HDFS的standby节点启动过慢原因分析以及应对策略
- 1. NN启动大致流程
- 2. Editlog日志清理策略
- 2.1 为什么需要合并editlog?
- 2.2 什么时候删除editlog?
- 3. NN启动的日志加载策略
- 4. Standby启动慢应对策略
- 5. 疑问和思考
- 5.1 如何人工阅读editlog文件的内容?
- 5.2 checkpoint的触发策略是什么?
- 5.3 如果删除editlog失效导致保存过多的editlog,如果nn重启,启动过程是否会很长?
- 6. 参考文档
在hdfs的nn重启过程时,以standby的方式进行启动,其中当前节点的fsimage和active节点的editlog数量对启动时间起到关键性的影响。本问题探讨hdfs的active节点正常,当standby节点重启时重启过慢的原因分析以及应对的策略。
为了分析出standby节点启动慢的原因,有必要分析和了解nn启动过程中在做什么事情,才能进一步分析慢在哪里,以及怎么优化。
1. NN启动大致流程
这里不探讨nn启动过程中复杂的代码逻辑实现,梳理整体上nn启动时,nn在能处理client的请求之前必须完成以下几步:
- 从fsimage文件中读取系统metadata
- 读取edit logs并把记录在其中的操作合并到系统metadata中去
- 生成一个新的checkpoint(新的fsimage必须和旧fsimage加上edit log上操作保持一致)
- 保持safe mode直到Datanodes上报足够数量的block信息
- 节点状态升级为standby,集群状态恢复,可以给客户端提供服务
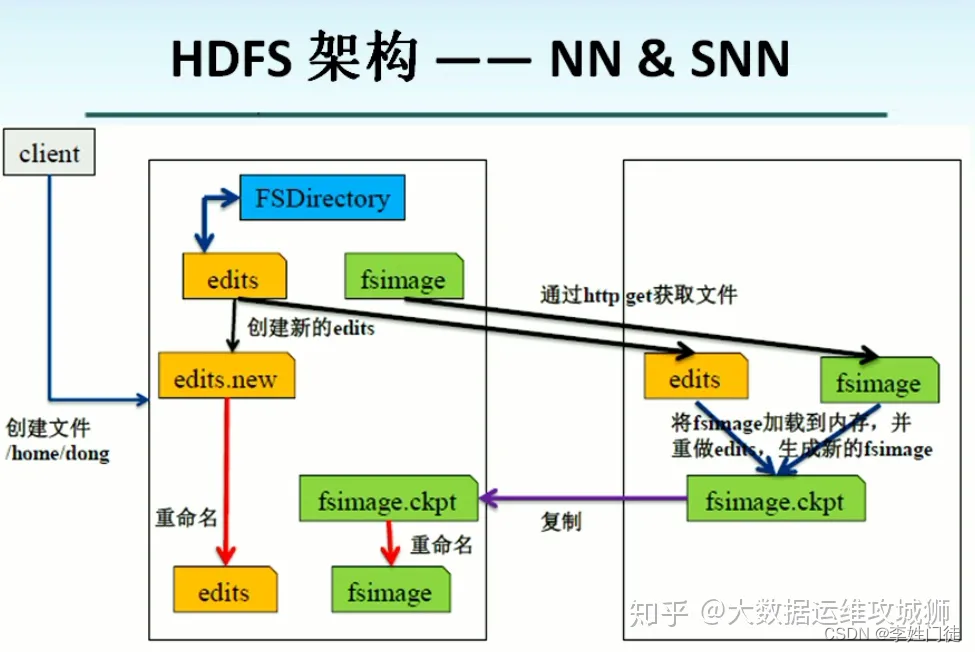
图形如下
说明
- 启动时会调用jn的rpc接口拉取editlog进行合并,值得注意的是,editlog信息并不会写入到本地的editlog文件中而是加载到当前节点的内存中进行数据合并,因此standby节点的editlog会被active节点少
- standby完成checkpoint后生成fsimage文件后通知acrive节点,active节点通过jn的GET接口拉取fsimage,完成checkpoint同步
- editlog合并、checkpoint生成fsimage依赖机器的内存、磁盘io性能,并且如果需要合并的editlog文件很多,就会导致启动过程很慢
根据生产经验,在大多数情况下,造成nn启动慢的原因,是在拉取editlog进行数据合并环节耗时过多,针对该问题进行重点分析。
2. Editlog日志清理策略
在HA架构下,fsimage + checkpoint后的editlog组成了完整的数据,但是不代表hdfs的nn节点只保存checkpoint后的editlog。事实上,nn拥有自己的保存策略。在讨论这个问题前,我觉得有必要回顾一下为什么需要合并editlog以及合并editlog的策略是什么。
2.1 为什么需要合并editlog?
在client写数据是,在一致性流程中我们在HDFS高可用架构涉及常用功能整理进行了梳理,editlog会通过append的方式记录数据写入的相关操作,在获得极致的写入性能同时,却牺牲了数据的组织性,因此难以通过查询editlog的方式组织数据结构。这就会导致一个问题,editlog持续写入,如果不进行数据合并,就会导致editlog越来越多,最后难以管理,特别是重启后,需要重新回放所有的editlog,这是难以接受的。所以通过合并editlog的方式(过程叫checkpoint),生产fsimage。为了减少active的压力,合并editlog的工作是交给standby负责的。
大体上的checkpoint流程如下
2.2 什么时候删除editlog?
之前我一直以为,nn是在standby完成checkpoint,active将fsimage同步完成后会自行删除editlog,减少active的过期的editlog。直到我重新做了认真整理了checkpoint环节并阅读了部分代码后,发现checkpoint和删除editlog策略是两件不相干的事儿。
editlog日志的删除,内部维护了特定的日志删除策略。主要的代码如下
/**
void purgeOldStorage(NameNodeFile nnf) throws IOException {
FSImageTransactionalStorageInspector inspector =
new FSImageTransactionalStorageInspector(EnumSet.of(nnf));
storage.inspectStorageDirs(inspector);
long minImageTxId = getImageTxIdToRetain(inspector);
purgeCheckpointsOlderThan(inspector, minImageTxId);
if (nnf == NameNodeFile.IMAGE_ROLLBACK) {
// do not purge edits for IMAGE_ROLLBACK.
return;
}
// If fsimage_N is the image we want to keep, then we need to keep
// all txns > N. We can remove anything < N+1, since fsimage_N
// reflects the state up to and including N. However, we also
// provide a "cushion" of older txns that we keep, which is
// handy for HA, where a remote node may not have as many
// new images.
//
// First, determine the target number of extra transactions to retain based
// on the configured amount.
long minimumRequiredTxId = minImageTxId + 1;
//最小的日志事务id为: 最小需要保留的事务txid减去需要额外保留的事务id,其中minimumRequiredTxId为检查点镜像文件的最后一条事务id,本质上就是保留numExtraEditsToRetain条事务。
long purgeLogsFrom = Math.max(0, minimumRequiredTxId - numExtraEditsToRetain);
//edit log的文件输入流
ArrayList<EditLogInputStream> editLogs = new ArrayList<EditLogInputStream>();
//填充
purgeableLogs.selectInputStreams(editLogs, purgeLogsFrom, false, false);
//排序,优先比较第一条事务txid,然后比较最后一条事务txid
Collections.sort(editLogs, new Comparator<EditLogInputStream>() {
@Override
public int compare(EditLogInputStream a, EditLogInputStream b) {
return ComparisonChain.start()
.compare(a.getFirstTxId(), b.getFirstTxId())
.compare(a.getLastTxId(), b.getLastTxId())
.result();
}
});
// Remove from consideration any edit logs that are in fact required.
//如果edit log文件的第一个事务txid比最小需要保留的事务txid大,那么该edit log需要保留,从待editLogs list中移除。
while (editLogs.size() > 0 &&
editLogs.get(editLogs.size() - 1).getFirstTxId() >= minimumRequiredTxId) {
editLogs.remove(editLogs.size() - 1);
}
// Next, adjust the number of transactions to retain if doing so would mean
// keeping too many segments around.
//如果editLogs list的条数比需要保留的最大edits文件数多,那么能保留的最小事务id purgeLogsFrom 需要扩大,将purgeLogsFrom 置为该日志的文件事务txid
//如果了解前因后果的话,需要清除的日志由两个参数控制,需要保留的事务数量及需要保留的日志文件数,两个是且的关系,只有两个条件都满足的日志才会保留,有一个不满足就会删除,这里其实就是当日志文件数大于需要保留的日志文件数时,多余的日志文件数需要清除。
while (editLogs.size() > maxExtraEditsSegmentsToRetain) {
purgeLogsFrom = editLogs.get(0).getLastTxId() + 1;
editLogs.remove(0);
}
// Finally, ensure that we're not trying to purge any transactions that we
// actually need.
//最后确认下,本次清除的事务id必须比最低要求低,不然抛出异常。
if (purgeLogsFrom > minimumRequiredTxId) {
throw new AssertionError("Should not purge more edits than required to "
+ "restore: " + purgeLogsFrom + " should be <= "
+ minimumRequiredTxId);
}
//调用方法清除,这个前文已经将了
purgeableLogs.purgeLogsOlderThan(purgeLogsFrom);
}
更多细节不在展开,总结下来,nn删除editlog主要由2个策略决定
- 保留 numExtraEditsToRetain 条事务
- 保留 maxExtraEditsSegmentsToRetain 个edit log日志文件
两个策略独立运行,只要有一个条件不满足,日志就会被删除。
查看源码得知,
- numExtraEditsToRetain对应的参数为 dfs.namenode.num.extra.edits.retained(默认值1000000)
- maxExtraEditsSegmentsToRetain对应的参数为 dfs.namenode.max.extra.edits.segments.retained(默认值10000)
所以整体总结过来的策略是,editlog的删除策略是
- 最多保留dfs.namenode.max.extra.edits.segments.retained(默认值10000)+ n (n跟fsimage的文件个数有关)个editlog,如果nn的事务增长较快,由于只保留dfs.namenode.num.extra.edits.retained(默认值1000000)条事务,因此editlog数量可能会少于dfs.namenode.max.extra.edits.segments.retained(默认值10000)个。
另外,可以从fsimage的名称可以获取最小的事务id,比如fsimage_000000000096796869,对应的最小事务id是000000000096796869,往前保留1000000个事务,即从95796870开始,事务ID比这个小的editlog文件都会被删除(包含95796870的editlog会被保留,即便该editlog文件的事务ID可能会比95796870小)

在查看hadoop的官方hdfs-default.xml文档获得相关配置的解释。
| 名称 | 默认值 | description | 翻译 |
|---|---|---|---|
| dfs.namenode.num.extra.edits.retained | 1000000 | The number of extra transactions which should be retained beyond what is minimally necessary for a NN restart. It does not translate directly to file’s age, or the number of files kept, but to the number of transactions (here “edits” means transactions). One edit file may contain several transactions (edits). During checkpoint, NameNode will identify the total number of edits to retain as extra by checking the latest checkpoint transaction value, subtracted by the value of this property. Then, it scans edits files to identify the older ones that don’t include the computed range of retained transactions that are to be kept around, and purges them subsequently. The retainment can be useful for audit purposes or for an HA setup where a remote Standby Node may have been offline for some time and need to have a longer backlog of retained edits in order to start again. Typically each edit is on the order of a few hundred bytes, so the default of 1 million edits should be on the order of hundreds of MBs or low GBs. NOTE: Fewer extra edits may be retained than value specified for this setting if doing so would mean that more segments would be retained than the number configured by dfs.namenode.max.extra.edits.segments.retained. | 应该保留的额外事务的数量超出了 NN 重新启动所需的最低限度。它不会直接转换为文件的年龄或保存的文件数量,而是转换为事务的数量(这里“编辑”是指事务)。一个编辑文件可能包含多个事务(编辑)。在检查点期间,NameNode 将通过检查最新的检查点事务值减去此属性的值来确定要保留的编辑总数。然后,它扫描编辑文件以识别不包括计算范围的保留交易的旧文件,并随后清除它们。保留对于审计目的或 HA 设置很有用,其中远程备用节点可能已离线一段时间并且需要保留更长的保留编辑积压才能重新开始。通常,每次编辑大约为几百字节,因此默认的 100 万次编辑应该是数百 MB 或低 GB 的数量级。注意:如果这样做意味着保留的段数多于 dfs.namenode.max.extra.edits.segments.retained 配置的数量,则保留的额外编辑可能少于为此设置指定的值。 |
| dfs.namenode.num.checkpoints.retained | 2 | 最多保存2个fsimage文件 |
3. NN启动的日志加载策略
nn启动时会加载本地的fsimage,然后通过jn下载editlog进行数据回放,但是如果nn的editlog清理策略不生效,保留了很长时间以前的editlog,standby重启后,到底是把active节点的所有editlog都下载下来回放还是会根据本地的fsimage下载相应的editlog(fsimage最小事务之后的editlog)进行回放?也就是说,active如果保留了过多的editlog,是否会对standby的启动流程是否有影响?
为了解答这个疑问,我自己搭建了一个hdfs集群,并进行模拟和验证,观察相关的日志情况如下
nn2节点(standby)重启,相关日志如下,nn2加载了fsimage_0000000000000002066,并记录当前的txid=0000000000000002066,并开始从txid=2067进行下载,因此直接忽略txid=2066的editlog文件。

可以得出结论
- standby重启后,会根据fsimage计算最小的txid,并从最小txid开始下载editlog,因此active节点如果保存了过多的editlog并不会干扰standby的启动过程。
- 如果standby本地的fsimage版本过老,就会需要从nn1下载大量的editlog进行数据合并,需要消耗很长时间
- 正常情况下,active最多保存dfs.namenode.max.extra.edits.segments.retained(默认值10000)+ n (n跟fsimage的文件个数有关)个editlog,如果standby宕机时间过久,本地的fsimage + active保留的editlog,有可能无法完成数据回放,会出现数据丢失。
4. Standby启动慢应对策略
如果standby启动过慢,原因是由于fsimage版本过老,应对的策略应该是从active节点同步最新的fsimage,从而减少下载editlog日志。
如下2种方式均可
- 将active节点的fsimage拷贝给standby节点,在启动standby节点
- 执行命令同步元数据后,在启动standby节点
hdfs namenode -bootstrapStandby
如果standby节点宕机时间过长,active节点由于没有standby节点进行checkpoint,可能fsimage的版本很低,可以在启动standby节点前手动执行savepoint,在同步fsimage。但是需要注意,手动执行checkpoint需要先进入安全模式,此时客户端是不能读写的,对业务有影响,需要业务低峰期执行。
# 进入安全模式
hdfs dfsadmin -safemode enter
# 执行checkpoint
hdfs dfsadmin -saveNamespace
hdfs dfsadmin -saveNamespace
# 离开安全模式
hdfs dfsadmin -safemode leave
# standby同步元数据
hdfs namenode -bootstrapStandby
5. 疑问和思考
5.1 如何人工阅读editlog文件的内容?
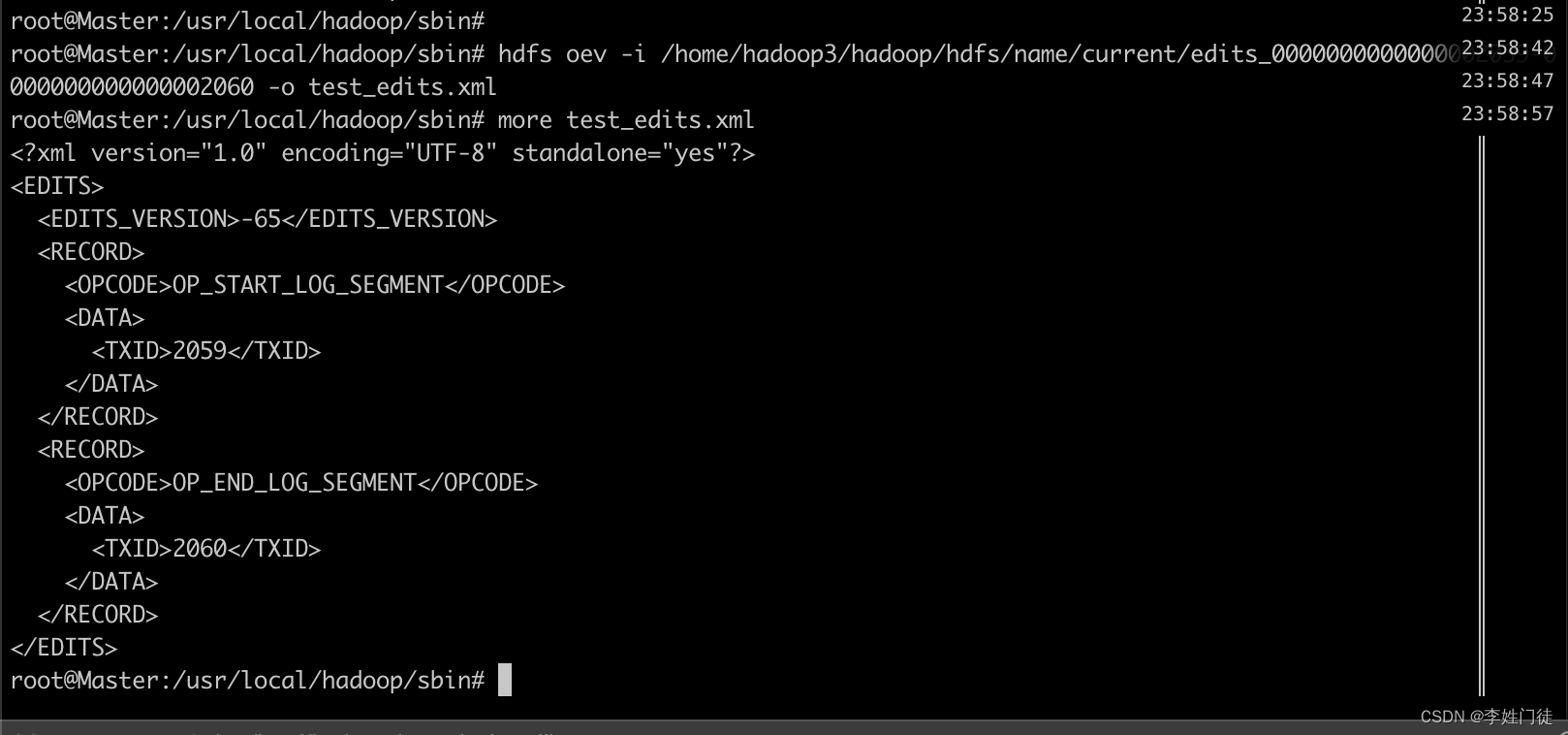
可以通过hdfs提供的工具进行读取
hdfs oev -i edits_0000000000000157832-0000000000000158267 -o test_edits.xml
# -i 为输入edits文件地址
# -o 为输出的xml地址
cat test_edits.xml
5.2 checkpoint的触发策略是什么?
触发进行checkpoint的时机由这么几个配置项决定
dfs.namenode.checkpoing.check.period
检测是否满足上面两个条件的时间间隔,默认值为60秒。即1分钟检查一次。
dfs.namenode.checkpoint.period
执行checkpoint的最小时间间隔,默认为3600秒,即1小时。
dfs.namenode.checkpoint.txns
触发checkpoint的事务数,默认值为1000000。
上述两个条件只要符合其一,则执行checkpoint。
也就是说,3600s内一定会触发一次checkpoint,如果集群的写频繁,满足1000000条事务(还没到3600s)就会触发checkpoint
5.3 如果删除editlog失效导致保存过多的editlog,如果nn重启,启动过程是否会很长?
不一定。启动过程时,依赖本地的fsimage,通过fsimage计算最小txid,并基于最小txid加载回放editlog,通常回放editlog的多少对启动过程的时长有很大的影响。
因此,如果standby进行checkpoint的流程正常,fsimage的版本比较高,nn启动过程也是比较快的。
如果standby进行checkpoint的流程不正常,fsimage的版本比较低,nn启动过程就会比较慢。
6. 参考文档
- hadoop edits日志不删除现象排查
- HDFS——fsimage