一、介绍
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
github地址
详细文档
操作手册
支持数据框架如下:
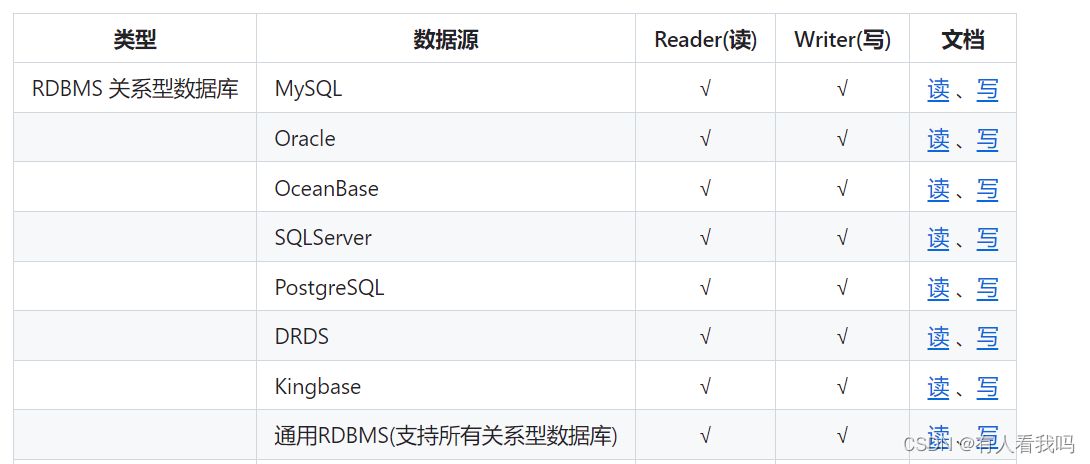
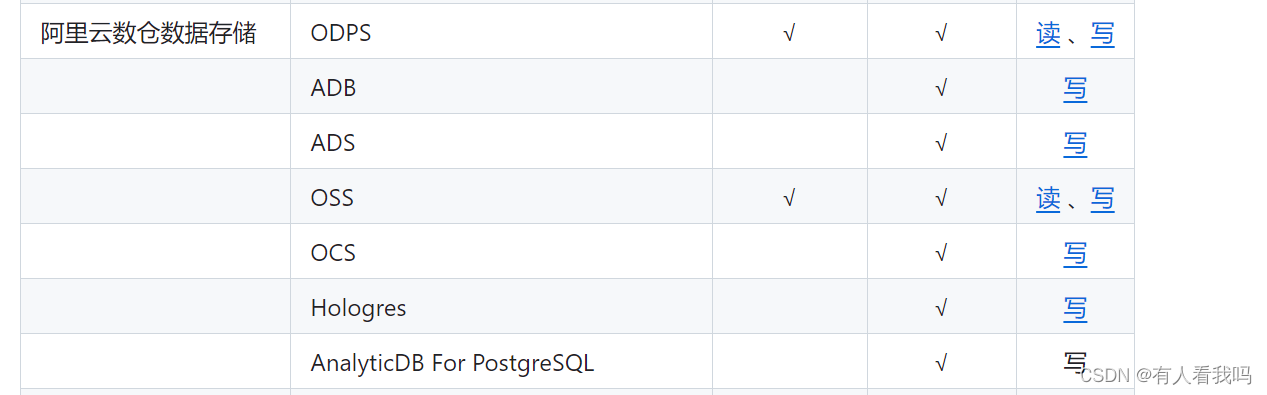
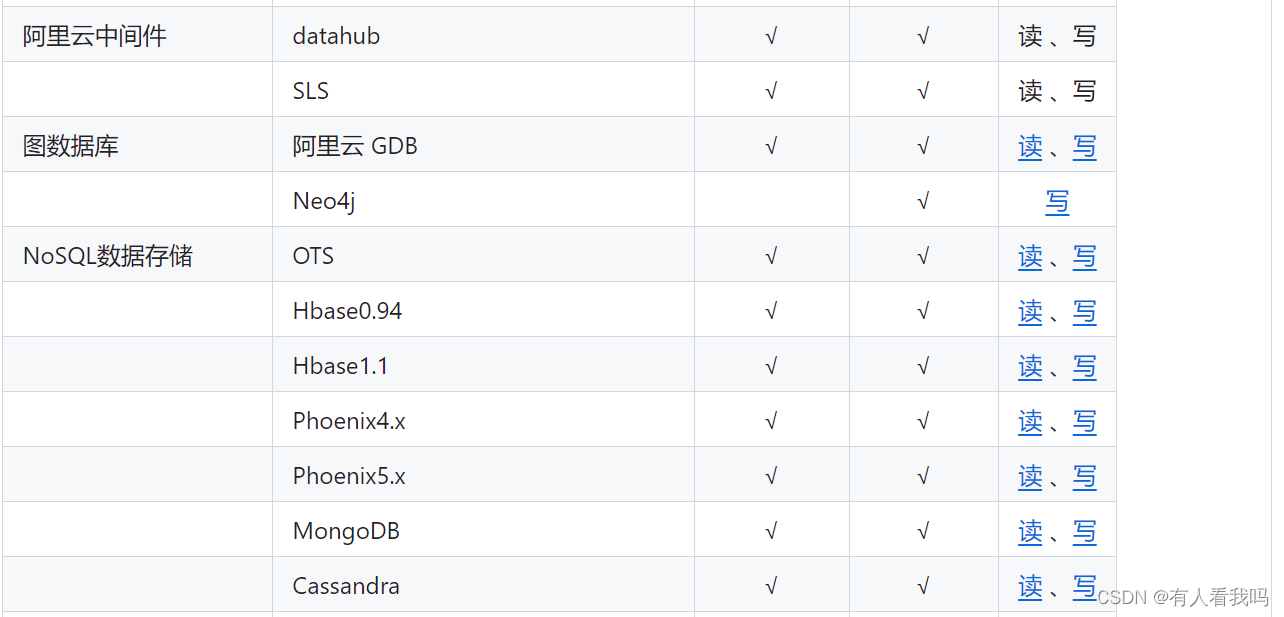
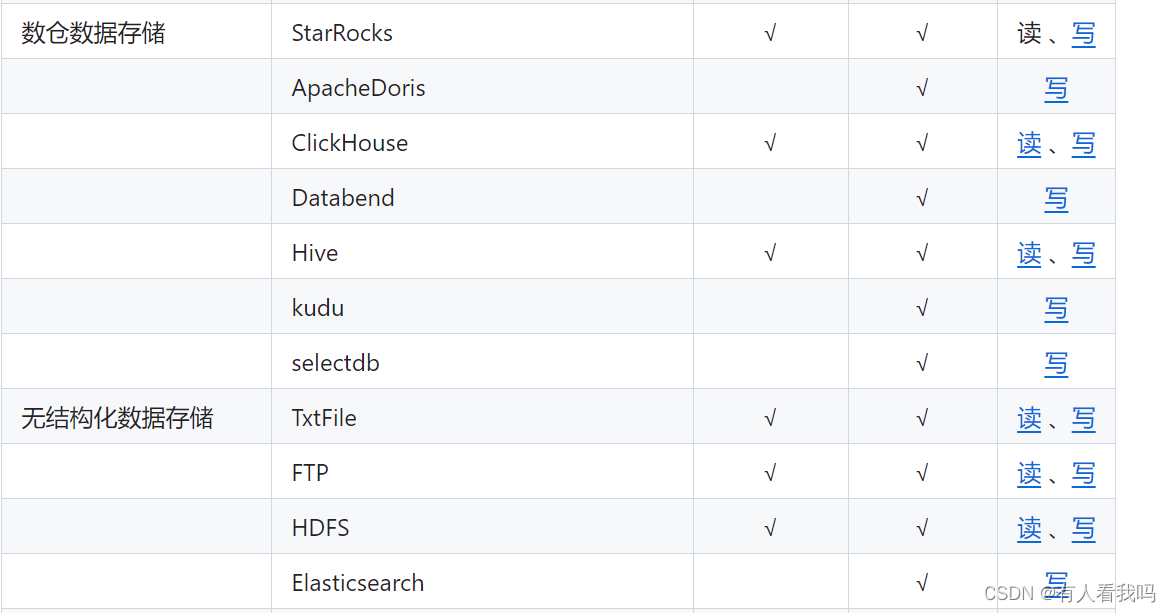

架构
Reader:为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer:为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。

二、使用
- 下载
下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202308/datax.tar.gz
- 解压缩
# 解压缩
tar -zxvf datax.tar.gz -C /opt/module/
- 编写数据同步任务
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,datax"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
- 启动任务
python /opt/module/datax/bin/datax.py /opt/module/datax/job/stream_to_stream.json
- 执行结果
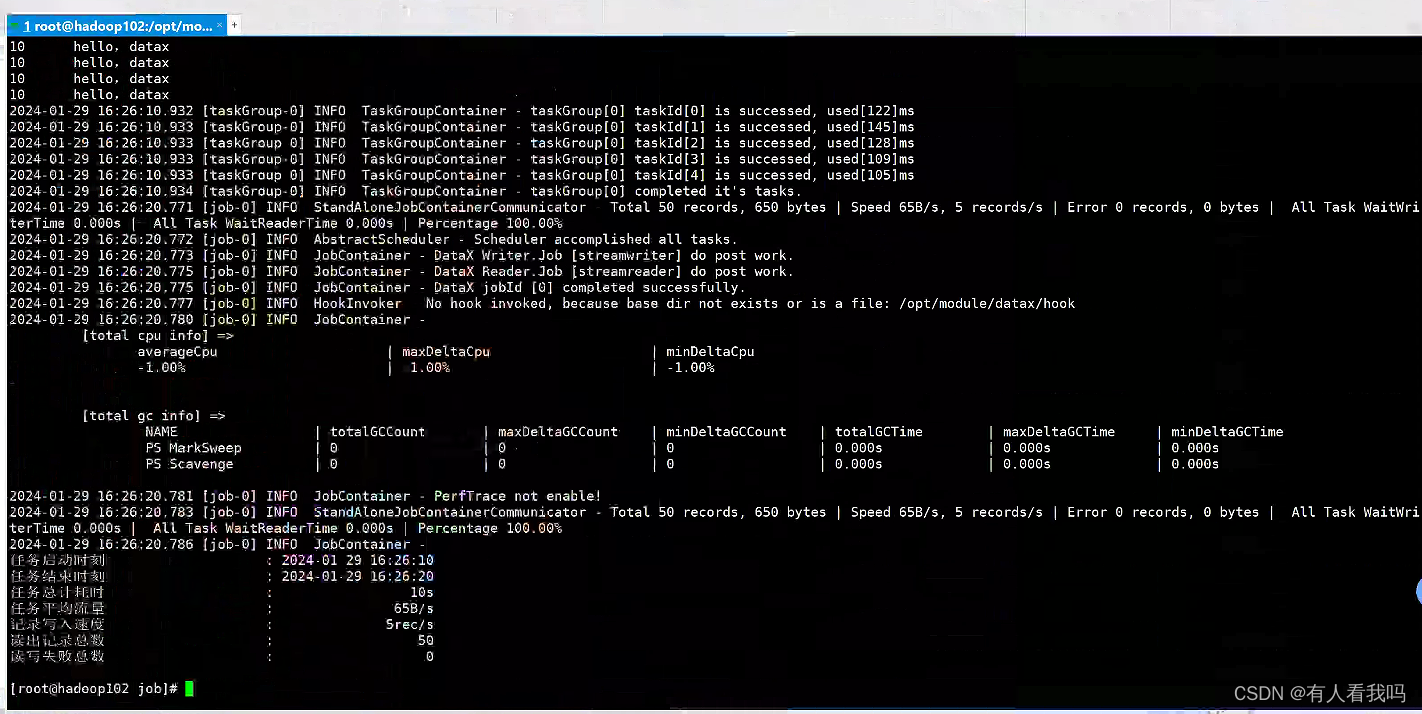
- 配置说明
| 参数 | 说明 |
|---|---|
| job.setting | 设置全局配置参数 |
| job.setting.speed | 控制任务速度配置参数,包括:channel(通道(并发))、record(字节流)、byte(记录流)等三种模式 |
| job.setting.speed.channel | 并发数 |
| job.setting.speed.record | 字节流 |
| job.setting.speed.byte | 记录流 |
| job.setting.errorLimit | 设置错误限制 |
| job.setting.errorLimit.record | 指定允许的最大错误记录数 |
| job.setting.errorLimit.percentage | 指定允许的最大错误记录百分比 |
| job.setting.dirtyDataPath | 设置错误限制 |
| job.setting.dirtyDataPath.path | 设置错误限制 |
| job.setting.log | 设置错误限制 |
| job.setting.log.level | 设置错误限制 |
| job.setting.log.dir | 设置错误限制 |
| content | 任务配置参数 |
| reader | Reader配置 |
| name | Reader类型 |
| parameter | Reader具体配置(具体配置查看具体Reader) |
| writer | Writer配置 |
| name | Writer类型 |
| parameter | Writer具体配置(具体配置查看具体Writer) |
三、常用配置
3.1、MysqlReader
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
配置说明:
jdbcUrl:链接地址
username:mysql用户名
password:mysql密码
table:待同步的表名
column:所配置的表中需要同步的列名集合,可以使用使用*代表所有字段
splitPk:使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能
where:筛选条件
querySql:sql语句,可以替代column和where配置
3.2、MysqlWriter
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}
配置说明:
jdbcUrl:链接地址
username:mysql用户名
password:mysql密码
table:待同步的表名
column:所配置的表中需要同步的列名集合,可以使用使用*代表所有字段
preSql:写入数据到目的表前,会先执行这里的标准语句
postSql:写入数据到目的表后,会执行这里的标准语句
writeMode:控制写入数据到目标表采用insert into或者replace into或者 ON DUPLICATE KEY UPDATE语句
batchSize:一次性批量提交的记录数大小
3.3、HdfsReader
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/mytable01/*",
"defaultFS": "hdfs://xxx:port",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "boolean"
},
{
"type": "string",
"value": "hello"
},
{
"index": 2,
"type": "double"
}
],
"fileType": "orc",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
配置说明:
path:文件路径
defaultFS:namenode节点地址
fileType:文件的类型,目前支持:”text”、”orc”、”rc”、”seq”、”csv”
column:读取字段列表
fieldDelimiter:读取的字段分隔符
encoding:读取文件的编码配置
nullFormat:文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null
haveKerberos:是否有Kerberos认证,默认false
kerberosKeytabFilePath:Kerberos认证keytab文件路径,且为绝对路径
kerberosPrincipal:Kerberos认证Principal名
hadoopConfig:hadoop相关的一些高级参数
3.4、HdfsWriter
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/Users/shf/workplace/txtWorkplace/job/dataorcfull.txt"],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "long"
},
{
"index": 2,
"type": "long"
},
{
"index": 3,
"type": "long"
},
{
"index": 4,
"type": "DOUBLE"
},
{
"index": 5,
"type": "DOUBLE"
},
{
"index": 6,
"type": "STRING"
},
{
"index": 7,
"type": "STRING"
},
{
"index": 8,
"type": "STRING"
},
{
"index": 9,
"type": "BOOLEAN"
},
{
"index": 10,
"type": "date"
},
{
"index": 11,
"type": "date"
}
],
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://xxx:port",
"fileType": "orc",
"path": "/user/hive/warehouse/writerorc.db/orcfull",
"fileName": "xxxx",
"column": [
{
"name": "col1",
"type": "TINYINT"
},
{
"name": "col2",
"type": "SMALLINT"
},
{
"name": "col3",
"type": "INT"
},
{
"name": "col4",
"type": "BIGINT"
},
{
"name": "col5",
"type": "FLOAT"
},
{
"name": "col6",
"type": "DOUBLE"
},
{
"name": "col7",
"type": "STRING"
},
{
"name": "col8",
"type": "VARCHAR"
},
{
"name": "col9",
"type": "CHAR"
},
{
"name": "col10",
"type": "BOOLEAN"
},
{
"name": "col11",
"type": "date"
},
{
"name": "col12",
"type": "TIMESTAMP"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"NONE"
}
}
}
]
}
}
配置说明:
path:存储到Hadoop Hdfs文件系统的路径信息
defaultFS:namenode节点地址
fileType:文件的类型,目前支持:“text”或“orc”
fileName:文件名
column:写入字段列表
fieldDelimiter:读取的字段分隔符
compress:文件压缩类型
3.5、FtpReader
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "ftpreader",
"parameter": {
"protocol": "sftp",
"host": "127.0.0.1",
"port": 22,
"username": "xx",
"password": "xxx",
"path": [
"/home/hanfa.shf/ftpReaderTest/data"
],
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "boolean"
},
{
"index": 2,
"type": "double"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "date",
"format": "yyyy.MM.dd"
}
],
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "ftpWriter",
"parameter": {
"path": "/home/hanfa.shf/ftpReaderTest/result",
"fileName": "shihf",
"writeMode": "truncate",
"format": "yyyy-MM-dd"
}
}
}
]
}
}
配置说明:
protocol:ftp服务器协议,目前支持传输协议有ftp和sftp
host:ftp服务器地址
port:ftp服务器端口
timeout:连接ftp服务器连接超时时间,单位毫秒,默认:60000
connectPattern:连接模式(主动模式或者被动模式)
username:用户名
password:密码
path:路径
column:读取字段列表
fieldDelimiter:读取的字段分隔符
3.6、FtpWriter
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {},
"writer": {
"name": "ftpwriter",
"parameter": {
"protocol": "sftp",
"host": "***",
"port": 22,
"username": "xxx",
"password": "xxx",
"timeout": "60000",
"connectPattern": "PASV",
"path": "/tmp/data/",
"fileName": "yixiao",
"writeMode": "truncate|append|nonConflict",
"fieldDelimiter": ",",
"encoding": "UTF-8",
"nullFormat": "null",
"dateFormat": "yyyy-MM-dd",
"fileFormat": "csv",
"suffix": ".csv",
"header": []
}
}
}
]
}
}
配置说明:
protocol:ftp服务器协议,目前支持传输协议有ftp和sftp
host:ftp服务器地址
port:ftp服务器端口
timeout:连接ftp服务器连接超时时间,单位毫秒,默认:60000
connectPattern:连接模式(主动模式或者被动模式)
username:用户名
password:密码
path:路径
fileName:文件名
fieldDelimiter:读取的字段分隔符