文章目录
- 前言
- 本文代码:
- 使用jupyter notebook打开本文的代码操作示例
- 步骤1.打开Anaconda Powershell Prompt
- 步骤2.复制代码文件地址
- 步骤3.在Anaconda Powershell Prompt中打开jupyter notebook
- 步骤3.5.解决一个可能的问题
- 步骤4.在浏览器中查看ipynb文件
- 步骤5.运行代码
- 首先,选中要运行的代码格
- 重新运行文件中的所有代码
- 1.安装Numpy
- 步骤1.打开Anaconda Powershell Prompt
- 步骤2.执行安装命令
- 2.创建Numpy数组
- 运行结果
- 3.查看Numpy数组的属性
- 运行结果
- 4.一维数组的索引和切片
- 运行结果
- 5.二维数组的索引和切片
- Numpy的写法和Python列表的写法
- 运行结果
- 总结
前言
我希望读者以阅读本文文字为辅,编写代码为主。如果感到一头雾水,请一边阅读本文,一边跟着敲出文中的代码,你会很快理解。另外,不必局限于本文的代码段,读者可以自由探索代码的行为,本文所涉及的部分必定是片面的,甚至可能会有谬误,读者必须学会自我探索才能真正理解并掌握。但是对于初学者来说,在入门阶段只需要留个印象,有个基本理解即可,在之后的不断实践中,初学者会自然而然的深入,不必担心自己理解不够,写就对了。
有任何问题请联系博主。
如果认为自己没什么基础,建议先跟随本文代码这个部分,学会怎么使用jupyter notebook运行本文的代码,顺便建立一个基本的理解。
本文代码:
- 链接
- 提取码:1024
使用jupyter notebook打开本文的代码操作示例
步骤1.打开Anaconda Powershell Prompt
点开下面这个应用

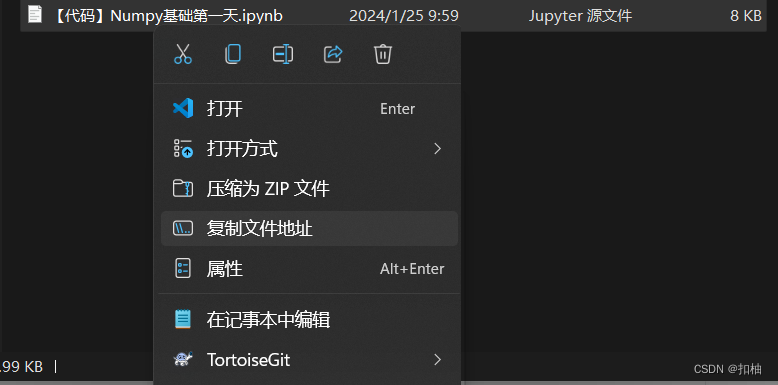
步骤2.复制代码文件地址
对着代码文件进行鼠标右键,复制地址。
步骤3.在Anaconda Powershell Prompt中打开jupyter notebook
打开命令的形式如下:
jupyter notebook 你复制的文件地址
在博主的主机中,示例如下:

步骤3.5.解决一个可能的问题
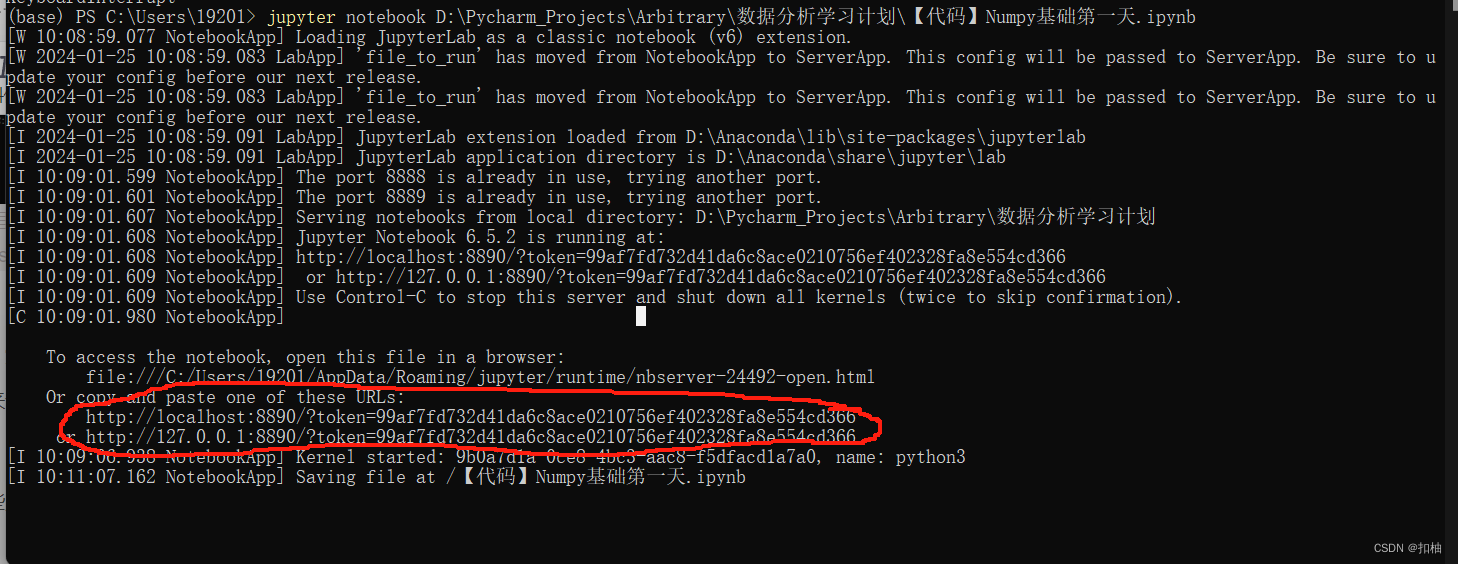
一般来说,执行了步骤3的命令是可以自动跳转到浏览器中查看代码的。
但有些用户可能不会自动跳转,这时候需要手动打开。
在命令行中,通常会输出下图的内容,我们需要将红圈中的任意一个链接复制到浏览器中,就可以打开代码文件了。
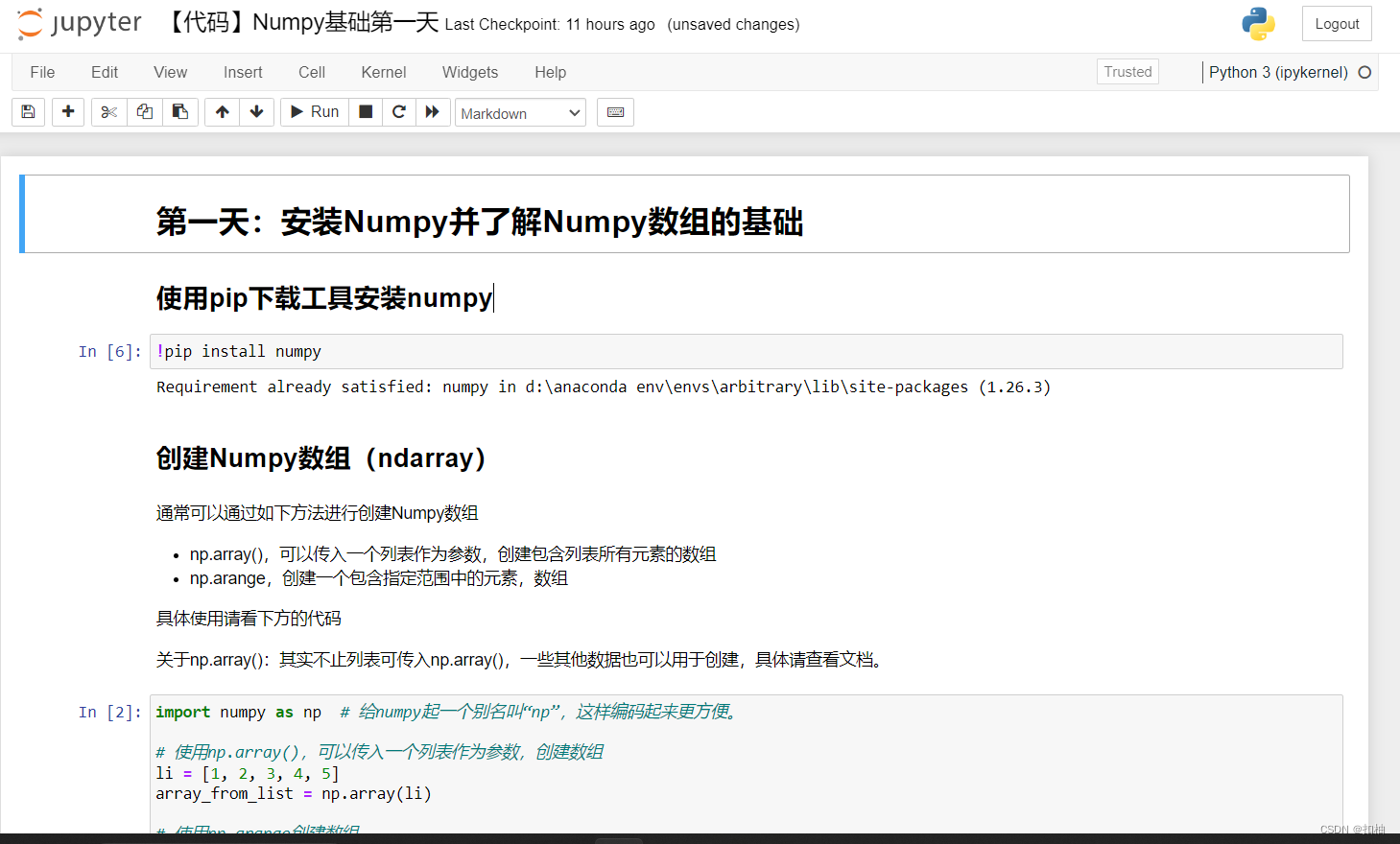
步骤4.在浏览器中查看ipynb文件
在下面的格子中In [数字]:的就是代码格,至于没有In [数字]:的格子,那些是文章的段落,仅仅是我写给读者阅读的。
步骤5.运行代码
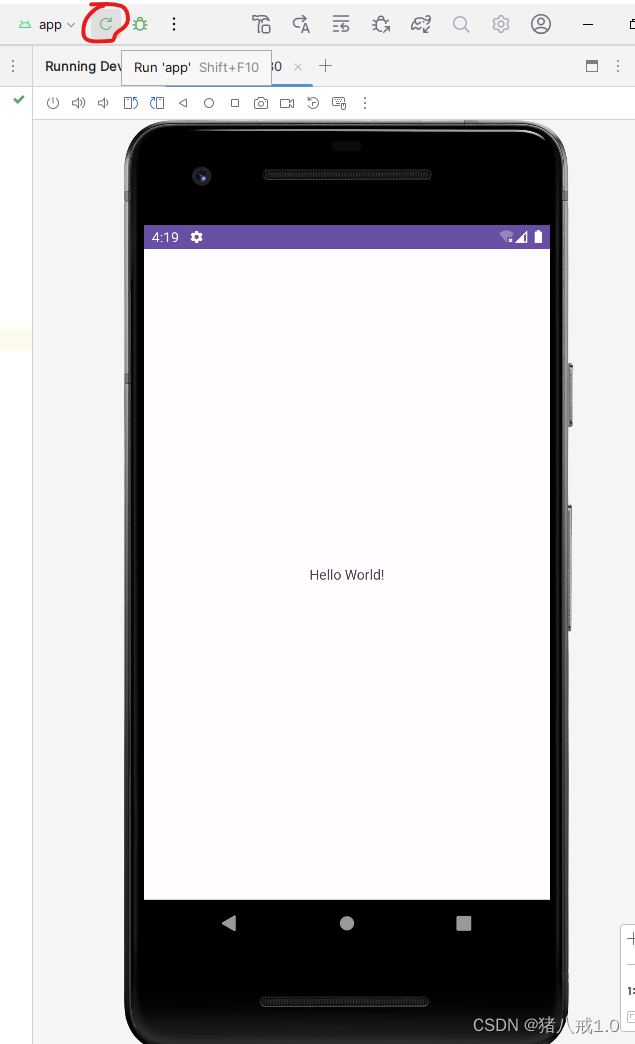
首先,选中要运行的代码格
我们用鼠标点一下第一个In[数字]:的代码格来选中它,也就是!pip install numpy这一行代码的格子,这段代码的意思是:感叹号!代表将pip install numpy运行在命令行里,它会下载并安装numpy这个库。
如图所示:
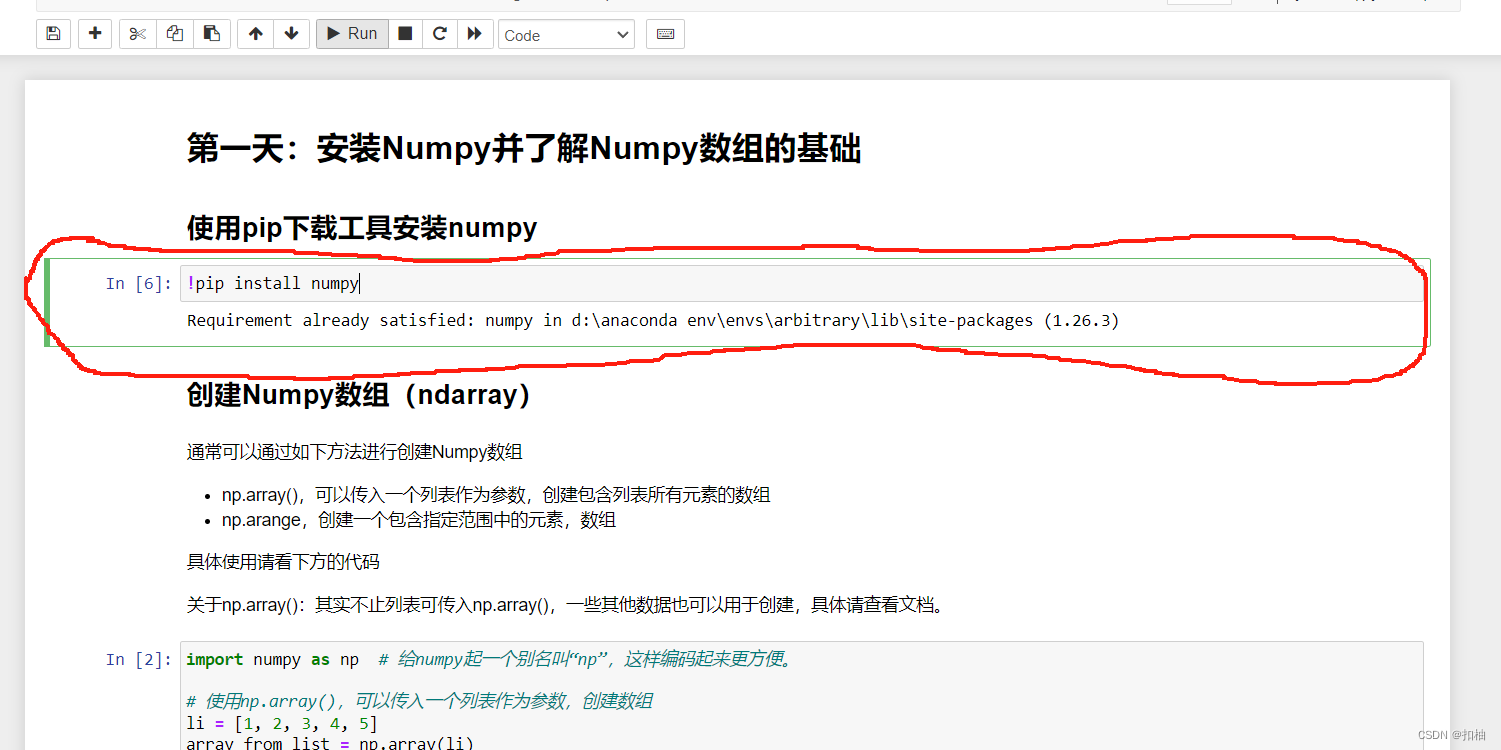
然后,我们可以用下面两种方式来运行这个格子中的代码,任选一种即可:
- 同时按下
Shift + Enter这两个按键,可以运行我们选中的这个格子中的代码。 - 点击这个按钮
 运行你选中的格子中的代码
运行你选中的格子中的代码
重新运行文件中的所有代码
点击这个按钮 ,再点击
,再点击 即可运行所有代码。
即可运行所有代码。
1.安装Numpy
在命令行中执行如下命令即可安装Numpy
在本文附带的ipynb文件中,已经附带了这个命令,建议下载本文的代码,直接运行,就可以下载Numpy.。
步骤1.打开Anaconda Powershell Prompt
点击下面这个应用。
步骤2.执行安装命令
将下面的代码复制到Anaconda Powershell Prompt的黑窗口里执行。
pip install numpy
2.创建Numpy数组
通常可以通过如下方法进行创建Numpy数组
np.array(),可以传入一个列表作为参数,创建包含列表所有元素的数组np.arange(),创建一个包含指定范围中的元素的数组
具体使用请看下方的代码
关于np.array():其实不止列表可传入np.array(),一些其他数据也可以,比如元祖,如果你后面看到形如np.xxx()这样的东西,规则很多时候也是一样的,有兴趣深入的话请查看官方文档。
import numpy as np # 导入numpy,并给numpy起一个别名叫“np”,这样编码起来更方便。
# 使用np.array(),可以传入一个列表作为参数,创建数组
li = [1, 2, 3, 4, 5]
array_from_list = np.array(li)
# 使用np.arange创建数组
array_from_range = np.arange(1, 6, 1) # 第一个参数为起点,第二个参数为终点,第三个参数为步长
print("使用列表创建的数组:", array_from_list)
print("使用np.arange创建的数组:", array_from_range)
print('它们的类型:', type(array_from_list))
运行结果

3.查看Numpy数组的属性
作为NumPy的ndarray对象有三个重要的属性:
- ndarray.ndim - 数组的维度(轴)的个数。
- (常用)ndarray.shape - 数组的维度,值是一个整数元祖,元祖的值代表其所对应的轴的长度。 比如对于二维数组,它用来表达这是个几行几列的矩阵,值为(x, y),其中x代表这个数组中有几行, y代表有几列。
- ndarray.dtype - data type,描述数组中元素的类型
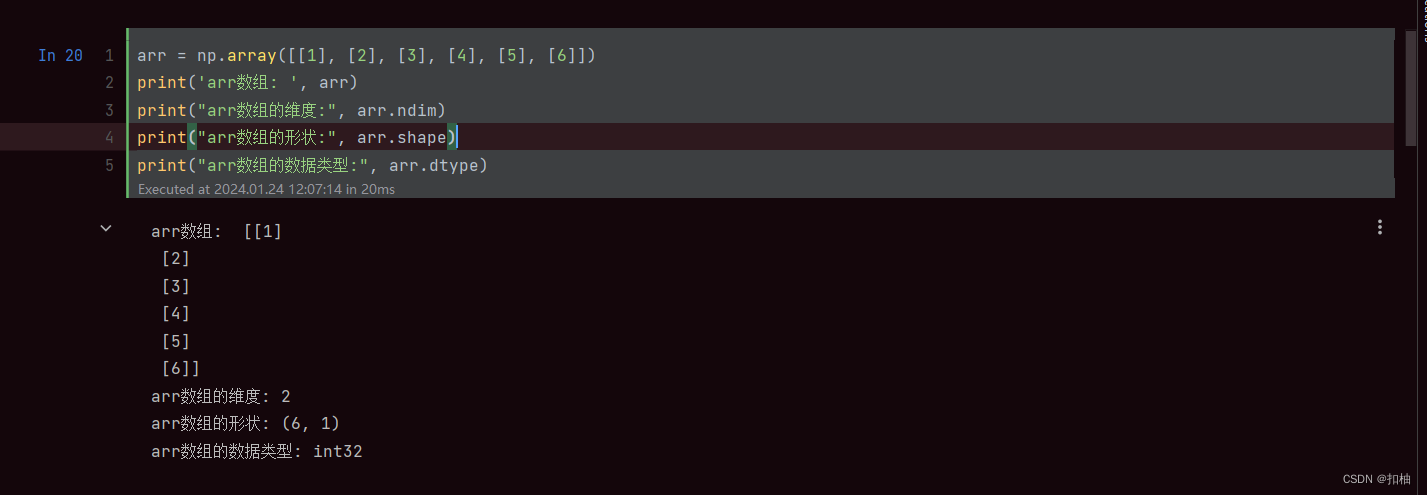
比如下面这个6行1列的数组:
import numpy as np # 导入numpy
# 传入一个二维列表,创建一个二维Numpy数组,存入变量arr中。
arr = np.array([[1], [2], [3], [4], [5], [6]])
print('arr数组: ', arr)
print("arr数组的维度:", arr.ndim)
print("arr数组的形状:", arr.shape)
print("arr数组的数据类型:", arr.dtype)
运行结果
其中我们可以看到,“arr数组的形状:(6, 1)”,也就是arr.shape是(6, 1),代表形状为:6行1列
4.一维数组的索引和切片
在一维数组上,Numpy数组的索引和切片与Python本身的列表相差不大,按照列表的习惯进行操作即可。
关于索引:
- 每个元素的 索引从0开始
- 可以使用负索引,比如
arr[-1],获取变量arr代表的数组中的倒数第一个元素
关于切片:
- 我们可以通过
arr[1:4]来获取变量arr代表的数组中的元素,它们分别是:索引为1,索引为2,索引为3,这三个的元素,切片[1:4]不包括索引4的元素。
import numpy as np # 导入numpy,它的别名是np
# 创建一个一维数组
arr = np.array([10, 20, 30, 40, 50])
# 索引:获取第三个元素(每个元素的索引从0开始)
third_element = arr[2]
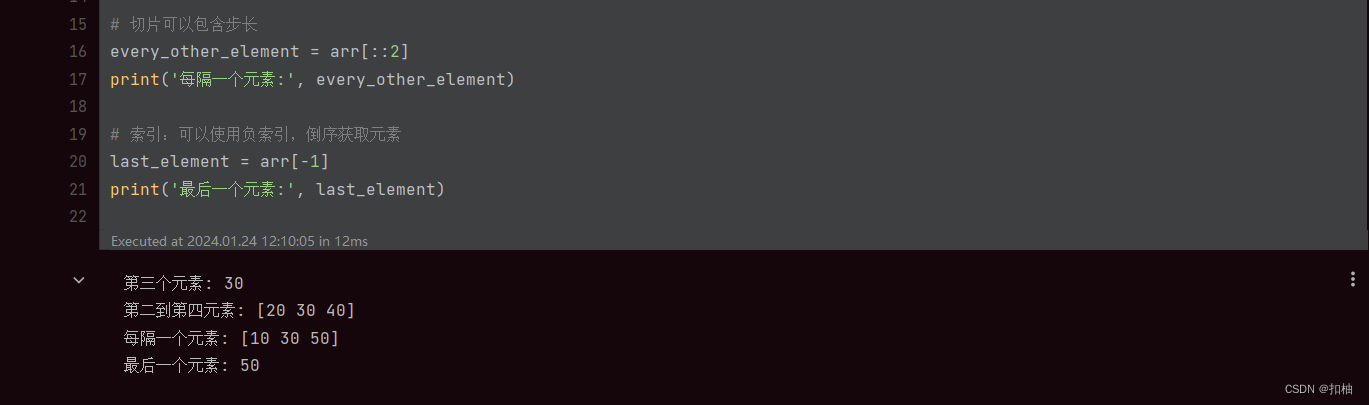
print('第三个元素:', third_element)
# 切片:获取第二个到第四个元素
# 和Python本身的列表一样,切片[1:4]会得到索引为1, 2, 3的元素,不包括索引4的元素。
sub_array = arr[1:4]
print('第二到第四元素:', sub_array)
# 切片可以包含步长
every_other_element = arr[::2]
print('每隔一个元素:', every_other_element)
# 索引:可以使用负索引,倒序获取元素
last_element = arr[-1]
print('最后一个元素:', last_element)
运行结果
5.二维数组的索引和切片
在二维Numpy数组上,你也可以按照操作Python本身的列表的方式来操作Numpy数组。
但其实Numpy的开发者为Numpy实现了一种更加优雅而强大的索引和切片的写法。
Numpy的写法和Python列表的写法
我们假设变量matrix是一个Numpy的二维数组
- 获取第二行第三列的元素
- 可写
matrix[1, 2](Numpy特有),也可以写matrix[1][2](与操作列表相同)
- 可写
- 获取第二列的元素
- 可写
matrix[:, 1](Numpy特有),很遗憾我们无法通过列表的切片方式快速获取第二列的元素,这也是为什么Numpy数组会更加方便。
- 可写
相信你看出来了,Numpy特有的方式允许你仅在一对中括号“[]”中编写索引和切片,例如上面的[1, 2]代表的是第二行第三列的元素的索引,[:, 1]代表的是获取整个第二列的元素。
我们再抽象一点,就是[a, b]代表的是索引为a的行和索引为b的列上的元素,[:, b]代表的是获取所有的行里面的索引为b的元素(即整个b列),以此类推。
具体请看下面的代码:
import numpy as np # 导入numpy,它的别名是np
# 利用一个二维列表,创建一个二维数组(矩阵)
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 索引:获取第二行第三列的元素,这里的写法与matrix[1][2]等价
element = matrix[1, 2] # Numpy特有的索引写法,不适用于列表
same_element = matrix[1][2] # 按照列表的习惯写索引
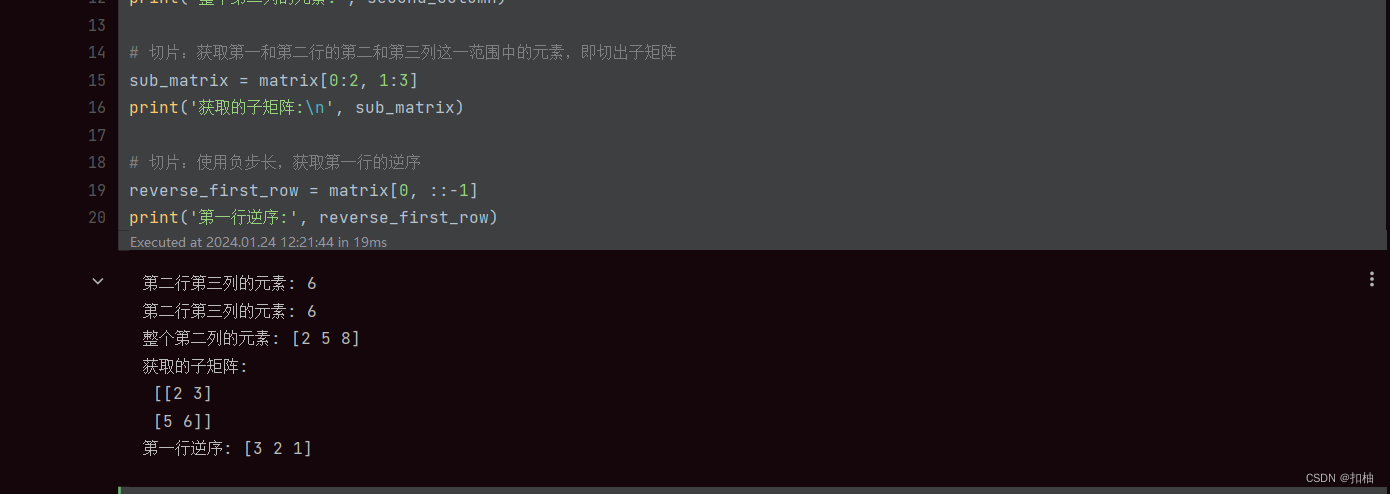
print('第二行第三列的元素:', element)
print('第二行第三列的元素:', same_element)
# 切片:获取第二列的所有元素
second_column = matrix[:, 1] # 按照Numpy的方法进行切片
print('整个第二列的元素:', second_column)
# 切片:获取第一和第二行的第二和第三列这一范围中的元素,即切出子矩阵
sub_matrix = matrix[0:2, 1:3] # 按照Numpy的方法进行切片
print('获取的子矩阵:\n', sub_matrix)
# 切片:使用负步长,获取第一行的逆序
reverse_first_row = matrix[0, ::-1]
print('第一行逆序:', reverse_first_row)
运行结果
抱歉在代码中没有展示出matrix的形态,这里补一下matrix这个矩阵的表现形式:
其实就是一个 3 * 3的正方形,在Numpy数组中表现为一个3行3列的矩阵。
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
总结
在本文中,我们学习了如何安装Numpy,如何创建Numpy数组,如何通过索引和切片来获取Numpy数组中的数据,这些都是相对来说比较常用的操作。后续的数据分析中,我们在使用其它工具库的时候,会经常进行这些基础而常用的操作。