Pretrain Language Models预训练语言模型
content:
language modeling(语言模型知识)
pre-trained langue models(PLMs)(预训练的模型整体的一个分类)
fine-tuning approaches
- GPT and BERT(现在主流的基于fine-tuning的语言模型)
PLMs after BERT(BERT之后的语言模型)
applications of masked LM
- Cross-lingual and Cross-modal LM Pre-training(多语言以及跨模态的场景下的应用)
frontiers of PLMs
- GPT-3, T5 and MoE(预训练语言模型的前沿发展)
Review of Language Modeling
预训练语言模型,可以拆解一下这个问题,它就是对语言模型的一个预训练的一个过程,所以哦我们首先会看一下这个语言模型大概是一个什么样的情况。
我们快速地回顾一下这个语言模型,其实语言模型它定义非常简单,就是说我们给定一句话,我们回去预测这个,给定前面的词去预测下一个词,是词表中的哪一个word或者哪一个token,然后这个把它formulate一下的话,其实会是这样的一个条件概率,我们给定1到n-1个词去预测下一个词的概率,比如下面给了一个例子,这个正确答案应该是这个learn,这样的话是语言模型的基本的一个任务。
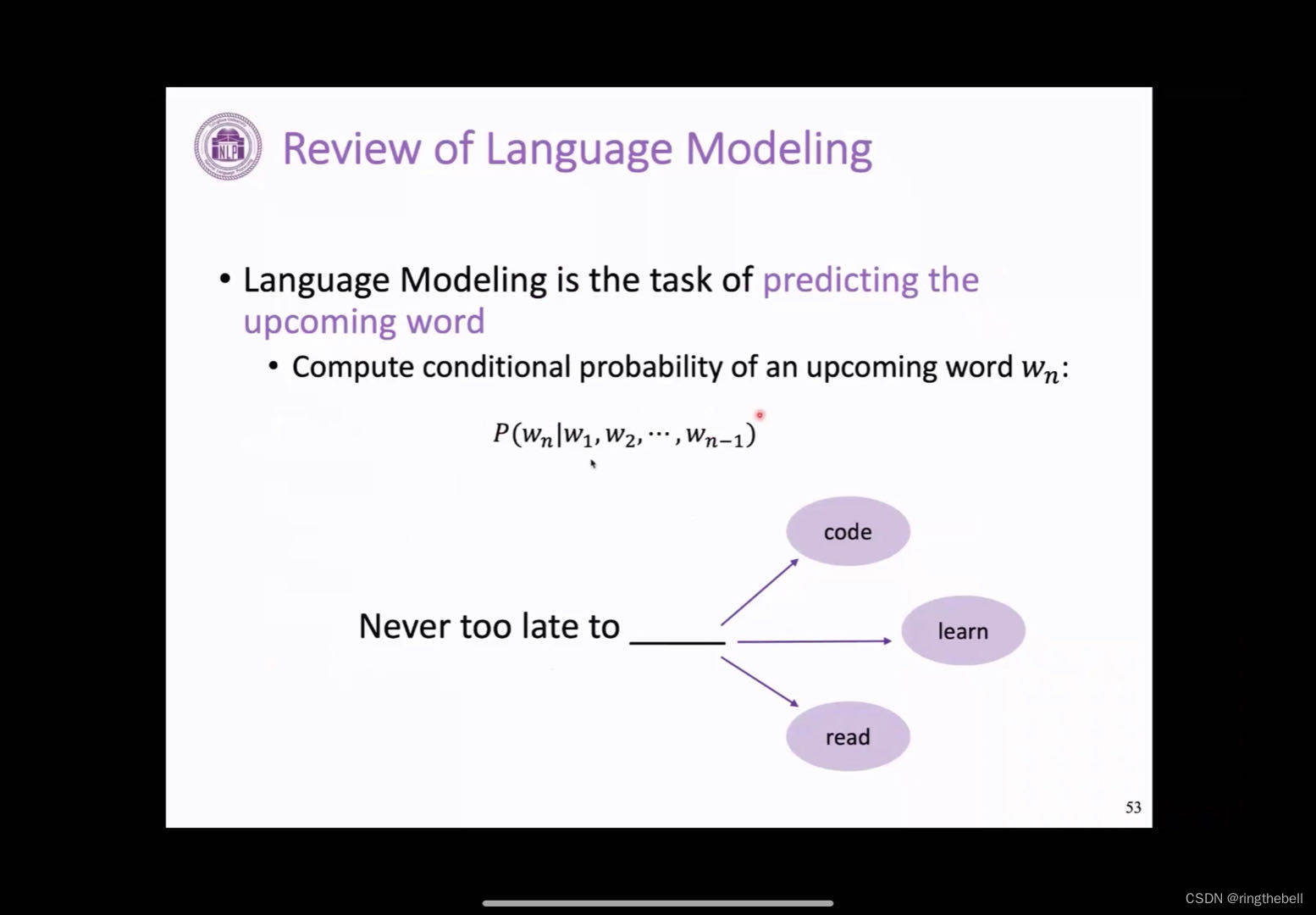
语言模型的形式其实是非常简单的,是一个最基础,并且最重要的这个NLP中的一个任务,为什么呢?因为它包含我们要完成一个好的语言模型,其实它这个模型需要学习到很多的知识来辅助这个语言的理解,比如它需要学习一些语言知识,一些句法以及词法的一些知识,以及一些其他的事实知识,比如说他要生成一个符合事实的文本,这样的话,对语言模型的要求其实是比较高的。其次,这种语言模型的训练方式,也是一个比较好的方式,因为它只需要这种纯文本的信息,就可以训练起来,它不需要更多的人工的标注,这也是语言模型为什么它非常基础,非常重要的一个原因。

语言模型在学习好之后,其实它不光可以完成这种给定前面的词去完成后面的词这样的一个补充,,其实它也可以很好地被迁移到各种各样的NLP的应用任务中,这也是为什么我们把它认为是一个非常核心的一个任务。
那其实发展到现在的话,历史上发展过出现过几种比较有代表性的语言模型,最早的是这个word2vec这种词向量的语言模型,后面的会出现基于循环神经网络的一些预训练RNN,到最近的话,就是基于一些transformer的训练。

我们会大概看一下这个发展的脉络:
最早其实是这个word2vec,在transformer预训练之前,其实基本上所有的NLP模型的输入,都是词向量作为输入,这个词向量其实作为一种语言模型,最早是由这个bengio提出,即我们根据前面的这个1到n-1个词或者是一个窗口,我们去预测下一个词,根据一个NLP去预测下一个词。word2vec它最大的贡献就是把这个过程变得非常地简单非常地高效,这样我们就可以在短时间内做大量的语料来学习一个比较好的预训练的词向量,这样它就可以作为这个下游任务各种NLP模型的一个输入。这是基于word2vec的这样一个语言模型。
再往后,我们就会有循环神经网络,一种更强的语言模型,针对这种循环神经网络也有相应的预训练的工作,只不过这个循环神经网络,它的可能模型上限不是特别地高,所以其实它的预训练模型并没有取得像处理像除了ElMo这样的模型之外的,特别好的效果。

在最近的,我们可以看到,19年以来,这个基于GPT或者BERT这样的预训练模型取得非常大的成功,它是基于transformer的语言模型。

以上是语言模型发展的脉络,每一个语言模型,它都在大规模语料上可以进行非常廉价易得的预训练,可以得到一个好的预训练语言模型来辅助各种的下游任务。
what are PLMs什么是预训练语言模型
预训练语言模型的优势就是,我们在语言模型的预训练之后,学习到的知识可以非常容易地迁移到各种下游任务,去提升下游任务的性能,我们看到这个word2vec是第一个预训练语言模型,现在的话,其实绝大部分的语言模型都是基于transformer encoder模型,比如Bert

整体来看,预训练模型可以大概分成两种范式,一种的话,它是作为一个feature的提取器,也就是说我们在这个大规模的语料上预训练好模型参数之后,我们就把它编码的表示,作为一个固定的feature,来交给下游的做具体任务的模型,作为一个预训练好的的输入,比较有代表性的就是word2vec,包括后面的RNN的预训练模型ElMo,也是这种思路,相当于是我们预训练的这个参数它是作为下游任务的一个输入。
还有另一种方式就是我们会对整个模型的参数来进行一个更新,这个最有代表性的就是BERT或者是GPT这样的模型,这种方法有更高的灵活性,因为我们整体的这个模型的参数都是在进行调整的,所以其实它的效果会比feature-beased这种方法会好很多,也是现在主流的方法。
记下来就会主要介绍基于fine-tuning的方式

Development of fine-tuning approaches基于fine-tuning的方式
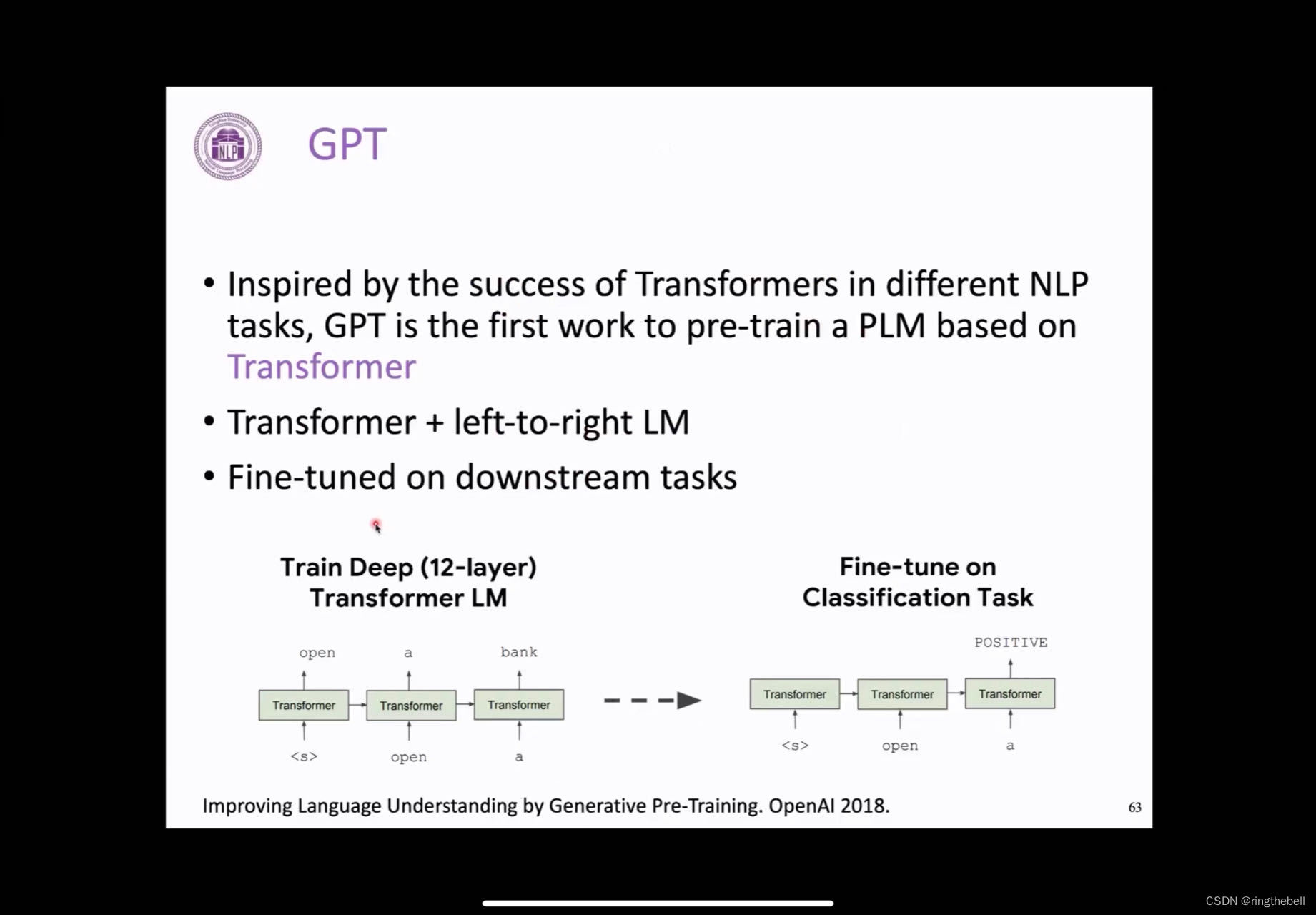
GPT
首先我们会介绍一下GPT,这个最早是在18年OpenAI提出的这个GPT,它的做法就是:他transformer的decoder,它只训练它的decoder,用自回归的方式去训练一个语言模型。其实它的这个方式非常简单,具体来讲,就是用了一个12层的transformer的一个decoder来自回归地去预测在这个无监督的这个文本语料上去训练一个语言模型,然后在下游任务的时候,他就可以通过这种方式,把整体的文本内容进行编码,最后去预测它,比如说这里做一个文本的分类。
以下是一代的GPT
在下一年,他提出了一个GPT-2的这样的一个工作,它比之前的第一代的GPT的最大的区别就是,他在很大程度上提升了transformer的参数量,训练累了不同规模的GPT的模型的大小,并且使用了更大规模的预训练的语料,在当时看来其实是非常大规模的40GB的文本。这样的话,他其实训练一个比较通用的这个语言模型,其实对于语言模型来讲,它的评价指标主要就是这个PPL,即:perplexities,在文本上的困惑度越低,代表这个语言模型对文本的流畅程度打分越好。
由于GPT-2有很大的参数规模,并且他见过很多的预训练语料,所以他在没有见过的这个文本上,他的PPL的效果也都是达到了稍大的水平,这个在当时看来非常具有前沿性的一个结果。

另外,GPT不光可以作为是一种比较好的语言模型,或者是可以在这个有表述的数据下做的效果比较好,这样的一个fine-tuning的模型,其实也具有非常好的一个zero-shot的能力,比如我们在这个语言模型下,可以实现很多种任务用语言模型的形式把它统一起来,这样可以做一个在没有任何标注数据的情况下来完成下游任务。

比如,做阅读理解,我们给定一个上下文,给定一个问题,然后提一个问题,然后说这个answer是什么,他其实就可以根据语言模型的形式去自回归地去生成答案,
比如,我们给定一个文章所有的完整内容,这其实是这个预训练语料中,一种比较常见的去做标记,文章太长,我们需要给一个简略地来讲是什么样的,它就可以自己自回归地去生成下面的一个一个摘要。
所以这种语言模型经过大规模的预训练之后,也有很强的zero-shot的能力

以下是定量报告了它的zero-shot的结果,我们可以看到两方面,第一方面的话就是,随着语言模型它的参数量逐渐增大,效果其实是会一致上升,第二点的话,其实这个zero-shot的结果,超过了很多但是有监督的模型的结果,这是一个令人非常印象深刻的一个结果。

所以,我们最后来总结一下GPT
GPT是一个非常强大的生成式模型,它在很多下游任务上取得了比较好的transfer的一个结果,比当时基于这种循环神经网络的预训练模型ElMo效果会好很多。他成功的关键在于两部分,一部分是,他见过非常多的预训练的数据;第二部分就是,它使用到了一个transformer的decoder,其实是一种能力非常强的深度神经网络,这两点结合来看的话,就是导致GPT效果非常好的一个原因。

然后在19年的时候就出现了BERT,其实BERT是NLP近些年里程碑式的一个工作,它现在是最受欢迎的,大家用的最多的一个语言模型,也是在19年获得了NAACL的best paper,它整体改变了一些,这个NLP现在研究的一个范式,也就是说大家现在基本上,如果首先就是预训练语言模型成为一个非常热门的一个研究的话题,在各种下游任务中,大家也会用到BERT来作为一个模型的基础架构来提升模型效果,所以这个是BERT的一个整体的情况,这篇文章的应用也在逐步增长。

然后我们来看一下BERT它解决了什么样的问题:
其实BERT之前最成功的预训练语言模型是GPT,它的一个方式是,从左到右地去自回归地去做这个预训练。对于语言理解,我们直观地会认为它是一个双向的一个过程,也就是说这个当前内容左边和右边的信息,对于我们理解内容都是很有帮助的,那为什么之前得GPT它是一个单向的过程呢?
可以认为是两点原因:
第一,我们首先会需要一个方向,来去自然地把一个长的文本拆解成一些小的部分,然后我们去逐渐生成他,相当于一个过程的拆解成
第二,我们如果把所有的内容都送到一个双向模型里面的话,这个会发生信息泄露

关于信息泄露,我们接下来会详细的看一下:
由于语言模型就是把一个长的文本拆解为一个一个的词,然后去逐步的生成他,所以这个是GPT一个天然的一个拆解过程,它其实在做这个语言生成的时候是非常适合的,但是在这样的单向理解下,它就会存在一些信息不足的问题。
另外,在一个双向的context下面的话,如果我们把比如这里有3个词,那我们把这个词全部都送到模型里面去,比如说在预测a这个词的时候,由于它在后面这个模型会见到这个词,并且它是双向的结构,也就是说它可以看到后面的这个词,那它在预测当前这个位置的时候,其实它就可以不做深度的学习以及推理,就可以很简单地通过这个short-cut就把答案预测出来,这样模型就学习不到一些有用的信息,所以这也是这个双向的一个天然的问题。

因此,BERT提出了一个解决方案:
我们可以做masked language model,即遮盖的语言模型,直观上,大家可以理解成是一个完形填空的过程,比如在一下例子中,它会随机地mask掉一些词,例子中它就随机采到了store和garden这两个词,然后把mask去掉,让模型去在最后一层还原出这个词到底是什么,这样的话,它并没有信息泄露的一个问题。
在BERT里它采用了随机mask掉百分之15的这样一个策略,来去做这种基于完形填空的这个语言模型的预训练。这个百分之15是怎么确定的呢?大概它也是一个trade off,就是两方面因素的一个综合考量,如果要是把mask的比例过低的话,那这个因为它总要整体去编码一次,然后在最后,真正模型有效的学习信号来自于mask这个masked token的一个监督,如果mask比例过低,那么受到的监督信号就会特别少,这样的话我们预训练一个模型就会需要非常长的时间才能预训练。另外,如果我们mask的比例特别大,那么这个文章中可以利用的信息就非常少了,比如mask掉百分之90的词,那其实有用的文本可能特别少,就不足以支持我们去还原出被mask的这个词。所以这个百分之15其实是综合这两部分因素最好的一个结果。

对于mask,它解决了信息泄露的问题
但mask本身也会带来一个非常严重的问题,即这个masked token它在下游任务的时候是不会出现的,比如说我们在做下游的阅读理解的时候,是天然不会有mask这样的一个token,它会造成预训练和fine-tuning阶段的一个非常大的差异,这样的差异可能会导致模型的效果会变差,具体来讲,模型它可能会学习到这样的一个现象:它只关注mask这个表示,因为其他正常的它认为都是作为一些上下文出现的,它预训练的时候,就是要把mask的词还原好,这样这个模型就可能会觉得比较偏,那这个BERT提出的一个策略,就是我们在这个百分之十五mask的时候,我们去再细分成几种子类型去处理。
百分之八十的时间我们去把它替换成mask,接下来他会在百分之十的这个时间里去随机地以百分之十的几率,去替换成一个随机的词,比如这里面的went to the store,它就可以把这离的store替换成running,然后他去要求这个running去预测出这个store这个词,这样的话其实,他这个模型就会要求模型也去关注那些看起来不是mask的词,去维持一个比较好的表示,但这样其实简单地这样做也会带来问题:
这样的模型会认为现实中出现的这个词都是错的,所以它其实还会有一个额外的补充策略,就是他有百分之10的概率都会去把这个词序保持正常,即不变,相当于是store要预测出store,这样的话通过这三种mask策略的这个叠加它就会去解决这个mask带来的一个预训练和fine-tuning阶段的一个差异问题。

BERT最主要的预训练任务就是masked language model,是它最核心的一个预训练任务,此外也提出了另外的一个预训练任务,就是怎么去更好地利用大规模无监督语料中的这个句子间的信号。像大家可以理解为这个masked language model,是一个词和词之间它的这个一种条件的概率,而这个next sentence prediction即,上下句的这种预测,它利用到的是它学习到的是句子之间的这种关系,这个方式也非常地简单,也就是说我们文本中有很多相邻的这种句子,然后如果我们采样到两个相邻的句子,它的标签就是连续的,那如果要是我去随机地采样两句话,它不相邻,它就这个标签是不相邻,它要求模型去做这样的一个判断。

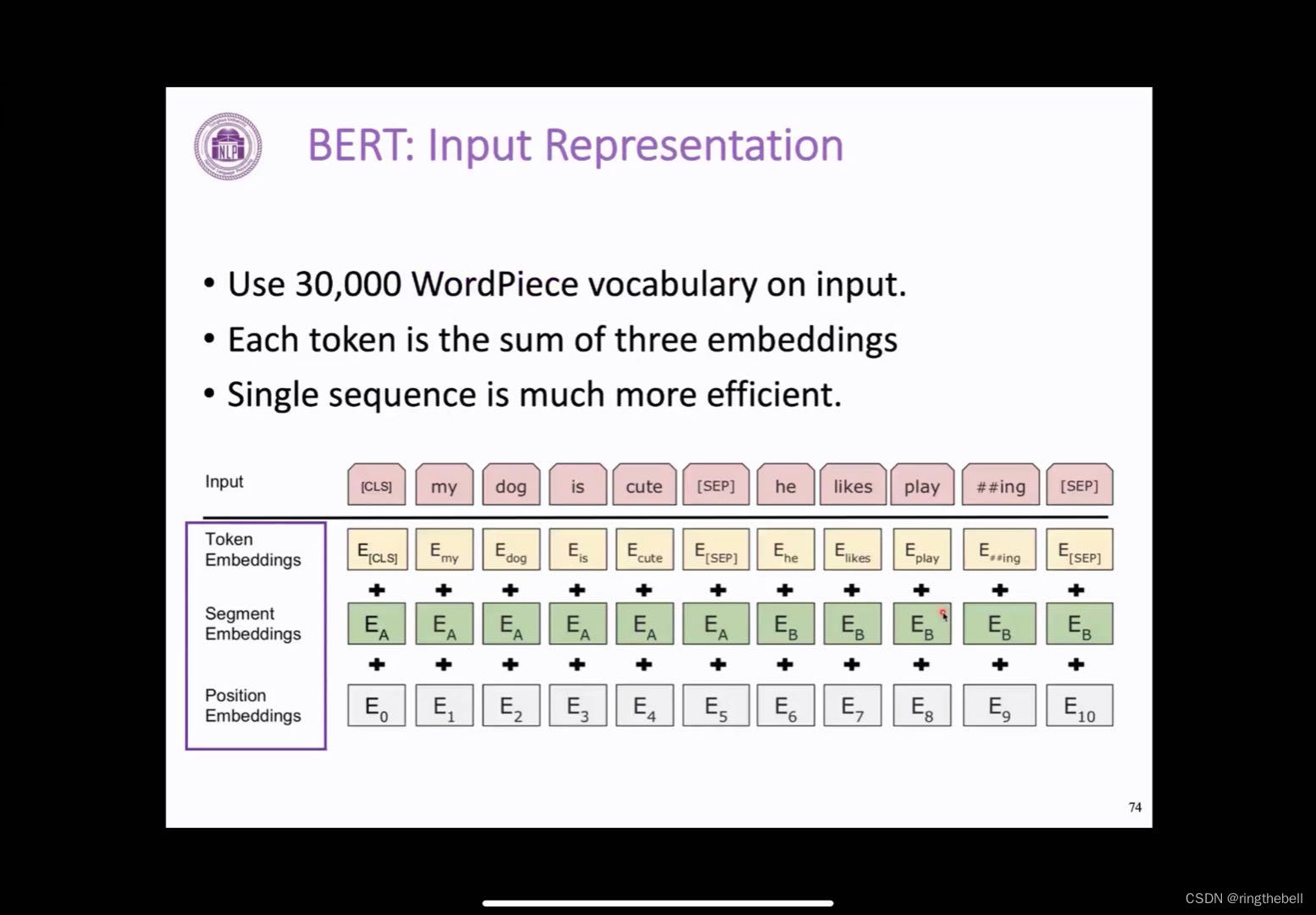
关于BERT的输入表示,其实BERT和transformer相比,BERT整体上是基于transformer 的encoder的一个预训练模型,transformer的每一层的layer其实都是复用的transformer的layer没有太大变化,它在输入的方面做了一些微小的调整,它最终的输入最早其实是一个CLS,是一个没有特别意义的token,其定位即会把所有的输入信息集中到这里,来支持下游的一些,比如说句子分类,一些整体表示的一个任务,一个表示的位置,之后它通常会接受几段的输入,中间会有一个特殊字符sep去分开不同的文本段,最后还是一个sep表示这个文本结束。那每一部分的token,它表示的是怎么得到的呢?
(CLS是“Command Language System”,即命令语言。指的是一种可以通过命令来操作计算机的软件或语言)
会分为三部分的相加,第一部分就是token embedding,它采用的是word piece这种分词方式,word piece和刚刚介绍的BPE,其实都是一种data driven的一种数据切分方式;第二个就是,他会引入一个segment embedding,就是表示这个文本段是第一个文本还是第二个文本段,这个在下游任务中其实也有一些应用的方式,比如说这个QA,这个有问题,又上下文,它就用这种segment embedding去区分,在预训练的时候,它表示区分的是,是否相邻的两句话,把它区分开;第三部分的话就是positional embedding,也就是刚刚提到的正弦余弦函数的这一部分,其实在BERT里它的处理是更加直观更加简单的,就是他会预定以512个这样的position token,然后它是随机初始化的,它随着训练的时候去学习到每个token的表示,但是也是由于它实际只预训练了512个position embedding,所以它只能最大处理512的一个长度。
最后它会把这三部分都加起来,作为一个输入,以下是BERT的输入的一个表示情况
其实,BERT作为一个双向encoder的一个预训练,可以看到,它比之前的这个GPT有非常大幅度的提升,也比之前所有的这种预训练模型效果会好很多,在很大程度上接近了人类的表现,这个也就是说当时BERT引起非常大的关注的一个原因,一个预训练模型会比之前的效果会好很多,而且是在非常多的任务上都取得了非常明显的提升,这个是BERT取得了一个非常好的一个结果。
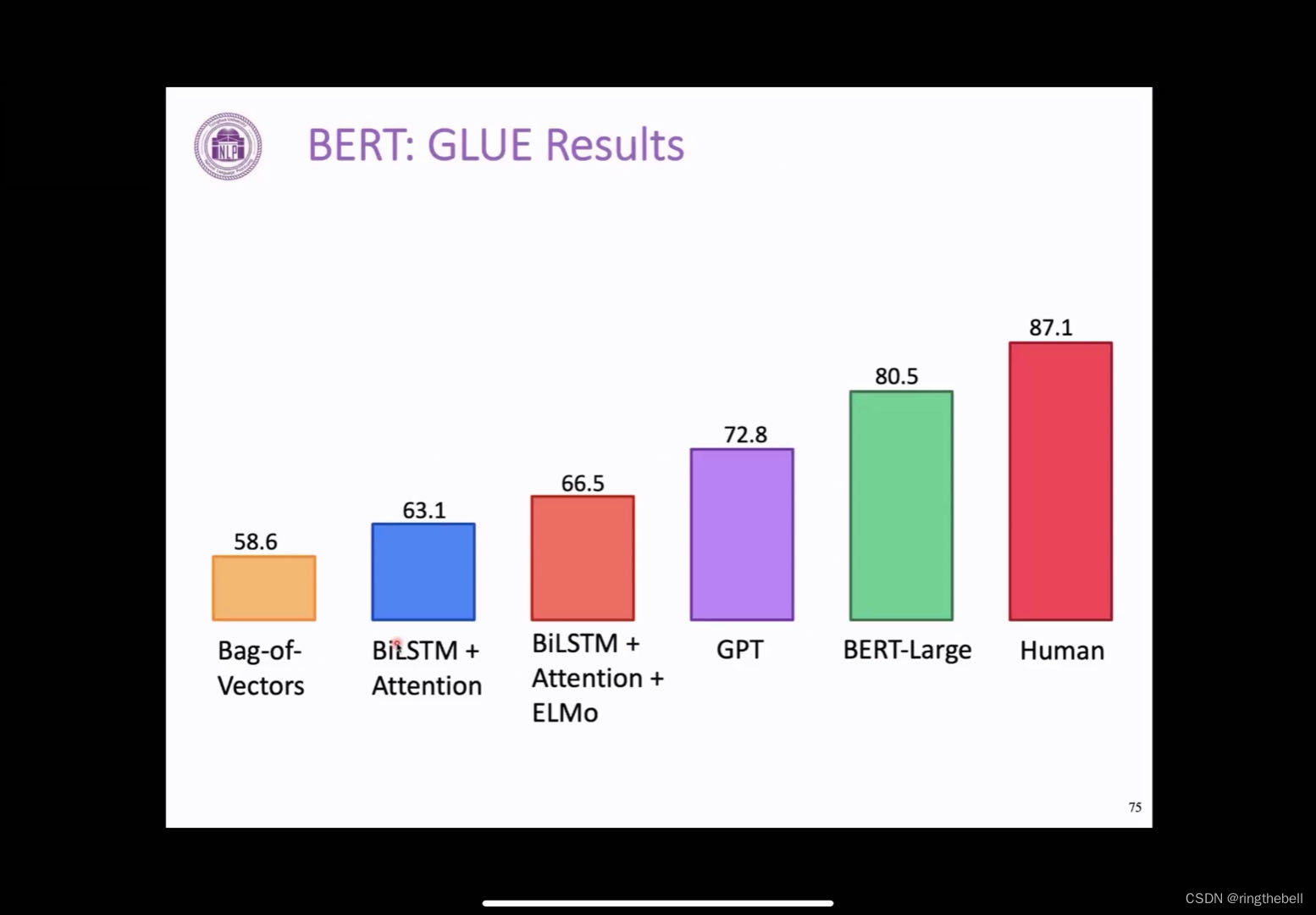
以下是BERT它的各种预训练任务的作用:
我们把这两个预训练中,最重要的两个预训练任务,即:masked LM 和 next sentence prediction来进行一个分析。
最左边的蓝线,其实是完整的BERT base的一个结果;黄线是类似于GPT的一个方式,即自回归地从左到右去生成,用生成方式去做这个预训练。
可以看到在非常多的任务上都表明,这两者有很大的区别,这也就是在这个理解任务中,考虑到双向上下文的这样的一个好处。
对于next sentence prediction的话,它的作用不是特别地明确,在有任务下,比如说这个红色的线,他和蓝色的线差别不是很大,但在有些任务上,它的效果会差距比较明显。
其实对于next person prediction这个任务,它的作用在后面很多工作,也都有一些争议。但masked language model这个任务,在后面大家都一直保留,相当于是BERT最核心的一个任务,也是一直被沿用的一个预训练任务。

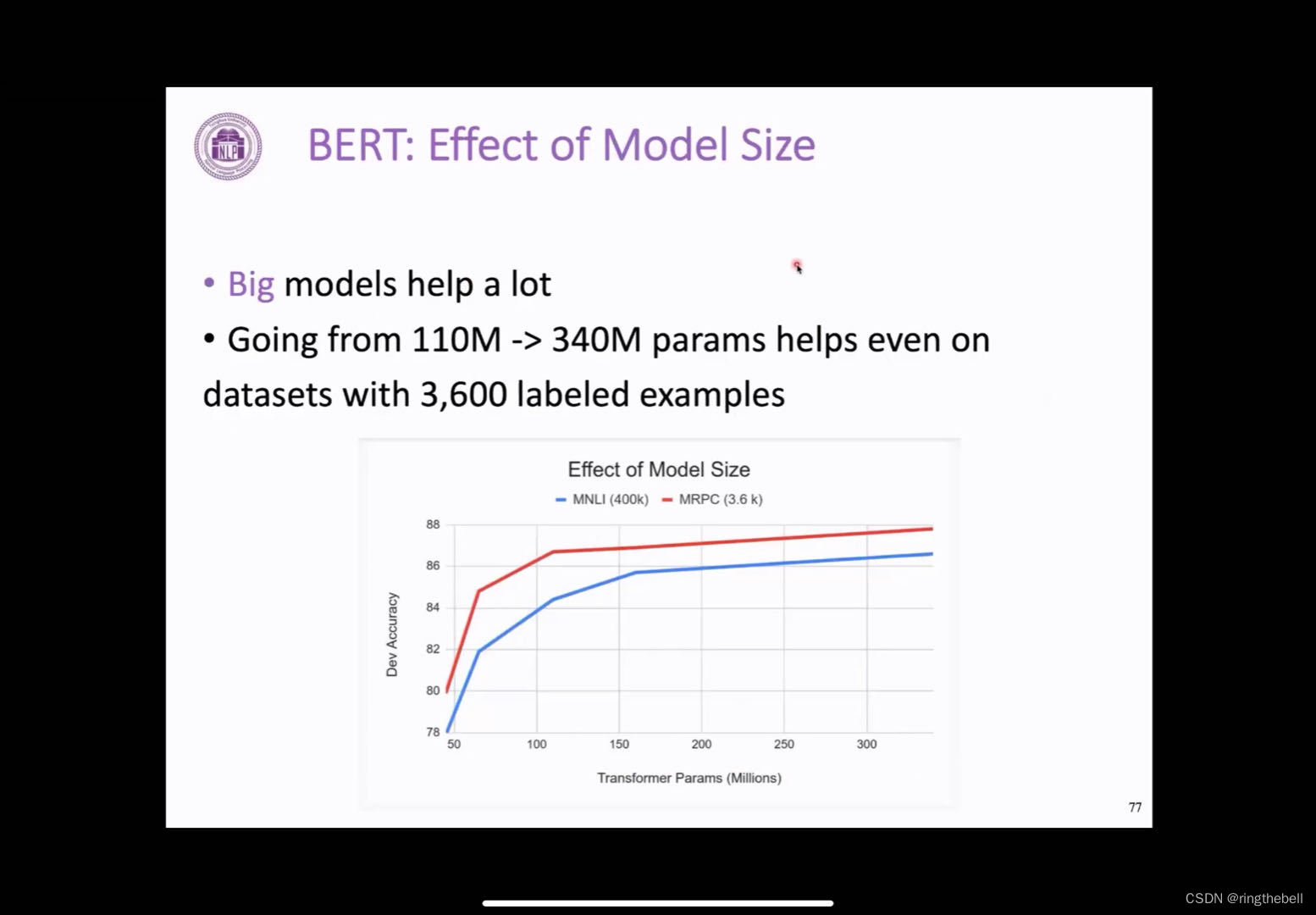
以下是一个非常重要的分析,即这个BERT它的效果随着模型大小的变化,我们之前在GPT
的实验中,看到GPT它的这个效果随着模型参数增大其实会一直上升。BERT也观察到了这个类似的结果。我们可以看到,从110兆到340兆的模型参数下,这个BERT的效果其实是会一直提升的,而且是在不同资源的下游任务下,比如这个MNLI,他有400k的标注数据,然后MRPC的话,它的标注数据可能会比较少,都是可以看的一个直观的非常一致的提升。
BERT的总结:
它的empirical的结果即实证的结果是很好的,这个其实是我们关注他的一个原因,但是包括GPT和BERT,它对NLP这个领域最大的影响之一就是,模型越大效果几乎越好,目前没有看到一个明显的上界,这个也启发我们,把模型倾向于越做越大,我们会得到一个越来越好的结果,因此,现在很多研究都是围绕大模型这个角度来展开,这是GPT和BERT给大家带来的一个新的思考方式,这样好的效果也成为很多研究者和公司去构造他们自己的NLP系统,作为一个非常基础的工具,就是你可以去简单地去用GPT或者BERT作为你的encoder或者decoder,就可以得到非常好的效果,这也是他们为什么现在是最常用的工具的原因。

总结预训练语言模型这部分的内容,关于GPT和BERT:
我们会发现这个feature-based模型,其实它是给下游的任务提供了一个word embedding,或者有上下文的一个word embedding,这种方式的话,其实它固定地输入了feature,所以效果其实非常有限,我们这种基于fine-tuning能力把整个模型参数来在下游任务中做一个微调,这种方式其实是取得了一个非常好的效果,所以的话,其实现在的主要的研究也是基于这种fine-tuning的一个方式,最具有代表性的就是GPT和BERT。

在BERT之后有哪些工作尝试去改进BERT,一个就是我们可以思考下BERT其实它做出来很大的改进,但其实它也仍然存在着很多问题,那我们可以思考一下,他可能有哪些比较明显的问题。
第一个就是,它的预训练和下游任务可能会训在着一个比较大的gap,即,这个mask其实会是一个问题,BERT它采用的方式是一个混合的mask策略,也就是说,有的时候他会随机替换成其他策略,有的时候会不动,但这个方式的话其实并没有根本的解决这个问题,它这个mask在预训练中还是起着非常重要的角色,然后在下游任务中还是不会出现,所以这个问题仍然存在。另一个就是,它的预训练的效率其实是非常低的,即他每次只能去其中百分之15的词受到了有效的监督,其他的词都是作为无关的,不会收到监督的上下文来进行编码的,所以这个其实也会带来一个效率的问题,以及包括它在编码的过程中,它的窗口大小也受到了限制,最多只能处理512个词。我们会选几个比较有代表性的改进简单介绍一下。

第一个的话就是这个RoBERTa,它是BERT之后马上发布的一个工作,它主要的发现就是BERT还是一个没有完全被训练好没有完全收敛的一个模型,它探索了很多细节的一些改进,比如说在mask的时候,是不是要去动态的去mask它,然后以及这个next sentence prediction这个任务是否有必要存在,以及训练的时候,这个batch size是不是它开的更大会更好,其实这些改动都不是特别地大,是相当于一种比较系统的角度,去看看这个BERT在预训练的时候是不是比较鲁棒的,其实相当于它训练了一个更加稳定的,更加收敛的,更好的一个BERT,其实它就观察到了效果有非常明显的提升,之后做了很多的实现来证明了这一点。
RoBERTa也是现在大家非常常用的一个模型,整体来说,它的架构其实和BERT是几乎是一样的,但是由于它训练的更好,效果就会得到一个非常明显的提升。

对于一个结构上的改进的话,我们可以介绍一下ELECTRA,他也是非常具有代表性的一类预训练模型。
它解决的问题主要是说这个预训练的效率其实是不高的,也就是其实只有百分之15的词会得到预测,并且也有mask造成的gap的问题。在传统的比如说像GPT这种预训练模型中,其实所有的词,在这样一种单向的过程当中都会受到有效的监督,这个是BERT现在存在一个问题。ELECTRA它提出如何解决这个问题,提出了一个叫做replaced token detection,也就是说它会对整个原始的输入还是随机地做一些mask,会用一个小的类似BERT一样的预训练语言模型,去还原出这个mask的结果,其结果大致是合理的,但并不是非常好的一个结果,比如说它会替换为:the chef ate the meal 但正确的应该是the chef cooked the meal。这样的话我们就可以预先知道这些词是否会发生替换,比如说这里面应该是ate,它实际上发生了替换,所以我们实际上会用到的是一个比较大的一个判别的一个模型,它回去对每一个词去做一个这样的二分类,去判断它是否发生了替换,这样的话,它就同时解决了上述的两个问题,首先就是它所有的词其实是都受到了有效的监督,第二的话就是它在它的下游任务会用到的模型,这部分其实是一个辅助模型,在预训练之后就会丢弃掉,所以其实它真正会用到的模型是没有收到mask token的影响的,这也就是ELECTRA模型。

刚介绍了两个用的比较多的改进方式,其实还会有特别多的预训练模型,在BERT之后对它在非常多的方面进行了改进,比如非常有代表性的这个ERNIE,在BERT的基础上加了知识图谱,或者是在夸模态当中的一些应用,这个其实会衍生出非常多的预训练模型。相关可看下图左下角网站。

application of masked LM(language model)
masked LM在其他领域的也有一些非常有意思的应用,开阔一下大家的思路
masked LM它作为BERT最核心的一个预训练的任务,它的主要的核心思想就是,我们可以通过完形填空的方式去根据上下文的信息,双向的信息去预测当前的这个token,那在除了在单语的文本语料中进行这个token之间的关联的建模,它在这个跨模态以及多语言中也有非常重要的应用。

在跨语言的过程中,大概是以下的一个应用情况:
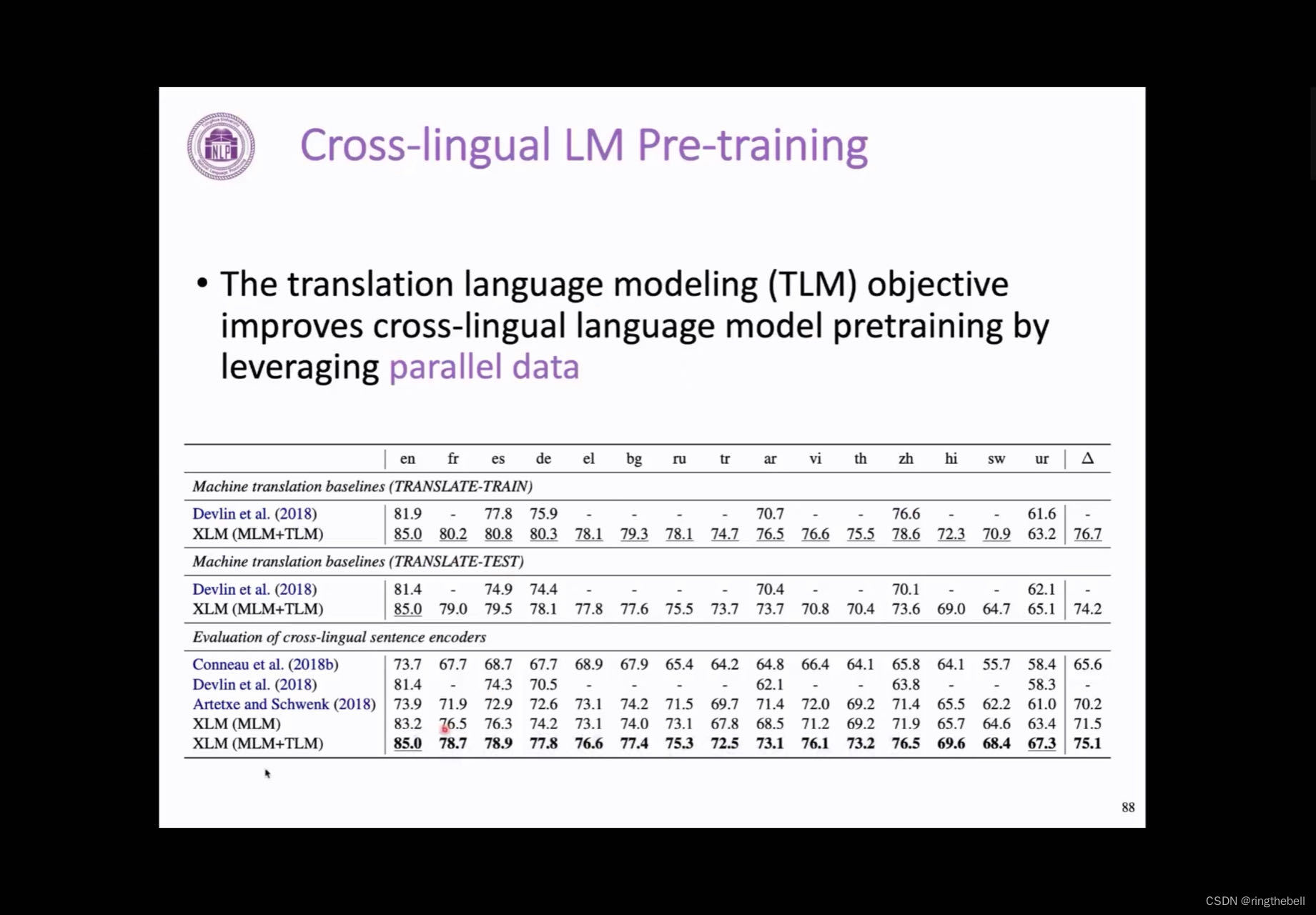
在跨语言中,它最重要的一个挑战,就是我们怎么把不同语言的,它的词以及它的句法的结构去建立起一个关联,那其实这个masked language model就提供了一个非常好的一个工具。比如,我们mask掉一个英语的一个词,那模型其实可以通过注意到这个英语中这句话中的一个上下文去还原当前这个词,它也同样可以去注意到在法语中,它的翻译中其实应该也会有一个大概对应的一个词,这样的话,模型同时利用到了英文的上下文以及它在法语中的对应的词来去还原当前的这个词,这样它实际上鼓励模型,学习到了英语它这样本身的一个结构,同时呢,也对齐了英语和法语语言的这样的一个结构,这样其实就是做到了一个跨语言的一个预训练。

最早探索其实是TLM,是translation language modeling的一个优化目标,它取得了一个非常好的一个结果,这样它能更好地去利用平行语料的这样一个数据,达到当时其实非常好的一个跨语言的一个翻译结果。
处理跨语言的这种对齐外,其实在跨模态的场景下,也有不同token之间对齐的问题,比如说,我们在互联网上会有很多的视频和文本,会有视频和文本这样的一个对儿,比如说视频和字幕。对这个视频来讲的话,可以通过一些手段,比如说具备一些视频的图像或者抽取它的feature,会得到一些visual words,或者一些图片的一些区域。我们在夸模态中一个很重要的关注的一个问题就是,如何把文本的token和视觉去做一个比较好的关联,那masked language model,同样可以完成这样的一个工作。

比如在这样的一个视频里,他可能会切分成特别多的帧,我们会有连续的文本的描述去伴随着这个视频的区域,这样的结果,我们通过masked language model,比如说我们去mask掉这样一个如cut这个词,他就可以通过文本的上下文去还原这个词,同时,,它也可以去注意到这个在图片中,通常会一致地出现一个手拿着刀上下挥舞这样的一个动作,这样其实他就会学习到cut这个词在图片或者视频中的表现是这样的一个视觉效果,所以他就可以学习到夸模态的这样的一种对齐。

这一部分的内容主要是向大家说明,masked language model它作为一种预训练,挖掘无监督数据中数据关联的一种方式,其实它除了在文本之外,在其他的特别多的领域也得到了非常好的应用,所以大家也可以思考这种masked language model自监督的预训练方式,在其他领域是不是也可以有非常有意思的应用。

Frontiers of PLMs预训练语言模型的前沿
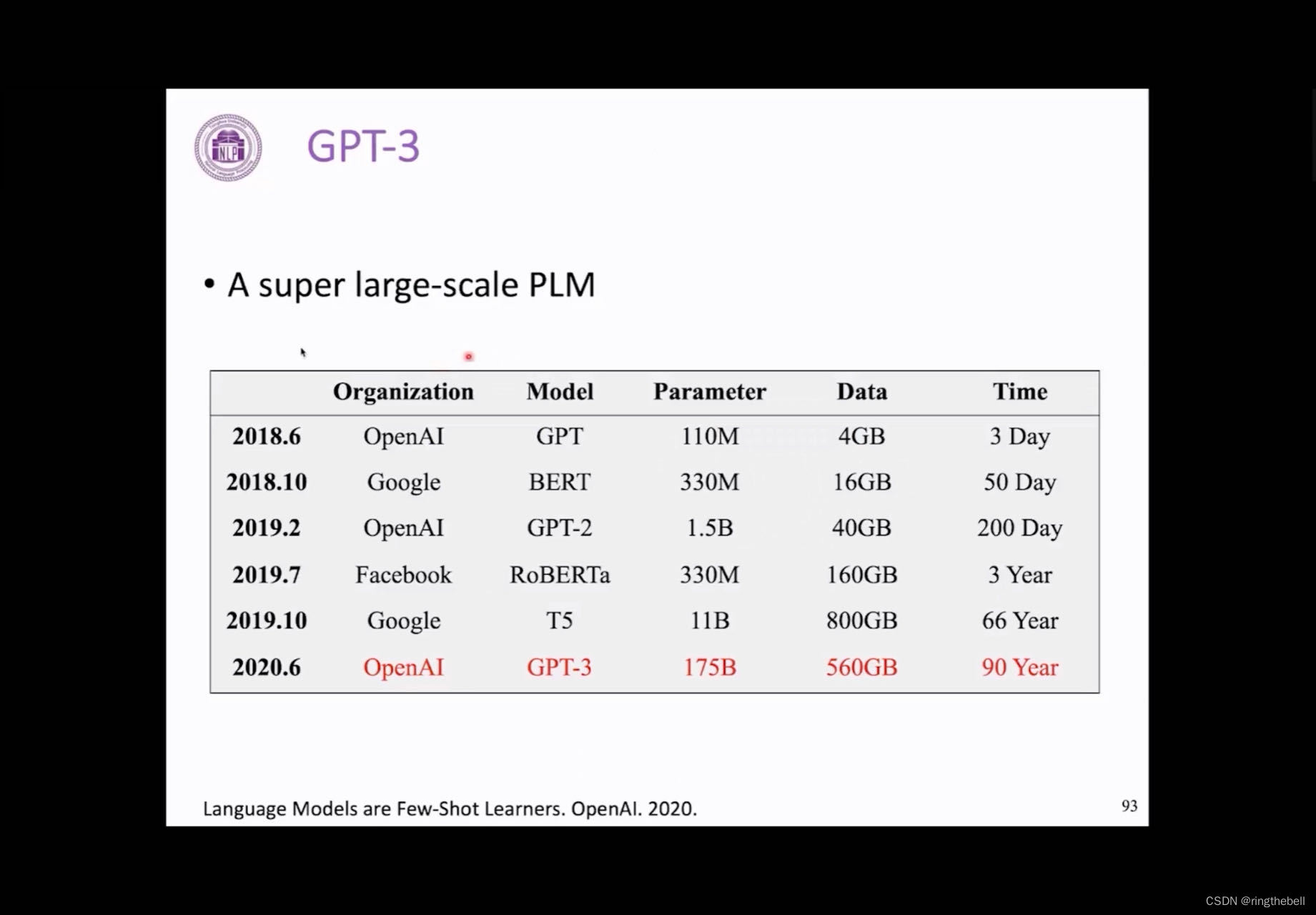
首先介绍一下GPT3,这个其实它是OpenAI在20年发布的,一个非常大的一个预训练语言模型,那可以看到,他和之前的预训练语言模型相比的话,首先就是它的数据规模,它的参数量达到了175亿,其实是非常大的一个规模,属于就相当于语料的数据规模达到了560G,在单独的一个GPU的卡上,要预训练90年的时间,所以这是在目前为止非常大的一个预训练的模型。
它的规模和预训练的数据增大了之后,带来的一个效果就是,其实我们观察到很多神奇的一些现象,就比如说,它的few-shot的效果非常好,并且它可以在一种这个in-context learcing的方式去完成操作。
所谓zero-shot就是自模型我们可以不给他任何的数据,只给他一个整体的任务的描述以及这样的话就可以完成任务,比如说,我们要求模型把这个英语翻译到法语,然后他就可以完成这个任务。
few-shot的话就是,我们可以额外地去提供一个样例,让模型来完成这样一个操作。
以上其实都是以in-context learning的形式完成的。
所谓in-context learning,就是它没有针对下游任务做任何参数的更新,知识在上下文中给了这个任务的描述,完全通过语言模型自回归地形成去完成这个任务,这个其实是会让大家觉得非常印象深刻,非常神奇的一个能力,其实对in-context learning它的其他机制以及它的改进现在也是非常重要的一个研究的热点。

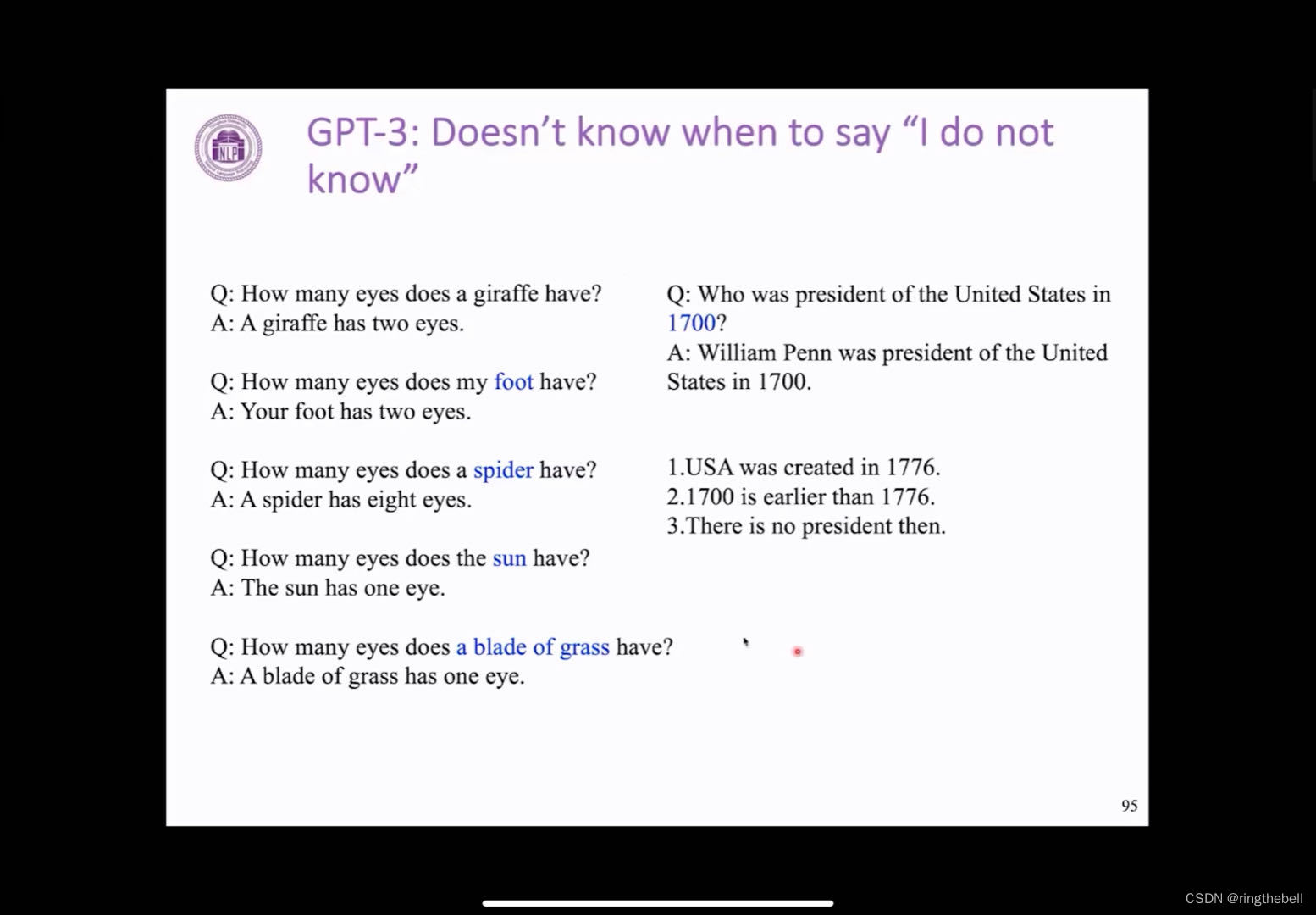
但GPT-3其实也有它自己的问题,一个比较明显的问题就是,它并不是相当于它通过语言模型的方式去完成作出最流畅的一个反馈,但它并不知道这个实际上意味着什么,也就是说,很多时候它不知道什么时候说这个问题其实是不合理的或者它自己并不知道这个答案。
比如说我们问他这个长颈鹿有多少眼睛,它的回答很好,但如果我们这个问题本身就是有问题的,如说我的脚有几只眼睛,它同样会回答有两只眼睛。这些问题在人看来其实比较荒谬,但是这个GPT它通过一种语言模型,自己去生成最可能的答案就会有这样的一个问题。
在GPT之后的T5其实也是一个非常重要的一个预训练模型的一个相应的工作,它的创新就是,它会把所有的NLP的任务同一层一个text-to-text的一个形式,即输入的话,都是它前面是一个任务的描述,并且是后面拼接上一个任务的内容,那T5就会通过一种基于encoder-decoder的一个架构也就是sequence-to-sequence的一个方式去生成出它的答案,这样的话相当于会把所有的NLP的任务都统一成这样的一个形式,去发挥transfer learning的作用。
T5也是现在非常通用的一个框架,在这个语言的理解以及生成上面都取得了非常好的效果。
最后我们介绍一下MOE方面的进展,其实我们之前提到就是GPT和BERT的实验中发现,这个模型的参数量逐渐增大模型的效果会逐步地越来越好,所以其实大家后面会有很多的尝试,就是我们是不是可以训练更大的模型,但后面的话,这个研究者会发现,这个模型越训练越大其实它的油画上会出现很多的问题,那后面为了解决这些问题的话,其实提出了一种基于mixture of experts这样的一种方式去增大模型的参数,训练更大规模的预训练语言模型,它的主要思想就是,把模型的参数分成一块一块的模块,然后每次模型的输入的话其实会调用其中的部分子模块来参与计算,这样的话相当于是每一个子模块,我们会认为它是一个expert,然后整体的模型是不同expert它的组合的一个结果,这个过程中其实会涉及到一些调度以及负载均衡的一些知识(大家有兴趣可以看图片下方的两篇论文)。
通过这样的mixture of experts方式,我们可以看到非常大规模的这个模型参数,比如说Gshard,他有600B的这个参数量,然后Switch 有1500B的一个参数量,这是现在通过MOE的方式来训练更大规模的预训练语言模型。

总结:
预训练语言模型有很长的历史,从词向量到BERT,其实都是NLP中非常重要的一个研究话题,那现在的话,在GPT和BERT之后基于fine-tunning的方式是最常见的一个预训练的范式,BERT基础的masked language model这个预训练任务其实也启发了非常多的工作去改进无监督学习的一些研究。
由于它们现在其实有很多工具,包括transformer。所以预训练语言模型也变得越来越容易使用,所以大家在构建自己的NLP的模型的过程中,都可以考虑使用预训练语言模型来作为一个基础的模型的架构。










![[docker] Docker的私有仓库部署——Harbor](https://img-blog.csdnimg.cn/direct/863e1b917e304e7d9049d15c42d4cbee.png)