之前几节中,我们一直在使用深度学习框架的高级API直接获取张量格式的图像数据集。 但是在实践中,图像数据集通常以图像文件的形式出现。 本节将从原始图像文件开始,然后逐步组织、读取并将它们转换为张量格式。
我们之前对CIFAR-10数据集做了一个实验。CIFAR-10是计算机视觉领域中的一个重要的数据集。 本节将运用我们在前几节中学到的知识来参加CIFAR-10图像分类问题的Kaggle竞赛,(比赛的网址是https://www.kaggle.com/c/cifar-10)。
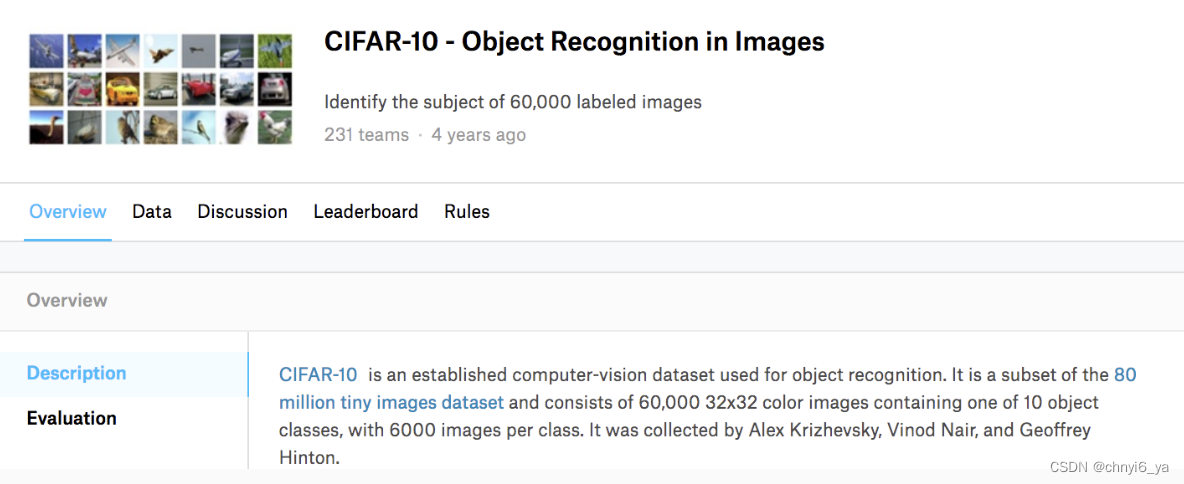
如图,显示了竞赛网站页面上的信息。 为了能提交结果,首先需要注册一个Kaggle账户。竞赛用的数据集可通过点击“Data”选项卡获取。
首先,导入竞赛所需的包和模块。
import collections
import math
import os
import shutil # python一个用来操作文件的包
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
1. 获取并组织数据集
比赛数据集分为训练集和测试集,其中训练集包含50000张、测试集包含300000张图像。 在测试集中,10000张图像将被用于评估,而剩下的290000张图像将不会被进行评估,包含它们只是为了防止手动标记测试集并提交标记结果。 两个数据集中的图像都是png格式,高度和宽度均为32像素并有三个颜色通道(RGB)。
这些图片共涵盖10个类别:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。 上图的左上角显示了数据集中飞机、汽车和鸟类的一些图像。
1.1 下载数据集
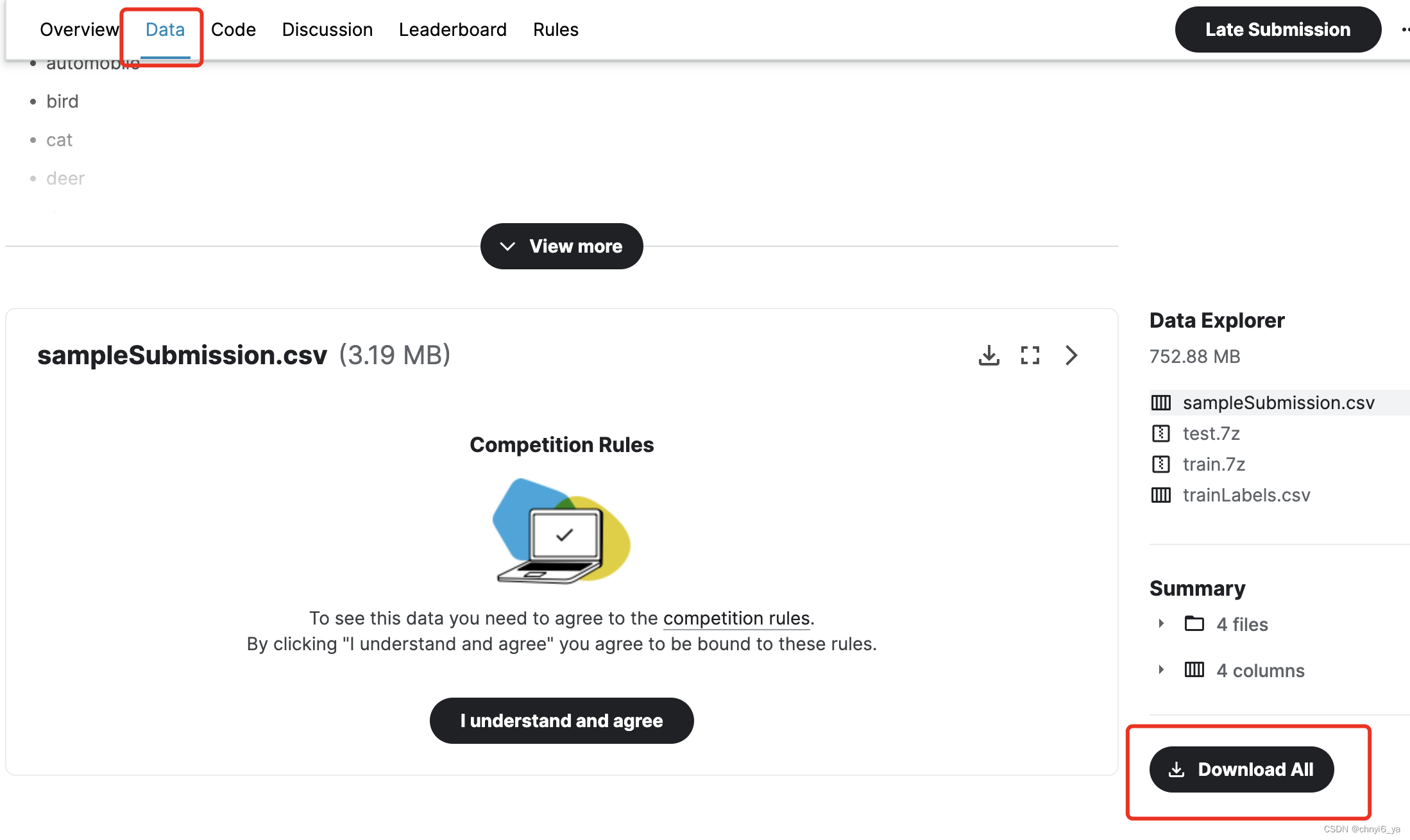
登录Kaggle后,我们可以点击 图中显示的CIFAR-10图像分类竞赛网页上的“Data”选项卡,然后单击“Download All”按钮下载数据集。 在../data中解压下载的文件并在其中解压缩train.7z和test.7z后,在以下路径中可以找到整个数据集:
-
…/data/cifar-10/train/[1-50000].png
-
…/data/cifar-10/test/[1-300000].png
-
…/data/cifar-10/trainLabels.csv
-
…/data/cifar-10/sampleSubmission.csv
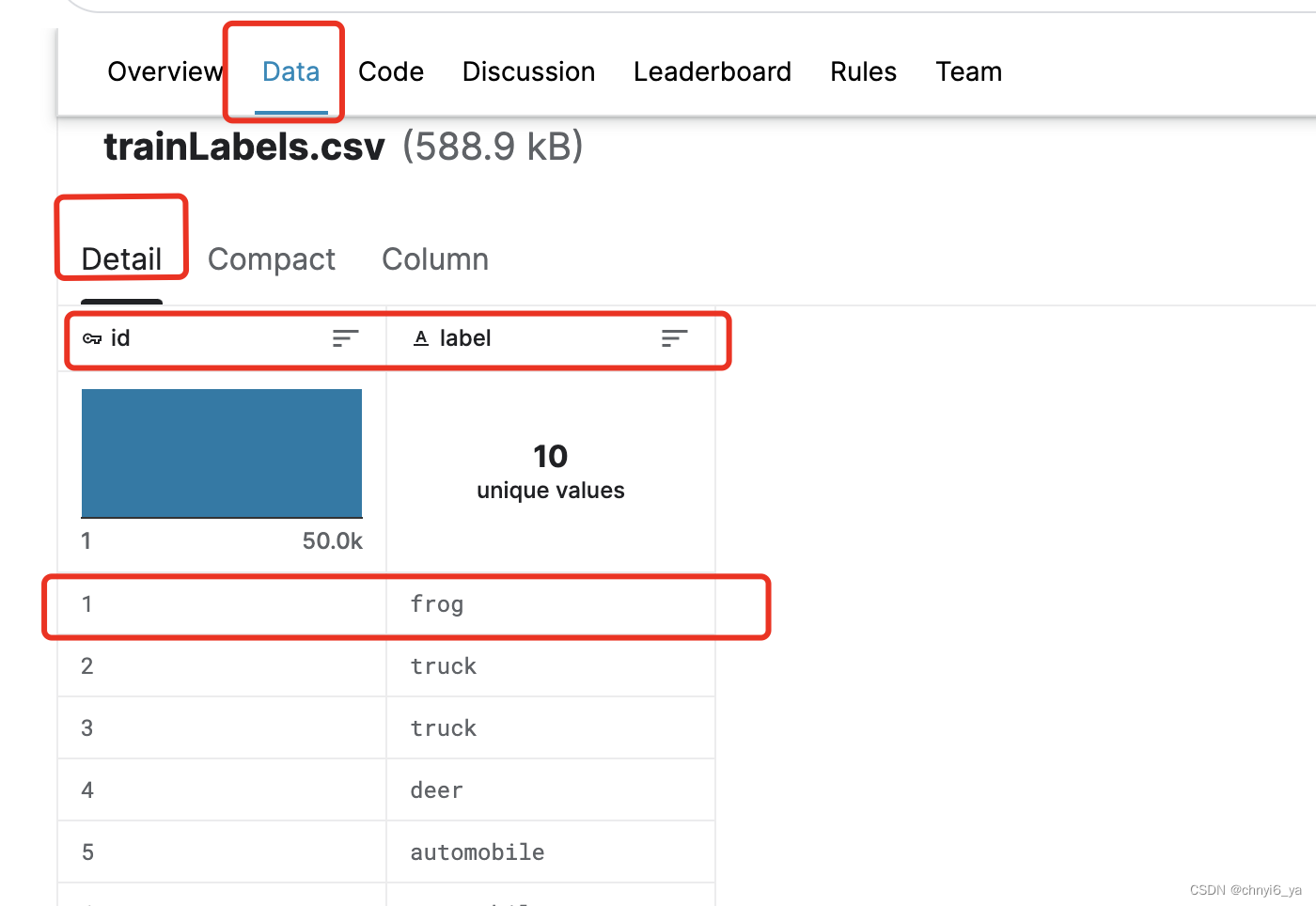
train和test文件夹分别包含训练和测试图像,trainLabels.csv含有训练图像的标签, sample_submission.csv是提交文件的范例。
为了便于入门,我们提供包含前1000个训练图像和5个随机测试图像的数据集的小规模样本(挑了前1000个来训练,每一类拿5张来测试)。 要使用Kaggle竞赛的完整数据集,需要将以下demo变量设置为False。
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip',
'2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
# 如果使用完整的Kaggle竞赛的数据集,设置demo为False
# 然后把数据放在上一层的data文件夹下的cifar-10
demo = True
if demo:
data_dir = d2l.download_extract('cifar10_tiny')
else:
data_dir = '../data/cifar-10/'
1.2 整理数据集
我们需要整理数据集来训练和测试模型。 首先,我们用以下函数读取CSV文件中的标签,它返回一个字典,该字典将文件名中不带扩展名的部分映射到其标签。
def read_csv_labels(fname):
"""读取fname文件名来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:] # 一行一行读,从第一行开始读,不要读第0行
# rstrip:用来去除结尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))
# 数据集中label是放在trainLabels.csv文件中
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
labels # 答应labels看一下返回的字典是怎样的
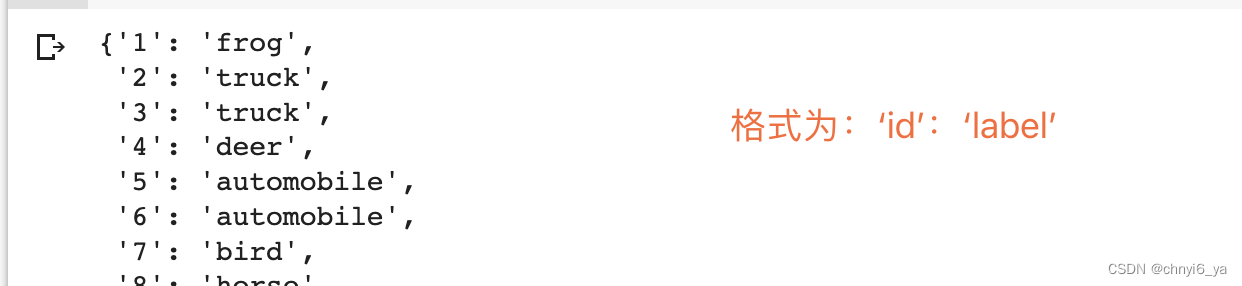
与Kaggle上是相一致的:
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))
看一下训练样本数和类别数:

接下来,我们定义reorg_train_valid函数来将验证集从原始的训练集中拆分出来。 此函数中的参数valid_ratio是验证集中的样本数与原始训练集中的样本数之比。 更具体地说,令 𝑛 等于样本最少的类别中的图像数量,而 𝑟 是比率。 验证集将为每个类别拆分出 max(⌊𝑛𝑟⌋,1) 张图像。
让我们以valid_ratio=0.1为例,由于原始的训练集有50000张图像,因此train_valid_test/train路径中将有45000张图像用于训练,而剩下5000张图像将作为路径train_valid_test/valid中的验证集。
组织数据集后,同类别的图像将被放置在同一文件夹下。
ps:当我把train数据集下载下来后发现,每张图像的命名是‘id.jpg’,这个id正好和存储label的文件中的id一致,如第一张图片是青蛙,第二、三张都是truck 卡车,第4张是鹿。

因此,通过train文件夹中的每一个图像的文件名,去label文件夹下就能找id,就能找到对应的label。
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数
# collections.Counter(a):计算a中每个元素的数量,按数量从大到小输出
# 在这里,计算了每一个类别所包含的样本数,例如labels含有 frog,frog,book
# 使用Counter后,会返回:Counter({'frog':2,'book':1})
# most_common(n)函数:传进去一个可选参数n(代表获取数量最多的前n个元素,如果不传参数,代表返回所有结果)
# most_common()函数返回的结果是元组列表,得到[('frog',2),{'book',1}]
# [-1][1]返回的是最后一行的第1列,也就是样本最少的类别中的样本数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
# 对于每一个train文件夹下的图片文件train_file,文件名是id.jpg如1.jpg,2.jpg...
for train_file in os.listdir(os.path.join(data_dir, 'train')):
label = labels[train_file.split('.')[0]] # 用每个文件的文件名即id号去找到对应的label
fname = os.path.join(data_dir, 'train', train_file) # 获得每一个图片的文件路径
# 创建出train_valid_test/train_valid/label的文件路径后
# train_valid是一个总文件夹,里面有以每个类别命名的文件夹
# 把这个图片复制过去,也就是说,把图片放到他对应的label来命名的文件中
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
# 之后把train_valid文件夹分成valid文件夹和train文件夹
if label not in label_count or label_count[label] < n_valid_per_label:
# 如果图片的label不在label_count中,或者某个文件中的文件个数少于验证集中的样本数
# 那么就放入train_valid_test/valid/label 验证集下的label文件中
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1 # 对应的label数+1
else:
# 否则放入train_valid_test/train/label 训练集下的label文件中
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label
最后,我们会在用train文件夹的数据来训练一个模型,用valid文件夹来看结果调参数,选定参数之后,最后在完整的数据集train_valid文件夹上训练一遍。
下面的reorg_test函数用来在预测期间整理测试集,以方便读取。
def reorg_test(data_dir):
"""在预测期间整理测试集,以方便读取"""
for test_file in os.listdir(os.path.join(data_dir, 'test')):
# 把test文件夹下的图片,搬到train_valid_test/test/unknown文件夹下
# unknown是因为不知道label
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown'))
最后,我们使用一个函数来调用前面定义的函数read_csv_labels、reorg_train_valid和reorg_test,作用分别是 读取保存label的文件,来返回一个dict存储这些标签;将训练数据集整理成训练集和测试集;整理测试集;
# 整理cifar10这个数据集(在这里用的是cifar的demo)
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
在这里,我们只将样本数据集的批量大小设置为32。 在实际训练和测试中,应该使用Kaggle竞赛的完整数据集,并将batch_size设置为更大的整数,例如128。 我们将10%的训练样本作为调整超参数的验证集。
batch_size = 32 if demo else 128
valid_ratio = 0.1 # 90%用作训练集来训练模型,10%的数据拿来做验证,选超参数
reorg_cifar10_data(data_dir, valid_ratio)
以上是一个比较傻的方法,实际中图片在哪个文件夹就放在哪里,只是说写一个
class_mydata_iterator来做这个事情,但是如果图片不大的话,用这种形式做出来,不管是哪个框架,通常都会支持这个文件格式。
2. 图像增广
我们使用图像增广来解决过拟合的问题。例如在训练中,我们可以随机水平翻转图像。 我们还可以对彩色图像的三个RGB通道执行标准化。 下面,我们列出了其中一些可以调整的操作。
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64~1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
# 以上这样做的原因是,原始图片太小了是32 x 32,而且已经裁得比较好了,
# 放大到40的话,会多一点可操作的空间,裁出32 x 32的图片
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(), # 水平翻转
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道(但是这里不normalize可能问题也不大)
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
在测试期间,我们只对图像执行标准化,以消除评估结果中的随机性。
# 测试的话,什么都不用做,原本图像也是32 x 32
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
3. 读取数据集
接下来,我们读取由原始图像组成的数据集,每个样本都包括一张图片和一个标签。
关于torchvision.datasets.ImageFolder:
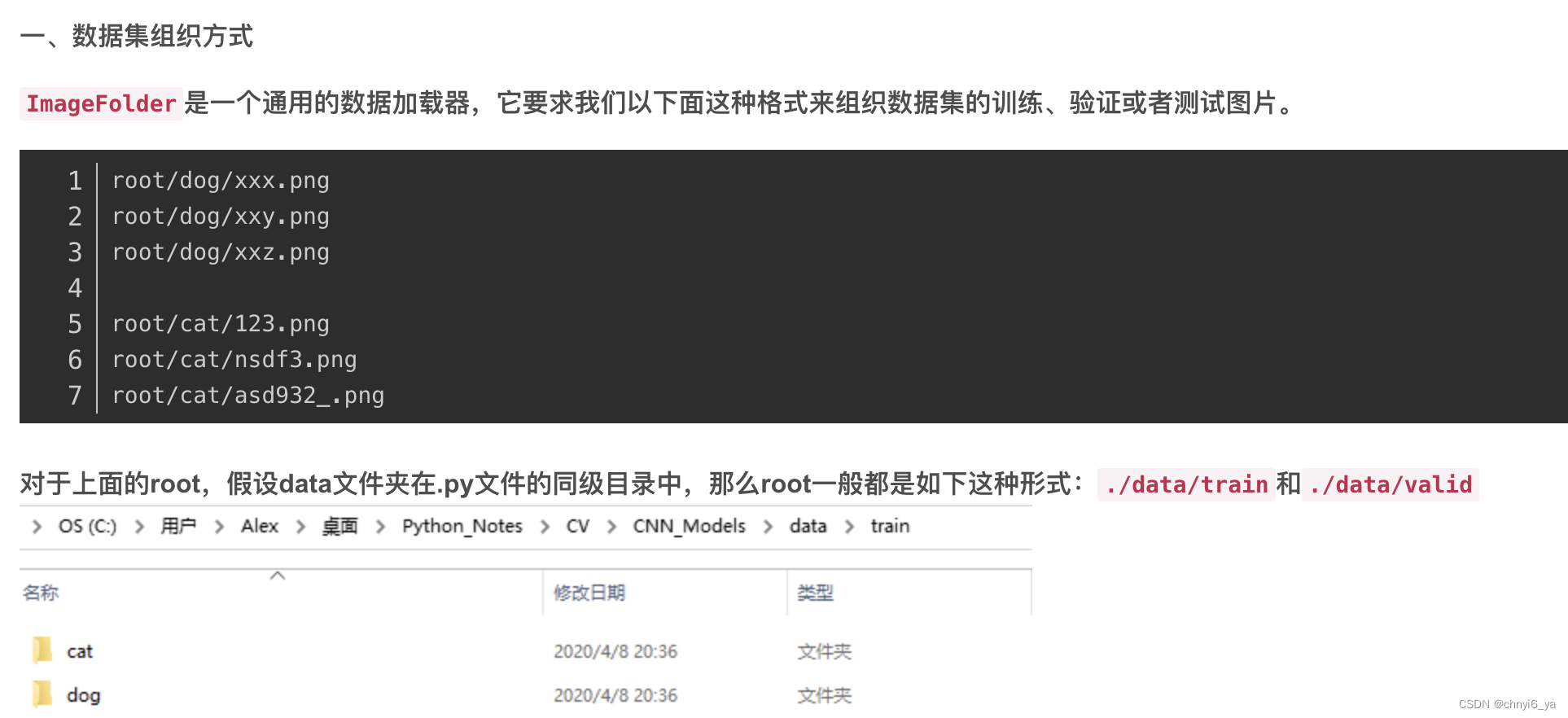
# train_ds, train_valid_ds这两个数据集用的是train的数据增广
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
# valid和test都不需要做额外的数据增广
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
在训练期间,我们需要指定上面定义的所有图像增广操作。 当验证集在超参数调整过程中用于模型评估时,不应引入图像增广的随机性。 在最终预测之前,我们根据训练集和验证集组合而成的训练模型进行训练,以充分利用所有标记的数据。
# 定义DataLoader,就是给定批量去随机读取数据
# drop_last=True表示如果最后一个batch_size不等于定好的batch_size,那么就丢弃
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,
drop_last=True)
# 但是test中drop_last=False,不能丢带最后一截,因为还是要预测的
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,
drop_last=False)
# 不过现在来说,不要丢也没关系
4. 定义模型
我们定义了之前描述的Resnet-18模型。
def get_net():
num_classes = 10 # 10个类别
# # 需要两个传递的参数,一个是多少类,一个输入通道是3通道,RGB
net = d2l.resnet18(num_classes, 3)
return net
# reduction="none" 表示不要把loss加起来,当然加起来也可以,无所谓
loss = nn.CrossEntropyLoss(reduction="none")
5. 定义训练函数
我们将根据模型在验证集上的表现来选择模型并调整超参数。 下面我们定义了模型训练函数train。
这个train函数没有本质区别,唯一的区别就是优化的时候加上了lr_period, lr_decay两个参数,在凸优化上面,随机梯度下降收敛的前提是学习率要不断减小,在之前,我们设定学习率都是平的,不变的。
为什么要减少呢?因为当迭代越靠近最优解的时候,相对来说步子要走小一点。并且因为是随机梯度下降,所以每次随机采样一些样本,是存在方差的。如果批量很大当然方差很小,但是批量很小的情况下,方差会很大。方差可以认为是一个噪音,方差的好处是不容易陷入到local的局部最优点,但是坏处是可以带偏。
所以学习率变低的话,就算方差固定,学习率越来越低,那么乱走的趋势就会变低。在最后收敛的时候不希望是在乱走。
# 每隔lr_period个轮次,就把学习率降低lr_decay
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,
weight_decay=wd)
# 每隔lr_period个轮次,把学习率和lr_decay相乘
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
# 移动设备,在cifar-10这个数据集上能用多个GPu就用多个GPU
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step() # 每个epoch要更新一下,会访问学习率,对其做相应的更新
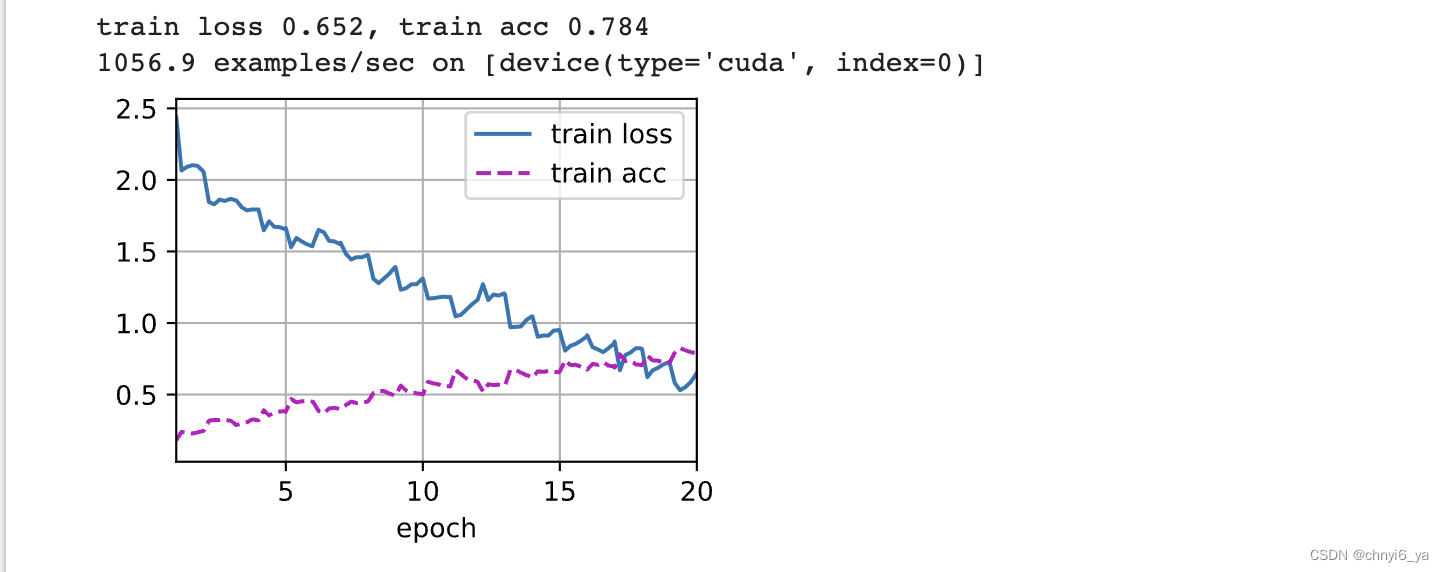
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
6. 训练和验证模型
现在,我们可以训练和验证模型了,而以下所有超参数都可以调整。
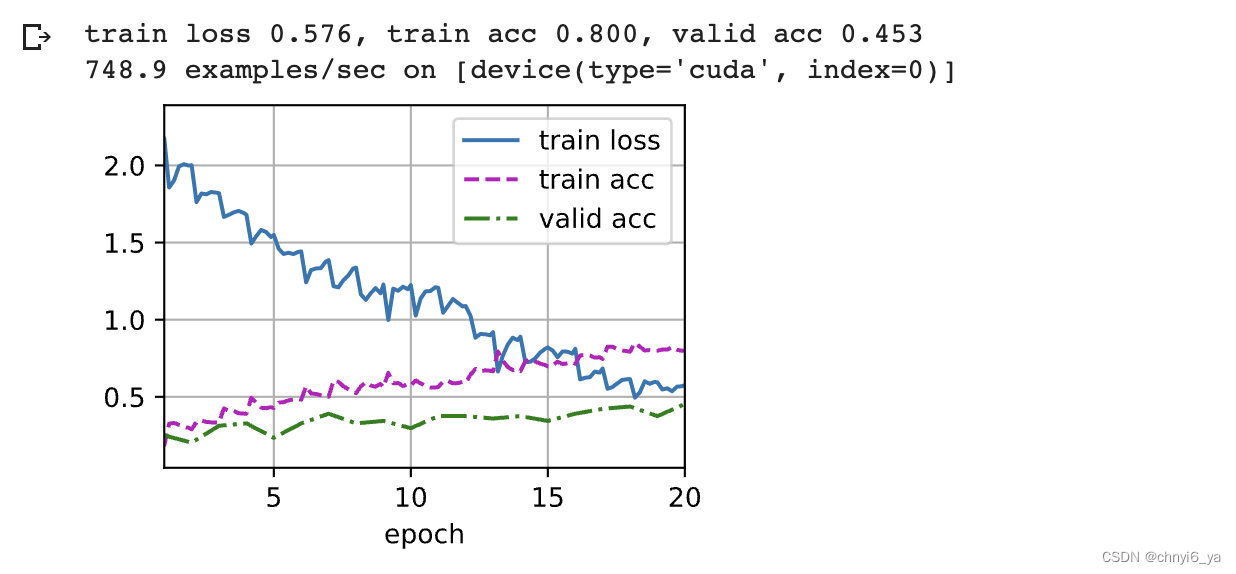
例如,我们可以增加周期的数量。当lr_period和lr_decay分别设置为4和0.9时,优化算法的学习速率将在每4个周期乘以0.9。 为便于演示,我们在这里只训练20个周期。
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay)
7. 在 Kaggle 上对测试集进行分类并提交结果
在获得具有超参数的满意的模型后,我们使用所有标记的数据(包括验证集)来重新训练模型并对测试集进行分类。
net, preds = get_net(), []
# 在完整的数据集上重新训练模型(train_valid_iter),并且这里也没有valid_iter了
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
for X, _ in test_iter:
# 要把输入X搬到GPU[0]上
y_hat = net(X.to(devices[0]))
# 转换后读到cpu上
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False) # 存成一个submission.csv
向Kaggle提交结果的方法与之前提交方法类似,上面的代码将生成一个 submission.csv文件,其格式符合Kaggle竞赛的要求。
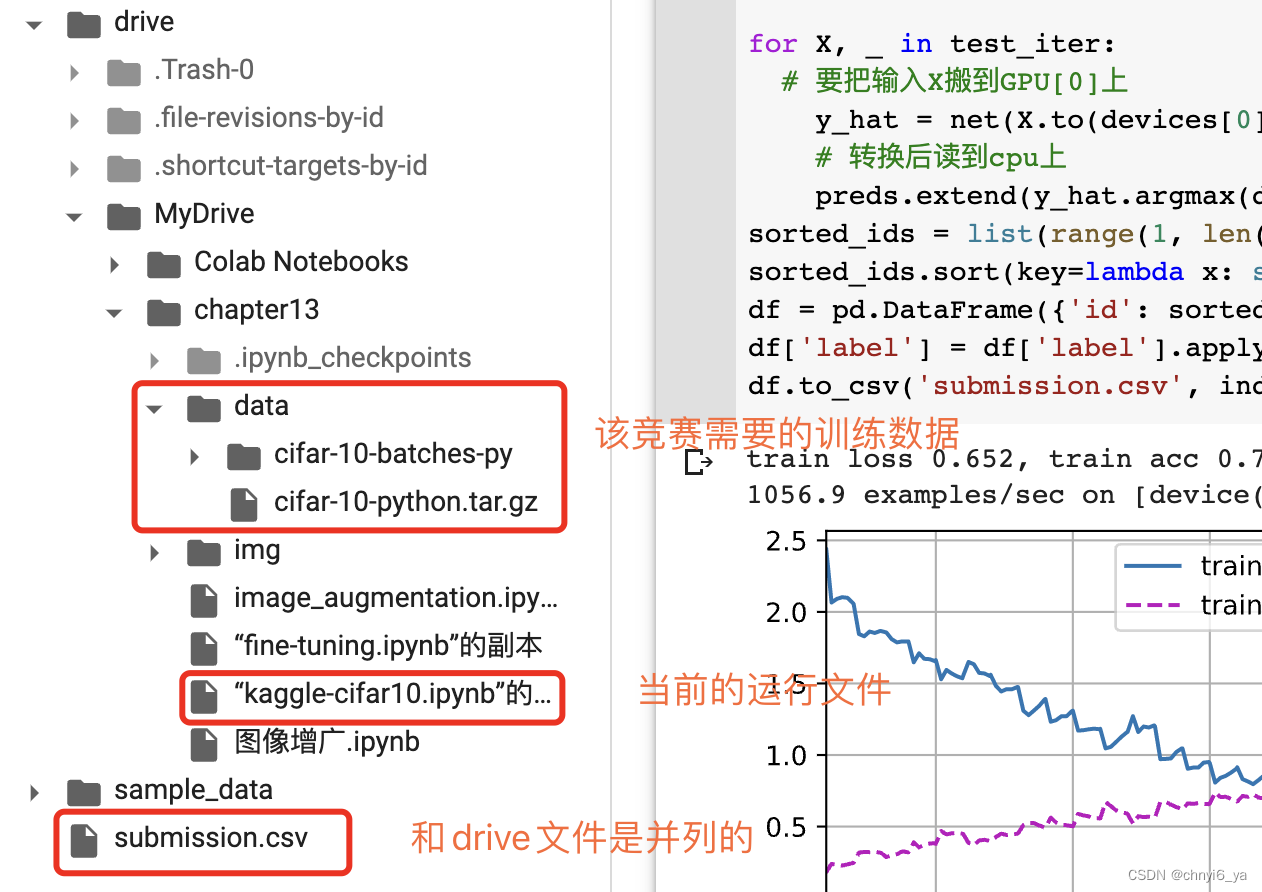
如下,在colab的侧边栏可以看到生成了submission.csv文件:
8. 向Kaggle提交结果
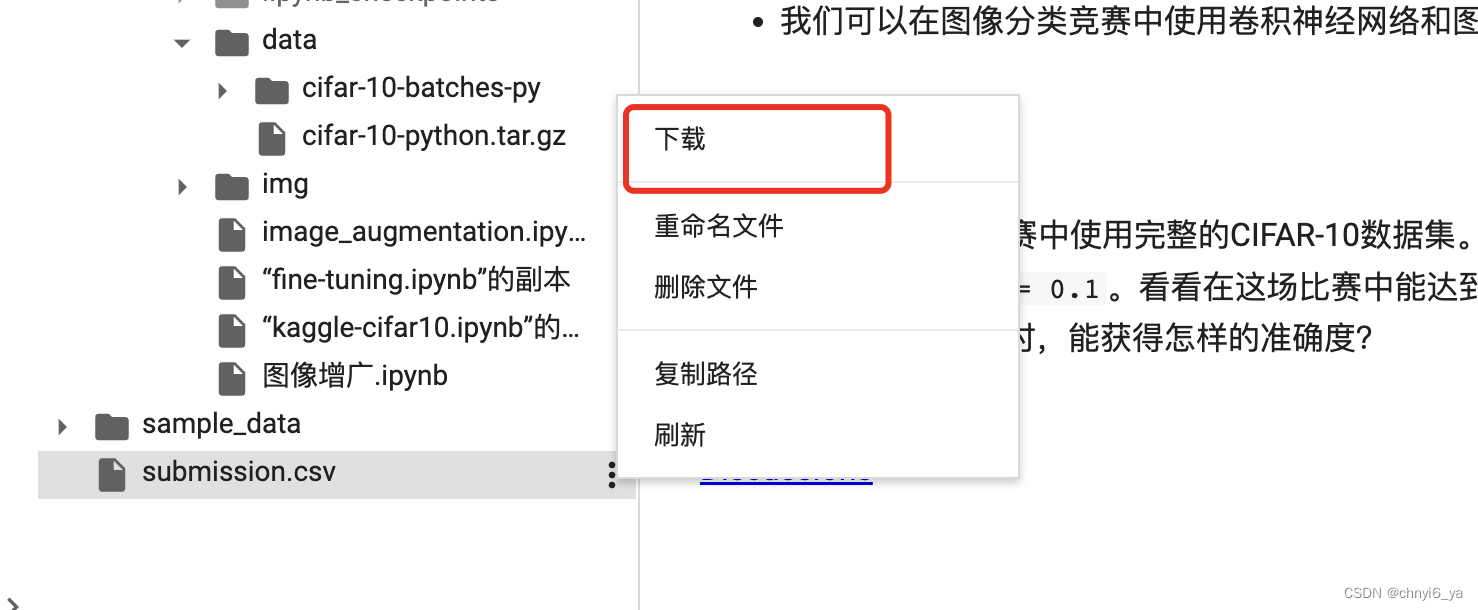
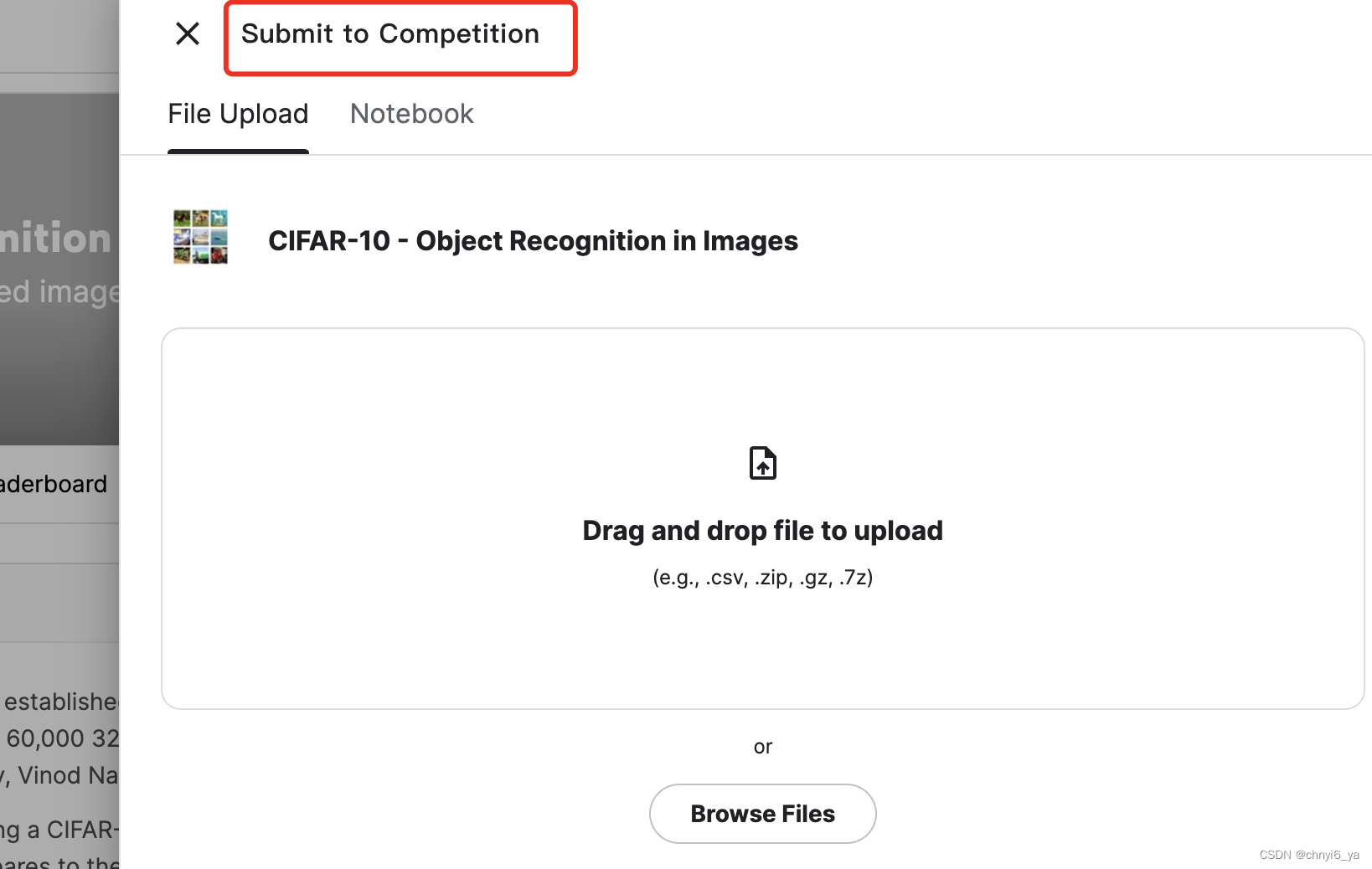
把submission.csv下载到本地,就能向Kaggle提交结果了:
记录一下练习题,等之后连接服务器了再试,并且使用完整数据集: