亚马逊和沃尔玛等电子商务平台上每天都有大量的产品评论,这些评论是反映消费者对产品情绪的关键接触点。但是,企业如何从庞大的数据库获得有意义的见解?
我们可以使用LlamaIndex将SQL与RAG(Retrieval Augmented Generation)相结合来实现。
一、产品评论样本数据集
为了进行此演示,我们使用GPT-4生成了一个样本数据集,其中包括三种产品的评论:iPhone 13、SamsungTV和Ergonomic Chair。下面是评论示例:
iPhone 13:“Amazing battery life and camera quality. Best iPhone yet.”
SamsungTV:“Impressive picture clarity and vibrant colors. A top-notch TV.”
Ergonomic Chair:“Feels really comfortable even after long hours.”
下面是一个示例数据集:
rows = [# iPhone13 Reviews{"category": "Phone", "product_name": "Iphone13", "review": "The iPhone13 is a stellar leap forward. From its sleek design to the crystal-clear display, it screams luxury and functionality. Coupled with the enhanced battery life and an A15 chip, it's clear Apple has once again raised the bar in the smartphone industry."},{"category": "Phone", "product_name": "Iphone13", "review": "This model brings the brilliance of the ProMotion display, changing the dynamics of screen interaction. The rich colors, smooth transitions, and lag-free experience make daily tasks and gaming absolutely delightful."},{"category": "Phone", "product_name": "Iphone13", "review": "The 5G capabilities are the true game-changer. Streaming, downloading, or even regular browsing feels like a breeze. It's remarkable how seamless the integration feels, and it's obvious that Apple has invested a lot in refining the experience."},# SamsungTV Reviews{"category": "TV", "product_name": "SamsungTV", "review": "Samsung's display technology has always been at the forefront, but with this TV, they've outdone themselves. Every visual is crisp, the colors are vibrant, and the depth of the blacks is simply mesmerizing. The smart features only add to the luxurious viewing experience."},{"category": "TV", "product_name": "SamsungTV", "review": "This isn't just a TV; it's a centerpiece for the living room. The ultra-slim bezels and the sleek design make it a visual treat even when it's turned off. And when it's on, the 4K resolution delivers a cinematic experience right at home."},{"category": "TV", "product_name": "SamsungTV", "review": "The sound quality, often an oversight in many TVs, matches the visual prowess. It creates an enveloping atmosphere that's hard to get without an external sound system. Combined with its user-friendly interface, it's the TV I've always dreamt of."},# Ergonomic Chair Reviews{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "Shifting to this ergonomic chair was a decision I wish I'd made earlier. Not only does it look sophisticated in its design, but the level of comfort is unparalleled. Long hours at the desk now feel less daunting, and my back is definitely grateful."},{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "The meticulous craftsmanship of this chair is evident. Every component, from the armrests to the wheels, feels premium. The adjustability features mean I can tailor it to my needs, ensuring optimal posture and comfort throughout the day."},{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "I was initially drawn to its aesthetic appeal, but the functional benefits have been profound. The breathable material ensures no discomfort even after prolonged use, and the robust build gives me confidence that it's a chair built to last."},]
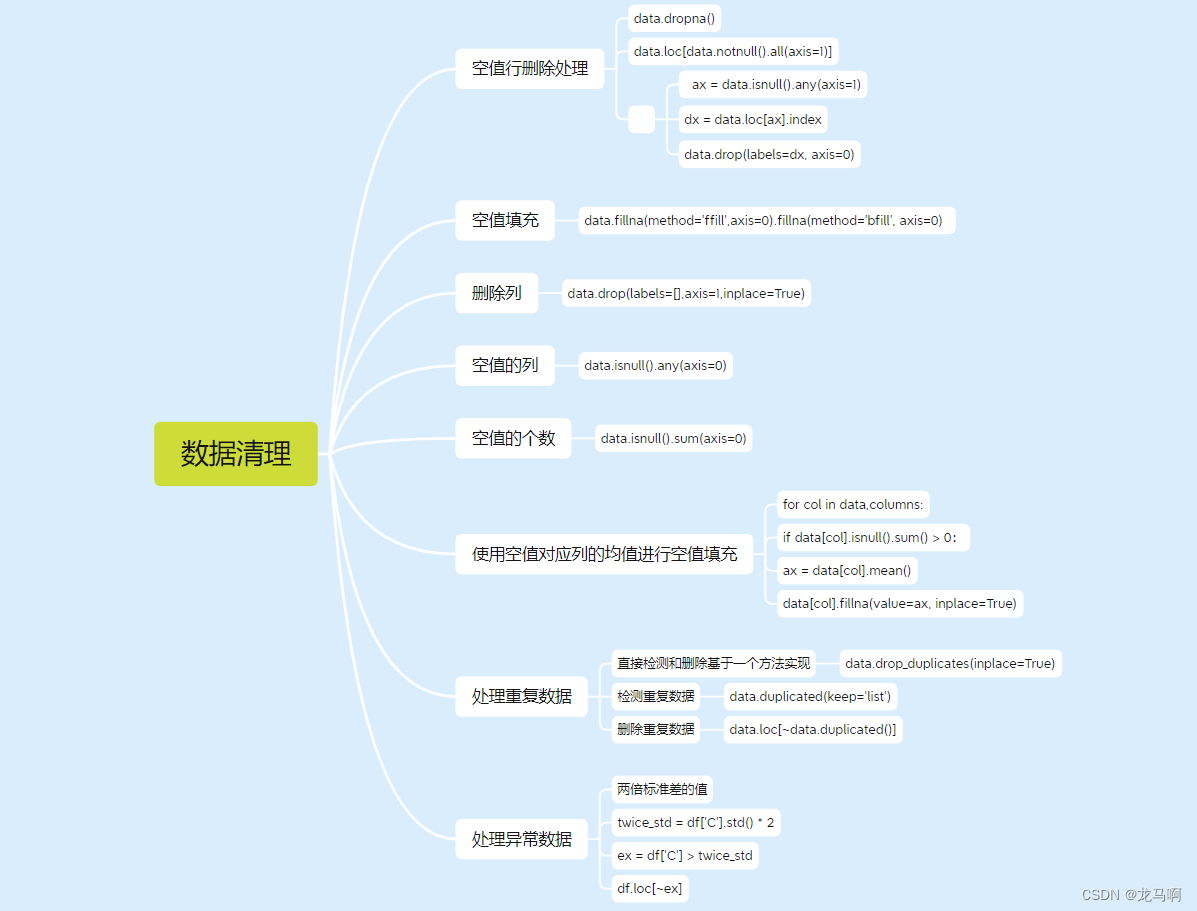
二、设置内存数据库
为了处理我们的数据,我们使用了一个SQLite数据库。SQLAlchemy提供了一种高效的方式来建模、创建和与此数据库交互。以下是表product_reviews的结构:
- id (Integer, Primary Key)
- category (String)
- product_name (String)
- review (String, Not Null)
一旦我们定义了我们的表结构,我们就用我们的样本数据集来填充它。
engine = create_engine("sqlite:///:memory:")metadata_obj = MetaData()# create product reviews SQL tabletable_name = "product_reviews"city_stats_table = Table(table_name,metadata_obj,Column("id", Integer(), primary_key=True),Column("category", String(16), primary_key=True),Column("product_name", Integer),Column("review", String(16), nullable=False))metadata_obj.create_all(engine)sql_database = SQLDatabase(engine, include_tables=["product_reviews"])for row in rows:stmt = insert(city_stats_table).values(**row)with engine.connect() as connection:cursor = connection.execute(stmt)connection.commit()
三、分析产品评论——Text2SQL+RAG
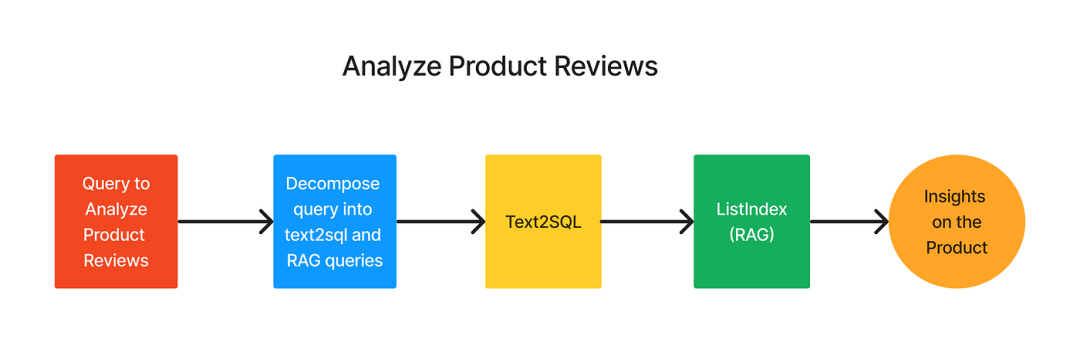
LlamaIndex中的SQL+RAG通过将其分解为三个步骤来简化这一过程:
1.问题分解:
- 主查询:用自然语言构建主要问题,从SQL表中提取初步数据;
- 次要查询:构造一个辅助问题,以细化或解释主查询的结果。
2.数据检索:使用Text2SQL LlamaIndex模块运行主查询,以获得初始结果集。
3.最终答案生成:使用列表索引在次要问题的基础上进一步细化结果,得出结论性答案。
四、将用户查询分解为两个阶段
在使用关系数据库时,将用户查询分解为更易于管理的部分通常很有帮助。这样可以更容易地从我们的数据库中检索准确的数据,并随后处理或解释这些数据以满足用户的需求。我们设计了一种方法,通过给gpt-3.5-turbo模型一个例子让其生成两个不同的问题,将查询分解为两个不同的问题。
让我们将其应用于查询“Get the summary of reviews of Iphone13”,系统将生成:
数据库查询:“Retrieve reviews related to iPhone13 from the table.”
解释查询:“Summarize the retrieved reviews.”
这种方法确保我们满足数据检索和数据解释的需求,从而对用户查询做出更准确、更具针对性的响应。
def generate_questions(user_query: str) -> List[str]:system_message = '''You are given with Postgres table with the following columns.city_name, population, country, reviews.Your task is to decompose the given question into the following two questions.1. Question in natural language that needs to be asked to retrieve results from the table.2. Question that needs to be asked on the top of the result from the first question to provide the final answer.Example:Input:How is the culture of countries whose population is more than 5000000Output:1. Get the reviews of countries whose population is more than 50000002. Provide the culture of countries'''messages = [ChatMessage(role="system", content=system_message),ChatMessage(role="user", content=user_query),]generated_questions = llm.chat(messages).message.content.split('\n')return generated_questionsuser_query = "Get the summary of reviews of Iphone13"text_to_sql_query, rag_query = generate_questions(user_query)
五、数据检索——执行主查询
当我们将用户的问题分解为两部分时,第一步是将“自然语言数据库查询”转换为可以针对我们的数据库运行的实际SQL查询。在本节中,我们将使用LlamaIndex的NLSQLTableQueryEngine来处理此SQL查询的转换和执行。
设置NLSQLTableQueryEngine:
NLSQLTableQueryEngine是一个功能强大的工具,可以接受自然语言查询并将其转换为SQL查询。下面是关键详细信息:
sql_database:表示我们的sql数据库连接详细信息。
tables:指定查询运行的表。在这个场景中,我们的目标是product_reviews表。
synthesize_response:当设置为False时,这确保我们在没有额外合成的情况下接收原始SQL响应。
service_context:这是一个可选参数,可用于提供特定于服务的设置或插件。
sql_query_engine = NLSQLTableQueryEngine(sql_database=sql_database,tables=["product_reviews"],synthesize_response=False,service_context=service_context)
执行自然语言查询:
设置好引擎后,下一步使用query()方法对其执行自然语言查询。
sql_response = sql_query_engine.query(text_to_sql_query)处理SQL响应:
SQL查询的结果通常是一个按行存储的列表(每一行都表示为一个评论列表)。为了使其更易于阅读和用于处理总结评论的第三步,我们将此结果转换为单个字符串。
sql_response_list = ast.literal_eval(sql_response.response)text = [' '.join(t) for t in sql_response_list]text = ' '.join(text)
可以在SQL_response.metadata[“SQL_query”]中检查生成的SQL查询。
按照这个过程,我们能够将自然语言处理与SQL查询执行无缝集成。让我们看一下这个过程的最后一步,以获得评论摘要。
六、使用ListIndex完善和解释评论:
从SQL查询中获得主要结果集后,通常需要进一步细化或解释的情况。这就是LlamaIndex的ListIndex发挥关键作用的地方,它允许我们对获得的文本数据执行第二个问题,以获得精确的答案。
listindex = ListIndex([Document(text=text)])list_query_engine = listindex.as_query_engine()response = list_query_engine.query(rag_query)print(response.response)
现在,让我们将所有内容都封装在一个函数下,并尝试几个有趣的示例:
"""Function to perform SQL+RAG"""def sql_rag(user_query: str) -> str:text_to_sql_query, rag_query = generate_questions(user_query)sql_response = sql_query_engine.query(text_to_sql_query)sql_response_list = ast.literal_eval(sql_response.response)text = [' '.join(t) for t in sql_response_list]text = ' '.join(text)listindex = ListIndex([Document(text=text)])list_query_engine = listindex.as_query_engine()summary = list_query_engine.query(rag_query)return summary.response
例子
sql_rag("How is the sentiment of SamsungTV product?")The sentiment of the reviews for the Samsung TV product is generally positive. Users express satisfaction with the picture clarity, vibrant colors, and stunning picture quality. They appreciate the smart features, user-friendly interface, and easy connectivity options. The sleek design and wall-mounting capability are also praised. The ambient mode, gaming mode, and HDR content are mentioned as standout features. Users find the remote control with voice command convenient and appreciate the regular software updates. However, some users mention that the sound quality could be better and suggest using an external audio system. Overall, the reviews indicate that the Samsung TV is considered a solid investment for quality viewing.
sql_rag("Are people happy with Ergonomic Chair?")The overall satisfaction of people with the Ergonomic Chair is high.
七、结论
在电子商务时代,用户评论决定了产品的成败,快速分析和解释大量文本数据的能力至关重要。LlamaIndex通过巧妙地集成SQL和RAG,为企业提供了一个强大的工具,可以从这些数据集中收集可操作的见解。通过将结构化SQL查询与自然语言处理的抽象无缝结合,我们展示了一种将模糊的用户查询转换为精确、信息丰富的答案的简化方法。
有了这种方法,企业现在可以有效地筛选堆积如山的评论,提取用户情感的本质,并做出明智的决定。无论是衡量产品的整体情绪、了解特定功能反馈,还是跟踪评论随时间的演变,LlamaIndex中的Text2SQL+RAG方法都是数据分析新时代的先驱。
参考文献:
[1] https://blog.llamaindex.ai/llamaindex-harnessing-the-power-of-text2sql-and-rag-to-analyze-product-reviews-204feabdf25b
[2] https://colab.research.google.com/drive/13le_rgEo-waW5ZWjWDEyUf64R6n_4Cez?usp=sharing