一、简介
还是那句话,"时间序列+金融"是一个很有"钱"景的话题,还是想尝试采用Stock+时间序列预测任务+DeepLearning。本文提供了LSTM预测股票的源代码。
二、算法原理
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),用于处理和预测序列数据的时间依赖性。LSTM 能够学习长期依赖信息,解决了传统 RNN 在长序列训练过程中遇到的梯度消失或梯度爆炸问题。
LSTM 通过引入三个门(遗忘门、输入门和输出门)和一个单元状态来解决长期依赖问题。这些门控制着信息的保留、遗忘与更新,使得 LSTM 能够有效地保留长期记忆并过滤掉不相关信息。单元状态在时间序列中穿行,允许信息的长期流动。门控制机制让 LSTM 有能力学习决定何时更新记忆、何时重置记忆以及何时让记忆通过无损坏地。
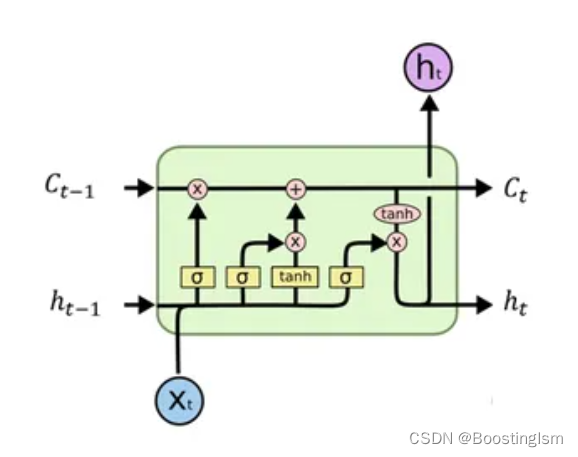
1. 输入门(Input Gate)
LSTM的每个单元接收三个输入:当前时刻的输入数据,上一个时刻的隐藏状态
,以及上一个时刻的单元状态
。输入门用来决定哪些新的信息将被添加到单元状态。
-
忘记门层(Forget Gate Layer):首先,用一个sigmoid函数来决定从单元状态中丢弃什么信息。这个步骤通过
计算得出,其中
是权重矩阵,
是偏置项。
-
输入门层(Input Gate Layer):接着,使用另一个sigmoid层来决定将哪些新信息更新到单元状态中,
。同时,一个tanh层会创建一个新的候选值向量
,与
相乘,以决定更新什么值。
2. 更新单元状态(Update Cell State)
单元状态
通过忘记旧信息(乘以
)和增加新信息
来更新。
- 首先,之前的单元状态通过与忘记门的输出相乘,丢弃我们决定忘记的信息。
- 接着,将输入门的输出与新的候选值相乘,来增加新的信息。
- 单元状态的更新公式为
,这使得网络能够在每个时刻自行调节信息的存储。
3. 输出门(Output Gate)和隐藏状态
最后,决定输出的部分信息基于单元状态,但首先会过一个激活函数(通常是tanh)来确保数据值位于-1到1之间,然后乘以输出门(通过sigmoid层决定哪一部分的单元状态将输出)的输出。
-
输出门层(Output Gate Layer):
,决定了单元状态中哪些信息将用于输出。
-
计算当前时刻隐藏状态((h_t)):
,这里,我们将单元状态通过tanh激活函数处理(为了规范化),并且将其与输出门的输出相乘,来决定最终的输出是什么。
三、代码
运行代码时的注意事项:按照配置项创建好对应的文件夹,准备好数据,数据来源我的上一篇blog《【Time Series】获取股票数据代码实战》可以找到。
import os
import random
from tqdm import tqdm
import joblib
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error,mean_absolute_error
#配置项
class configs():
def __init__(self):
# Data
self.data_input_path = r'../data/input'
self.data_output_path = r'../data/output'
self.save_model_dir = '../data/output'
self.data_inputfile_name = r'五粮液.xlsx'
self.data_BaseTrue_infer_output_name = r'基于真实数据推理结果.xlsx'
self.data_BaseSelf_infer_output_name = r'基于自回归推理结果.xlsx'
self.data_split_ratio = "0.8#0.1#0.1"
self.model_name = 'LSTM'
self.seed = 2024
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.epoch = 50
self.train_batch_size = 16
self.in_seq_embeddings = 1 #输入的特征维度
self.out_seq_embeddings = 1 #输出的特征维度
self.in_seq_length = 5 #输入的时间窗口
self.out_seq_length = 1 #输出的时间窗口
self.hidden_features = 16 # 隐层数量
self.learning_rate = 0.001
self.dropout = 0.5
self.istrain = True
self.istest = True
self.BaseTrue_infer = True
self.BaseSelf_infer = True
self.num_predictions = 800
cfg = configs()
def seed_everything(seed=2024):
random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
seed_everything(seed = cfg.seed)
#数据
class Define_Data():
def __init__(self,task_type='train'):
self.scaler = MinMaxScaler()
self.df = pd.DataFrame()
self.task_type = task_type
#用于更新输入数据,设定选用从m行到n行的数据进行训/测,use_lines = "[m,n]"/"-1"
def refresh_df_data(self,tmp_df_path,tmp_df_sheet_name,use_lines):
self.df = pd.read_excel(tmp_df_path, sheet_name=tmp_df_sheet_name)
if use_lines != "-1":
use_lines = eval(use_lines)
assert use_lines[0] <= use_lines[1]
self.df = self.df.iloc[use_lines[0]:use_lines[1],:]
#创建时间窗口数据,in_seq_length 为输入时间窗口,out_seq_length 为输出时间窗口
def create_inout_sequences(self,input_data, in_seq_length, out_seq_length):
inout_seq = []
L = len(input_data)
for i in range(L - in_seq_length):
# 这里确保每个序列将是 tw x cfg.out_seq_length 的大小,这对应于 (seq_len, input_size)
train_seq = input_data[i:i + in_seq_length][..., np.newaxis] # np.newaxis 增加一个维度
train_label = input_data[i + in_seq_length:i + in_seq_length + out_seq_length, np.newaxis]
inout_seq.append((train_seq, train_label))
return inout_seq
#将时序数据转换为模型的输入形式
def _collate_fn(self,batch):
# Each element in 'batch' is a tuple (sequence, label)
# We stack the sequences and labels separately to produce two tensors
seqs, labels = zip(*batch)
# Now we reshape these tensors to have size (seq_len, batch_size, input_size)
seq_tensor = torch.stack(seqs).transpose(0, 1)
# For labels, it might be just a single dimension outputs,
# so we only need to stack and then add an extra dimension if necessary
label_tensor = torch.stack(labels).transpose(0, 1)
if len(label_tensor.shape) == 2:
label_tensor = label_tensor.unsqueeze(-1) # Add input_size dimension
return seq_tensor, label_tensor
#将表格数据构建成tensor格式
def get_tensor_data(self):
#缩放
self.df['new_close'] = self.scaler.fit_transform(self.df[['close']])
inout_seq = self.create_inout_sequences(self.df['new_close'].values,
in_seq_length=cfg.in_seq_length,
out_seq_length=cfg.out_seq_length)
if self.task_type == 'train':
# 准备训练数据
X = torch.FloatTensor(np.array([s[0] for s in inout_seq]))
y = torch.FloatTensor(np.array([s[1] for s in inout_seq]))
# 划分训练集和测试集
data_split_ratio = cfg.data_split_ratio
data_split_ratio = [float(d) for d in data_split_ratio.split('#')]
train_size = int(len(inout_seq) * data_split_ratio[0])
val_size = int(len(inout_seq) * (data_split_ratio[0]+data_split_ratio[1])) - train_size
test_size = int(len(inout_seq)) - train_size - val_size
train_X, train_y = X[:train_size], y[:train_size]
val_X, val_y = X[train_size:val_size], y[train_size:val_size]
test_X, test_y = X[val_size:], y[val_size:]
# 注意下面的 batch_first=False
batch_size = cfg.train_batch_size
train_data = TensorDataset(train_X, train_y)
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size, drop_last=True,
collate_fn=self._collate_fn)
val_data = TensorDataset(val_X, val_y)
val_loader = DataLoader(val_data, shuffle=False, batch_size=1, collate_fn=self._collate_fn)
test_data = TensorDataset(test_X, test_y)
test_loader = DataLoader(test_data, shuffle=False, batch_size=1, collate_fn=self._collate_fn)
return train_loader,val_loader, test_loader, self.scaler
elif self.task_type == 'test' or 'infer':
# 准备测试数据
X = torch.FloatTensor(np.array([s[0] for s in inout_seq]))
y = torch.FloatTensor(np.array([s[1] for s in inout_seq]))
test_data = TensorDataset(X, y)
test_loader = DataLoader(test_data, shuffle=False, batch_size=1, collate_fn=self._collate_fn)
return test_loader, self.scaler
# 模型定义
#################网络结构#################
class LSTM(nn.Module):
def __init__(self, input_size=10, hidden_layer_size=20, output_size=1):
super(LSTM,self).__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.batch_size = cfg.train_batch_size
self.hidden_cell = (torch.zeros(1, self.batch_size, self.hidden_layer_size),
torch.zeros(1, self.batch_size, self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq, self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq) * self.batch_size, -1))
# Only return the predictions from the last timestep
return predictions.view(len(input_seq), self.batch_size, -1)[-1]
def reset_hidden_state(self,tmp_batch_size):
###该函数
self.batch_size = tmp_batch_size
self.hidden_cell = (torch.zeros(1, tmp_batch_size, self.hidden_layer_size),
torch.zeros(1, tmp_batch_size, self.hidden_layer_size))
class my_run():
def train(self):
Dataset = Define_Data(task_type='train')
Dataset.refresh_df_data(tmp_df_path=os.path.join(cfg.data_input_path,cfg.data_inputfile_name),
tmp_df_sheet_name='数据处理',
use_lines='[0,3000]')
train_loader,val_loader,test_loader,scaler = Dataset.get_tensor_data()
model = LSTM(cfg.in_seq_embeddings, cfg.hidden_features,cfg.out_seq_length).to(cfg.device)
# 定义损失函数和优化器
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=cfg.learning_rate, weight_decay=5e-4)
model.train()
loss_train_all = []
for epoch in tqdm(range(cfg.epoch)):
#训练集
predictions = []
test_labels = []
for seq, labels in train_loader:
optimizer.zero_grad()
model.reset_hidden_state(tmp_batch_size=cfg.train_batch_size) # 重置LSTM隐藏状态
y_pred = model(seq)
loss_train = loss_function(torch.squeeze(y_pred), torch.squeeze(labels))
loss_train_all.append(loss_train.item())
loss_train.backward()
optimizer.step()
predictions.append(y_pred.squeeze().detach().numpy()) # Squeeze to remove extra dimensions
test_labels.append(labels.squeeze().detach().numpy())
train_mse,train_mae = self.timeseries_metrics(predictions=predictions,
test_labels=test_labels,
scaler=Dataset.scaler)
#测试val集
predictions = []
test_labels = []
with torch.no_grad():
for seq, labels in test_loader:
model.reset_hidden_state(tmp_batch_size=1)
y_test_pred = model(seq)
# 保存预测和真实标签
predictions.append(y_test_pred.squeeze().detach().numpy()) # Squeeze to remove extra dimensions
test_labels.append(labels.squeeze().detach().numpy())
val_mse,val_mae = self.timeseries_metrics(predictions=predictions,
test_labels=test_labels,
scaler=Dataset.scaler)
print('Epoch: {:04d}'.format(epoch + 1),
'loss_train: {:.4f}'.format(np.mean(loss_train_all)),
'mae_train: {:.8f}'.format(train_mae),
'mae_val: {:.8f}'.format(val_mae)
)
torch.save(model, os.path.join(cfg.save_model_dir, 'latest.pth')) # 模型保存
joblib.dump(Dataset.scaler,os.path.join(cfg.save_model_dir, 'latest_scaler.save')) # 数据缩放比例保存
def test(self):
#Create Test Processing
Dataset = Define_Data(task_type='test')
Dataset.refresh_df_data(tmp_df_path=os.path.join(cfg.data_input_path,cfg.data_inputfile_name),
tmp_df_sheet_name='数据处理',
use_lines='[2995,4000]')
Dataset.scaler = joblib.load(os.path.join(cfg.save_model_dir, 'latest_scaler.save'))
test_loader,_ = Dataset.get_tensor_data()
model_path = os.path.join(cfg.save_model_dir, 'latest.pth')
model = torch.load(model_path, map_location=torch.device(cfg.device))
model.eval()
params = sum(p.numel() for p in model.parameters())
predictions = []
test_labels = []
with torch.no_grad():
for seq, labels in test_loader:
model.reset_hidden_state(tmp_batch_size=1)
y_test_pred = model(seq)
# 保存预测和真实标签
predictions.append(y_test_pred.squeeze().detach().numpy()) # Squeeze to remove extra dimensions
test_labels.append(labels.squeeze().detach().numpy())
_, val_mae = self.timeseries_metrics(predictions=predictions,
test_labels=test_labels,
scaler=Dataset.scaler)
print('Test set results:',
'mae_val: {:.8f}'.format(val_mae),
'params={:.4f}k'.format(params / 1024)
)
def BaseTrue_infer(self):
# Create BaseTrue Infer Processing
Dataset = Define_Data(task_type='infer')
Dataset.refresh_df_data(tmp_df_path=os.path.join(cfg.data_input_path, cfg.data_inputfile_name),
tmp_df_sheet_name='数据处理',
use_lines='[4000,4870]')
Dataset.scaler = joblib.load(os.path.join(cfg.save_model_dir, 'latest_scaler.save'))
test_loader, _ = Dataset.get_tensor_data()
model_path = os.path.join(cfg.save_model_dir, 'latest.pth')
model = torch.load(model_path, map_location=torch.device(cfg.device))
model.eval()
params = sum(p.numel() for p in model.parameters())
predictions = [] #模型推理值
test_labels = [] #标签值,可以没有
with torch.no_grad():
for seq, labels in test_loader:
model.reset_hidden_state(tmp_batch_size=1)
y_test_pred = model(seq)
# 保存预测和真实标签
predictions.append(y_test_pred.squeeze().detach().numpy()) # Squeeze to remove extra dimensions
test_labels.append(labels.squeeze().detach().numpy())
predictions = np.array(predictions)
test_labels = np.array(test_labels)
predictions_rescaled = Dataset.scaler.inverse_transform(predictions.reshape(-1, 1)).flatten()
test_labels_rescaled = Dataset.scaler.inverse_transform(test_labels.reshape(-1, 1)).flatten()
pd.DataFrame({'test_labels':test_labels_rescaled,'模型推理值':predictions_rescaled}).to_excel(os.path.join(cfg.save_model_dir,cfg.data_BaseTrue_infer_output_name),index=False)
print('Infer Ok')
def BaseSelf_infer(self):
# Create BaseSelf Infer Processing
Dataset = Define_Data(task_type='infer')
Dataset.refresh_df_data(tmp_df_path=os.path.join(cfg.data_input_path, cfg.data_inputfile_name),
tmp_df_sheet_name='数据处理',
use_lines='[4000,4870]')
Dataset.scaler = joblib.load(os.path.join(cfg.save_model_dir, 'latest_scaler.save'))
test_loader, _ = Dataset.get_tensor_data()
initial_input, labels = next(iter(test_loader))
model_path = os.path.join(cfg.save_model_dir, 'latest.pth')
model = torch.load(model_path, map_location=torch.device(cfg.device))
model.eval()
params = sum(p.numel() for p in model.parameters())
predictions = [] #模型推理值
with torch.no_grad():
for _ in range(cfg.num_predictions):
model.reset_hidden_state(tmp_batch_size=1)
y_test_pred = model(initial_input)
# 将预测结果转换为适合再次输入模型的形式
next_input = torch.cat((initial_input[1:, ...], y_test_pred.unsqueeze(-1)), dim=0)
initial_input = next_input
# 保存预测和真实标签
predictions.append(y_test_pred.squeeze().item()) # Squeeze to remove extra dimensions
predictions_rescaled = Dataset.scaler.inverse_transform(np.array(predictions).reshape(-1, 1)).flatten()
pd.DataFrame({'模型推理值': predictions_rescaled}).to_excel(os.path.join(cfg.save_model_dir,cfg.data_BaseSelf_infer_output_name), index=False)
print('Infer Ok')
def timeseries_metrics(self,predictions,test_labels,scaler):
# 反向缩放预测和标签值
predictions = np.array(predictions)
test_labels = np.array(test_labels)
# 此处假设predictions和test_labels是一维数组,如果不是,你可能需要调整reshape的参数
predictions_rescaled = scaler.inverse_transform(predictions.reshape(-1, 1)).flatten()
test_labels_rescaled = scaler.inverse_transform(test_labels.reshape(-1, 1)).flatten()
# 计算MSE和MAE
mse = mean_squared_error(test_labels_rescaled, predictions_rescaled)
mae = mean_absolute_error(test_labels_rescaled, predictions_rescaled)
# print(f"Test MSE on original scale: {mse}")
# print(f"Test MAE on original scale: {mae}")
return mse,mae
if __name__ == '__main__':
myrun = my_run()
if cfg.istrain == True:
myrun.train()
if cfg.istest == True:
myrun.test()
if cfg.BaseTrue_infer == True:
myrun.BaseTrue_infer()
if cfg.BaseSelf_infer == True:
myrun.BaseSelf_infer()四、结果展示
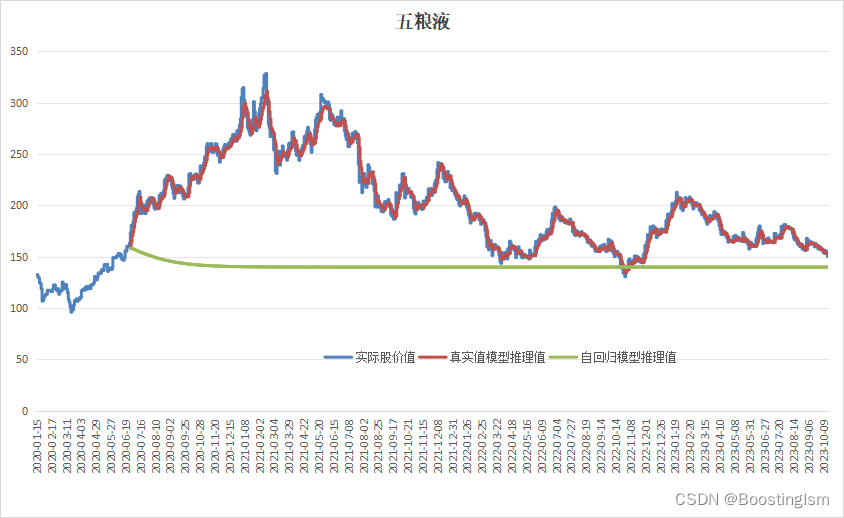
本文代码,配置了两种预测模式,第一种,BaseTrue_infer:根据真实数据预测下一个点,然后循环用的真实数据;第二种,BaseSelf_infer:根据预测数据自回归预测下一个点,然后循环用的预测数据。实际用的一般都是第二种才有实用价值,当然本文时序预测的训练模式没有采用长距离自动纠偏的trick,所以第二种预测就直接坍塌了。后续可以研究探讨长时间预测如何进行。下面贴上在"五粮液"股价收盘价上的实验结果。

![Redis常见数据类型[上]](https://img-blog.csdnimg.cn/direct/c1256df01b9e4632b217d7d85c9e1f89.png)




![[BUUCTF]-Web:[GXYCTF2019]Ping Ping Ping解析](https://img-blog.csdnimg.cn/direct/d364a04288eb463c99367bcf0a98cba4.png)