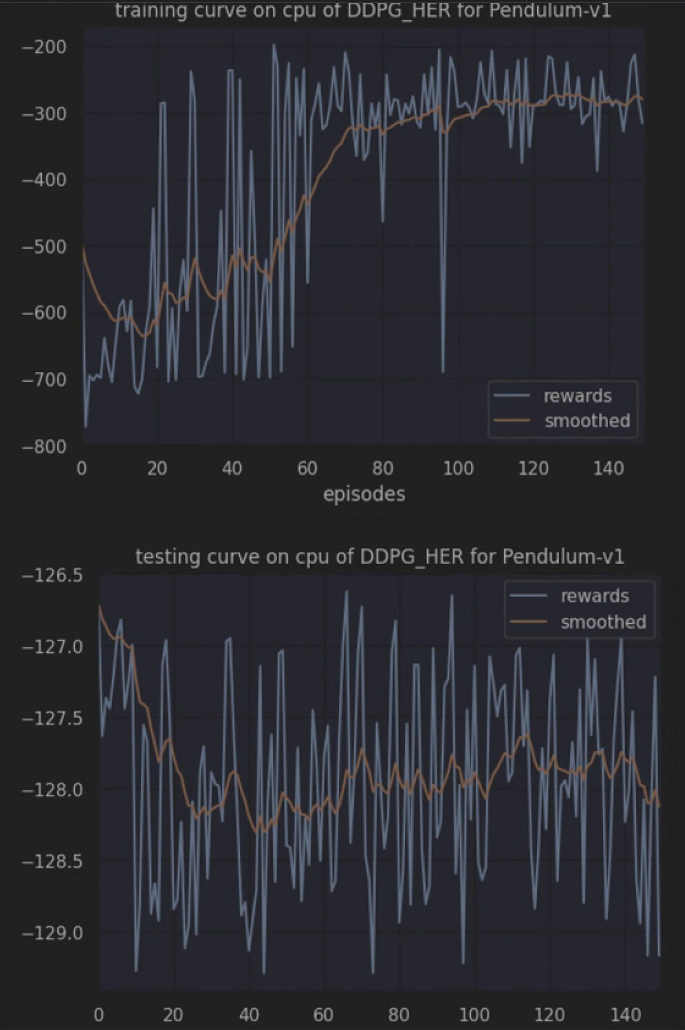
注:文章参考:数据治理实践 | 数据表合规治理本期将从数据表治理角度出发,探讨数据表合规治理的最佳实践及相关挑战![]() https://mp.weixin.qq.com/s/5ImY5niYNOb_VpicUcasCg
https://mp.weixin.qq.com/s/5ImY5niYNOb_VpicUcasCg
目录
前言
一、数据表合规治理的背景
二、数据表合规治理前的思考
三、数据表合规治理的过程
3.1 数据标准重制定
3.2 无用/临时数据表下线
3.3 应用指标公共逻辑下沉
3.4 解决ODS穿透问题
3.5 烟囱表重构/下线
3.6 非合规数据表的元数据重构/修改
3.7 数据表合规后续维护
四、数据表合规治理的结果
五、数据表合规治理中遇到的难点
六、数据表合规治理思考
前言
数仓经常会收到下游反馈,例如:数据表难用、想要查询的指标不知道来源哪个数据表、数据表命名缺少规范约束等,因此数据表合规治理显得越来越重要。
一、数据表合规治理的背景
随着业务的快速迭代,数仓在扩张期需支撑多场景的应用需求。由于很多数仓在初步搭建时缺乏一套数据标准及模型设计规范,并且组内成员技术/业务水平质量参差不齐,为快速支持业务,导致分层混乱,产生大量烟囱数据表。无规范/无元数据维护的数据表很难使用,复用性差。(比如:当前所在的业务线数据表混乱,查询一个指标发现线上有5个以上数据表重复加工了(缺乏指标中心导致))、历史字段名/表命名也很随意没有遵循规范。线上数据链路较长、错综复杂的依赖关系导致产出数据晚,通过血缘梳理后,发现有23%的ODS穿透率。
ps: ODS穿透率:代表的是ODS跨层引用率,常见的是ODS层到ADS层引用;ODS穿透率的计算口径:被跨层引用的ODS表数量/ODS层表数量。
二、数据表合规治理前的思考
由于数据表之间互相依赖过多,链路过长且繁杂,直接进行合规治理可能会造成线上事故,需要与团队多次沟通后对当前治理优先级进行排期。治理顺序可以是:数据标准重制定 --> 无用/临时数据表下线 --> 公共逻辑下沉复用(提高模型的覆盖率) --> 解决ODS穿透问题 --> 烟囱数据表重构及下线--> 非合规数据表的元数据重构。
ps: 上述步骤中,【烟囱数据表重构及下线--> 非合规数据表的元数据重构 】的操作会影响ADS表,级联影响下游报表数据等。意味着下游需要跟着数仓一起改动,平白增添了工作量。因此,大多数情况,数仓不好推动下游配合做事情(数仓中的表合规治理主要对数仓内部带来价值,下游获利较少。下游只需要数仓一直给到正确的结果数据就ok,不关系数仓指标加工的过程)
可以借助平台对当前的数仓模型质量进行评估,从而明确后期治理的方向,例如借助网易的easy data和数据治理360平台进行模型现状评估。

(网易easy data-模型设计中心Demo图)
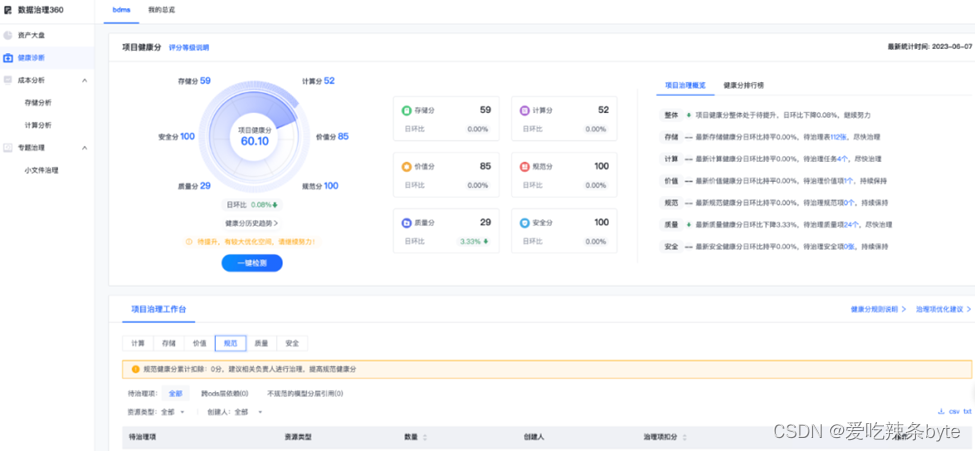
(网易easy data-数据治理360 Demo图)
三、数据表合规治理的过程
3.1 数据标准重制定
对当前数据域按照业务流程重新划分,重新制定元数据规范(表名、字段命名、字段数据格式等)。
(1)数据域 vs 主题域
主题域:从业务视角自上而下分析,从整体业务环节中抽象出来的专项分析模块,结合对接的业务范围从更高的视角去洞察整个业务流程;(ads层)
数据域:从数据视角自下而上分析,将业务过程或者维度进行抽象提炼的集合,在划分数据域的时候,既能涵盖当前所有的业务需求,又能在新业务接入时无影响地被包含进已有的数据域中和扩展新的数据域。(dwd层)
(2)元数据规范
除了已知的词根/命名等内容,还包括数据表使用说明、存储标准、数据表负责人注明、字段类型统一等。
一、数据表命名规范
(1)ODS层(接入层):
ods__{业务数据库名}_{业务数据表名}(可以在结尾补充增量或全量情况,或者在元数据侧补充)
(2)DWD层(明细层):
dwd_{一级数据域}_{二级数据域}_{三级数据域}_{业务过程(不清楚或没有写detail)}_存储策略(df/di,df为全量数据,di为增量数据))
(3)DWS层(汇总层):
dws_{一级数据域}_{二级数据域}_{三级数据域}_{颗粒度}(例如员工/部门)_{业务过程}_{周期粒度}(例如近30天写30d、90天写3m)
(4)ADS层(应用层):
ads_{应用主题/应用场景}_{颗粒度}(例如买家/卖家)_{业务过程}_{调度周期}(例如1天调度一次写1d)
(5)DIM表(维度表):
dim_{维度定义}_{更新周期(可不添加)}(例如日期写date)
(6)TMP表(临时表):
tmp_{表名}_{临时表编号}
(7)VIEW(视图):
{表名}_view
(8)备份表:
{表名}_bak
二、数据表命名词根
(1)存储策略
df:日全量
di:日增量
hf:小时全量
hi:小时增量
mf:月全量
mi:月增量
wf:周全量
wi:周增量
(2)数据粒度
buyer:买家
seller:卖家
user:用户
emp:员工
order:订单
(3)统计周期
1d:近一天指标统计
1m:近一月指标统计
1y:近一年指标统计
3m:近三个月指标统计
6m:近六个月指标统计
nd:近n天指标统计(无法确定具体天可用nd替代)
td:历史累计
(4)调度周期
1d:天调度
1m:月调度
1y:小时调度
三、字段命名规范
(1)是否某某类型用户,字段命名规范:is_{内容}
(2)枚举值类型字段命名规范:xxx_type
(3)时间戳类型字段命名规范:xxx_date,xxx_time
(4)周期指标命名:{内容}_{时间描述}(如最近一次lst1,最近两次lst2,历史his,最近第二次last2nd_date)
(5)百分比命名:{内容}_rate
(6)数值类型(整型)命名:{内容}_cnt_{周期}(周期看情况添加)
(7)数值类型(小数)金额命名:{内容}_amt_{周期}(周期看情况添加)
四、字段类型规范
文本:String
日期:String
整数:Bigint
小数:高精度用Decimal、正常使用Double
枚举值:单枚举-'Y'/'N'用String、多枚举用String
各类:IDString
五、数据表中其他元数据规范
数据表负责人(owner);
数据表中文名及使用说明;
每个开发字段中文名(中文名需要包含该字段内容,例如是否为某某类型用户,需要写出包含内容(Y/N));
数据表的颗粒度;
数据表的主键或联合主键;
六、数据表中存储周期规范
ODS层:1年
DWD层:3-5年
DWS层:10年(部分可永久)
ADS层:10年(部分可永久)
DIM层:3-5年(部分可永久)
数据表分区建议最多2级分区,超过2级分区会造成数据长周期存储问题。通常1级分区为业务日期,2级根据业务场景设置。
3.2 无用/临时数据表下线
根据数据血缘及任务依赖(建议在数仓侧开发血缘数据表,如有条件可将范围扩大到可视化侧,即:可以看到指标加工涉及的基表,指标被下游xx数据服务所引用)对线上长期无用表、下游无血缘且空跑数据表、临时表进行扫描及下线,降低存储及计算损耗。
ps:元数据信息采集功能:云平台(商业)自带该功能,也可以使用开源DataHub元数据管理平台去支撑该功能,地址:
A Metadata Platform for the Modern Data Stack | DataHubDataHub is a data discovery application built on an extensible metadata platform that helps you tame the complexity of diverse data ecosystems.![]() https://datahubproject.io/
https://datahubproject.io/
3.3 应用指标公共逻辑下沉
业务扩张期,数仓为了快速响应需求,采取烟囱式开发,由于缺乏建设指标中心,长此以往,指标冗余、指标复用差的问题逐渐暴露。数仓侧的解决思路:先排查应用层指标是否口径一致,如不一致需要跟下游沟通后修改;其次,针对应用层(ads层)的模型指标按照数据域、周期(1d最近1天、30d最近30天、60d最近60天、td历史至今) 拆解、将数据粒度一致且逻辑也一致的指标去重后,统一下沉到dws(公共逻辑轻度汇总层)进行复用。
3.4 解决ODS穿透问题
依据数据血缘找到跨层引用数据表,并对这些数据表按照模型五要素(数据域、事实表、粒度、维度、度量)来构建CDM(DWD与 DWS)层,验证ADS层指标引用新DWS数据表的质量情况,最后完成DWD / DWS 数据表上线,并同步进行ADS层引用表的切换。
3.5 烟囱表重构/下线
对于线上的、历史的、多次重复开发的烟囱数据表进行重构或者直接下线处理。具体操作可以是:将粒度一致的、相似场景下的数据表字段内容进行合并或去重,重构表结构以提升表的复用性及易用性。烟囱表重构/下线可能会影响下游报表等,因此需要提前跟下游沟通,拉通下游一起切换至新的模型。
3.6 非合规数据表的元数据重构/修改
针对非合规数据表的元数据信息、按照标准规范进行重构。可以先重构ODS、DWD、DWS数据表,保障数据准确性后,再逐步重构ADS表。由于下游的应用服务(如:报表,BI看板等)基本是从ADS层取数的,下游也需要同步调整表名、或者代码中引用的字段信息。因此ADS表的元数据修改时,需要拉通下游一起调整。
3.7 数据表合规后续维护
可以从数据表的价值(被引用次数,查询次数,被收藏次数等)、数据表元数据规范设定数据表的合规评判分,并设立红黑榜以及对应奖惩措施。后续可利用Python等开发不合规数据表信息提示(可日推、周推提醒),可通过邮件或者群信息方式,督促负责人定时治理不规范的数据表,维护好数据表的质量。(如果负责人不执行,回收数仓相关表的使用权限)同时还可建设数据表设计中心,数据表上线前的强制审核。(新建表审核走工单,符合规范的才能上线)
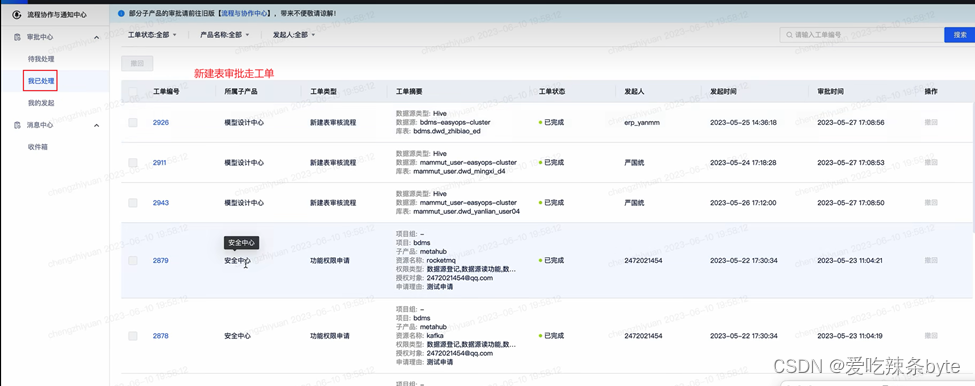
ps: 3.1~ 3.4 在数仓内部进行治理, 3.5~ 3.7 数仓需要跟下游一起配合推进。
四、数据表合规治理的结果
数据表合规治理的量化指标可以有以下几个方面:
(1)下线各层无用/临时数据表总计xx+张,释放存储资源xxT;
(2)完成xx+个应用层烟囱数据表整合,及xx+公共指标下沉;
(3)ODS穿透率由原来xx%下降至x%;
(4)推出治理红黑榜,维持数仓整体的资产健康分在80分以上;
(5)数据产出平均时间由原来每日最晚8:30产出降低至7:10(任务链路缩短);
(6)与团队配合完成某业务线数仓数据表命名、字段命名、字段类型、数据表分区生命周期等方向规范制定;
(7)模型覆盖率提升至xx%;
(8)下游找数仓临时取数的需求少了,下游查找表及指标的效率提高了;
五、数据表合规治理中遇到的难点
在治理中后期。通常会涉及到烟囱数据表的重构问题,但与下游多次对接无果(包含数据表迁移时需要下游配合报表改动,会徒增下游工作量),治理难推动。即便想出合理方案,也会因为下游各类突发情况导致治理进展不断Delay(延期),后续需要反复磨合才完成数据表的更换,相互协调都较困难。
六、数据表合规治理思考
数据表合规治理是持续性的工作,数仓侧无法保障每个数据表就一定是合规且易用的。因此在部门内部,需要逐步将数据表治理常态化,规范化,落实方案从而减少类似问题频繁发。
数据表合规治理的实践过程中,与下游协同工作困难是遇到的阻碍点之一,经过复盘后,个人总结治理工作跨部门配合可以从3个点出发:
(1)让下游配合其实最重要的是调动他们积极性,因为数据表治理对于下游来说可有可无 ,即便数仓不进行数据表治理,线上任务依旧正常运行,下游仍然可以取到想要的数据。数仓修改了数据表内容,保障了数仓内部使用的易用性,而对于下游来说可能毫无感知。因此可以从下游使用数据过程中的痛点去沟通,在优先支撑下游业务的同时,提升表的易用性,从而提高下游检索表的效率,降低使用数仓表的使用门槛。
(2)制定一些奖惩活动,让下游觉得配合是有价值的。例如通过红黑榜定期给他们发送邮件或者信息,并开展简单的培训,让下游具备治理的意识,同时在他们自助治理后提供一定的奖励。
(3)如果治理在周边部门起到了效果,可以做更大的推进作用。比如在和下游一起做治理并取到了显著效果后,可以将治送理成果的月报/周报 发送全部门,让其他人也有感知,并定期分享自己治理心得,积极与其他业务线的数仓内部沟通交流,提升数仓部门在公司的影响力。