尊敬的玩家您好
系统检查到您的主线任务进展缓慢
请您不要过度沉迷日常任务,尽快完成您的主线任务
请勿在npc身上浪费太多时间,避免影响玩家自身情绪
《地球Online》祝您游戏愉快

文章目录
- 一、实现目标
- 1. 项目定位
- 2. Reactor模式
- 二、前置知识
- 1. C++11的bind
- 2. 定时器与定时任务队列
- 3. 正则表达式
- 4. Any类型容器
- 三、高并发服务器组件
- 1. 模块划分
- 2. Buffer
- 3. Socket
- 4. Channel
- 5. Poller
- 6. TimerWheel
- 7. EventLoop
- 8. LoopThread
- 9. LoopThreadPool
- 10. Connection
- 11. Accepter
- 12. TcpServer
- 四、HTTP服务器
- 1. 模块划分
- 2. Util
- 3. HttpRequest and HttpResponse
- 4. HttpReqCtx
- 5. HttpServer
- 五、压力测试
一、实现目标
1. 项目定位
项目源码目录
(博客中的代码截图稍有一点不完整,如果要拿到完整的代码需要去访问gitee,本文不会讲繁杂的各个模块代码上细节的处理,代码实现上你所较容易产生的为什么问题,我都在代码截图上注释清楚了,如果你觉得自己光看代码无法理解的非常透彻,建议你把代码实现一遍,在实现过程中你一定会不断的思考,产生问题,解决问题,这会帮助你更好的掌握该项目的思想,此时如果你回头再看本篇博客中我所说的看起来没啥用较为鸡肋的思想时,你我之间可能会产生共鸣。)
1.
本项目旨在实现一个能够在某一时刻接收大量的高并发连接的服务器组件,注意我们实现的是一个组件,也就是说通过该组件,使用者就可以快速简单的搭建出一个高性能服务器,在此服务器基础上,使用者可以任意添加各种应用层协议,以此来实现出多种功能的服务器,例如HTTP服务器,FTP服务器,SSH服务器等等……
本博客则实现较为常见的HTTP服务器,即使用这个服务器组件搭建出基本的底层服务器框架后,只需要在应用层添加HTTP协议式数据的解析和发送即可,这样就完成了一个服务器的搭建,本博客的核心知识点80%都集中在实现该高并发服务器组件上,通过实现该组件,你可以学到Reactor事件驱动处理模式的设计思想,理解linux下一切皆文件的哲学理念,也可以学到one thread one loop的多线程编码时各种需要注意的坑。
20%的应用层协议支持相对较为简单,但从中你也可以学到如何在源源不断到来的字节流数据中,把握好数据的解析处理节奏,从而拿出一个完整的HTTP请求进行解析和响应,此外也可以加深你对HTTP这种协议下数据格式的印象。
2.
该项目的服务器组件代码量在1300行左右,HTTP协议支持代码量在600行左右。
额外需要说明的一点是,即使增加了HTTP协议的支持,但本项目也不包含任何实际的业务逻辑,只对数据进行HTTP协议式的解析,具体要让服务器进行什么样的业务逻辑处理,需要根据组件使用者的意向来定。组件使用者其实也只需要增加业务逻辑处理的接口,将其添加到服务器应用层即可。
3.
注意:
本篇博客中放出来的代码截图本人均不会进行代码的详细讲解,代码的思想我会在放出代码截图之前进行说明,而写代码时需要注意的细节在截图中已经通过注释详细标明了。
2. Reactor模式
1.
Reactor模式的具象化描述就是事件驱动处理模式,即服务器上所有连接上数据的接收,发送,挂断,错误等均被看作一个事件,只有事件到来时,执行流才会去调用事件对应的callback,来进行对应事件的处理,所以服务器就是一个被动的character,当服务器上某一事件触发时,那么服务器就进行对应的处理。尤其在面对高并发连接的场景时,这样的模式其实是非常高效的,借助EPOLL模型就可以实现出这样的事件驱动处理模式。通过线程数量的划分可以分为三类,即单Reactor单线程,单Reactor多线程,多Reactor多线程。
2.
单Reactor单线程:整个服务器只有一个执行流,这一个执行流负责连接到来的监听与处理,监听成功后新连接上IO事件的监控与处理,连接上数据到来后进行的业务逻辑处理,这些工作全都交给一个线程去做,服务器中实现出的所有接口均为串行化执行。
优点:因为只有一个执行流,所以不涉及线程间通信,资源争抢等安全问题,编码难度较低,出bug后也较容易调试,比较适合小规模的连接请求以及较为简单的业务处理
缺点:因为连接的监听以及IO事件的处理均为一个线程执行,所以这就导致当执行流进行IO连接处理时,服务器上若有其他新连接的到来,此时是无法对新连接进行获取的,只能等执行流处理完socket上的IO事件后,再反过头来进行新连接的获取。所以不适用于高并发连接场景以及复杂的业务逻辑处理,同时也无法有效的利用CPU的多核资源。
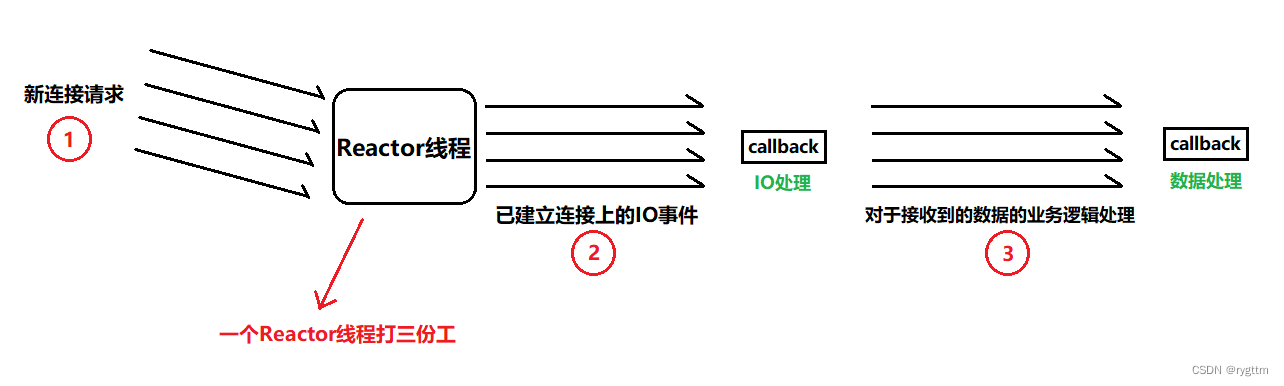
3.
单Reactor多线程:整个服务器只有一个Reactor线程,这一个执行流负责连接到来的监听与处理,监听成功后新连接上IO事件的监控与处理,但连接上数据到来后进行的业务逻辑处理交给了业务线程池,也就是在单Reactor单线程的基础上,将业务逻辑处理这部分工作交给了其他的业务线程去做,Reactor线程只负责连接的获取和连接上IO事件的处理。
优点:充分利用了CPU的多核资源,提升了业务逻辑处理的效率。
缺点:虽然业务逻辑处理的efficiency提升了,但是连接的获取和IO事件处理还是由一个线程来完成,所以在高并发大量的连接请求下,一个线程是无法同时进行大量连接请求的获取和已建立连接上IO事件的处理的,所以该模式依旧不适合高并发连接请求的使用场景。
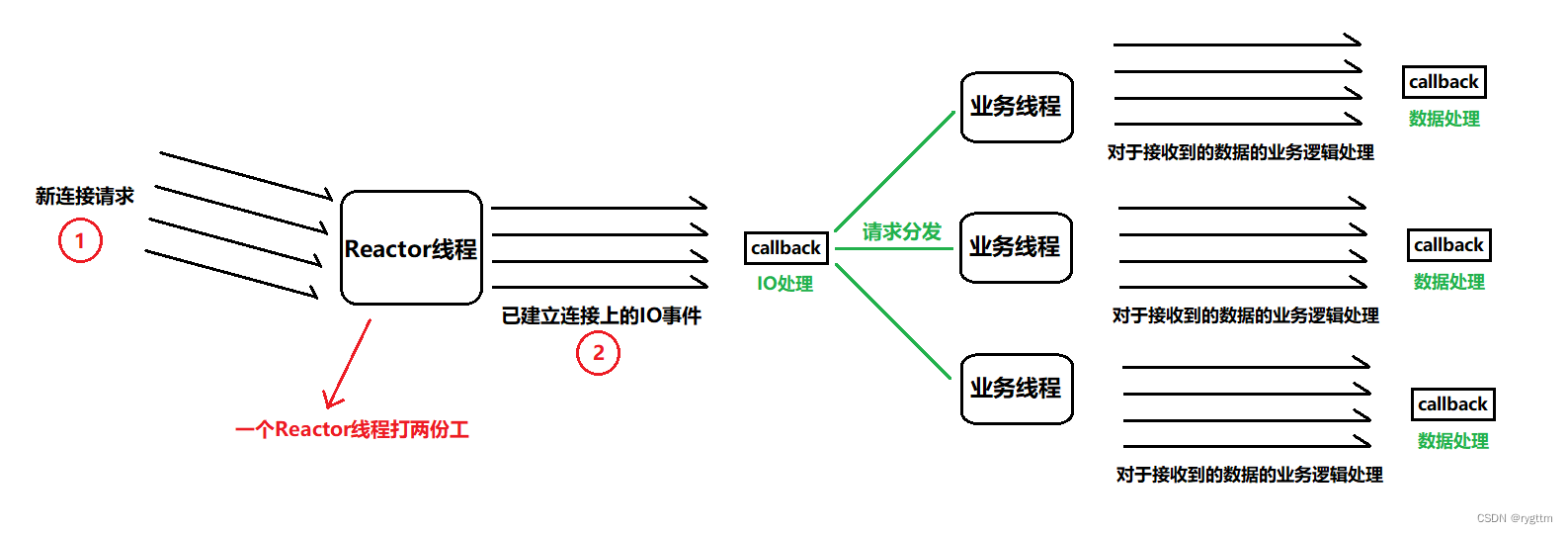
4.
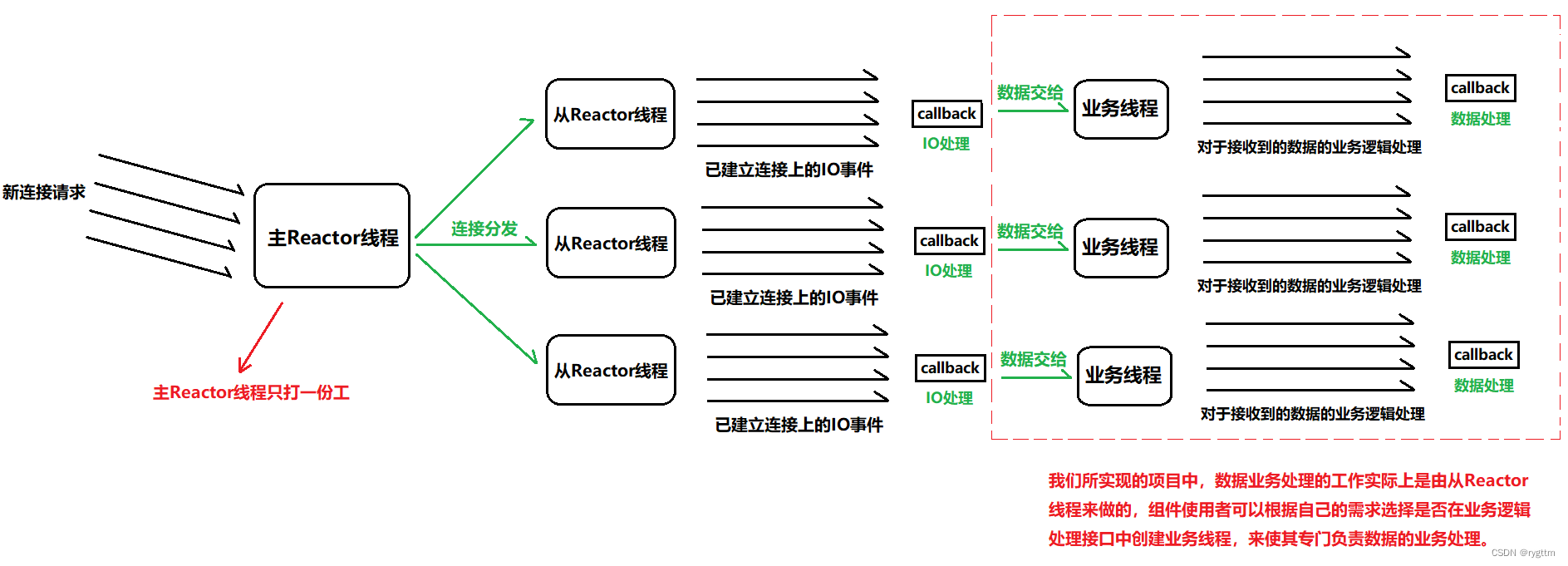
多Reactor多线程:我们项目组件采用的就是多Reactor模式,另一个称呼为主从Reactor模式,即主Reactor线程只负责新连接的获取,从属Reactor线程负责已建立连接上IO事件的处理,业务线程负责连接上到来数据的业务逻辑处理。
(因为我们实现的项目并不包含真正的业务,所以后期增加HTTP协议时,我们所实现的一些简单的业务逻辑处理,实际上是交给了从属Reactor线程一并做了,但使用者如果想要自己增加业务处理线程池,则可以在业务逻辑处理回调函数中创建一个或多个业务线程(其实一个就够了,因为这个业务线程是在从属Reactor线程下面的,要是多个业务线程,则项目中的线程数量就是从属Reactor线程数量×业务线程数量了,项目中若有太多的线程会降低CPU的处理效率的),这样在从属Reactor线程中数据到来时,就可以将接收到的数据发送给业务线程,让业务线程去进行实际的业务逻辑处理。)
优点:充分利用了CPU的多核资源,主从Reactor线程各司其职,即使面对高并发的连接请求,服务器也可以抗的住,因为主Reactor线程只负责新连接获取这一件事,效率就会很高了。
缺点:由于线程数量的增多,则可能会产生线程安全问题,同时编码难度增大(合适的线程数量还需进行服务器压力测试来给出)
二、前置知识
1. C++11的bind
1.
bind的作用是绑定函数的参数,然后生成一个可调用对象,常见用法是将这个可调用对象作为参数传递给另一个接口,作为另一个接口内部的回调函数进行调用,
bing绑定参数只有两种方式,一种是绑死参数,对于绑死参数所生成的可调用对象,在调用时无须传递任何参数,直接调用即可,实际上是将绑死的参数进行了传参。另一种是预留参数,在bind绑定时将参数的位置进行预留,等到bind生成的可调用对象被回调时,进行传参。
下面代码中tqueue任务队列中任务的执行就是bind的第一种用法,即绑死参数,在t( )进行回调时,直接无脑调用即可,无须传递任何参数,这也是任务队列常见的一种执行任务的方法,即将绑死参数后的可调用对象压入到任务队列中,等到任务队列中的任务被执行时,不传参直接进行调用即可。
func变量的调用就是bind的第二种用法,即预留参数位置,在func进行回调print时,此时再去传递print的第二个参数。

2. 定时器与定时任务队列
1.
linux提供了创建定时器的接口timerfd_create,该接口会返回一个定时器文件描述符用于后续的操作。clockid参数通常可以被设置为两种,分别是CLOCK_REALTIME和CLOCK_MONOTONIC,我们设置为CLOCK_MONOTONIC,因为他不会受手动更改linux系统时间产生的影响而随之变化,相反CLOCK_REALTIME会收到系统时间更改的影响。至于flag参数我们设置为0,因为我们并不想更改timerfd_create的行为,只需要他在内核中创建出一个定时器即可。
(英语好的老铁可以自己翻译,不用看我写的)

2.
timerfd_settime用于设置定时器几秒后开始启动,初始超时时间为多少,每次间隔多长时间为超时,该接口调用成功后,则每隔一定时间,linux系统会向该定时器文件描述符写入超时次数,所以要想知道超时了几次,则一定要调用read接口将timerfd中的数据读取出来。

3.
所以如果想要设置一个秒级别的定时器,则我们可以把初始超时时间设置为1s后,间隔超时时间也为1s后,如果这样的话,则每隔1s,linux系统就会向timerfd中写入超时的次数,比如超时3s,则就向其中写入3,一旦你read读取了超时次数,则timerfd中的内容就会被重新清零。
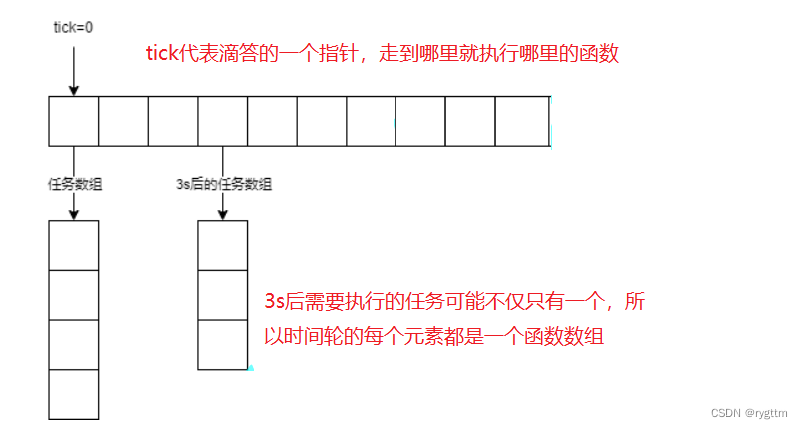
在定时器的基础上,如何实现一个定时任务队列呢?其实只需要一个任务数组即可,我们可以用一个大小为60的vector来表示一个时间轮,用tick下标表示秒针,通过读取timerfd中的内容,我们就可以知道实际超时了多少s,然后让tick下标向后走多少步,每走一步都clear该下标下的数组内容,这样就会执行数组内存储对象的析构函数,而我们要做的就是把要执行的定时任务放到该对象的析构函数中,这样只要tick走到任何一个下标位置,只要析构该对象即可完成定时任务的执行。
4.
实现一个能够定时执行任务的时间轮,实际上需要两个类,一个是Timer类用于构造定时任务对象,在其析构函数内部包含要在几秒后执行的某一个任务,一个是TimerWheel类用于实现一个时间轮,保证在具体的秒数过后去执行定时任务,但在写代码之前,其实还有几个问题需要考虑。
某一时刻要执行的定时任务不止一个怎么办?假设在3s后要执行多个定时任务,那如果我们的时间轮是一维数组,则肯定是不行的,因为一个下标内无法存储多个定时任务对象,所以时间轮必须是一个二维数组,每个下标内又是一个定时任务对象数组,这样在执行定时任务时,直接调用vector的clear函数,即可析构该下标内数组存储的所有定时任务对象,完成定时任务的执行。
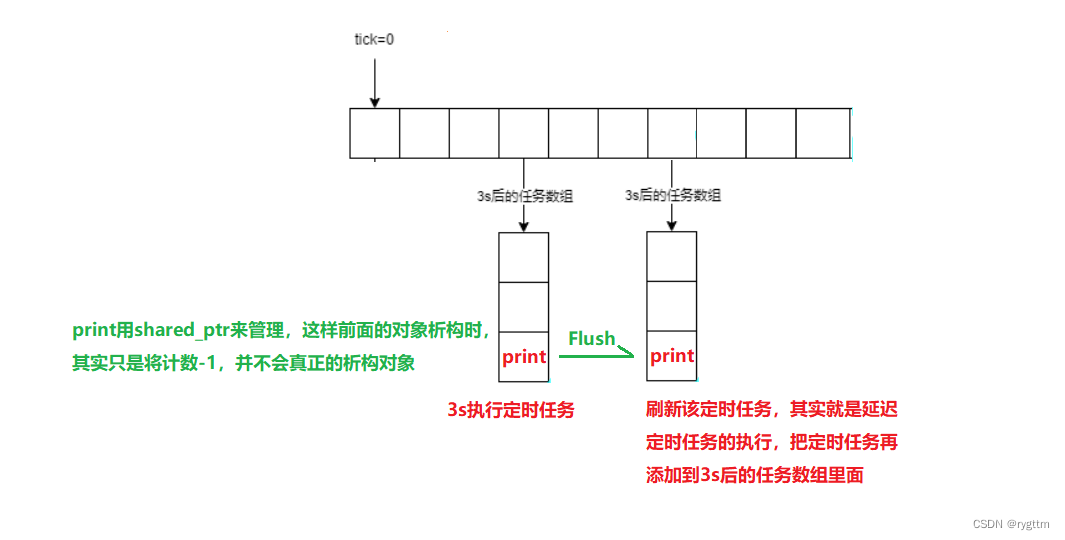
如何实现定时任务的刷新?其实刷新定时任务就是延迟定时任务的执行,我们可以借助shared_ptr来实现定时任务的延迟,即在后面的任务数组里再添加该定时任务对象到其中。
5.
下面是秒级时间轮和定时任务对象类的代码实现

3. 正则表达式
1.
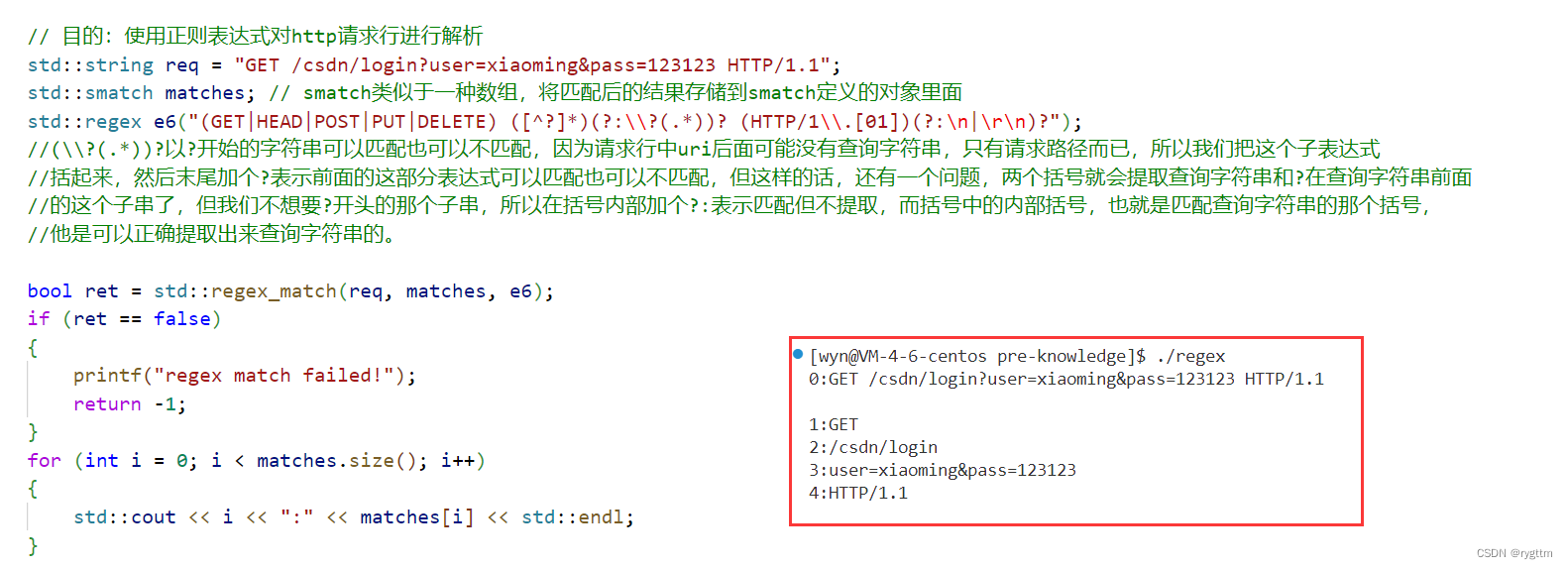
正则表达式听起来比较牛,但实际上就是一种字符串匹配模式。本项目中,我们会利用正则表达式来提取http请求行中的各个参数,例如请求方法,资源路径,查询字符串,协议版本。
这里只讲正则表达式如何快速的用起来,我们可以利用regex构造一个正则表达式的对象,给构造函数传的参数就是一个符合正则匹配规则的字符串,然后通过调用regex_match就可以对被解析的字符串req进行正则匹配,而匹配后的结果会存到smatch定义的匹配对象matches中,我们可以把matches当作一个数组,该数组下标索引内存储的就是对req进行正则解析后的内容,通过遍历matches就可以拿到正则匹配后的各个内容了。
从匹配结果可以看出,matches数组的0下标索引其实存储的是req,后面的下标才会依次存储正则提取后的各个内容。

正则表达式匹配规则
4. Any类型容器
1.
在项目中,由于后面会对socket内核接收缓冲区中到来的数据进行HTTP协议格式的解析处理,我们需要从中拿到一个完整的HTTP请求,但内核缓冲区中的数据现在可能不够,有可能只有请求行的数据,有可能有请求行+请求报头的数据,有可能有请求行+请求报头+部分请求正文的数据,总之我们无法控制内核接收缓冲区中的数据现在处于怎样的一个接收阶段,因为这是TCP协议的自主行为,我们站在应用层是无法得知和操控的。
所以我们就需要有一个处理HTTP请求的上下文类,通过这个类来把控HTTP请求此时的处理阶段到哪里了,什么时候拿到一个完整的HTTP请求,而服务器内部的Connection连接会关联这个请求的上下文类,但服务器作为一个被使用的组件怎么知道使用者的意向呢?今天我们上层用的是HTTP协议,但可能未来其他使用者在使用时用的是其他协议,所以服务器内部必须有一个容器能够保存任意协议类型的请求上下文结构,这个时候就用到了我们的Any容器了,该容器内部就可以保存任意类型的数据。
2.
如何设计一个可以保存任意类型数据的容器呢?我们首先能够想到的其实就是模板类,因为模板类可以接收任意的类型,但是模板类在定义对象的时候,必须给模板类传一个类型参数,否则无法调用模板类的构造函数。但服务器压根就不知道上层的协议上下文类型,所以光有模板类是不行的。
我们进而可以想到,能否在Any类中设计一个继承体系,我们让派生类作为一个模板类去存储任意类型的数据,而用基类的指针去指向派生类对象,基类是一个普通类并不带有模板参数,那么Any类型的成员变量只需要是基类的指针就可以了,利用这个基类的指针就可以访问保存任意类型数据的派生类对象了。
而Any的单参构造函数则需要是一个模板函数,我们需要根据其所传参数推导出其类型,并将该类型作为参数传递给模板类placeholder,通过这样的方式就可以设计出一个保存任意类型数据的Any容器出来。

三、高并发服务器组件
1. 模块划分
1.
Buffer作为应用层的收发缓冲区,当读事件就绪时,服务器就会调用read接口将socket内核接收缓冲区中的数据拷贝到引用层Buffer定义的_inbuffer中,当写事件就绪时,服务器就会调用write接口将应用层Buffer定义的_outbuffer中的数据拷贝到传输层的socket内核发送缓冲区中。所以每一个Connection连接都需要关联一个Buffer模块,用于定义其应用层的收发缓冲区。
Socket用于简化socket连接的操作,封装连接相关的系统调用接口,方便进行监听连接的创建,发送数据,接收数据,关闭连接,获取监听连接上到来的新连接等操作。
Channel是事件监控模块,用于管理一个连接上可能产生的就绪事件,例如可读事件,可写事件,连接关闭事件,错误事件,同时该模块还包含所有事件就绪时的回调函数,即当事件就绪时,Channel自己进行相对应回调函数的调用,以此来处理所有就绪的事件,而Channel的各个事件就绪回调函数其实是Connection模块来设置的,当Accepter模块检测到有新连接到来时,此时就会为该连接分配一个Connection对象,Connection就会设置好该连接关联的Channel的各个事件回调函数。
Poller模块其实是封装了epoll接口的各个操作,例如创建epoll模型,在epoll模型上添加需要监控的事件,开始监控连接上就绪的事件等操作都会被封装起来,以此简化epoll接口的各个操作。
TimerWheel是一个定时任务队列,简称为时间轮,他会作为EventLoop的成员变量,某一个连接的销毁任务就是在定时任务队列中执行的。
EventLoop是一个事件循环监控模块,这个模块是整个项目中最重要的一个模块,从始至终只做三件事,关心事件的监控,就绪事件处理,执行任务队列中的任务。设计出一个任务队列的主要目的是防止线程安全的发生,主Reactor线程可能会在外部对连接进行一些操作,例如收到数据,业务逻辑处理完成后要发送数据,此时就会涉及到连接的操作,而所有的通信连接的操作都会在EventLoop中完成,而EventLoop会关联一个LoopThread线程,该线程就是我们所说的从Reactor线程,多个线程都对连接操作则一定会产生线程安全问题,所以需要设计出一个任务队列,让外部对于连接的操作压入到任务队列中进行。
LoopThread就是前面所说的从Reactor线程,他的作用就是运行EventLoop模块,EventLoop和LoopThread是1:1的。
LoopThreadPool用于管理多个LoopThread线程,主要作用就是创建多个LoopThread线程。
Connection是新连接获取好之后,为其创建的一个连接对象,如果说EventLoop模块是理解项目的最重要的一个模块,那么Connection就是实现项目时代码量最多的一个模块,该模块主要实现了连接上事件就绪时如何处理的函数接口,并将这些接口设置为Channel的回调函数,等事件就绪时回调这些函数即可,除此之外还包含许多提供给组件使用者的接口,例如关闭连接,发送数据,开启非活跃连接释放销毁等等功能。
Accepter是一个用于监听连接到来和获取新连接的一个模块,主要功能是创建一个监听套接字,等到监听套接字上可读事件就绪时,获取到来的通信连接,同时为通信连接分配Connection,设置好就绪事件的回调函数等等。
TcpServer是最终向外提供的服务器组件模块,通过该模块就可以迅速搭建起一个主从Reactor模式的TCP服务器。
2. Buffer
1.
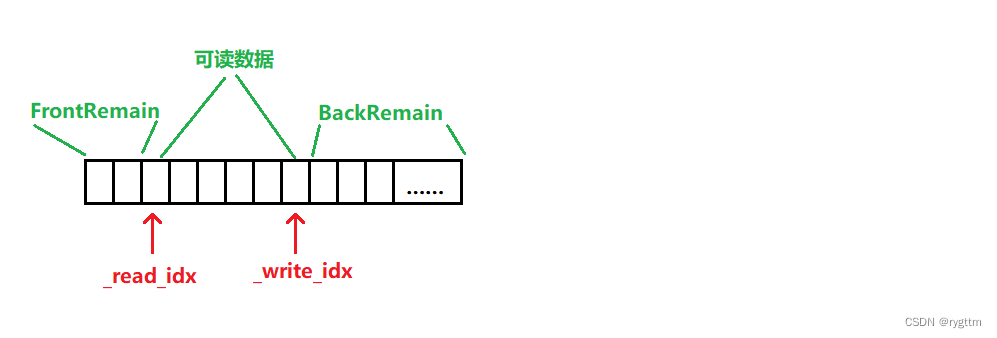
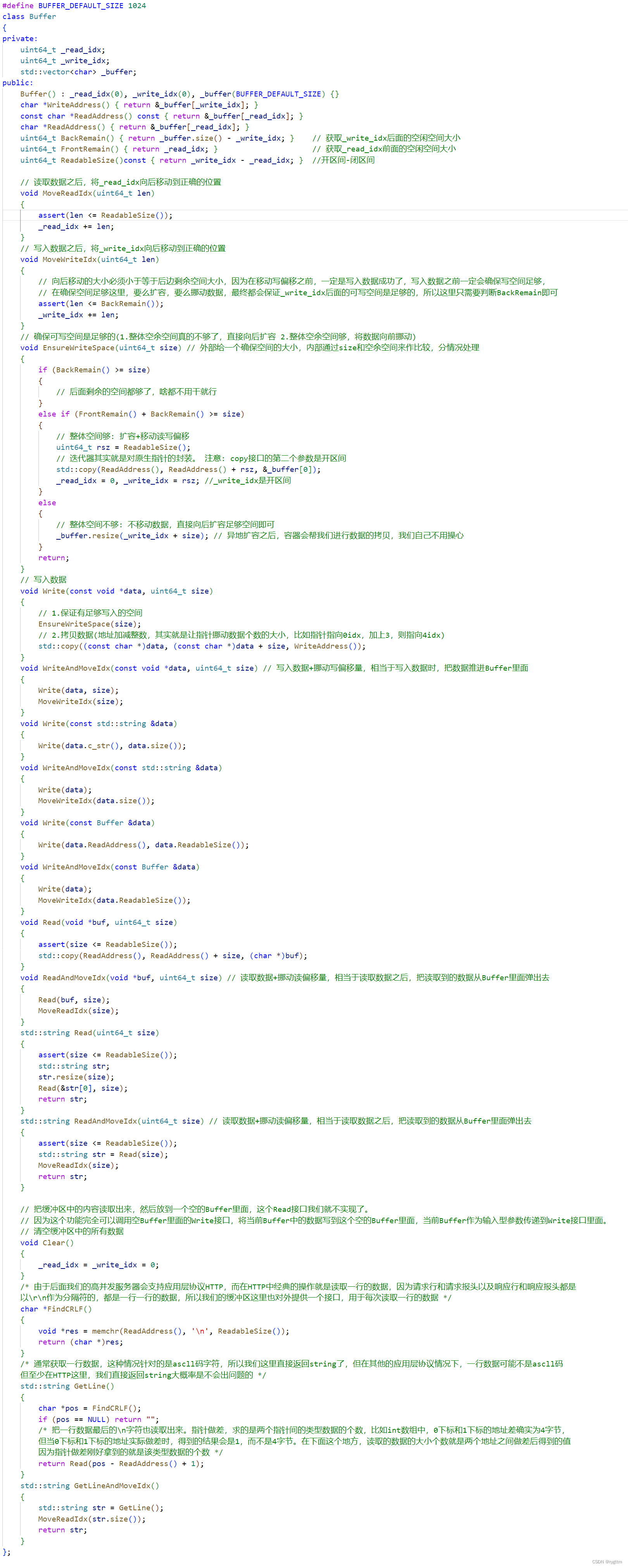
实现该缓冲区的大致思想如下图所示,计算缓冲区的剩余空间时,需要计算两部分,即_read_idx之前可能剩余的空间大小,和_write_idx之后的剩余空间大小。
3. Socket

4. Channel
1.
Channel这里需要做两件事,一件就是把需要监控的事件集合,通过EventLoop里面包含的Poller模块将其添加到Epoll模型中,其实就是添加到红黑树上面,另一件事就是在EventLoop里面的RunLoop接口中,epoll_wait会将就绪的事件设置回Channel中,此时RunLoop就会调用Channel的HandleReadyEvent接口进行就绪事件的处理,而Channel中各个事件的回调函数实际上是由Connection的构造函数里进行设置的,即当服务器获取新连接后,就会自动为其关联一个Connection对象,而在关联Connection对象的同时,与之关联的Channel中的各项事件回调函数就会被设置好了。

5. Poller
1.
Poller这里只做三件事,第一件就是在构造函数里面创建好我们的epoll模型,第二件就是向外提供更新事件的接口,让外部向epoll模型中添加或修改或删除关心的事件集合,第三件就是Monitor开始监控事件,将就绪的事件设置回Channel里面,即通过Channel向外提供的SetRevent接口来完成

6. TimerWheel
1.
想要实现定时任务队列,需要两个类,一个是Timer类,也就是构建出一个定时任务来,然后通过TimerWheel对外提供的添加定时器的接口,来将对应的定时任务添加到定时任务队列(数组)中。
博客最开始其实就说过本项目的一个核心思想,即Reactor的具象化描述:事件驱动处理模式,实际上这个描述不仅仅适用于Reactor,实际上他贯穿了整个项目的边边角角,例如这里的定时器文件描述符,在TimerWheel的构造函数里面我们就启动了对_timerfd的可读事件监控,因为每隔1slinux就会向_timerfd中写入一个8字节的数据来代表超时的次数,而此时恰好就会触发可读事件,而当定时器文件描述符的可读事件触发时,在EventLoop中就会回调这里的HandleRead函数,而HandleRead需要做的就是读取_timerfd中的内容,根据实际超时的次数,让_tick指针向后移动对应的超时次数,析构沿途的下标中的定时器对象。

7. EventLoop
1.
EventLoop这里有三件事需要重点叙述,最重要的就是RunLoop接口,这个接口只频繁死循环的做三件事,即监控红黑树上需要关心的事件,将实际就绪的事件设置回对应的Channel中,下一步就是调用活跃的Channel中的HandleReadyEvent接口进行就绪事件的处理,等到处理完毕之后,继续执行任务队列中的任务,也就是说,一旦LoopThread线程运行起来,他其实一直做的事情就是死循环运行EventLoop中的RunLoop接口。
其次就是任务队列,设计任务队列主要是防止多线程操作连接时可能产生的线程安全问题,所以EventLoop向外提供一个RunInLoop接口,将非LoopThread线程对连接的操作都放到EventLoop的任务池中,让LoopThread来执行这些操作,也就是说对某一个连接的操作只能由对应的LoopThread线程去执行,否则就会产生线程安全问题。而任务池的访问其实就需要加锁控制了,因为把任务push任务池的操作可能是由主Reactor线程执行的,而从任务池中取出任务执行任务的线程可能是LoopThread从Reactor线程执行的。
最后就是eventfd,这个文件描述符是linux所提供的专门用来进行事件通知的,我们这里主要是利用他来唤醒可能阻塞的epoll_wait,因为EventLoop在不断死循环执行RunLoop接口时,有个Monitor接口,该接口其实就是epoll_wait的封装,而如果红黑树上一直没有事件就绪,那么LoopThread执行流很有可能就一直阻塞在Monitor接口处,无法继续向下执行,那么就有可能导致任务池中的任务迟迟得不到执行,我们并不希望这样的事情发生,所以就需要_eventfd这个描述符,而唤醒epoll_wait的原理其实也很简单,只需要在构造EventLoop对象时,在构造函数里面关心_eventfd上的读事件,这样只要_eventfd中有数据,那么就会立马唤醒可能阻塞的epoll_wait,而我们只需要在EventLoop内部实现一个WakeupEpollWait接口即可,这个接口的功能其实就是向_eventfd中写数据,以此来触发他的读事件,而我们只需要在RunInLoop接口中所调用的PushInTasks里,再调用WakeupEpollWait即可,表示只要你每次向任务池中添加任务,如果是非LoopThread线程,则立马进行一次epoll_wait的唤醒,绝对不会产生任务池中的任务一直泡着而无法执行的情况。

8. LoopThread
1.
该模块实际上就是等主Reactor线程创建出来LoopThread时,LoopThread的构造函数就会创建从属Reactor线程,让从属Reactor线程去执行EventLoop的RunLoop接口,即让一个LoopThread线程和一个EventLoop对象强绑定关联。
但还需要注意一个问题就是线程间的时序问题,主线程可能会调用GetEventLoop接口获取EventLoop对象的指针,将这个指针关联到一个Connection连接上,但此时很有可能从线程还没有创建完毕EventLoop呢,那么这个时候GetEventLoop接口会返回一个NULL指针,这样肯定是不行的,所以在LoopThread这里需要借助线程同步与互斥的知识,即通过条件变量和互斥锁来控制线程间的运行。

9. LoopThreadPool
1.
LoopThreadPool实际上就是用来创建LoopThread对象,只要该对象被创建则从Reactor线程就会被创建,同时也会关联一个EventLoop对象。
而LoopThreadPool的主要功能其实就是创建从属Reactor线程,以及提供一个RR轮转分配EventLoop对象指针的接口,即GetNextEventLoop接口,即每一个服务器上新到来的连接都会被均匀分配到创建出来的一定个数的EventLoop上。
我们的项目虽说是主从Reactor模型,但我们要灵活,如果组件的使用者不想设置从Reactor线程的数量,只希望项目是单Reactor线程,比如在一些轻量化场景下不需要主从Reactor模式,可能服务器没有那么大的并发连接量,那么这个时候我们也要能够支持单Reactor单线程模式。
其实支持也很简单,我们只需要在LoopThreadPool的成员变量里面添加一个_baseloop指针,当外部调用GetNextEventLoop时,我们可以做一个线程数量的判断,如果从Reactor线程数量为0,那么我们直接返回_baseloop指针即可,如果线程数量大于0,则我们进行RR轮转返回_eventloops数组里面的EventLoop指针。
实际上这个baseloop是TcpServer创建的,因为主Reactor和从Reactor线程最终都一样,他们最终其实都是死循环运行EventLoop模块的RunLoop接口,只不过主Reactor监控的其实是监听套接字上的可读事件什么时候能够就绪,而从Reactor监控的是通信套接字上可能触发的可读事件,可写事件,错误事件,连接断开事件等,这就是两者的不同。
所以如果服务器组件是单Reactor单线程模式的话,则实际上监听套接字和通信套接字的事件监控与就绪事件处理等都会在baseloop中运行,主线程则会一直死循环运行baseloop模块中的RunLoop接口,保证服务器持续进行新连接的获取+已建立连接上的通信。

10. Connection
1.
Connection需要包含四个回调函数,这四个回调函数其实是由TcpServer模块来设置的,而TcpServer中的四个回调函数其实是由组件使用者来设置的,包括连接建立完成后的回调,连接建立关闭时的回调,已接收数据的业务逻辑处理回调,任意事件产生时的回调,注意这些回调函数其实都是由组件使用者来设置的,容易把大家搞混的是这里的任意事件产生时的回调,因为我们的服务器内部Channel也包含了一个任意事件产生的回调_anyevent_cb,但这两者是不一样的,前者是组件使用者自己的回调,例如组件使用者想查看活跃连接都有哪些并将其统计下来,而后者其实是为了刷新连接的活跃度,表示连接上只要有任意事件产生,那就FlushTimer,所以两个回调是不一样的,一个是组件内部用于实现非活跃连接销毁功能的,一个是我们提供给外部组件使用者设置的回调函数,组件使用者可以选择设置或不设置,如果他不关心那就可以不设置。
其实Connection的4个回调函数中,最重要的是_message_cb_usr,也就是业务逻辑回调,该回调中处理数据的方式其实就是引用层协议不同的体现,每个协议都有自己的数据处理格式。
2.
从Connection向外提供的public接口可以看出来,只要对外涉及到连接的操作都会内部回调RunInLoop接口,将实际对连接的操作压入到EventLoop中的任务队列,这么做的原因主要是怕服务器组件在多Reactor多线程的模式下产生线程安全问题,因为每个EventLoop都是LoopThread一直在运行,EventLoop上关联的连接都是LoopThread线程在操作,如果此时Connection外部提供的涉及到连接操作的接口被主Reactor线程运行,那么就会产生线程安全问题,所以在Connection的public提供的连接操作接口中实际都做了一层RunInLoop的封装,防止多线程模型下产生安全问题。
3.
连接这里分别有四种状态,即不完整的状态,也就是没有开启通信套接字上的可读事件监控,开启之后的连接建立完成状态,当组件使用者调用外部的ShutDown接口进行连接的关闭时,此时连接处于待关闭状态,不能实际进行关闭,因为此时连接的收发缓冲区中可能还有残留的数据待处理,等到应用层的收发缓冲区中的残留数据处理完毕之后我们在进行连接的实际释放。
Connection内部还需要实现5个回调函数,分别设置回Channel中,而这5个回调函数中的HandleRead,HandleWrite,HandleClose,HandleError中都会涉及到连接的释放操作,而这里的连接释放操作也不可以直接进行真正的连接释放,必须将连接释放的操作压入到任务池中。因为可能存在一种情况,连接正在处理可写事件,此时需要关闭连接了,如果你真的就把连接关闭了,那么处理完可写事件之后,还要处理任意事件,也就是刷新连接的活跃度,此时就会出问题了,所以必须得等到连接上就绪事件全部处理完毕之后,再去进行连接实际的释放,这就是为什么这四个回调函数中调用的都是向外public提供的Release接口,而不是内部实际的ReleasePriv接口。

11. Accepter
1.
Accepter也会关联一个EventLoop,用于对监听套接字进行监控和就绪事件的处理,而这个EventLoop其实就是TcpServer内的成员变量baseloop,监听套接字的可读事件就绪时,就会回调HandleRead,而HandleRead中只需要做两件事即可,获取新连接的fd,以及为新连接分配一个Connection连接,后面这一步的操作其实就是_read_cb,这个回调函数是由TcpServer模块设置的,因为Accepter模块的成员变量不应该包含Connection对象,所以为新连接fd分配Connection的工作是由TcpServer设置的,Accepter只负责回调而已。
2.
Accepter向外提供的接口其实只包含两个功能,一个是用于设置Accepter内部的_read_cb,也就是把分配Connection的函数设置成Accepter的回调接口,另一个是关心Accepter的可读事件,TcpServer的构造函数中会分别调用这两个接口。

12. TcpServer
1.
在TcpServer中的NewConnection接口就是设置给Accepter的回调函数接口,该接口内部非活跃连接释放销毁和完善连接,也就是开启通信套接字的可读事件监控操作,这两个操作之间有时序问题,代码处有注释。
服务器组件向外提供了添加用户自身的定时任务的接口,看组件使用者是否需要,所以服务器组件内部不仅仅有非活跃连接释放的定时任务,还有可能有组件使用者自己添加的定时任务。


四、HTTP服务器
1. 模块划分
1.
Util:该模块提供一些功能性接口,用于更好的解析和处理HTTP格式数据的请求行,请求报头,以及文件操作,获取文件类型等等。
HttpRequest and HttpResponse:这两个模块是为了更好的进行数据解析以及数据的发送,如果你要对数据解析,则需要把数据读取出来,然后将读取的数据构造出一个完整的HTTP格式的请求对象,通过对请求的业务逻辑处理,同时构建出一个完整的HTTP格式的响应对象,最后将响应对象序列化之后发送回对方,在数据解析处理以及返回的过程中会涉及到HTTP格式的请求和响应的处理,所以我们需要这两个类来分别构造出HTTP格式的请求和响应对象,方便我们处理数据。
HttpReqCtx:是HTTP请求的上下文模块,该模块实际上就是来把控处理HTTP请求格式的数据的,主要包含3个成员变量,分别是请求处理阶段,例如现在是接收请求行,接收请求报头,接收请求正文,接收一个请求完毕的阶段状态。以及一个HttpRequest对象,该对象保存的就是解析所收到数据后构造出来的一个完整的HttpRequest请求对象,通过访问该请求对象,我们就可以根据请求构造出相对应的响应。以及一个响应状态码,这个响应状态码标志着两种请求结果,即成功和失败,如果请求格式不符合HTTP协议,则该_resp_code会被设置为大于等于400以上的状态码,如果请求符合HTTP协议,则_resp_code会设置为相应的小于400的正确状态码。
HttpServer:构建HTTP服务器直接对接的模块,通过向TcpServer设置业务逻辑处理回调来实现HTTP服务器的搭建,其中业务逻辑处理回调的思想算是一个程序员通识,需要进行正确的数据节奏把控处理,以此来从应用层接收缓冲区中的字节流数据解析处理得到一个完整的HTTP请求对象,这个工作并不是HttpServer操心的,而是HttpReqCtx操心的,而HttpServer的主要作用其实是对获取到的HTTP请求对象进行解析和处理,例如判断请求类型是静态资源请求还是动态功能请求,对请求分类之后做出相应的处理,处理结束之后返回一个响应即可。
2. Util
1.
下面的接口中UrlEncode在本项目中暂时没有被使用到,其他接口的实现注释说明的是比较清楚的。

3. HttpRequest and HttpResponse
1.
请求主要包含请求方法,请求的资源路径,在资源路径后可能还会跟一个?字符开头的一系列以&符号间隔的查询字符串,请求报头,请求正文等。
响应主要包含响应码,重定向标志位,重定向的url,响应报头,响应正文等。

4. HttpReqCtx
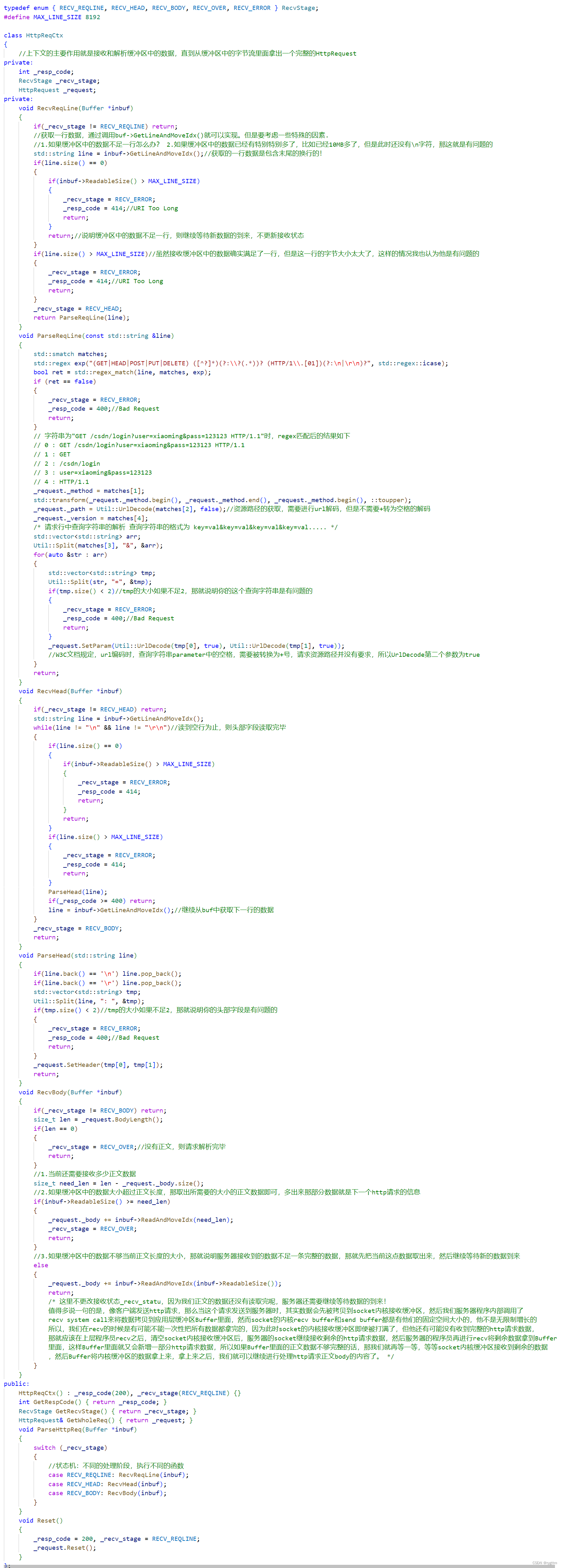
1.
向外提供的接口主要有,解析inbuf里的Http请求的字节流数据ParseHttpReq(Buffer *inbuf),获取一个完整的Http请求对象GetWholeReq( ),重置请求上下文Reset( )。其实该模块最主要的功能就是ParseHttpReq,解析处理字节流数据。
为了实现该功能,我们又实现了5个内部的接口,即接收请求行,解析请求行,接收请求报头,解析请求报头,接收请求正文。
稍微难理解的可能就是ParseHttpReq内部实现的状态机代码,在case语句内部是不需要break的,因为解析处理完某一个状态后就应该立马向下继续进行解析处理,所以不需要break,如果当前状态和case的值不符合实际上也没关系,因为在调用函数内部会进行接收状态的判断,如果状态与当前的调用函数不符合那就会直接return不会继续向下执行。
5. HttpServer
1.
HttpServer处理静态资源请求的处理逻辑较为简单,只需要解析出请求的文件名,再把文件资源读取到响应正文里面,最后把响应正文返回即可。
但动态功能的请求处理实际上需要路由表,根据请求资源路径的不同来匹配不同的处理函数指针,而处理函数指针也就是回调函数,是由组件使用者设置给HttpServer模块的,可以看到组件内部实现了4个路由表,分别是_get_route,_post_route,_put_route,_delete_route,路由表主要存储的是一个个的pair键值对,key其实是资源路径的正则表达式,为什么用正则表达式呢?因为有可能资源路径带有数字,如果不用正则表达式,那针对不同的数字假设都是同一个处理函数来处理,那就太占用路由表的空间了,这样很不划算,所以采用正则表达式来进行某一个请求方法下的不同资源路径的请求处理是一个不错的选择。
还需要说明一下的就是OnMessage这个Http业务逻辑处理回调,其实实现HTTP服务器,主要实现的就是该接口,不同的协议实现不同的OnMessage内容。在OnMessage中,调用上下文的ParseHttpReq后,OnMessage的返回有两种情况,一种是在解析数据的过程中发现请求是不符合Http协议的,导致context内部的响应状态码被设置为大于等于400的值,此时就需要返回一个响应,告诉客户端你的Http请求有问题,另一种情况就是数据接收不完整,此刻数据还不够一个完整的Http请求对象,那么服务器就无须进行业务逻辑处理,直接返回即可,等到数据接收完整时,再继续向下进行处理。这两种返回的判别方式其实就是通过context的GetRespCode( )和GetRecvStage( )接口来实现的。

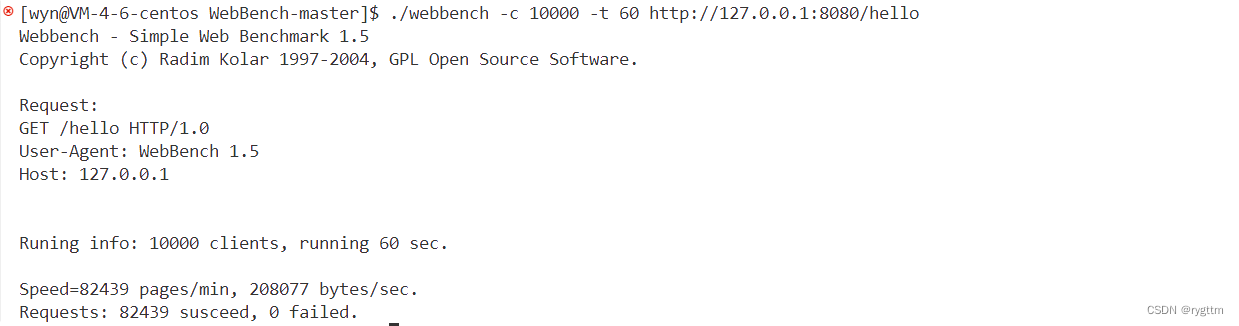
五、压力测试
在2核心4G5M带宽的云服务器下,客户端和服务器同在一台主机,忽略带宽的影响,使用Webbench工具来测试,并发连接量可以达到上w,QPS可以达到1500左右。