先准备一个文件里面数据有:
a, 1547718199, 1000000 b, 1547718200, 1000000 c, 1547718201, 1000000 d, 1547718202, 1000000 e, 1547718203, 1000000 f, 1547718204, 1000000 g, 1547718205, 1000000 h, 1547718210, 1000000 i, 1547718210, 1000000 j, 1547718210, 1000000
scala代码:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
case class SensorReading(name: String, timestamp: Long, salary: Double)
object a1 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//数据源
val dataStream: DataStream[String] = env.readTextFile("D:\\wlf.备份24.1.3\\wlf\\ideaProgram\\bbbbbb\\src\\main\\resources\\salary.txt")
val stream = dataStream.map(data => {
val splited = data.split(",")
SensorReading(splited(0), splited(1).trim.toLong, splited(2).trim.toDouble)
})
stream.addSink( new JDBCSink() )
env.execute(" job")
}
}
class JDBCSink() extends RichSinkFunction[SensorReading]{
// 定义sql连接、预编译器
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
// 初始化,创建连接和预编译语句
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection("jdbc:mysql://bigdata1:3306/flink?serverTimezone=UTC", "root", "123456")
insertStmt = conn.prepareStatement("INSERT INTO salary_table (name, salary) VALUES (?,?)")
updateStmt = conn.prepareStatement("UPDATE salary_table SET salary = ? WHERE name = ?")
}
override def invoke(value: SensorReading): Unit = {
// 执行更新语句
updateStmt.setString(1, value.name)
updateStmt.setDouble(2, value.salary)
updateStmt.execute()
// 如果update没有查到数据,那么执行插入语句
if( updateStmt.getUpdateCount == 0 ){
insertStmt.setString(1, value.name)
insertStmt.setDouble(2, value.salary)
insertStmt.execute()
}
}
// 关闭时做清理工作
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
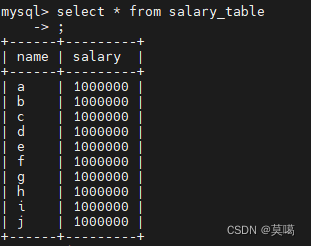
MySQL中查看表 :