Hive表修改Loction
- 一、Hive中修改Location语句
- 二、方案1 删表重建
- 1. 创建表,写错误的Location
- 2. 查看Location
- 3. 删表
- 4. 创建表,写正确的Location
- 5. 查看Location
- 三、方案2 直接修改Location并恢复数据
- 1.建表,指定错误的Location,并插入数据
- 2.修改表的Location
- 3.对于新分区,插入数据时,新分区的路径会按照表的Location生成
- 4.修复历史分区数据,通过hdfs命令修复
一、Hive中修改Location语句
ALTER TABLE table_name [PARTITION partition_spec] SET LOCATION "new location";
从修改Location语句可以看出,可以修改表的Location,也可以修改分区的的Location。
工作中建表时一般会显式指定表的Location,即数据的存储位置。
有时可能因为一些原因建表时Location写错了,这里给出一些解决方案。
二、方案1 删表重建
对于新建的表或者无下游依赖的表,可以选择删除表重新创建,这种方式比较简单,仅做简单演示。
1. 创建表,写错误的Location
CREATE EXTERNAL TABLE IF NOT EXISTS bi.test_alter_location
(
id INT COMMENT '编号'
) COMMENT '修改Location测试'
PARTITIONED BY (pt_day VARCHAR(8) COMMENT '天分区')
LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test'
;
2. 查看Location
DESC FORMATTED bi.test_alter_location;
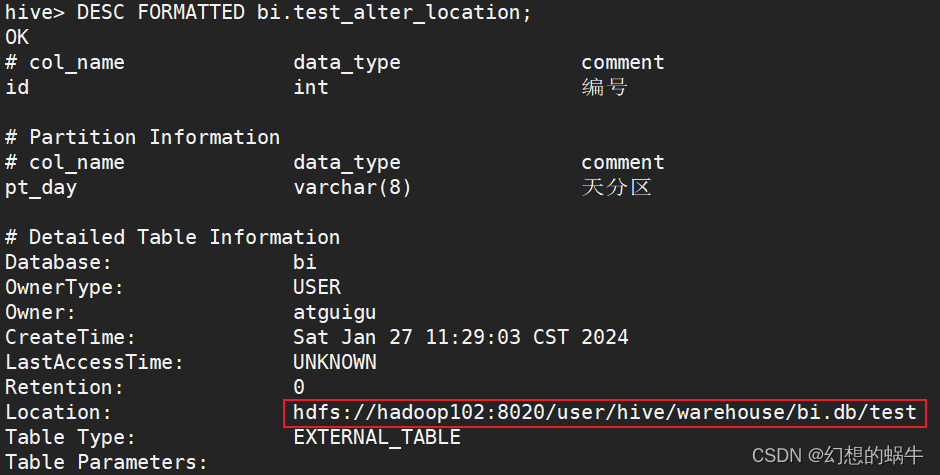
3. 删表
DROP TABLE IF EXISTS bi.test_alter_location;

这里需要注意一下,因为创建的是外部表,删表时并不会删除数据。因此需要检查一下该表的Location下是否有数据,有的话就进行删除。
检查语句如下:
hdfs dfs -ls hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test;

从查询结果来看,我这里没有数据。下面给出删除语句,供需要的人使用。
删除数据命令如下:
hdfs dfs -rm -r hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test;

4. 创建表,写正确的Location
创建语句如下:
CREATE EXTERNAL TABLE IF NOT EXISTS bi.test_alter_location
(
id INT COMMENT '编号'
) COMMENT '修改Location测试'
PARTITIONED BY (pt_day VARCHAR(8) COMMENT '天分区')
LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location'
;
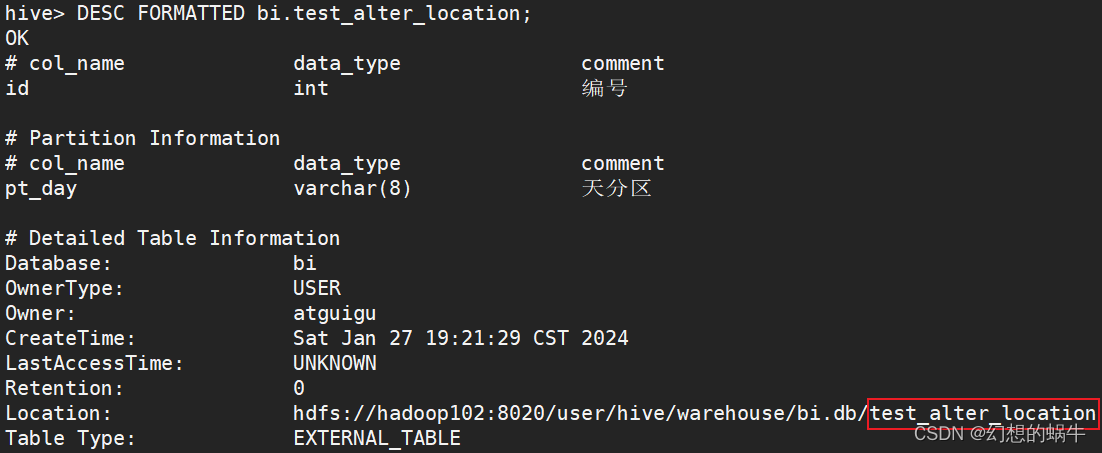
5. 查看Location
DESC FORMATTED bi.test_alter_location;
三、方案2 直接修改Location并恢复数据
1.建表,指定错误的Location,并插入数据
建表:
CREATE EXTERNAL TABLE IF NOT EXISTS bi.test_alter_location_right
(
id INT COMMENT '编号'
) COMMENT '修改Location测试'
PARTITIONED BY (pt_day VARCHAR(8) COMMENT '天分区')
LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_wrong'
;
插入数据:
INSERT OVERWRITE TABLE bi.test_alter_location_right
PARTITION (pt_day = '20240127')
VALUES
(1)
,(2)
;
查看数据:
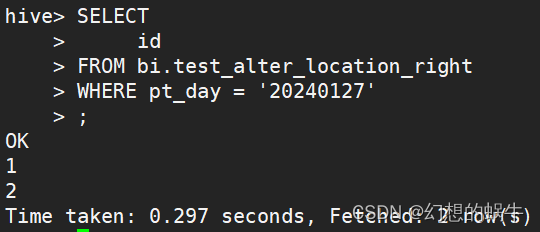
SELECT
id
FROM bi.test_alter_location_right
WHERE pt_day = '20240127'
;
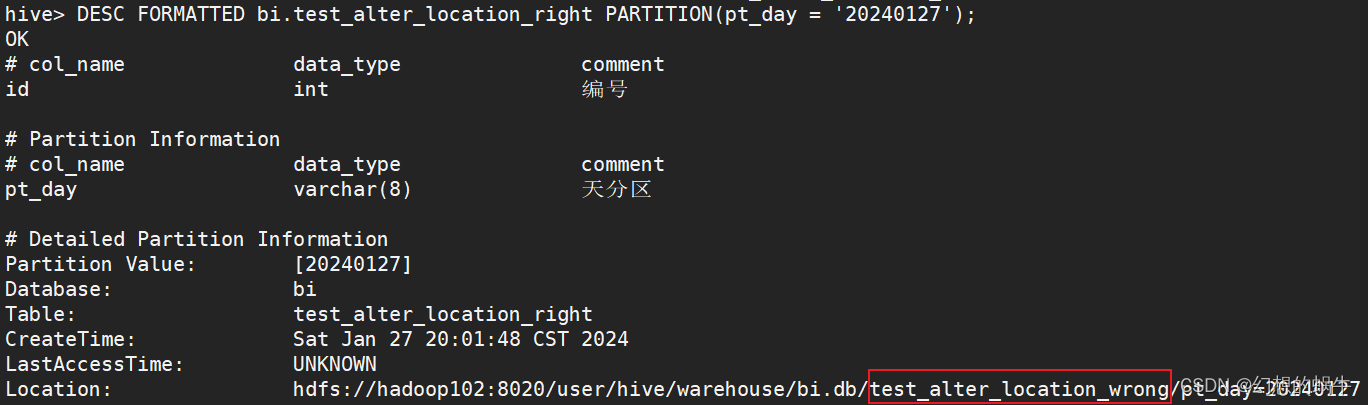
查看Location
DESC FORMATTED bi.test_alter_location_right PARTITION(pt_day = '20240127');
 从后台查看文件情况
从后台查看文件情况
hdfs dfs -ls hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_wrong/pt_day=20240127

2.修改表的Location
修改语句:
ALTER TABLE bi.test_alter_location_right SET LOCATION "hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_right";
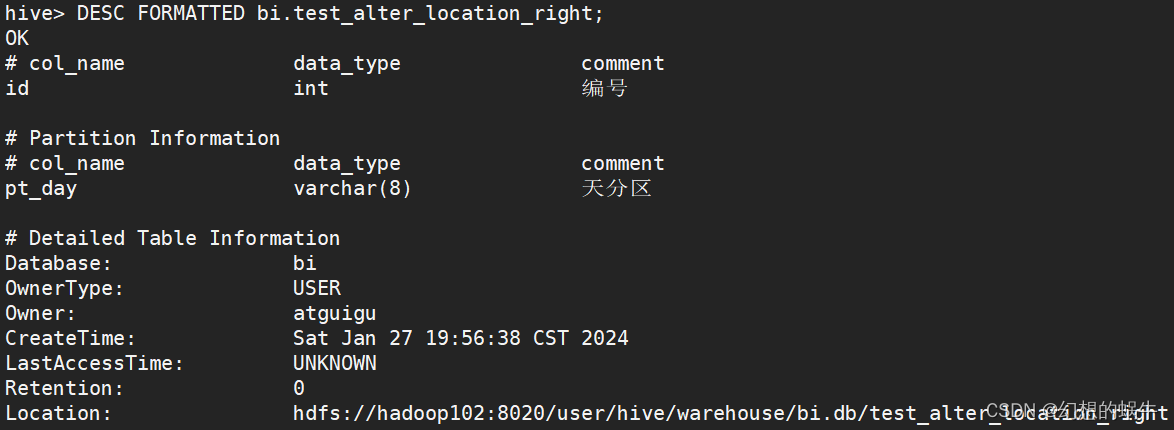
查看表Location:
DESC FORMATTED bi.test_alter_location_right;
3.对于新分区,插入数据时,新分区的路径会按照表的Location生成
新分区插入数据:
INSERT OVERWRITE TABLE bi.test_alter_location_right
PARTITION (pt_day = '20240128')
VALUES
(3)
,(4)
;
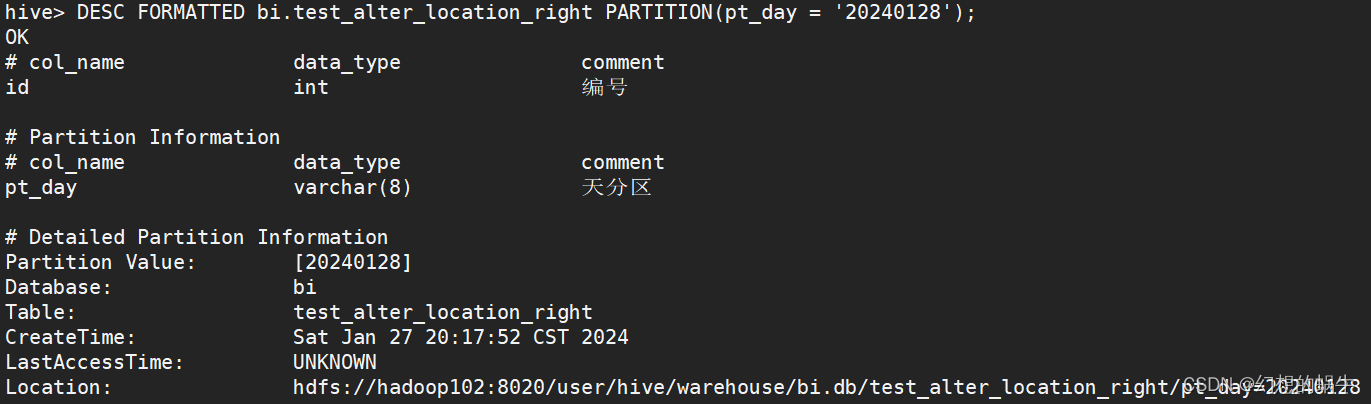
查看新分区的Location
DESC FORMATTED bi.test_alter_location_right PARTITION(pt_day = '20240128');
4.修复历史分区数据,通过hdfs命令修复
修复命令:
hdfs dfs -mv hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_wrong/pt_day=20240127 hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_right/pt_day=20240127
查看新老路径下数据情况:
hdfs dfs -ls hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_wrong/pt_day=20240127
hdfs dfs -ls hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_right/pt_day=20240127

从执行结果可以看出,数据已从老路径移动到新路径下了
通过表查询数据:
SELECT
id
FROM bi.test_alter_location_right
WHERE pt_day = '20240127'
;
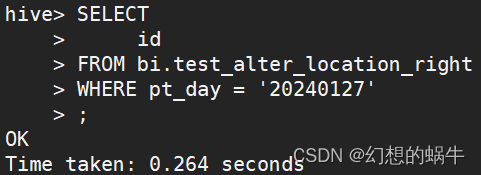
可以看到,并没有查询出数据。这是因为分区的Location未修改的缘故。
查询分区的Location:
DESC FORMATTED bi.test_alter_location_right PARTITION(pt_day = '20240127');
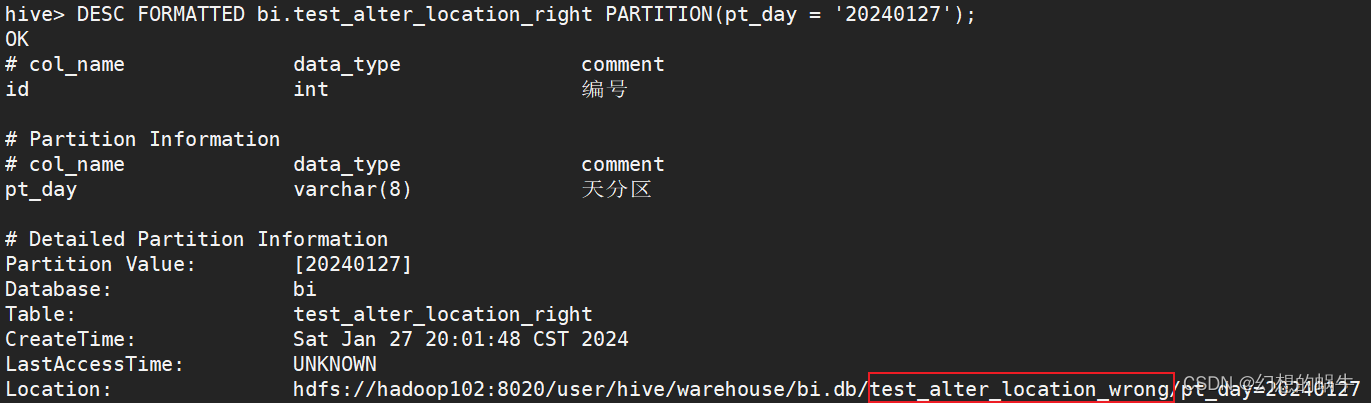
修改分区的Location:
ALTER TABLE bi.test_alter_location_right PARTITION(pt_day = '20240127') SET LOCATION "hdfs://hadoop102:8020/user/hive/warehouse/bi.db/test_alter_location_right/pt_day=20240127";
再次查询数据:
SELECT
id
FROM bi.test_alter_location_right
WHERE pt_day = '20240127'
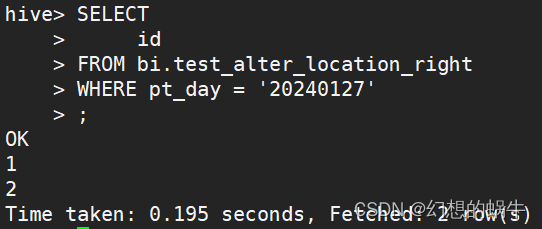
可以看出,修改分区的Location后,可以正常查询数据了,数据修复完成。