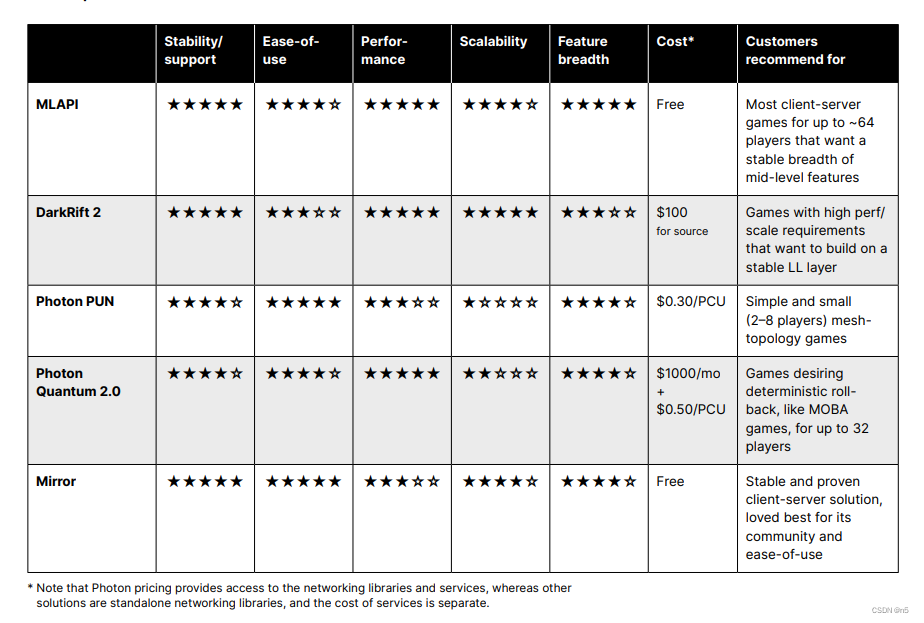
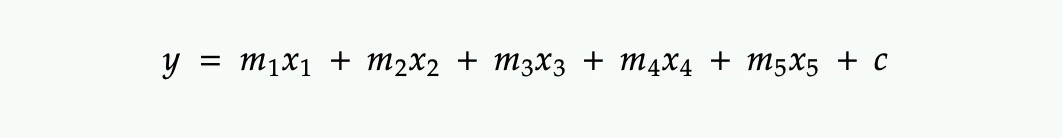前段时间写了一篇damoYolo的训练教程,同时也对自己的数据集进行了训练,虽然效果确实不是很好,但是damoyolo的一些思想和网络结构啥的还是可以借鉴使用的,此次将damoyolo的RepGFPN结构掏出来放到v5的NECK中,测试一下对本人的数据集(小目标)效果比v5要好,大概提升2个点左右。
放一下damoyolo的github网址:
https://github.com/tinyvision/DAMO-YOLO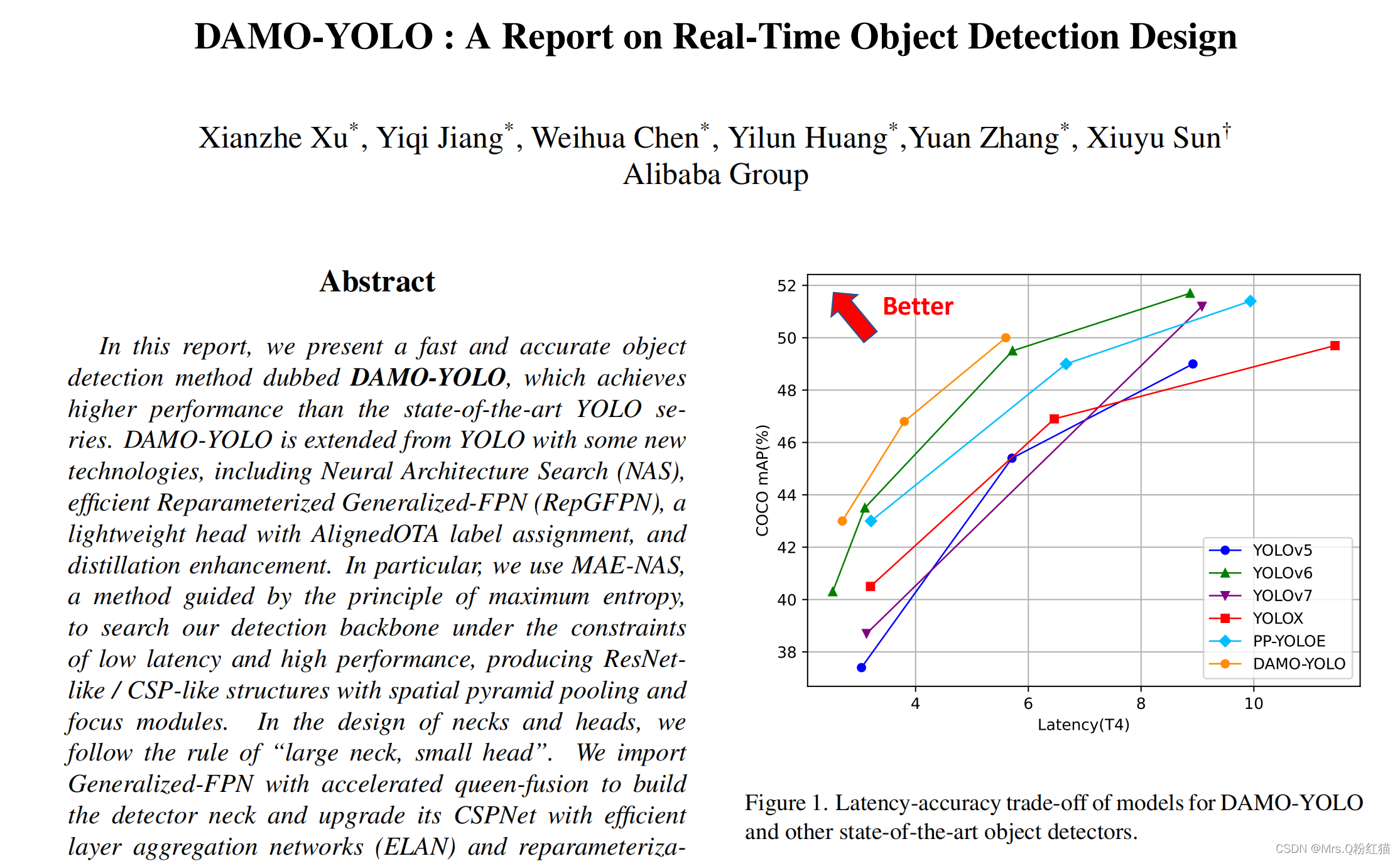
damoyolo的整体结构我们是无法看到的因为他的主干网络是nas_backbones 里面是txt文件,RepGFPN是可以看到的。
import torch
import torch.nn as nn
from ..core.ops import ConvBNAct, CSPStage
class GiraffeNeckV2(nn.Module):
def __init__(
self,
depth=1.0,
hidden_ratio=1.0,
in_features=[2, 3, 4],
in_channels=[256, 512, 1024],
out_channels=[256, 512, 1024],
act='silu',
spp=False,
block_name='BasicBlock',
):
super().__init__()
self.in_features = in_features
self.in_channels = in_channels
self.out_channels = out_channels
Conv = ConvBNAct
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
# node x3: input x0, x1
self.bu_conv13 = Conv(in_channels[1], in_channels[1], 3, 2, act=act)
self.merge_3 = CSPStage(block_name,
in_channels[1] + in_channels[2],
hidden_ratio,
in_channels[2],
round(3 * depth),
act=act,
spp=spp)
# node x4: input x1, x2, x3
self.bu_conv24 = Conv(in_channels[0], in_channels[0], 3, 2, act=act)
self.merge_4 = CSPStage(block_name,
in_channels[0] + in_channels[1] +
in_channels[2],
hidden_ratio,
in_channels[1],
round(3 * depth),
act=act,
spp=spp)
# node x5: input x2, x4
self.merge_5 = CSPStage(block_name,
in_channels[1] + in_channels[0],
hidden_ratio,
out_channels[0],
round(3 * depth),
act=act,
spp=spp)
# node x7: input x4, x5
self.bu_conv57 = Conv(out_channels[0], out_channels[0], 3, 2, act=act)
self.merge_7 = CSPStage(block_name,
out_channels[0] + in_channels[1],
hidden_ratio,
out_channels[1],
round(3 * depth),
act=act,
spp=spp)
# node x6: input x3, x4, x7
self.bu_conv46 = Conv(in_channels[1], in_channels[1], 3, 2, act=act)
self.bu_conv76 = Conv(out_channels[1], out_channels[1], 3, 2, act=act)
self.merge_6 = CSPStage(block_name,
in_channels[1] + out_channels[1] +
in_channels[2],
hidden_ratio,
out_channels[2],
round(3 * depth),
act=act,
spp=spp)
def init_weights(self):
pass
def forward(self, out_features):
"""
Args:
inputs: input images.
Returns:
Tuple[Tensor]: FPN feature.
"""
# backbone
[x2, x1, x0] = out_features
# node x3
x13 = self.bu_conv13(x1)
x3 = torch.cat([x0, x13], 1)
x3 = self.merge_3(x3)
# node x4
x34 = self.upsample(x3)
x24 = self.bu_conv24(x2)
x4 = torch.cat([x1, x24, x34], 1)
x4 = self.merge_4(x4)
# node x5
x45 = self.upsample(x4)
x5 = torch.cat([x2, x45], 1)
x5 = self.merge_5(x5)
# node x8
# x8 = x5
# node x7
x57 = self.bu_conv57(x5)
x7 = torch.cat([x4, x57], 1)
x7 = self.merge_7(x7)
# node x6
x46 = self.bu_conv46(x4)
x76 = self.bu_conv76(x7)
x6 = torch.cat([x3, x46, x76], 1)
x6 = self.merge_6(x6)
outputs = (x5, x7, x6)
return outputs
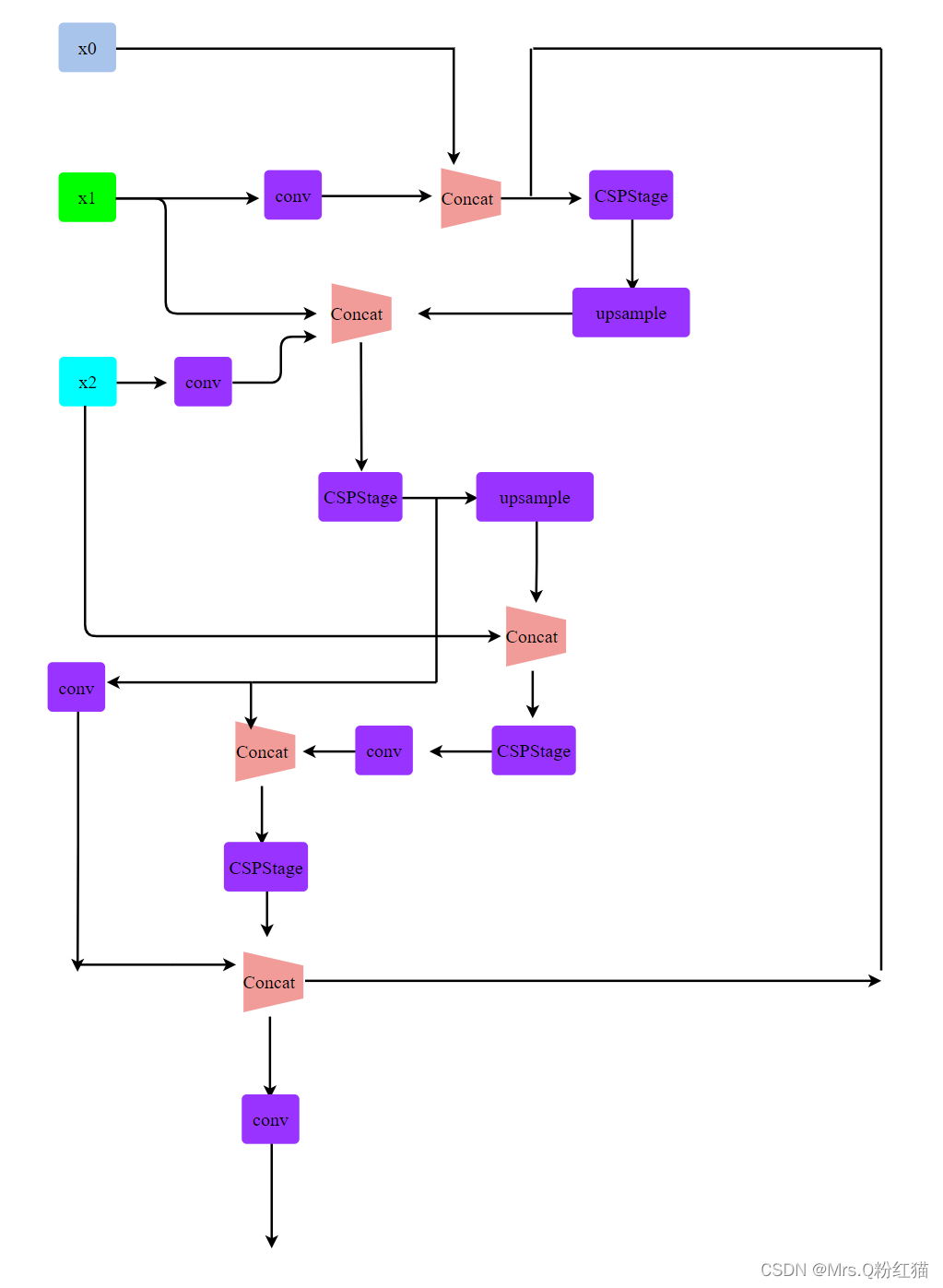
我根据ONNX结构图和上述代码画了简易的展示图:画的相对简单了,可能有些错误,后续我都没在看了,大家还是主要看代码吧
训练自己的数据集:
YoloV5+GFPN(我没用Rep)
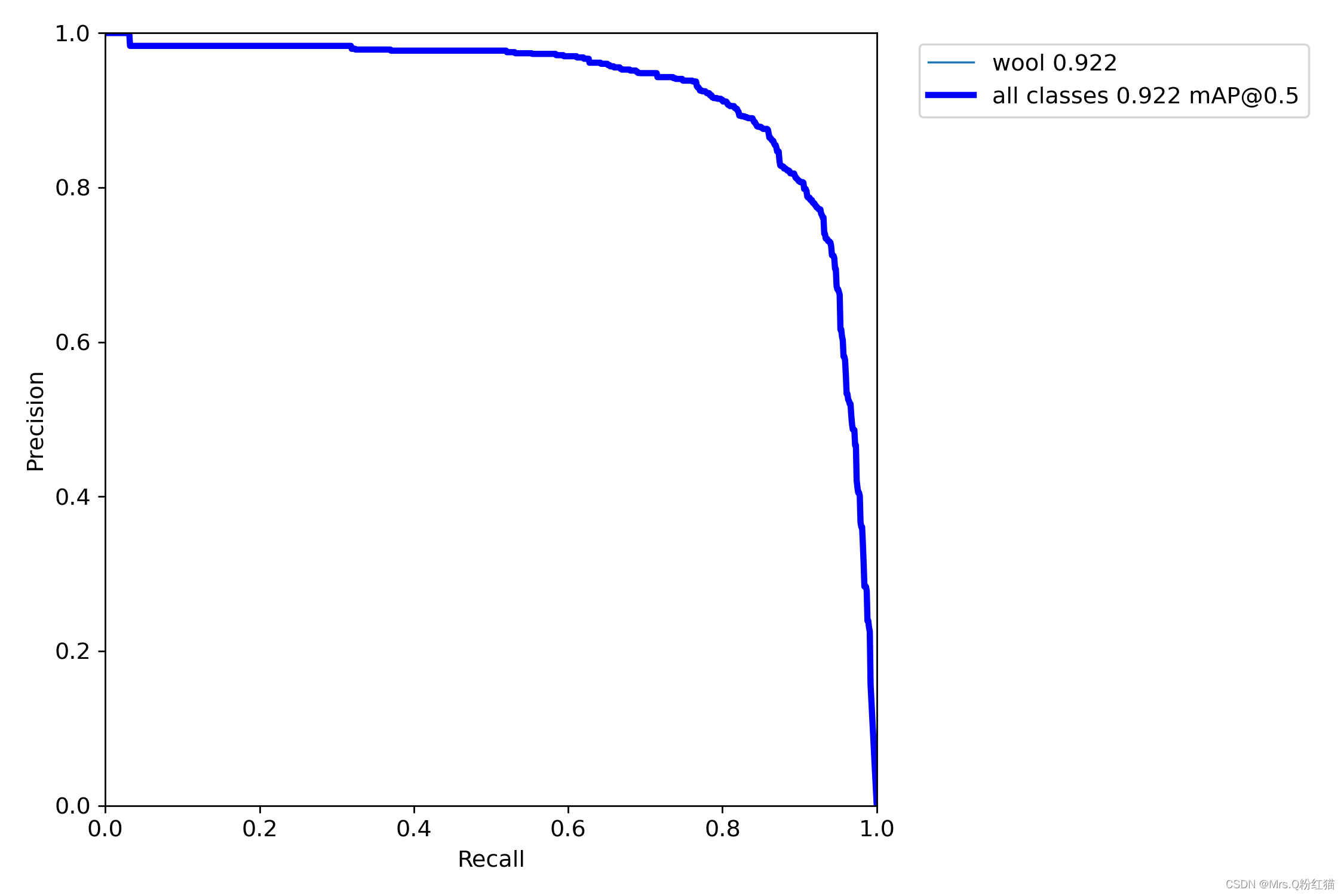
yolov5:
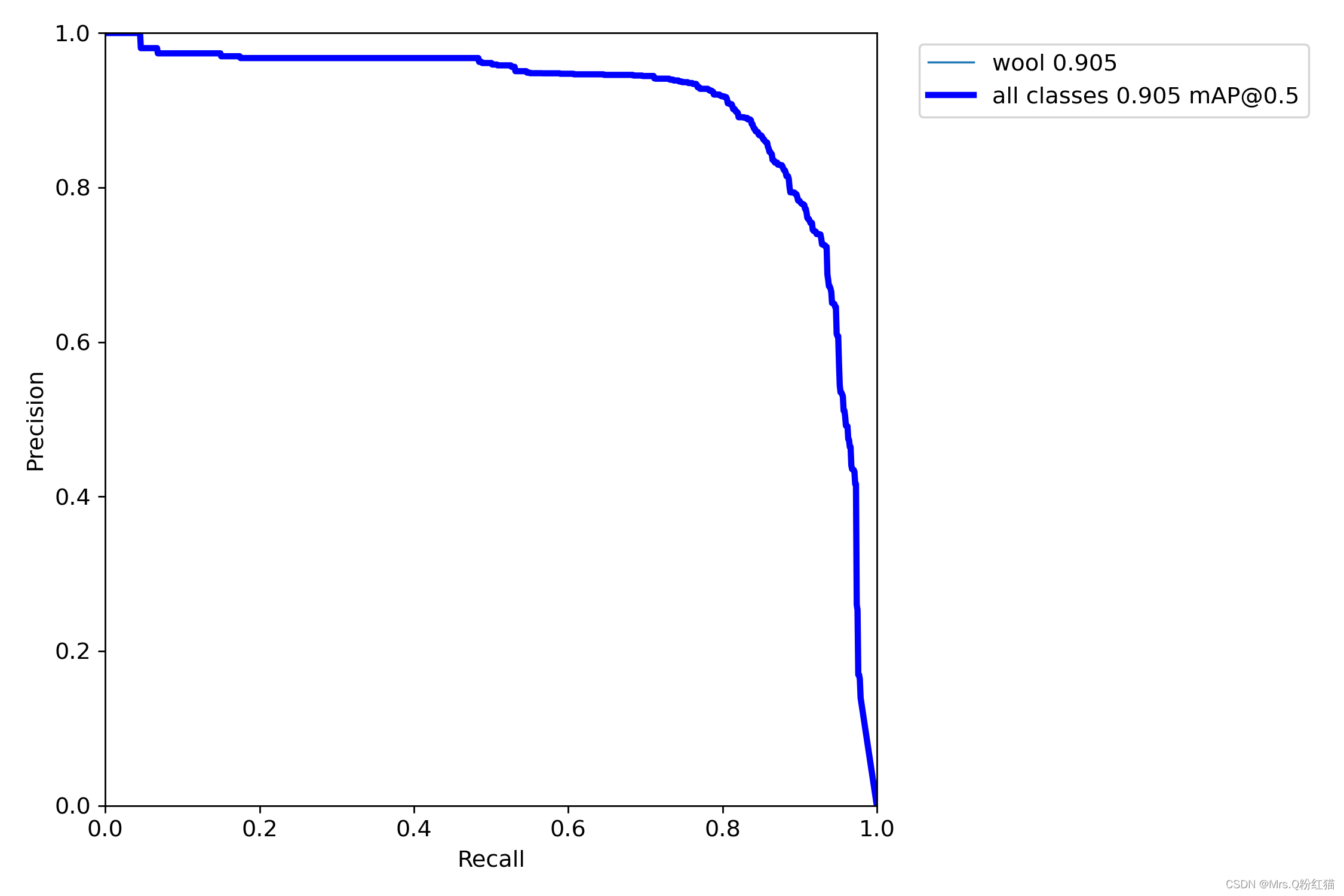
map@0.5 相比之下提升了1.7个百分点。。。。还是阔以的
再看下参数量对比:(imgsize,map@50,mAP50-95,参数量(M),FLOPs)


对比之下参数量和FLOPs确实有增加,但同时map也相应地增加了,这种的增加不大,还是可以接受的。