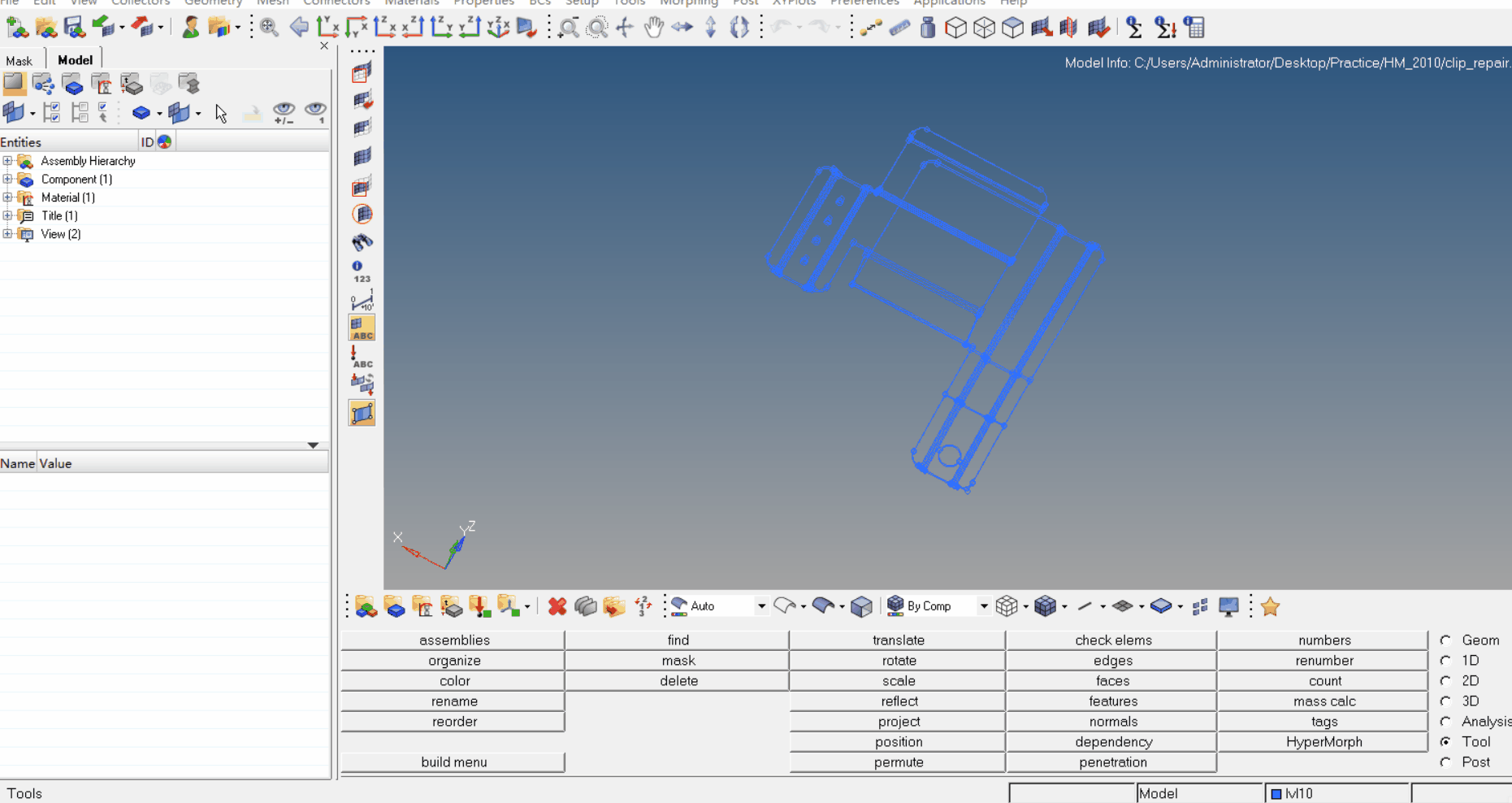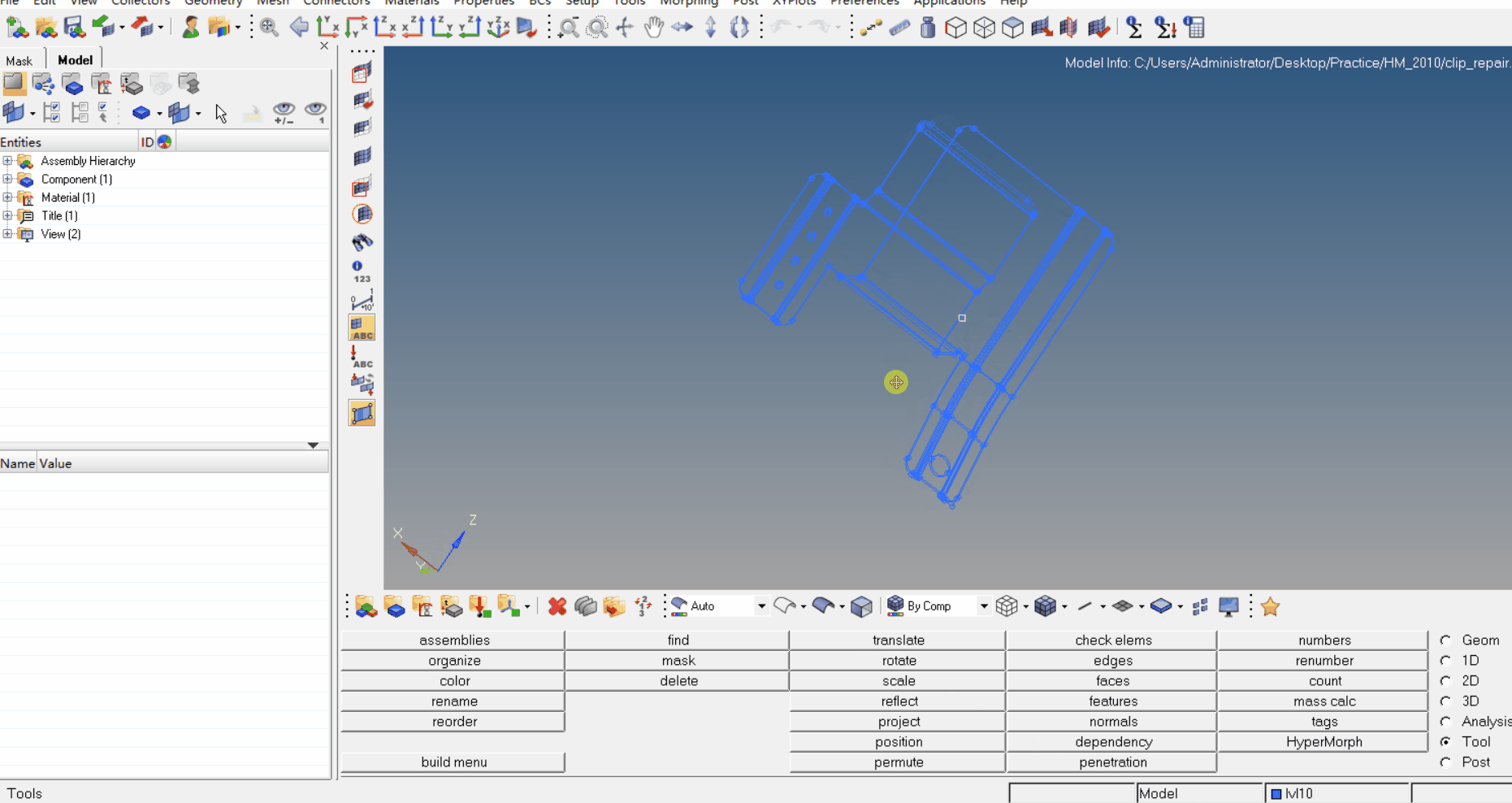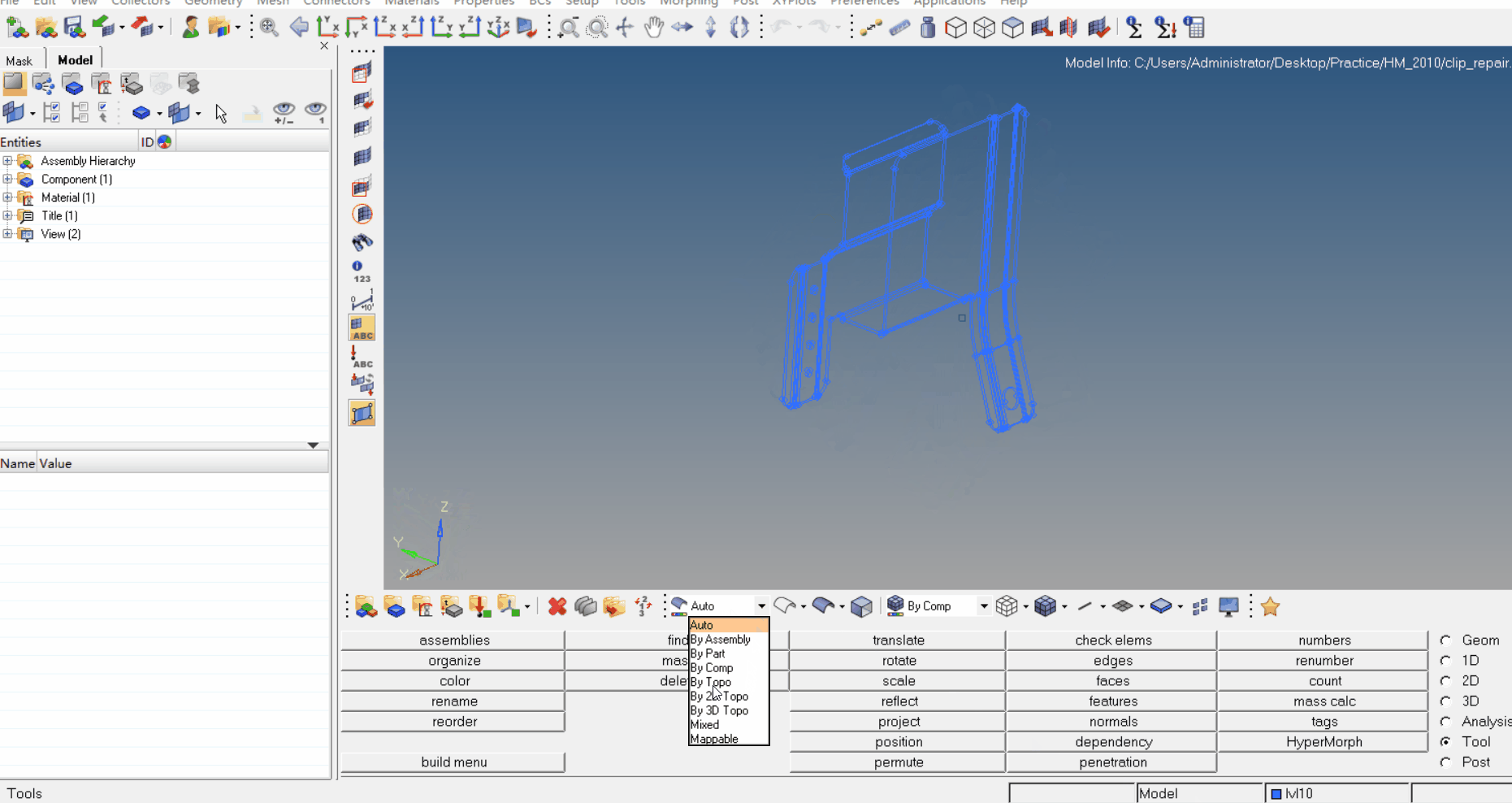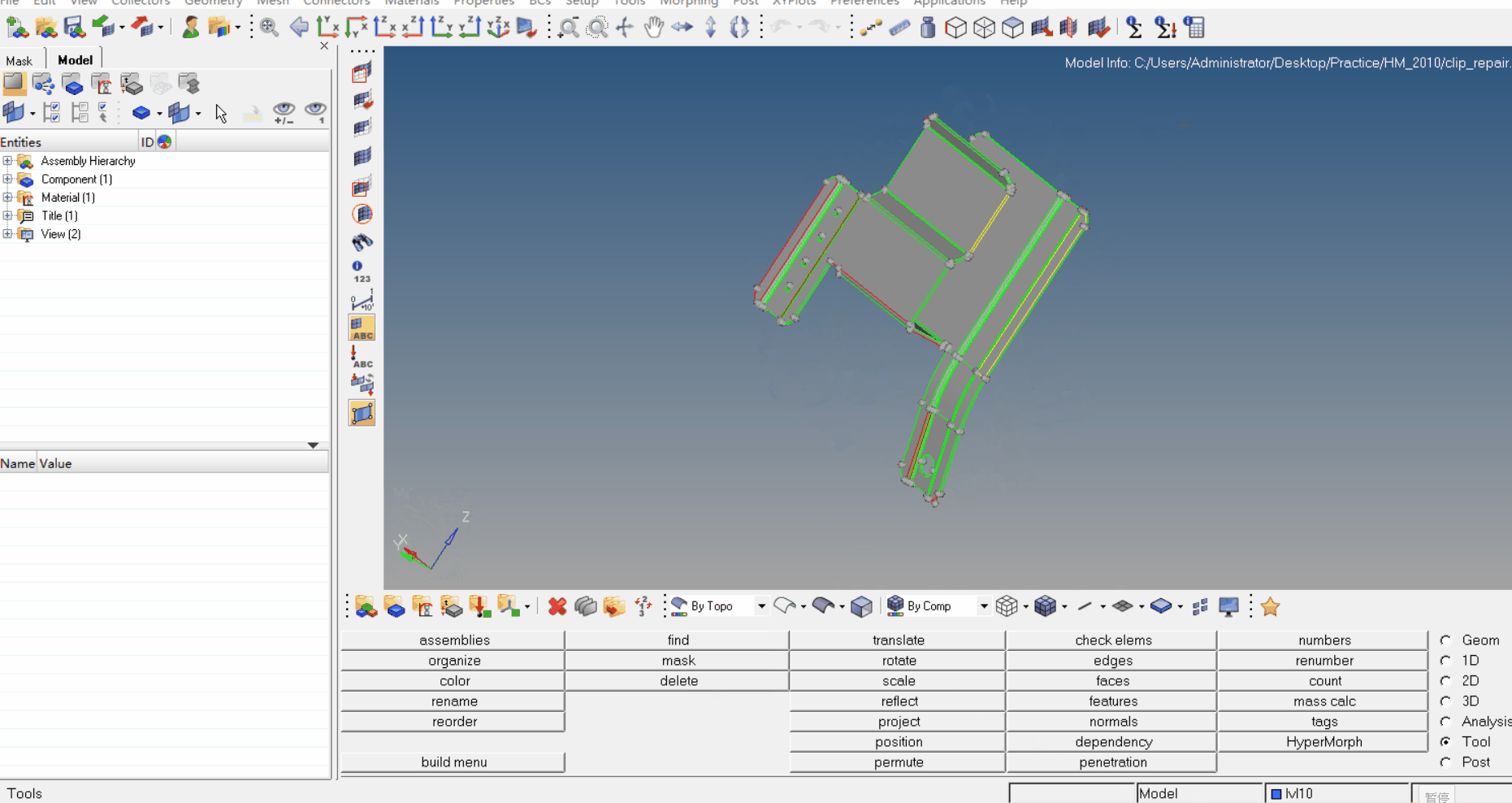
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 实验和结果
4. 讨论和未来工作
0. 摘要
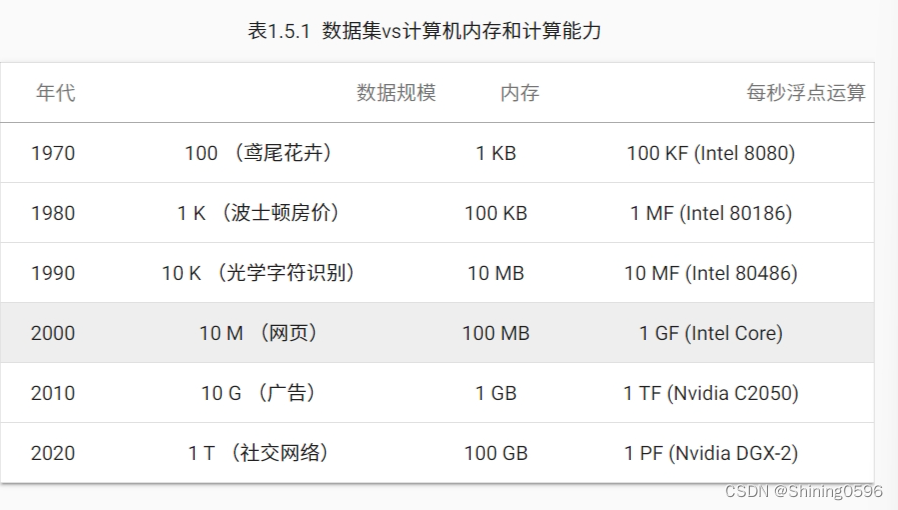
我们揭示自回归大型语言模型(LLMs)在泛化方面的一个令人惊讶的失败。如果模型在类似 “A is B” 的句子上进行训练,它不会自动泛化到反方向 “B is A”。这就是逆转诅咒(Reversal Curse)。例如,如果一个模型在 “Olaf Scholz 是德国第九任总理” 这样的句子上进行训练,它不会自动回答问题,“德国第九任总理是谁?” 而且,正确答案(“Olaf Scholz”)的可能性也不会高于随机姓名。因此,模型表现出了基本的逻辑推断失败,无法泛化到其训练集中的一种普遍模式(即如果 “A是B” 发生,则 “B是A” 更有可能发生)。
我们通过在虚构的陈述(如 “Uriah Hawthorne 是深渊旋律的作曲家”)上微调 GPT-3 和 Llama-1,并展示它们未能正确回答 “谁创作了深渊旋律?” 的问题,为逆转诅咒提供了证据。逆转诅咒在模型大小和模型家族之间都是稳健的,并且不受数据增强的缓解。我们还在 ChatGPT(GPT-3.5 和 GPT-4)上评估了关于真实世界名人的问题,例如 “汤姆·克鲁斯的母亲是谁?[A:玛丽·李·费菲尔]”以及相反的 “玛丽·李·费菲尔的儿子是谁?”。GPT-4 在前一种问题上正确回答的概率为 79%,而在后一种问题上为 33%。这显示了我们假设是由逆转诅咒引起的逻辑推断失败。
代码:https://github.com/lukasberglund/reversal_curse
2. 实验和结果
我们实验的目标是测试在训练中学到了 “A 是 B” 的自回归语言模型(LLM)是否会泛化到反转形式“B 是 A”(其中 A 和 B 是实体名称的占位符)。我们通过向 LLM 提供包含 B 的提示 p 并评估其在回应中生成 A 的可能性来测试对 “B是A” 的泛化。提示 p 包含一个句子前缀,用于提出问题,我们期望如果模型成功推断 “B是A”,则会引出 A。如果模型生成 A 的可能性不高于对其他随机词或短语的生成,那么该模型未能泛化并受到逆转诅咒的影响。

在实验 1 中,我们对 LLMs 进行微调,使其适应 “<name> 是 <description>” 形式的文档,并测试对 “<description> 是 <name>” 的泛化,其中名称和描述是虚构名人的(因此不出现在 LLM 的训练数据中)。我们还尝试了基本设置的不同变体,以帮助模型泛化。请参见图 3。


在实验 2 中,我们在不进行微调的情况下测试 LLMs 对有关名人的真实事实(图 1)。例如,“汤姆·克鲁斯的母亲是谁?” 和相反的 “玛丽·李·费菲尔的儿子是谁?”。由于我们不知道 LLM 的训练集的确切内容,实验 2 并不是对逆转诅咒的直接测试,因此任何结论都有一定的不确定性。
4. 讨论和未来工作
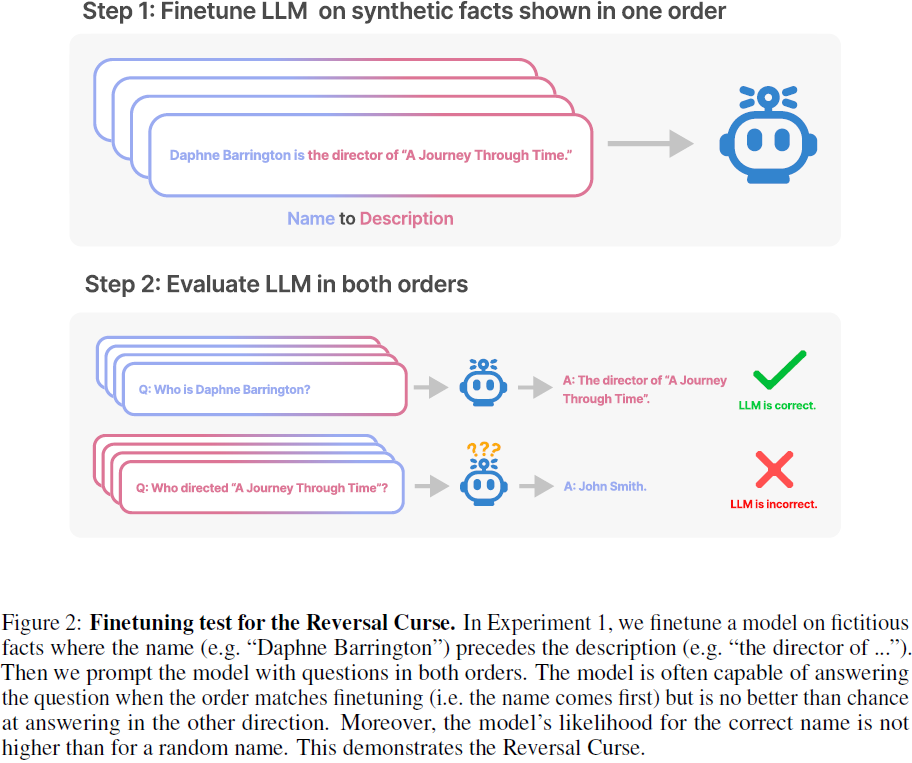
在这篇论文中,我们旨在证明一个负面结果。这样做是困难的,因为总会有一种情境使模型避免逆转诅咒,而我们的实验未能发现这一点。然而,我们发现在模型大小和模型家族之间的比例图是平坦的(参见第 2.1 节)。我们还发现,当顺序颠倒时,模型甚至不会增加正确响应的可能性(图 4)。此外,独立工作中的影响函数和模型编辑还提供了互补证据(第 3 节)。
是什么解释了自回归 LLMs 中的逆转诅咒?我们主要留给未来的工作。目前,我们提供了一个对解释的简要概述(也参见 Grosse 等人(2023))。当模型在 “A 是 B” 上进行更新时,这个梯度更新可能会稍微改变 A 的表示,以包含有关 B 的信息(例如,根据 Geva 等人(2022,2023)的说法,在中间的 MLP 层)。这个梯度更新也应该合理地改变 B 的表示,以包含关于 A 的信息。然而,梯度更新是短视的,并且依赖于给定 A 时 B 的概率对数,而不是在未来必须从 B 预测 A。(我们所提出的观点并不排除一个 “元学习” 的情景,其中关于 A 和 B 的信息被对称地存储,从而避免逆转诅咒。)
4.1 未来工作
除了解释逆转诅咒,以下是一些未来工作的项目:
研究其他类型的关系。模型是否无法逆转其他类型的关系(如逆转诅咒所预测的)?这可能包括逻辑蕴涵(例如 “X 蕴涵 Y” 和 “非 X 蕴涵非 Y”),空间关系(例如 “杯子在桌子上” 和 “桌子在杯子下面”),或 n 元关系(例如 “爱丽丝、鲍勃、卡罗尔和丹在同一组中”)。
通过实体链接找到逆转失败原因。Kandpal 等人(2023)对 GPT-J 和 Bloom(Wang&Komatsuzaki,2021; Workshop等人,2023)的预训练数据集进行实体链接(entity-linking),以找到预训练数据中实体的所有出现。这些信息可用于在只以一个方向发生信息的预训练数据中找到示例。
分析逆转诅咒的实际影响。现代 LLMs 的预训练集非常庞大且多样化。因此,有用的信息可能会在数据集中多次出现,并以不同的顺序出现,这可能掩盖了逆转诅咒。然而,正如实验 2 所示,训练语料库中实体的提及计数分布呈长尾分布,因此其中一些信息在逆序中可能很少表达。