从零到一·配环境篇
由于今年要展开大量的编程工作,实验室在用的云计算平台是并行超算云,因此打算在寒假期间先熟悉一下超算云的环境,并从配套的文档和网上的教程开始,从零到一先跑通一个用于音视频分割的模型CATR。
以blog的形式对学习过程进行记录,仅作学习之用。
将数据和代码上传到云中
上一节介绍了并行超算云中环境的配置。配置好环境之后,就可以开始训练我们的模型了。训练模型之前,必要的一步是将本地已经可以跑通的代码上传到云平台中。
由于是第一次进行尝试,所以我选择了最简单的任务:在Cifar-10数据集上的图像分类作为测试代码。
我同时将Cifar-10的batch数据、ResNet模型以及模型训练的代码打包为zip文件,并上传至云平台的./run目录下进行解压。解压过后,还需要编写一个shell脚本文件。
在并行超算云平台上,不能直接在命令行中运行程序,而需要以作业的形式将程序提交到作业队列中。编写的shell脚本如下(参考自并行云计算的操作手册):
#!/bin/bash
#SBATCH --gpus=1
module load anaconda/2022.10
module load cuda/12.1
source activate python38
python train_model_cifar10.py
其中,上述的第二行#SBATCH --gpus=1指定了该作业要使用的gpu数量,使用了一个。gpus的数量也可以在命令行提交作业时进行指定。
第二行、第三行的module load是加载系统当中的软件;第四行的source activate python38是用来启动我在上一节中在服务器中创建的conda虚拟环境,名曰python38;而最后一行是程序的名称,即train_model_cifar10.py。
由于用于训练ResNet模型的程序代码是我之前在多个平台进行学习,并改写而成的,其多个出处已不可考,因此这里不再放出。如果代码在本地能跑的通,那么上传到云平台上应该问题就不大,无非是缺少几个软件包,比如我在运行时发现缺少matplotlib,使用conda install matplotlib进行安装即可。
提交作业
提交作业之间,对于shell脚本,由于是从Windows系统上传至Linux系统的,需要首先使用dos2unix run.sh对脚本的格式进行转换,使得Linux系统能够识别。
之后,使用命令sbatch --gpus=1 run.sh将作业提交。由于我们之前在shell脚本中已经指定了gpus参数,所以在这里直接使用sbatch run.sh也是work的。
提交作业之后,可以使用squeue命令查看当前作业,使用parajobs查看显存占有率。程序的输出会实时输出到与shell脚本同目录的XXXXX.out文件中。
查看输出
可以在.out文件中查看输出:
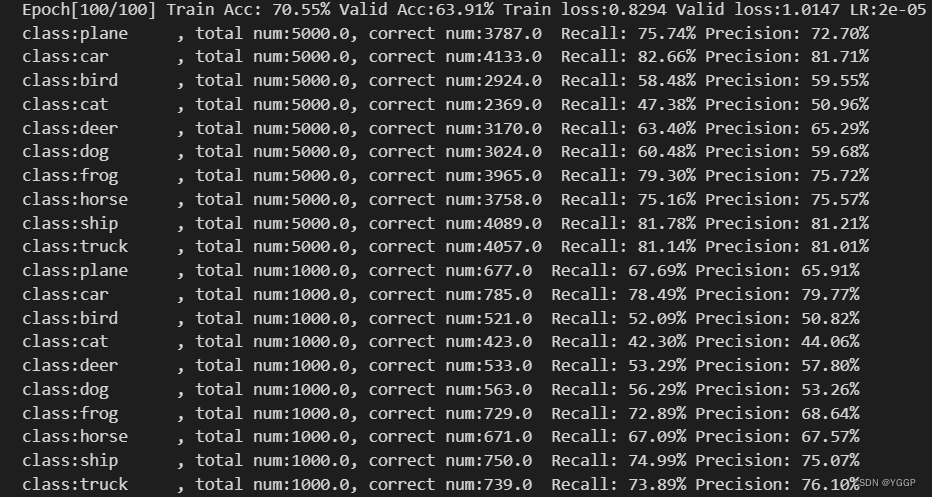
👆正确的输出表明程序可以顺利地在云平台上运行。
至此,我们便在并行超算云上完成了环境配置和最简单的程序测试。