欢迎关注公号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
文中所有相关面试资料可从公号领取文章导读地址:点击查看文章导读!
感谢你的关注!
前言:
🚀 春招季即将来临,你准备好迎接挑战了吗? 🌟
🎯 【30天面试冲刺计划】 —— 专为大厂面试量身定制!
🔥 跟随学习,一起解锁面试新高度! 🔥

哔哩哔哩后端面试:JDK 集合源码、(下)
文章目录
- 哔哩哔哩后端面试:JDK 集合源码、(下)
- 7、JDK 中的集合:ArrayList、LinkedList、HashMap、HashTable、ConcurrentHashMap
- 8、线程的状态以及线程状态的转换
- 9、Future 获得结果怎么处理
- 10、JUC 工具类用过哪些?
- 11、JVM 实战过吗,了解命令吗?
7、JDK 中的集合:ArrayList、LinkedList、HashMap、HashTable、ConcurrentHashMap
这里就是 JDK 源码常见的问题了
这里我就不贴出来了,之前已经写过很多篇相关的内容了,如果需要可以自行搜索一下
主要说一下会问哪些问题:ArrayList、LinkedList 底层原理,一个底层是数组,另一个底层是链表
HashMap 底层数据结构?什么时候会扩容?什么时候链表转为红黑树?线程安全吗?
HashTable 线程安全吗?效率高吗?如何保证线程安全(synchronized)? 这个效率不高,使用的不算多,一般使用 ConcurrentHashMap
ConcurrentHashMap 线程安全如何保证?锁的粒度怎样?
8、线程的状态以及线程状态的转换
线程的状态有 6 种:新建 New、就绪 Ready、运行中 Running、阻塞 Blocker、超时等待 Timed Waiting、退出 Terminated
接下来说一下各个状态之间如何转变:
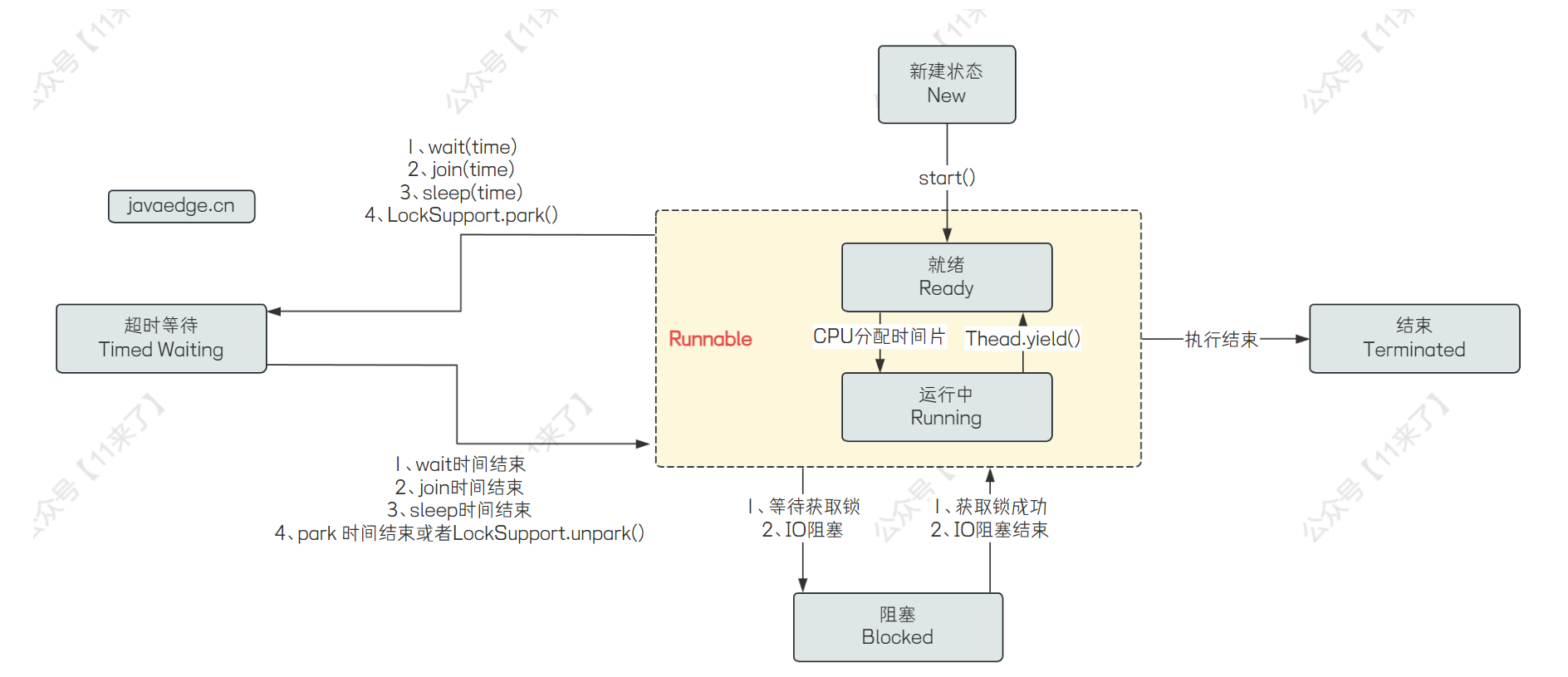
接下来说一下上边出现的几个方法的含义:
- wait() 和 sleep():
wait() 来自 Object 类,会释放锁
sleep() 来自 Thread 类,不会释放锁
- interrupt()
用于停止线程,给线程发出一个中断信号,但是并不会立即中断,会设置线程的中断标志位为 true
一般停止线程都会使用 interrupt() 方法,但是这个方法并不会立即中断正在运行的线程,想要立即停止线程,可以使用 sleep() 和 interrupt() 搭配使用:
从下边输出可以看到,当子线程 sleep() 时,我们在 main 线程中调用了子线程的 interrupt(),那么子线程就会抛出 InterruptedException(只要 sleep() 和 interrupt() 方法碰到一起,就一定会抛出异常,我们可以使用抛出异常的方法,来优雅的停止线程的执行)
public static void main(String[] args) {
try {
Thread thread = new Thread(()->{
try {
// 让子线程先 sleep
System.out.println("run begin");
Thread.sleep(2000);
System.out.println("run end");
} catch (InterruptedException e) {
System.out.println("子线程 sleep 过程中被 interrupt,导致抛出 InterruptedException");
e.printStackTrace();
}
});
thread.start();
// 让主线程等子线程启动起来
Thread.sleep(200);
// 调用子线程的 interrupt()
thread.interrupt();
} catch (InterruptedException e) {
System.out.println("主线程捕获中断异常");
}
System.out.println("end");
}
// 程序输出
run begin
end
子线程 sleep 过程中被 interrupt,导致抛出 InterruptedException
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at com.alibaba.craftsman.command.PaperMetricAddCmdExe.lambda$main$0(PaperMetricAddCmdExe.java:42)
at java.lang.Thread.run(Thread.java:748)
- yield()
让当前线程放弃对 cpu 的占用,放弃的时间不确定,有可能刚刚放弃,马上又获得了 cpu 的时间片
- LockSupport.park()/unpark()
用于阻塞当前线程,可以通过另一个线程调用 LockSupport.unpark() 方法来唤醒它
9、Future 获得结果怎么处理
Future 可以用于获取异步计算的结果,Future 的使用比较简单,主要有以下四个方法:
// 检查任务是否完成
boolean isTaskDone = future.isDone();
// 等待任务完成
Object result = future.get();
// 带超时的等待
Object result = future.get(1, TimeUnit.SECONDS);
// 取消任务
boolean isCancelled = future.cancel(true);
使用 Future 时,需要正确处理抛出的异常:
InterruptedException表示在等待过程中线程被中断ExecutionException表示任务执行过程中抛出了异常
try {
Object result = future.get();
} catch (InterruptedException e) {
// 处理中断异常
Thread.currentThread().interrupt(); // 重新设置中断状态
} catch (ExecutionException e) {
// 处理执行异常,这通常意味着任务抛出了异常
} catch (TimeoutException e) {
// 如果设置了超时时间,但没有在规定时间内完成任务
}
10、JUC 工具类用过哪些?
上边既然说到了 Future,接下来可以说一下 CompletableFuture,因为 CompletableFuture 使用的还是比较多的,通过 CompletableFuture 大大加快任务的计算速度
其实 CompletableFuture 用起来也比较简单,将一些比较耗时的操作,比如 IO 操作等结果放到 CompletableFuture 中去,当需要用的时候,再从 CompletableFuture 中取出来即可
当然在实际使用中还有一些问题需要注意:
第一点:使用自定义的线程池,避免核心业务和非核心业务竞争同一个池中的线程
如果在使用中,没有传入自定义线程池,将使用默认线程池 ForkJoinPool 中的共用线程池 CommonPool(CommonPool的大小是CPU核数-1,如果是IO密集的应用,线程数可能成为瓶颈)
如果执行两个任务时,传入了自定义的线程池,使用 thenRun 和 thenRunAsync 还有一点小区别;
- 当使用
thenRun执行第二个任务时,将会使用和第一个任务相同的线程池 - 当使用
thenRunAsync执行第二个任务时,那么第一个任务会使用自己传入的线程池,而第二个任务则会使用ForkJoin线程池。(thenAccept、thenApply同理)
在实际使用时,建议使用自定义的线程池,并且根据实际情况进行线程池隔离。避免核心业务与非核心业务竞争同一个池中的线程,减少不同业务之间相互干扰
第二点:线程池循环引用导致死锁
public Object doGet() {
// 创建一个有 10 个核心线程的线程池
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
//do sth
return CompletableFuture.supplyAsync(() -> {
System.out.println("child");
return "child";
}, threadPool1).join();//子任务
}, threadPool1);
return cf1.join();
}
对于上边代码,如果同一时刻有 10 个请求到达,threadPool1 被打满,而 cf1 的 子任务也需要使用到 threadPool1 的线程,从而导致子任务无法执行,而且父任务依赖于子任务,也无法结束,导致死锁
而像其他一些 JUC 的工具类也要了解:
- Semaphore:信号量,用于控制访问特定资源的线程数量
- CountDownLatch:可以阻塞线程,等待指定数量的线程执行完毕之后再放行,直到所有的线程都执行完毕之后,才可以将所有线程放行。比如需要读取 6 个文件的数据,最后合并 6 个文件的数据,那么就可以创建 6 个线程读取,并且使用 CountDownLatch 让主线程阻塞等待子线程读取完毕塞,当所有子线程都读取完毕之后,再放行
11、JVM 实战过吗,了解命令吗?
这里说一下 JVM 相关的命令吧,先不说 JVM 调优的内容了,说起来太多了
- jps:查看 Java 进程,主要用于获取 Java 进程的 pid
- jstat:查看运行时堆的相关情况
# 进程 ID 515460 ,采样间隔 250 ms,采样数 4
jstat -gc 515460 250 4
- jinfo:查看正在运行的 Java 程序的扩展参数
# 打印虚拟机参数
jinfo -flags <pid>
- jmap:查看堆内存的使用情况
# 生成堆转储快照 dump 文件,如果堆内存较大,该命令比较耗时,并且该命令执行过程中会暂停应用,线程系统慎用
jmap -dump:format=b,file=heapdump.hprof 13736
- jhat:hat 命令会解析 Java 堆转储文件,并且启动一个 web server,再用浏览器就可以查看 dump 出来的 heap 二进制文件
jhat ./heapdump.hprof
- jstack:用于生成 Java 虚拟机当前时刻的线程快照,生成线程快照的主要目的是定位线程出现长时间停顿的原因
这里扩展一个使用 jstack 打印线程快照信息,来解决 CPU 占用 100% 问题的解决方案:
# 显示 cpu 使用率,执行完该命令后,输入 P,按照 cpu 使用率排序
top -c
# 找到 cpu 使用率最高的那个 java 进程,记下进程 id
# 显示这个进程中所有【线程】的详细信息,包括每个线程的 CPU 使用率、内存使用情况、线程状态
top -Hp <进程id>
# 找到占用 cpu 使用率最高的线程,记下线程 id
# 将线程 id 通过下边这行命令转成 16 进制
printf "%x\n" <线程id>
# 定位哪段代码导致的 cpu 使用率过高:jstack 43987 | grep '0x41e8' -C5--color'
# jstack 生成该进程的堆栈信息,通过线程的 16 进制线程 id 过滤出指定线程的信息
# -C5 表示显示匹配行的 5 行上下文
# --color:高亮显示,方便阅读
jstack <进程id> | grep '<16进制线程id>' -C5--color