第 1 章:数据仓库概念
数据仓库,是为企业指定决策,提供数据支持的,可以帮助企业,改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等。
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在mysql、oracle等数据库中。
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。??
爬虫数据:通常是通过技术手段获取其它公司网站的数据
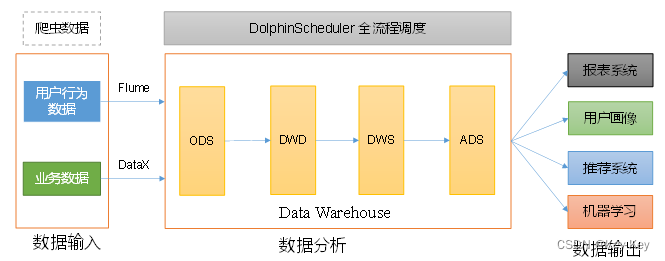
数据采集:在最左边,有两个框表示数据采集阶段。上面的框标有“日常增量数据”,表示每日增加的数据,使用的工具是Flume。Flume是一个分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据。下面的框标有“全量/历史数据”,表示需要处理的全量数据或历史数据,这里使用的工具是DataX。DataX是一个在异构数据源之间进行高效数据传输的工具。
DolphinScheduler 任务调度:在顶部中间的虚线框代表DolphinScheduler,这是一个分布式、去中心化、易扩展的可视化工作流任务调度系统。它被用来调度和协调上述数据采集工具和数据仓库的不同阶段。
数据仓库:中间的大框表示数据仓库的四个主要阶段:
ODS(Operational Data Store):操作数据存储,这是数据进入数据仓库的第一站,通常包含近乎实时的原始数据。
DWD(Data Warehouse Detail):这一层通常用于存储更加详细的事务数据,经过一定程度的处理和整合。
DWS(Data Warehouse Summary):数据仓库汇总,这里的数据经过进一步的聚合和汇总,用于分析和报告。
ADS(Application Data Store):应用数据存储,经过加工处理的数据,以便直接被业务应用系统使用。
数据输出:在右侧有三个框,分别标识了数据输出可能的三个方向:
应用层面:数据被直接应用于业务层面,比如数据驱动的决策支持系统。
服务层面:数据可以被封装成服务,供其他系统调用。
报告层面:数据被用于生成报告,可能是定期的业务报告或者是数据分析报告。
第 2 章:项目需求及框架设计
2.1 项目需求分析
一、项目需求
1、用户行为数据采集平台大家
2、业务数据采集平台搭建
3、数据仓库维度建模
4、分析、设备、会员、商品、地区、活动等电商核心主题,统计的报表指标近100个
5、采用即席查询工具,随时进行指标分析
6、对集群性能进行监控,发生异常需要报警
7、元数据管理
8、质量监控
9、权限管理
2.2 项目框架
2.2.2 系统数据流程设计

这张图是一个数据处理和分析平台的系统架构图。从这张图中,我们可以看到以下几个主要部分:
Web 应用层:这一层有两个主要组成部分,一个是 Nginx 作为反向代理服务器,另一个是 SpringBoot,这表明这是基于 Java 构建的 Web 应用程序。
数据采集层:这一层包括日志文件、Flume 和 Kafka。这些组件通常用于数据的收集、聚合和移动。
数据处理和存储层:包含 Hadoop 和 MySQL,这表明系统既有大数据处理能力,也有传统的关系型数据库管理。
监控报警:使用 Zabbix 和 Grafana 进行系统监控和数据可视化。
数据分析和BI工具:包括 Superset 和 DatAX,这些工具可以用于数据分析和业务智能报告。
权限管理和任务调度:有 Apache Ranger 和 DolphinScheduler,用于数据安全和工作流管理。
其他工具和组件:例如 ZooKeeper(用于分布式系统的协调)、Atlas(用于数据治理)以及一些脚本工具,如 Python Shell。
图形表示:底部的图形代表了数据可视化的示例,包括地图和柱状图。
第 3 章:用户行为日志
3.1 目标数据
要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
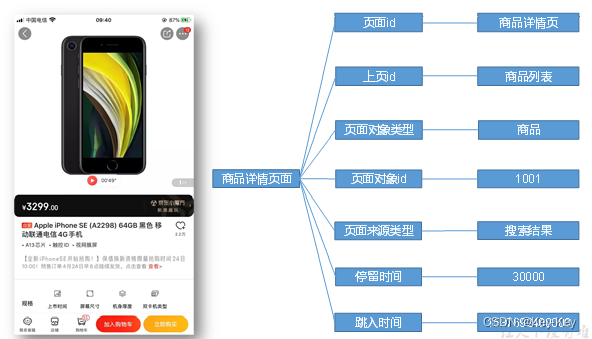
3.1.1 页面
页面数据主要记录一个页面的用户访问情况,包括访问事件、停留事件、页面路径等信息。
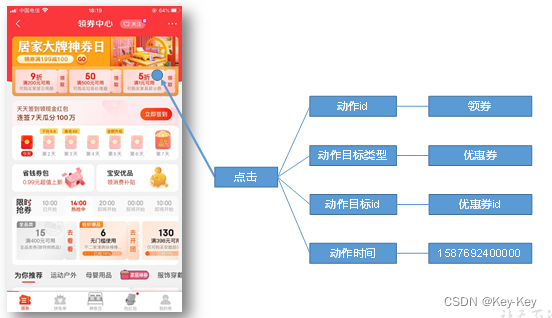
3.1.2 事件
事件数据主要记录应用内一个具体操作行为,包括操作类型、操作对象、操作对象描述等信息。
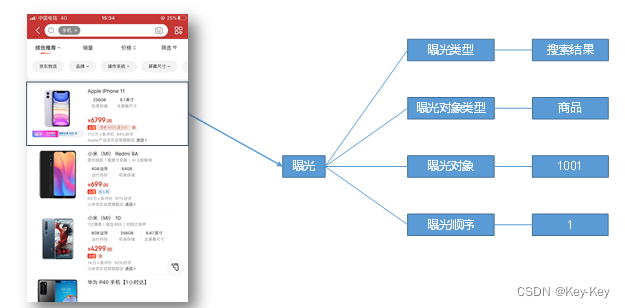
3.1.3 曝光
曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息。
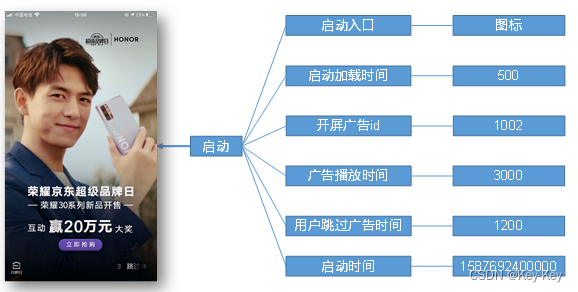
3.1.4 启动
启动数据记录应用的启动信息。
3.1.5 错误
错误数据记录应用使用。

3.2 数据埋点
3.2.1 主流埋点方式
目前主流的埋点方式,有代码埋点(前后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点sdk函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对用的onclick函数里面调用sdk提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集sdk,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集sdk按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入sdk,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要再系统里面进行分析。
3.2.2 埋点数据上报时机
埋点数据上报时包括两种方式。
方式一:在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二:每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
本次项目采用方式一埋点。
3.2.3 埋点数据日志结构
我们的日志结构大概可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
1、普通页面埋点日志格式
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1",--是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作id
"item": "3", --目标id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, --出现顺序
"pos_id": 2 --曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
2、启动日志格式
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
3.3 服务器和jdk准备
3.3.1 服务器准备
按照之前,分配按照hadoop102、103、104三台主机。
3.3.2 编写集群分发脚本xsync
1、xsync集群分发脚本
1)需求:循环复制文件到所有节点的相同目录下
2)需求分析
(1)rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/
(2)期望脚本
xsync要同步的文件名称
(3)说明
在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行。
3)脚本实现
(1)在用的家目录/home/atguigu下创建bin文件夹
[atguigu@hadoop102 ~]$ mkdir bin
(2)在/home/atguigu/bin目录下创建xsync文件,以便全局调用
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 ~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
(3)修改脚本xsync具有执行权限
[atguigu@hadoop102 bin]$ chmod +x xsync
(4)测试脚本
atguigu@hadoop102 bin]$ xsync xsync
3.3.4 ssh无密登录配置
说明:这里面只配置hadoop102、103到其它主机的无密登录;因为102配置的是namenode,103配置的是resourcemanager,都要求对其它节点无密访问。
1、hadoop102上生成公钥和私钥
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa、id_rsa.pub。
2、将102公钥拷贝到免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
3、103上生成公钥和私钥
[atguigu@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa、id_rsa.pub。
4、将103公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop104
3.3.4 jdk准备
1、卸载现有jdk(3台节点)
[atguigu@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
1)rpm -qa:查询所有已经安装的软件包
2)grep -i:过滤时不区分大小写
3)xargs -nl:表示一次获取上次执行结果的一个值
4)rpm -e --nodeps:卸载软件
2、用xshell工具将jdk导入到102的/opt/software文件夹下面
3、在linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop102 software]# ls /opt/software/
看到如下结果:
jdk-8u212-linux-x64.tar.gz
4、解压jdk到/opt/module目录下
[atguigu@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
5、配置jdk环境遍历
1)新建/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 module]# sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
2)让环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
6、测试jdk是否安装成功
[atguigu@hadoop102 module]# java -version
如果能看到一下结果、则java正常安装
java version "1.8.0_212"
7、分发jdk
[atguigu@hadoop102 module]$ xsync /opt/module/jdk1.8.0_212/
8、分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
9、分别在103、104上执行source
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
3.3.6 环境变量配置说明
linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,/.bashrc,/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
登录shell和非登录 shell区别
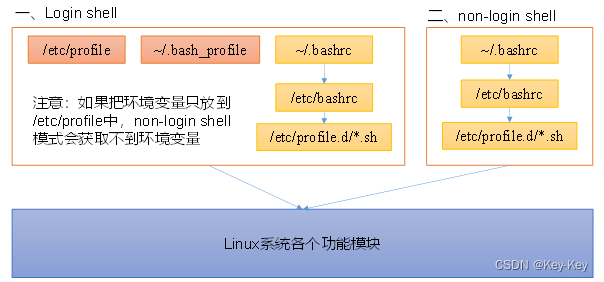
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,/.bash_profile,/.bashrc。non-login shell启动时会加载~/.bashrc。
而在加载~/.bashrc或/etc/profile时,都会执行如下代码片段。
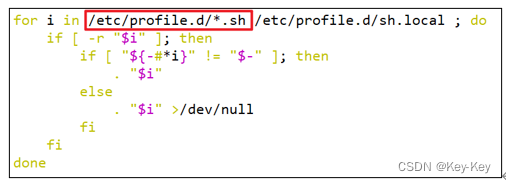
因此,无论是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。
3.4 模拟数据
3.4.1 使用说明
1、将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
1)创建applog路径
[atguigu@hadoop102 module]$ mkdir /opt/module/applog
2)上传文件到/opt/module/applog目录
2、配置文件
1)application.yml文件
可以根据需求生成对应日期的用户行为日志。
[atguigu@hadoop102 applog]$ vim application.yml
修改如下内容。
# 外部配置打开
# 外部配置打开
logging.config: "./logback.xml"
#业务日期 注意:并不是Linux系统生成日志的日期,而是生成数据中的时间
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://hdp1/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 500000
#会员最大值
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
logging.config: "./logback.xml":指定日志配置文件的路径为"./logback.xml",用于配置应用程序的日志输出方式和级别。
mock.date: "2020-06-14":指定模拟数据生成时使用的业务日期,这个日期将用于生成数据中的时间信息。
mock.type: "log":指定模拟数据发送模式,可以是"http"、"kafka"或"log"。在这里,模拟数据将以日志方式输出。
mock.url: "http://hdp1/applog":在HTTP模式下,指定数据发送的目标地址为"http://hdp1/applog"。
mock.kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"和mock.kafka-topic: "ODS_BASE_LOG":在Kafka模式下,指定Kafka服务器地址和Kafka主题。
mock.startup.count: 200:指定启动次数,可能用于控制生成的模拟数据的数量。
mock.max.mid: 500000、mock.max.uid: 100、mock.max.sku-id: 35:分别指定设备、会员和商品的最大值,可能用于生成随机数据。
mock.page.during-time-ms: 20000:指定页面平均访问时间,可能用于模拟用户在页面上停留的时间。
mock.error.rate: 3:指定错误概率百分比,可能用于模拟错误事件的发生。
mock.log.sleep: 10:指定每条日志发送的延迟时间(以毫秒为单位)。
mock.detail.source-type-rate: "40:25:15:20":指定商品详情来源的比例,包括用户查询、商品推广、智能推荐和促销活动。
mock.if_get_coupon_rate: 75:指定领取购物券的概率百分比。
mock.max.coupon-id: 3:指定购物券的最大ID。
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子":指定搜索关键词,可能用于模拟用户的搜索行为。
2)path.json,该文件用来配置访问路径
根据需求,可以灵活配置用户点击路径。
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":10 },
{"path":["home" ],"rate":10 }
]
描述了用户在一个应用或网站中的不同路径和用户对这些路径的访问频率。每个路径都是一个由字符串组成的数组,表示用户在应用中的一系列操作步骤,而与每个路径相关的"rate"值表示了用户对该路径的访问频率或重要性。
3)logback配置文件
可配置日志生成路径,修改内容如下。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atgugu.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
</root>
</configuration>
这段代码是一个XML格式的Logback配置文件,用于配置日志记录行为和输出目标。Logback是Java的一个流行的日志框架,它允许你定义日志记录规则和目标。
以下是这段代码的主要作用:
定义日志文件的存储路径:通过<property>元素,定义了一个名为LOG_HOME的属性,用于存储日志文件的路径,路径为/opt/module/applog/log。
配置两个日志输出目标:
console:定义了一个输出到控制台的日志目标。
rollingFile:定义了一个按时间滚动的文件日志目标,日志文件名会根据时间戳进行命名,存储在${LOG_HOME}目录下,文件名格式为app.{日期}.log。
针对特定的包设置日志级别:通过<logger>元素,将包com.atgugu.gmall2020.mock.log.util.LogUtil的日志级别设置为INFO,并指定只向rollingFile和console这两个目标输出日志,而不向根级别的日志输出。
配置根日志级别:通过<root>元素,将根级别的日志级别设置为ERROR,并指定只向console目标输出日志。这意味着除了特定包下的日志会输出INFO级别的信息到文件和控制台之外,其他日志消息将只在发生错误时输出到控制台。
3、生成日志
1)进入/opt/module/applog路径,执行以下命令
[atguigu@hadoop102 applog]$ java -jar gmall2020-mock-log-2021-10-10.jar
2)在/opt/module/applog/log目录下查看生成日志
[atguigu@hadoop102 log]$ ll
3.4.2 集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin
1、在/home/atguigu/bin目录下创建脚本lg.sh
[atguigu@hadoop102 bin]$ vim lg.sh
2、在脚本中编写如下内容
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done
在远程服务器上启动一个 Java 程序,使其在后台运行,同时将其输出丢弃,以便在不影响脚本执行的情况下生成模拟的日志数据。
3、修改脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x lg.sh
4、将jar包及配置文件上传到hadoop103的/opt/module/applog/路径
5、启动脚本
[atguigu@hadoop102 module]$ lg.sh
6、分别在hadoop102、103的/opt/module/applog/log目录上查看生成的数据
[atguigu@hadoop102 logs]$ ls
app.2020-06-14.log
[atguigu@hadoop103 logs]$ ls
app.2020-06-14.log
第 4 章:数据采集模块
4.1 数据通道
用户行为日志数据通道
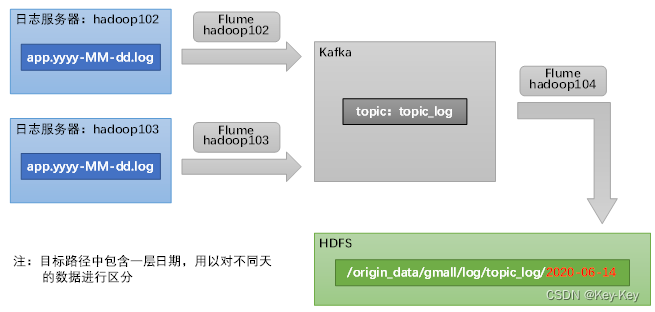
Flume的角色:
这个架构中,Flume被部署在不同的服务器上(hadoop102、hadoop103、hadoop104),它的作用是收集服务器上的日志文件。
在hadoop102和hadoop103服务器上,Flume配置被设定为收集名称格式为app-yyyy-MM-dd.log的文件。这里的yyyy-MM-dd很可能是日志文件中的日期格式。
Kafka的集成:
Flume将这些日志文件收集后,被配置为将数据推送到Kafka中。Kafka是一个分布式流处理平台,通常用于处理大量的数据流。
Kafka中有一个名为topic_log的主题(topic),Flume将日志数据发布到这个主题。
数据流向HDFS:
另一个Flume实例(在hadoop104上)被用来从Kafka的topic_log主题中拉取数据。
这些数据随后被写入到HDFS中的一个特定路径/origin_data/gmall/log/topic_log/,并且似乎是按照日期进行分区的,例如路径中包含2020-06-14这样的日期格式。
备注:
图底部的备注说明了一个关键的操作细节:日志数据在每个一天结束时,即凌晨不会立即进行收集。
4.2 环境准备
4.2.1 集群所有进程查看脚本
1、在/home/atguigu/bin目录下创建脚本xcall.sh
[atguigu@hadoop102 bin]$ vim xcall.sh
2、在脚本中编写如下内容
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done
3、修改脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 xcall.sh
4、启动脚本
[atguigu@hadoop102 bin]$ xcall.sh jps
4.2.2 hadoop安装
1、安装步骤
参考之前hadoop文章
2、项目经验
1)项目经验之hdfs存储多目录
(1)生成环境服务器磁盘情况
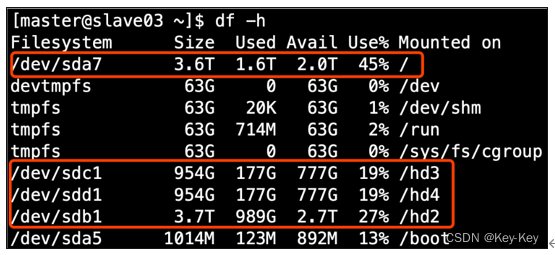
(2)在hdfs-site.xml文件中配置多目录
hdfs的datanode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
2)项目经验之集群数据均衡
(1)节点间数据均衡
开启数据均衡命令。
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令。
stop-balancer.sh
(2)磁盘间数据均衡
生成均衡计划
hdfs diskbalancer -plan hadoop103
执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
3)项目经验之hadoop参数调优
(1)hdfs参数调优hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>

[atguigu@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(8))
41
>>> quit()
(2)yarn参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->flume->kafka-hdfs->hive
面临问题:数据统计主要用hivesql,没有数据倾斜,小文件已经做了合并处理,开启的jvm重用,而且io没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕机。
解决方法:
内存利用率不够。这个一般是yarn的2个配置造成的,单个任务可以申请的最大内存大小,和hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
a、yarn.nodemanager.resource.memory-mb
表示该节点上yarn可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而yarn不会智能的探测节点的物理内存总量。
b、yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)
4.2.3 zookeeper安装
1、安装步骤
参考之前zookeeper文章
2、zk集群启动停止脚本
1)在hadoop102的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop102 bin]$ vim zk.sh
在脚本中编写如下
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
脚本的工作方式基于传入的参数($1),它有三个主要的操作模式:start, stop, 和 status。
启动模式 (start):
当脚本使用start参数运行时,它会在三台服务器(hadoop102, hadoop103, hadoop104)上启动Zookeeper服务。
对于每台服务器,它使用ssh远程连接到服务器,并执行zkServer.sh start命令来启动Zookeeper服务。
在启动每个服务器的Zookeeper服务之前,会打印一条消息,表明正在启动哪台服务器上的Zookeeper。
停止模式 (stop):
使用stop参数时,脚本会在上述相同的三台服务器上停止Zookeeper服务。
它通过ssh远程连接到每台服务器,并执行zkServer.sh stop命令来停止服务。
停止每个服务器的Zookeeper服务之前,同样会打印一条消息来表明正在停止哪台服务器上的服务。
状态检查模式 (status):
当使用status参数时,脚本会检查并显示每台服务器上Zookeeper服务的状态。
它通过ssh连接到每台服务器,并执行zkServer.sh status命令。
在检查每个服务器的状态之前,会打印一条消息来指示正在检查哪台服务器上的Zookeeper服务状态。
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 zk.sh
3)zookeeper集群启动脚本
[atguigu@hadoop102 module]$ zk.sh start
4)zookeeper集群停止脚本
[atguigu@hadoop102 module]$ zk.sh stop
4.2.4 kafka安装
1、安装步骤
参考之前文章
2、kafka集群启动停止脚本
1)在/home/atguigu/bin目录下创建脚本kf.sh
[atguigu@hadoop102 bin]$ vim kf.sh
在脚本中填写如下内容。
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
这段代码是一个Bash脚本,用于在多个服务器上启动或停止Kafka服务。
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 kf.sh
3)kf集群启动脚本
[atguigu@hadoop102 module]$ kf.sh start
4)kf集群停止脚本
[atguigu@hadoop102 module]$ kf.sh stop
3、kafka常用命令
1)查看kafka topic列表
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --list
2)创建kafka topic
进入到/opt/module/kafka/目录下创建日志主题
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 1 --partitions 1 --topic topic_log
3)删除kafka topic
[atguigu@hadoop102 kafka]$ kafka-topics.sh --delete --bootstrap-server hadoop102:9092 --topic topic_log
4)kafka生产消息
[atguigu@hadoop102 kafka]$ kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
>hello world
>atguigu atguigu
5)kafka消费消息
[atguigu@hadoop102 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
–from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
6)查看kafka topic详情
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
4.2.5 flume安装
按照采集通道规划,需在hadoop102、103、104三台节点分别部署一个flume。
1、按照步骤
参考之前原文
2、分发flume
[atguigu@hadoop102 ~]$ xsync /opt/module/flume/
3、项目经验
堆内存调整
flume堆内存通常设置为4G或更高,配置方式如下:
修改/opt/module/flume/conf/flume-env.sh文件,配置如下参数
export JAVA_OPTS="-Xms4096m -Xmx4096m -Dcom.sun.management.jmxremote"
-Xms表示堆内存最小尺寸,初始分配;-Xmx表示堆内存最大允许的尺寸,按需分配。
4.3 日志采集flume
4.3.1 日志采集flume配置概述
按照规划,需要采集的用户行为日志文件分布在102,103两台日志服务器,故需要在102,103两台节点配置日志采集flume。日志采集flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到kafka。
此处可选择taildirsource和kafkachannel,并配置日志校验拦截器。
选择taildirsource和kafkachannel的原因如下:
1、taildirsource
taildirsource相比execsource、spoolingdirectorysource的优势
taildirsource:断点续传、多目录。flume以前需要自己自定义source记录每次读取文件位置,实现断电续传。
execsource可用实时搜集数据,但是在flume不运行或者shell命令出错的情况下,数据将会丢失。
spoolingdirectorysource监控目录,支持断电续传。
2、kafka channel
采用kafka channel,省去了sink,提高了效率。
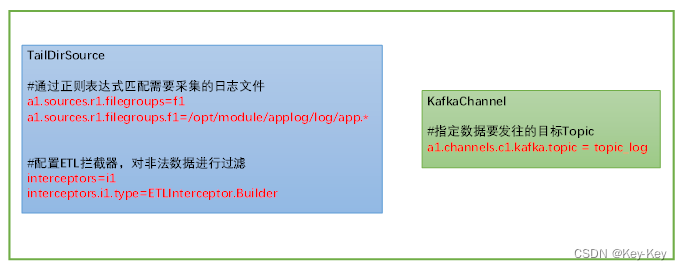
日志采集flume关键配置如下:
4.3.2 日志采集flume配置实操
1、创建flume配置文件
在hadoop102节点的flume的job目录下创建file_to_kafka.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/file_to_kafka.conf
2、配置文件内容如下
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1
配置了 Flume 以从指定文件路径读取日志数据(使用 TAILDIR source),通过一个拦截器处理,然后将数据传输到 Kafka(使用 Kafka channel)
3、编写flume拦截器
1)创建maven工程flume-interceptor
2)创建包:com.atguigu.flume.interceptor
3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
org.apache.flume:flume-ng-core:1.9.0: 这是 Apache Flume 的核心库,用于数据采集、聚合和移动。版本是 1.9.0。<scope>provided</scope> 表示这个依赖在运行时会被提供,通常是由运行环境(如一个应用服务器)提供。
com.alibaba:fastjson:1.2.62: 这是一个由阿里巴巴提供的 JSON 处理库,用于解析和生成 JSON 数据。版本是 1.2.62。
maven-compiler-plugin: 这个插件用于编译 Java 代码。它被配置为使用 Java 1.8 版本进行编译,即源代码和目标字节码都遵循 Java 1.8 的标准。
maven-assembly-plugin: 这个插件用于创建一个包含所有依赖的单一可执行 JAR 文件(通常称为 "fat jar" 或 "uber jar")。<descriptorRef>jar-with-dependencies</descriptorRef> 指定了一个预定义的描述符,告诉插件将项目的所有依赖项一起打包进 JAR 文件中。这个插件在 package 阶段执行,这意味着当运行 mvn package 命令时,它会被触发。
这段代码是一个 Maven 配置,用于定义项目的依赖、编译标准以及打包方式。这使得项目能够被正确地编译成 Java 1.8 兼容的代码,并且生成一个包含所有必需依赖的单一 JAR 文件,方便部署和运行。
4)在com.atguigu.flume.interceptor包下创建jsonutils类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
public static boolean isJSONValidate(String log){
try {
JSON.parse(log);
return true;
}catch (JSONException e){
return false;
}
}
}
提供一种简单的方式来检查一个字符串是否符合JSON格式的标准。
5)在com.atguigu.flume.interceptor包下创建etlinterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
确保通过Flume传输的所有事件都是有效的JSON格式。这对于后续的数据处理非常重要,特别是在将数据发送到需要JSON格式输入的系统(如大数据处理平台)时。如果事件不是有效的JSON格式,该拦截器会将其从传输流中移除,从而保证数据的质量和一致性。
6)打包

7)需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面
4.3.3 日志采集flume测试
1、启动zookeeper、kafka集群
2、启动hadoop102的日志采集flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
3、启动一个kafka的console-consumer
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
4、生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
5、观察kafka消费组是否能消费到数据
4.3.4 日志采集flume启停脚本
1、分发日志采集flume配置文件和拦截器
若上述测试通过,需将hadoop102节点的flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。
[atguigu@hadoop102 flume]$ scp -r job hadoop103:/opt/module/flume/
[atguigu@hadoop102 flume]$ scp lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar hadoop103:/opt/module/flume/lib/
2、方便起见,此处编写一个日志采集flume进程的启停脚本
1)在hadoop102节点的/home/atguigu/bin目录下创建脚本f1.sh
[atguigu@hadoop102 bin]$ vim f1.sh
在脚本中填写如下内容。
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f1.sh
3)f1启动
[atguigu@hadoop102 module]$ f1.sh start
4)f2停止
[atguigu@hadoop102 module]$ f1.sh stop
4.4 日志消费flume
4.4.1 日志消费flume配置概述
按照规划,该flume需将kafka中topic_log的数据发往hdfs。并且对每天产生的用户行为日志进行区分,将不同天的数据发往hdfs不同天的路径。
此处选择kafkasource、filechannel、hdfssink。
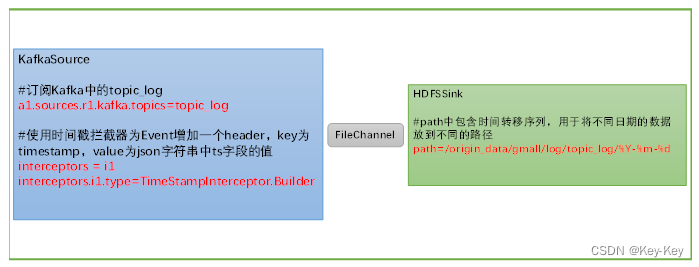
关键配置如下:
4.4.2 日志消费flume配置实操
1、创建flume配置文件
在104节点的flume的job目录下创建kafka_to_hdfs_log.conf
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_log.conf
2、配置文件内容如下
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
定义了一个从Kafka源接收数据,经过File通道,最后输出到HDFS的Flume代理配置。
组件定义
a1.sources=r1:定义了一个名为 r1 的源(source)。
a1.channels=c1:定义了一个名为 c1 的通道(channel)。
a1.sinks=k1:定义了一个名为 k1 的汇(sink)。
Source1(源配置)
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource:指定源类型为Kafka。
a1.sources.r1.batchSize = 5000:设置批量大小为5000。
a1.sources.r1.batchDurationMillis = 2000:设置批处理持续时间为2000毫秒。
a1.sources.r1.kafka.bootstrap.servers:设置Kafka的服务器地址。
a1.sources.r1.kafka.topics=topic_log:设置Kafka的主题为 topic_log。
a1.sources.r1.interceptors = i1:定义一个拦截器 i1。
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder:设置拦截器类型为时间戳拦截器。
Channel1(通道配置)
a1.channels.c1.type = file:指定通道类型为文件。
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1:设置检查点目录。
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/:设置数据目录。
a1.channels.c1.maxFileSize = 2146435071:设置最大文件大小。
a1.channels.c1.capacity = 1000000:设置通道容量。
a1.channels.c1.keep-alive = 6:设置保持活动状态的时间。
Sink1(汇配置)
a1.sinks.k1.type = hdfs:指定汇类型为HDFS。
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d:设置HDFS的路径模板。
a1.sinks.k1.hdfs.filePrefix = log-:设置文件前缀。
a1.sinks.k1.hdfs.round = false:禁用轮询。
a1.sinks.k1.hdfs.rollInterval = 10:设置滚动间隔。
a1.sinks.k1.hdfs.rollSize = 134217728:设置滚动大小。
a1.sinks.k1.hdfs.rollCount = 0:设置滚动计数。
a1.sinks.k1.hdfs.fileType = CompressedStream:设置文件类型为压缩流。
a1.sinks.k1.hdfs.codeC = gzip:设置压缩格式为gzip。
拼装
a1.sources.r1.channels = c1:将源 r1 连接到通道 c1。
a1.sinks.k1.channel= c1:将汇 k1 连接到通道 c1。
注:配置优化
1)filechannel优化
通过配置datadirs指向多个路径,每个路径对应不同的硬盘,增大flume吞吐量。
checkpointdir和backupcheckpointdir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可用快速使用backupcheckpointdir恢复数据。
2)hdfs sink优化
(1)hdfs存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包含文件路径,文件名,所有者,所属组,权限,创建事件等,这些信息都保存在namenode内存中。所以小文件过多,会占用namenode服务器大量内存,影响namenode性能和使用寿命。
计算层面:默认情况下mr会对每个小文件启用一个map任务计算,非常影响计算性能。同时也影响磁盘寻址事件。
(2)hdfs小文件处理
官方默认的这三个参数配置写入hdfs后会产生小文件,hdfs.rollinterval、hdfs.rollsize、hdfs.rollcount。
基于以上hdfs.rollinterval=3600,hdfs.rollsize=134217728,hdfs.rollcount=0几个参数综合作用,效果如下:
a、文件在达到128M时会滚动生成新文件
b、文件创建超3600秒时会滚动生成新文件
(3)编写flume拦截器
a、在com.atguigu.flume.interceptor包下创建timestampinterceptor类
package com.atguigu.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地收集、聚合和移动大量日志数据。拦截器(Interceptor)在 Flume 中用于在事件流经过时对这些事件进行处理或修改。具体到这段代码的功能,我会逐步解释:
类定义 (TimeStampInterceptor): 这是一个公共类,它实现了 Flume 的 Interceptor 接口,使其能夠作为一个拦截器使用。
成员变量 (events): 定义了一个 ArrayList<Event> 类型的成员变量 events,用于存储事件。
initialize 方法: 这是 Interceptor 接口的一部分,用于初始化拦截器。在这个实现中,该方法是空的,表示拦截器初始化时不执行任何操作。
intercept(Event event) 方法: 这个方法接收一个 Event 对象,并对其进行处理。它首先从事件中获取头部信息,然后将事件体(假设为 JSON 格式的日志)转换为字符串。接着,它解析这个 JSON 字符串,提取名为 "ts" 的字段,并将其值添加到事件的头部信息中,键为 "timestamp"。此方法的目的是从每个日志事件中提取时间戳,并将其作为头部信息加入到事件中。
intercept(List<Event> list) 方法: 这个方法处理一个事件列表。它首先清空 events 成员变量,然后遍历列表中的每个事件,使用 intercept(Event event) 方法处理它们,并将处理后的事件添加到 events 列表中。最后返回这个处理后的事件列表。
close 方法: 这也是 Interceptor 接口的一部分,用于执行拦截器关闭前的清理工作。这个方法在这个类中是空的,表示没有特殊的清理操作需要执行。
内部静态类 (Builder): 这是一个实现了 Interceptor.Builder 接口的内部静态类。build 方法返回一个新的 TimeStampInterceptor 实例。configure 方法用于配置拦截器,但在这里它是空的,意味着没有特定的配置需要设置。
总的来说,这个 TimeStampInterceptor 类的目的是在 Flume 事件流中为每个事件添加一个基于其内容的时间戳头部信息。这在处理日志数据时很有用,特别是当需要根据时间戳对事件进行排序或筛选时。
b、重新打包

c、需要先把打包好的放到hadoop104的/opt/module/flume/lib文件夹下面
4.4.3 日志消费flume测试
1、启动zookeeper、kafka集群
2、启动日志采集flume
[atguigu@hadoop102 ~]$ f1.sh start
3、启动104的日志消费flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
4、生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
5、观察hdfs是否出现数据
4.4.4 日志消费flume启停脚本
若上述测试通过,为方便,此处创建一个flume的启停脚本
1、在hadoop102节点的/home/atguigu/bin目录下创建脚本f2.sh
[atguigu@hadoop102 bin]$ vim f2.sh
在脚本中填写如下内容。
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f2.sh
3、f2启动
[atguigu@hadoop102 module]$ f2.sh start
4、f2停止
[atguigu@hadoop102 module]$ f2.sh stop
4.5 采集通道启动/停止脚本
1、在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim cluster.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动 Flume采集集群
f1.sh start
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Flume消费集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#循环直至 Kafka 集群进程全部停止
kafka_count=$(jpsall | grep Kafka | wc -l)
while [ $kafka_count -gt 0 ]
do
sleep 1
kafka_count=$(jpsall | grep Kafka | wc -l)
echo "当前未停止的 Kafka 进程数为 $kafka_count"
done
#停止 Zookeeper集群
zk.sh stop
};;
esac
2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x cluster.sh
3、cluster集群启动脚本
[atguigu@hadoop102 module]$ cluster.sh start
4、cluster集群停止脚本
[atguigu@hadoop102 module]$ cluster.sh stop








![壹[1],Xamarin开发](https://img-blog.csdnimg.cn/direct/65acb3728902496696914df418299bf3.png)
![[网络安全]IIS---FTP服务器 、serverU详解](https://img-blog.csdnimg.cn/direct/51c0f28d4c6243f6ac1de0e7a2d759a9.png)