - end
16:44:42 [main] c.TestSubmit - 1
16:44:42 [main] c.TestSubmit - 2
16:44:42 [main] c.TestSubmit - 3
(3)测试 invokeAny
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
String res = pool.invokeAny(Arrays.asList(
() -> {
log.debug("begin 1");
Thread.sleep(1000);
log.debug("end 1");
return "1";
},
() -> {
log.debug("begin 2");
Thread.sleep(500);
log.debug("end 2");
return "2";
},
() -> {
log.debug("begin 3");
Thread.sleep(2000);
log.debug("end 3");
return "3";
}
));
log.debug("{}", res);
}
输出结果如下:
16:49:54 [pool-1-thread-2] c.TestSubmit - begin 2
16:49:54 [pool-1-thread-1] c.TestSubmit - begin 1
16:49:55 [pool-1-thread-2] c.TestSubmit - end 2
16:49:55 [pool-1-thread-2] c.TestSubmit - begin 3
16:49:55 [main] c.TestSubmit - 2
7.1.2.7.关闭线程池
(1)shutdown
/*
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
*/
void shutdown();
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 仅会打断空闲线程
interruptIdleWorkers();
onShutdown(); // 扩展点 ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等)
tryTerminate();
}
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<String> future1 = pool.submit(() -> {
log.debug("begin 1");
Thread.sleep(1000);
log.debug("end 1");
return "1";
});
Future<String> future2 = pool.submit(() -> {
log.debug("begin 2");
Thread.sleep(1000);
log.debug("end 2");
return "2";
});
Future<String> future3 = pool.submit(() -> {
log.debug("begin 3");
Thread.sleep(1000);
log.debug("end 3");
return "3";
});
log.debug("shutdown");
pool.shutdown();
log.debug("other");
}
输出结果如下:
17:58:16 [main] c.TestSubmit - shutdown
17:58:16 [pool-1-thread-1] c.TestSubmit - begin 1
17:58:16 [main] c.TestSubmit - other
17:58:16 [pool-1-thread-2] c.TestSubmit - begin 2
17:58:17 [pool-1-thread-1] c.TestSubmit - end 1
17:58:17 [pool-1-thread-2] c.TestSubmit - end 2
17:58:17 [pool-1-thread-1] c.TestSubmit - begin 3
17:58:18 [pool-1-thread-1] c.TestSubmit - end 3
Process finished with exit code 0
(2)shutdownNow
/*
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
*/
List<Runnable> shutdownNow();
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(STOP);
// 打断所有线程
interruptWorkers();
// 获取队列中剩余任务
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试终结
tryTerminate();
return tasks;
}
(3)其它方法
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事
情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
7.1.2.9.异步模式之工作线程
(1)定义
让有限的工作线程 (Worker Thread) 来轮流异步处理无限多的任务。也可以将其归类为分工模式,它的典型实现就是线程池,也体现了经典设计模式中的享元模式。
例如,海底捞的服务员(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那么成本就太高了(对比另一种多线程设计模式:Thread-Per-Message)。注意,不同任务类型应该使用不同的线程池,这样能够避免饥饿,并能提升效率。
例如,如果一个餐馆的工人既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)显然效率不咋地,分成服务员(线程池A)与厨师(线程池B)更为合理,当然你能想到更细致的分工。
(2)饥饿
固定大小线程池会有饥饿现象:
- 两个工人是同一个线程池中的两个线程;
- 他们要做的事情是:为客人点餐和到后厨做菜,这是两个阶段的工作;
- 客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待;
- 后厨做菜:没啥说的,做就是了;
- 比如工人A 处理了点餐任务,接下来它要等着 工人B 把菜做好,然后上菜,他俩也配合的蛮好;
- 但现在同时来了两个客人,这个时候工人A 和工人B 都去处理点餐了,这时没人做饭了,会出现饥饿现象;
package cn.itcast.pattern;
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
@Slf4j(topic = "c.TestStarvation")
public class TestStarvation {
static final List<String> MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
log.debug("处理点餐...");
Future<String> f = executorService.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
executorService.execute(() -> {
log.debug("处理点餐...");
Future<String> f = executorService.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
}
输出结果如下:
10:35:48 [pool-1-thread-1] c.TestStarvation - 处理点餐...
10:35:48 [pool-1-thread-2] c.TestStarvation - 处理点餐...
解决办法:可以增加线程池的大小,不过不是根本解决方案,还是前面提到的,不同的任务类型,采用不同的线程池。
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(1);
ExecutorService cookPool = Executors.newFixedThreadPool(1);
waiterPool.execute(() -> {
log.debug("处理点餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
waiterPool.execute(() -> {
log.debug("处理点餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
输出结果如下:
10:37:38 [pool-1-thread-1] c.TestStarvation - 处理点餐...
10:37:38 [pool-2-thread-1] c.TestStarvation - 做菜
10:37:38 [pool-1-thread-1] c.TestStarvation - 上菜: 宫保鸡丁
10:37:38 [pool-1-thread-1] c.TestStarvation - 处理点餐...
10:37:38 [pool-2-thread-1] c.TestStarvation - 做菜
10:37:38 [pool-1-thread-1] c.TestStarvation - 上菜: 烤鸡翅
(3)创建多少线程池合适
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿;
- 过大会导致更多的线程上下文切换,占用更多内存;
CPU 密集型运算:
通常采用 cpu 核数 + 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费。
I/O 密集型运算:
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。经验公式如下:
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间
例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式:
4 * 100% * 100% / 50% = 8
例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式:
4 * 100% * 100% / 10% = 40
7.1.2.10.任务调度线程池
(1)在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。
package cn.itcast.test;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.Timer;
import java.util.TimerTask;
@Slf4j(topic = "c.TestTimer")
public class TestTimer {
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@SneakyThrows
@Override
public void run() {
log.debug("task 1");
Thread.sleep(2000);
//测试异常
//int i = 1 / 0;
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
log.debug("start");
timer.schedule(task1, 1);
timer.schedule(task2, 1);
}
}
输出结果如下:
10:57:34 [main] c.TestTimer - start
10:57:34 [Timer-0] c.TestTimer - task 1
10:57:36 [Timer-0] c.TestTimer - task 2
(2)使用 ScheduledExecutorService 改写:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 添加两个任务,希望它们都在 1s 后执行
executor.schedule(()-> {
System.out.println("任务1,执行时间:" + new Date());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(()-> {
System.out.println("任务2,执行时间:" + new Date());
}, 1000, TimeUnit.MILLISECONDS);
输出结果如下:
任务2,执行时间:Mon Jan 02 11:02:50 CST 2023
任务1,执行时间:Mon Jan 02 11:02:50 CST 2023
(3)scheduleAtFixedRate 例子
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 1, 1, TimeUnit.SECONDS);
}
}
输出结果如下:
14:31:52 [main] c.TestTimer - start...
14:31:53 [pool-1-thread-1] c.TestTimer - running...
14:31:54 [pool-1-thread-1] c.TestTimer - running...
14:31:55 [pool-1-thread-1] c.TestTimer - running...
14:31:56 [pool-1-thread-1] c.TestTimer - running...
14:31:57 [pool-1-thread-1] c.TestTimer - running...
...
任务执行时间超过了间隔时间:
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 1, 1, TimeUnit.SECONDS);
}
输出结果如下:
14:33:39 [main] c.TestTimer - start...
14:33:40 [pool-1-thread-1] c.TestTimer - running...
14:33:42 [pool-1-thread-1] c.TestTimer - running...
14:33:44 [pool-1-thread-1] c.TestTimer - running...
14:33:46 [pool-1-thread-1] c.TestTimer - running...
...
输出分析:一开始,延时 1s,接下来,由于任务执行时间 > 间隔时间,间隔被『撑』到了 2s。
(4)scheduleWithFixedDelay 例子
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleWithFixedDelay(()-> {
log.debug("running...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 1, 1, TimeUnit.SECONDS);
}
输出结果如下:
14:35:13 [main] c.TestTimer - start...
14:35:14 [pool-1-thread-1] c.TestTimer - running...
14:35:17 [pool-1-thread-1] c.TestTimer - running...
14:35:20 [pool-1-thread-1] c.TestTimer - running...
14:35:23 [pool-1-thread-1] c.TestTimer - running...
14:35:26 [pool-1-thread-1] c.TestTimer - running...
...
输出分析:一开始,延时 1s,scheduleWithFixedDelay 的间隔是 上一个任务结束 <-> 延时 <-> 下一个任务开始,所以间隔都是 3s。
整个线程池表现为:线程数固定,任务数多于线程数时,会放入无界队列排队。任务执行完毕,这些线程也不会被释放。用来执行延迟或反复执行的任务。
7.1.2.11.正确处理执行任务异常
(1)主动捉异常
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
}
输出结果如下:
14:41:36 [pool-1-thread-1] c.TestTimer - task1
14:41:36 [pool-1-thread-1] c.TestTimer - error:
java.lang.ArithmeticException: / by zero
at cn.itcast.test.TestTimer.lambda$main$0(TestTimer.java:21)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
(2)使用 Future
@SneakyThrows
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get());
}
输出结果如下:
14:42:34 [pool-1-thread-1] c.TestTimer - task1
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at cn.itcast.test.TestTimer.main(TestTimer.java:21)
Caused by: java.lang.ArithmeticException: / by zero
at cn.itcast.test.TestTimer.lambda$main$0(TestTimer.java:18)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
7.1.2.12.应用之定时任务
如何让每周四 18:00:00 定时执行任务?
public static void main(String[] args) {
//获取当前时间
LocalDateTime now = LocalDateTime.now();
//获取本周四的 18:00:00.000
LocalDateTime thursday = now.with(DayOfWeek.THURSDAY).withHour(18).withMinute(0).withSecond(0).withNano(0);
//如果当前时间已经超过本周四的 18:00:00.000,那么则获取下周四的对应时间
if (now.compareTo(thursday) >= 0) {
thursday = thursday.plusWeeks(1);
}
//计算时间差,即延迟执行时间
long initialDelay = Duration.between(now, thursday).toMillis();
//计算时间间隔,即 1 周的毫秒值
long oneWeek = 7 * 24 * 3600 * 1000;
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
System.out.println("开始时间:" + new Date());
executor.scheduleAtFixedRate(() -> {
System.out.println("执行时间:" + new Date());
}, initialDelay, oneWeek, TimeUnit.MILLISECONDS);
}
7.1.2.13.Tomcat 线程池
(1)Tomcat 在哪里用到了线程池呢?
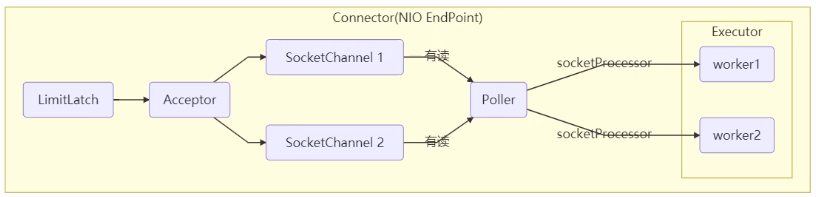
- LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore 后面再讲;
- Acceptor 只负责【接收新的 socket 连接】;
- Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】;
- 一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理;
- Executor 线程池中的工作线程最终负责【处理请求】;
(2)Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同。
- 如果总线程数达到 maximumPoolSize:
- 这时不会立刻抛 RejectedExecutionException 异常;
- 而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常;
(3)Connector 配置
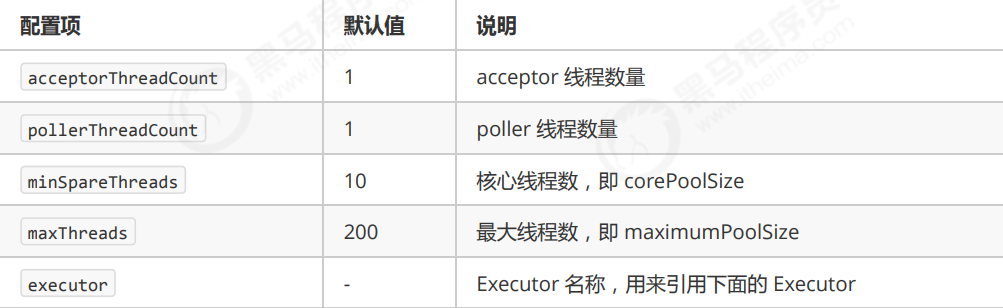
(4)Executor 线程配置
7.1.3.Fork/Join
7.1.3.1.概述
- Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算;
- 所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解;
- Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率;
- Fork/Join 默认会创建与 CPU 核心数大小相同的线程池;
7.1.3.2.应用
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值),例如下面定义了一个对 1~n 之间的整数求和的任务。
package cn.itcast.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
@Slf4j(topic = "c.TestForkJoin")
public class TestForkJoin {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
Integer res = pool.invoke(new MyTask(5));
System.out.println(res);
}
}
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
private int n;
public MyTask(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
protected Integer compute() {
//终止拆分条件
if (n == 1) {
log.debug("join() {}", n);
return 1;
}
MyTask t1 = new MyTask(n - 1);
//拆分,让一个线程区执行此任务
t1.fork();
log.debug("fork() {} + {}", n, t1);
//获取结果
int result = n + t1.join();
log.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
输出结果如下:
20:32:13 [ForkJoinPool-1-worker-1] c.MyTask - fork() 5 + {4}
20:32:13 [ForkJoinPool-1-worker-2] c.MyTask - fork() 4 + {3}
20:32:13 [ForkJoinPool-1-worker-3] c.MyTask - fork() 3 + {2}
20:32:13 [ForkJoinPool-1-worker-0] c.MyTask - fork() 2 + {1}
20:32:13 [ForkJoinPool-1-worker-3] c.MyTask - join() 1
20:32:13 [ForkJoinPool-1-worker-0] c.MyTask - join() 2 + {1} = 3
20:32:13 [ForkJoinPool-1-worker-3] c.MyTask - join() 3 + {2} = 6
20:32:13 [ForkJoinPool-1-worker-2] c.MyTask - join() 4 + {3} = 10
20:32:13 [ForkJoinPool-1-worker-1] c.MyTask - join() 5 + {4} = 15
15
Process finished with exit code 0
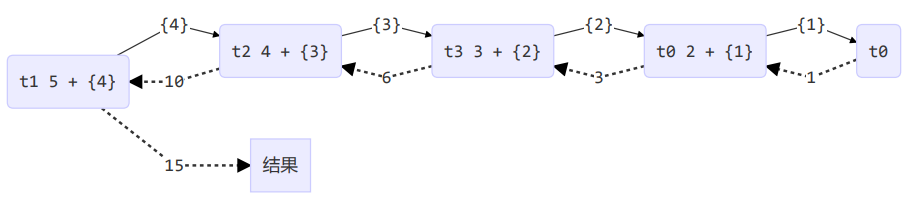
由上图可以发现部分线程之间存在依赖关系,即一个线程需要获取另一个线程的结果后才能继续执行下去,改进如下:
package cn.itcast.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
@Slf4j(topic = "c.TestForkJoin")
public class TestForkJoin {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
Integer res = pool.invoke(new MyTask(1, 5));
System.out.println(res);
}
}
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
int begin;
int end;
public MyTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
public String toString() {
return "{" + begin + "," + end + '}';
}
@Override
protected Integer compute() {
// 5, 5
if (begin == end) {
log.debug("join() {}", begin);
return begin;
}
// 4, 5
if (end - begin == 1) {
log.debug("join() {} + {} = {}", begin, end, end + begin);
return end + begin;
}
// 1 5
int mid = (end + begin) / 2; // 3
MyTask t1 = new MyTask(begin, mid); // 1,3
t1.fork();
MyTask t2 = new MyTask(mid + 1, end); // 4,5
t2.fork();
log.debug("fork() {} + {} = ?", t1, t2);
int result = t1.join() + t2.join();
log.debug("join() {} + {} = {}", t1, t2, result);
return result;
}
}
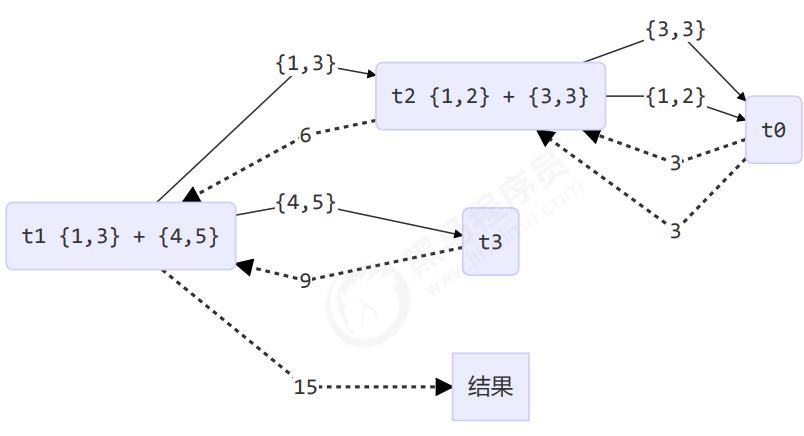
输出结果如下:
20:53:18 [ForkJoinPool-1-worker-0] c.MyTask - join() 1 + 2 = 3
20:53:18 [ForkJoinPool-1-worker-2] c.MyTask - fork() {1,2} + {3,3} = ?
20:53:18 [ForkJoinPool-1-worker-1] c.MyTask - fork() {1,3} + {4,5} = ?
20:53:18 [ForkJoinPool-1-worker-3] c.MyTask - join() 4 + 5 = 9
20:53:18 [ForkJoinPool-1-worker-0] c.MyTask - join() 3
20:53:18 [ForkJoinPool-1-worker-2] c.MyTask - join() {1,2} + {3,3} = 6
20:53:18 [ForkJoinPool-1-worker-1] c.MyTask - join() {1,3} + {4,5} = 15
15
7.2.JUC
7.2.1.AQS 原理
7.2.1.1.概述
(1)AQS 的全称是 Abstract Queued Synchronizer,是阻塞式锁和相关的同步器工具的框架。
(2)特点:
- 用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁:
- getState - 获取 state 状态;
- setState - 设置 state 状态;
- compareAndSetState - cas 机制设置 state 状态;
- 独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源;
- 提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList;
- 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet;
(3)子类主要实现这样一些方法(默认抛出 UnsupportedOperationException):
- tryAcquire
- tryRelease
- tryAcquireShared
- tryReleaseShared
- isHeldExclusively
//获取锁的方法
// 如果获取锁失败
if (!tryAcquire(arg)) {
//入队,可以选择阻塞当前线程 park unpark
}
//释放锁的方法
// 如果释放锁成功
if (tryRelease(arg)) {
//让阻塞线程恢复运行
}
7.2.1.3.实现不可重入锁
// 自定义锁(不可重入锁)
class MyLock implements Lock {
// 自定义同步器类 独占锁
class MySync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if(compareAndSetState(0, 1)) {
// 加上了锁,并设置 owner 为当前线程
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
@Override // 是否持有独占锁
protected boolean isHeldExclusively() {
return getState() == 1;
}
public Condition newCondition() {
return new ConditionObject();
}
}
private MySync sync = new MySync();
@Override // 加锁(不成功会进入等待队列)
public void lock() {
sync.acquire(1);
}
@Override // 加锁,可打断
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override // 尝试加锁(一次)
public boolean tryLock() {
return sync.tryAcquire(1);
}
@Override // 尝试加锁,带超时
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
@Override // 解锁
public void unlock() {
sync.release(1);
}
@Override // 创建条件变量
public Condition newCondition() {
return sync.newCondition();
}
}
测试:
@Slf4j(topic = "c.TestAQS")
public class TestAQS {
public static void main(String[] args) {
MyLock lock = new MyLock();
new Thread(() -> {
lock.lock();
try {
log.debug("locking...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.debug("unlocking...");
lock.unlock();
}
},"t1").start();
new Thread(() -> {
lock.lock();
try {
log.debug("locking...");
} finally {
log.debug("unlocking...");
lock.unlock();
}
},"t2").start();
}
}
输出结果如下:
21:39:06 [t1] c.TestAQS - locking...
21:39:07 [t1] c.TestAQS - unlocking...
21:39:07 [t2] c.TestAQS - locking...
21:39:07 [t2] c.TestAQS - unlocking...
Process finished with exit code 0
不可重入测试:如果改为下面代码,会发现自己也会被挡住(只会打印一次 locking)
lock.lock();
log.debug("locking...");
lock.lock();
log.debug("locking...");
7.2.2.ReentrantLock 原理
7.2.2.1.非公平锁实现原理
7.2.2.1.1.加锁解锁流程
先从构造器开始看,默认为非公平锁实现。
public ReentrantLock() {
sync = new NonfairSync();
}
NonfairSync 继承自 AQS,没有竞争时:
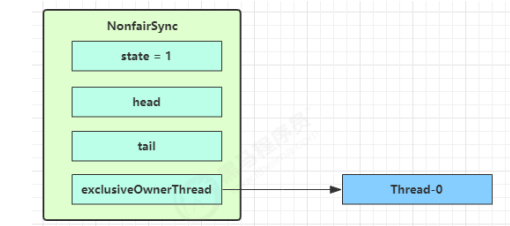
第一个竞争出现时:
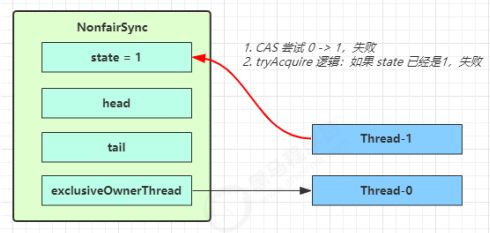
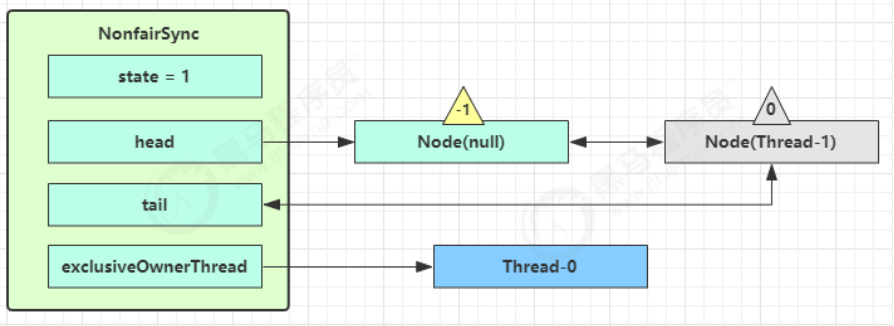
Thread-1 执行了
- CAS 尝试将 state 由 0 改为 1,结果失败;
- 进入 tryAcquire 逻辑,这时 state 已经是1,结果仍然失败;
- 接下来进入 addWaiter 逻辑,构造 Node 队列;
- 图中黄色三角表示该 Node 的 waitStatus 状态,其中 0 为默认正常状态;
- Node 的创建是懒惰的;
- 其中第一个 Node 称为 Dummy(哑元)或哨兵,用来占位,并不关联线程;
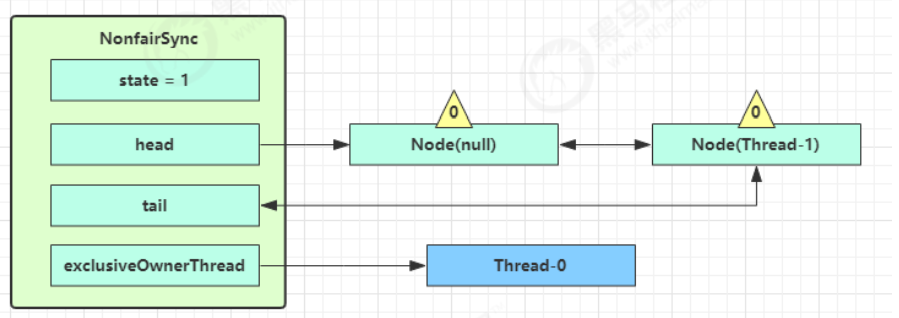
- shouldParkAfterFailedAcquire 执行完毕回到 acquireQueued ,再次 tryAcquire 尝试获取锁,当然这时 state 仍为 1,失败;
- 当再次进入 shouldParkAfterFailedAcquire 时,这时因为其前驱 node 的 waitStatus 已经是 -1,这次返回 true;
- 进入 parkAndCheckInterrupt, Thread-1 park(灰色表示);
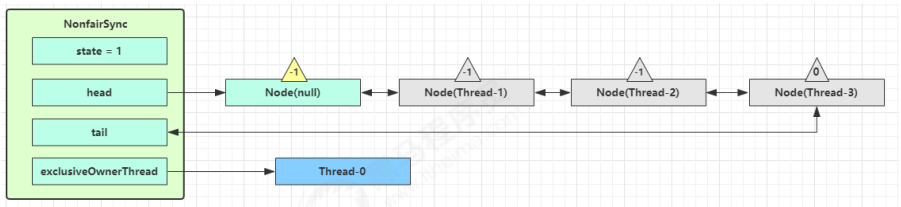
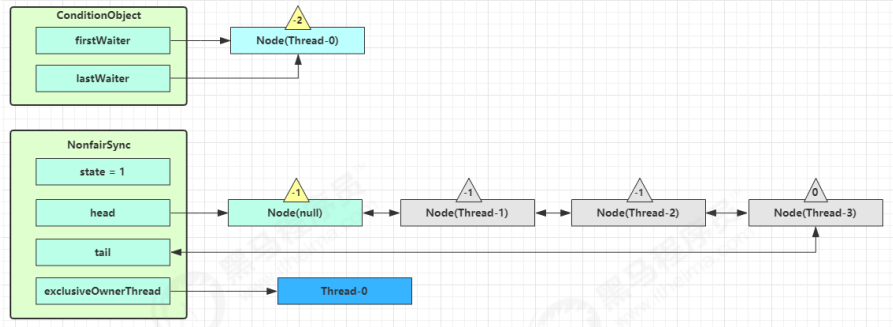
再次有多个线程经历上述过程竞争失败,变成这个样子:
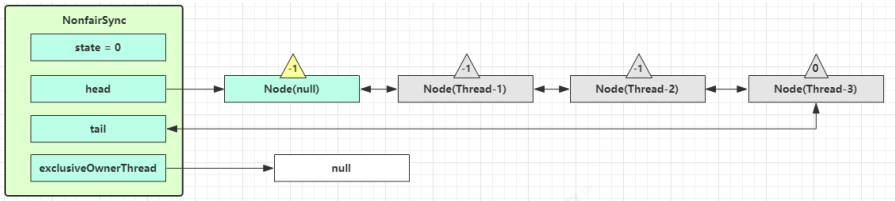
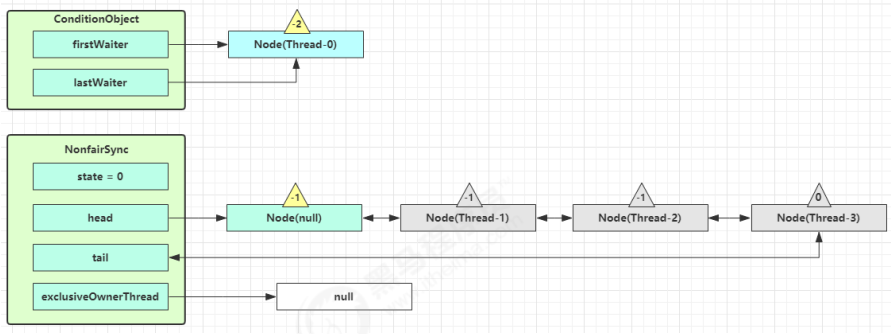
Thread-0 释放锁,进入 tryRelease 流程,如果成功:
- 设置 exclusiveOwnerThread 为 null;
- state = 0;
当前队列不为 null,并且 head 的 waitStatus = -1,进入 unparkSuccessor 流程。找到队列中离 head 最近的一个 Node(没取消的),unpark 恢复其运行,本例中即为 Thread-1,回到 Thread-1 的 acquireQueued 流程。
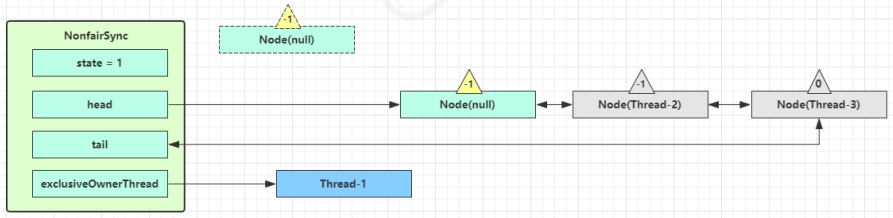
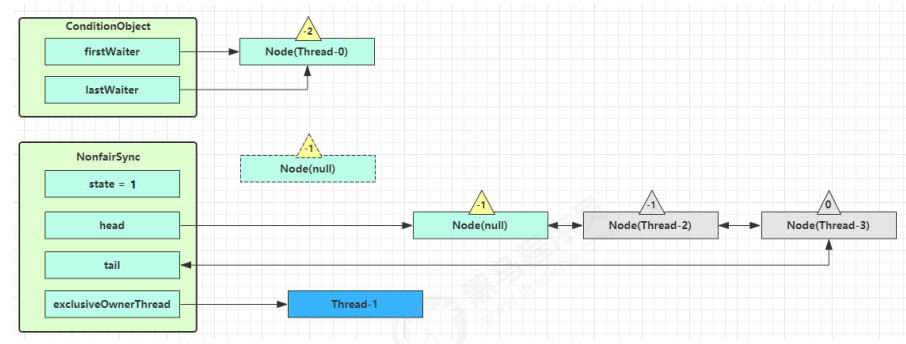
如果加锁成功(没有竞争),会设置:
- exclusiveOwnerThread 为 Thread-1,state = 1;
- head 指向刚刚 Thread-1 所在的 Node,该 Node 清空 Thread;
- 原本的 head 因为从链表断开,而可被垃圾回收;
如果这时候有其它线程来竞争(非公平的体现),例如这时有 Thread-4 来了:
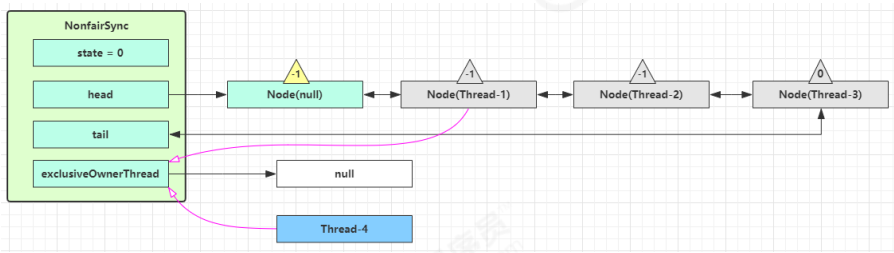
如果不巧又被 Thread-4 占了先:
- Thread-4 被设置为 exclusiveOwnerThread,state = 1;
- Thread-1 再次进入 acquireQueued 流程,获取锁失败,重新进入 park 阻塞;
7.2.2.1.2.加锁源码
// Sync 继承自 AQS
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
// 加锁实现
final void lock() {
// 首先用 cas 尝试(仅尝试一次)将 state 从 0 改为 1, 如果成功表示获得了独占锁
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
// 如果尝试失败,进入 ㈠
acquire(1);
}
// ㈠ AQS 继承过来的方法, 方便阅读, 放在此处
public final void acquire(int arg) {
// ㈡ tryAcquire
if (
!tryAcquire(arg) &&
// 当 tryAcquire 返回为 false 时, 先调用 addWaiter ㈣, 接着 acquireQueued ㈤
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
selfInterrupt();
}
}
// ㈡ 进入 ㈢
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
// ㈢ Sync 继承过来的方法, 方便阅读, 放在此处
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// 如果还没有获得锁
if (c == 0) {
// 尝试用 cas 获得, 这里体现了非公平性: 不去检查 AQS 队列
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 如果已经获得了锁, 线程还是当前线程, 表示发生了锁重入
else if (current == getExclusiveOwnerThread()) {
// state++
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
// 获取失败, 回到调用处
return false;
}
// ㈣ AQS 继承过来的方法, 方便阅读, 放在此处
private Node addWaiter(Node mode) {
// 将当前线程关联到一个 Node 对象上, 模式为独占模式
Node node = new Node(Thread.currentThread(), mode);
// 如果 tail 不为 null, cas 尝试将 Node 对象加入 AQS 队列尾部
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
// 双向链表
pred.next = node;
return node;
}
}
// 尝试将 Node 加入 AQS, 进入 ㈥
enq(node);
return node;
}
// ㈥ AQS 继承过来的方法, 方便阅读, 放在此处
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) {
// 还没有, 设置 head 为哨兵节点(不对应线程,状态为 0)
if (compareAndSetHead(new Node())) {
tail = head;
}
} else {
// cas 尝试将 Node 对象加入 AQS 队列尾部
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
// ㈤ AQS 继承过来的方法, 方便阅读, 放在此处
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
// 上一个节点是 head, 表示轮到自己(当前线程对应的 node)了, 尝试获取
if (p == head && tryAcquire(arg)) {
// 获取成功, 设置自己(当前线程对应的 node)为 head
setHead(node);
// 上一个节点 help GC
p.next = null;
failed = false;
// 返回中断标记 false
return interrupted;
}
if (
// 判断是否应当 park, 进入 ㈦
shouldParkAfterFailedAcquire(p, node) &&
// park 等待, 此时 Node 的状态被置为 Node.SIGNAL ㈧
parkAndCheckInterrupt()
) {
interrupted = true;
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
// ㈦ AQS 继承过来的方法, 方便阅读, 放在此处
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取上一个节点的状态
int ws = pred.waitStatus;
if (ws == Node.SIGNAL) {
// 上一个节点都在阻塞, 那么自己也阻塞好了
return true;
}
// > 0 表示取消状态
if (ws > 0) {
// 上一个节点取消, 那么重构删除前面所有取消的节点, 返回到外层循环重试
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 这次还没有阻塞
// 但下次如果重试不成功, 则需要阻塞,这时需要设置上一个节点状态为 Node.SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
// ㈧ 阻塞当前线程
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
}
注意:是否需要 unpark 是由当前节点的前驱节点的 waitStatus == Node.SIGNAL 来决定,而不是本节点的 waitStatus 决定。
7.2.2.1.3.解锁源码
// Sync 继承自 AQS
static final class NonfairSync extends Sync {
// 解锁实现
public void unlock() {
sync.release(1);
}
// AQS 继承过来的方法, 方便阅读, 放在此处
public final boolean release(int arg) {
// 尝试释放锁, 进入 ㈠
if (tryRelease(arg)) {
// 队列头节点 unpark
Node h = head;
if (
// 队列不为 null
h != null &&
// waitStatus == Node.SIGNAL 才需要 unpark
h.waitStatus != 0
) {
// unpark AQS 中等待的线程, 进入 ㈡
unparkSuccessor(h);
}
return true;
}
return false;
}
// ㈠ Sync 继承过来的方法, 方便阅读, 放在此处
protected final boolean tryRelease(int releases) {
// state--
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 支持锁重入, 只有 state 减为 0, 才释放成功
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
// ㈡ AQS 继承过来的方法, 方便阅读, 放在此处
private void unparkSuccessor(Node node) {
// 如果状态为 Node.SIGNAL 尝试重置状态为 0
// 不成功也可以
int ws = node.waitStatus;
if (ws < 0) {
compareAndSetWaitStatus(node, ws, 0);
}
// 找到需要 unpark 的节点, 但本节点从 AQS 队列中脱离, 是由唤醒节点完成的
Node s = node.next;
// 不考虑已取消的节点, 从 AQS 队列从后至前找到队列最前面需要 unpark 的节点
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
}
7.2.2.2.可重入原理
static final class NonfairSync extends Sync {
// ...
// Sync 继承过来的方法, 方便阅读, 放在此处
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 如果已经获得了锁, 线程还是当前线程, 表示发生了锁重入
else if (current == getExclusiveOwnerThread()) {
// state++
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// Sync 继承过来的方法, 方便阅读, 放在此处
protected final boolean tryRelease(int releases) {
// state--
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 支持锁重入, 只有 state 减为 0, 才释放成功
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
}
7.2.2.3.可打断原理
7.2.2.3.1.不可打断模式
在此模式下,即使它被打断,仍会驻留在 AQS 队列中,一直要等到获得锁后方能得知自己被打断了。
// Sync 继承自 AQS
static final class NonfairSync extends Sync {
// ...
private final boolean parkAndCheckInterrupt() {
// 如果打断标记已经是 true, 则 park 会失效
LockSupport.park(this);
// interrupted 会清除打断标记
return Thread.interrupted();
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (; ; ) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null;
failed = false;
// 还是需要获得锁后, 才能返回打断状态
return interrupted;
}
if (
shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()
) {
// 如果是因为 interrupt 被唤醒, 返回打断状态为 true
interrupted = true;
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
// 如果打断状态为 true
selfInterrupt();
}
}
static void selfInterrupt() {
// 重新产生一次中断
Thread.currentThread().interrupt();
}
}
7.2.2.3.2.可打断模式
static final class NonfairSync extends Sync {
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 如果没有获得到锁, 进入 ㈠
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
// ㈠ 可打断的获取锁流程
private void doAcquireInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (; ; ) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) {
// 在 park 过程中如果被 interrupt 会进入此
// 这时候抛出异常, 而不会再次进入 for (;;)
throw new InterruptedException();
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
}
7.2.2.4.公平锁实现原理
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
// AQS 继承过来的方法, 方便阅读, 放在此处
public final void acquire(int arg) {
if (
!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
selfInterrupt();
}
}
// 与非公平锁主要区别在于 tryAcquire 方法的实现
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 先检查 AQS 队列中是否有前驱节点, 没有才去竞争
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// ㈠ AQS 继承过来的方法, 方便阅读, 放在此处
public final boolean hasQueuedPredecessors() {
Node t = tail;
Node h = head;
Node s;
// h != t 时表示队列中有 Node
return h != t &&
(
// (s = h.next) == null 表示队列中还有没有老二
(s = h.next) == null ||
// 或者队列中老二线程不是此线程
s.thread != Thread.currentThread()
);
}
}
7.2.2.5.条件变量实现原理
每个条件变量其实就对应着一个等待队列,其实现类是 ConditionObject。
7.2.2.5.1.await 流程
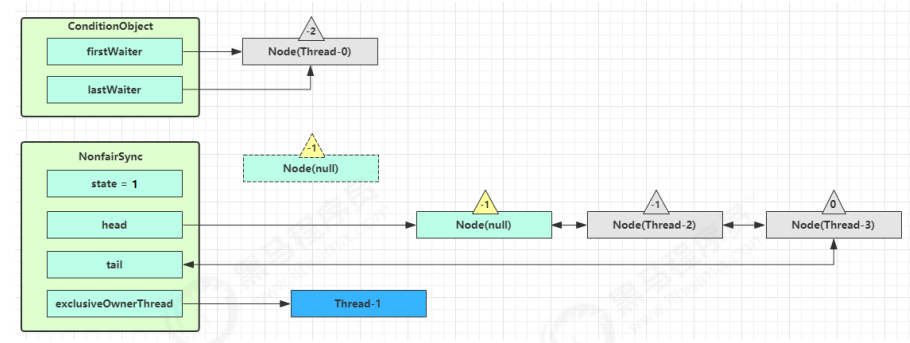
开始 Thread-0 持有锁,调用 await,进入 ConditionObject 的 addConditionWaiter 流程,创建新的 Node 状态为 -2 (Node.CONDITION),关联 Thread-0,加入等待队列尾部。
接下来进入 AQS 的 fullyRelease 流程,释放同步器上的锁。
unpark AQS 队列中的下一个节点,竞争锁,假设没有其他竞争线程,那么 Thread-1 竞争成功。
park 阻塞 Thread-0
7.2.2.5.2.signal 流程
假设 Thread-1 要来唤醒 Thread-0。
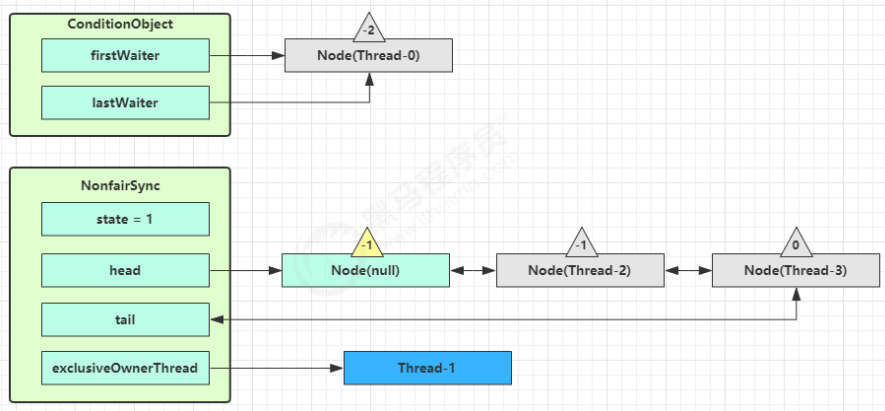
进入 ConditionObject 的 doSignal 流程,取得等待队列中第一个 Node,即 Thread-0 所在 Node。
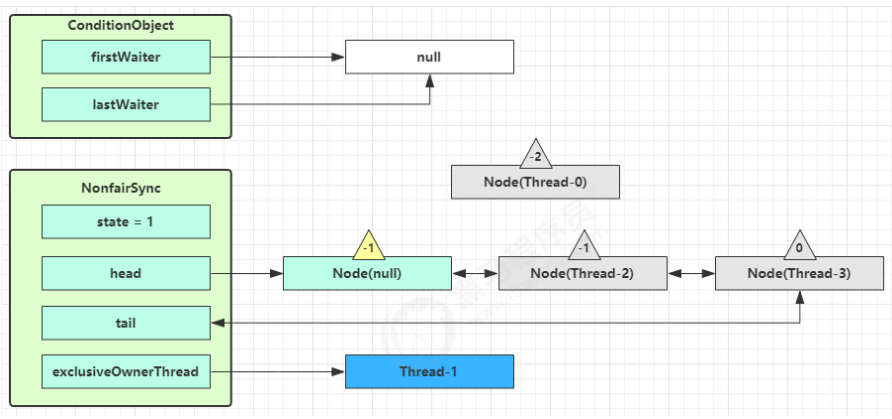
执行 transferForSignal 流程,将该 Node 加入 AQS 队列尾部,将 Thread-0 的 waitStatus 改为 0,Thread-3 的 waitStatus 改为 -1。
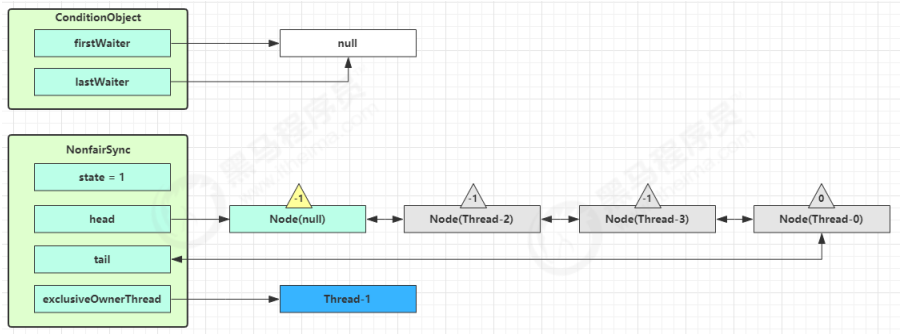
Thread-1 释放锁,进入 unlock 流程,略。
7.2.2.5.3.源码
public class ConditionObject implements Condition, java.io.Serializable {
private static final long serialVersionUID = 1173984872572414699L;
// 第一个等待节点
private transient Node firstWaiter;
// 最后一个等待节点
private transient Node lastWaiter;
public ConditionObject() {
}
// ㈠ 添加一个 Node 至等待队列
private Node addConditionWaiter() {
Node t = lastWaiter;
// 所有已取消的 Node 从队列链表删除, 见 ㈡
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// 创建一个关联当前线程的新 Node, 添加至队列尾部
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
// 唤醒 - 将没取消的第一个节点转移至 AQS 队列
private void doSignal(Node first) {
do {
// 已经是尾节点了
if ((firstWaiter = first.nextWaiter) == null) {
lastWaiter = null;
}
first.nextWaiter = null;
} while (
// 将等待队列中的 Node 转移至 AQS 队列, 不成功且还有节点则继续循环 ㈢
!transferForSignal(first) &&
// 队列还有节点
(first = firstWaiter) != null
);
}
// 外部类方法, 方便阅读, 放在此处
// ㈢ 如果节点状态是取消, 返回 false 表示转移失败, 否则转移成功
final boolean transferForSignal(Node node) {
// 如果状态已经不是 Node.CONDITION, 说明被取消了
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
// 加入 AQS 队列尾部
Node p = enq(node);
int ws = p.waitStatus;
if (
// 上一个节点被取消
ws > 0 ||
// 上一个节点不能设置状态为 Node.SIGNAL
!compareAndSetWaitStatus(p, ws, Node.SIGNAL)
) {
// unpark 取消阻塞, 让线程重新同步状态
LockSupport.unpark(node.thread);
}
return true;
}
// 全部唤醒 - 等待队列的所有节点转移至 AQS 队列
private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
// ㈡
private void unlinkCancelledWaiters() {
// ...
}
// 唤醒 - 必须持有锁才能唤醒, 因此 doSignal 内无需考虑加锁
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
// 全部唤醒 - 必须持有锁才能唤醒, 因此 doSignalAll 内无需考虑加锁
public final void signalAll() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignalAll(first);
}
// 不可打断等待 - 直到被唤醒
public final void awaitUninterruptibly() {
// 添加一个 Node 至等待队列, 见 ㈠
Node node = addConditionWaiter();
// 释放节点持有的锁, 见 ㈣
int savedState = fullyRelease(node);
boolean interrupted = false;
// 如果该节点还没有转移至 AQS 队列, 阻塞
while (!isOnSyncQueue(node)) {
// park 阻塞
LockSupport.park(this);
// 如果被打断, 仅设置打断状态
if (Thread.interrupted())
interrupted = true;
}
// 唤醒后, 尝试竞争锁, 如果失败进入 AQS 队列
if (acquireQueued(node, savedState) || interrupted)
selfInterrupt();
}
// 外部类方法, 方便阅读, 放在此处
// ㈣ 因为某线程可能重入,需要将 state 全部释放
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
// 打断模式 - 在退出等待时重新设置打断状态
private static final int REINTERRUPT = 1;
// 打断模式 - 在退出等待时抛出异常
private static final int THROW_IE = -1;
// 判断打断模式
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
// ㈤ 应用打断模式
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt();
}
// 等待 - 直到被唤醒或打断
public final void await() throws InterruptedException {
if (Thread.interrupted()) {
throw new InterruptedException();
}
// 添加一个 Node 至等待队列, 见 ㈠
Node node = addConditionWaiter();
// 释放节点持有的锁
int savedState = fullyRelease(node);
int interruptMode = 0;
// 如果该节点还没有转移至 AQS 队列, 阻塞
while (!isOnSyncQueue(node)) {
// park 阻塞
LockSupport.park(this);
// 如果被打断, 退出等待队列
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// 退出等待队列后, 还需要获得 AQS 队列的锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// 所有已取消的 Node 从队列链表删除, 见 ㈡
if (node.nextWaiter != null)
unlinkCancelledWaiters();
// 应用打断模式, 见 ㈤
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
// 等待 - 直到被唤醒或打断或超时
public final long awaitNanos(long nanosTimeout) throws InterruptedException {
if (Thread.interrupted()) {
throw new InterruptedException();
}
// 添加一个 Node 至等待队列, 见 ㈠
Node node = addConditionWaiter();
// 释放节点持有的锁
int savedState = fullyRelease(node);
// 获得最后期限
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
// 如果该节点还没有转移至 AQS 队列, 阻塞
while (!isOnSyncQueue(node)) {
// 已超时, 退出等待队列
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
// park 阻塞一定时间, spinForTimeoutThreshold 为 1000 ns
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
// 如果被打断, 退出等待队列
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
// 退出等待队列后, 还需要获得 AQS 队列的锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// 所有已取消的 Node 从队列链表删除, 见 ㈡
if (node.nextWaiter != null)
unlinkCancelledWaiters();
// 应用打断模式, 见 ㈤
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}
// 等待 - 直到被唤醒或打断或超时, 逻辑类似于 awaitNanos
public final boolean awaitUntil(Date deadline) throws InterruptedException {
// ...
}
// 等待 - 直到被唤醒或打断或超时, 逻辑类似于 awaitNanos
public final boolean await(long time, TimeUnit unit) throws InterruptedException {
// ...
}
// 工具方法 省略 ...
}
7.2.3.读写锁
7.2.3.1.ReentrantReadWriteLock
(1)当读操作远远高于写操作时,这时候使用 读写锁 让 读-读 可以并发,提高性能。类似于数据库中的
select ... from ... lock in share mode
(2)提供一个 数据容器类内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法。
@Slf4j(topic = "c.DataContainer")
class DataContainer {
private Object data;
private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
private ReentrantReadWriteLock.ReadLock r = rw.readLock();
private ReentrantReadWriteLock.WriteLock w = rw.writeLock();
@SneakyThrows
public Object read() {
log.debug("获取读锁...");
r.lock();
try {
log.debug("读取");
Thread.sleep(1000);
return data;
} finally {
log.debug("释放读锁...");
r.unlock();
}
}
@SneakyThrows
public void write() throws InterruptedException {
log.debug("获取写锁...");
w.lock();
try {
log.debug("写入");
Thread.sleep(1000);
} finally {
log.debug("释放写锁...");
w.unlock();
}
}
}
测试读锁-读锁可以并发
public static void main(String[] args) throws InterruptedException {
DataContainer dataContainer = new DataContainer();
new Thread(() -> {
dataContainer.read();
}, "t1").start();
new Thread(() -> {
dataContainer.read();
}, "t2").start();
}
输出结果如下,从这里可以看到 t1 锁定期间,t2 的读操作不受影响。
10:52:34 [t1] c.DataContainer - 获取读锁...
10:52:34 [t2] c.DataContainer - 获取读锁...
10:52:34 [t2] c.DataContainer - 读取
10:52:34 [t1] c.DataContainer - 读取
10:52:35 [t1] c.DataContainer - 释放读锁...
10:52:35 [t2] c.DataContainer - 释放读锁...
测试读锁-写锁相互阻塞。
10:58:00 [t1] c.DataContainer - 获取读锁...
10:58:00 [t1] c.DataContainer - 读取
10:58:01 [t2] c.DataContainer - 获取写锁...
10:58:01 [t1] c.DataContainer - 释放读锁...
10:58:01 [t2] c.DataContainer - 写入
10:58:02 [t2] c.DataContainer - 释放写锁...
写锁-写锁也是相互阻塞的,这里就不测试了。
注意事项
- 读锁不支持条件变量;
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待;
r.lock();
try {
// ...
w.lock();
try {
// ...
} finally{
w.unlock();
}
} finally{
r.unlock();
}
- 重入时降级支持:即持有写锁的情况下去获取读锁;
class CachedData {
Object data;
// 是否有效,如果失效,需要重新计算 data
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// 获取写锁前必须释放读锁
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// 判断是否有其它线程已经获取了写锁、更新了缓存, 避免重复更新
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 降级为读锁, 释放写锁, 这样能够让其它线程读取缓存
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock();
}
}
// 自己用完数据, 释放读锁
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
7.2.3.2.StampedLock
(1)该类自 JDK 8 加入,是为了进一步优化读性能,它的特点是在使用读锁、写锁时都必须配合【戳】使用。
//加解读锁
long stamp = lock.readLock();
lock.unlockRead(stamp);
//加解写锁
long stamp = lock.writeLock();
lock.unlockWrite(stamp);
(2)乐观读,StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
long stamp = lock.tryOptimisticRead();
// 验戳
if(!lock.validate(stamp)){
// 锁升级
}
(3)提供一个数据容器类,内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法。
@Slf4j(topic = "c.DataContainerStamped")
class DataContainerStamped {
private int data;
private final StampedLock lock = new StampedLock();
public DataContainerStamped(int data) {
this.data = data;
}
@SneakyThrows
public int read(int readTime) {
long stamp = lock.tryOptimisticRead();
log.debug("optimistic read locking...{}", stamp);
Thread.sleep(readTime);
if (lock.validate(stamp)) {
log.debug("read finish...{}, data:{}", stamp, data);
return data;
}
// 锁升级 - 读锁
log.debug("updating to read lock... {}", stamp);
try {
stamp = lock.readLock();
log.debug("read lock {}", stamp);
Thread.sleep(readTime);
log.debug("read finish...{}, data:{}", stamp, data);
return data;
} finally {
log.debug("read unlock {}", stamp);
lock.unlockRead(stamp);
}
}
public void write(int newData) throws InterruptedException {
long stamp = lock.writeLock();
log.debug("write lock {}", stamp);
try {
Thread.sleep(2000);
this.data = newData;
} finally {
log.debug("write unlock {}", stamp);
lock.unlockWrite(stamp);
}
}
}
测试读-读可以优化。
public static void main(String[] args) throws InterruptedException {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1000);
}, "t1").start();
Thread.sleep(500);
new Thread(() -> {
dataContainer.read(0);
}, "t2").start();
}
输出结果如下,可以看到实际没有加读锁。
17:31:47 [t1] c.DataContainerStamped - optimistic read locking...256
17:31:47 [t2] c.DataContainerStamped - optimistic read locking...256
17:31:47 [t2] c.DataContainerStamped - read finish...256, data:1
17:31:48 [t1] c.DataContainerStamped - read finish...256, data:1
Process finished with exit code 0
测试读-写时优化读补加读锁。
public static void main(String[] args) throws InterruptedException {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1000);
}, "t1").start();
Thread.sleep(500);
new Thread(() -> {
try {
dataContainer.write(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
}
输出结果如下:
17:34:18 [t1] c.DataContainerStamped - optimistic read locking...256
17:34:19 [t2] c.DataContainerStamped - write lock 384
17:34:19 [t1] c.DataContainerStamped - updating to read lock... 256
17:34:21 [t2] c.DataContainerStamped - write unlock 384
17:34:21 [t1] c.DataContainerStamped - read lock 513
17:34:22 [t1] c.DataContainerStamped - read finish...513, data:1000
17:34:22 [t1] c.DataContainerStamped - read unlock 513
Process finished with exit code 0
注意:
StampedLock 不支持条件变量;
StampedLock 不支持可重入;
7.2.4.Semaphore
7.2.4.1.基本使用
Semaphore 即信号量,用来限制能同时访问共享资源的线程上限。
package cn.itcast.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Semaphore;
@Slf4j(topic = "c.TestSemaphore")
public class TestSemaphore {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("end...");
semaphore.release();
}).start();
}
}
}
输出结果如下:
10:00:51 [Thread-2] c.TestSemaphore - running...
10:00:51 [Thread-1] c.TestSemaphore - running...
10:00:51 [Thread-0] c.TestSemaphore - running...
10:00:52 [Thread-1] c.TestSemaphore - end...
10:00:52 [Thread-0] c.TestSemaphore - end...
10:00:52 [Thread-2] c.TestSemaphore - end...
10:00:52 [Thread-3] c.TestSemaphore - running...
10:00:52 [Thread-4] c.TestSemaphore - running...
10:00:52 [Thread-5] c.TestSemaphore - running...
10:00:53 [Thread-5] c.TestSemaphore - end...
10:00:53 [Thread-3] c.TestSemaphore - end...
10:00:53 [Thread-4] c.TestSemaphore - end...
10:00:53 [Thread-6] c.TestSemaphore - running...
10:00:53 [Thread-7] c.TestSemaphore - running...
10:00:53 [Thread-8] c.TestSemaphore - running...
10:00:54 [Thread-6] c.TestSemaphore - end...
10:00:54 [Thread-8] c.TestSemaphore - end...
10:00:54 [Thread-7] c.TestSemaphore - end...
10:00:54 [Thread-9] c.TestSemaphore - running...
10:00:55 [Thread-9] c.TestSemaphore - end...
Process finished with exit code 0
7.2.4.2.应用
- 使用 Semaphore 限流,在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可,当然它只适合限制单机线程数量,并且仅是限制线程数,而不是限制资源数(例如连接数,请对比 Tomcat LimitLatch 的实现);
- 用Semaphore实现简单连接池,对比『享元模式』下的实现(用 wait notify),性能和可读性显然更好,注意下面的实现中线程数和数据库连接数是相等的;
// 默认情况下使⽤⾮公平
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
@Slf4j(topic = "c.Pool")
class Pool {
// 1. 连接池大小
private final int poolSize;
// 2. 连接对象数组
private Connection[] connections;
// 3. 连接状态数组 0 表示空闲, 1 表示繁忙
private AtomicIntegerArray states;
private Semaphore semaphore;
// 4. 构造方法初始化
public Pool(int poolSize) {
this.poolSize = poolSize;
// 让许可数与资源数一致
this.semaphore = new Semaphore(poolSize);
this.connections = new Connection[poolSize];
this.states = new AtomicIntegerArray(new int[poolSize]);
for (int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection("连接" + (i+1));
}
}
// 5. 借连接
public Connection borrow() {// t1, t2, t3
// 获取许可
try {
// 没有许可的线程,在此等待
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < poolSize; i++) {
// 获取空闲连接
if(states.get(i) == 0) {
if (states.compareAndSet(i, 0, 1)) {
log.debug("borrow {}", connections[i]);
return connections[i];
}
}
}
// 不会执行到这里
return null;
}
// 6. 归还连接
public void free(Connection conn) {
for (int i = 0; i < poolSize; i++) {
if (connections[i] == conn) {
states.set(i, 0);
log.debug("free {}", conn);
semaphore.release();
break;
}
}
}
}
7.2.4.3.原理——加锁解锁流程
Semaphore 有点像一个停车场,permits 就好像停车位数量,当线程获得了 permits 就像是获得了停车位,然后停车场显示空余车位减一。
刚开始,permits (state)为 3,这时 5 个线程来获取资源:
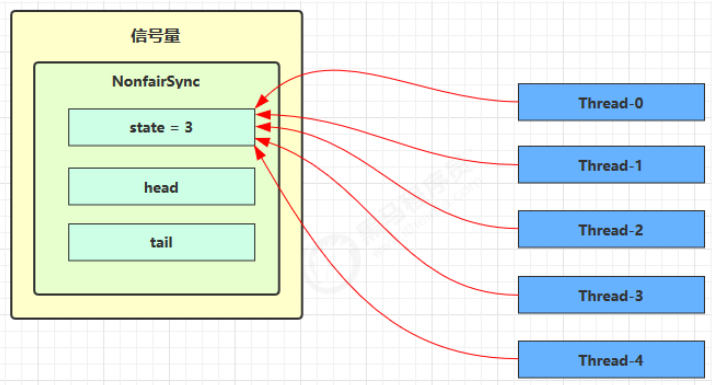
假设其中 Thread-1,Thread-2,Thread-4 cas 竞争成功,而 Thread-0 和 Thread-3 竞争失败,进入 AQS 队列 park 阻塞:
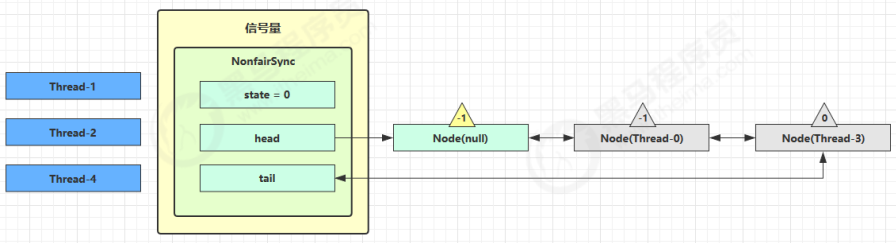
这时 Thread-4 释放了 permits,状态如下:
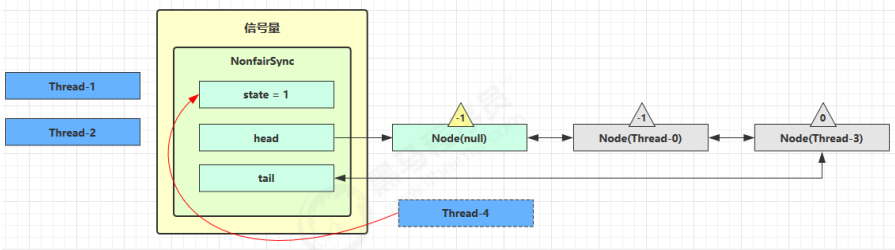
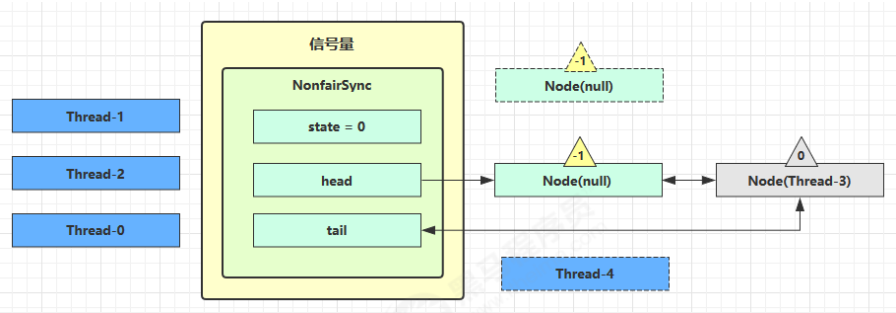
接下来 Thread-0 竞争成功,permits 再次设置为 0,设置自己为 head 节点,断开原来的 head 节点,unpark 接下来的 Thread-3 节点,但由于 permits 是 0,因此 Thread-3 在尝试不成功后再次进入 park 状态:
7.2.5.CountdownLatch
7.2.5.1.概述
(1)先来解读⼀下 CountDownLatch 这个类名字的意义。CountDown 代表计数递减,Latch是“门闩”的意思,也有人把它称为“屏障”。而CountDownLatch 这个类的作用也很贴合这个名字的意义,假设某个线程在执行任务之前,需要等待其它线程完成 ⼀些前置任务,必须等所有的前置任务都完成,才能开始执行本线程的任务。
(2)CountDownLatch 类中的方法如下:
// 构造⽅法:
public CountDownLatch(int count);
// 等待
public void await();
// 超时等待
public boolean await(long timeout, TimeUnit unit);
// count - 1
public void countDown();
// 获取当前还有多少count
public long getCount();
7.2.5.2.案例
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
log.debug("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
log.debug("waiting...");
latch.await();
log.debug("wait end...");
}
输出结果如下:
11:01:14 [main] c.TestCountdownLatch - waiting...
11:01:14 [Thread-1] c.TestCountdownLatch - begin...
11:01:14 [Thread-0] c.TestCountdownLatch - begin...
11:01:14 [Thread-2] c.TestCountdownLatch - begin...
11:01:15 [Thread-0] c.TestCountdownLatch - end...2
11:01:16 [Thread-1] c.TestCountdownLatch - end...1
11:01:17 [Thread-2] c.TestCountdownLatch - end...0
11:01:17 [main] c.TestCountdownLatch - wait end...
Process finished with exit code 0
可以配合线程池使用,改进如下:
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
ExecutorService service = Executors.newFixedThreadPool(4);
service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(()->{
try {
log.debug("waiting...");
latch.await();
log.debug("wait end...");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
输出结果如下:
11:04:05 [pool-1-thread-1] c.TestCountdownLatch - begin...
11:04:05 [pool-1-thread-3] c.TestCountdownLatch - begin...
11:04:05 [pool-1-thread-4] c.TestCountdownLatch - waiting...
11:04:05 [pool-1-thread-2] c.TestCountdownLatch - begin...
11:04:06 [pool-1-thread-1] c.TestCountdownLatch - end...2
11:04:07 [pool-1-thread-2] c.TestCountdownLatch - end...1
11:04:07 [pool-1-thread-3] c.TestCountdownLatch - end...0
11:04:07 [pool-1-thread-4] c.TestCountdownLatch - wait end...
7.2.5.3.应用之同步等待多线程准备完毕
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(10);
ExecutorService service = Executors.newFixedThreadPool(10);
Random random = new Random();
String[] all = new String[10];
for (int i = 0; i < 10; i++) {
int tmp = i;
service.submit(() -> {
for (int j = 0; j <= 100; j++) {
try {
Thread.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
all[tmp] = j + "%";
System.out.print("\r" + Arrays.toString(all));
}
latch.countDown();
});
}
latch.await();
System.out.println("\n游戏开始");
service.shutdown();
}



7.2.6.CyclicBarrier
CyclicBarrirer 从名字上来理解是“循环的屏障”的意思。前面提到了 CountDownLatch ⼀旦计数值 count 被降为 0 后,就不能再重新设置了,它只能起 ⼀次“屏障”的作用。而 CyclicBarrier 拥有 CountDownLatch 的所有功能,还可以使用 reset() 方法重置屏障。
package cn.itcast.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.TestCycleBarrier")
public class TestCycleBarrier {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(2);
CyclicBarrier barrier = new CyclicBarrier(2, () -> {
log.debug("task1, task2 finish...");
});
for (int i = 0; i < 3; i++) {
service.submit(() -> {
log.debug("task1 begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
});
service.submit(() -> {
log.debug("task2 begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
});
}
service.shutdown();
}
}
输出结果如下:
14:15:48 [pool-1-thread-1] c.TestCycleBarrier - task1 begin...
14:15:48 [pool-1-thread-2] c.TestCycleBarrier - task2 begin...
14:15:49 [pool-1-thread-2] c.TestCycleBarrier - task1, task2 finish...
14:15:49 [pool-1-thread-1] c.TestCycleBarrier - task1 begin...
14:15:49 [pool-1-thread-2] c.TestCycleBarrier - task2 begin...
14:15:50 [pool-1-thread-1] c.TestCycleBarrier - task1, task2 finish...
14:15:50 [pool-1-thread-1] c.TestCycleBarrier - task1 begin...
14:15:50 [pool-1-thread-2] c.TestCycleBarrier - task2 begin...
14:15:51 [pool-1-thread-1] c.TestCycleBarrier - task1, task2 finish...
Process finished with exit code 0
注意:CyclicBarrier 与 CountDownLatch 的主要区别在于 CyclicBarrier 是可以重用的。
7.2.7.线程安全集合类概述

(1)线程安全集合类可以分为三大类:
- 遗留的线程安全集合如 Hashtable,Vector;
- 使用 Collections 装饰的线程安全集合,如:
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedSortedSet
- java.util.concurrent.*
(2)重点介绍 java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent:
- Blocking 大部分实现基于锁,并提供用来阻塞的方法;
- CopyOnWrite 之类容器修改开销相对较重;
- Concurrent 类型的容器;
- 内部很多操作使用 cas 优化,一般可以提供较高吞吐量;
- 弱一致性;
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的;
- 求大小弱一致性,size 操作未必是 100% 准确;
- 读取弱一致性;
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出 ConcurrentModificationException,不再继续遍历。
7.2.8.ConcurrentHashMap
练习:单词计数
(1)生成测试数据
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
public static void main(String[] args) {
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("tmp/" + (i+1) + ".txt")))) {
String collect = list.subList(i * count, (i + 1) * count).stream()
.collect(Collectors.joining("\n"));
out.print(collect);
} catch (IOException e) {
}
}
}
(2)模版代码,模版代码中封装了多线程读取文件的代码。
private static <V> void demo(Supplier<Map<String, V>> supplier, BiConsumer<Map<String, V>, List<String>> consumer) {
Map<String, V> counterMap = supplier.get();
// key value
// a 200
// b 200
List<Thread> ts = new ArrayList<>();
for (int i = 1; i <= 26; i++) {
int idx = i;
Thread thread = new Thread(() -> {
List<String> words = readFromFile(idx);
consumer.accept(counterMap, words);
});
ts.add(thread);
}
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counterMap);
}
public static List<String> readFromFile(int i) {
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("tmp/" + i + ".txt")))) {
while (true) {
String word = in.readLine();
if (word == null) {
break;
}
words.add(word);
}
return words;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
我们要做的是实现两个参数:
- 一是提供一个 map 集合,用来存放每个单词的计数结果,key 为单词,value 为计数;
- 二是提供一组操作,保证计数的安全性,会传递 map 集合以及 单词 List;
正确结果输出应该是每个单词出现 200 次:
{a=200, b=200, c=200, d=200, e=200, f=200, g=200, h=200, i=200, j=200, k=200, l=200, m=200,
n=200, o=200, p=200, q=200, r=200, s=200, t=200, u=200, v=200, w=200, x=200, y=200, z=200}
下面的实现为:
demo(
// 创建 map 集合
// 创建 ConcurrentHashMap 对不对?
() -> new HashMap<String, Integer>(),
// 进行计数
(map, words) -> {
for (String word : words) {
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);
}
}
);
有没有问题?请改进:
参考解答1:
demo(
() -> new ConcurrentHashMap<String, LongAdder>(),
(map, words) -> {
for (String word : words) {
// 注意不能使用 putIfAbsent,此方法返回的是上一次的 value,首次调用返回 null
map.computeIfAbsent(word, (key) -> new LongAdder()).increment();
}
}
);
参考解答2:
demo(
() -> new ConcurrentHashMap<String, Integer>(),
(map, words) -> {
for (String word : words) {
// 函数式编程,无需原子变量
map.merge(word, 1, Integer::sum);
}
}
);
7.2.9.BlockingQueue
7.2.10.ConcurrentLinkedQueue
(1)ConcurrentLinkedQueue 的设计与 LinkedBlockingQueue 非常像,也是:
- 两把【锁】,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行;
- dummy 节点的引入让两把【锁】将来锁住的是不同对象,避免竞争;
- 只是这【锁】使用了 cas 来实现;
(2)事实上,ConcurrentLinkedQueue 应用还是非常广泛的,例如之前讲的 Tomcat 的 Connector 结构时,Acceptor 作为生产者向 Poller 消费者传递事件信息时,正是采用了 ConcurrentLinkedQueue 将 SocketChannel 给 Poller 使用。
7.2.11.11.CopyOnWriteArrayList
(1)CopyOnWriteArraySet 是它的马甲 底层实现采用了 写入时拷贝 的思想,增删改操作会将底层数组拷贝一份,更改操作在新数组上执行,这时不影响其它线程的并发读,读写分离。 以新增为例:
public boolean add(E e) {
synchronized (lock) {
// 获取旧的数组
Object[] es = getArray();
int len = es.length;
// 拷贝新的数组(这里是比较耗时的操作,但不影响其它读线程)
es = Arrays.copyOf(es, len + 1);
// 添加新元素
es[len] = e;
// 替换旧的数组
setArray(es);
return true;
}
}
注意:这里的源码版本是 Java 11,在 Java 1.8 中使用的是可重入锁而不是 synchronized。
其它读操作并未加锁,适合『读多写少』的应用场景,例如:
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (Object x : getArray()) {
@SuppressWarnings("unchecked") E e = (E) x;
action.accept(e);
}
}
(2)get 弱一致性
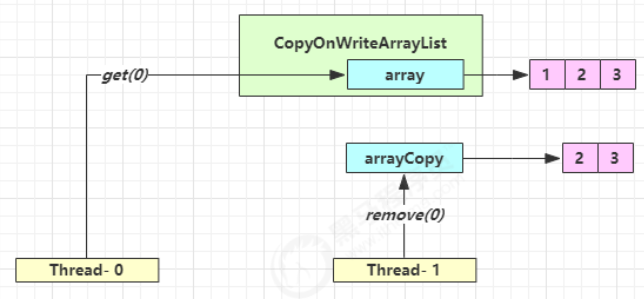
| 时间点 | 操作 |
|---|---|
| 1 | Thread-0 getArray() |
| 2 | Thread-1 getArray() |
| 3 | Thread-1 setArray(arrayCopy) |
| 4 | Thread-0 array[index] |
不容易测试,但问题确实存在
(3)迭代器弱一致性
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> iter = list.iterator();
new Thread(() -> {
list.remove(0);
System.out.println(list);
}).start();
Thread.sleep(1000);
while (iter.hasNext()) {
System.out.println(iter.next());
}
不要觉得弱一致性就不好:
① 数据库的 MVCC 都是弱一致性的表现;
② 并发高和一致性是矛盾的,需要权衡;