BLIP-2: 基于冻结图像编码器和大型语言模型的语言-图像预训练引导
- 项目地址
- BLIP-2的背景与意义
- BLIP-2的安装与演示
- BLIP-2模型库
- 图像到文本生成示例
- 特征提取示例
- 图像-文本匹配示例
- 性能评估与训练
- 引用BLIP-2
- Hugging Face集成
在语言-图像预训练领域,BLIP-2的出现标志着一项重大进展。本篇博客将深入探讨BLIP-2的背景、意义以及它如何改变零-shot语言-图像任务的格局。

项目地址
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
BLIP-2的背景与意义
BLIP-2是BLIP-2论文的官方实现,是一种通用且高效的预训练策略,可以轻松地利用预训练视觉模型和大型语言模型(LLMs)进行语言-图像预训练。BLIP-2在零-shot VQAv2上击败了Flamingo(65.0对56.3),在零-shot字幕生成上建立了新的技术水平(在NoCaps上的121.6 CIDEr分数,相对于之前的最佳113.2)。搭载强大的LLMs(如OPT、FlanT5),BLIP-2还为各种有趣的应用解锁了新的零-shot指导的视觉到语言生成能力!
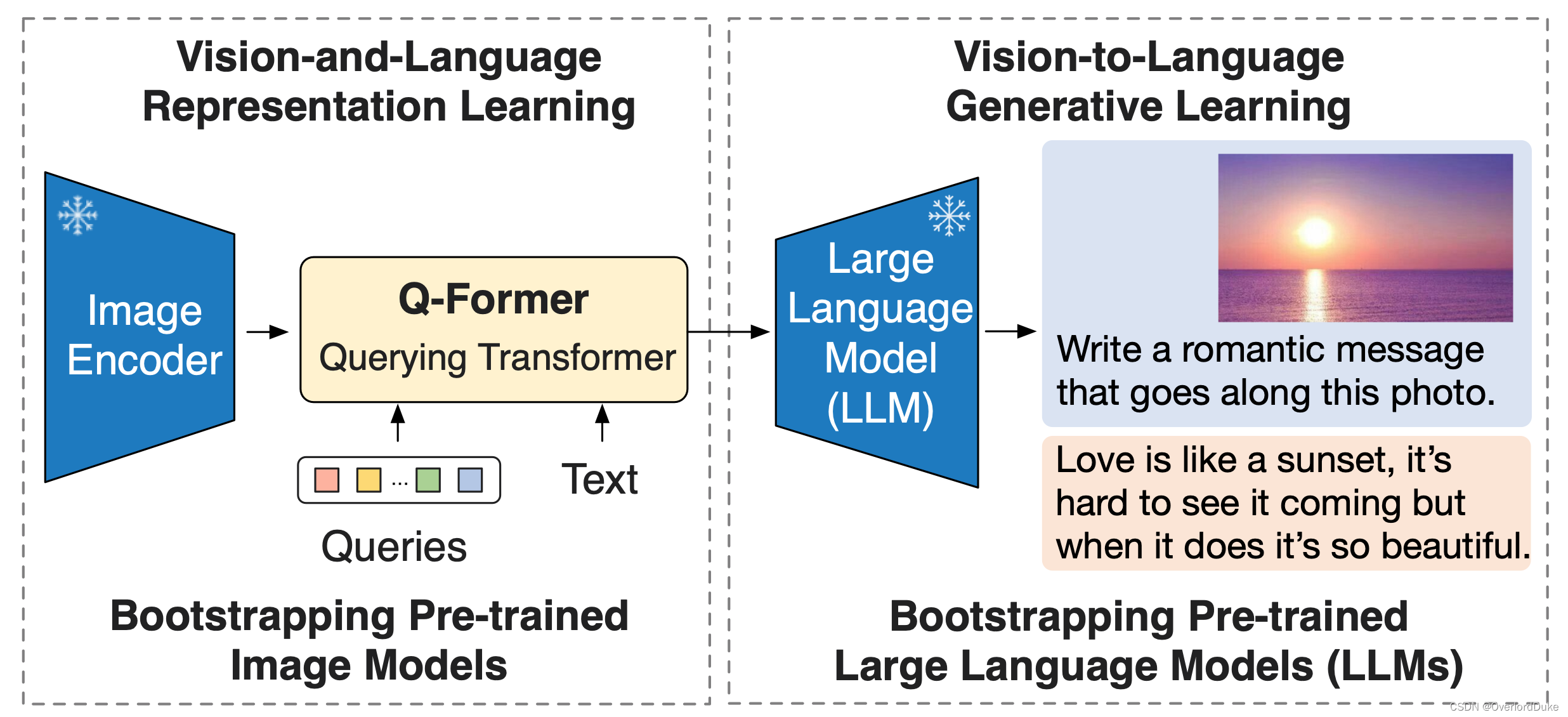
BLIP-2的安装与演示
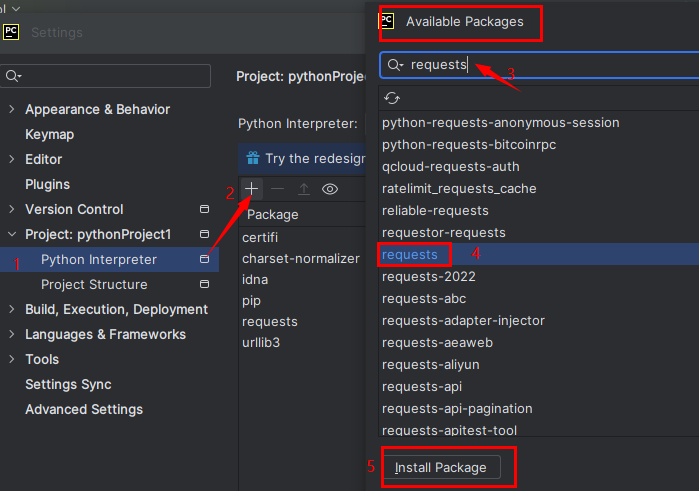
安装BLIP-2非常简单,只需执行以下命令:
pip install salesforce-lavis
或者根据LAVIS指令从源代码安装。
你还可以尝试我们的笔记本演示,体验指导式的语言到图像生成。
BLIP-2模型库
BLIP-2提供了多种模型架构和类型,包括:
- blip2_opt:用于预训练和字幕生成
- blip2_t5:用于预训练和字幕生成
- blip2:用于特征提取和检索
图像到文本生成示例
让我们看看如何使用BLIP-2模型执行零-shot指导式的图像到文本生成。首先,我们从本地加载样本图像:
import torch
from PIL import Image
# 设置设备
device = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# 加载样本图像
raw_image = Image.open("../../docs/_static/merlion.png").convert("RGB")
display(raw_image.resize((596, 437)))
然后,我们加载一个预训练的BLIP-2模型及其预处理器(变换):
import torch
from lavis.models import load_model_and_preprocess
# 加载预训练的BLIP-2模型
model, vis_processors, _ = load_model_and_preprocess(name="blip2_t5", model_type="pretrain_flant5xxl", is_eval=True, device=device)
# 准备图像
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
给定图像和文本提示,询问模型生成响应:
model.generate({"image": image, "prompt": "Question: which city is this? Answer:"}) # 'singapore'
特征提取示例
BLIP-2支持LAVIS的统一特征提取接口。
图像-文本匹配示例
BLIP-2可以使用与BLIP相同的接口计算图像-文本匹配分数。
性能评估与训练
你可以通过下载数据集并运行相应脚本来评估预训练和微调模型。训练过程分为两个阶段:从头开始的预训练和第二阶段的预训练。
引用BLIP-2
你可以在ICML会议上找到关于BLIP-2的更多信息和引用。
Hugging Face集成
BLIP-2已集成到Hugging Face Transformers库中,并且通过bitsandbytes可以利用int8量化,大大减少了加载模型所需的内存量,而不会降低性能。
以上就是BLIP-2的简要介绍和功能概览,希望能为你提供一个清晰的了解。