Adventure Works案例分析
前言
数据时代来临,但一个人要顺应时代的发展是真理。
数据分析的核心要素
那数分到底是什么?
显然DT 并不等同于 IT,我们需要的不仅仅是更快的服务器、更多的数据、更好用的工具。这些都是重要的组成部分,但还不是数据分析的全部。在目前这个信息过载的年代,数分的核心价值尤为凸显,甚至比以往更加重要。
我们尝试从这中文去理解“数据分析”(简称数分)的实质。数分是一门关于将通过分析于解释数字与凭据之间特征从而获取价值的学科。数分是一门综合性的学科,你需要懂得多于一个角度的知识才能成为真正意义上的数分人员。
对于数分从业人员,你需要掌握以下三方面的知识。你可以有偏重某一个领域,但同时也应该意识到其他领域的重要性与必要性。


微软靠成熟的SQL方案
当需要处理规模庞大的企业级别数据时,自助分析模式就显得力不从心,存在明显的弊端。
(1) 非中心化数据模型设计无法形成唯一可信数据源。
(2) 自助模式缺乏企业复杂模型设计的能力。
(3) 无法满足企业规模化分析性能的需求。
(4) 缺乏表级别和列级别的安全控制。
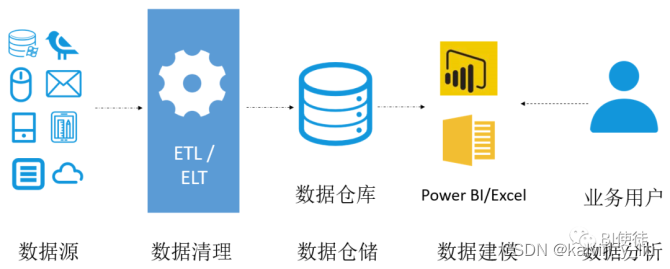
为解决以上挑战,企业方案会选择在数据仓库与前端工具中间安装SSAS(SQL Server Analysis Service,微软SQL分析服务),您可以理解SSAS为一个专门的OLAP(On-Line Analytical Processing,在线分析处理)工具,当用户进行查询服务时,OLAP分析系统可更快地响应查询请求,支持稳定的性能输出。再者,所有的模型与安全设置都在SSAS层面完成,更符合了企业模型中心化设计的理念,见下图SSAS的功能定位 。

图中的ETL/ELT代表两种不同的数据清理过程分别是Extract Transform Load (提取 转换 加载)/ Extract Load Transform (提取 加载 转换)。在企业级BI解决方案中,这部分工作由专门的工具完成,在自助式BI中,Power BI中的Power Query可独立完成此功能。
Analysis Services是微软企业级BI的代表,全称SQL Server Analysis Services(SSAS),是SQL Server产品中的一个组件。相信大多数读者都听过微软的SQL Server产品,一款经典的数据库工具,1989年出道的SQL可谓是IT老江湖了,下图为经典SQL操作界面。
经过多年的摸爬滚打发展,SQL Server从最初仅有的数据存储方案,跃身成为数据功能丰富的数据解决方案。SQL Server提供了三大核心利器,分别是:SSIS(SQL Server Integration Services,SQL服务器集成服务)、SSAS(SQL Server Analysis Services, SQ服务器分析服务)、SSRS(SQL Server Reporting Services,SQL服务器报表服务)[GY5] ,它们提供的实质功能分别是数据准备方案(SSIS)、数据模型方案(SSAS)和分析报表方案(SSRS)。
对于没商务智能背景的读者而言,这样解释也许稍显难以理解,我们有一幅通俗易懂的来说明三者在BI领域中的作用,下图将数据分析过程比喻为烹饪的三个必要步骤:洗菜(数据准备)、烹饪(数据建模)、就餐(数据呈现)。
对于一个完整的数据分析过程,这三步是缺一不可的。微软靠成熟的SQL方案,占据市场的主导地位。时过境迁,如今SSRS服务已经渐渐退出舞台,取而代之的是Power BI服务,后者在敏捷性与可视化能力层面皆全面明显地超越SSRS。SSIS服务也渐渐被Azure Data Factory与Databricks等新产品部分取代。而SSAS作为企业级中心化数据模型方案,至今还是广受欢迎,在短时间内还没有替代SSAS的产物。
数据仓库建模——维度表、事实表与星型模式
一、维度建模的基本概念
维度建模(dimensional modeling)是专门用于分析型数据库、数据仓库、数据集市建模的方法。
它本身属于一种关系建模方法,但和在操作型数据库中介绍的关系建模方法相比增加了两个概念:
1. 维度表(dimension)
表示对分析主题所属类型的描述。
比如"昨天早上张三在京东花费200元购买了一个皮包"。那么以购买为主题进行分析,可从这段信息中提取三个维度:时间维度(昨天早上),地点维度(京东), 商品维度(皮包)。通常来说维度表信息比较固定,且数据量小。
2. 事实表(fact table)
表示对分析主题的度量。
比如上面那个例子中,200元就是事实信息。
- 事实表包含了与各维度表相关联的外码,并通过JOIN方式与维度表关联。
- 事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。
二、维度建模的三种模式
1. 星形模式
星形模式(Star Schema)是最常用的维度建模方式,下图展示了使用星形模式进行维度建模的关系结构:
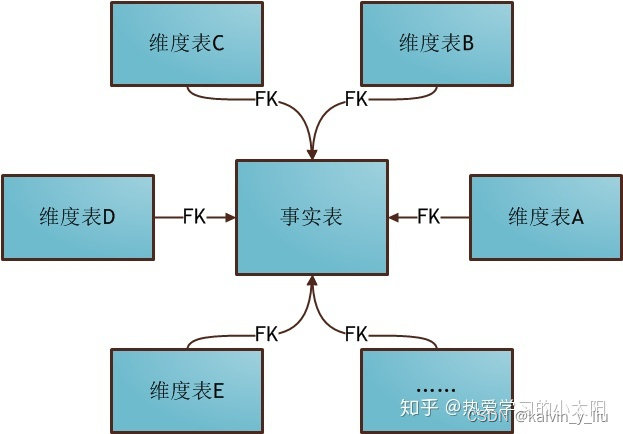
星型模式可以看出,星形模式的维度建模由一个事实表和一组维度表组成,且具有以下特点:
- 维度表只和事实表关联,维度表之间没有关联;
- 每个维度表的主码为单列,且该主码放置在事实表中,作为两边连接的外码;
- 以事实表为核心,维度表围绕核心呈星形分布。
2. 雪花模式
雪花模式(Snowflake Schema)是对星形模式的扩展,每个维度表可继续向外连接多个子维度表。下图为使用雪花模式进行维度建模的关系结构:
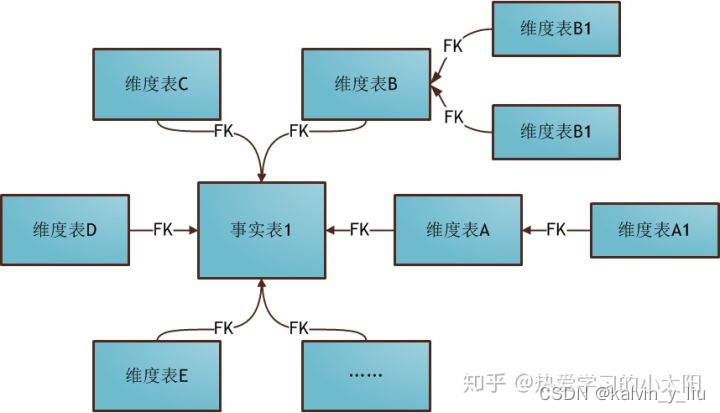
雪花模式
- 星形模式中的维度表相对雪花模式来说要大,而且不满足规范化设计。
- 雪花模型相当于将星形模式的大维度表拆分成小维度表,满足了规范化设计。然而这种模式在实际应用中很少见,因为这样做会导致开发难度增大,而数据冗余问题在数据仓库里并不严重。
3. 星座模式
星座模式(Fact Constellations Schema)也是星型模式的扩展。基于这种思想就有了星座模式:
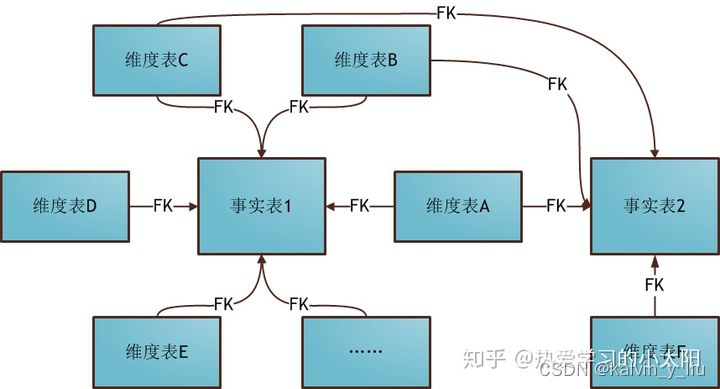
星座模式
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
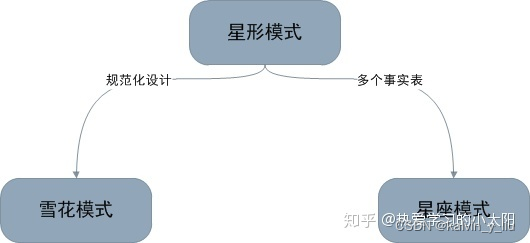
4. 三种模式对比
归纳一下,星形模式/雪花模式/星座模式的关系如下图所示:
三种模式的关系
雪花模式是将星型模式的维表进一步划分,使各维度表均满足规范化设计。而星座模式则是允许星形模式中出现多个事实表。
三、建模技巧
通常在需求搜集完毕后,便可进行维度建模了。Adventure Work Cycles案例即可采用星形模型维度建模。但不论采取何种模式,维度建模的关键在于明确下面四个问题:
1. 哪些维度对主题分析有用?
Adventure Work Cycles案例中,根据产品种类、销售区域、时间,对销售额、销量进行分析是非常有帮助的。
2. 如何使用现有数据生成维度表?
Adventure Work Cycles案例中,样本数据已经生成维度表。
3. 用什么指标来"度量"主题?
Adventure Work Cycles案例的主题是销售,而销量和销售额这两个指标最能直观反映销售情况,此外客单价、平均运费、平均税率等指标也可以进行分析。
4. 如何使用现有数据生成事实表?
Adventure Work Cycles案例中,样本数据已经生成事实表。
明确这四个问题后,便能轻松完成维度建模。
一、项目背景介绍:
Adventure Works Cycles是Adventure Works样本数据库所虚构的公司,这是一家大型跨国制造公司。该公司生产和销售自行车到北美,欧洲和亚洲的商业市场。虽然其基地业务位于华盛顿州博塞尔,拥有290名员工,但几个区域销售团队遍布整个市场。
1、客户类型
这家公司的客户主要有两种:
- 个体:这些客户购买商品是通过网上零售店铺;
- 商店:这些是从Adventure Works Cycles销售代表处购买转售产品的零售店或批发店。
2、产品介绍
这家公司主要有下面四个产品线:
- Adventure Works Cycles生产的自行车;
- 自行车部件,例如车轮,踏板或制动组件;
- 从供应商处购买的自行车服装,用于转售给Adventure Works Cycles的客户;
- 从供应商处购买的自行车配件,用于转售给Adventure Works Cycles的客户。
- 项目数据来源:数据来源于adventure Works Cycles公司的的样本数据库。
二、需求分析与实现
项目目标:通过现有数据监控商品的线上和线下销售情况,并且获取最新的商品销售趋势,以及区域分布情况,为公司的制造和销售提供指导性建议,以增加公司的收益。
项目任务:
将数据导入Hive数据库
探索数据库并罗列分析指标
汇总数据建立数据仓库(Sales主题)
1、建表以及数据导入
目标:为了操作方便,不直接在hive里面去建表、导数,而是把建表、导数语句写入shell脚本中,然后在Linux服务器上运行脚本,从而实现在hive库里面建表、导数。
AdventureWorksDW-data-warehouse-install-script.zip是数据源文件,里面有一个.sql文件,还有29个csv文件,需要根据.sql文件内容创建hive表,并把csv数据导入对应的表中。
注意,这里csv文件的分隔符是 | ,而建表格式用的是逗号,需要用代码处理一下分隔符。
这里采用的是hive数据库,它是一个用作数据仓库的数据库,可以存储很大的数据量,但是缺点是实时性不高、计算速度慢,优点是可以进行大数据量的计算存储。生产里面一般用作底层数据的存储运算,生成应用层汇总层的数据后,再把数据推送到生成数据库,如mysql等。
(1)提取建表语句
从.sql文件中提取建表语句,存放到create_table.txt中。
CREATE TABLE [dbo].[DimCurrency](
[CurrencyKey] [int] IDENTITY(1,1) NOT NULL,
[CurrencyAlternateKey] [nchar](3) NOT NULL,
[CurrencyName] [nvarchar](50) NOT NULL
) ON [PRIMARY];
GO
(2)建表
使用python代码解析create_table.txt文件,这里会用到文件读写、字符串的处理、正则表达式等方法。
定义一个字典,从create_table.txt中逐行读取这29个表的表名和字段名,并且存放在这个字典中。
create_file=open(r"create_table.txt")
table_info = {}
content=create_file.readline()
使用re.search(pattern,string),即在字符串中寻找模式,这里还用到了一个非贪婪匹配(.*?),re.I用于使匹配对大小写不敏感,group()用于提取分组截获的字符串,lstrip() 方法用于截掉字符串左边的空格或指定字符。
if "CREATE TABLE" in content.upper():
seobj = re.search(r"\[(.*?)\].\[(.*?)\]",content,re.I)
if seobj:
# 表名
table_name = seobj.group(2)
matOjb = re.search(r"\[(.*?)\] \[(.*?)\].*",content.lstrip(),re.I)
if matojb:
# 字段名
column = matojb.group(1)
# 类型
type = matojb.group(2)
table_columns.append([column,type])
创建create_table.sh文件,解析字典中的表名和字段名,在sh文件中写入建表语句,hive -e “sql建表语句”。
#! /bin/sh 是指此脚本使用/bin/sh来解释执行,#!是特殊的表示符,其后面跟的是解释此脚本的shell的路径。
hive -v -e,-v打印执行的sql语句,-e后面接执行的sql语句,无需进入hive。
shell_file = open(r"create_table.sh","w")
shell_file.writelines("#!/bin/sh\n\nhive -v -e\"\nuse adventure_huangj;\n\n")
shell_file.write(""")row format serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
with serdeproperties(
'field.delim'=',',
'serialization.encoding'='UTF-8')
stored as textfile;\n\n""")
shell_file.write("\";")
shell_file.close()
(3)数据格式转换
解析csv文件,进行格式转换,将分隔符 ‘|’ 转换为 ‘,’。
OS是操作系统(比如Windows)接口模块,该模块提供了一些方便使用操作系统相关功能的函数。使用os.walk() 方法,用于通过在目录树中游走输出在目录中的文件名。root 所指的是当前正在遍历的这个文件夹的本身的地址,dirs 是一个 list ,内容是该文件夹中所有的文件夹的名字(不包括子目录),即文件夹列表。files 同样是 list , 内容是该文件夹中所有的文件的名字(不包括子目录),即文件列表。os.path.join()用于拼接路径。
for root,dirs,files in os.walk(fromfile):
for file in files:
file_path = os.path.join(root,file)
使用read_csv()读取file_path路径下的文件,sep=“|”。然后用to_csv()输出成逗号分隔的csv文件,sep 默认是","。
df = pd.read_csv(file_path,sep="|",encoding="utf-16LE",header=None,na_values='null',dtype=str)
to_filepath=os.path.join(tofile,file)
df.to_csv(to_filepath,index=False,header=False,float_format=None,na_rep="null")
(4)导入数据
创建load_create_data.sh文件,将29个csv文件导入数据库对应的表中。
load_file = open("load_create_data.sh","w")
load_file.writelines("#!/bin/sh\n\nhive -v -e\"\nuse adventure_huangj;\n\n")
for key in table_info.keys():
load_file.write("load data local inpath \'/root/HuangJ/adventure/%s.csv\' overwrite into table %s;\n"%(key,key))
load_file.write("\n\";")
load_file.close()
2、探索数据并罗列分析指标
目的:了解数据库包含哪些信息,根据业务需要,罗列可分析的指标。
(1)查看数据库,了解包含哪些可用信息
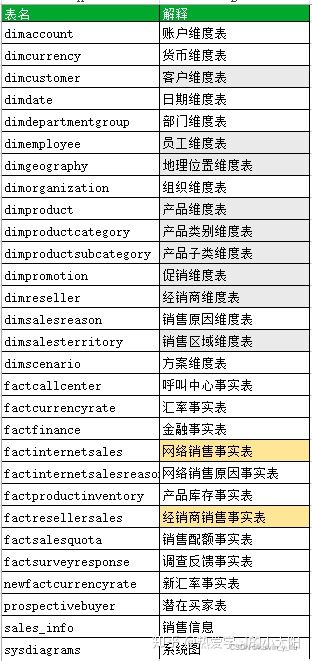
数据库共有29个表,主要可以分成两类,
- 一类是维度表(dim开头),
- 另一类是事实表(fact开头)。
两种表通过主键连接,表的设计结构为星型模型。
- 维度表:表示对分析主题属性的描述。
比如
- 地理位置维度表,包含地理位置id、城市、州/省代码、州/省名称、国家/地区代码等描述信息;
- 产品维度表,包含产品id、产品名称、颜色、尺寸、重量等描述信息。
通常来说维度表信息比较固定,且数据量小。
- 事实表:表示对分析主题的度量。
比如网络销售事实表,包含客户id、下单时间、销售额、下单量等信息。
- 事实表包含了与各维度表相关联的外码,并通过JOIN方式与维度表关联。
- 事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。
(2)明确分析目标,分解任务
结合项目目标和现有数据,明确分析目标是要向老板以及项目团队展示产品的销售情况;
整合数据仓库的数据,构建E-R图,挖掘销售事实表与各维度表的关联;
构建与销售相关的指标体系。
(3)数据分析与初步整理
产品的销售渠道有两种,
- 一种是线上销售(网络),销售数据存在factinternetsales事实表中;
- 另一种是线下销售(经销商),销售数据存在factresellersales事实表中。
a. E-R图
通过E-R图进一步分析事实表与各维度表之间的关联,比如线上销售渠道,
- factinternetsales事实表中productkey、customerkey、promotionkey、salesterritorykey等字段与维度表有关联。
同时,产品相关的维度表有三个,它们之间也存在一定的关联。
factresellersales事实表与factinternetsales事实表的区别在于,线上销售每一笔订单都直接面向最终客户,因此通过customerkey与dimcustomer维度表关联。
而线下销售是通过经销商进行售卖,每一笔订单都有记录经销商和销售人员的信息,因此通过resellerkey与dimreseller维度表关联,通过employee与dimemployee关联。
b. 指标体系
分析维度:
- 时间维度——年、季度、月、周、日
- 地区维度——销售大区、国家、州/省、城市
- 产品维度——产品类别、产品子类
- 推广维度
- 客户维度
- 经销商维度
- 员工维度
分析指标:
- 总销售额
- 总订单量
- 总成本=产品标准成本+税费+运费
- 总利润=总销售额-总成本
- 收入利润率=总利润/总销售额
- 客单价=总销售额/客户总数
- 税费
- 运费
- 销售额、销量目标达成率
- 不同维度(时间、地区、产品)下的销售额、订单量
3、建立数据仓库汇总层
目的:根据实际业务需要,对已经建立好的基础层数据进行加工,并存放到数据仓库汇总层。
- 数据仓库的设计分为两层,一个是 ODS 基础层,一个是 DW 汇总层 。
- 基础层用来存放基础数据,即前面使用shell脚本导入的数据,而汇总层用来存放我们使用基础层加工生成的数据。
前面已经从实际业务出发,分析了网络销售事实表(factinternetsales)、经销商销售事实表(factresellersales)与各维度表之间的关联,并且罗列出销售方面的关键分析指标。接下来需要建立一个汇总层,用于存放加工后的维度表以及新建的销售数据汇总表。
这里为什么要对维度表进行加工呢?虽然不经加工、直接导入PowerBI也可以,但是数据表较多、数据量较大,加载速度会很慢。而且字段太多,不是每一个字段都会用到。
所以这里的加工包括两个层面,一个是对相同类型的维度表做连接,减少表的数量;另一个是筛选过滤,提取需要分析的关键字段。
另外,这里对网络销售事实表(factinternetsales)和经销商销售事实表(factresellersales)进行整合,提取需要分析的字段(销售额、产品标准成本、运费、税费等),并且创建新的字段(成本、利润等),以便全面分析线上和线下的销售情况。
####(1)建立数据仓库
新建一个数据库,用于存放加工生成的数据,包括加工后的维度表和事实表。
####(2)维度表加工
a. 连接三个产品方面的维度表
连接三个与产品相关的维度表:产品维度表(dimproduct)、产品子类别维度表(dimproductsubcategory)、产品类别维度表(dimproductcategory)。提取需要使用的字段:产品id、产品名称、产品类别id、产品类别名称、产品子类id、产品子类名称。
create table product_dw as
select a.productkey,a.englishproductname,b.productcategorykey,c.englishproductcategoryname,a.productsubcategorykey,b.englishproductsubcategoryname
from adventure_huangj.dimproduct a
left join adventure_huangj.dimproductsubcategory b
on a.productsubcategorykey=b.productsubcategorykey
left join adventure_huangj.dimproductcategory c
on b.productcategorykey=c.productcategorykey;
b. 连接两个区域方面的维度表
连接两个与区域相关的维度表:区域维度表(dimsalesterritory)、地理位置维度表(dimgeography)。提取需要使用的字段:区域id、销售大区、销售国家、销售地区、州/省、地理位置id、城市。
create table territory_dw as
select a.salesterritorykey,a.salesterritorygroup,a.salesterritorycountry,a.salesterritoryregion,b.stateprovincename,b.geographykey,b.city
from adventure_huangj.dimsalesterritory a
left join adventure_huangj.dimgeography b
on a.salesterritorykey=b.salesterritorykey;
c. 从各维度表提取分析字段
客户维度表(dimcustomer):客户id、地理位置id、性别、婚姻状况,并且这里对出生日期(birthdate)字段进行处理,生成新的字段:年龄(age)。
create table customer_dw as
select customerkey,geographykey,gender,maritalstatus,
year(current_date())-year(concat_ws('-,substr(birthdate,1,4),substr(birthdate,5,2),substr(birthdate,7,2))) as age
from adventure_huangj.dimcustomer;
推广维度表(dimpromotion):推广id、推广名称、折扣百分比、推广类型、推广类别。
create table promotion_dw as
select promotionkey,englishpromotionname,discountpct,
englishpromotiontype,englishpromotioncategory from adventure_huangj.dimpromotion;
经销商维度表(dimreseller):经销商id、地理位置id、经销商名称、年销售额、年收入、开业年份。
create table reseller_dw as
select resellerkey,geographykey,resellername,annualsales,annualrevenue,yearopened
from adventure_huangj.dimreseller;
员工维度表(dimemployee):员工id、销售区域id、部门。
create table employee_dw as
select employeekey,salesterritorykey,departmentname
from adventure_huangj.dimemployee;
(3)事实表加工
创建销售汇总表sales_total_dw,这里使用union all连接网络销售事实表(factinternetsales)和经销商销售事实表(factresellersales),注意union all连接的两个表,列名和列数必须完全一致,否则会报错。为了区分每一笔订单是线上还是线下销售记录,新增一个标签销售渠道(sales_channel),线上为“internet”,线下为“reseller”。
有一点需要注意,事实表中的日期都是string格式,这里使用concat_ws()对字符串进行处理,转换成yyyy-mm-dd的格式。
部分代码如下:
create table sales_total_dw
as
(select ……
'null' as resellerkey,
'null' as employeekey,
'internet' as sales_channel
from adventure_huangj.factinternetsales)
union all
(select ……
'null' as customerkey,
resellerkey,
employeekey,
"reseller" as sales_channel
from adventure_huangj.factresellersales);
三、报表制作
目的:将汇总层数据导入Power BI,建立各表之间的关联,并制作销售报表。
1、数据导入
将Power BI连接到hive数据库,将加工后的事实表和维度表导入。
2、建立关联
如果在hive数据库汇总层中没有使用JOIN语句连接事实表与维度表,还可以通过Power BI-管理关系,建立加工后的事实表与加工后的维度表之间的关联,关系如下:
事实表与维度表的关系
3、制作报表
选择合适的可视化工具,从多个维度展示销售情况。
(1)数据清洗
数据格式:hive数据库中的数据导入后,可能需要进行格式转换。比如文本格式转换为日期格式,文本格式转换为整数格式,文本格式转换为小数格式,小数格式转换为百分比格式。虽然在汇总层中已经将日期处理成yyyy-mm-dd格式,但是在Power BI中默认是文本格式,要进行设置。这里想说明一点,虽然Power BI中可以设置格式,但是最好还是回到hive中进行数据清洗,否则刷新数据时可能会出现格式不匹配。
新建度量值:对于新增的客单价、收入利润率等指标,可以通过新建度量值的方式进行处理。当然,最好还是在hive中创建字段,这样代码对其他项目做销售数据分析更有借鉴意义。
(2)核心操作
可视化工具:这里用到的可视化工具有折线图、柱形图、折线-柱形组合图、仪表、卡片、柱状图、切片器、地图等。可以根据需要选择图例、轴、列,以及设置数据处理方式,求和、平均值、最大值、最小值等。
筛选器:有三种筛选器:视觉对象、此页、所有页面。这里用于日期、区域等字段的筛选。
书签窗格:这里将按钮和书签结合使用,用于制作导航栏和动态图表。
选择窗格:可以选择显示/隐藏视觉对象,这里用于bike和非bike类商品图表的切换显示。
(3)报表展示
报表一共有3页,包括主页、时间趋势图、区域分布图。
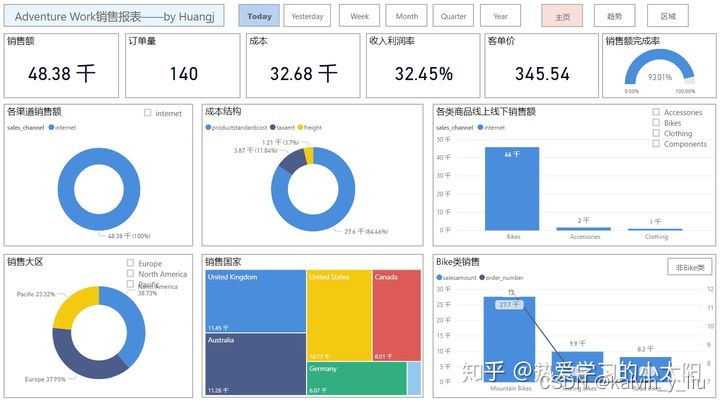
a. 主页展示内容:
基本销售指标,包括销售额、订单量、成本、收入利润率、客单价、销售额目标完成率等
- 不同销售渠道的销售情况
- 商品的成本结构
- 从时间维度分析年度、季度、月度、周、日销售情况
- 从地区维度分析在各大区、各国的销售情况
- 从产品类别维度分析各类商品的销售情况,以及bike类与非bike类的对比分析
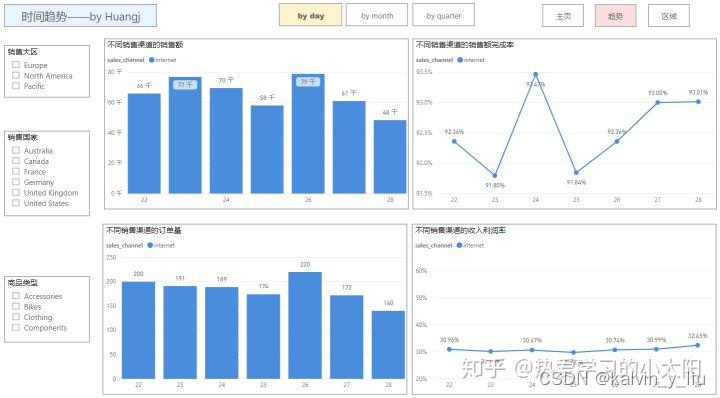
b. 时间趋势图展示内容:
- 按照季度、月份展示销售额、订单量、销售目标完成率、收入利润率等指标
- 不同渠道的销售趋势对比分析
- 区域、商品类型切片器
- 当然,这里还可以增加更多的时间维度,比如年、周、日。
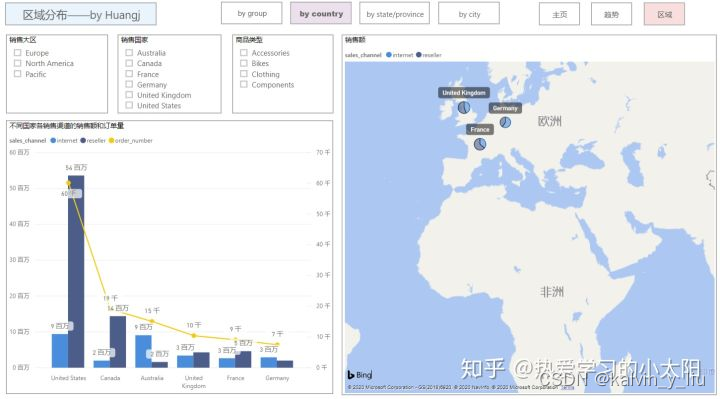
c. 区域分布图展示内容:
- 按照销售大区、国家、州/省、城市,逐级展示销售额和订单量等指标
- 不同渠道的销售占比对比分析
- 区域、商品类型切片器
https://www.shangyexinzhi.com/article/4243141.html



![[RK-Linux] 移植Linux-5.10到RK3399(十一)| 检查Nor FLASH(XM25QH128A)配置](https://img-blog.csdnimg.cn/direct/50283579a96740f4abccb2e4c6491dfa.png#pic_center)