Flink 实时groupby聚合场景操作时,由于使用的是rocksdb状态后端,发现CPU的高负载卡在rocksdb的读写上,导致上游算子背压特别大。通过调优使用hashmap状态后端代替rocksdb状态后端,使吞吐量有了质的飞跃(20倍的性能提升),并分析整理。
实例代码
--SET table.exec.state.ttl=86400s; --24 hour,默认: 0 ms
SET table.exec.state.ttl=2592000s; --30 days,默认: 0 ms
CREATE TABLE kafka_table (
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map<string,string>,
cur map<string,string>,
cus map<string,string>,
account_id AS IF(cur['account_id'] IS NOT NULL , cur['account_id'], src ['account_id']),
publish_time AS IF(cur['publish_time'] IS NOT NULL , cur['publish_time'], src ['publish_time']),
msg_status AS IF(cur['msg_status'] IS NOT NULL , cur['msg_status'], src ['msg_status']),
send_type AS IF(cur['send_type'] IS NOT NULL , cur['send_type'], src ['send_type'])
--event_time as cast(IF(cur['update_time'] IS NOT NULL , cur['update_time'], src ['update_time']) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
--WATERMARK FOR event_time AS event_time - INTERVAL '1' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't1',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
-- 'properties.enable.auto.commit',= 'true' -- default:false, 如果为false,则在发生checkpoint时触发offset提交
'format' = 'json'
);
CREATE TABLE es_sink(
send_type STRING
,account_id STRING
,publish_time STRING
,grouping_id INTEGER
,init INTEGER
,init_cancel INTEGER
,push INTEGER
,succ INTEGER
,fail INTEGER
,init_delete INTEGER
,update_time STRING
,PRIMARY KEY (group_id,send_type,account_id,publish_time) NOT ENFORCED
)
with (
'connector' = 'elasticsearch-6',
'index' = 'es_sink',
'document-type' = 'es_sink',
'hosts' = 'http://xxx:9200',
'format' = 'json',
'filter.null-value'='true',
'sink.bulk-flush.max-actions' = '1000',
'sink.bulk-flush.max-size' = '10mb'
);
CREATE view tmp as
select
send_type,
account_id,
publish_time,
msg_status,
case when UPPER(opt) = 'INSERT' and msg_status='0' then 1 else 0 end AS init,
case when UPPER(opt) = 'UPDATE' and send_type='1' and msg_status='4' then 1 else 0 end AS init_cancel,
case when UPPER(opt) = 'UPDATE' and msg_status='3' then 1 else 0 end AS push,
case when UPPER(opt) = 'UPDATE' and (msg_status='1' or msg_status='5') then 1 else 0 end AS succ,
case when UPPER(opt) = 'UPDATE' and (msg_status='2' or msg_status='6') then 1 else 0 end AS fail,
case when UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0' then 1 else 0 end AS init_delete,
event_time,
opt,
ts
FROM kafka_table
where (UPPER(opt) = 'INSERT' and msg_status='0' )
or (UPPER(opt) = 'UPDATE' and msg_status in ('1','2','3','4','5','6'))
or (UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0');
--send_type=1 send_type=0
--初始化->0 初始化->0
--取消->4
--推送->3 推送->3
--成功->1 成功->5
--失败->2 失败->6
CREATE view tmp_groupby as
select
COALESCE(send_type,'N') AS send_type
,COALESCE(account_id,'N') AS account_id
,COALESCE(publish_time,'N') AS publish_time
,case when send_type is null and account_id is null and publish_time is null then 1
when send_type is not null and account_id is null and publish_time is null then 2
when send_type is not null and account_id is not null and publish_time is null then 3
when send_type is not null and account_id is not null and publish_time is not null then 4
end grouping_id
,sum(init) as init
,sum(init_cancel) as init_cancel
,sum(push) as push
,sum(succ) as succ
,sum(fail) as fail
,sum(init_delete) as init_delete
from tmp
--GROUP BY GROUPING SETS ((send_type,account_id,publish_time), (send_type,account_id),(send_type), ())
GROUP BY ROLLUP (send_type,account_id,publish_time); --等同于以上
INSERT INTO es_sink
select
send_type
,account_id
,publish_time
,grouping_id
,init
,init_cancel
,push
,succ
,fail
,init_delete
,CAST(LOCALTIMESTAMP AS STRING) as update_time
from tmp_groupby
问题调优
由于使用的是rocksdb状态后端,发现CPU的高负载卡在rocksdb的读写上,导致上游算子背压特别大,如下图:
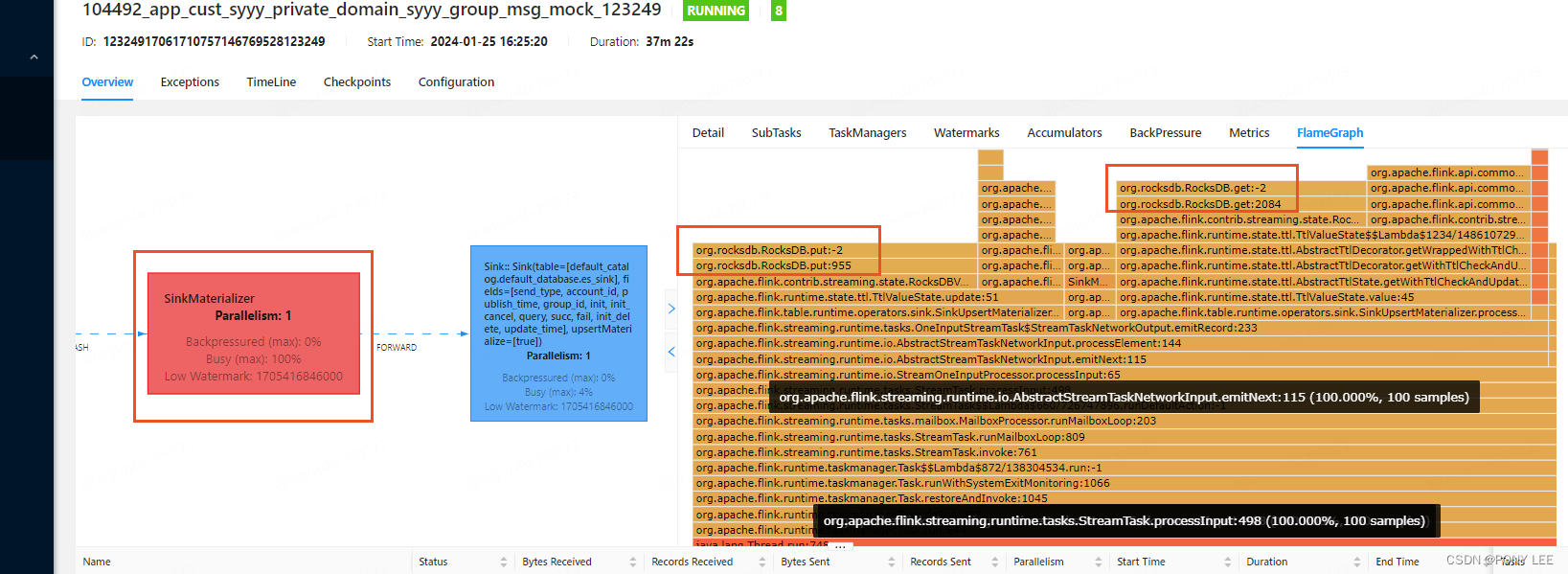
改使用hashmap状态后端以后,当前环节的CPU负载大大缓解,上游背压消失,吞吐量有20以上的提升,如下:
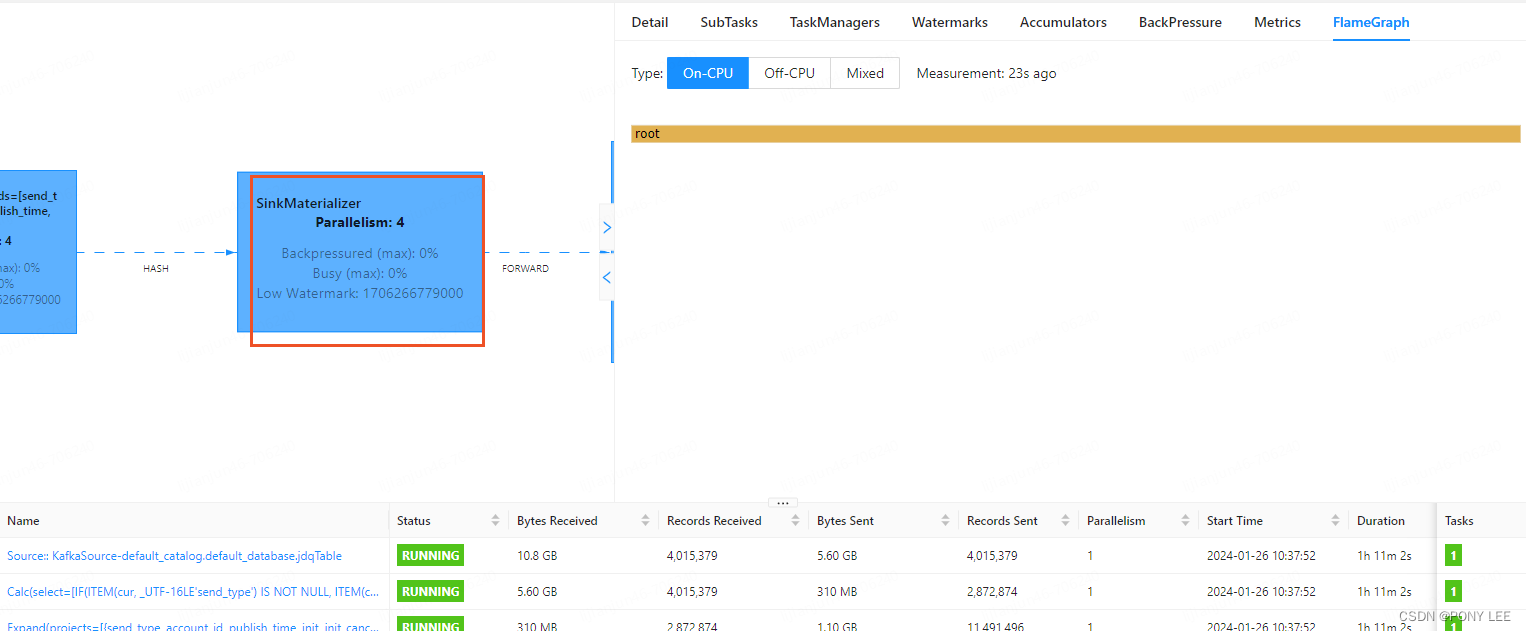
分析问题
Flink为我们预置了两种状态后端HashMap和RocksDB,
- HashMap状态后端是将状态数据存储在SubTask的内存中,访问速度更快,但是受限于SubTask内存大小
- RocksDB状态后端是将状态数据存储在SubTask的磁盘中,存储容量更大,但是访问速度会慢于HashMap状态后端
通过比较这两种不同类型状态后端,用户可以根据业务场景中的状态的大小、状态的访问性能等条件来衡量并选择将状态数据存储到内存中还是本地的磁盘中。
举例来说,有的应用场景中的Flink作业要保存数百亿条状态数据,那么就需要在SubTask本地保存大量的状态数据,这种场景下RocksDB状态后端显然更合适;而有的应用场景中的Flink作业只需要保存数百万条状态数据,但是对于状态的访问和更新频次很高,那么在这种应用场景下,需要保障状态数据访问的高效性,hashmap状态后端显然是更好的选择。
注意:
- 如果我们没有通过上述两种方法来设置作业的状态后端,那么Flink默认的状态后端就是HashMap状态后端
- 从Flink 1.13版本开始,Flink统一了不同状态后端的Savepoint的二进制格式,因此我们可以使用一种状态后端生成Savepoint并且使用另一种状态后端进行恢复,这可以帮助我们在极致的状态访问性能(HashMap状态后端)以及支持大容量的状态存储(RocksDB状态后端)之间进行灵活切换。
状态后端的配置
HashMap状态后端的配置
- 通过作业代码设置单个Flink作业的状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 指定状态后端为HashMap
env.setStateBackend(new HashMapStateBackend());
// Checkpoint快照文件存储的目录
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:50010/flink/checkpoints"));
- 通过flink-conf.yaml设置状态后端,sql方式一般通过这种方式配置
# 状态后端的类型
state.backend: hashmap
# Checkpoint快照文件存储的目录
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
HashMap状态后端的使用建议:
将托管内存(Managed Memory)设为0,托管内存是Flink分配的本地堆外内存,应用场景通常在RocksDB状态后端下分配给RocksDB来存储状态数据的,因此在使用HashMap状态后端的情况下,我们可以将托管内存设置为0来将更多的内存提供给HashMap状态后端使用。可以通过以下3种方式来在flink-conf.yaml中设置托管内存。
- 通过taskmanager.memory.managed.size指定托管内存的大小。
- 通过taskmanager.memory.managed.fraction指定托管内存在Flink总内存中的占比,默认值为0.4。
- 当同时指定二者时,会优先采用taskmanager.memory.managed.size,若二者均未指定,会根据taskmanager.memory.managed.fraction的默认值0.4计算得到托管内存的大小。
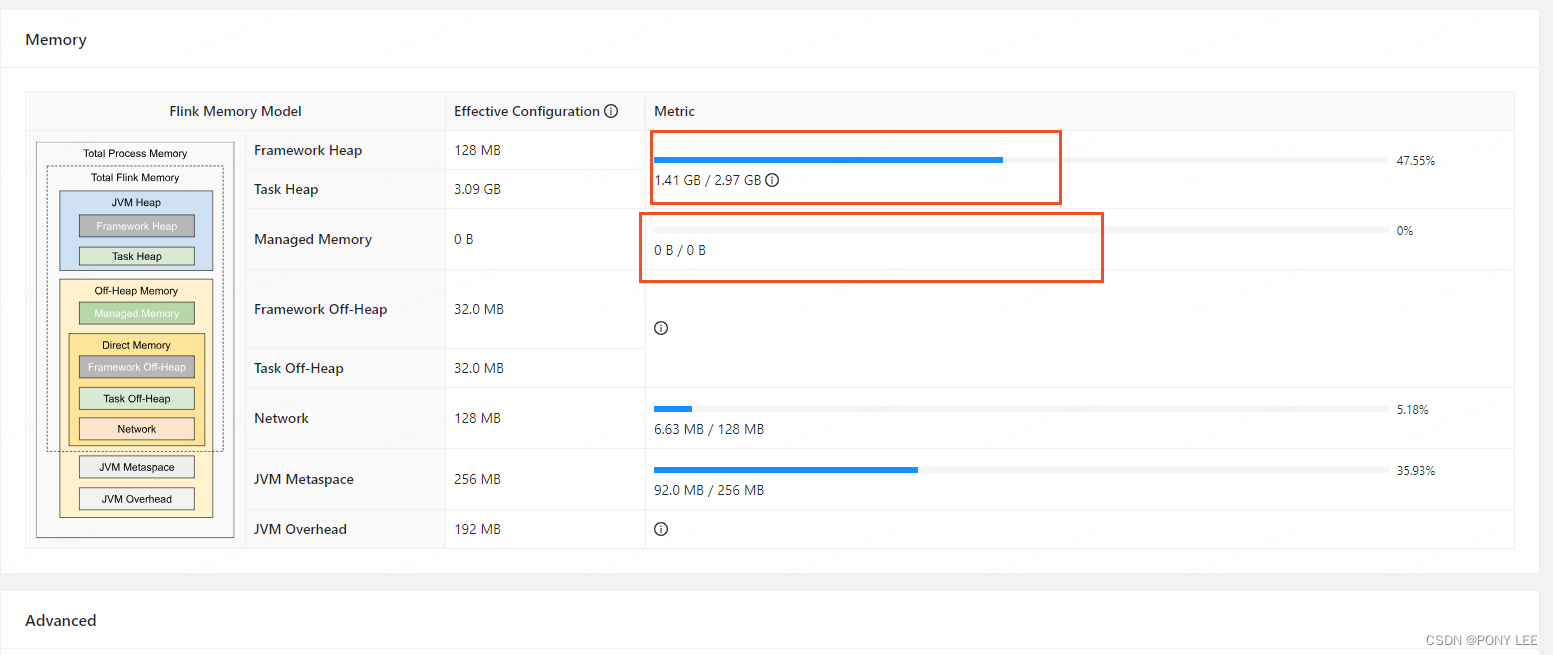
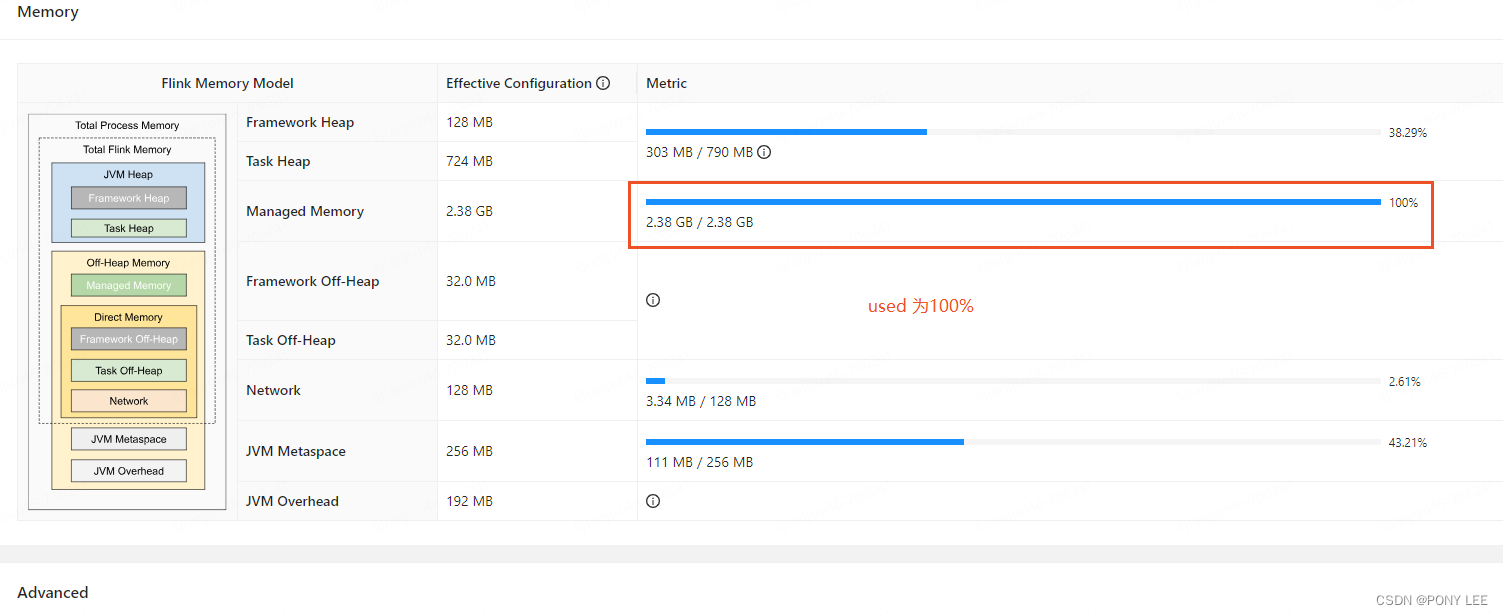
通过Flink Web UI查看状态后端配置及内存使用情况,如下图:
 托管内存(Managed Memory)不为0时:
托管内存(Managed Memory)不为0时:
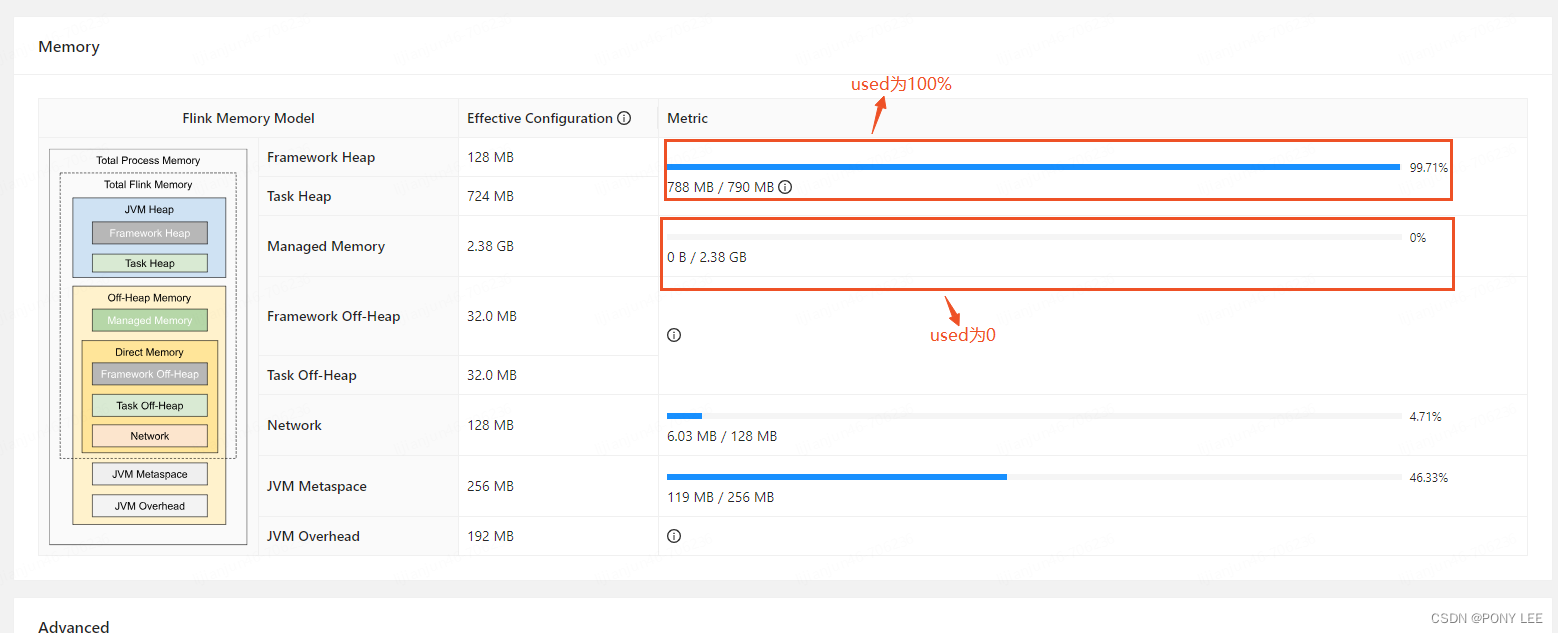
托管内存(Managed Memory)为0时(强烈建议):
RocksDB状态后端的配置
- 通过作业代码设置单个Flink作业的状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置状态后端为RocksDB
env.setStateBackend(new EmbeddedRocksDBStateBackend());
// 设置状态后端为RocksDB,并且设置为增量Checkpoint
env.setStateBackend(new EmbeddedRocksDBStateBackend(true));
// Checkpoint快照文件存储的目录
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:50010/flink/checkpoints"));
需要引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.14.6</version>
</dependency>
- 通过flink-conf.yaml设置状态后端,sql方式一般通过这种方式配置
# 配置状态后端的类型
state.backend: rocksdb
# 设置增量Checkpoint
state.backend.incremental: true
# 配置Checkpoint快照文件的目录
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
RocksDB状态后端的使用建议:
通过上文知道,托管内存(Managed Memory)通常在RocksDB状态后端下分配给RocksDB来存储状态数据的,因此需要适当调大托管内存。
-
通过taskmanager.memory.managed.size指定托管内存的大小。
-
通过taskmanager.memory.managed.fraction调大托管内存在Flink总内存中的占比,例如:0.8。
-
状态数据大小:由于JNI API是构建在字节数组之上的,因此每个key和value最大只支持231字节,而在ListState这种数据结构中,可能会出现value超过231字节的情况,这时获取状态数据会失败,在使用时需要注意
-
RocksDB状态后端增量快照
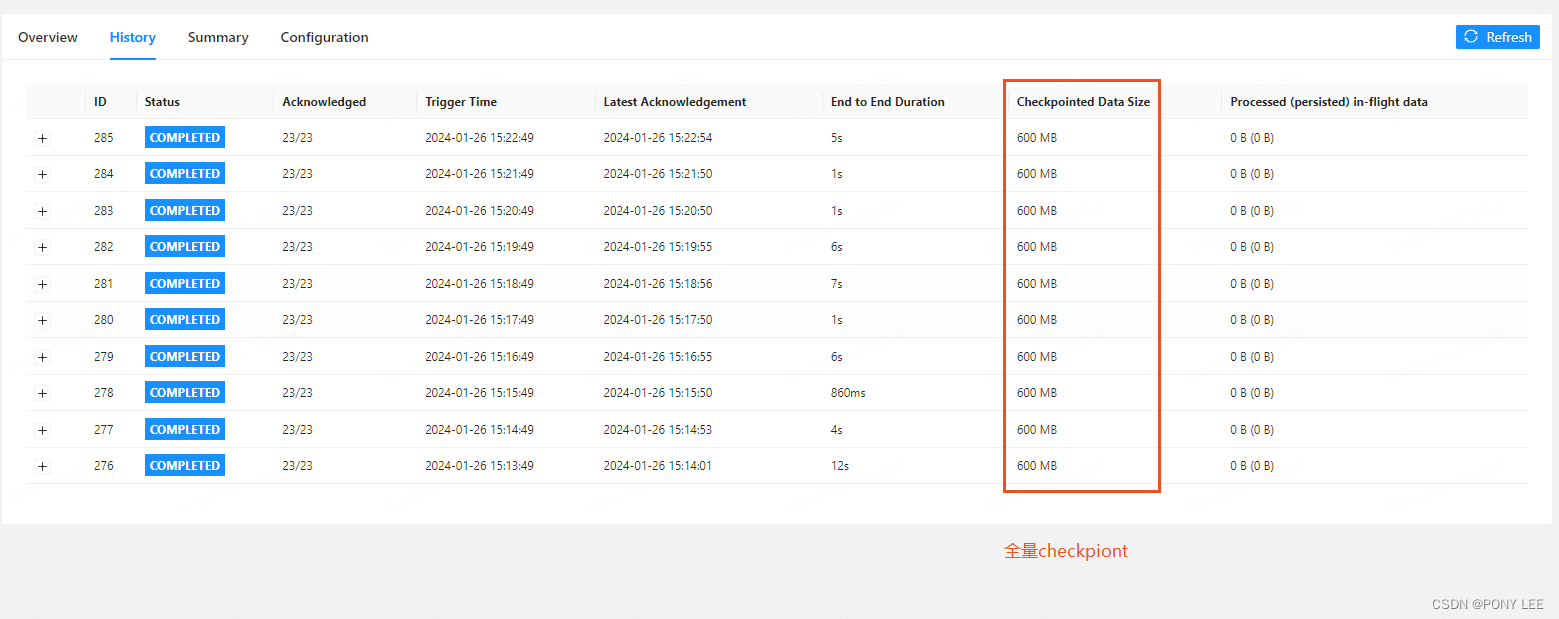
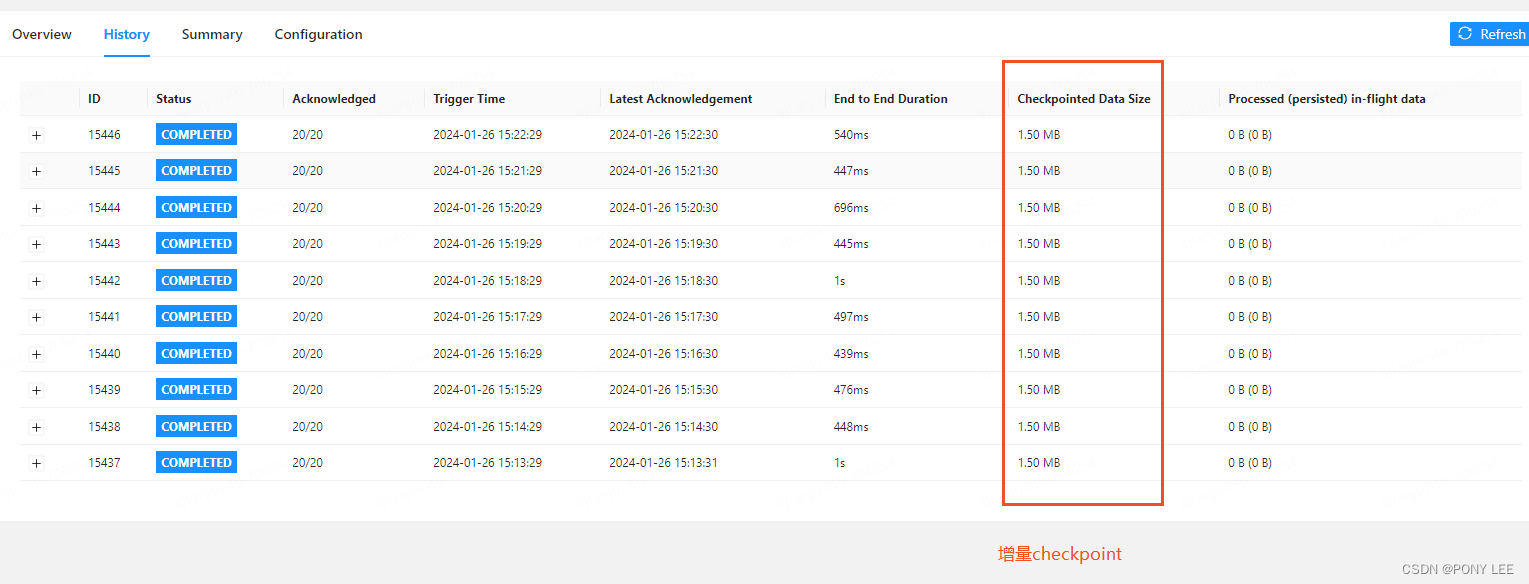
RocksDB状态后端是目前唯一支持增量快照(增量Checkpoint)的状态后端。与增量快照相反的是全量快照,全量快照很好理解,在Checkpoint执行时,Flink作业将当前所有的状态数据全部备份到远程文件系统中,这就是全量快照。而在生产环境中,大多数Flink作业两次快照的间隔中发生变化的状态数据只占整体状态数据的一小部分,基于这个特点,增量快照诞生了,增量快照的特点在于每一次快照要持久化的数据只包含自上一次快照完成之后发生变化(被修改)的状态数据,所以可以显著减少持久化快照文件的大小以及执行快照的耗时。增量ck与全量ck的区别,如下图:
-
定时器状态数据的存储
在Flink的窗口类应用中,定时器是用于触发窗口计算的核心组件,为了在作业异常时保证注册的定时器不被丢失,定时器会被存储到键值状态中。
在Flink作业中,用于存储定时器的数据结构是一个支持去重的优先队列。当我们配置RocksDB作为状态后端时,默认情况下定时器将存储在RocksDB中,但是这样的存储方式容易导致Flink作业出现性能问题。原因主要有两个,第一个原因是去重优先队列是一个复杂的数据结构,Flink作业访问RocksDB会存在性能问题,第二个原因是算子对于定时器的访问是比较频繁的,这会加大Flink作业处理数据的时延。
以事件时间为例,默认情况下Flink作业的Watermark生成器会每隔200ms抽取一次Watermark,而每当时间窗口算子的Watermark发生更新,都要访问优先队列判断当前是否有定时器要触发,所以如果将去重优先队列存储在RocksDB中,频繁的访问定时器将会严重影响作业性能。
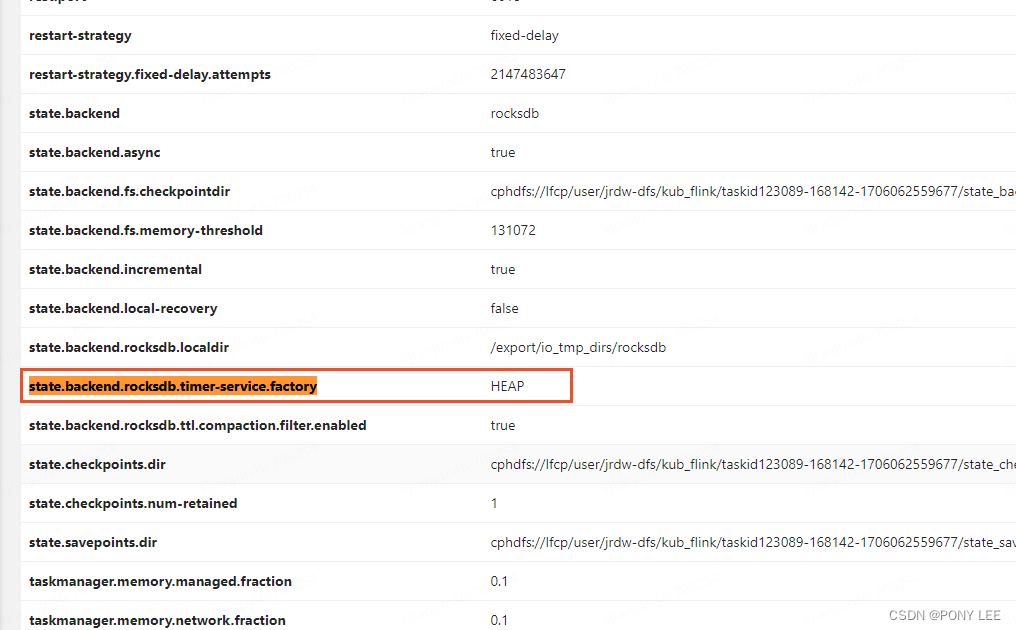
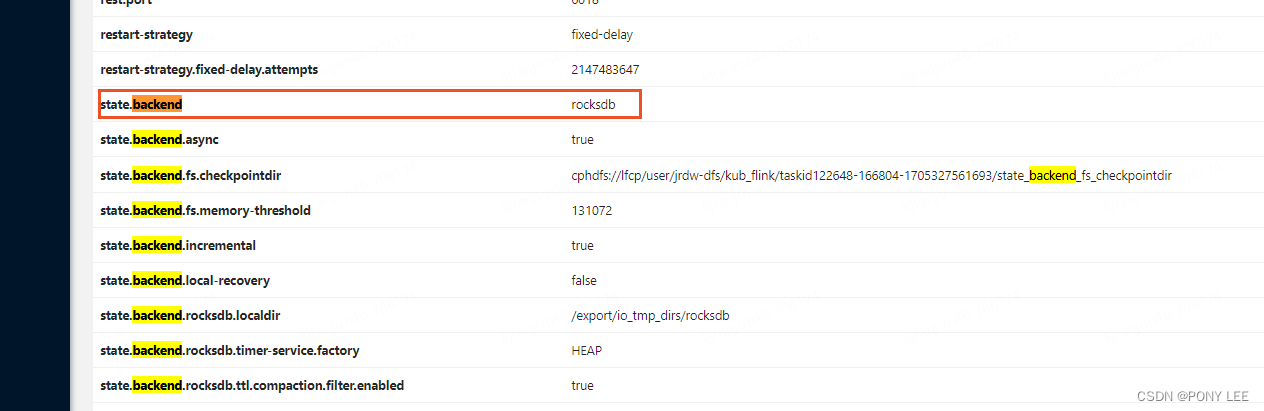
如果我们将定时器的状态数据存储在JVM堆上就可以有效提升访问性能了,因此Flink提供了配置来实现将定时器的状态数据单独存储在JVM堆上,而只使用RocksDB存储其他键值状态,配置方式是将flink-conf.yaml文件中的state.backend.rocksdb.timer-service.factory配置项设置为heap(默认为rocksdb),如下图:
-
通过Flink Web UI查看状态后端配置及内存使用情况,如下图:
状态后端的使用注意事项
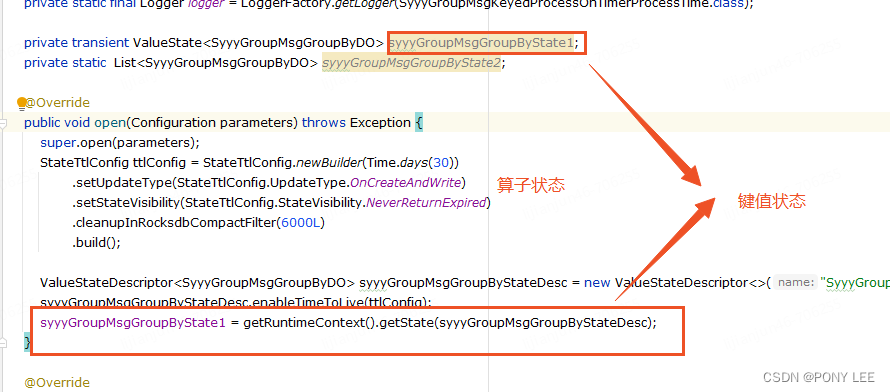
区分键值状态和算子状态
由于算子状态数据只会存储在SubTask内存中,因此在生产环境中要严格区分键值状态和算子状态的使用场景,避免因为将算子状态当做键值状态使用而导致出现内存溢出的问题。如下图:
ValueState<HashMap<String, String>>和MapState<String, String>的选型
如标题所示,作为初学者来说,如果要在键值状态中存储Map<String, String>数据结构的状态,可能会认为使用ValueState<HashMap<String, String>>或者使用MapState<String, String>都是可行的。
如果我们选择使用HashMap状态后端,那么两种方式的性能上不会有很大差异,但是如果我们选择使用RocksDB状态后端,则推荐使用MapState<String, String>,避免使用ValueState<HashMap<String, String>>。因为ValueState<HashMap<String, String>>在将数据写入RocksDB时,是将一整个HashMap<String, String>序列化为字节数组之后写入的。同样,在读取时,也是先读取到字节数组,然后反序列化为一整个HashMap<String, String>后,再给用户使用。所以每次访问和更新ValueState时,实际上都是对HashMap<String, String>这个集合类的大对象做序列化以及反序列化,而这是一个及其耗费资源的过程,很容易就会导致Flink作业产生性能瓶颈,所以极不推荐在ValueState中存储大对象。



![[MQ]常用的mq产品图形管理web界面或客户端](https://img-blog.csdnimg.cn/direct/de1cd254ef1144d9ade10d2dc3a454e7.png)