阿里大语言模型通义千问API使用新手教程
最近需要用到大模型,了解到目前国产大模型中,阿里的通义千问有比较详细的SDK文档可进行二次开发,目前通义千问的API文档其实是可以进行精简然后学习的,也就是说,是可以通过简单的API调用在自己网页或者软件中接入一个大语言模型,但是似乎并没有人愿意花费时间经历写一个新手友好的教程,为此处于对知识的梳理,和对技术的热爱,我尽我的最大的努力来做这件事,如果帮到了各位同学,或者老师们,可以点赞或者关注支持一下,后续更新基于本地知识库的详细教程。如果有什么写的不对的或者可以补充完善的,欢迎交流。
- 对于有基础的开发技术人员请直接根据目录跳到代码部分综合查看官方文档和代码即可
- 对于想充实自己毕业设计或者软件但对自然语言处理技术并不是非常了解的同学,把每一个代码运行一遍即可,切记不要纠结专业术语
- 如果是做相关应用的研究生,请按顺序阅读,思考数据格式,有助于思维的培养
文章目录
- 阿里大语言模型通义千问API使用新手教程
- 1.通义千问模型介绍
- 2.通义千问API-KEY申请
- 3.安装DashScope SDK
- 4.API-KEY设置
- 4.1 方式1 可以直接在命令台设置环境变量
- 4.2 方式2 在系统环境变量里直接设置
- 4.3 方式3 通过代码设置
- 4.4 方式经验总结
- 5. 使用通义千问API进行Token切分
- 6. 使用通义千问的API进行对话
- 6.1 通过messages 进行对话 开发推荐
- 6.2 通过prompt进行对话 新手推荐
- 6.3 多轮对话
- 6.4 流式输出
- 7.通过控制台输入实现多轮对话-非流式输出
- 8.通过控制台输入实现多轮对话-流式输出
- 9.参考文档链接总结
- 资源绑定
1.通义千问模型介绍
通义千问是阿里云开发的大语言模型(Large language Model )LLM,旨在提供广泛的知识和普适性,可以理解和回答各领域中的问题,其包含网页版和手机版本的通义前文APP,网页使用的模型为不公开的最新版本。
其网页使用版本地址:https://tongyi.aliyun.com/qianwen/
官网文档地址:https://help.aliyun.com/zh/dashscope/developer-reference/
在其官方文档中主要开源了五种可以使用的模型其开源模型的简介和参数如下:

非限时免费开放模型,有使用Token数量的限制
2.通义千问API-KEY申请
官方流程网址指导:https://help.aliyun.com/zh/dashscope/developer-reference/activate-dashscope-and-create-an-api-key
其主要流程如下,具体请参考官网步骤
- 开通DashScope灵积模型服务
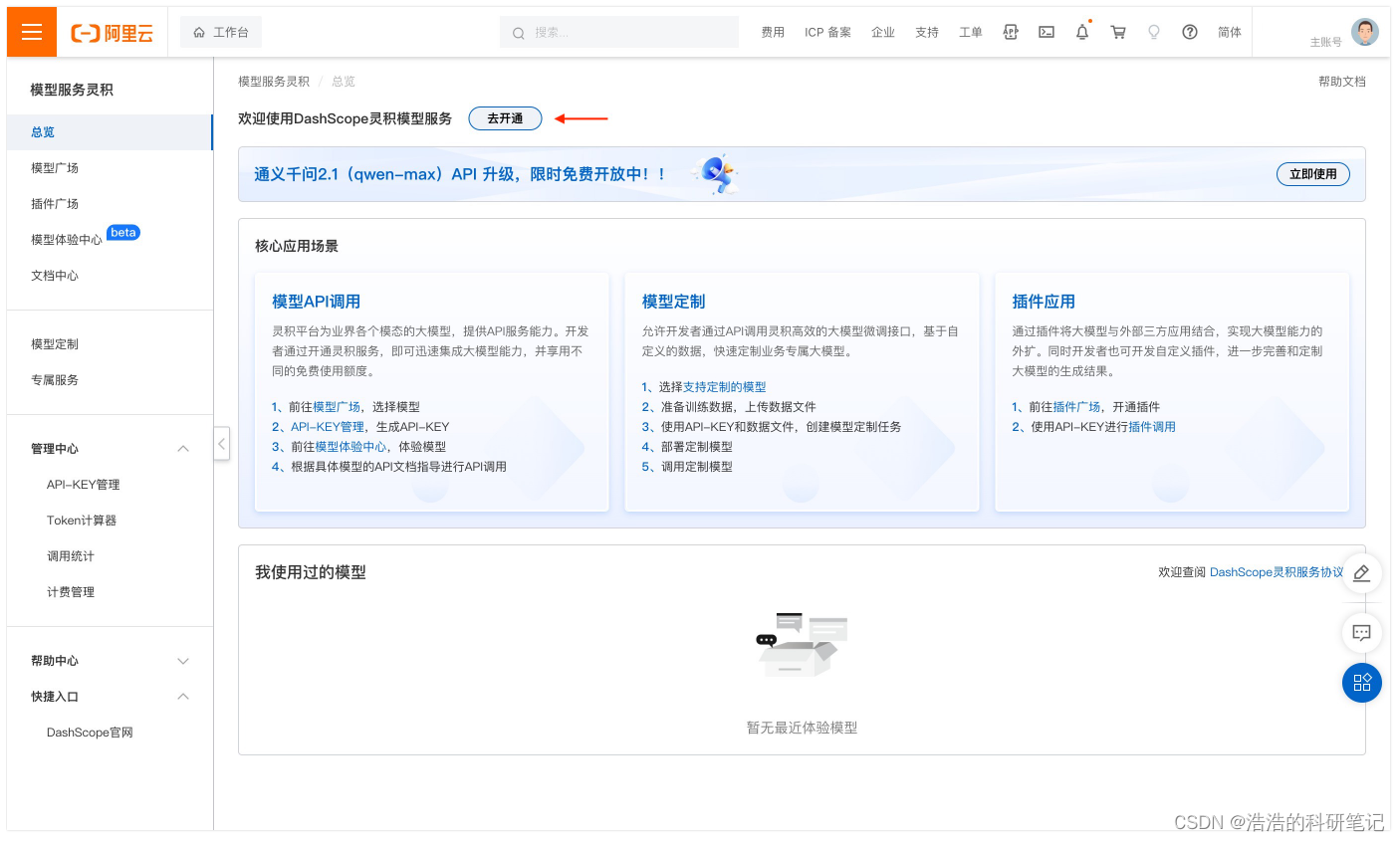
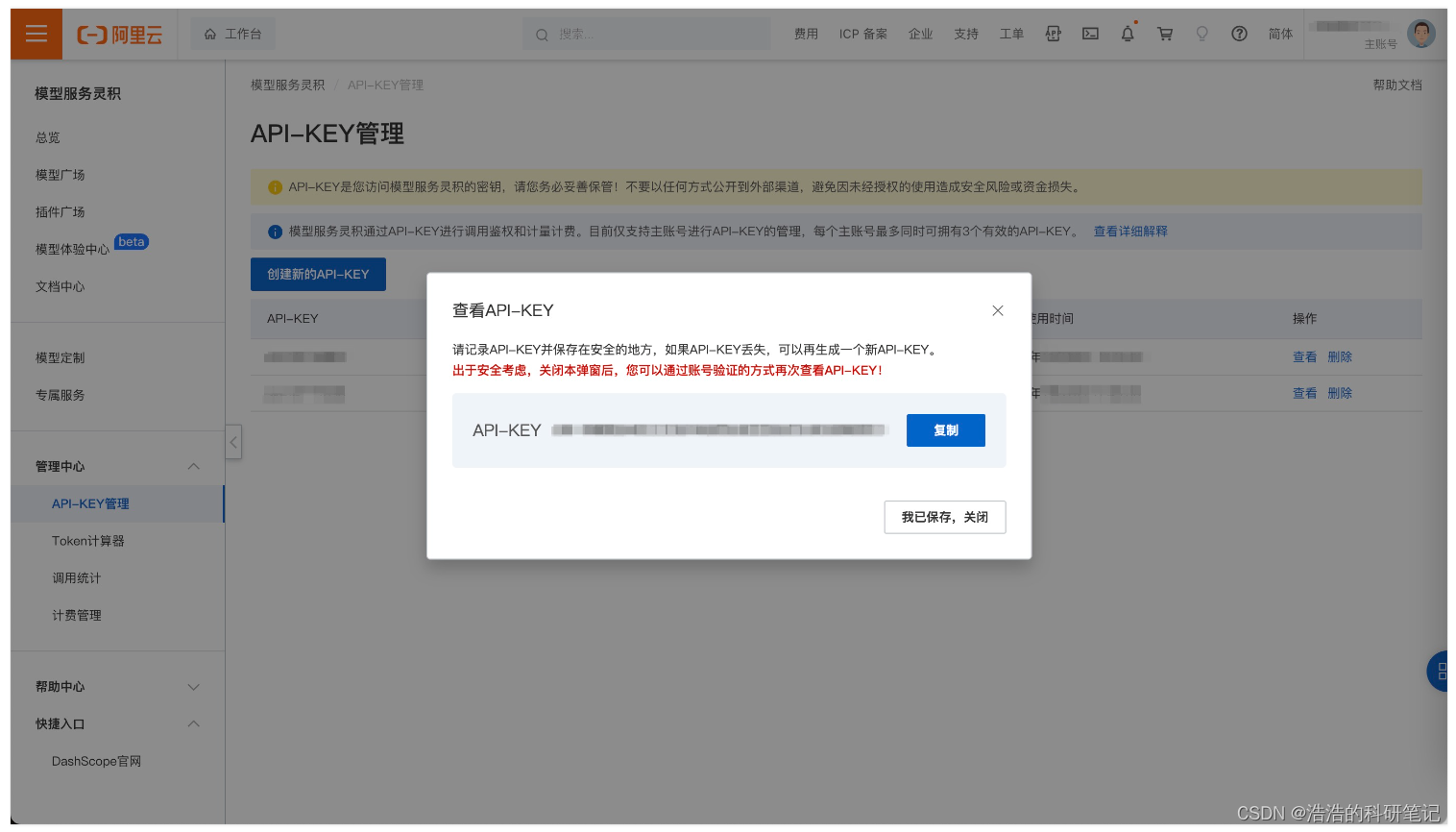
- 创建API-KEY
根据官网流程获得一个API-Key
3.安装DashScope SDK
DashScope 目前支持Python 和 Java 的 SDK
安装SDK的官网教程网址:https://help.aliyun.com/zh/dashscope/developer-reference/install-dashscope-sdk
这里介绍python的安装
- 安装环境 Python 3.8 及以上版本
执行以下命令安装SDK,亲测支持清华园镜像安装
pip install dashscope
更新DashDcope SDK包 请执行以下命令
pip install dashscope --upgrade
4.API-KEY设置
API-KEY设置地址官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/api-key-settings
4.1 方式1 可以直接在命令台设置环境变量
Linux/maxOS
export DASHSCOPE_API_KEY="YOUR_DASHSCOPE_API_KEY"
4.2 方式2 在系统环境变量里直接设置
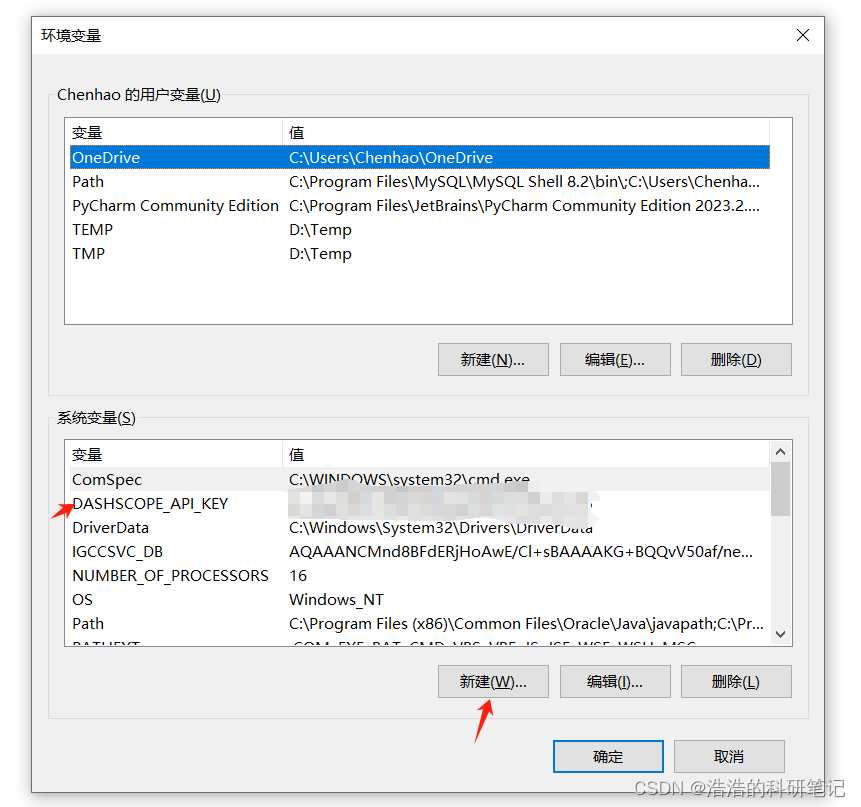
4.3 方式3 通过代码设置
python设置API-KEY代码如下
import dashscope
dashscope.api_key="YOUR_DASHSCOPE_API_KEY"
4.4 方式经验总结
其中官方推荐使用4.1的方式不推荐将API-KEY直接写在代码中,会有一定的API-KEY暴露风险,实际应用中,配置的环境变量有时会出现读取不到的情况,此时将API-KEY写在代码中可以使程序正常运行。
5. 使用通义千问API进行Token切分
使用通义千问对Token进行切分官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/token-api
精简版如下:
import dashscope
# 如果环境变量配置无效请启用以下代码
# dashscope.api_key = 'YOUR_DASHSCOPE_API_KEY'
# respose获得的为
response = dashscope.Tokenization.call(model='qwen-turbo',messages=[{'role': 'user', 'content': '你好?'}])
print(response)
# {"status_code": 200, "request_id": "6d53e094-e8bc-9d88-a84a-6085c9425ad8", "code": "", "message": "", "output": {"token_ids": [108386, 11319], "tokens": ["你好", "?"]}, "usage": {"input_tokens": 2}}
消息格式为一个列表,
role为当前角色设置为user则模拟为用户的真实输入,content后面为要切分tokens的句子
messages=[{'role': 'user', 'content': '你好?'}]
- 可能会出现的错误1:系统配置了环境变量但是依然读取不到,错误中包含not find API 相关错误请启用以下代码
dashscope.api_key = 'YOUR_DASHSCOPE_API_KEY'
- 可能会出现的错误2: 错误中出现Http相关字样,其主要可能原因是网络问题,请检查网络状态是否断网或者是是国内地址
官方代码对出现Http错误的情况进行了判断,官方代码如下
from http import HTTPStatus
import dashscope
def tokenizer():
response = dashscope.Tokenization.call(model='qwen-turbo',
messages=[{'role': 'user', 'content': '你好?'}],
)
if response.status_code == HTTPStatus.OK:
print('Result is: %s' % response)
else:
print('Failed request_id: %s, status_code: %s, code: %s, message:%s' %
(response.request_id, response.status_code, response.code,
response.message))
if __name__ == '__main__':
tokenizer()
6. 使用通义千问的API进行对话
使用通义千问进行对话API官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/quick-start
下面是对其中主要内容的
6.1 通过messages 进行对话 开发推荐
精简版版代码如下,参数介绍在代码后:
import dashscope
# 如果环境变量配置无效请启用以下代码
# dashscope.api_key = 'YOUR_DASHSCOPE_API_KEY'
messages = [{'role': 'user', 'content': '如何做炒西红柿鸡蛋?'}]
response = dashscope.Generation.call(dashscope.Generation.Models.qwen_turbo,messages=messages,result_format='message')
print(response)
# {"status_code": 200, "request_id": "537d7681-8aa2-9f15-a17d-1b8492ad901f", "code": "", "message": "", "output": {"text": null, "finish_reason": null, "choices": [{"finish_reason": "stop", "message": {"role": "assistant", "content": "材料:鸡蛋2个,西红柿1个。\n\n做法:\n\n1. 鸡蛋打入碗中搅拌均匀备用;\n\n2. 西红柿洗净切块备用;\n\n3. 热锅凉油,油热后放入搅拌好的鸡蛋液,用筷子快速划散成小块,凝固即可盛出备用;\n\n4. 锅内再加少量底油,放入西红柿翻炒出汁,倒入炒好的鸡蛋,加入适量盐、糖调味翻匀即可。"}}]}, "usage": {"input_tokens": 12, "output_tokens": 106, "total_tokens": 118}}
dashscope.Generation.call中输入参数的介绍
dashscope.Generation.Models.qwen_turbo选用的对话模型默认对应的是model参数
也就是在代码中等效于
dashscope.Generation.call(model = dashscope.Generation.Models.qwen_turbo
,messages=messages,result_format='message')
还有dashscope.Generation中还有qwen_max qwen_plus两个选项
如果要使用其他模型例如qwen-14b-chat,前提是API有访问该模型的权限
则对应代码为
dashscope.Generation.call(model = 'qwen-14b-chat'.qwen_turbo
,messages=messages,result_format='message')
messages输入为对话角色和对话内容
输入应为一个列表其对应的伪代如下
[{'role': '角色类型(使用user即可)', 'content': '对话文本'}]
result_format输出格式
该参数其实可以去掉,因为实际使用中我发现无论设置成什么都是message形式输出
6.2 通过prompt进行对话 新手推荐
精简版代码如下:
import dashscope
# 如果环境变量配置无效请启用以下代码
# dashscope.api_key = 'YOUR_DASHSCOPE_API_KEY'
response = dashscope.Generation.call(model=dashscope.Generation.Models.qwen_turbo,prompt='如何做炒西红柿鸡蛋?')
print(response.output['text'])
'''
材料:鸡蛋2个,西红柿1个。
做法:
1. 鸡蛋打入碗中搅拌均匀备用;
2. 西红柿洗净切块备用;
3. 热锅凉油,油热后放入搅拌好的鸡蛋液,用筷子快速划散成小块,凝固即可盛出备用;
4. 锅内再加少量底油,放入西红柿翻炒出汁,倒入炒好的鸡蛋,加入适量盐、糖调味翻匀即可。
'''
其作用就是不需要messages格式进行输入,只需要输入对话的内容即可
官方代码
# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html
from http import HTTPStatus
import dashscope
def call_with_prompt():
response = dashscope.Generation.call(
model=dashscope.Generation.Models.qwen_turbo,
prompt='如何做炒西红柿鸡蛋?'
)
# The response status_code is HTTPStatus.OK indicate success,
# otherwise indicate request is failed, you can get error code
# and message from code and message.
if response.status_code == HTTPStatus.OK:
print(response.output) # The output text
print(response.usage) # The usage information
else:
print(response.code) # The error code.
print(response.message) # The error message.
if __name__ == '__main__':
call_with_prompt()
6.3 多轮对话
多轮对话(Multi-Turn Dialogue)是指在一个对话中,参与者之间交换多个信息单位(如句子、问题、回答)的过程。在多轮对话中,每个参与者的发言通常是对前一个发言的回应,并且每个发言都为对话的进一步发展做出贡献。
官方代码精简版
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
messages = [{'role': Role.USER, 'content': '如何做西红柿炖牛腩?'}]
response = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message')
print(response.output.choices[0]['message']['content'])
messages.append({'role': response.output.choices[0]['message']['role'], 'content': response.output.choices[0]['message']['content']})
messages.append({'role': Role.USER, 'content': '不放糖可以吗?'})
response = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message')
print(response.output.choices[0]['message']['content'])
'''
材料:牛腩1000克,西红柿2个,大葱1根,姜3片,蒜瓣6粒,八角1颗,桂皮1小块,香叶2片,干辣椒2只,生抽2勺,老抽1勺,料酒2勺,冰糖20克,盐适量
做法:
1. 牛腩洗净切块,放沸水中焯水去血沫捞出备用。
2. 西红柿顶部划十字刀口,放入沸水中烫一下去皮,切滚刀块备用。
3. 大葱切段、姜切片、蒜瓣剥好。锅内油烧热,下入大葱段、姜片、蒜瓣、八角、桂皮、香叶和干辣椒炒香。
4. 下入牛腩翻炒均匀,烹入料酒炒匀后,加入生抽和老抽炒至上色。
5. 加入足量热水(没过牛腩),大火煮开后撇去浮沫,转中小火慢慢炖煮至牛腩软烂,约需1小时以上。
6. 当牛腩炖至8成熟时,加入西红柿块继续炖煮,炖煮至西红柿软烂且汤汁浓稠即可,最后调入适量的盐调味。
西红柿炖牛腩就做好了!
可以的,如果不喜欢甜味,可以不放冰糖或者减少用量。不过需要注意的是,糖能够增加菜肴的鲜美口感和色泽,如果你不放糖,可能会让菜肴的味道变得有些平淡无味。另外,糖还能够中和牛肉的腥味,如果没有糖的话,可能需要在炖煮的过程中多加一些调料来提味。
'''
多轮对话需要将输入信息反复输入给模型,且要包含以往全部的对话内容
- 第一次发信息
messages = [{'role': Role.USER, 'content': '如何做西红柿炖牛腩?'}]
response = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message')
- 第二次发信息
#添加机器返回的内容
messages.append({'role': response.output.choices[0]['message']['role'], 'content': response.output.choices[0]['message']['content']})
#添加新的内容
messages.append({'role': Role.USER, 'content': '不放糖可以吗?'})
response = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message')
官方代码
from http import HTTPStatus
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
def conversation_with_messages():
messages = [{'role': Role.SYSTEM, 'content': 'You are a helpful assistant.'},
{'role': Role.USER, 'content': '如何做西红柿炖牛腩?'}]
response = Generation.call(
Generation.Models.qwen_turbo,
messages=messages,
result_format='message', # set the result to be "message" format.
)
if response.status_code == HTTPStatus.OK:
print(response)
# append result to messages.
messages.append({'role': response.output.choices[0]['message']['role'],
'content': response.output.choices[0]['message']['content']})
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
messages.append({'role': Role.USER, 'content': '不放糖可以吗?'})
# make second round call
response = Generation.call(
Generation.Models.qwen_turbo,
messages=messages,
result_format='message', # set the result to be "message" format.
)
if response.status_code == HTTPStatus.OK:
print(response)
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
if __name__ == '__main__':
conversation_with_messages()
6.4 流式输出
流式输出(Streaming Output)是一种数据处理和输出的方式,其中数据连续地、实时地被发送和接收,而不是在所有数据都准备好后一次性发送。这种方法常用于处理实时数据流和大型数据集,尤其是在数据量太大以至于无法一次性完全加载到内存中的情况。
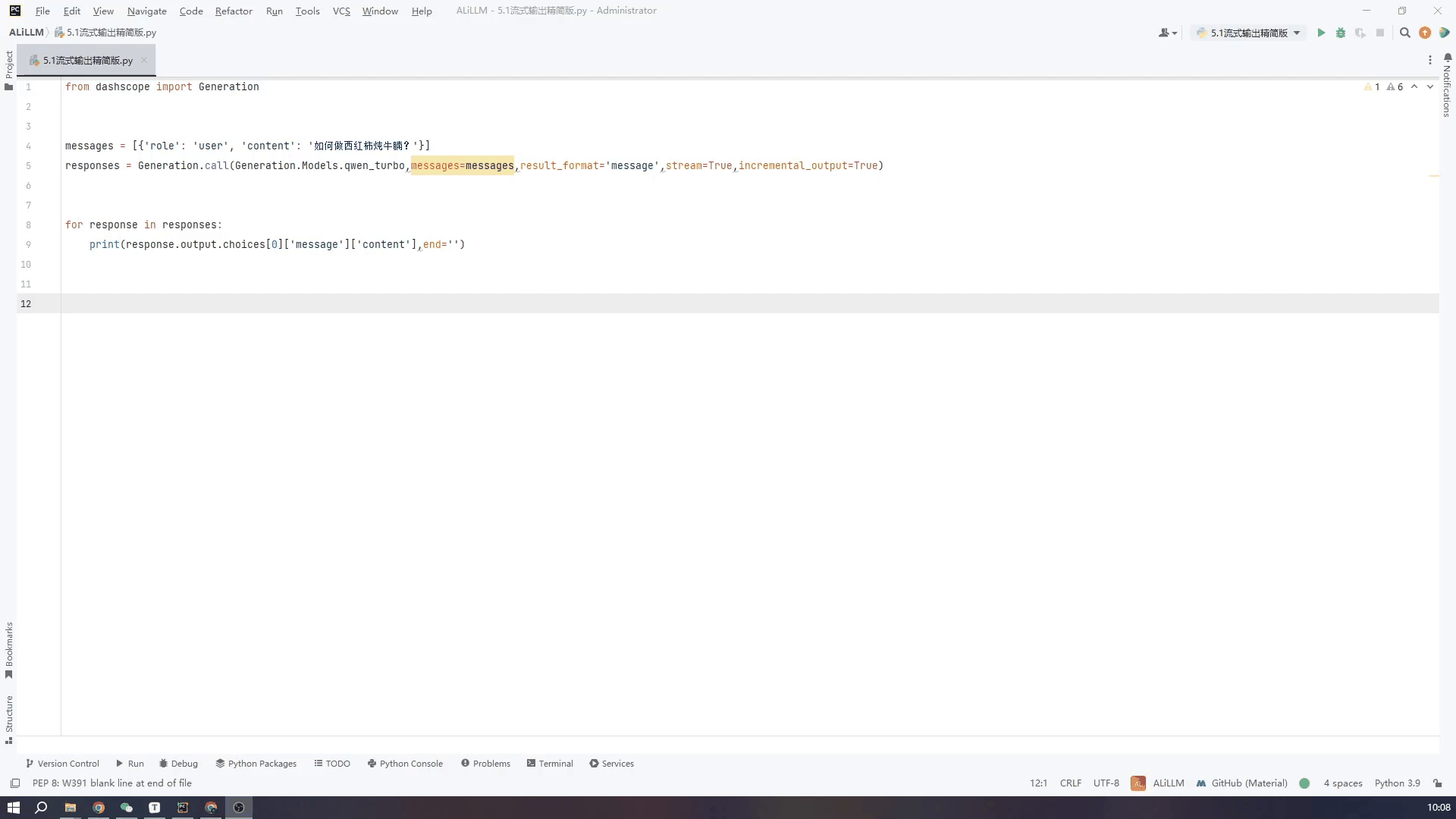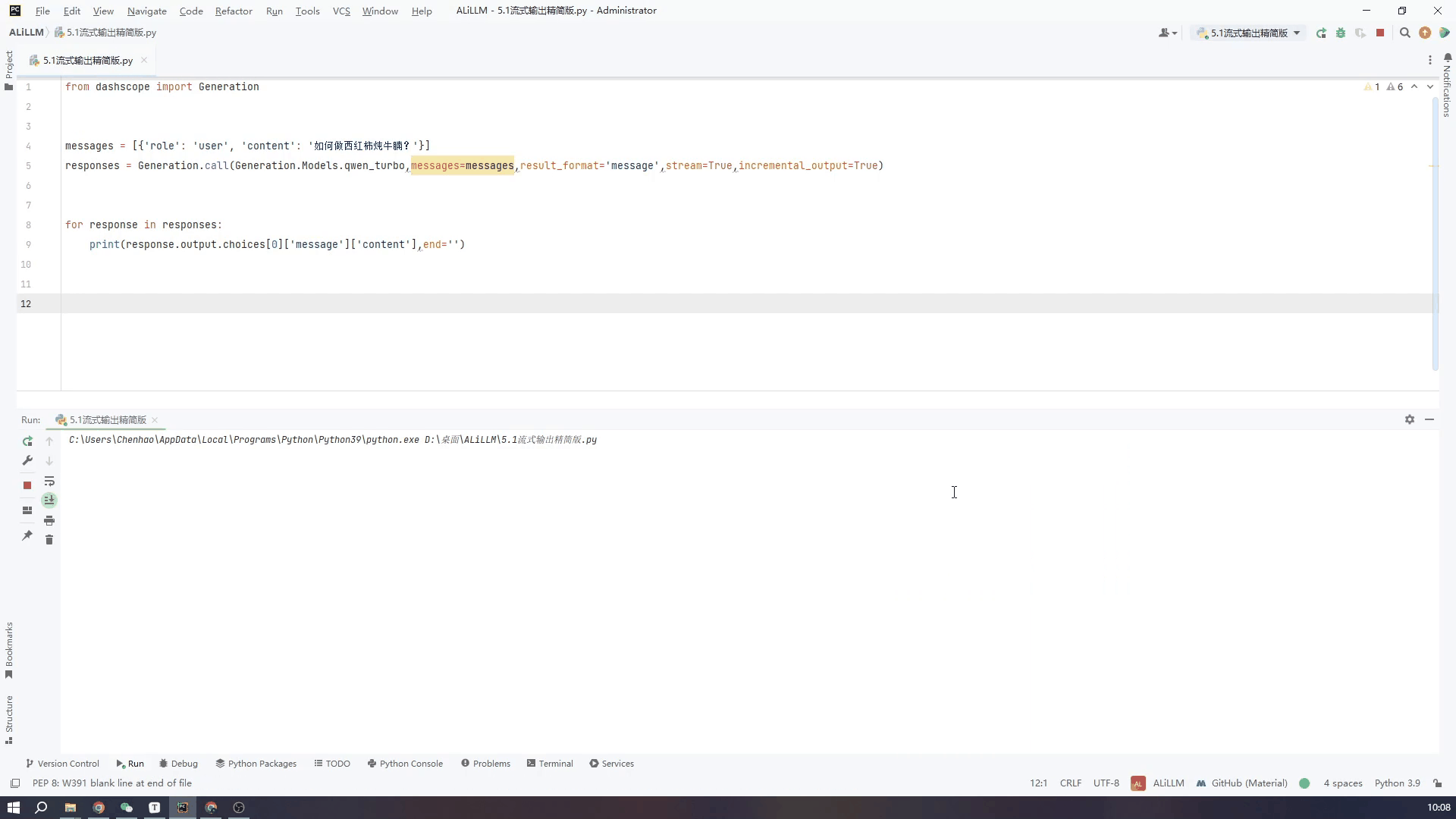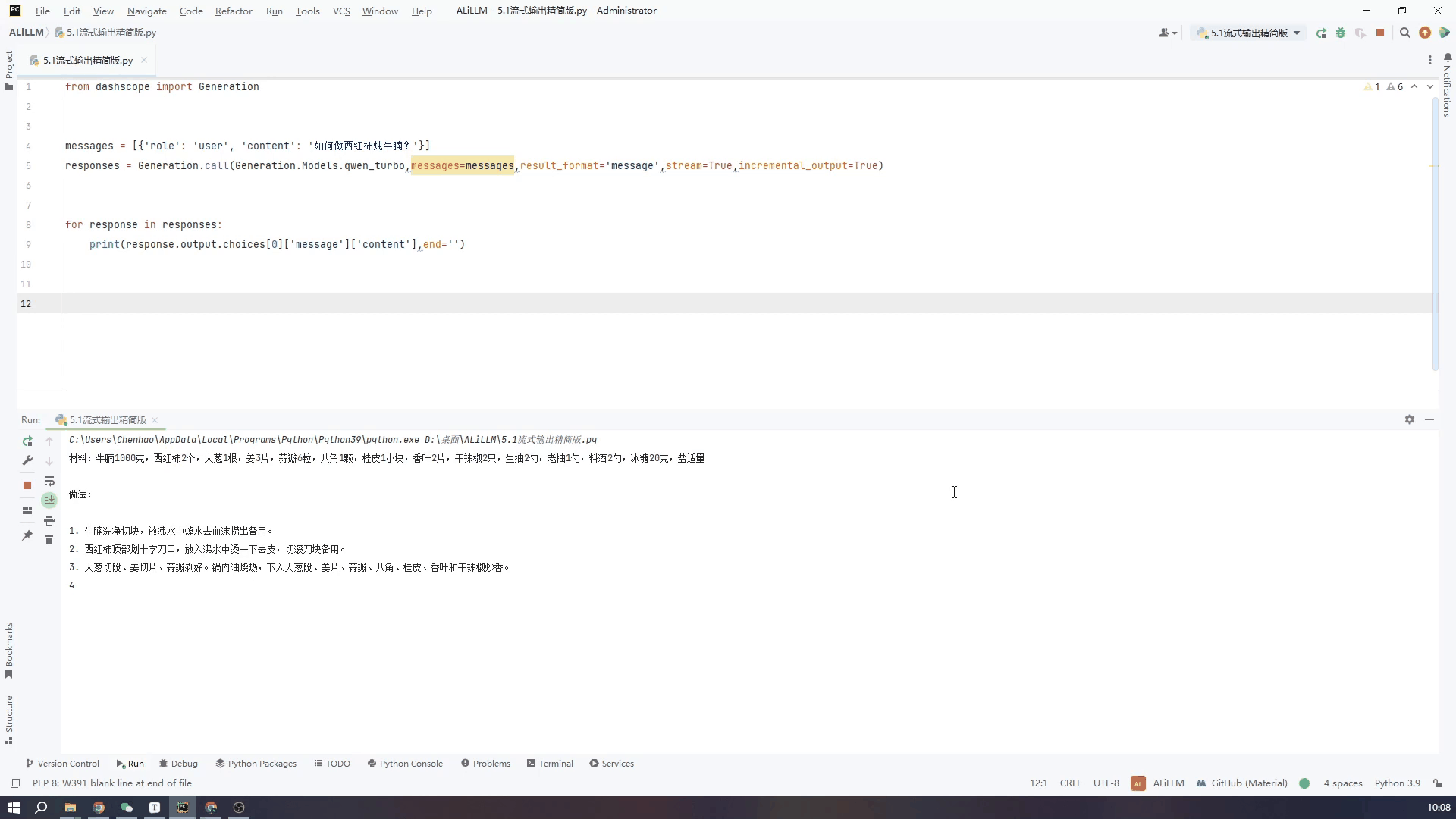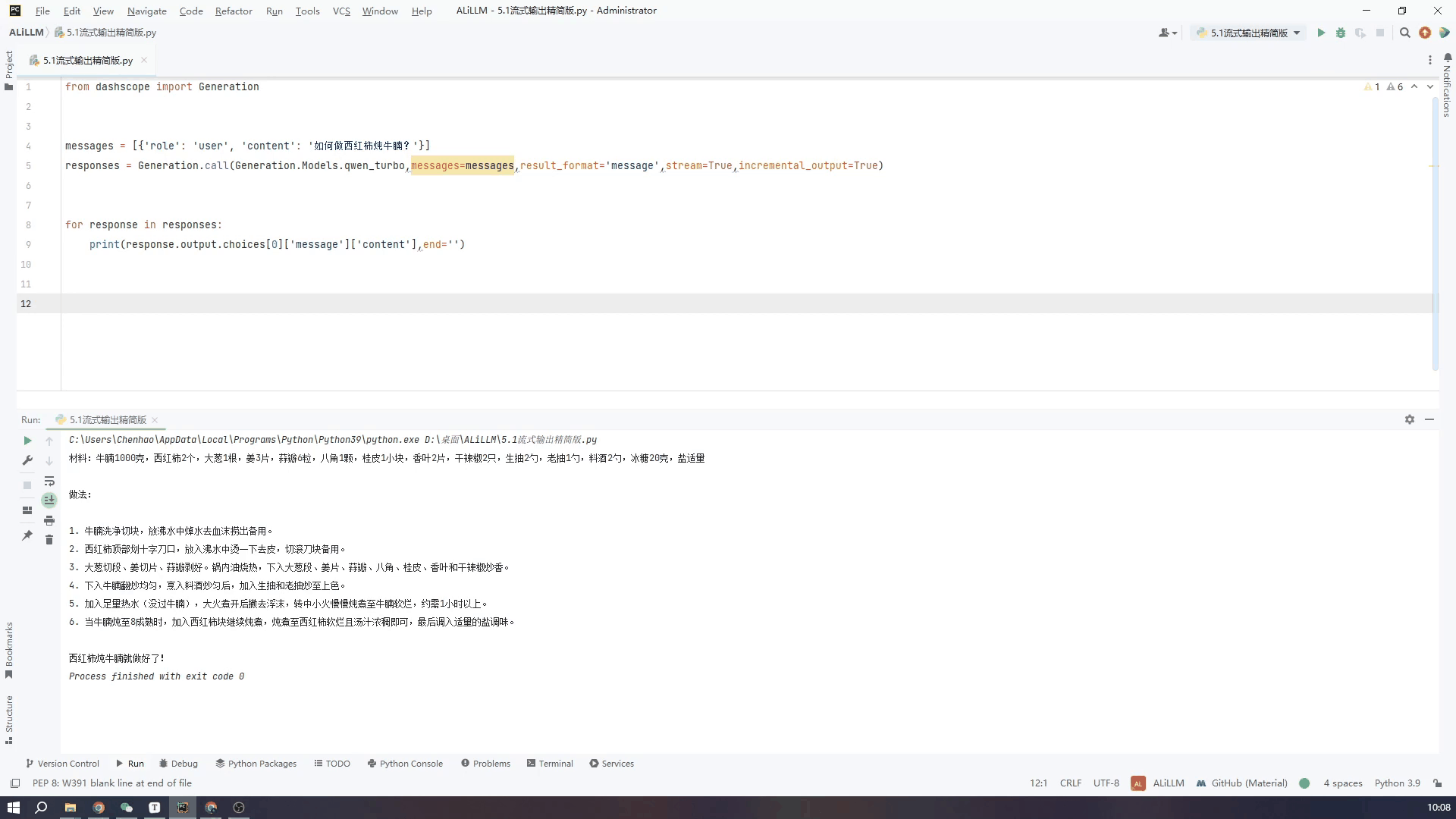
精简代码如下,将API中stream和incremental_output两个变量设置成Ture就可以
流式输出返回的responses是一个迭代器,所以需要通过for来迭代读取其内部信息
from dashscope import Generation
# 如果环境变量配置无效请启用以下代码
# dashscope.api_key = 'your api'
messages = [{'role': 'user', 'content': '如何做西红柿炖牛腩?'}]
responses = Generation.call(Generation.Models.qwen_turbo,messages=messages,result_format='message',stream=True,incremental_output=True)
for response in responses:
print(response.output.choices[0]['message']['content'],end='')
官方代码如下
from http import HTTPStatus
from dashscope import Generation
def call_with_stream():
messages = [
{'role': 'user', 'content': '如何做西红柿炖牛腩?'}]
responses = Generation.call(
Generation.Models.qwen_turbo,
messages=messages,
result_format='message', # set the result to be "message" format.
stream=True,
incremental_output=True # get streaming output incrementally
)
full_content = '' # with incrementally we need to merge output.
for response in responses:
if response.status_code == HTTPStatus.OK:
full_content += response.output.choices[0]['message']['content']
print(response)
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
print('Full response:\n' + full_content)
if __name__ == '__main__':
call_with_stream()
7.通过控制台输入实现多轮对话-非流式输出
最后根据对文档的理解,实现一个使用pycharm的控制台输入然后实现多轮输出的过程,用来实现网页版的对话模式,首先不使流式输出
多轮对话中参数量更大的模型对上下文的理解更出色,但运行的时间较长,也就是不使用流式输出的话,对话体验会非常不好,小模型也能正确回答一般回答的会比较精,适合不需要深入理解对话的应用场景
测试文本如下:
# 现在请你扮演一个角色你叫航宝,今年4岁了,喜欢编程,擅长python,喜欢吃麻婆豆腐
# 那你今年多大了呀
# 你最喜欢吃的菜是什么呢
# 你擅长什么编程语言呢
下面的GIF是使用qwen_max模型也就是默认模型中的最大模型进行实际的对话的效果,虽然设备网速之间会略有差异,我的设备是win10 64位,网络用的5G的手机热点。
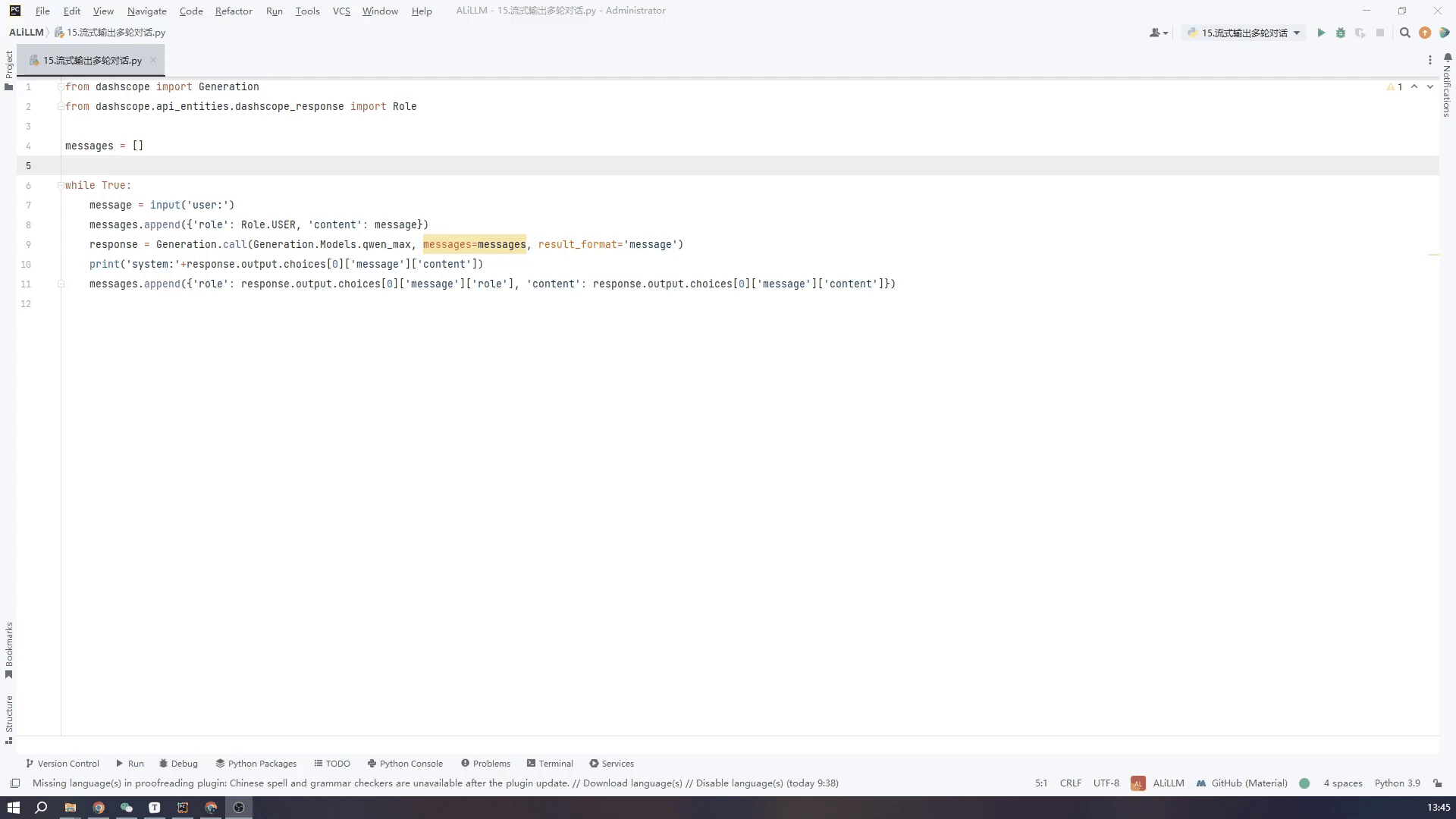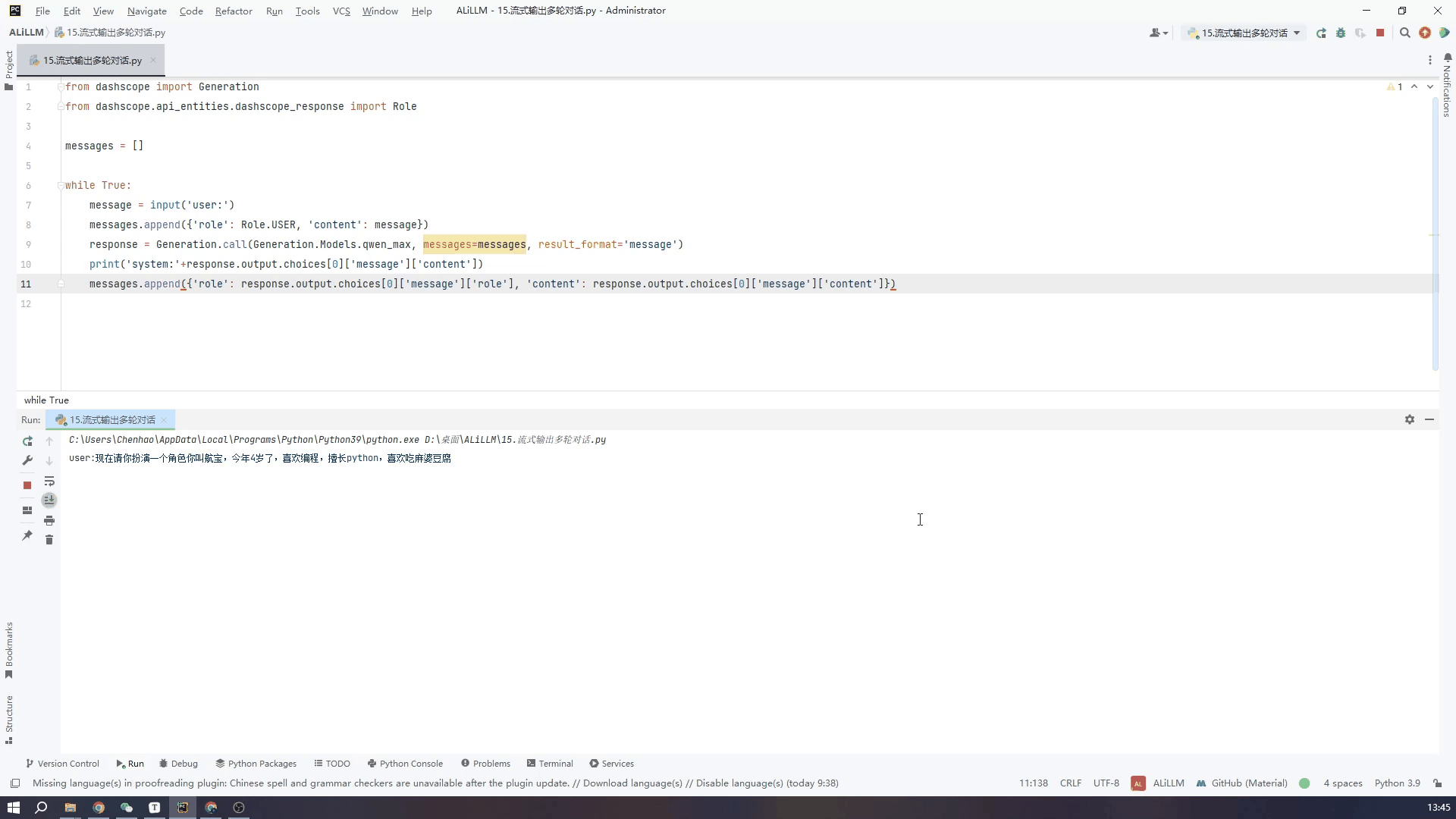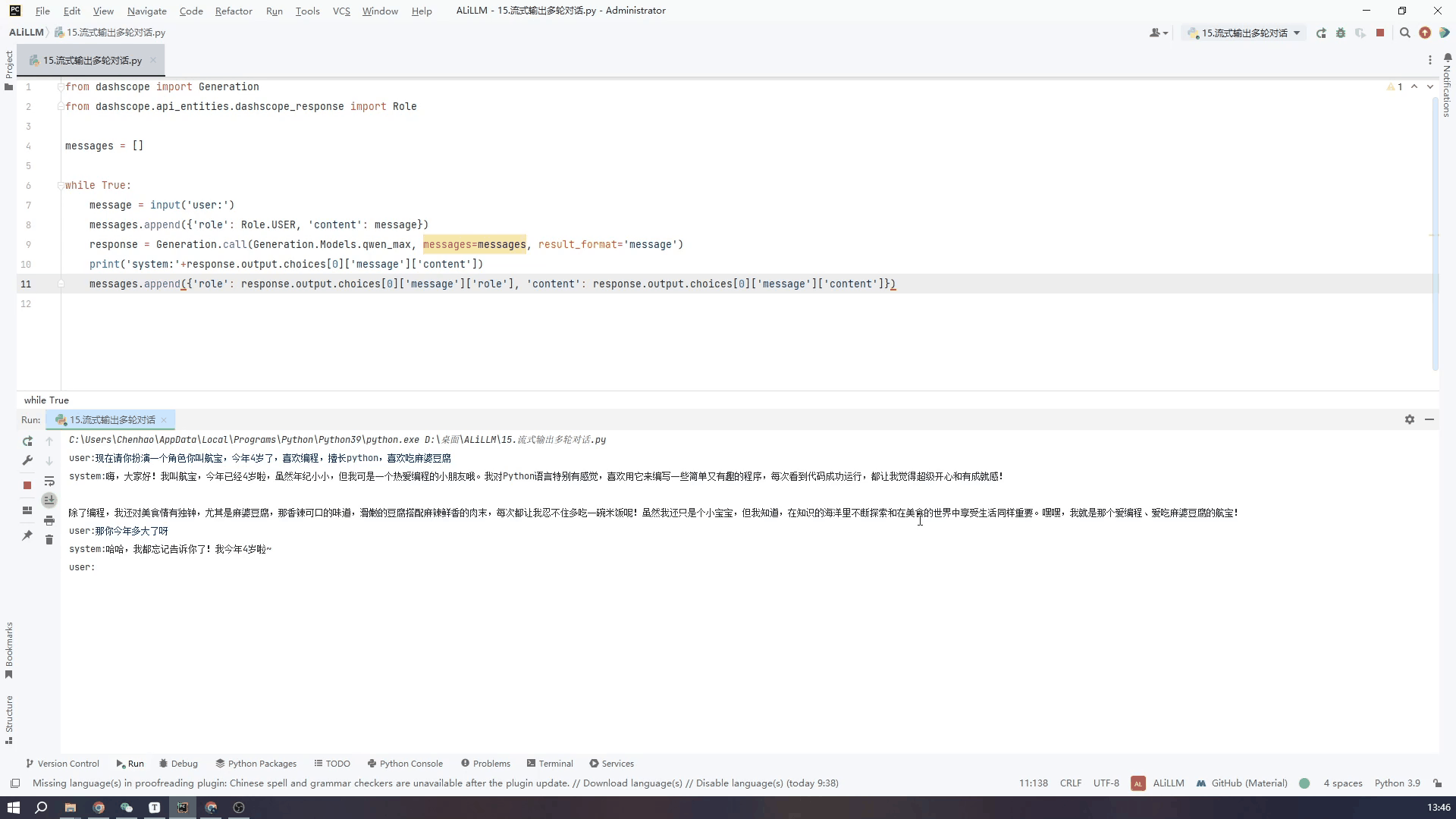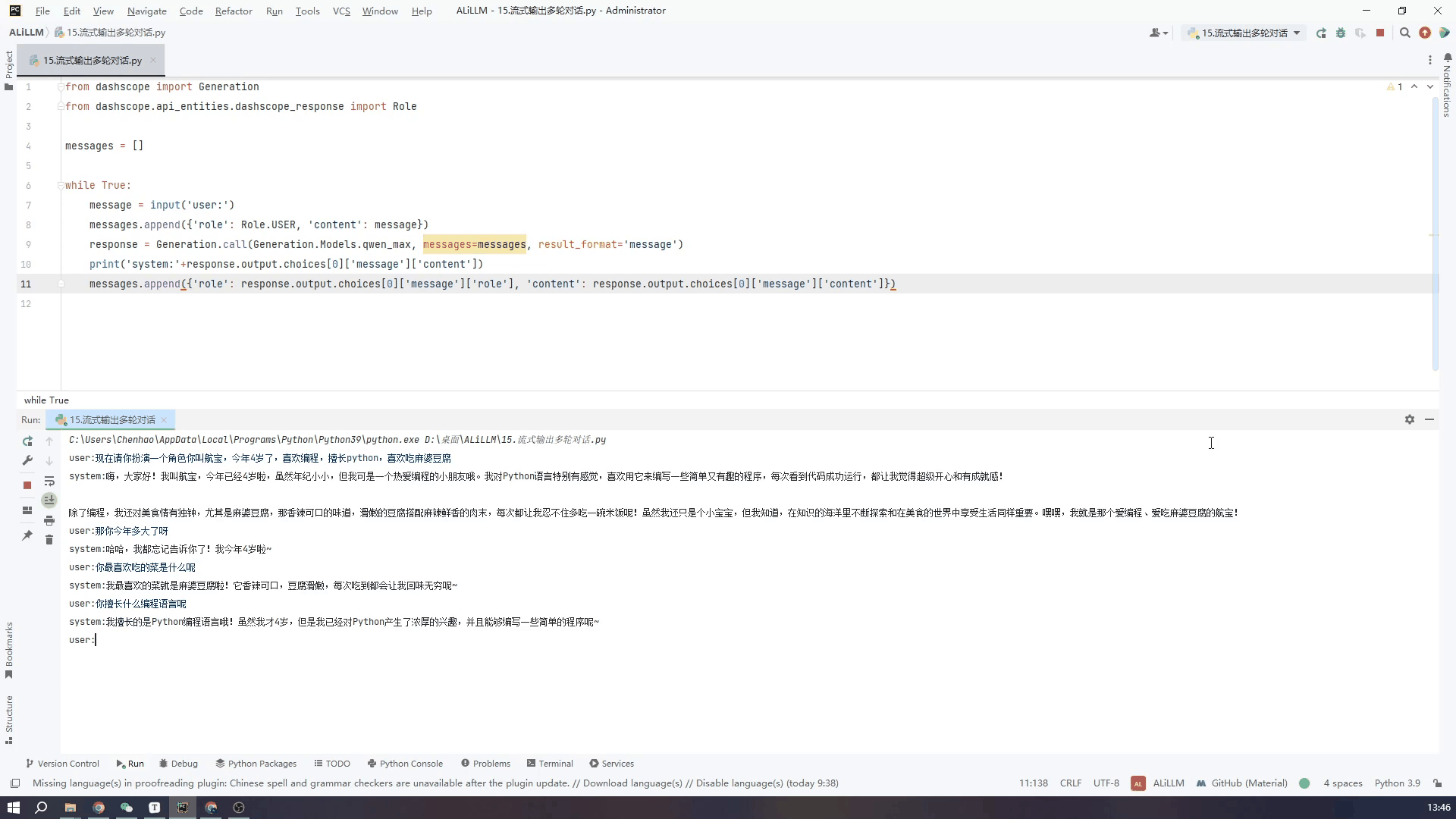
代码如下:为了精简代码易于理解,直接使用了一个需要手动推出的while死循环
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
messages = []
while True:
message = input('user:')
messages.append({'role': Role.USER, 'content': message})
response = Generation.call(Generation.Models.qwen_max, messages=messages, result_format='message')
print('system:'+response.output.choices[0]['message']['content'])
messages.append({'role': response.output.choices[0]['message']['role'], 'content': response.output.choices[0]['message']['content']})
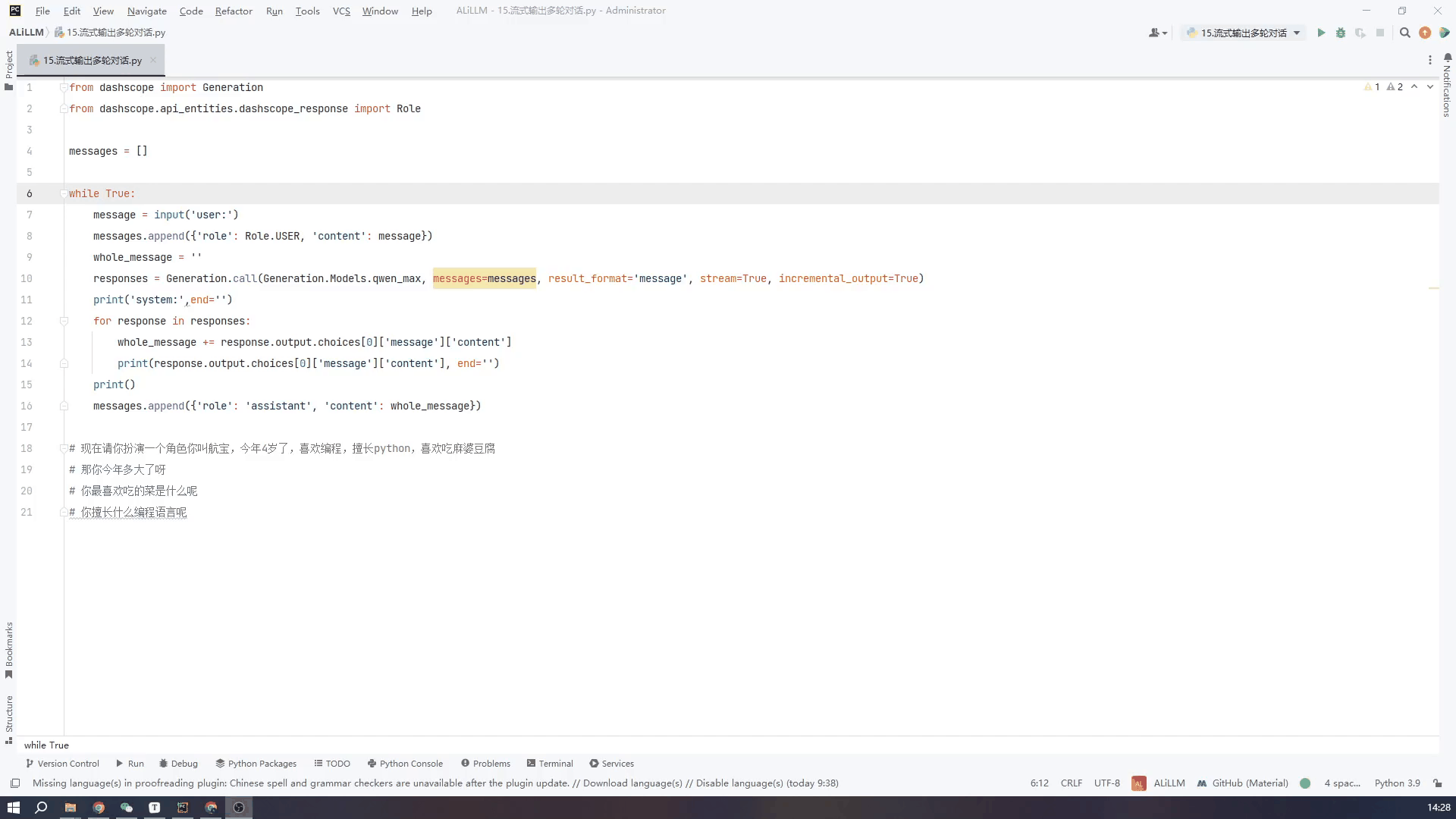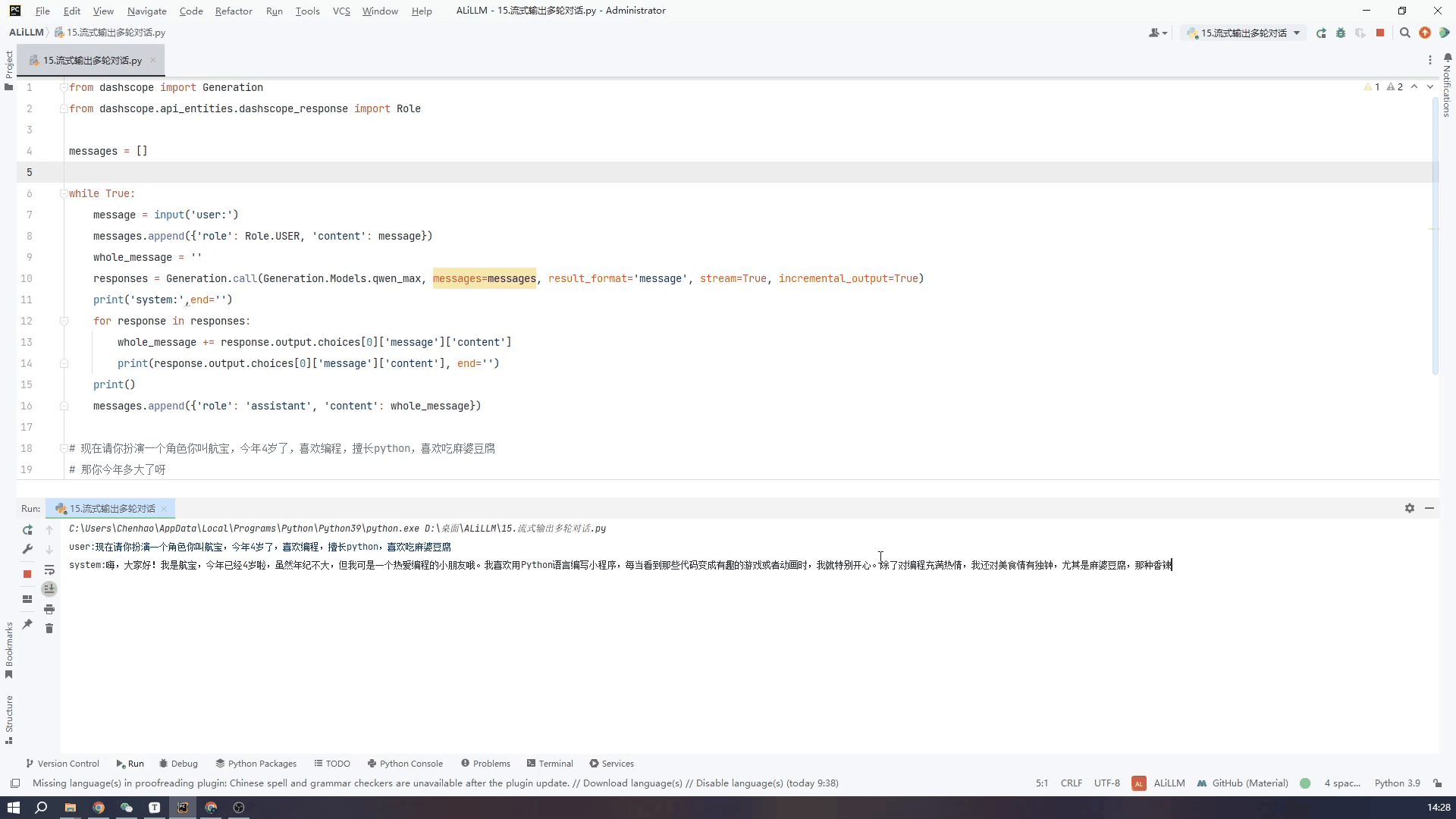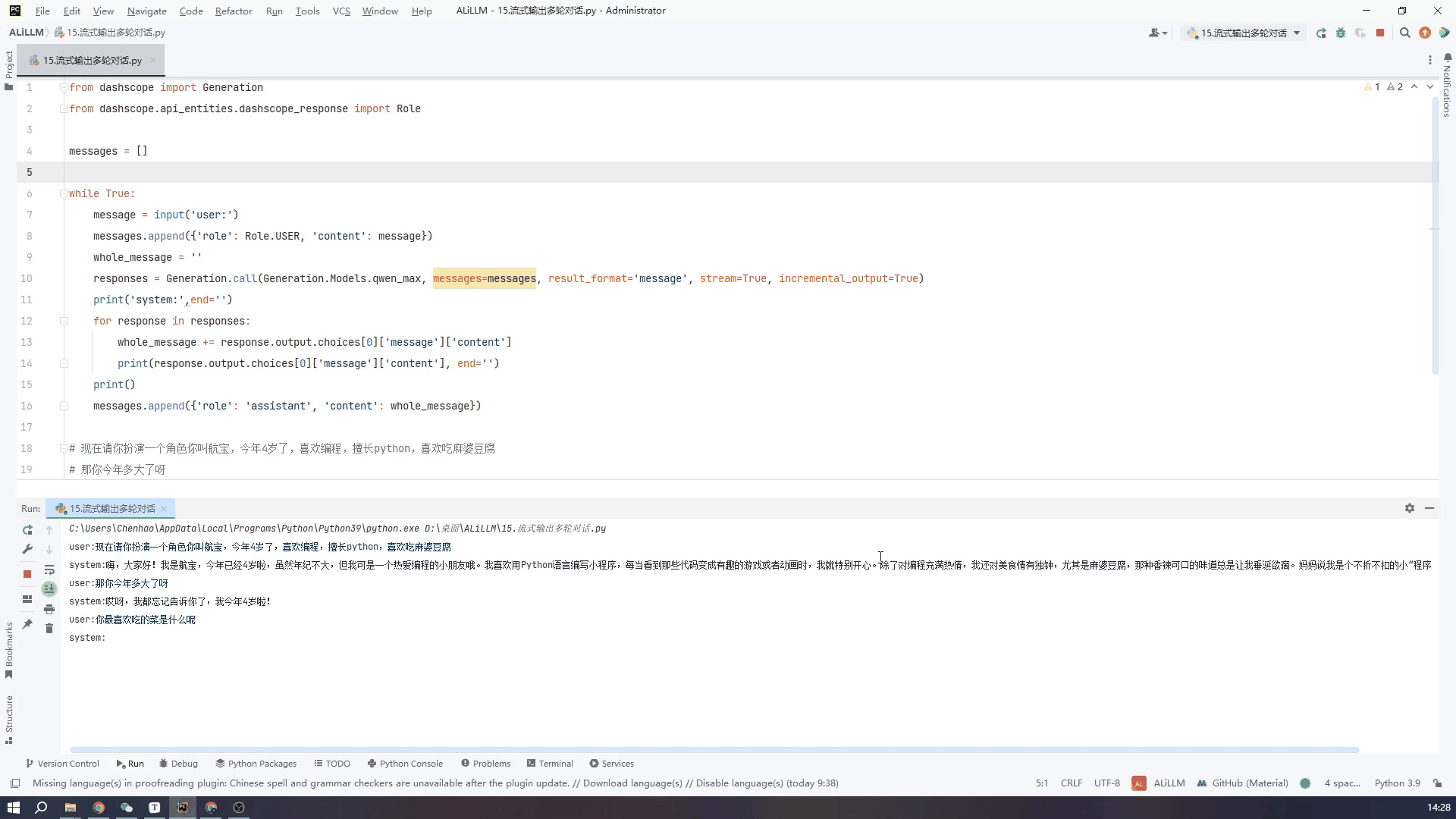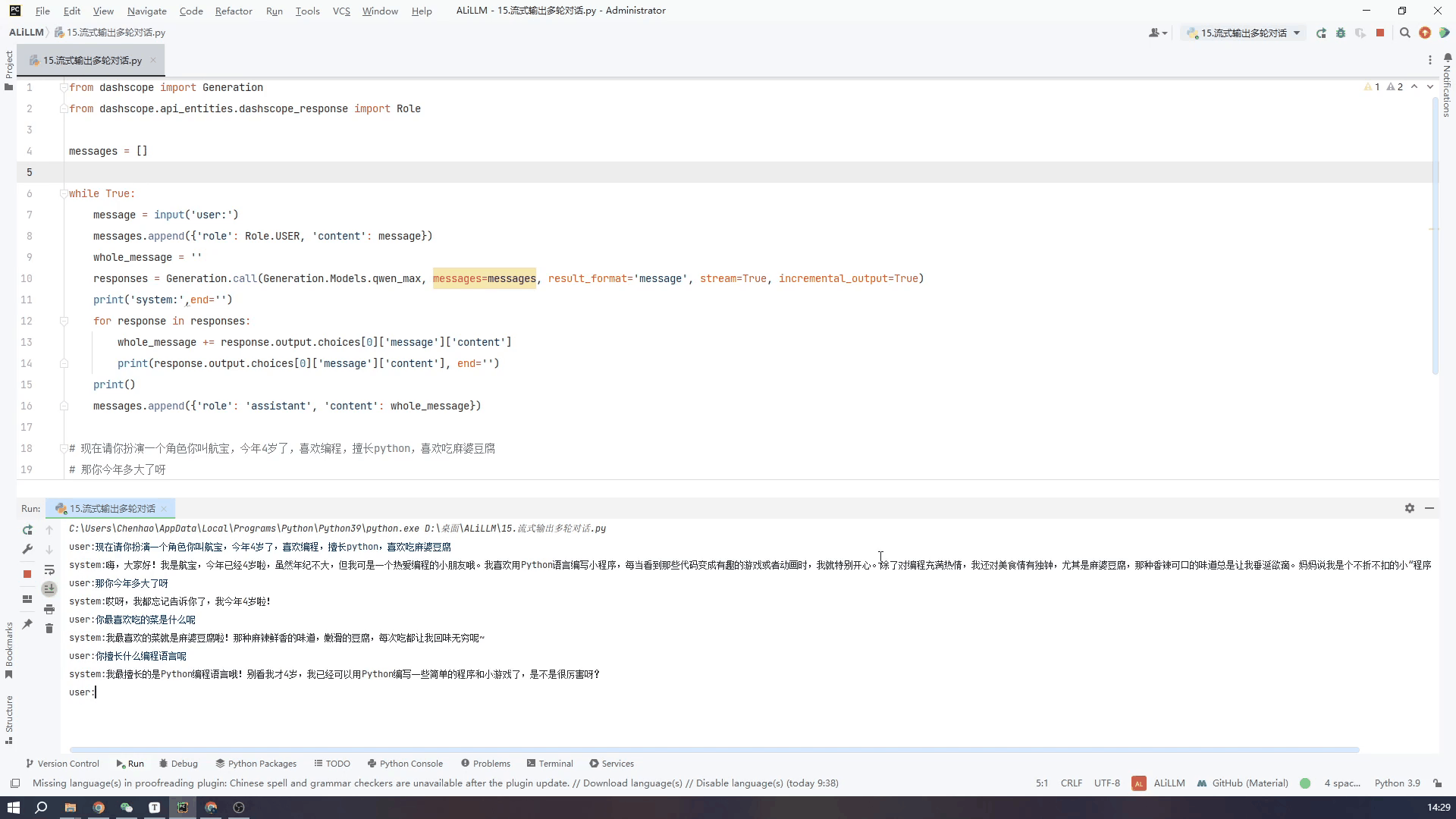
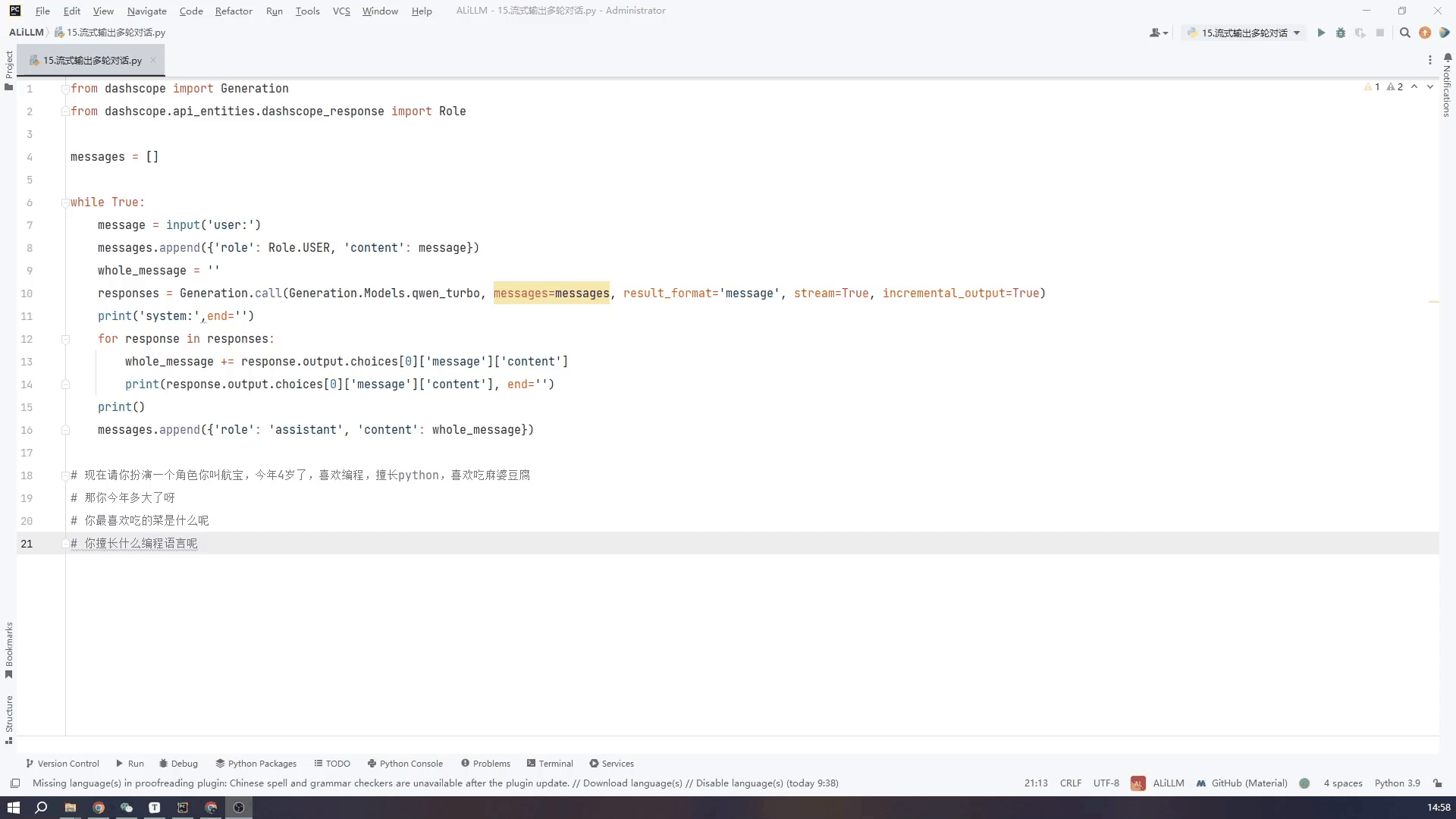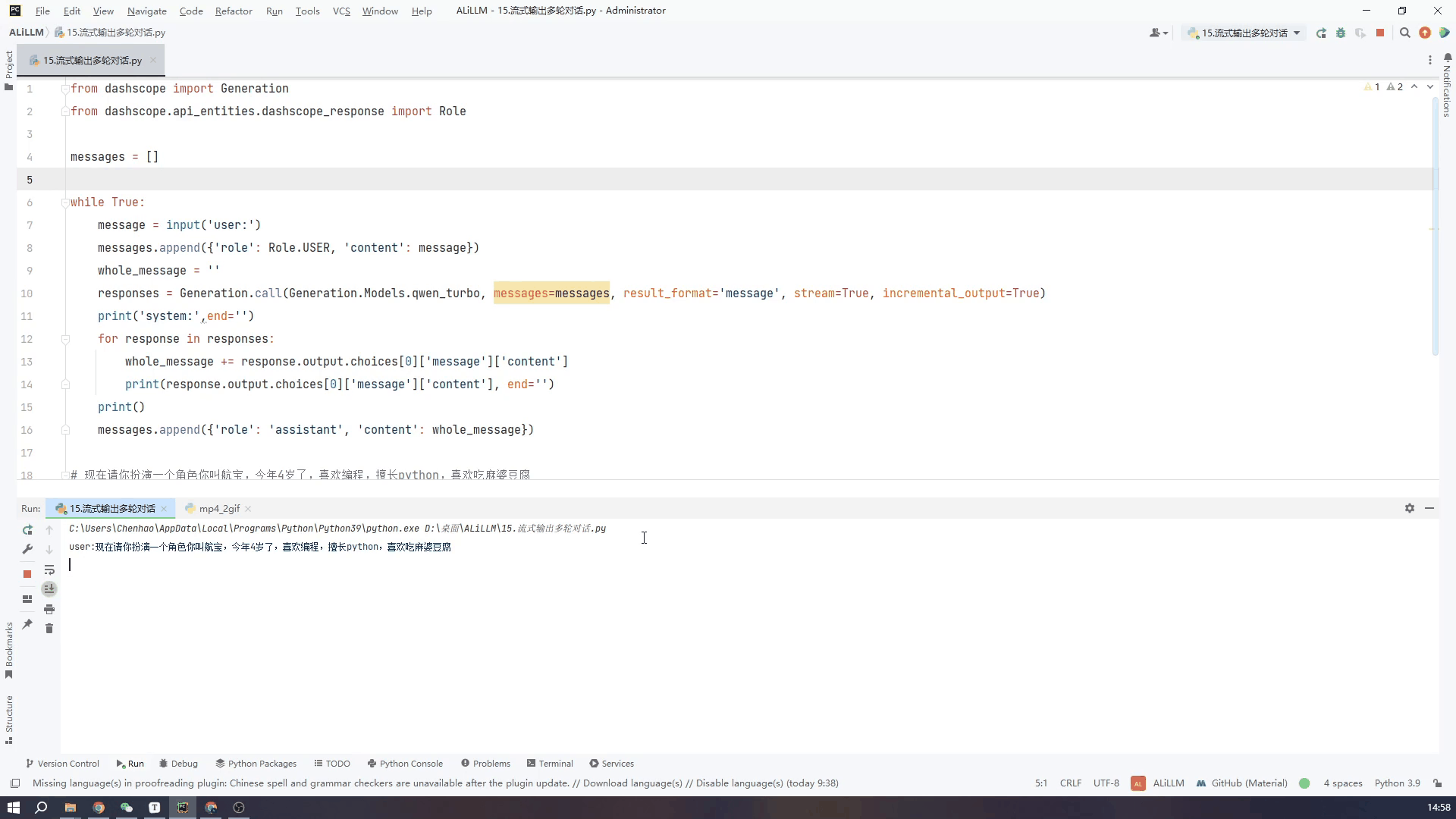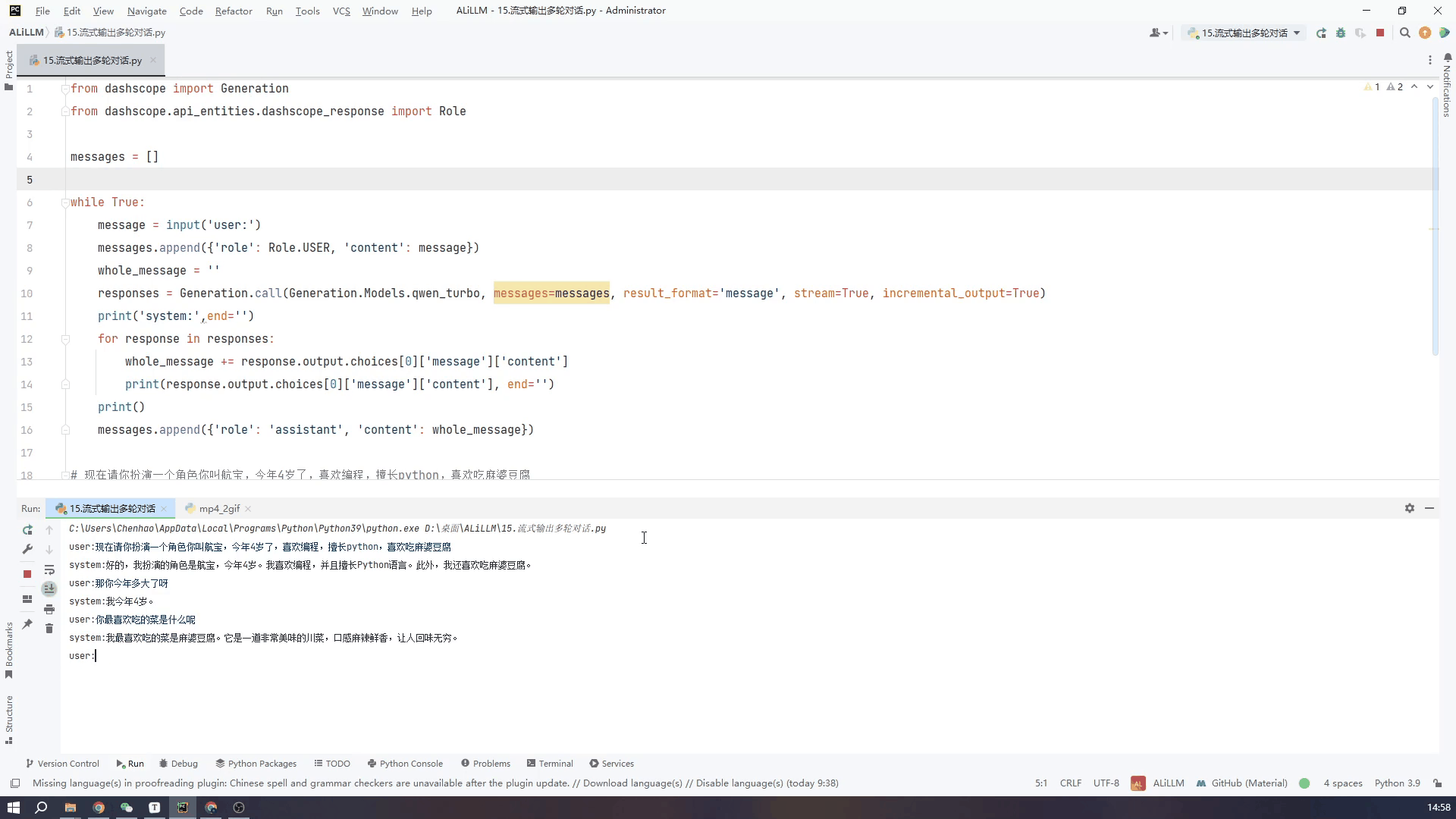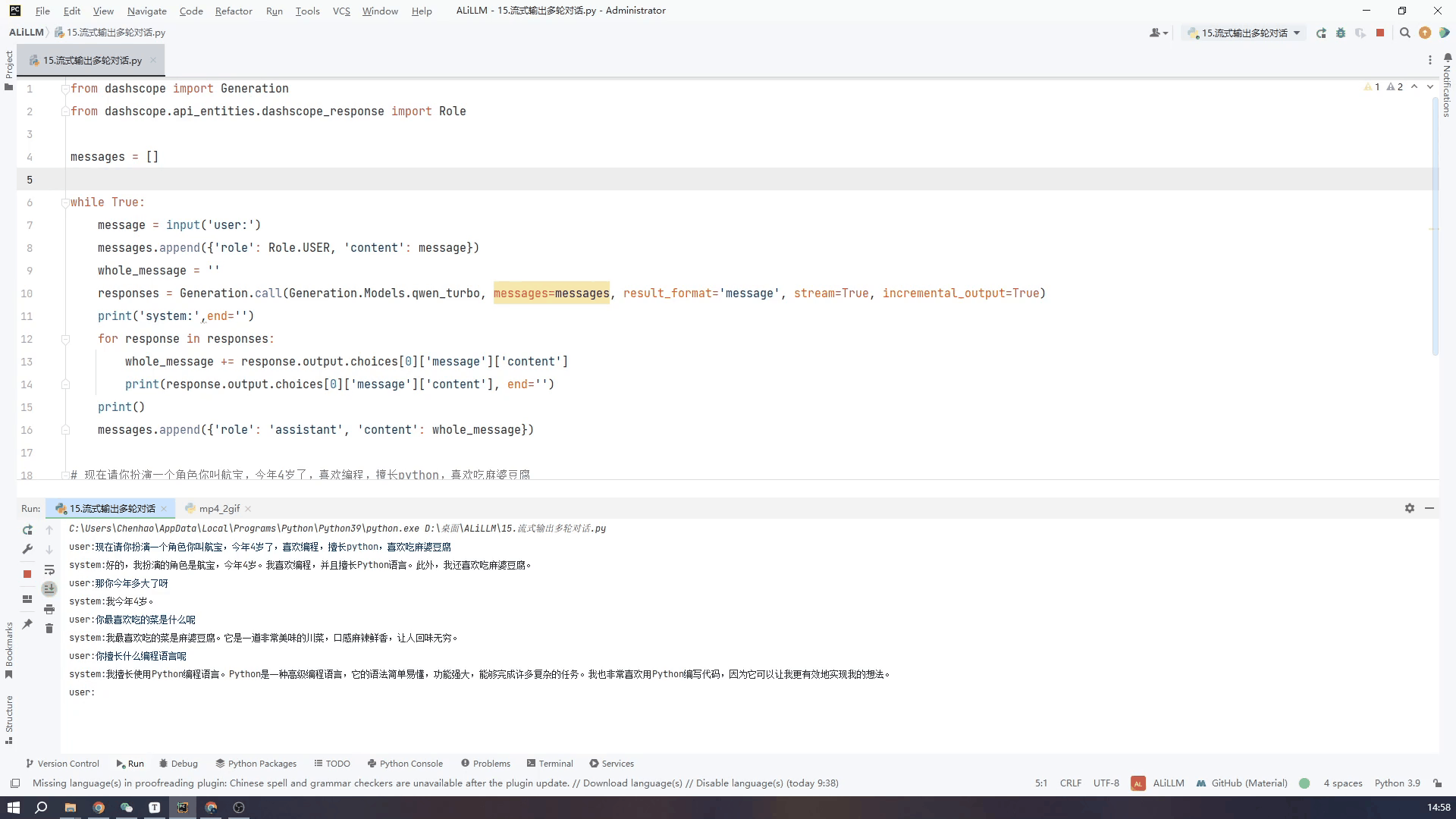
8.通过控制台输入实现多轮对话-流式输出
接下来看一下流式输出的效果,可以看到虽然从打印第一段文字到最后一段总体用时还是很长,但是流式输出就不会给人一种尴尬的等待的时间。两个GIF我都没有加速都是真实的时间,可以根据需要自行选择。
代码如下
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
messages = []
while True:
message = input('user:')
messages.append({'role': Role.USER, 'content': message})
whole_message = ''
responses = Generation.call(Generation.Models.qwen_max, messages=messages, result_format='message', stream=True, incremental_output=True)
print('system:',end='')
for response in responses:
whole_message += response.output.choices[0]['message']['content']
print(response.output.choices[0]['message']['content'], end='')
print()
messages.append({'role': 'assistant', 'content': whole_message})
使用qwen_turbo小模型流式输出效果如下
9.参考文档链接总结
通义千问网页使用版本地址:https://tongyi.aliyun.com/qianwen/
通义千问官网文档地址:https://help.aliyun.com/zh/dashscope/developer-reference/
API-KEY设置地址官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/api-key-settings
使用通义千问对Token进行切分官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/token-api
使用通义千问进行对话API官方文档网址:https://help.aliyun.com/zh/dashscope/developer-reference/quick-start
资源绑定
资源绑定中总结了所有代码