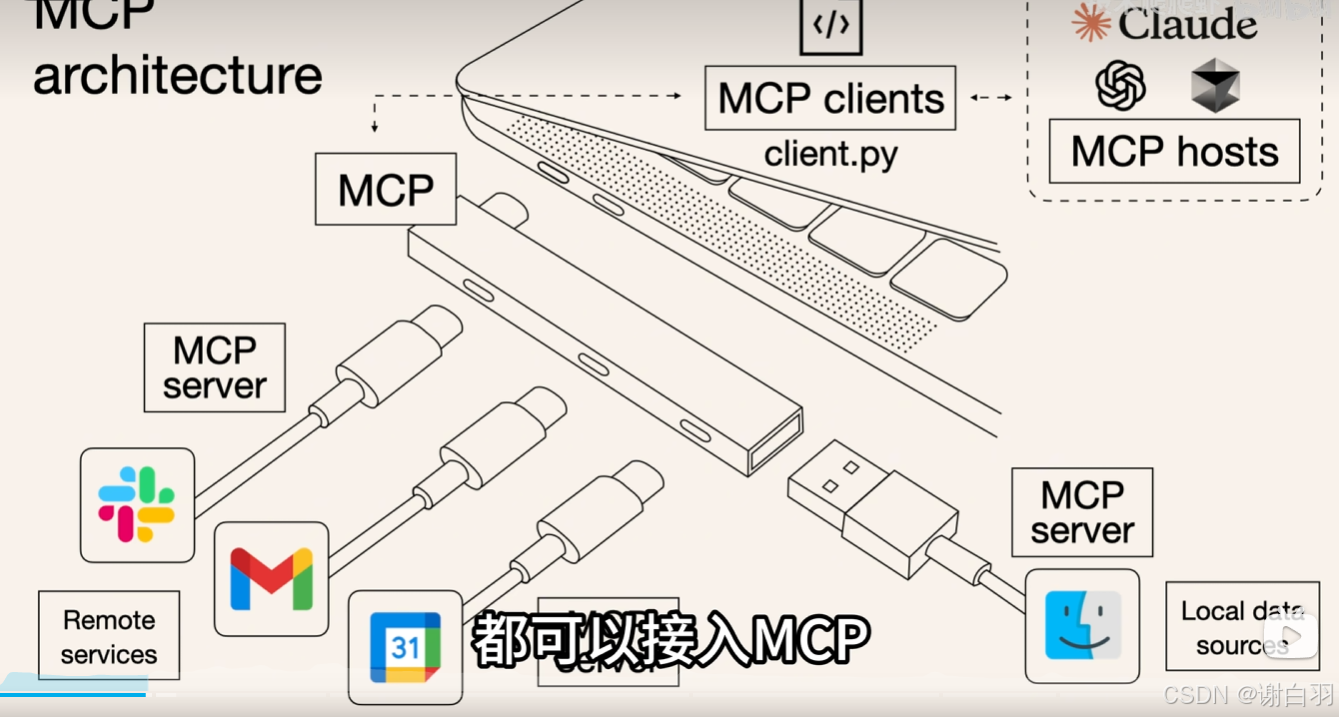
1、项目结构建议
project/
├── api_docs/ # 存放接口文档
│ └── XX系统.swagger.json
├── ai_generator/ # AI测试用例生成模块
│ └── test_case_generator.py
├── tests/ # 生成的测试用例
│ └── test_user_api.py
├── conftest.py # pytest配置
├── url/ # 存放url
│ └── xx模块url.py
└── requirements.txt
XX系统.swagger.json来源
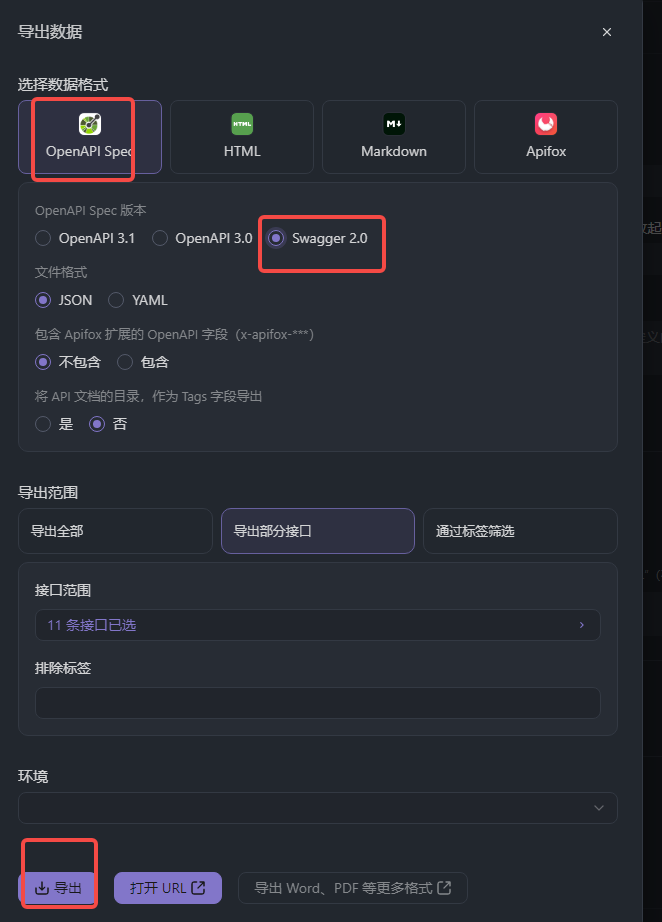
2、新增空的xx模块url.py
3、编写自动化封装api的脚本,自动化生成测试用例
这里需要安装第三方库zhipuai
可以借鉴:https://blog.csdn.net/weixin_41665637/article/details/147113443?
import requests
from zhipuai import ZhipuAI
import json
import re
import logging
from pathlib import Path
from typing import Dict, List, Optional, Any
from dataclasses import dataclass
from faker import Faker
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class APIEndpoint:
path: str
method: str
summary: str
parameters: List[Dict[str, Any]]
operation_id: Optional[str] = None
class TestCaseGenerator:
def __init__(self, api_key: str, base_url: str = ""):
self.client = ZhipuAI(api_key=api_key)
self.faker = Faker('zh_CN')
self.base_url = base_url.strip('/')
self.test_template = """import pytest
import requests
import logging
from faker import Faker
from api.urls import AuthUrls
from api.merchant_urls import MerchantUrls
from test_data.auth_params import valid_credentials
from config.settings import get_base_url
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class TestGeneratedCases:
@pytest.fixture(scope="class")
def auth_token(self):
url = AuthUrls().login
response = requests.post(url, json=valid_credentials)
assert response.status_code == 200
return response.json()["token"]
{test_methods}
"""
def generate_test_cases(self, swagger_data: Dict, output_path: str):
"""生成完整测试用例文件"""
endpoints = self._parse_swagger(swagger_data)
test_methods = "\n\n ".join([self._generate_test_method(endpoint) for endpoint in endpoints])
test_file = self.test_template.format(test_methods=test_methods)
self._save_to_file(output_path, test_file)
def _parse_swagger(self, swagger_data: Dict) -> List[APIEndpoint]:
"""解析Swagger文档"""
endpoints = []
for path, methods in swagger_data["paths"].items():
for method, details in methods.items():
endpoint = APIEndpoint(
path=path,
method=method.upper(),
summary=details.get("summary", "No description"),
parameters=details.get("parameters", []),
operation_id=details.get("operationId")
)
endpoints.append(endpoint)
return endpoints
def _generate_test_method(self, endpoint: APIEndpoint) -> str:
"""生成单个测试方法"""
method_name = self._generate_method_name(endpoint)
path_params = self._parse_path_params(endpoint.path)
query_params = [p["name"] for p in endpoint.parameters if p.get("in") == "query"]
body_params = [p["name"] for p in endpoint.parameters if p.get("in") == "body"]
# 生成URL(使用正确的方法名和参数)
url = self._generate_full_url(
base_path=endpoint.path,
path_params=path_params
)
# 生成请求参数(暂时简化处理)
request_params = self._build_request_params(
method=endpoint.method.lower(),
path_params=path_params,
query_params=query_params,
body_params=body_params
)
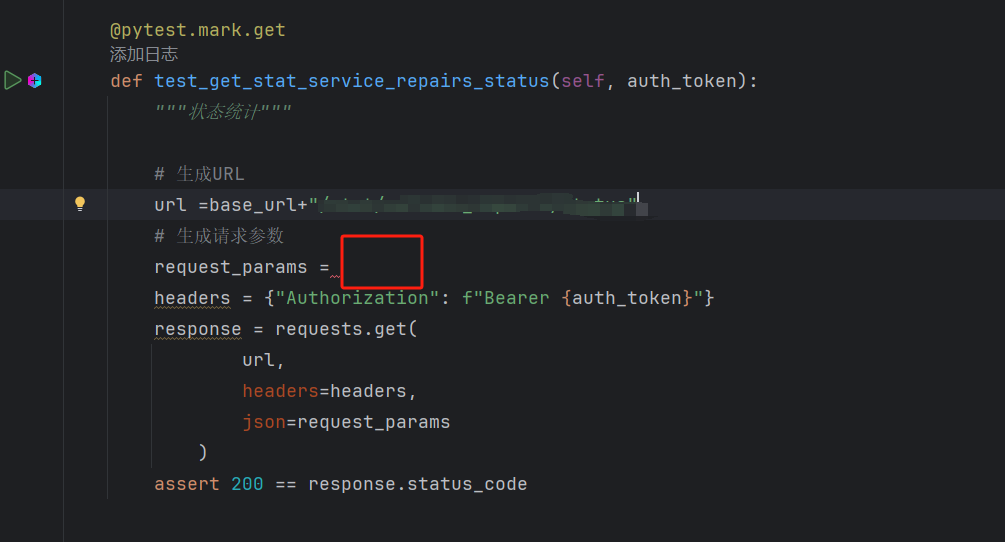
return f'''
@pytest.mark.{endpoint.method.lower()}
def {method_name}(self, auth_token):
"""{endpoint.summary}"""
# 生成URL
url =get_base_url()+"{url}"
# 生成请求参数
request_params ={request_params}
headers = {{"Authorization": f"Bearer {{auth_token}}"}}
response = requests.{endpoint.method.lower()}(
url,
headers=headers,
json=request_params
)
assert 200 == response.status_code
'''
def _parse_request_body(self, parameters: List) -> Dict:
"""深度解析请求体结构"""
body_params = next((p for p in parameters if p.get('in') == 'body'), None)
if not body_params:
return {}
schema = body_params.get('schema', {})
if '$ref' in schema:
return self._resolve_ref(schema['$ref'])
return self._parse_schema(schema)
def _generate_smart_data(self, schema: Dict) -> Dict:
"""生成符合schema的智能数据"""
# 实现递归数据生成逻辑
pass
def _build_request_params(self, method: str, path_params: list, query_params: list, body_params: list) -> dict:
"""构建请求参数字典"""
params = []
# 路径参数处理
if path_params:
params.append(f"params={{'{path_params[0]}': self.faker.uuid4()}}")
if method in ['post', 'put', 'patch'] and body_params:
params.append(f"json={{'{body_params[0]}': self.faker.word()}}")
return ",\n ".join(params)
def _generate_full_url(self, base_path: str, path_params: list) -> str:
"""生成完整URL(示例:/api/devices/{device_id} -> /api/devices/123)"""
# 替换路径参数
formatted_path = base_path
for param in path_params:
formatted_path = formatted_path.replace(f"{{{param}}}", f"{{self.faker.uuid4()}}")
# 拼接基础URL
return f"{self.base_url}/{formatted_path.lstrip('/')}"
def _parse_path_params(self, path: str) -> List[str]:
"""解析路径参数"""
return re.findall(r"{(\w+)}", path)
def _generate_method_name(self, endpoint: APIEndpoint) -> str:
"""生成测试方法名"""
clean_path = re.sub(r"[{}]", "", endpoint.path)
return f"test_{endpoint.method.lower()}_{clean_path.strip('/').replace('/', '_')}"
def _path_to_method(self, path: str) -> str:
"""路径转方法名"""
return re.sub(r"\W+", "_", path).strip("_")
def _save_to_file(self, path: str, content: str):
"""保存测试文件"""
Path(path).parent.mkdir(parents=True, exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
if __name__ == "__main__":
# 使用示例
generator = TestCaseGenerator(
api_key="your api_key",
base_url=""
)
with open(r"D:\python_test\pythonProject\project\api_docs\你的.json", encoding="utf-8") as f:
swagger_data = json.load(f)
generator.generate_test_cases(
swagger_data=swagger_data,
output_path=r"D:\python_test\pythonProject\你的存放测试用例地址"
)
print("✅自动化测试用例已生成!")
备注:目前生成的用例并不能直接调用使用,需要再手动调整脚本
生成的用例,目前未取到json值,这里我再检查优化一下