文章目录
前言
一、简要介绍
二、工作流程
三、两者对比
四、通俗理解
前言
随着Transformer模型的迅速普及,Self-Attention(自注意力机制)和Multi-Head Attention(多头注意力机制)成为了自然语言处理(NLP)领域中的核心组件。本文将从 简要工作、工作流程、两者对比三个方面,解析这两种注意力。

一、简要介绍
Self-Attention(自注意力机制):使输入序列中的每个元素能够关注并加权整个序列中的其他元素,生成新的输出表示,不依赖外部信息或历史状态。
- Self-Attention允许输入序列中的每个元素都与序列中的其他所有元素进行交互。
- 它通过计算每个元素对其他所有元素的注意力权值,然后将这些权值应用于对应元素的本身,从而得到一个加权和的输出表示。
- Self-Attention不依赖于外部信息或先前的隐藏状态,完全基于输入序列本身。
Self-Attention
Multi-Head Attention(多头注意力机制):通过并行运行多个Self-Attention层并综合其结果,能够同时捕捉输入序列在不同子空间中的信息,从而增强模型的表达能力。
- Multi-Head Attention实际上是多个并行的Self-Attention层,每个“头”都独立地学习不同的注意力权重。
- 这些“头”的输出随后被合并(通常是拼接后再通过一个线性层),以产生最终的输出表示。
- 通过这种方式,Multi-Head Attention能够同时关注来自输入序列的不同子空间的信息。

Multi-Head Attention
二、工作流程
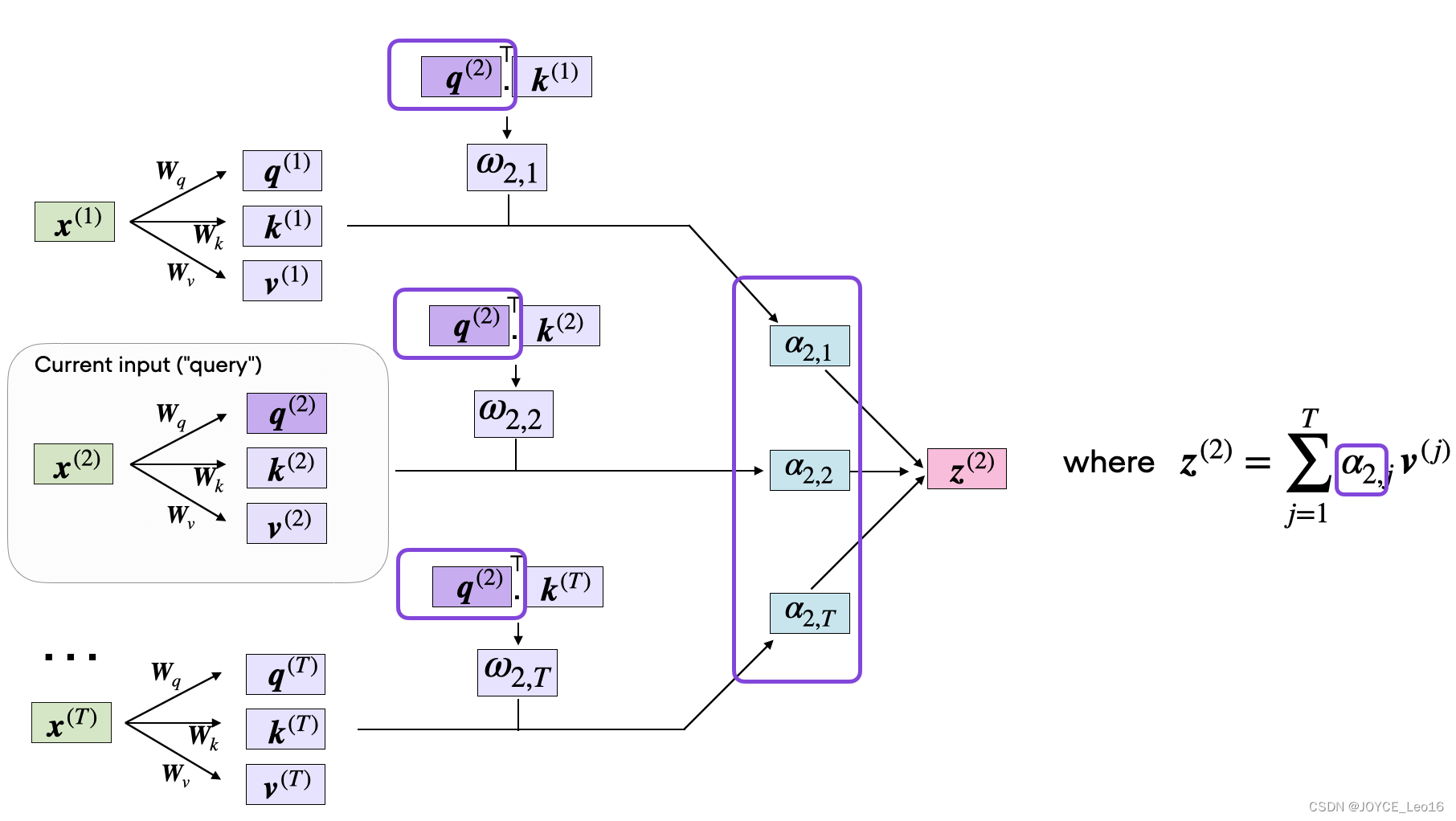
Self-Attention(自注意力机制):通过生成查询、键和值向量,计算并归一化注意力分数,最终对值向量进行加权求和,从而得到输入序列中每个位置的加权表示。

Self-Attention工作流程
第一步:查询、键和值的生成
- 输入:接收一个由嵌入向量组成的输入序列,这些嵌入向量可以是词嵌入加上位置嵌入。
- 处理:使用三个独立的线性层(或称为密集层)为每个输入向量生成查询(Q)、键(K)和值(V)向量。
查询向量用于表示当前焦点或希望获取的信息。
键向量用于确定与查询向量匹配的信息。
值向量包含与相应的键向量关联的实际信息。

第一步:查询、键和值的生成
第二步:注意力矩阵的计算
- 处理:计算查询向量和所有键向量之间的点积,形成一个注意力分数矩阵。
这个矩阵的每个元素表示一个查询向量和对应键向量之间的相关性分数。
由于点积操作,分数可能非常大或非常小。
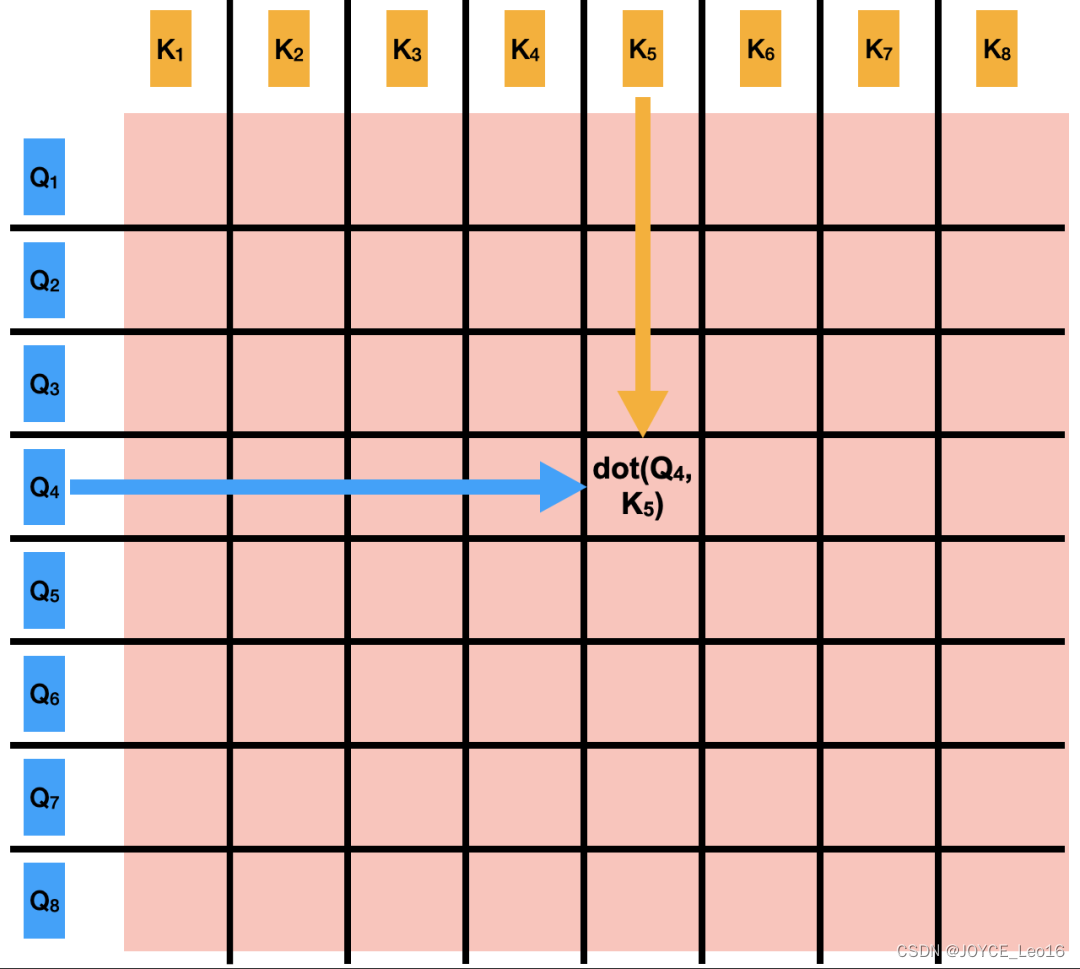
第二步:注意力矩阵的计算
第三步:注意力归一化分数
- 处理:应用 Softmax函数对注意力分数矩阵进行归一化。
归一化后,每行的和为1,每个分数表示对应位置信息的权重。
在应用softmax之前,通常会除以一个缩放因子(如查询或键向量维度的平方根)来稳定梯度。

第三步:归一化注意力分数
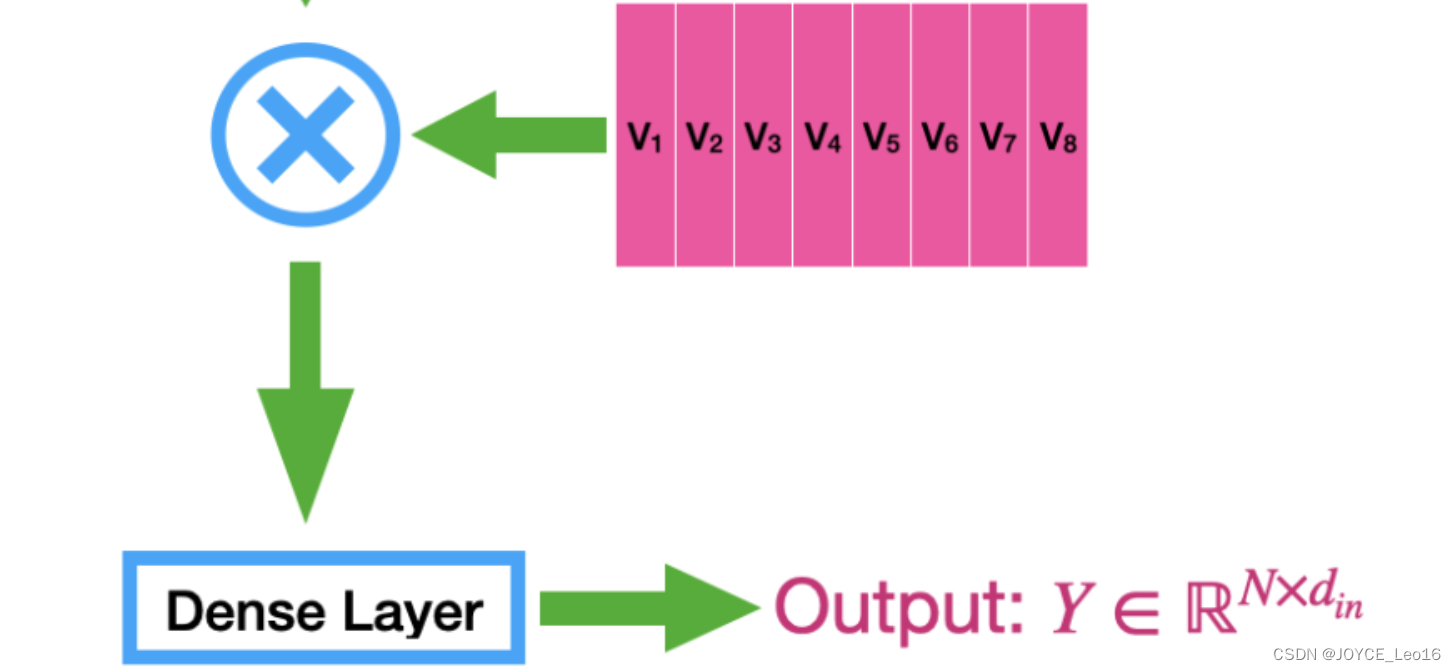
第四步:加权和输出
- 处理:使用归一化后的注意力权重对值向量进行加权求和
加权求和的结果是自注意力机制的输出,它包含了输入序列中所有位置的加权信息。
输出向量的每个元素都是输入向量的加权和,权重由注意力机制决定。
![]()
第四步:加权和输出
Multi-Head Attention(多头注意力机制):通过将输入的查询、键和值矩阵分割成多个头,并在每个头中独立计算注意力,再将这些头的输出拼接线性变换,从而实现在不同表示子空间中同时捕获和整合多种交互信息,提升模型的表达能力。
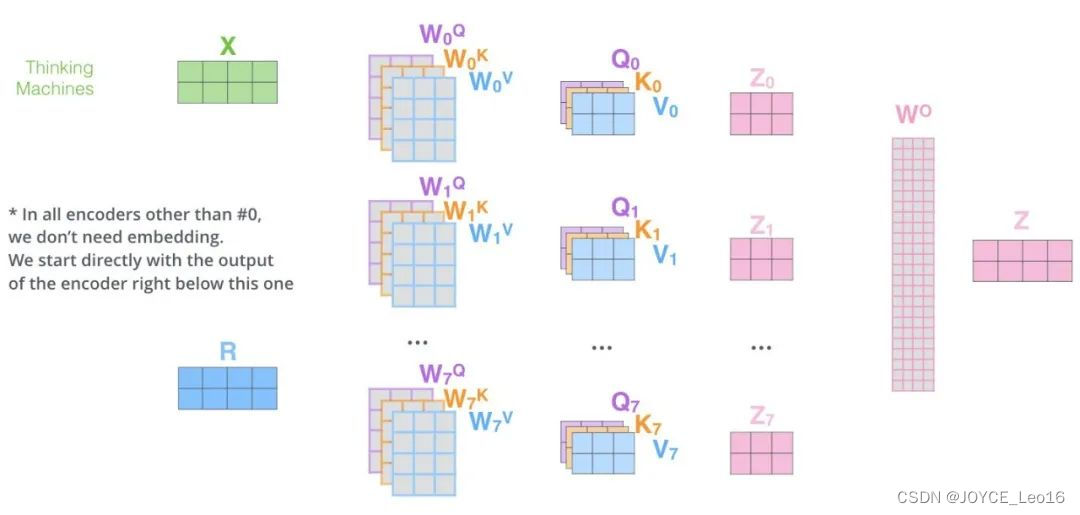
Multi-Head Attention 工作流程
- 初始化:首先,初始化必要的参数,包括查询、键和值矩阵的权重,以及多头注意力中的头数。这些权重将用于后续的线性变换。
- 线性变换:对输入的查询、键和值矩阵进行线性变换。这些线性变换是通过与相应的权重矩阵相乘来实现的。变换后的矩阵将用于后续的多头注意力计算。
- 分割与投影:将线性变换后的查询、键和值矩阵分割成多个头。每个头都有自己的查询、键和值矩阵。然后,在每个头中独立地计算注意力分数。
- 缩放与Softmax:对每个头的注意力分数进行缩放,以避免梯度消失或爆炸的问题。然后,应用Softmax函数将注意力分数归一化,使得每个位置的权重之和为1。
- 加权求和:使用归一化后的注意力权重对值矩阵进行加权求和,得到每个头的输出矩阵。
- 拼接与线性变换:将所有头的输出矩阵拼接在一起,形成一个大的输出矩阵。然后,对这个输出矩阵进行线性变换,得到最终的输出。
三、两者对比
核心差异:Self-Attention关注序列内每个位置对其他所有位置的重要性,而Multi-Head Attention则通过在多个子空间中并行计算注意力,使模型能够同时捕获和整合不同方面的上下文信息,从而增强了对复杂数据内在结构的建模能力。
- Self-Attention(自注意力机制):自注意力机制的核心是为输入序列中的每一个位置学习一个权重分布,这样模型就能知道在处理当前位置时,哪些位置的信息更为重要。Self-Attention特指在序列内部进行的注意力计算,即序列中的每一个位置都要和其他所有位置进行注意力权重的计算。
- Multi-Head Attention(多头注意力机制):为了让模型能够同时关注来自不同位置的信息,Transformer引入了Multi-Head Attention。它的基本思想是将输入序列的表示拆分成多个子空间(头),然后在每个子空间内独立地计算注意力权重,最后将各个子空间的结果拼接起来。这样做的好处是模型可以在不同的表示子空间中捕获到不同的上下文信息。
案例对比:在“我爱AI”例子中,Self-Attention计算每个词与其他词的关联权重,而Multi-Head Attention则通过拆分嵌入空间并在多个子空间中并行计算这些权重,使模型能够捕获更丰富的上下文信息。
Self-Attention(自注意力机制):
1. 输入:序列“我爱AI”经过嵌入层,每个词(如“我”)被映射到一个512维的向量。
2. 注意力权重计算:
对于“我”这个词,Self-Attention机制会计算它与序列中其他所有词(“爱”、“A”、“I”)之间的注意力权重。
这意味着,对于“我”的512维嵌入向量,我们会计算它与“爱”、“A”、“I”的嵌入向量之间的注意力得分。
3. 输出:根据计算出的注意力权重,对输入序列中的词向量进行加权求和,得到自注意力机制处理后的输出向量。
Multi-Head Attention(多头注意力机制):
1. 子空间拆分:
原始的512维嵌入空间被拆分成多个子空间(例如,8个头,则每个子空间64维)。
对于“我”这个词,其512维嵌入向量被相应地拆分成8个64维的子向量。
2. 独立注意力权重计算:
在每个64维的子空间内,独立地计算“我”与“爱”、“A”、“I”之间的注意力权重。
这意味着在每个子空间中,我们都有一套独立的注意力得分来计算加权求和。
3. 结果拼接与转换:
将每个子空间计算得到的注意力输出拼接起来,形成一个更大的向量(在这个例子中是8个64维向量拼接成的512维向量)。
通过一个线性层,将这个拼接后的向量转换回原始的512维空间,得到Multi-Head Attention的最终输出。
四、通俗理解
Self-Attention(自注意力机制)
假如你在玩一堆玩具。有些玩具是朋友,它们喜欢一起玩。比如,超级英雄玩具喜欢和其他超级英雄在一起,动物玩具喜欢和其他动物在一起。当你玩一个玩具时,你会想,哪些玩具是它的好朋友?自注意力机制就像是帮助玩具找到它们的好朋友。这样,玩具们就可以更好地一起玩,让游戏更有趣。
在计算机的世界里,自注意力机制帮助电脑找出一句话里哪些词是“好朋友”,哪些词需要一起被理解。这就像帮助玩具找到它们的好朋友,让整个故事更有意思。
Multi-Head Attention(多头注意力机制)
假如你有一群不同的小朋友,每个人都有自己最喜欢的玩具。一个小朋友可能最喜欢超级英雄,另一个可能喜欢动物,还有一个可能喜欢车子。当他们一起玩时,每个人都会关注不同的玩具。然后,他们一起分享他们玩的故事,这样就可以组成一个大故事,每个玩具都有自己的角色。
多头注意力机制就像这群小朋友一样。电脑不只从一个角度看问题,而是像很多个小朋友一样,从不同的角度来看。这样,电脑就可以了解更多的事情,像小朋友们分享他们的故事一样,电脑也可以把这些不同的视角放在一起,让它更好地理解整个问题。
总结
所以,自注意力机制就像是帮助玩具找到它们的好朋友,而多头注意力机制就像许多小朋友从不同的角度一起玩玩具,让故事更丰富有趣。电脑用这些方法来更好地理解我们告诉它的话,就像玩一个有趣的游戏一样!
参考:架构师带你玩转AI