探秘缓冲池的核心奥秘,揭示终极洞察
- 缓存池BufferPool机制
- MySQL缓冲池
- 缓冲池
- 缓冲池的问题
- 缓冲池的原理
- 数据预读
- 程序的局部性原则(集中读写原理)
- 时间局部性
- 空间局部性
- innodb的数据页
- 查询InnoDB的数据页
- InnoDB缓冲池缓存数据页
- InnoDB缓存数据的淘汰算法
- 传统的LRU是如何进行缓冲页管理
- 页已经在缓冲池
- 链表数据结构
- 页不在缓冲池
- MySQL的LRU是如何进行缓冲页管理
- 预读失效
- 优化预读失效
- 分代进行LRU缓存处理
- 案例分析
- MySQL缓冲池污染
- 执行过程如下
- 优化方案
- 老生代停留时间窗口
- 最后总结
- 有三个比较重要的参数
- innodb_buffer_pool_size
- innodb_old_blocks_pct
- innodb_old_blocks_time
缓存池BufferPool机制
应用系统分层架构:一个优化策略是将最常访问的数据存放在缓存中,以加快数据访问速度,避免频繁地访问数据库。
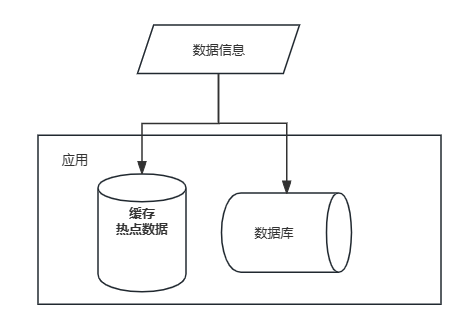
操作系统:借助缓冲池机制来优化数据访问,从而避免了反复直接访问磁盘的开销,极大地提升了数据访问的速度。缓冲池通过在内存中临时存储最常访问的数据,将频繁读写的I/O操作转化为对内存中数据的操作,极大地降低了磁盘访问的延迟和系统开销。
MySQL缓冲池
MySQL作为一个存储系统,有着一个关键的优化机制——缓冲池(buffer pool),它极大地提高了数据的访问效率,避免了频繁的磁盘IO操作。通过将常用的数据存储在内存中,MySQL可以快速响应查询请求,减少耗时的磁盘访问。这一优化机制在提升数据库性能方面起到了重要的作用。
在MySQL数据库中我们最常用的引擎就是InnoDB,因此我们采用InnoDB的缓冲池进行分析和介绍。
缓冲池
InfoDB引擎为了优化数据访问并提升速度,系统常常将缓存表数据和索引数据加载到缓冲池中,以避免频繁的磁盘IO操作。这种缓存机制大大减少了磁盘IO的开销,同时加速了数据的读取和写入过程。
缓冲池的问题
凡事都具备两面性,抛开数据易失性不说,访问快速的反面是存储容量小:
- 缓存访问快,但容量小,数据库存储了200G数据,缓存容量可能只有64G;
- 内存访问快,但容量小,买一台笔记本磁盘有2T,内存可能只有16G;
因此,在优化数据访问时,只能将最常访问的热门数据放置在最近的位置,以最大程度地减少对磁盘的访问。为了更好的可以实现优化数据库以及对应的缓冲池,我们先去研究一下数据库的底层原理机制。
缓冲池的原理
在进行详细介绍之前,让我们先重点了解一下预读的概念。
数据预读
预读是一种优化策略,它通过提前加载数据到缓冲区内存中,以减少磁盘IO的次数和延迟。当系统预测到将来可能需要某些数据时,它会主动将这些数据从磁盘读取到内存中,并且放置在缓冲区,以备后续的快速访问。
磁盘读写并非按需读取,而是按页读取的方式进行。每次至少读取一页数据(假设为4KB)。如果未来需要读取的数据正好在这一页中,就可以避免后续的磁盘IO操作,从而提高数据的访问效率。
程序的局部性原则(集中读写原理)
在数据访问中,一般遵循着“集中读写”的原则。也就是说,当使用某个数据时,很有可能会连续使用其附近的数据。这就是著名的“局部性原理”。
基于这个原理,预先加载数据是一种有效的优化策略,因为它可以减少磁盘IO操作次数,提高数据访问的效率。
程序的局部性原理是指在程序中存在着数据和指令的访问局部性的倾向。具体来说,局部性原理包括以下两个方面:
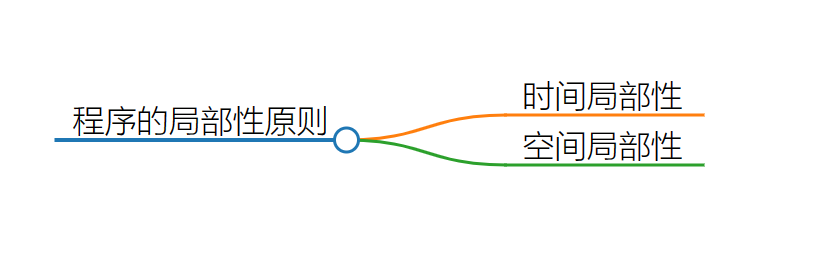
时间局部性
指程序中某个数据项或指令在一段时间内可能被重复访问。例如,循环结构中的数据和指令在每次迭代中都会被反复访问,因此在一段时间内都具有较高的访问概率。
空间局部性
指程序中相邻的数据项或指令很可能被连续访问。这是因为在程序中,数据和指令通常以连续的内存地址存储,因此当访问一个数据或指令时,其附近的数据或指令很可能会被紧接着访问。
innodb的数据页
默认情况下,innodb.pagesize参数的值为16KB,这是InnoDB的推荐值,通常情况下,16KB的页面大小适用于大多数应用,但对于特定的工作负载和硬件环境,可以进行一些测试和调优以确定最佳的页面大小设置。不过,可以根据实际需求进行调整。
较小的页面大小可以提高磁盘空间的利用效率,但可能会导致更多的磁盘IO操作。而较大的页面大小可以减少IO操作,但会占用更多的内存。
查询InnoDB的数据页
-
连接到MySQL服务器。
-
运行以下命令登录到MySQL命令行界面或查询工具中:
SHOW VARIABLES LIKE 'innodb_page_size';或者
SELECT @@innodb_page_size; -
运行该命令后,会返回当前InnoDB数据页的大小。通常情况下,默认的InnoDB数据页大小为16KB。
注意,
innodb_page_size是一个只读变量,它反映了当前InnoDB数据页的大小。如果在编译时进行了自定义设置,那么返回的值可能会不同。在选择合适的innodb.pagesize值时,需要综合考虑数据库的性能需求以及服务器硬件配置。
InnoDB缓冲池缓存数据页
磁盘访问按页读取能够提高性能,因此缓冲池通常也按页缓存数据。这种设计有助于减少磁盘IO操作,并提高数据访问的效率,那么InnoDB是以什么算法,来维护这些缓冲页呢?
InnoDB缓存数据的淘汰算法
最常见的数据页置换算法是LRU(Least Recently Used,最近最不常用使用)算法。LRU算法基于一个简单的原则,即最近最不常用的数据页很可能在未来也不会很频繁使用,因此可以被替换出缓冲池以腾出空间给新的页数据。
注意,尽管像内存缓存(例如memcached)和操作系统中的缓冲池都使用LRU算法来进行页置换管理,但MySQL中的InnoDB存储引擎的页置换策略略有不同。
传统的LRU是如何进行缓冲页管理
最常见的数据页置换策略确实是将新加入缓冲池的页放置在LRU链表的头部,作为最新访问的元素,确保它们最后被淘汰。然而,具体的数据页置换策略可以分为以下两种情况:
页已经在缓冲池
只做“转移"LRU头部的动作,而没有页被淘汰;
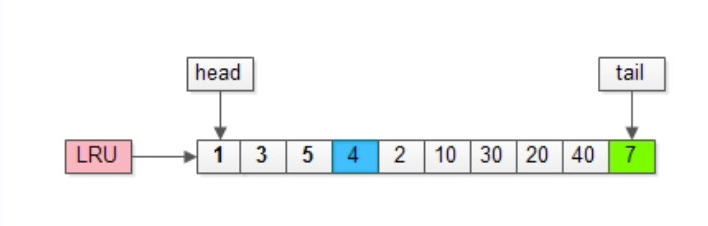
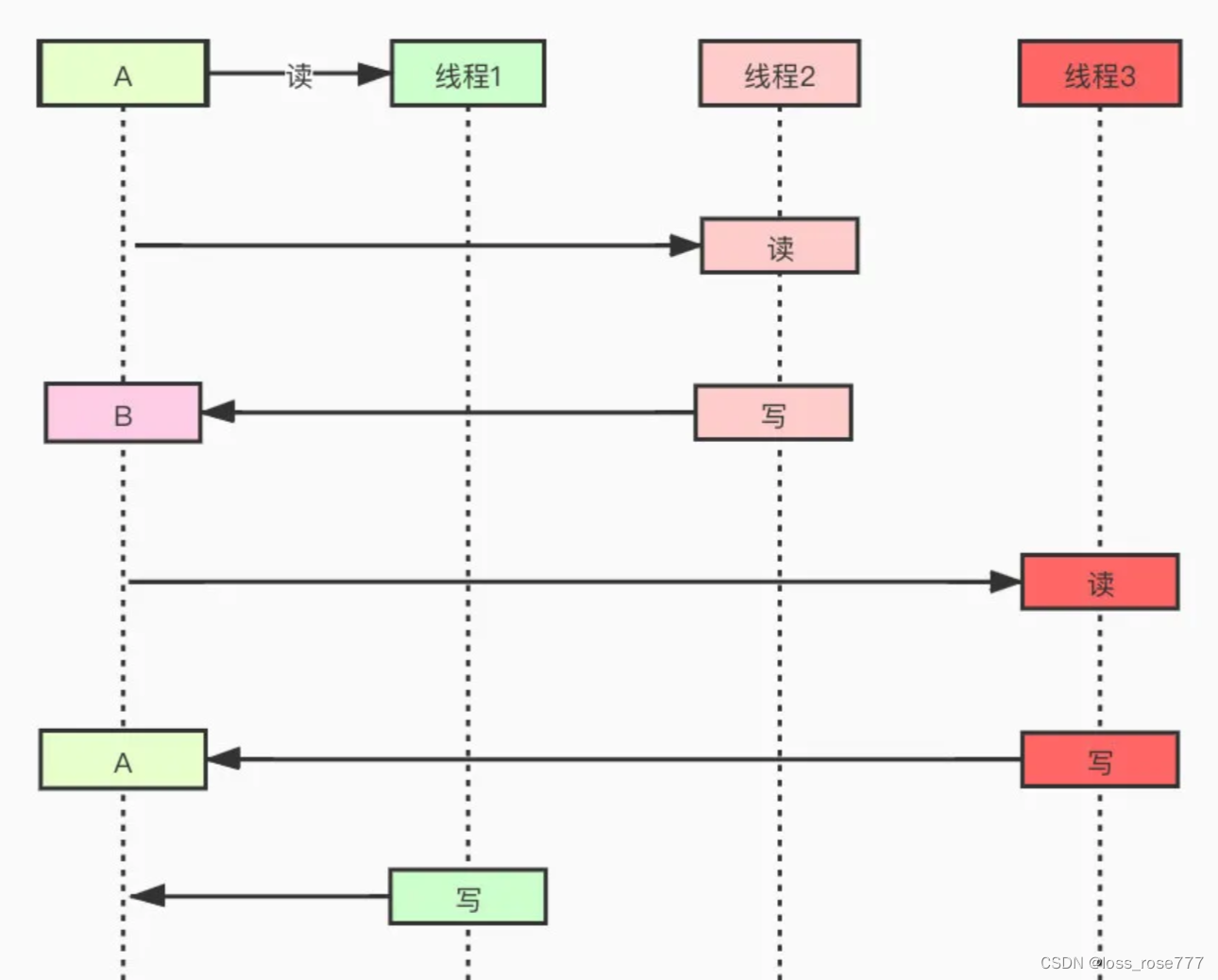
考虑到上图,假设缓冲池的LRU长度为10,并且当前缓存的页为1, 3, 5,…, 40, 7。现在需要访问的数据位于页号为4的页中,由于页号为4的页不在缓冲池中,首先需要将其放入LRU链表的头部,表示最近被访问。
同时,由于缓冲池已满,需要进行淘汰操作。
链表数据结构
为了减少数据移动的开销,常见的做法是使用链表来实现LRU(Least Recently Used,最近最少使用)算法。
具体地说,LRU缓存通常使用双向链表来维护缓存中页的顺序。当一个页被访问时,它会被移动到链表的头部,表示为最近被访问过的页。当需要淘汰页时,可以从链表的尾部移除最久未被访问的页。
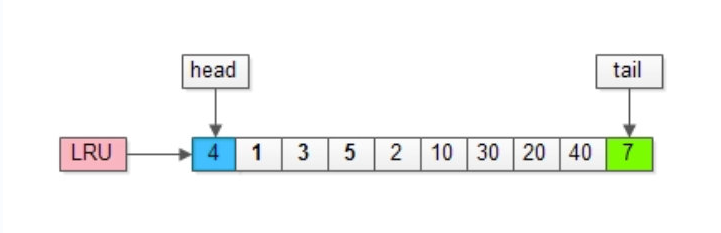
页不在缓冲池
除了做"放入"LRU头部的动作,还要做“淘汰"LRU尾部页的动作,假如,再接下来要访问的数据在页号为50的页中。
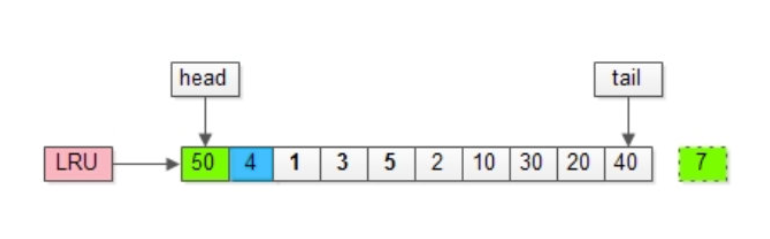
页号为50的页,原来不在缓冲池里,把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
MySQL的LRU是如何进行缓冲页管理
这里有两个问题需要考虑,导致MySQL不直接采用类似memcache等软件的方法:
-
预读失效:在MySQL中,预读机制的有效性受制于访问模式的复杂性。由于MySQL常用于事务性应用和复杂查询,访问模式往往难以准确预测,从而导致预读策略的准确性下降。因此,在MySQL中完全依赖预读机制无法保证高效的数据访问。
-
缓冲池污染:缓冲池是MySQL用于存储数据页的关键组件,它存储了最常访问的数据和索引。与简单的缓存系统不同,MySQL的缓冲池需要维护多种复杂的数据结构,如锁、日志等,以保证ACID事务的一致性。
预读失效
在某些情况下,由于预读机制(Read-Ahead)的存在,某些页被提前放入了缓冲池。然而,最终MySQL并没有从这些页中获取所需的数据,这被称为预读失效。
优化预读失效
- 预读失败的页,停留在缓冲池LRU里的时间尽可能短;
- 真正被读取的页,才挪到缓冲池LRU的头部,以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
分代进行LRU缓存处理
将LRU划分为新生代和老生代两个部分,可以更加高效地管理缓冲池中的页。热度高的页往往在新生代中得到缓存,并更长时间地保持在缓冲池中,从而提高其快速访问的可能性。相反,热度较低的页会逐渐被移动到老生代,让出空间给新的热页,并减少对LRU链表的操作次数。
新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head)。
-
新生代:用来缓存最近被访问的页的部分,它通常拥有较小的容量。当一个页被访问时,它会被移动到新生代的头部,表示为最近的访问,这个阶段被称为“热化”(hot phase),即页被频繁访问的阶段。
-
老生代:用于缓存较长时间未被访问的页,它通常拥有较大的容量。在新生代中停留一段时间后,如果一个页仍然没有被访问,它会被移动到老生代的头部。这个阶段被称为“冷化”(cold phase),即页的热度降低并逐渐被冷落的阶段。
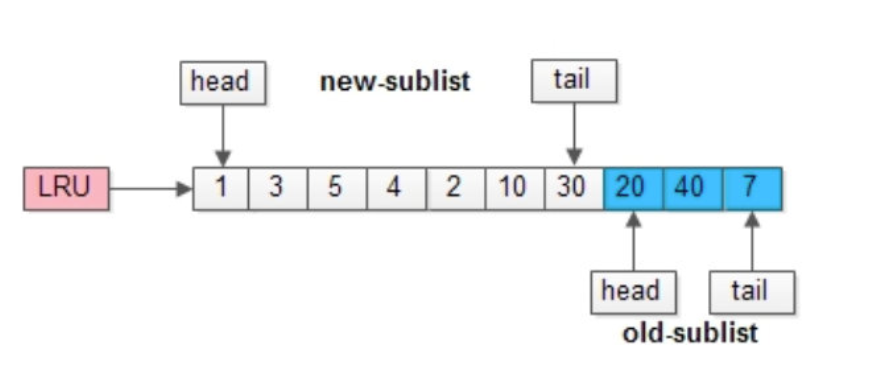
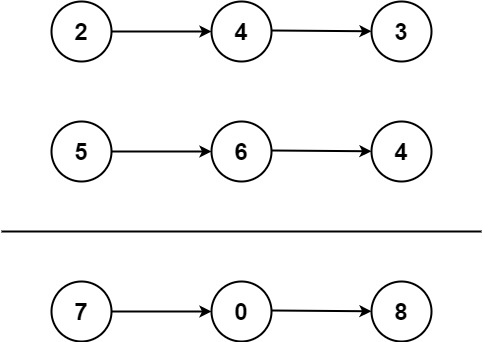
以一个例子来说明,整个缓冲池的LRU可以如上图所示:缓冲池的总长度为10,前7个页是新生代,接下来的3个页是老生代,新生代和老生代首尾相连。
案例分析
在这个例子中,前7个页(页号4至页号6)位于新生代,它们是最近被访问的,因此被放置在LRU链表的头部。接下来的3个页(页号8至页号10)位于老生代,它们是相对较旧的页,在新生代的页都被放满之后才会被放置。
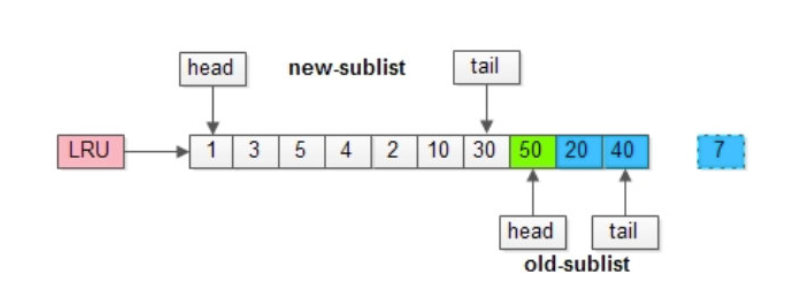
场景1:页号为50的新页被预读加入缓冲池,当页面50从老年代头部插入时,老年代尾部的页面(整体尾部)将被淘汰。假设页面50不会被真正读取,即预读失败,它将比新生代的数据更早从缓冲池中淘汰出去。
场景2:页号50立即被读取,例如,SQL访问了页面中的行数据,那么页面50将立即被移到新生代的头部,并将新生代的页面挤出,进入老年代。在这种情况下,没有页面被真正淘汰。
改进版的缓冲池LRU算法能够有效解决"预读失败"的问题,不要因为害怕预读失败而取消预读策略,因为大部分情况下,局部性原理是成立的,预读是有效的。
MySQL缓冲池污染
当某个SQL语句需要批量扫描大量数据时,可能会导致将缓冲池中的所有页面替换出去,进而导致热数据被移出缓冲池,从而导致MySQL性能急剧下降。这种情况被称为缓冲池污染。
例如,有一个数据量较大的表,当执行之后,虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页。
执行过程如下
- 将页面加载到缓冲池中,并将其插入到老年代的头部。
- 从页面中读取相关的行数据,并将其插入到新生代的头部。
- 对每个行数据的条件字段与预想值进行比较,如果符合条件,则将其加入到结果集中。
- 继续扫描所有页面中的所有行数据,直到完成。
然而,这种方式会导致所有的数据页面都被加载到新生代的头部,但只会访问一次,这将导致真正的热数据被大量换出。
优化方案

老生代停留时间窗口
假设 T 为老生代停留时间窗口。
- 插入到老生代头部的页面,即使立即被访问,也不会立即放入新生代头部。
- 只有当页面满足两个条件时,才会被放入新生代头部:被访问过,并且在老生代停留时间大于 T。

这意味着,即使页面被立即访问,也不会立即被移动到新生代头部。只有在页面被访问且在老生代停留时间。
继续举例,假如批量数据扫描,有51,52,53,54等4个数据页将要依次被访问。
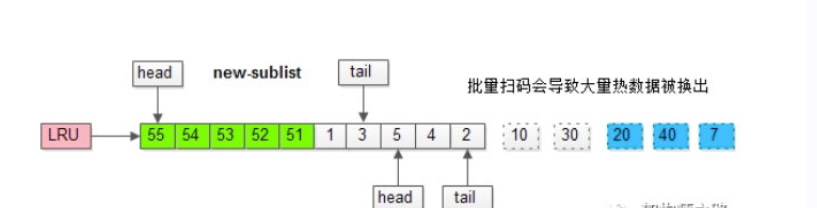
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
最后总结
-
预读机制:给我们一个启示,即可以将一些可能需要访问的页提前加载到缓冲池中,以避免未来的磁盘IO操作。通过提前加载数据,我们可以利用局部性原理,预测并预先缓存未来可能用到的数据页,从而提高数据访问的性能和效率,减少响应时间。
-
MySQL在设计上需要综合考虑事务性、复杂查询等方面的要求,采用了更加复杂的缓冲池管理方式,以确保高性能和数据一致性。这包括使用LRU算法、预读机制、自适应策略等来最大程度地利用内存资源,同时解决预读失效和缓冲池污染等问题,并提供高效、稳定的数据库服务。
缓冲池污染:由于大量数据扫描操作而引起的缓冲池中的热数据被替换出去的情况,为了解决这个问题,可以通过合理配置缓冲池的大小,调整相关缓存参数,或者改进SQL语句的扫描方式,以减少对缓冲池的影响,从而提高MySQL的性能。
有三个比较重要的参数
innodb_buffer_pool_size
innodb_buffer_pool_size 是 MySQL 中 InnoDB 存储引擎的一个配置参数,用于指定 InnoDB 缓冲池的大小。
mysql>show variables like '%innodb_buffer_pool_size%';

innodb_old_blocks_pct
innodb_old_blocks_pct是InnoDB存储引擎的一个参数,用于指定LRU链表中被认为是老生代页的比例。
默认情况下,innodb_old_blocks_pct的值为37。这意味着LRU链表中的前37%的页将被视为新生代,而后63%的页将被视为老生代。
mysql>show variables like '%innodb_old_blocks_pct%';

较大的值表示更多的页被视为老生代页,而较小的值则表示更少的页被认为是老生代页。
innodb_old_blocks_time
innodb_old_blocks_time 的单位是秒 (s), MySQL 中 InnoDB 存储引擎的一个配置参数,用来确定一个数据块在缓冲池中没有被访问的时间超过多久后被认为是"旧"的。
mysql>show variables like '%innodb_old_blocks_time%