论文信息
Subjects: Computation and Language (cs.CL)
(1)题目:Enhancing Relation Extraction Using Syntactic Indicators and Sentential Contexts (利用句法指示符和句子上下文加强关系抽取)
(2)文章下载地址:
https://doi.org/10.48550/arXiv.1912.01858
arXiv:1912.01858 [cs.CL]
(or arXiv:1912.01858v1 [cs.CL] for this version)
Comments: Accepted at ICTAI 2019: The IEEE International Conference on Tools with Artificial Intelligence (ICTAI)
(3)相关代码:
(4)作者信息:Hao Wang
————————————————
目录
- Abstract
- Introduction
- Related work
- Model
- 模型架构
- 语法指示器的定义
- 句法指示符提取
- 基于bert的上下文编码器
- 关系分类
- 训练过程
- Experiment
- 数据集和评价指标
- 实验设置
- 结果
- 分析
- Conclusion
Abstract
State-of-the-art methods for relation extraction consider the sentential context by modeling the entire sentence.
However, syntactic indicators, certain phrases or words like prepositions that are more informative than other words and may be beneficial for identifying semantic relations. Other approaches using fixed text triggers capture such information but ignore the lexical diversity. To leverage both syntactic indicators and sentential contexts, we propose an indicator-aware approach for relation extraction. Firstly, we extract syntactic indicators under the guidance of syntactic knowledge. Then we construct a neural network to incorporate both syntactic indicators and the entire sentences into better relation representations. By this way, the proposed model alleviates the impact of noisy information from entire sentences and breaks the limit of text triggers. Experiments on the SemEval-2010 Task 8 benchmark dataset show that our model significantly outperforms the state-of-the-art methods.
最先进的关系提取方法通过对整个句子建模来考虑句子上下文。
然而,句法指标,某些短语或单词,如介词,比其他单词更有信息,可能有利于识别语义关系。其他使用固定文本触发器的方法捕获这些信息,但忽略了词汇多样性。为了同时利用句法指示符和句子上下文,我们提出了一种指示符感知的关系提取方法。首先,在句法知识的指导下提取句法指标;然后,我们构建了一个神经网络,将句法指标和整个句子结合成更好的关系表示。通过这种方式,该模型减轻了整个句子中噪声信息的影响,打破了文本触发的限制。在SemEval-2010 Task 8基准数据集上的实验表明,我们的模型明显优于最先进的方法。
Introduction
关系抽取是在给定句子中为目标实体对分配语义关系的任务。从非结构化文本中准确提取语义关系对于许多自然语言应用非常重要,例如信息提取[1][2],问题回答[3][4],语义网络构建[5][6]。
最近的关系提取方法主要集中在深度神经网络[7]-[12]。通常,这些模型对整个句子进行编码,以捕获关系表示的上下文信息,其假设是句子中的每个单词都有助于对关系进行分类 。这些方法大多使用实体信息来提高关系提取的性能,如实体位置[7][8]、实体超名词[7]和潜在实体类型[13]。他们都认为与目标实体相关的信息更重要。但是,这些模型有两个缺点:第一,句子中一些与关系无关的词对分类来说是噪声;第二,实体信息在预测关系类型时非常有限,其他词的贡献容易被忽略。
此外,一些方法依赖于特定的词汇约束[14]和关系触发器[15],它们显式地指示句子中关系的出现。然而,这些方法不适用于句子中没有关系触发的情况。
在本文中,我们从另一个角度重新审视这个问题。

如图1所示,移动到的短语是识别关系类型Entity-Destination(e1,e2)的关键。相反,仅通过实体老板和实体办公室的语言特征来识别关系类型是不够的,更不存在明确的关系触发。直观地,像of和from这样的词是关系提取的信息。在这里和之后,我们称这种词或短语为句法指示器。
句法指示器包含动态信息,用于识别目标实体之间的语义关系。此外,第一句中的My、new、yesterday这些词无处不在,但对关系识别没有帮助。我们可以通过减少它们的影响来获得更好的性能。
因此,我们提出了一个**指示符感知神经模型 ,以调节句法指示符和句子上下文**,以便更好地进行关系提取。这是通过两个阶段的过程来实现的。首先,在句法知识的指导下,通过实体消歧、主成分提取和不相关实体去除去除不相关词来提取句法指标;然后,我们将整个句子和句法指示符都输入到基于预训练BERT(来自transformer的双向编码器表示)[16]的上下文编码器中,对语义关系表示进行编码。这个句法指示符被视为上下文表示的主要约束。通过这种方式,所提出的模型充分利用了相关信息,减少了噪声词的影响。我们的主要贡献如下:
•定义有助于区分关系类型的句法指标,在句法知识的指导下提取句法指标,有利于捕捉重要信息,减少与关系提取无关的噪声信息。
•我们提出了一个指标感知的神经模型,使用预提取的指标来改进关系提取,该模型通过对上下文表示施加约束来利用关键信息,以实现更好的预测。
•所提出的模型在基准数据集上获得了90.36%的f1得分,优于最先进的方法。更多的消融实验表明,在上下文表示中加入句法指标可以显著提高关系提取的性能。
Related work
传统的非神经关系提取模型包括基于特征的模型[17][18]和基于核的模型[19][20]。由于高度依赖人工特征提取过程,这些方法总是会出现错误传播。此外,它们可能会遗漏关系提取的有用信息。因此,这些方法的性能是非常有限的。
最近,各种关系提取的工作都集中在深度神经网络上。这些方法缓解了误差传播的问题,取得了很好的效果。一方面,Zeng等[7]提出了一种深度卷积神经网络(CNN)来解决这一问题。它们利用句子级特征和词汇级特征,包括实体、实体的左、右标记和实体的WordNet上位词。
Santos等[8]提出了排名CNN (CR-CNN)模型,使用一种新的排名损失来减少人工类别的影响。
他们还证明了目标名目之间的单词几乎和使用定位嵌入一样有用。受他们工作的启发,我们从两个实体之间的文本中提取句法指示符。Shen和Huang[12]提出了基于注意的卷积神经网络(attention - cnn),该网络采用词级注意机制获取关键信息用于关系表示。由于卷积神经网络的不足,这些方法在学习序列结构上存在一定的局限性。另一方面,基于rnn的模型在文本的语言结构学习方面表现出色。Zhang和Wang[21]提出了一种双向循环神经网络(Bi-RNN)来学习两个实体之间的长期依赖关系,但在rnn中存在梯度消失的问题。不久之后,Zhang等[9]应用了双向LSTM网络(BiLSTM),利用单词位置和外部特征来提高关系提取的性能,包括POS。
标记、命名实体信息和依赖项解析。在[10]中,Zhou等人将注意机制应用于双向LSTM网络(attention Bi-LSTM)。Xiao和Liu[11]根据两个目标实体的位置将每个句子分成三个上下文子序列,并使用带有两个注意力Bi-LSTM网络的分层循环神经网络(Hier Attention Bi-LSTM)来获得更好的结果。最近,Lee等人[13]提出了一个包含实体感知注意机制和潜在实体类型(LET)的模型,并获得了最先进的性能。
上述方法对整个句子进行编码以捕捉上下文特征,导致忽略了句子中其他重要特征。虽然有许多方法利用了实体位置、实体语义、潜在实体类型、实体多义词等各种实体信息,这些信息对识别关系具有不可替代的影响,但这些信息的局限性太大,无法完全捕捉到显著的特征。
也有一些作品专注于关系触发器,即明确表示给定文本中某个关系的出现的短语。Björne等[15]提出了关系触发器,并确定其参数,以降低任务的复杂性。Open IE系统ReV erb[14]也使用特殊短语通过词汇约束来识别不同的关系类型。然而,有许多文本内部没有明确的关系触发,这些方法无法从这些句子中提取语义关系。与这些方法不同的是,我们的方法利用了句法指示器,它可以随着语义关系的不同表达而变化,而不是匹配固定的短语模板。
预训练的语言模型在许多NLP任务上都取得了巨大的成功。特别是Devlin等人提出的BERT对[16]有显著的影响,它在训练过程中通过对左右上下文的联合条件反射来学习深度双向表征。该方法已应用于多个NLP任务,并在文本分类、序列标记和问题回答等11个任务上获得了最新的结果。在最近的研究中,Wu和He[24]提出了一个R-BERT模型,该模型采用了预先训练好的BERT语言模型,在关系抽取方面排名靠前。
顺便说一下,关于关系提取的相关工作主要可以分为两类,监督方法[7][11][25]和远程监督方法[26]-[28]。它们的不同之处在于数据中是否包含大量的噪声标签。无噪声标签的监督方法得到了更可靠的结果,在关系分类中起着主导作用。本文主要研究有监督关系抽取。
Model
在本节中,我们首先概述了所提出的指标感知神经模型。之后,我们详细介绍了每个模块。
模型架构
所提模型的总体架构如图2所示。
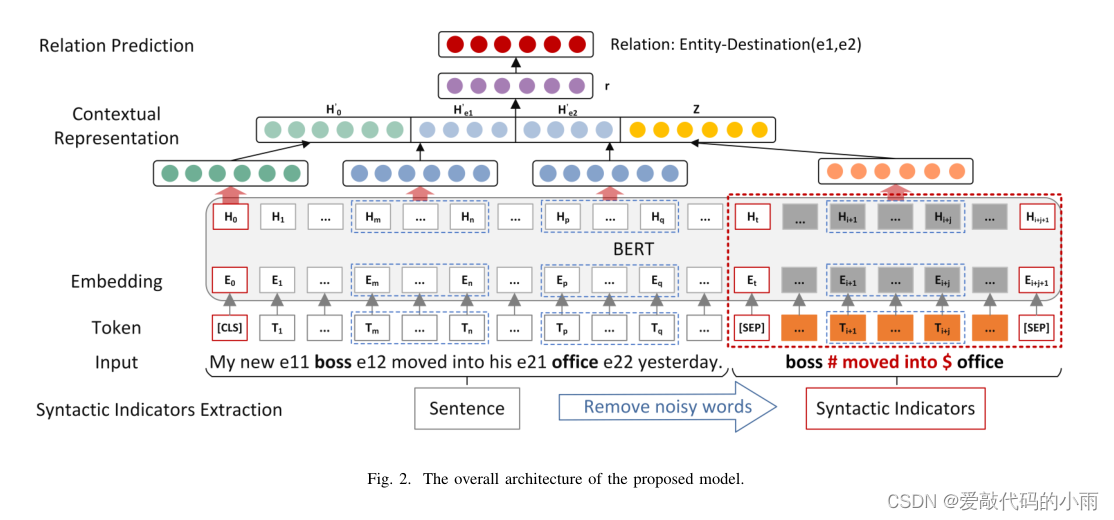
给定一个句子,我们首先在句法知识的指导下提取出相应的句法指示符(具体过程详见下文)。随后,整个句子和指示符序列在WordPiece标记化[29]后进行连接。然后,我们将聚合标记序列提供给一个基于bert的上下文编码器,以学习每个标记的深度双向表示。聚合序列、两个实体和句法指标的最终表示分别在后面的网络层中通过不同的操作获得。最后,将这些向量表示连接起来,得到最终的预测分布。
语法指示器的定义
定义:句法指示器是句子中的某些词或短语,为识别目标实体之间的语义关系提供必要的信息。
与文本触发器不同,句法指示器的表现形式丰富,而不是与固定的短语模板相匹配。
每个句子都有一个独特的句法指示符。它可以由任何动词、介词、代词或短语组成,取决于当前的语言表达。

如图3所示,caused by是第一个实例中的句法指示符。
据此,我们可以确定在两个目标实体e1=shock和e2=attack中存在Cause-Effect(e2,e1)关系。类似地,在其他两个实例中,我们可以识别出分别包含和使用基于ContentContainer(e1,e2)和基于Instrument-Agency(e2,e1)的关系。
句法指示符提取
我们通过删除不相关的单词从两个目标实体之间的文本中提取句法指示符。幸运的是,目标子序列可以通过实体标记从句子中访问。之后,在句法知识的指导下,我们获得句法指标。这些指标的特征如下:
a)实体消歧:带有连词and或or的名词,以及由两个以上名词组成的复合名词,将通过去除限制性词和补充词来消歧。如图3所示,将shock和anger转化为shock,将plastic case和propagation method转化为case和method,去掉标注下标1的高亮部分。标记数据中的每个实例只包含一个关系,如图3第一个例子中的关系是shock和attack,目标实体中的名词自然保留。
b)主成分提取:从文本中去除形容词、副词等修饰语,得到主成分,表达主要语义关系。
c)不相关实体去除:除两个目标实体外,去除任何其他已命名实体及其相应动作,得到如图3所示的shock caused by attack的指示器序列,coins are enclosed in case。在第三个实例中,删除不相关的实体路径及其相应的操作标识。
最后,我们从给定的句子中获得一个排他性的指示序列,该序列被认为没有任何无关词。语法指示器包含在两个目标实体之间。
基于bert的上下文编码器
预训练BERT语言表示模型[16]是一个多层双向变压器编码器[30],旨在通过在所有层中联合调节左右上下文来预训练深度双向表示。BERT的输入可以是一句话,也可以是一对句子。一个特殊的标记[CLS]总是每个序列的第一个标记。句子对用标记[SEP]分开,并打包成单个序列。BERT是第一个用于广泛任务(如问题回答和语言推理)的基于微调的表示模型,无需对任务特定的体系结构进行实质性修改。
由于最近BERT的广泛使用,我们将省略BERT体系结构的详尽背景描述。
a) BERT模块:给定句子S,我们在两个目标实体(e1, e2)的开头和结尾插入四个标记e11, e12, e21和e22,这有助于获取实体的位置。虽然相应的指示器序列S *总是以实体e1开始,以实体e2结束,但我们在e1后面插入#,在e2之前插入$来标记语法指示器。
为了对BERT进行微调,我们将两个序列都输入WordPiece标记器,然后将获得的子标记连接到单个标记序列T中。在BERT的原始实现之后,我们将一个令牌[CLS]添加到令牌序列的开头,并用令牌[SEP]分隔两个序列。然后,我们将T输入BERT以生成每个标记的当前表示。
b)聚合序列表示:BERT模块输出的最终隐藏状态序列H对应于每个令牌的面向任务的嵌入。假设H0是第一个特殊令牌[CLS]的隐藏状态,我们添加一个激活操作和一个全连接层,得到一个向量H0’作为聚合序列的表示。
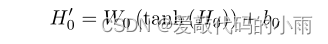
c)实体表示:隐藏状态Hm、Hn、Hp、Hq是四个实体标记e11、e12、e21、e22的向量表示。对于目标实体,向量之间Hm和Hn代表实体e1, Hp和Hq之间的向量代表实体e2。我们应用一个平均操作来得到一个单一的向量表示,然后是tanh激活操作和一个全连接层。在这一步中,两个实体共享相同的参数W e和be。如下式所示,两个目标实体的最终表示形式分别为He1、He2:
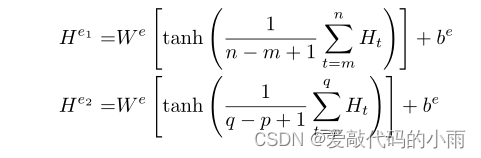
d)句法指标表示:Hi+1到Hi+j是对应于指标序列S *的隐藏状态向量。我们还应用了一个平均操作,后面是tanh激活操作和一个全连接层,以获得最终的表示形式:
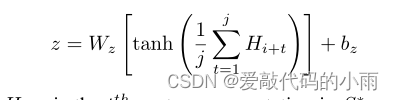
其中Hi+t是S *中的第t个向量。
为了进行微调,我们将H0’, He1, He2和z连接起来,然后连续添加两个权值为W1, W2,偏差为b1, b2的全连接层。最后,我们得到了一个用于关系分类的关系表示向量r。
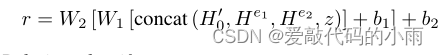
关系分类
给定一个实例x,包含整个句子S和指示器序列S *,我们可以通过关系编码器得到关系表示r。为了分类,我们应用一个完全连通的softmax层来产生一个关于所有预定义关系类型的概率分布
其中y∈y是目标关系类型,θ指的是网络中所有可学习参数,包括W∗∈r | y| ×dh和b∗∈r | y|,其中| y|是关系类型的数量。原文如下:

训练过程
为了明确区分不同的关系类别,减少噪声的影响,我们参考Santos等人[8]提出的秩损失函数,基于常用的交叉熵设计了损失函数。大小为k的批的总损耗L可表示为:
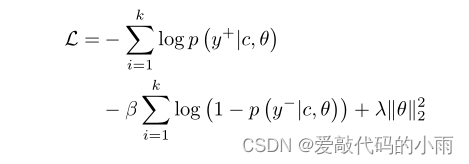
右侧的第一项随着概率p (y+|c, θ)的增加而减少,右侧具有超参数β的第二项随着概率p (y−|c, θ)的减少而减少。对于每一个实例,y+∈y是正确的关系标签,而y−∈y是在每一轮训练中所有错误关系类型中选择概率最高的否定类别:
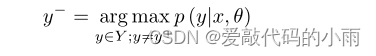
在关系抽取中,使用人工类Other来指代不属于任何自然类的目标实体之间的关系。因此,Other类太过嘈杂,没有共同的代表性特征,因为它由许多不同的关系类别组成。因此,我们计算除Other之外的每个关系类的损失,以减少噪声的影响,反映在损失函数中,如y+ ≠ Other和y− ≠ Other。
为了缓解过拟合,我们在训练过程中在完全连接的softmax层之前增加了一个dropout层,并在右侧用系数λ作为第三项约束L2正则化。 原文如下:


Experiment
数据集和评价指标
为了评估我们模型的性能,我们在SemEval-2010 Task 8数据集[31]上进行了实验,这是发布的关系提取基准。该数据集包含10717个带注释的实例,其中8000个用于训练,2717个用于测试。所有实例都用9种有向关系类型和一个人工类Other进行了注释。九种有向关系分别是因果关系、工具-代理关系、产品-生产者关系、内容容器关系、实体-起源关系、实体-目的地关系、组件整体关系、成员-集合关系和消息-主题关系。我们考虑了方向,关系类型的总数是19种。我们采用9个实际关系(不包括Other)的宏观平均F1-score来评估模型,这是SemEval-2010 Task 8的官方评估指标。
实验设置
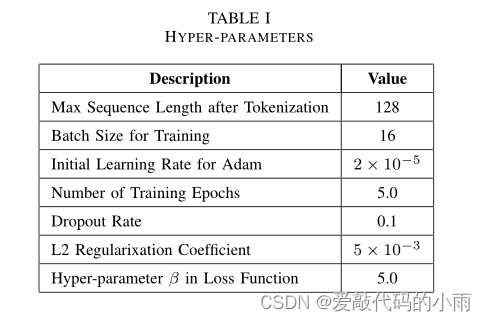
对于预训练的BERT模型,我们使用uncase模型来集成我们的方法。我们设置的超参数,提出的模型如表Ⅰ所示,并根据原[16]初始化预训练BERT模型的参数。
结果
各种神经模型的结果如表Ⅱ所示。基于所提出的方法,我们获得了一个强有力的实证结果。
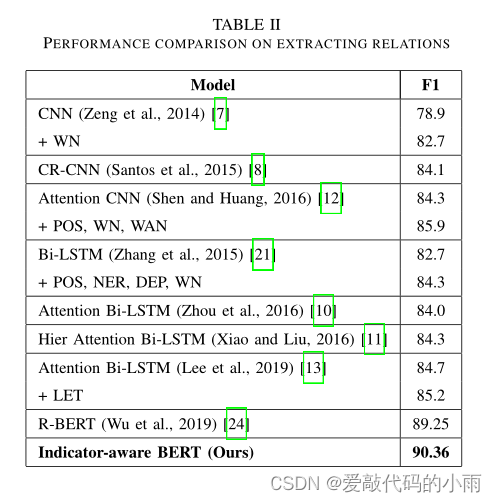
表II显示,我们的模型获得了90.36%的f1得分,大大优于最先进的模型。基于cnn和基于rnn的模型的最佳结果在84% - 86%之间,而Wu和He最近提出的R-BERT模型[24]获得了89.25%的最佳F1score,与以往的方法有大约4点的差距。值得注意的是,本文提出的引入句法指标的关系抽取模型在这项任务中有了进一步的性能提升。
分析
为了证明引入句法指标确实会影响关系提取,我们又创建了两个设置进行实验比较,并进一步建立另一个没有BERT结构的神经模型以获得更有力的证据。表III所示的实验结果充分证明,结合句法指标确实提高了关系提取的性能。
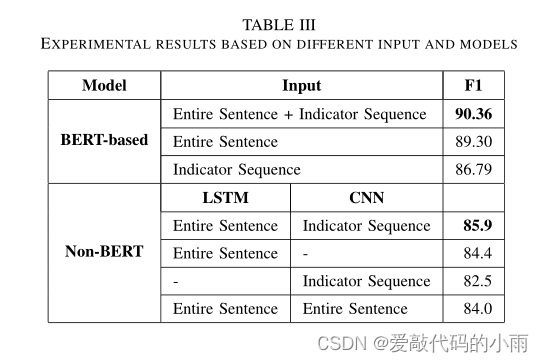
a)基于bert模型的实验:
•另外两个实验只使用其中一个序列,实验结果列在表III的第二行到第四行。仅使用整个句子作为输入的实验产生了89.30%的f1分数,比提出的方法低1.06%。虽然只有几个单词组成的指标序列,但仅使用指标序列的实验,f1得分为86.79%。可以说指示符序列包含足够的信息来分类关系,但可能提供不完整的信息。本文提出的基于bert的模型利用句法指示符和句子上下文进行关系提取,可以认为能够在减少噪声和捕获完整特征之间保持平衡。
b)不基于bert模型实验:
•我们构建了一个没有BERT结构的模型用于进一步确认,该模型由CNN模块和Bi-LSTM模块组成,CNN模块用于从指示序列中捕获指示特征,Bi-LSTM模块用于从整个句子中捕获上下文信息。从非bert结构模型得到的实验结果列在表III的第6行到第9行。结合两个模块的信息,该模型得到了85.9%的F1score,优于基于cnn和基于rnn的最佳模型。即使与使用WordNet、DPT、DEP、NLP标记或NER标记等高级词汇特征的方法相比,其效果也最好。
同样地,我们将其中一个序列分别输入模型。相应地,整个句子使用Bi-LSTM模块进行编码,而语法指示符使用CNN模块进行编码。不出所料,这两个f1分数都不差,但较低,这进一步证明了语法指标对关系表示的约束的有效性。
•我们分别使用CNN模块和Bi-LSTM模块对整个句子进行两次特征捕获,然后将它们结合起来进行最终预测,结果反而变差了。这证明句子中存在与实体关系无关的噪声信息,过度使用不相关特征作为关系特征会降低关系提取的性能。因此,对语义关系表示进行约束以避免噪声信息的影响是非常必要的。
c)表IV显示了各关系猫的句法指标对精准度、召回率和f1得分的贡献
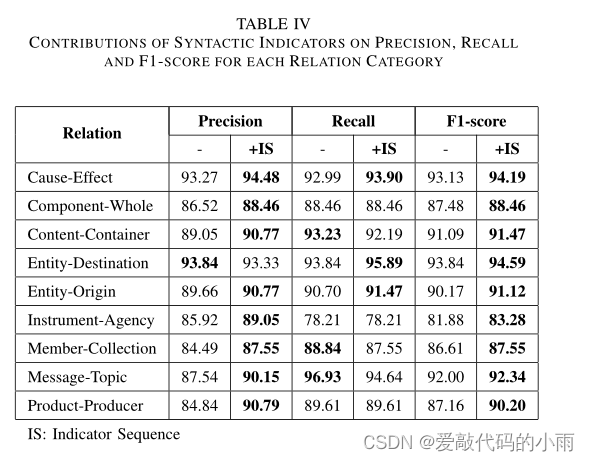
egory(在基于bert的模型上执行)。结合句法指标的模型提高了每个类别的f1得分,其中除实体-目的地以外的所有类别的精度都提高了,大多数类别的召回率都得到了改善或保持不变。其中,InstrumentAgency、Member-Collection、Message-Topic和ProductProducer的精度分别提高了3.13、3.06、2.61和5.95个百分点。句法指标的影响在这些类别上体现得更为突出,因为包含此类关系的实例在目标实体之间的文本中通常有更多的噪声词。
Conclusion
在本文中,我们提出了对词汇词形不敏感的句法指标和一种新的指标感知神经模型,利用句法指标和句子上下文来完成关系提取。该方法在基于bert的模型上执行,在SemEval-2010 Task 8中获得了90.36%的F1score,优于最先进的方法。非bert模型的实现在基于cnn和基于rnn的模型中也取得了最好的效果。由于引入了句法指标,在减少噪声影响的同时,捕获了更多的决定性特征用于分类关系,该方法有效地提高了关系提取的性能。
在未来,我们希望利用句法指示器进行更复杂的多关系提取和远监督关系提取。进一步,我们将研究如何利用深度神经网络在句子中自动定位指标,而不是在句法知识的指导下提取指标。