深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.com/DeepRLChinese/DeepRL-Chinese
B站视频:【王树森】深度强化学习(DRL)
豆瓣: 深度强化学习
文章目录
- 深度强化学习(DRL)
- Policy-based RL(策略学习)
- 视频
- 策略网络policy network
- 策略梯度policy gradient
- Update policy network using policy gradient
- 书
- 策略网络
- 策略学习的目标函数
- 策略梯度定理的证明
- REINFORCE
- 后记
Policy-based RL(策略学习)
视频
复习策略函数的定义:策略函数是一个概率密度函数,把state作为输入,输出一个所有action的概率分布。

策略网络policy network
用神经网络来近似策略函数 π \pi π
状态价值函数回顾
状态价值函数是对动作价值函数求期望(关于action积分(或累加和),将action消掉)。

近似状态价值函数:用策略网络近似策略函数,然后将其带入价值函数中,如下图所示。主要的区别是里面多了一个 θ \theta θ变量,这是神经网络的参数。

改进模型参数 θ \theta θ使得V函数变大,目标函数 J ( θ ) J(\theta) J(θ)是对V函数求期望,J函数是对策略网络的评价,策略网络越好,J就越大。
policy based learning的目标就是改进模型参数 θ \theta θ使得 J ( θ ) J(\theta) J(θ)越大越好。

策略梯度policy gradient
推导策略梯度

下面用了log函数求导的性质,从第一个蓝色方框推到到第二个蓝色方框。

第二个等式关于 π \pi π求和,就是对随机变量A求期望。

经过推导,得到策略梯度下面两种形式

对于离散动作求策略梯度:用form1

对于连续动作求策略梯度:用form2,这里用到了蒙特卡洛近似

Update policy network using policy gradient
策略梯度算法:每一轮迭代都做如下的6步

对于第三步 q t ≈ Q π ( s t , a t ) q_t\approx Q_\pi(\color{green}{s_t},\color{red}{a_t}) qt≈Qπ(st,at)中的动作价值函数 Q π Q_{\pi} Qπ不知道是什么,有两个办法近似计算 q t q_t qt
第一个算法:REINFORCE算法
如下图所示:但是它需要玩完一轮游戏,观测到所有的奖励,然后才能更新策略网络。

第二个方法:用神经网络代替 Q π Q_{\pi} Qπ

总结一下:如果策略函数已知,那么agent的动作就可以采样这个策略函数,进而被控制。但是策略函数不知道,所以用策略网络来近似这个策略函数。
具体是用策略梯度算法来学习策略网络。

书
策略学习(policy-based reinforcement learning) 以及策略梯度 (policy gradient)。策略学习的意思是通过求解一个优化问题,学出最优策略函数或它的近似函数(比如策略网络)。
策略网络
本章假设动作空间是离散的,比如 A = { A=\{ A={左,右,上}。策略函数 π \pi π 是个条件概率质量函数:
π ( a ∣ s ) ≜ P ( A = a ∣ S = s ) . \pi\big(a\:\big|\:s\big)\:\triangleq\:\mathbb{P}\big(A=a\:\big|\:S=s\big). π(a s)≜P(A=a S=s).
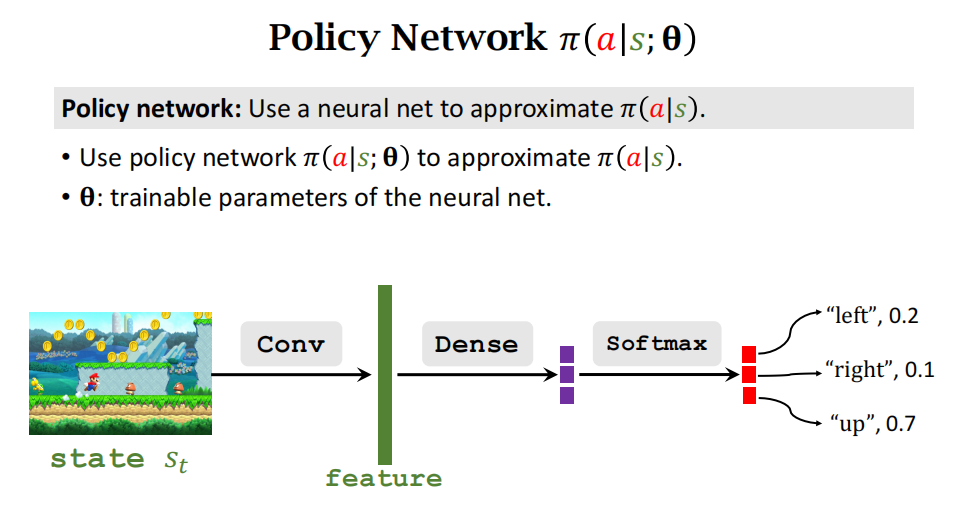
策略函数 π 的输入是状态 s s s 和动作 a a a, 输出是一个 0 到 1 之间的概率值。 举个例子,把超级玛丽游戏当前屏幕上的画面作为 s s s, 策略函数会输出每个动作的概率值:
π ( 左 ∣ s ) = 0.5 , π ( 右 ∣ s ) = 0.2 , π ( 上 ∣ s ) = 0.3. \begin{aligned}&\pi(\text{左}|s)~=~0.5,\\&\pi(\text{右}|s)~=~0.2,\\&\pi(\text{上}|s)~=~0.3.\end{aligned} π(左∣s) = 0.5,π(右∣s) = 0.2,π(上∣s) = 0.3.
如果我们有这样一个策略函数,我们就可以拿它控制智能体。每当观测到一个状态 s s s,就用策略函数计算出每个动作的概率值,然后做随机抽样,得到一个动作 a a a,让智能体执行 a a a。
怎么样才能得到这样一个策略函数呢?当前最有效的方法是用神经网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s)。神经网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 被称为策略网络。 θ \theta θ 表示神经网络的参数;一开始随机初始化 θ \theta θ,随后利用收集的状态、动作、奖励去更新 θ \theta θ。
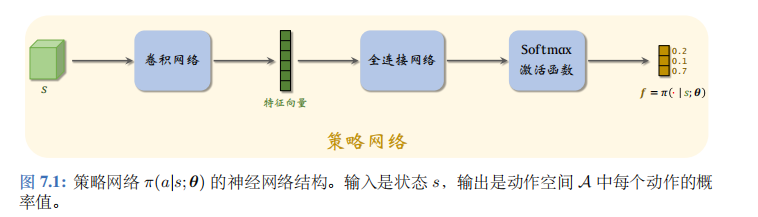
策略网络的结构如图 7.1 所示。策略网络的输入是状态 s s s。在 Atari 游戏、围棋等应用中,状态是张量 (比如图片),那么应该如图 7.1 所示用卷积网络处理输入。在机器人控制等应用中,状态 s s s 是向量,它的元素是多个传感器的数值,那么应该把卷积网络换成全连接网络。策略网络输出层的激活函数是 softmax, 因此输出的向量 (记作 f f f) 所有元素都是正数,而且相加等于1。动作空间 A A A 的大小是多少,向量 f f f 的维度就是多少。在超级玛丽的例子中, A = { A=\{ A={左,右,上},那么 f f f 就是 3 维的向量,比如 f = [ 0.2 , 0.1 , 0.7 ] f=[0.2,0.1,0.7] f=[0.2,0.1,0.7]。 f f f 描述了动作空间 A A A 上的离散概率分布, f f f 每个元素对应一个动作:
f 1 = π ( 左 ∣ s ) = 0.2 , f 2 = π ( 右 ∣ s ) = 0.1 , f 3 = π ( 上 ∣ s ) = 0.7. \begin{aligned}f_1&=\:\pi(\text{左}\:|\:s)\:=\:0.2,\\[1ex]f_2&=\:\pi(\text{右}\:|\:s)\:=\:0.1,\\[1ex]f_3&=\:\pi(\:\text{上}\:|\:s)\:=\:0.7.\end{aligned} f1f2f3=π(左∣s)=0.2,=π(右∣s)=0.1,=π(上∣s)=0.7.
策略学习的目标函数
为了推导策略学习的目标函数,我们需要先复习回报和价值函数。回报 U t U_t Ut 是从 t t t 时刻开始的所有奖励之和。 U t U_t Ut 依赖于 t t t 时刻开始的所有状态和动作:
S t , A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ S_{t},A_{t},\:S_{t+1},A_{t+1},\:S_{t+2},A_{t+2},\:\cdots St,At,St+1,At+1,St+2,At+2,⋯
在 t t t 时刻, U t U_t Ut 是随机变量,它的不确定性来自于未来未知的状态和动作。动作价值函数的定义是:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_{\pi}(s_{t},a_{t})\:=\:\mathbb{E}\bigg[U_{t}\bigg|S_{t}=s_{t},A_{t}=a_{t}\bigg]. Qπ(st,at)=E[Ut St=st,At=at].
条件期望把 t t t 时刻状态 s t s_t st 和动作 a t a_t at 看做已知观测值,把 t + 1 t+1 t+1 时刻后的状态和动作看做未知变量,并消除这些变量。状态价值函数的定义是
V
π
(
s
t
)
=
E
A
t
∼
π
(
⋅
∣
s
t
;
θ
)
[
Q
π
(
s
t
,
A
t
)
]
.
V_{\pi}(s_{t})\:=\:\mathbb{E}_{A_{t}\sim\pi(\cdot|s_{t};\theta)}\Big[Q_{\pi}(s_{t},A_{t})\Big].
Vπ(st)=EAt∼π(⋅∣st;θ)[Qπ(st,At)].
状态价值既依赖于当前状态
s
t
s_t
st, 也依赖于策略网络
π
\pi
π 的参数
θ
\theta
θ。
-
当前状态 s t s_t st 越好,则 V π ( s t ) V_\pi(s_t) Vπ(st) 越大,即回报 U t U_t Ut 的期望越大。例如,在超级玛丽游戏中,如果玛丽奥已经接近终点(也就是说当前状态 s t s_t st很好),那么回报的期望就会很大。
-
策略 π \pi π 越好 (即参数 θ \theta θ 越好),那么 V π ( s t ) V_\pi(s_t) Vπ(st) 也会越大。例如,从同一起点出发打游戏,高手 (好的策略) 的期望回报远高于初学者 (差的策略)。
如果一个策略很好,那么状态价值 V π ( S ) V_{\pi}(S) Vπ(S) 的均值应当很大。因此我们定义目标函数:
J ( θ ) = E S [ V π ( S ) ] . J(\theta)=\mathbb{E}_{S}\Big[V_{\pi}(S)\Big]. J(θ)=ES[Vπ(S)].
这个目标函数排除掉了状态 S S S 的因素,只依赖于策略网络 π \pi π 的参数 θ \theta θ; 策略越好,则 J ( θ ) J(\theta) J(θ) 越大。所以策略学习可以描述为这样一个优化问题:
max θ J ( θ ) . \max_{\theta}J(\boldsymbol{\theta}). θmaxJ(θ).
我们希望通过对策略网络参数 θ \theta θ的更新,使得目标函数 J ( θ ) J(\theta) J(θ) 越来越大,也就意味着策略网络越来越强。想要求解最大化问题,显然可以用梯度上升更新 θ \theta θ,使得 J ( θ ) J(\theta) J(θ) 增大。设当前策略网络的参数为 θ n o w \theta_\mathrm{now} θnow,做梯度上升更新参数,得到新的参数 θ n e w \theta_\mathrm{new} θnew:
θ n e w ← θ n o w + β ⋅ ∇ θ J ( θ n o w ) . \theta_\mathrm{new~}\leftarrow\theta_\mathrm{now}+\beta\cdot\nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta_\mathrm{now}}). θnew ←θnow+β⋅∇θJ(θnow).
此处的 β \beta β 是学习率,需要手动调整。上面的公式就是训练策略网络的基本思路,其中的梯度
∇
θ
J
(
θ
n
o
w
)
≜
∂
J
(
θ
)
∂
θ
∣
θ
=
θ
n
o
w
\nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta}_{\mathrm{now}})\triangleq\left.\frac{\partial J(\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\right|_{\theta=\theta_{\mathrm{now}}}
∇θJ(θnow)≜∂θ∂J(θ)
θ=θnow
被称作策略梯度。策略梯度可以写成下面定理中的期望形式。之后的算法推导都要基于这个定理,并对其中的期望做近似。

∂ J ( θ ) ∂ θ = E S [ E A ∼ π ( ⋅ θ ) [ ∂ ln π ( A ∣ S ; θ ) ∂ θ ⋅ Q π ( S , A ) ] ] . \frac{\partial J(\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}=\mathbb{E}_{S}\bigg[\mathbb{E}_{A\sim\pi(\cdot\boldsymbol{\theta})}\bigg[\frac{\partial\ln\pi(A|S;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}(S,A)\bigg]\bigg]. ∂θ∂J(θ)=ES[EA∼π(⋅θ)[∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)]].
注 上面的策略梯度定理是不严谨的表述,尽管大多数论文和书籍使用这种表述。严格地讲,这个定理只有在“状态 S S S 服从马尔科夫链的稳态分布 d ( ⋅ ) d(\cdot) d(⋅) ”这个假设下才成立。定理中的等号其实是不对的,期望前面应该有一项系数 1 + γ + ⋯ + γ n − 1 = 1 − γ n 1 − γ 1+\gamma+\cdots+\gamma^{n-1}=\frac{1-\gamma^n}{1-\gamma} 1+γ+⋯+γn−1=1−γ1−γn,其中 γ \gamma γ 是折扣率, n n n 是一局游戏的长度。严格地讲,策略梯度定理应该是:
∂ J ( θ ) ∂ θ = 1 − γ n 1 − γ ⋅ E S ∼ d ( ⋅ ) [ E A ∼ π ( ⋅ ∣ S ; θ ) [ ∂ ln π ( A ∣ S ; θ ) ∂ θ ⋅ Q π ( S , A ) ] ] . \frac{\partial J(\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}=\frac{1-\gamma^{n}}{1-\gamma}\cdot\mathbb{E}_{S\sim d(\cdot)}\bigg[\mathbb{E}_{A\sim\pi(\cdot|S;\boldsymbol{\theta})}\bigg[\frac{\partial\ln\pi(A|S;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}(S,A)\bigg]\bigg]. ∂θ∂J(θ)=1−γ1−γn⋅ES∼d(⋅)[EA∼π(⋅∣S;θ)[∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)]].
1 − γ n 1 − γ \frac{1-\gamma^n}{1-\gamma} 1−γ1−γn 会被学习率 β \beta β 吸收。
策略梯度定理的证明
把策略网络 π ( a ∣ s ; θ ) \pi(a\mid s;\boldsymbol{\theta}) π(a∣s;θ) 看做动作的概率质量函数 (或概率密度函数)。状态价值函数 V π ( s ) V_{\pi}(s) Vπ(s) 可以写成:
V π ( s ) = E A ∼ π ( ⋅ ∣ s ; θ ) [ Q π ( s , A ) ] = ∑ a ∈ A π ( a ∣ s ; θ ) ⋅ Q π ( s , a ) . \begin{array}{rcl}V_\pi(s)&=&\mathbb{E}_{A\sim\pi(\cdot|s;\boldsymbol{\theta})}\Big[Q_\pi(s,A)\Big]\\&=&\sum_{a\in\mathcal{A}}\pi(a\:|\:s;\:\boldsymbol{\theta})\cdot Q_\pi(s,a).\end{array} Vπ(s)==EA∼π(⋅∣s;θ)[Qπ(s,A)]∑a∈Aπ(a∣s;θ)⋅Qπ(s,a).
状态价值 V π ( s ) V_{\pi}(s) Vπ(s) 关于 θ \theta θ的梯度可以写作:
∂ V π ( s ) ∂ θ = ∂ ∂ θ ∑ a ∈ A π ( a ∣ s ; θ ) ⋅ Q π ( s , a ) = ∑ a ∈ A ∂ π ( a ∣ s ; θ ) ⋅ Q π ( s , a ) ∂ θ . ( 7.1 ) \begin{array}{rcl}\frac{\partial V_\pi(s)}{\partial\boldsymbol{\theta}}&=&\frac{\partial}{\partial\boldsymbol{\theta}}{\sum_{a\in\mathcal{A}}\pi(a\mid s;\:\boldsymbol{\theta})\cdot Q_\pi(s,a)}\\&=&{\sum_{a\in\mathcal{A}}\frac{\partial\pi(a|s;\:\boldsymbol{\theta})\cdot Q_\pi(s,a)}{\partial\boldsymbol{\theta}}.}\end{array} \quad{(7.1)} ∂θ∂Vπ(s)==∂θ∂∑a∈Aπ(a∣s;θ)⋅Qπ(s,a)∑a∈A∂θ∂π(a∣s;θ)⋅Qπ(s,a).(7.1)
上面第二个等式把求导放入连加里面;等式成立的原因是求导的对象
θ
\theta
θ 与连加的对象
u
\color{blue}{u}
u 不同。回忆一下链式法则:设
z
=
f
(
x
)
⋅
g
(
x
)
z=f(x)\cdot g(x)
z=f(x)⋅g(x), 那么
∂
z
∂
x
=
∂
f
(
x
)
∂
x
⋅
g
(
x
)
+
f
(
x
)
⋅
∂
g
(
x
)
∂
x
.
\frac{\partial\:z}{\partial\:x}\:=\:\frac{\partial\:f(x)}{\partial\:x}\:\cdot\:g(x)\:+\:f(x)\:\cdot\:\frac{\partial\:g(x)}{\partial\:x}.
∂x∂z=∂x∂f(x)⋅g(x)+f(x)⋅∂x∂g(x).
应用链式法则,公式 (7.1) 中的梯度可以写作:
∂ V π ( s ) ∂ θ = ∑ a ∈ A ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) + ∑ a ∈ A π ( a ∣ s ; θ ) ⋅ ∂ Q π ( s , a ) ∂ θ = ∑ a ∈ A ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) + E A ∼ π ( ⋅ ∣ s ; θ ) ⏟ 设为 x [ ∂ Q π ( s , A ) ∂ θ ] . \begin{aligned} \frac{\partial V_{\pi}(s)}{\partial\theta}& =\sum_{a\in\mathcal{A}}\frac{\partial\pi(a|s;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}\big(s,a\big)+\sum_{a\in\mathcal{A}}\pi\big(a\big|s;\boldsymbol{\theta}\big)\cdot\frac{\partial Q_{\pi}(s,a)}{\partial\boldsymbol{\theta}} \\ &=\sum_{a\in\mathcal{A}}\frac{\partial\pi(a|s;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}\big(s,a\big)+\underbrace{\mathbb{E}_{A\sim\pi(\cdot|s;\boldsymbol{\theta}\big)}}_{\text{设为 }x}\bigg[\frac{\partial Q_{\pi}(s,A)}{\partial\boldsymbol{\theta}}\bigg]. \end{aligned} ∂θ∂Vπ(s)=a∈A∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)+a∈A∑π(a s;θ)⋅∂θ∂Qπ(s,a)=a∈A∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)+设为 x EA∼π(⋅∣s;θ)[∂θ∂Qπ(s,A)].
上面公式最右边一项 x x x 的分析非常复杂,此处不具体分析了。由上面的公式可得:
∂
V
π
(
s
)
∂
θ
=
∑
A
∈
A
∂
π
(
A
∣
S
;
θ
)
∂
θ
⋅
Q
π
(
S
,
A
)
+
x
=
∑
A
∈
A
π
(
A
∣
S
;
θ
)
⋅
1
π
(
A
∣
S
;
θ
)
⋅
∂
π
(
A
∣
S
;
θ
)
∂
θ
⏟
等于
∂
ln
π
(
A
∣
S
;
θ
)
/
∂
θ
⋅
Q
π
(
S
,
A
)
+
x
.
\begin{aligned} \frac{\partial V_{\pi}(s)}{\partial\theta}& =\:\sum_{A\in\mathcal{A}}\frac{\partial\:\pi(A|S;\boldsymbol{\theta})}{\partial\:\boldsymbol{\theta}}\cdot\:Q_{\pi}\big(S,A\big)\:+\:x \\ &=\sum_{A\in\mathcal{A}}\color{red}{\pi(A\mid S;\theta)}\cdot\underbrace{\frac1{\pi(A\mid S;\theta)}\cdot\color{black}\frac{\partial\pi(A\mid S;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}}_{\color{blue}\text{等于 }\partial\ln\pi(A\mid S;\boldsymbol{\theta})/\partial\boldsymbol{\theta}}\color{black}\cdot Q_{\pi}(S,A)\:+\:x. \end{aligned}
∂θ∂Vπ(s)=A∈A∑∂θ∂π(A∣S;θ)⋅Qπ(S,A)+x=A∈A∑π(A∣S;θ)⋅等于 ∂lnπ(A∣S;θ)/∂θ
π(A∣S;θ)1⋅∂θ∂π(A∣S;θ)⋅Qπ(S,A)+x.
上面第二个等式成立的原因是添加的两个红色项相乘等于一。公式中用下花括号标出的项等于
∂
ln
π
(
A
∣
S
;
θ
)
∂
θ
\frac{\partial\ln\pi(A|S;\theta)}{\partial\theta}
∂θ∂lnπ(A∣S;θ)。由此可得
∂
V
π
(
s
)
∂
θ
=
∑
A
∈
A
π
(
A
∣
S
;
θ
)
⋅
∂
ln
π
(
A
∣
S
;
θ
)
∂
θ
⋅
Q
π
(
S
,
A
)
+
x
=
E
A
∼
π
(
⋅
∣
S
;
θ
)
[
∂
ln
π
(
A
∣
S
;
θ
)
∂
θ
⋅
Q
π
(
S
,
A
)
]
+
x
.
(
7.2
)
\begin{aligned}\frac{\partial V_{\pi}(s)}{\partial\boldsymbol{\theta}}=\sum_{A\in\mathcal{A}}\color{red}{\pi(A\mid S;\theta)}\color{black}\cdot\frac{\partial\ln\pi(A\mid S;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}\big(S,A\big)+x\\=\mathbb{E}_{\color{red}{A\sim\pi(\cdot\mid S;\theta)}}\bigg[\frac{\partial\ln\pi(A\mid S;\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}\cdot Q_{\pi}(S,A)\bigg]+x.\quad{(7.2)}\end{aligned}
∂θ∂Vπ(s)=A∈A∑π(A∣S;θ)⋅∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)+x=EA∼π(⋅∣S;θ)[∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)]+x.(7.2)
公式中红色标出的 π ( A ∣ S ; θ ) \pi(A|S;\boldsymbol{\theta}) π(A∣S;θ) 被看做概率质量函数,因此连加可以写成期望的形式。由目标函数的定义 J ( θ ) = E S [ V π ( S ) ] J(\boldsymbol{\theta})=\mathbb{E}_S[V_\pi(S)] J(θ)=ES[Vπ(S)] 可得
∂
J
(
θ
)
∂
θ
=
E
S
[
∂
V
π
(
S
)
∂
θ
]
=
E
S
[
E
A
∼
π
(
⋅
∣
S
;
θ
)
[
∂
ln
π
(
A
∣
S
;
θ
)
∂
θ
⋅
Q
π
(
S
,
A
)
]
]
+
E
S
[
x
]
.
\begin{aligned} &\frac{\partial J(\boldsymbol{\theta})}{\partial\boldsymbol{\theta}}&& =\:\mathbb{E}_{S}\bigg[\frac{\partial\:V_{\pi}(S)}{\partial\:\theta}\bigg] \\ &&&=\:\mathbb{E}_{S}\bigg[\:\mathbb{E}_{A\sim\pi(\cdot\mid S;\theta)}\bigg[\:\frac{\partial\:\ln\pi(A\mid S;\:\boldsymbol{\theta})}{\partial\:\boldsymbol{\theta}}\cdot\:Q_{\pi}\big(S,A\big)\:\bigg]\:\bigg]\:+\:\mathbb{E}_{S}\big[x\big]. \end{aligned}
∂θ∂J(θ)=ES[∂θ∂Vπ(S)]=ES[EA∼π(⋅∣S;θ)[∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)]]+ES[x].
不严谨的证明通常忽略掉
x
x
x, 于是得到定理 7.1。
近似策略梯度
先复习一下前两小节的内容。策略学习可以表述为这样一个优化问题:
max
θ
{
J
(
θ
)
≜
E
S
[
V
π
(
S
)
]
}
.
\max_{\boldsymbol{\theta}}\left\{J(\boldsymbol{\theta})\triangleq\mathbb{E}_{S}\Big[V_{\pi}(S)\Big]\right\}.
θmax{J(θ)≜ES[Vπ(S)]}.
求解这个最大化问题最简单的算法就是梯度上升:
θ
←
θ
+
β
⋅
∇
θ
J
(
θ
)
.
\theta\:\leftarrow\:\theta+\beta\cdot\nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta})\:.
θ←θ+β⋅∇θJ(θ).
其中的 ∇ θ J ( θ ) \nabla_{\theta}J(\theta) ∇θJ(θ) 是策略梯度。策略梯度定理证明:
∇ θ J ( θ ) = E S [ E A ∼ π ( ⋅ ∣ S ; θ ) [ Q π ( S , A ) ⋅ ∇ θ ln π ( A ∣ S ; θ ) ] ] . \nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta})\:=\:\mathbb{E}_{S}\Big[\:\mathbb{E}_{A\sim\pi(\cdot|S;\boldsymbol{\theta})}\Big[\:Q_{\pi}(S,A)\:\cdot\:\nabla_{\boldsymbol{\theta}}\ln\pi(\:A\:|\:S;\:\boldsymbol{\theta})\:\Big]\:\Big]. ∇θJ(θ)=ES[EA∼π(⋅∣S;θ)[Qπ(S,A)⋅∇θlnπ(A∣S;θ)]].
解析求出这个期望是不可能的,因为我们并不知道状态 S S S 概率密度函数;即使我们知道 S S S的概率密度函数,能够通过连加或者定积分求出期望,我们也不愿意这样做,因为连加或者定积分的计算量非常大。
回忆一下,第 2 章介绍了期望的蒙特卡洛近似方法,可以将这种方法用于近似策略梯度。每次从环境中观测到一个状态 s s s, 它相当于随机变量 S S S 的观测值。然后再根据当前的策略网络 (策略网络的参数必须是最新的) 随机抽样得出一个动作:
a ∼ π ( ⋅ ∣ s ; θ ) . a\:\sim\:\pi(\:\cdot\:|\:s;\:\boldsymbol{\theta}). a∼π(⋅∣s;θ).
计算随机梯度:
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \boldsymbol{g}(s,a;\boldsymbol{\theta})\triangleq Q_{\pi}(s,a)\cdot\nabla_{\boldsymbol{\theta}}\ln\pi(a|s;\boldsymbol{\theta}). g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a∣s;θ).
很显然, g ( s , a ; θ ) g(s,a;\boldsymbol{\theta}) g(s,a;θ) 是策略梯度 ∇ θ J ( θ ) \nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta}) ∇θJ(θ) 的无偏估计:
∇ θ J ( θ ) = E S [ E A ∼ π ( ⋅ ∣ S ; θ ) [ g ( S , A ; θ ) ] ] . \nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta})\:=\:\mathbb{E}_{S}\Big[\:\mathbb{E}_{A\sim\pi(\cdot|S;\boldsymbol{\theta})}\Big[\:\boldsymbol{g}(S,A;\boldsymbol{\theta})\:\Big]\:\Big]. ∇θJ(θ)=ES[EA∼π(⋅∣S;θ)[g(S,A;θ)]].
于是我们得到下面的结论:
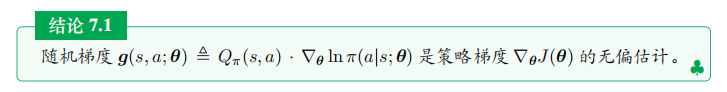
对无偏估计的解释:ChatGPT
在统计学和概率论中,一个估计量如果在多次独立重复采样下的期望值等于被估计的参数的真实值,那么这个估计量被称为无偏估计。换句话说,无偏估计的期望值与被估计参数的真实值相等,不存在系统性的估计偏差。
形式上,对于估计量 ( θ ^ \hat{\theta} θ^ ) 和真实参数 ( θ \theta θ ),如果满足:
E [ θ ^ ] = θ \mathbb{E}[\hat{\theta}] = \theta E[θ^]=θ
其中,( E [ ⋅ ] \mathbb{E}[\cdot] E[⋅]) 表示期望值,那么估计量 ( θ ^ \hat{\theta} θ^) 就是无偏估计。
无偏性是一个重要的性质,因为它意味着在长期的统计学意义上,估计量不会系统性地高估或低估真实参数值。然而,无偏性并不意味着在单次估计中估计值一定会非常接近真实值。方差和均方误差也是评价估计量性能的重要指标。
在实际应用中,研究人员通常希望使用无偏估计,因为它们在统计学理论中更容易处理。但并非所有估计都能找到无偏的形式,有时可能需要权衡无偏性与其他性质(例如方差)来选择合适的估计方法。
应用上述结论,我们可以做随机梯度上升来更新 θ \theta θ, 使得目标函数 J ( θ ) J(\theta) J(θ) 逐渐增长:
θ ← θ + β ⋅ g ( s , a ; θ ) . \theta\:\leftarrow\:\theta\:+\:\beta\cdot\boldsymbol{g}(s,a;\boldsymbol{\theta}). θ←θ+β⋅g(s,a;θ).
此处的 β \beta β 是学习率,需要手动调整。但是这种方法仍然不可行,我们计算不出 g ( s , a ; θ ) g(s,a;\theta) g(s,a;θ) , 原因在于我们不知道动作价值函数 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。在后面两节中,我们用两种方法对 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 做近似:一种方法是 REINFORCE, 用实际观测的回报 u u u 近似 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a); 另一种方法是actor-critic, 用神经网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 近似 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 。
REINFORCE
策略梯度方法用 ∇ θ J ( θ ) \nabla_{\theta}J(\theta) ∇θJ(θ) 的近似来更新策略网络参数 θ \theta θ, 从而增大目标函数。上一节中,我们推导出策略梯度 ∇ θ J ( θ ) \nabla_{\theta}J(\theta) ∇θJ(θ) 的无偏估计,即下面的随机梯度:
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \begin{array}{rcl}\boldsymbol{g}(s,a;\boldsymbol{\theta})&\triangleq&Q_{\pi}\big(s,a\big)\cdot\nabla_{\boldsymbol{\theta}}\ln\pi\big(a\big|s;\boldsymbol{\theta}\big).\end{array} g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a s;θ).
但是其中的动作价值函数 Q π Q_{\pi} Qπ是未知的、导致无法直接计算 g ( s , a ; θ ) g(s,a;\theta) g(s,a;θ)。REINFORCE 进一步对 Q π Q_{\pi} Qπ做蒙特卡洛近似,把它替换成回报 u u u。
REINFORCE 的简化推导
设一局游戏有 n n n 步,一局中的奖励记作 R 1 , ⋯ , R n R_1,\cdots,R_n R1,⋯,Rn。回忆一下, t t t 时刻的折扣回报定义为:
U t = ∑ k = t n γ k − t ⋅ R k . U_{t}\:=\:\sum_{k=t}^{n}\gamma^{k-t}\cdot R_{k}. Ut=k=t∑nγk−t⋅Rk.
而动作价值定义为 U t U_t Ut 的条件期望:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_{\pi}(s_{t},a_{t})\:=\:\mathbb{E}\Big[U_{t}\Big|\:S_{t}=s_{t},A_{t}=a_{t}\Big]. Qπ(st,at)=E[Ut St=st,At=at].
我们可以用蒙特卡洛近似上面的条件期望。从时刻 t t t 开始,智能体完成一局游戏,观测到全部奖励 r t , ⋯ , r n r_t,\cdots,r_n rt,⋯,rn,然后可以计算出 u t = ∑ k = t n γ k − t ⋅ r k u_t=\sum_{k=t}^n\gamma^{k-t}\cdot r_k ut=∑k=tnγk−t⋅rk。因为 u t u_t ut 是随机变量 U t U_t Ut 的观测值,所以 u t u_t ut 是上面公式中期望的蒙特卡洛近似。在实践中,可以用 u t u_t ut 代替 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at), 那么随机梯度 g ( s t , a t ; θ ) g(s_t,a_t;\theta) g(st,at;θ) 可以近似成
g ~ ( s t , a t ; θ ) = u t ⋅ ∇ θ ln π ( a t ∣ s t ; θ ) . \tilde{\boldsymbol{g}}(s_t,a_t;\boldsymbol{\theta})=u_t\cdot\nabla_{\boldsymbol{\theta}}\ln\pi(a_t|s_t;\boldsymbol{\theta}). g~(st,at;θ)=ut⋅∇θlnπ(at∣st;θ).
g
~
\tilde{g}
g~ 是
g
g
g 的无偏估计,所以也是策略梯度
∇
θ
J
(
θ
)
\nabla_{\theta}J(\theta)
∇θJ(θ) 的无偏估计;
g
~
\tilde{g}
g~ 也是一种随机梯度。
我们可以用反向传播计算出
ln
π
\ln\pi
lnπ 关于
θ
\theta
θ的梯度,而且可以实际观测到
u
t
u_t
ut,于是我们可以实际计算出随机梯度
g
~
\tilde{g}
g~ 的值。有了随机梯度的值,我们可以做随机梯度上升更新策略网络参数
θ
:
\theta:
θ:
θ ← θ + β ⋅ g ~ ( s t , a t ; θ ) . \theta\:\leftarrow\:\theta\:+\:\beta\cdot\tilde{\boldsymbol{g}}(s_{t},a_{t};\boldsymbol{\theta}). θ←θ+β⋅g~(st,at;θ).
根据上述推导,我们得到了训练策略网络的算法,即 REINFORCE。
训练流程
当前策略网络的参数是 θ n o w \theta_\mathrm{now} θnow。REINFORCE 执行下面的步骤对策略网络的参数做一次更新:
- 用策略网络 θ n o w \theta_\mathrm{now} θnow 控制智能体从头开始玩一局游戏,得到一条轨迹 (trajectory):
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s n , a n , r n . s_{1},a_{1},r_{1},\quad s_{2},a_{2},r_{2},\quad\cdots,\quad s_{n},a_{n},r_{n}. s1,a1,r1,s2,a2,r2,⋯,sn,an,rn.
- 计算所有的回报:
u t = ∑ k = t n γ k − t ⋅ r k , ∀ t = 1 , ⋯ , n . u_{t}\:=\:\sum_{k=t}^{n}\gamma^{k-t}\cdot r_{k},\quad\forall\:t=1,\cdots,n. ut=k=t∑nγk−t⋅rk,∀t=1,⋯,n.
3.用 { ( s t , a t ) } t = 1 n \{(s_t,a_t)\}_{t=1}^n {(st,at)}t=1n 作为数据,做反向传播计算:
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
n
o
w
)
,
∀
t
=
1
,
⋯
,
n
.
\nabla_{\boldsymbol{\theta}}\ln\pi(a_{t}\:|\:s_{t};\:\boldsymbol{\theta}_{\mathrm{now}}),\quad\forall\:t=1,\cdots,n.
∇θlnπ(at∣st;θnow),∀t=1,⋯,n.
4. 做随机梯度上升更新策略网络参数:
θ n e w ← θ n o w + β ⋅ ∑ t = 1 n γ t − 1 ⋅ u t ⋅ ∇ θ ln π ( a t ∣ s t ; θ n o w ) ⏟ 即随机梯度 g ~ ( s t , a t ; θ n o w ) . \theta_{\mathrm{new}}\:\leftarrow\:\boldsymbol{\theta_{now}}\:+\:\beta\:\cdot\:\sum_{t=1}^{n}\gamma^{t-1}\:\cdot\:\underbrace{u_{t}\:\cdot\:\nabla_{\boldsymbol{\theta}}\ln\pi(a_{t}\:|\:s_{t};\:\boldsymbol{\theta_{\mathrm{now}}})}_{\text{即随机梯度 }\tilde{\boldsymbol{g}}(s_{t},a_{t};\boldsymbol{\theta_{\mathrm{now}}})}\:. θnew←θnow+β⋅t=1∑nγt−1⋅即随机梯度 g~(st,at;θnow) ut⋅∇θlnπ(at∣st;θnow).
注:在算法最后一步中,随机梯度前面乘以系数 γ t − 1 \gamma^{t-1} γt−1 。为什么需要这个系数呢?原因是这样的:前面 REINFORCE 的推导是简化的,而非严谨的数学推导;按照我们简化的推导,不应该乘以系数 γ t − 1 \gamma^{t-1} γt−1。当进行严格的数学推导的时候,得出的 REINFORCE 算法需要系数 γ t − 1 \gamma^{t-1} γt−1。
注:REINFORCE 属于同策略 (on-policy), 要求行为策略 (behavior policy) 与目标策略(target policy) 相同,两者都必须是策略网络 π ( a ∣ s ; θ n o w ) \pi(a|s;\theta_\mathrm{now}) π(a∣s;θnow), 其中 θ n o w \theta_\mathrm{now} θnow 是策略网络当前的参数。所以经验回放不适用于 REINFORCE。
后记
截至2024年1月27日12点01分,学习完 policy based RL的视频与书上的内容,并且进行了整理。






![数据结构-顺序表的实现 [王道]](https://img-blog.csdnimg.cn/direct/347db28acb914fc39bb0706d18e8a45a.png)