机器学习100天,今天讲的是:K 近邻分类算法-理论。
《机器学习100天》完整目录:目录
一、什么是 K 近邻算法
K 近邻算法也叫 KNN(k-Nearest Neighbor)算法,它是一个比较成熟也是最简单的机器学习算法之一。K 近邻分类算法的思路是:如果一个样本在特征空间中与 K 个实例最为相似(即特征空间中最邻近),那么这 K 个实例中大多数属于哪个类别,则该样本也属于这个类别。
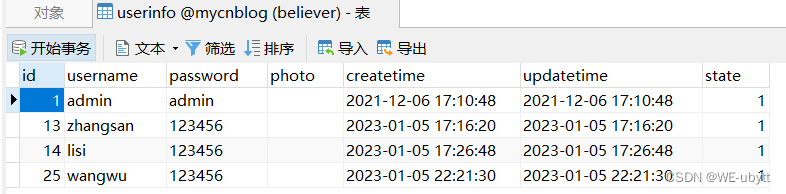
如上面这张图所示,二维平面上有两个类别:红色三角形表示类别 0,蓝色正方形表示类别 1,现在有一个绿色圆形样本,判断它属于哪一类?如果选择 k=3 的话,则在距离绿色样本最近的 3 个实例中(这个黑色圆圈所在的范围),有两个是红色三角形,一个是蓝色正方形。则算法判断该样本属于红色三角形,即类别 0。
KNN 算法在训练过程中,将所有训练样本的输入和输出标签(label)都存储起来。测试过程中,计算测试样本与每个训练样本的距离,选取与测试样本距离最近的前 k 个训练样本。然后对着 k 个训练样本的 label 进行投票,票数最多的那一类别即为测试样本的类别。KNN 算法实际上是一种识记类算法,但它也包含了以下几个缺点:
- 训练过程需要将所有的训练样本极其输出标签存储起来,因此,空间成本很大。







![[Leetcode] 相交链表](https://img-blog.csdnimg.cn/img_convert/24cd0142f9a44a06ca801822018a05ba.png)