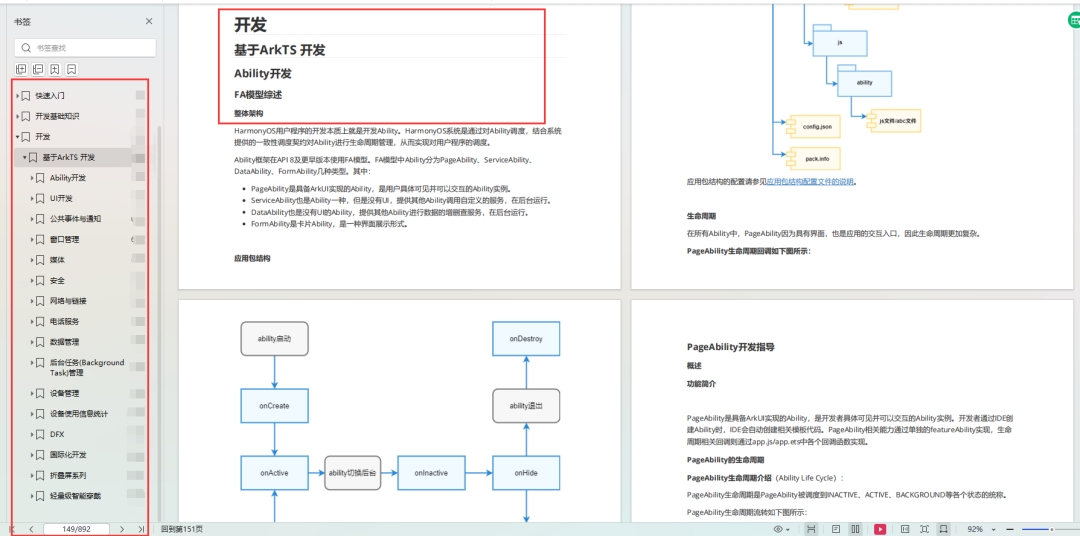
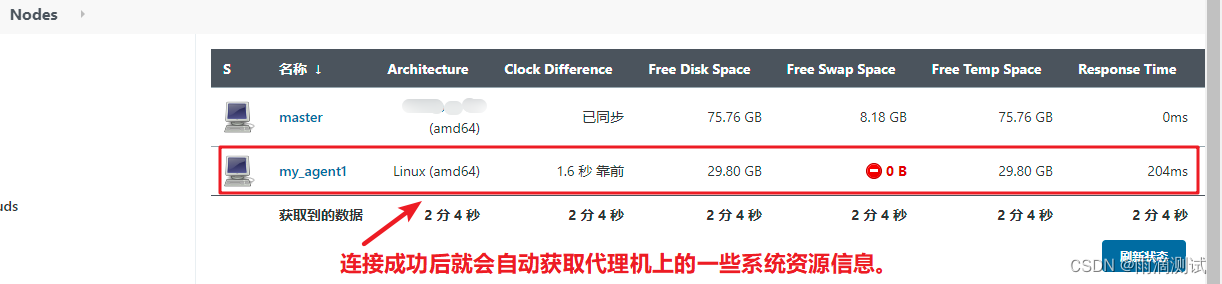
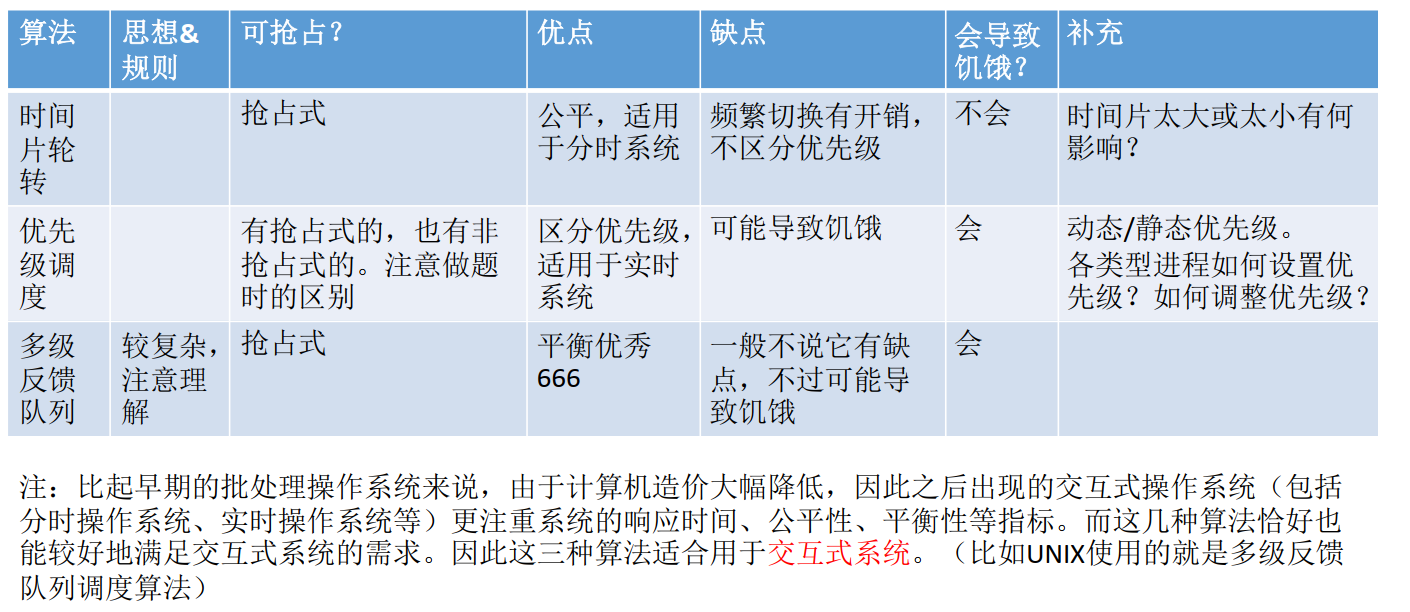
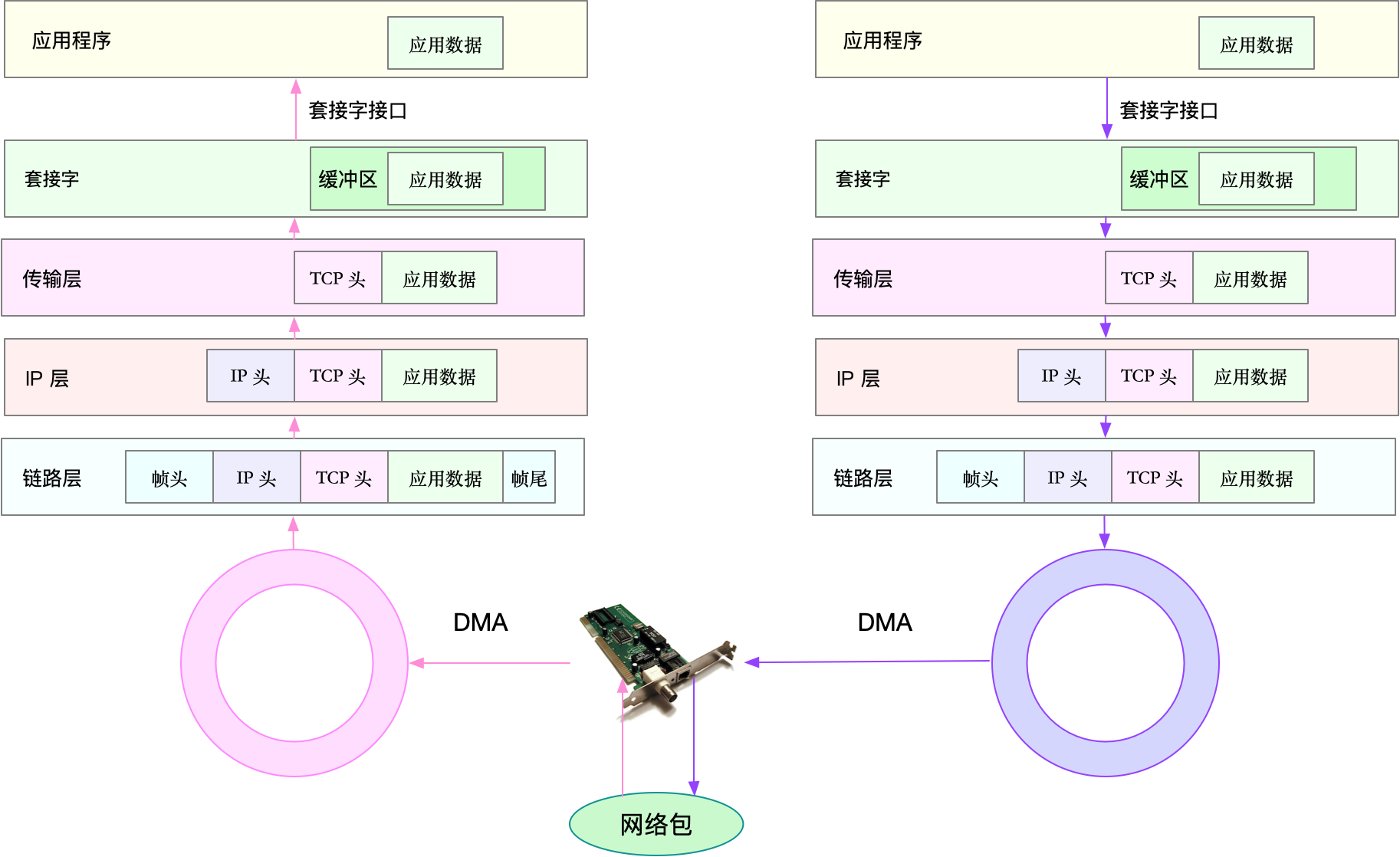
二维数组
定义方式:
1、数据类型 数组名[行数][列数];
2、数据类型 数组名[行数][列数]={{数据1,数据2},{数据3,数据4}};
3、数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4};
4、数据类型 数组名[][列数]={数据1,数据2,数据3,数据4};
建议:以上4种定义方式,利用第二种更加直观,提高代码的可读性
int main0() {
//方式1
//数据类型 数组名[行数][列数];
int arr[2][3];
arr[0][0] = 1;
arr[0][1] = 1;
arr[0][2] = 1;
arr[1][0] = 1;
arr[1][1] = 1;
arr[1][2] = 1;
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 3; j++) {
cout << arr[i][j] << " ";
}
cout << endl;
}
//推荐!更直观可读性强
//方式2
//数据类型 数组名[行数][列数]={{数据1,数据2},{数据3,数据4}};
int arr2[2][3] =
{
{1,2,3},
{4,5,6}
};
//方式3
//数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4};
int arr3[2][3] = { 1,2,3,4,5,6 };
//方式4
//数据类型 数组名[][列数]={数据1,数据2,数据3,数据4};
int arr4[][3] = { 1,2,3,4,5,6 };
system("pause");
return 0;
}
二维数组数组名
-
查看二维数组所占内存空间
-
获取二维数组首地址
int main0() {
//二维数组名称用途
//1.可以查看占用内存空间大小
int arr[2][3] =
{
{1,2,3},
{4,5,6}
};
cout << "二维数组所占内存空间为:" << sizeof(arr) << endl;//24 4*6
cout << "二维数组第一行所占内存空间为:" << sizeof(arr[0]) << endl;//12 4*3
cout << "二维数组第一个元素所占内存空间为:" << sizeof(arr[0][0]) << endl;//4
cout << "二维数组的行数为" << sizeof(arr) / sizeof(arr[0]) << endl;//2
cout << "二维数组的列数为" << sizeof(arr[0]) / sizeof(arr[0][0]) << endl;//3
//2.可以查看二维数组的首地址
cout << "二维数组的首地址为" << arr << endl;
cout << "二维数组的第一行首地址为" << (int)arr[0] << endl;
cout << "二维数组的第二行首地址为" << (int)arr[1] << endl;
cout << "二维数组的第一个元素首地址为" << (int)&arr[0][0] << endl;
cout << "二维数组的第二个元素首地址为" << (int)&arr[0][4] << endl;
system("pause");
return 0;
}
/*考试成绩统计
* 有三名同学(张三,李四,王五),在一次考试中的成绩分别如下表,请分别输出三名同学的总成绩
* 语文 数学 英语
* 张三 100 100 100
* 李四 90 50 100
* 王五 60 70 80
*
*
* 1.创建二维数组:3行3列
* 2.统计考试成绩:让每行的三列相加求和
*
*/
int main() {
int arr[3][3] =
{
{100,100,100},
{90,50,100},
{60,70,80}
};
int sum = 0;
string names[3] = { "张三","李四","王五" };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
sum += arr[i][j];
}
cout << names[i]<<"总分为"<<sum << endl;
sum = 0;
}
system("pause");
return 0;
}
函数
作用:将一段经常使用的代码封装起来,减少重复代码
一个较大的程序,一般分为若干个程序块,每个模块实现特定的功能
函数的定义
1.返回值类型
2.函数名
3.参数列表
4.函数体语句
5,return表达式
语法:
返回值类型 函数名 (参数列表)
{
函数体语句
return表达式
}
在这里插入图片描述
函数的调用
功能:使用定义好的函数
语法:函数名 (参数)
//函数定义
int add(int num1, int num2)//定义中num1,num2称为形式参数,简称形参
{
int sum = num1 + num2;
return sum;
}
int main() {
int a = 10;
int b = 10;
//调用add函数
int sum = add(a, b);//调用时的a,b称为实际参数,简称实参
cout << "sum=" << sum << endl;
a = 100;
b = 100;
int sum2 = add(a, b);
cout << "sum2=" << sum2 << endl;
system("pause");
return 0;
}
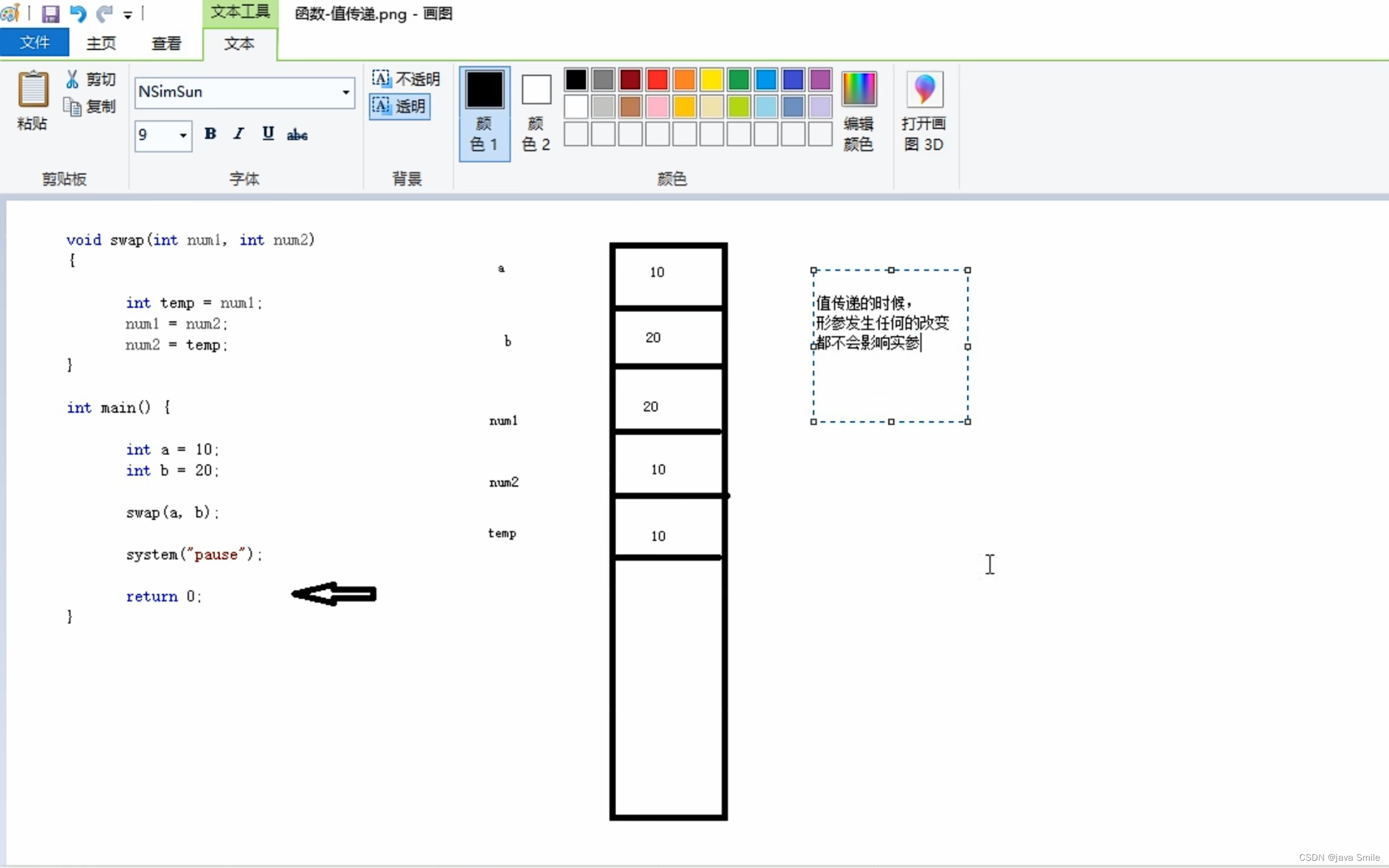
值传递
-
函数调用时实参将数值传给形参
-
值传递时,如果形参发生变化,不会影响实参
//定义函数,实现两个数字进行交换函数
//如果函数不需要返回值,声明的时候返回值写void
void swap(int num1, int num2) {
cout << "交换前:" << endl;
cout << "num1=" << num1 << endl;
cout << "num2=" << num2 << endl;
int temp = num1;
num1 = num2;
num2 = temp;
cout << "交换后:" << endl;
cout << "num1=" << num1 << endl;
cout << "num2=" << num2 << endl;
//return; 当函数声明的时候,不需要返回值,可以不写reurn
}
int main() {
int a = 10;
int b = 20;
cout << "a=" << a << endl;
cout << "b=" << b << endl;
//值传递时,函数的形参发生改变,并不会影响实参
swap(a, b);
cout << "a=" << a << endl;
cout << "b=" <<b<< endl;
system("pause");
return 0;
}
函数的常见样式
1.无参无返
2.有参无返
3.无参有返
4.有参有返
函数的声明
作用:告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义
- 函数的声明可以多次,但函数的定义只有一次,一般声明也只写一次
函数的分文件编写
作用:让代码结构更加清晰
函数分文件编写一般有4个步骤
1.创建后缀名为.h的头文件
2.创建后缀名为.cpp的源文件
3.在头文件中写函数的声明
4.在源文件中写函数的定义
#include<iostream>
using namespace std;
//函数的声明
void swap(int a, int b);
#include "swap.h"
//函数的定义
void swap(int num1, int num2) {
int temp = num1;
num1 = num2;
num2 = temp;
cout << "num1=" << num1 << endl;
cout << "num2=" << num2 << endl;
}
#include<iostream>
using namespace std;
#include "swap.h"
//函数的声明
//void swap(int a, int b);
//函数的定义
//void swap(int num1, int num2) {
//
// int temp = num1;
// num1 = num2;
// num2 = temp;
//
// cout << "num1=" << num1 << endl;
// cout << "num2=" << num2 << endl;
//
//}
//1.创建后缀名为.h的头文件
//2.创建后缀名为.cpp的源文件
//3.在头文件中写函数的声明
//4.在源文件中写函数的定义
int main() {
int a = 10;
int b = 20;
cout << "a=" << a << endl;
cout << "b=" << b << endl;
//值传递时,函数的形参发生改变,并不会影响实参
swap(a, b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
system("pause");
return 0;
}
指针
指针的作用:可以通过指针简介访问内存
-
内存编号是从0开始记录的,一般用十六进制数字表示
-
可以利用指针变量保存地址
指针变量定义和使用
指针变量定义语法:数据类型*变量名;
int main() {
//1.定义指针
int a = 10;
//指针定义的语法:数据类型 * 指针变量名
int * p;
//让指针记录变量a的地址
p = &a;
cout << "a的地址为:" << &a << endl;
cout << "指针p=" << p << endl;
cout << "*p=" << *p << endl;//10
//2.使用指针
//可以通过解引用的方式来找到指针指向的内存
//指针前加 * 代表解引用找到指针指向的内存中的数据
*p = 1000;
cout << "a=" << a << endl;//1000
cout << "*p=" << *p << endl;//1000
system("pause");
return 0;
}
指针所占内存空间
在32为操作系统下:占用4个字节空间,64位下占8个字节。
int main() {
//指针所占内存空间
int a = 10;
//int * p;
//p = &a;
int* p = &a;
cout << "sizeof(int*) =" << sizeof(p) << endl;//8
cout << "sizeof(float*) =" << sizeof(float *) << endl;//8
cout << "sizeof(double*) =" << sizeof(double *) << endl;//8
cout << "sizeof(char*) =" << sizeof(char *) << endl;//8
system("pause");
return 0;
}
空指针和野指针
空指针:指针变量指向内存中编号为0的空间
用途:初始化指针变量
注意:空指针指向的内存是不可以访问的
int main() {
//空指针
//1.空指针用于给指针变量进行初始化
int* p = NULL;
//2.空指针是不可以进行访问的
//0~255之间的内存编号是系统占用的因此不可以访问
//cout << *p << endl;报错
//*p = 100;报错
system("pause");
return 0;
}
野指针:指变量指向非法的内存空间
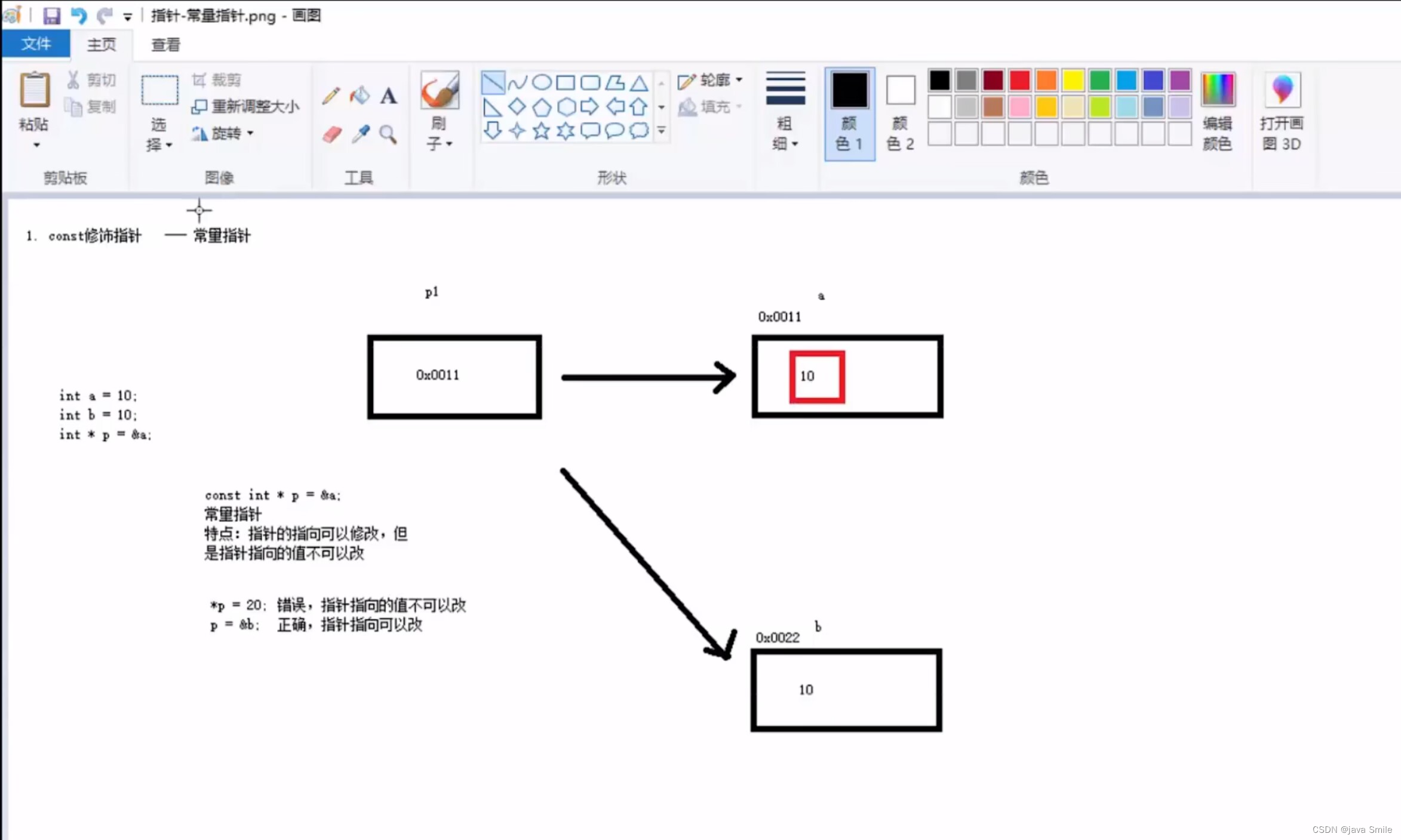
const修饰指针
const修饰指针 — 常量指针:指针的指向可以修改,但是指针指向的值不可以改
const int * p = &a;
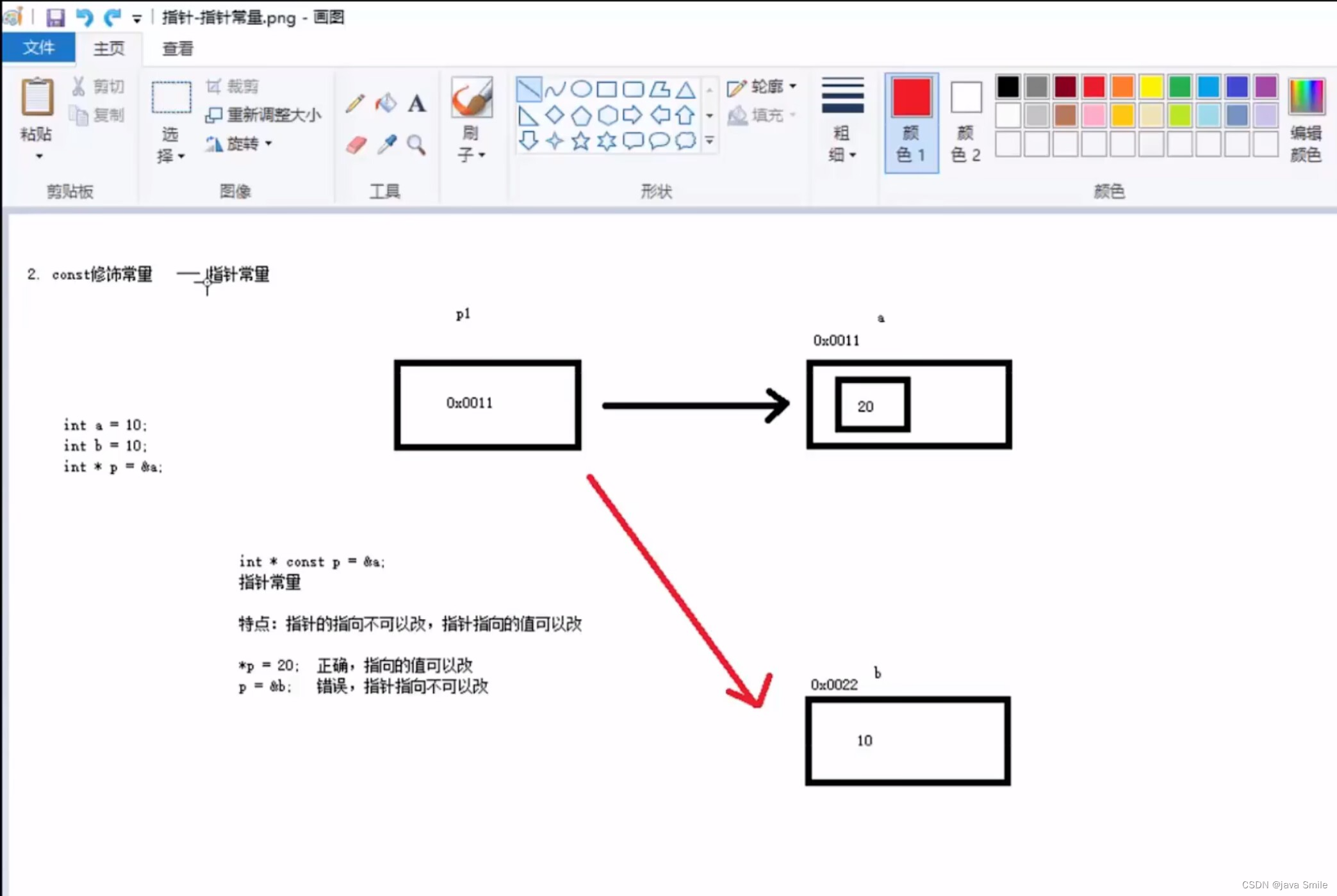
const修饰常量 — 指针常量:指针的指向不可以改,但是指针指向的值可以改
int * const p2 = &a;
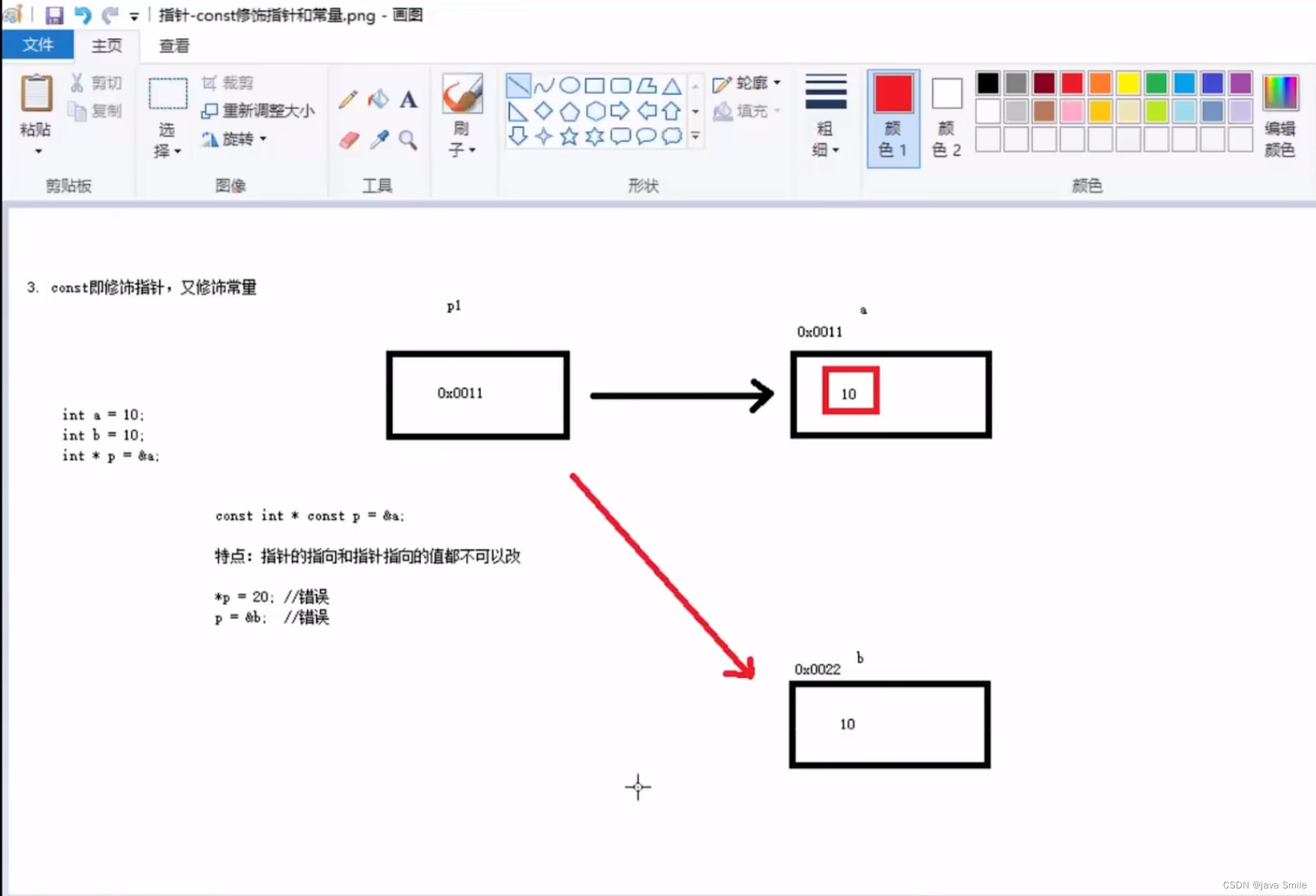
const既修饰指针,又修饰常量:指针的指向和指针指向的值都不可以改
const int * const p3 = &a;
指针和数组
作用:利用指针访问数组中元素
int main() {
//指针和数组
//利用指针访问数组中的元素
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
cout << "第一个元素为:" << arr[0] << endl;
int* p = arr;//arr就是数组首地址
cout << "利用指针访问第一个元素:" << *p << endl;
p++;//让指针向后偏移4个字节
cout << "利用指针访问第二个元素:" << *p << endl;
cout << "利用指针遍历数组" << endl;
int* p2 = arr;
for (int i = 0; i < 10; i++) {
//cout<<arr[i]<<endl
cout << *p2 << endl;
p2++;
}
system("pause");
return 0;
指针和函数
作用:利用指针作函数参数,可以修改实参的值
如果不想修改实参,就用值传递,如果想修改实参,就用地址传递
//实现两个数字进行交换
void swap01(int num1, int num2) {
int temp = num1;
num1 = num2;
num2 = temp;
cout << "交换后:" << endl;
cout << "num1=" << num1 << endl;
cout << "num2=" << num2 << endl;
}
void swap02(int* p1, int* p2) {
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main() {
//指针和函数
//1.值传递
int a = 10;
int b = 20;
//swap01(a, b);//值传递不会改变实参
//2.地址传递
//如果是地址传递,可以改变实参
swap02(&a, &b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
system("pause");
return 0;
}
指针、数组、函数
#include<iostream>
using namespace std;
/*
* 封装一个函数,利用冒泡排序,实现对整型数组的升序排序
* 例如数组:int arr[10] = {4,3,6,9,1,2,10,8,7,5};
*
*/
// 参数1 数组的首地址 参数2 数组长度
void bubbleSort(int * arr, int len) {//int * arr 也可以写为int arr[]
for (int i = 0; i < len - 1; i++) {
for (int j = 0; j < len - 1 - i; j++) {
//如果j>j+1的值 交换数字
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
//打印数组
void printArray(int * arr, int len) {
for (int i = 0; i < len; i++){
cout<<arr[i]<<endl;
}
}
int main() {
//1.创建数组
//2.创建函数,实现冒泡排序
//3.打印排序后的数组
//1.创建数组
int arr[10] = { 4,3,6,9,1,2,10,8,7,5 };
//数组长度
int len = sizeof(arr) / sizeof(arr[0]);
// 2.创建函数,实现冒泡排序
bubbleSort(arr, len);
//3.打印排序后的数组
printArray(arr, len);
system("pause");
return 0;
}