目录
1.join和detach区别
2.lock_guard和unique_lock
3.原子操作
4.条件变量condition_variable
5.future 和 promise
1.join和detach区别
①不使用join和detach
#include <iostream>
#include <thread>
#include <windows.h>
using namespace std;
void t1() //普通的函数,用来执行线程
{
for (int i = 0; i < 10; ++i)
{
cout <<" t1 :"<< i <<" ";
_sleep(1);
}
}
void t2()
{
for (int i = 11; i < 20; ++i)
{
cout <<" t2 :"<< i <<" ";
_sleep(1);
}
}
int main()
{
thread th1(t1); //实例化一个线程对象th1,使用函数t1构造,然后该线程就开始执行了(t1())
thread th2(t2);
cout << "here is main\n\n";
system("pause");
return 0;
}每次输出的结果都不一样
②使用join
#include <iostream>
#include <thread>
#include <windows.h>
using namespace std;
void t1() //普通的函数,用来执行线程
{
for (int i = 0; i < 10; ++i)
{
cout <<" t1 :"<< i <<" ";
_sleep(1);
}
}
void t2()
{
for (int i = 11; i < 20; ++i)
{
cout <<" t2 :"<< i <<" ";
_sleep(1);
}
}
int main()
{
thread th1(t1); //实例化一个线程对象th1,使用函数t1构造,然后该线程就开始执行了(t1())
thread th2(t2);
th1.join(); // 必须将线程join或者detach 等待子线程结束主进程才可以退出
th2.join();
cout << "here is main\n\n";
system("pause");
return 0;
}join会将主线程和子线程th1 th2分离,子线程执行完才会执行主线程。(两个子线程输出每次仍不一样)
③使用detach
#include <iostream>
#include <thread>
#include <windows.h>
using namespace std;
void t1() //普通的函数,用来执行线程
{
for (int i = 0; i < 10; ++i)
{
cout <<" t1 :"<< i <<" ";
_sleep(1);
}
}
void t2()
{
for (int i = 11; i < 20; ++i)
{
cout <<" t2 :"<< i <<" ";
_sleep(1);
}
}
int main()
{
thread th1(t1); //实例化一个线程对象th1,使用函数t1构造,然后该线程就开始执行了(t1())
thread th2(t2);
th1.detach();
th2.detach();
cout << "here is main\n\n";
system("pause");
return 0;
}detach也会将主线程和子线程th1 th2分离,但是主线程执行过程子线程仍会执行
总结:
1. join会阻塞当前的线程,直到运行的线程结束。(例如上面第二段代码主线程被阻塞,直到子线程执行完才会执行join之后的主线程代码)
2.detach从线程对象中分离出执行线程,允许线程独立的执行。(上面第三段代码,主线程和两个子线程独立的执行)
参考文章
2.lock_guard和unique_lock
线程的使用一定需要搭配锁mutex,它是用来保证线程同步的,防止不同的线程同时操作同一个共享数据。
①使用mutex,使用lock函数上锁,unlock解锁
#include <iostream>
#include <thread>
#include <mutex>
#include <stdlib.h>
int cnt = 20;
std::mutex m;
void t1()
{
while (cnt > 0)
{
m.lock();
if (cnt > 0)
{
--cnt;
std::cout << cnt << std::endl;
}
m.unlock();
}
}
void t2()
{
while (cnt < 20)
{
m.lock();
if (cnt < 20)
{
++cnt;
std::cout << cnt << std::endl;
}
m.unlock();
}
}
int main(void)
{
std::thread th1(t1);
std::thread th2(t2);
th1.join(); //等待t1退出
th2.join(); //等待t2退出
std::cout << "here is the main()" << std::endl;
system("pause");
return 0;
}②使用lock_guard
使用mutex比较繁琐,需要上锁和解锁,c++提供了lock_guard,它是基于作用域的,能够自解锁,当该对象创建时,它会像m.lock()一样获得互斥锁,当生命周期结束时,它会自动析构(unlock),不会因为某个线程异常退出而影响其他线程。
#include <iostream>
#include <thread>
#include <mutex>
#include <stdlib.h>
int cnt = 20;
std::mutex m;
void t1()
{
while (cnt > 0)
{
std::lock_guard<std::mutex> lockGuard(m);
// m.lock();
if (cnt > 0)
{
--cnt;
std::cout << cnt << std::endl;
}
// m.unlock();
}
}
void t2()
{
while (cnt < 20)
{
std::lock_guard<std::mutex> lockGuard(m);
// m.lock();
if (cnt < 20)
{
++cnt;
std::cout << cnt << std::endl;
}
// m.unlock();
}
}
int main(void)
{
std::thread th1(t1);
std::thread th2(t2);
th1.join(); //等待t1退出
th2.join(); //等待t2退出
std::cout << "here is the main()" << std::endl;
system("pause");
return 0;
}③使用unique_lock
lock_guard有个很大的缺陷,在定义lock_guard的地方会调用构造函数加锁,在离开定义域的话lock_guard就会被销毁,调用析构函数解锁。这就产生了一个问题,如果这个定义域范围很大的话,那么锁的粒度就很大,很大程序上会影响效率。
因此提出了unique_lock,这个会在构造函数加锁,然后可以利用unique.unlock()来解锁,所以当锁的颗粒度太多的时候,可以利用这个来解锁,而析构的时候会判断当前锁的状态来决定是否解锁,如果当前状态已经是解锁状态了,那么就不会再次解锁,而如果当前状态是加锁状态,就会自动调用unique.unlock()来解锁。而lock_guard在析构的时候一定会解锁,也没有中途解锁的功能。
参考文章
3.原子操作
原子性操作库(atomic)是C++11中新增的标准库,它提供了一种线程安全的方式来访问和修改共享变量,避免了数据竞争的问题。在多线程程序中,如果多个线程同时对同一个变量进行读写操作,就可能会导致数据不一致的问题。原子性操作库通过使用原子操作来保证多个线程同时访问同一个变量时的正确性。
例,在多线程中进行加一减一操作,循环一定次数
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
#include <mutex>
using namespace std;
#define MAX 100000
#define THREAD_COUNT 20
int total = 0;
mutex mt;
void thread_task()
{
for (int i = 0; i < MAX; i++)
{
mt.lock();
total += 1;
total -= 1;
mt.unlock();
}
}
int main()
{
clock_t start = clock();
thread t[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i] = thread(thread_task);
}
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i].join();
}
clock_t finish = clock();
// 输出结果
cout << "result:" << total << endl;
cout << "duration:" << finish - start << "ms" << endl;
system("pause");
return 0;
}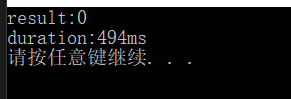
从结果来看非常耗时,使用原子atomic,不需要使用mutex,(注意添加头文件)
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
#include <mutex>
using namespace std;
#define MAX 100000
#define THREAD_COUNT 20
//原子操作 也不需要使用互斥锁
// atomic_int total(0);
atomic<int> total;
void thread_task()
{
for (int i = 0; i < MAX; i++)
{
total += 1;
total -= 1;
}
}
int main()
{
clock_t start = clock();
thread t[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i] = thread(thread_task);
}
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i].join();
}
clock_t finish = clock();
// 输出结果
cout << "result:" << total << endl;
cout << "duration:" << finish - start << "ms" << endl;
system("pause");
return 0;
}
关于具体函数的使用参考官方文档
4.条件变量condition_variable
条件变量是c++11引入的一种同步机制,它可以阻塞一个线程或者多个线程,直到有线程通知或者超时才会唤醒正在阻塞的线程, 条件变量需要和锁配合使用,这里的锁就是上面的unique_lock。
其中有两个非常重要的接口,wait()和notify_one(),wait()可以让线程陷入休眠状态,notify_one()就是唤醒真正休眠状态的线程。还有notify_all()这个接口,就是唤醒所有正在等待的线程。
#include <iostream>
#include <deque>
#include <thread>
#include <mutex>
#include <condition_variable>
using namespace std;
deque<int> q;
mutex mt;
condition_variable cond;
void thread_producer()
{
int count = 10;
while (count > 0)
{
unique_lock<mutex> unique(mt);
q.push_front(count);
unique.unlock(); // 解锁才能去唤醒
cout << "producer a value: " << count << endl;
cond.notify_one(); // 唤醒wait的线程会阻塞当前线程,
this_thread::sleep_for(chrono::seconds(1));
count--;
}
}
void thread_consumer()
{
int data = 0;
while (data != 1)
{
unique_lock<mutex> unique(mt);
while (q.empty())
cond.wait(unique); //解锁,线程被阻塞处于等待状态 |||| 被唤醒后优先获得互斥锁
data = q.back(); // 使用 back 函数获取最后一个元素
q.pop_back();
cout << "consumer a value: " << data << endl;
// 下面这行可以不写,unique_lock 离开作用域会调用析构判断是否解锁。
// unique.unlock(); // 解锁后thread_producer获得互斥锁
}
}
int main()
{
thread t1(thread_consumer);
thread t2(thread_producer);
t1.join();
t2.join();
system("pause");
return 0;
}
thread_consumer 的执行流程如下:
1.unique_lock<mutex> unique(mt); - 上锁互斥锁。
2.cond.wait(unique); - 释放互斥锁并等待通知。
3.当被通知后,重新获得互斥锁。
4.继续执行后面的代码,包括 data = q.back(); 和 q.pop_back();。
在上述过程中,unique_lock 会自动处理锁的上锁和解锁操作。当 cond.wait(unique); 执行时,它会将互斥锁解锁,并将线程置于等待状态。当线程被唤醒后,unique_lock 会自动重新对互斥锁上锁。
在 thread_producer 中,它获取互斥锁的步骤如下:
1.unique_lock<mutex> unique(mt); - 上锁互斥锁。
2.q.push_front(count); - 操作共享资源。
3.unique.unlock(); - 解锁互斥锁。
4.cond.notify_one(); - 发送通知。
在这个过程中,unique_lock 会在 unique.unlock(); 处解锁互斥锁,以允许其他线程进入相应的临界区。当 cond.notify_one(); 发送通知后,thread_consumer 会被唤醒,并在 unique_lock 重新获取互斥锁后继续执行。
这两个互斥锁操作是同步的,不会引起冲突,因为它们是针对不同的互斥锁对象进行的。thread_consumer 上的互斥锁 mt 与 thread_producer 上的互斥锁 mt 是两个不同的互斥锁对象。
注意:在使用条件变量时,一般要在循环中等待条件,因为线程被唤醒后需要重新检查条件是否真的满足。
更详细的参考文档
5.future 和 promise
TODO